基于改進(jìn)YOLOv2網(wǎng)絡(luò)的密集人群場景行人檢測
2018-11-03 06:03:58張楚楚呂學(xué)斌
現(xiàn)代計(jì)算機(jī) 2018年28期
張楚楚,呂學(xué)斌
(1.四川大學(xué)計(jì)算機(jī)學(xué)院,成都 610065;2.四川大學(xué)視覺合成圖形圖像技術(shù)國家重點(diǎn)學(xué)科實(shí)驗(yàn)室,成都 610065)
0 引言
行人檢測(Pedestrian Detection)是利用計(jì)算機(jī)視覺技術(shù)判斷圖像或者視頻序列中是否存在行人并給予精確定位。目前廣泛應(yīng)用于視頻監(jiān)控、人工智能系統(tǒng)、車輛輔助駕駛系統(tǒng)、智能機(jī)器人、智能交通等領(lǐng)域。近年來各個(gè)科技公司大力發(fā)展的無人駕駛汽車項(xiàng)目使得行人檢測技術(shù)成為當(dāng)今的研發(fā)熱點(diǎn)。雖然經(jīng)過多年的發(fā)展,行人檢測技術(shù)取得了精度和速度上的較大進(jìn)步。但由于行人本身所具有的非剛性的特性,外觀易受穿著、尺度、姿態(tài)和視角等影響。尤其是密集人群場景中行人密度大,遮擋問題更為嚴(yán)重,而且要保證較高的實(shí)時(shí)性。這些問題又使得行人檢測成為計(jì)算機(jī)視覺領(lǐng)域中一個(gè)極具挑戰(zhàn)性的問題。
本文主要針對密集人群場景進(jìn)行行人檢測。通過對大量密集人群場景的行人數(shù)據(jù)進(jìn)行分析,提出改進(jìn)的YOLOv2網(wǎng)絡(luò)并引入了用于檢測行人的頭肩模型,在不影響行人檢測的實(shí)時(shí)性的前提下,提高密集人群場景行人檢測的準(zhǔn)確性。
1 概述
傳統(tǒng)的行人檢測往往采用手工設(shè)計(jì)模型的方法。比較典型的有以下幾種:Viola和Jones[1,2]采用AdaBoost學(xué)習(xí)算法提取基本和擴(kuò)展的Haar-like特征,用于視頻監(jiān)控的行人檢測。Dalal等人[3]提出了梯度方向直方圖特征(Histogram of Oriented Gradient,HOG),并采用SVM分類器來訓(xùn)練模型。Pedro Felzenswalb等人[4]提出的經(jīng)典的基于統(tǒng)計(jì)學(xué)習(xí)可形變部件模型(Deformable Part Model,DPM)目標(biāo)檢測算法。這些方法在當(dāng)時(shí)都取得了很好的成果。但是,人工設(shè)計(jì)特征提取器很難應(yīng)對復(fù)雜場景和多特征融合的問題。隨著卷積神經(jīng)網(wǎng)絡(luò)的迅速發(fā)展,研究人員開始將深度學(xué)習(xí)模型應(yīng)用到目標(biāo)檢測上來[5]。區(qū)域建議卷積神經(jīng)網(wǎng)絡(luò)(Regions with Convolutional Neural Network,RCNN)[6]、空間金字塔池化網(wǎng)絡(luò)(Spatial Pyramid Pooling Net,SPP-Net)[7]、Fast R-CNN[8]、Faster R-CNN[9]、YOLO(You Only Look Once)[10]、SSD(Single Shot MultiBox Detector)[11]這一系列目標(biāo)檢測算法的精確度和速度都在不斷的提高著。其中Redmon等人在YOLO網(wǎng)絡(luò)的基礎(chǔ)之上通過設(shè)計(jì)新的網(wǎng)路結(jié)構(gòu)提出的YOLOv2[12]算法是當(dāng)前最為優(yōu)秀的目標(biāo)檢測算法之一,在目標(biāo)檢測的實(shí)時(shí)性和準(zhǔn)確性上,取得了突破性的進(jìn)展。
根據(jù)最新的目標(biāo)檢測技術(shù)的發(fā)展,本文提出將YOLOv2網(wǎng)絡(luò)應(yīng)用于密集人群場景的行人檢測。對于密集人群場景的行人檢測,最大的難點(diǎn)就是行人的遮擋問題,如行人和行人、行人與其他物體的遮擋。遮擋問題會(huì)產(chǎn)生關(guān)鍵屬性的丟失,導(dǎo)致基于目標(biāo)整體形狀的信息進(jìn)行分析的算法準(zhǔn)確性大大降低。相對于人體多變性的特點(diǎn),人體頭肩區(qū)域的形狀變化最小,具有較高的穩(wěn)定性。所以本文將密集人群場景的行人檢測問題轉(zhuǎn)化為頭肩部位的檢測。頭肩模型的引入又產(chǎn)生另外一個(gè)問題,就是頭肩區(qū)域在人體整體區(qū)域中占比較小,在YOLOv2網(wǎng)絡(luò)多層卷積、池化提取高度抽象特征后,可能會(huì)造成小目標(biāo)信息丟失,所以本文相應(yīng)的改進(jìn)了YOLOv2的網(wǎng)絡(luò)結(jié)構(gòu)來提高“頭肩”模型的檢測效果。
2 本文工作
2.1 網(wǎng)絡(luò)結(jié)構(gòu)
多數(shù)的檢測系統(tǒng)使用VGG-16[13]作為基礎(chǔ)特征提取器。VGG-16是一個(gè)高精度的有效的分類網(wǎng)絡(luò),但是有些過于復(fù)雜。YOLOv2使用DarkNet-19作為目標(biāo)檢測的分類網(wǎng)絡(luò),DarkNet-19對圖片做前向計(jì)算速度更快。相較于YOLOv1網(wǎng)絡(luò),YOLOv2的改進(jìn)主要在以下幾個(gè)方面:(1)使用了Batch Normalization[14]穩(wěn)定模型訓(xùn)練,加速訓(xùn)練的收斂并泛化模型。(2)針對YOLOv1利用全連接層預(yù)測邊框?qū)е聛G失空間信息以及定位不準(zhǔn)的問題,YOLOv2采用了類似Faster-RCNN的anchor boxes機(jī)制,來預(yù)測圖片中的行人候選框,在訓(xùn)練過程中網(wǎng)絡(luò)會(huì)動(dòng)態(tài)的調(diào)整anchor boxes的大小。(3)采用多尺度訓(xùn)練提高對不同尺寸圖像檢測的魯棒性。(4)針對小目標(biāo)的檢測,進(jìn)行了部分卷積層的特征重排和特征融合。
本文為提高“頭肩”模型在密集人群場景行人檢測下的檢測質(zhì)量,一方面通過添加兩個(gè)不同分辨率的轉(zhuǎn)移層直接把淺層特征圖連接到深層特征圖即將高層的語義信息和不同層次低級特征信息進(jìn)行融合,在考慮行人粗粒度全局特征的情況下又考慮了細(xì)粒度的局部特征。另一方面在融合低級特征信息前使用1×1的卷積核對低級特征進(jìn)行卷積操作。新增加的卷積操作實(shí)現(xiàn)了低級特征跨通道的信息交互和整合,并且在尺度不變的條件下減少了模型的參數(shù)進(jìn)而在增加網(wǎng)絡(luò)深度的同時(shí)降低了對檢測實(shí)時(shí)性的影響。本文提出了YO?LOv2-E網(wǎng)絡(luò)(如圖1所示)。
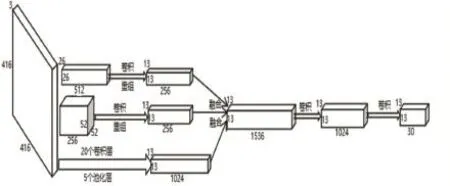
圖1 YOLOv2-E網(wǎng)絡(luò)結(jié)構(gòu)圖
2.2 頭肩模型
對于密集人群場景的行人檢測問題,最重要的就是解決行人遮擋問題。如圖2(a)為行人遮擋問題的一個(gè)樣例。基于整體特征的檢測對遮擋問題造成的部分屬性信息甚至是關(guān)鍵屬性信息的缺失更加敏感。不能很好地解決遮擋問題,檢測的準(zhǔn)確性就難以保證。通過分析大量密集場景人群的數(shù)據(jù),發(fā)現(xiàn)行人的頭肩部位在數(shù)據(jù)中的可見性最高,而且在行人姿態(tài)變化較大的時(shí)候,頭肩部位依然保持著較高的穩(wěn)定性[15]。如圖2(b)為行人姿態(tài)變化的一個(gè)樣例。頭肩的輪廓始終保持近似豎直的矩形框,這也提高檢測的魯棒性。所以本文提出頭肩模型來進(jìn)行密集人群場景的行人檢測。

圖2 頭肩模型在復(fù)雜場景中的應(yīng)用
2.3 改進(jìn)的YYOOLLOO.2--EE算法的實(shí)現(xiàn)步驟
輸入:圖片數(shù)據(jù)集X
輸出:圖片數(shù)據(jù)集X的特征檢測器模型
步驟1:圖片預(yù)處理,針對本算法使用的頭肩模型,在數(shù)據(jù)集X中使用標(biāo)注工具對每張圖片生成頭肩目標(biāo)的矩形區(qū)域坐標(biāo)。
步驟2:將預(yù)處理完的圖片數(shù)據(jù)X輸入網(wǎng)絡(luò)經(jīng)過20個(gè)卷積層和5個(gè)池化層獲取深層特征圖13×13×1024,同時(shí)經(jīng)過轉(zhuǎn)移層逆向提取前面網(wǎng)絡(luò)經(jīng)過連續(xù)3×3、1×1 卷積的兩個(gè)淺層特.6×26×512 和 52×52×256。對提取的淺層特征使用卷積和池化操作進(jìn)行跨通道信息整合并通過重組層將得到的新特征分別重組為13×13×256.3×13×256。然后將兩層淺層特征和深層特征進(jìn)行堆疊并經(jīng)3×3卷積層把通道數(shù)降為1024。
步驟3:網(wǎng)絡(luò)是在最后一層生成的13×13特征圖的每個(gè)cell上根據(jù)k個(gè)anchor boxes預(yù)測k個(gè)bounding boxes。但是由于anchor boxes是一種先驗(yàn)知識,對訓(xùn)練的樣本X進(jìn)行統(tǒng)計(jì),選取合適的anchor boxes數(shù)目和形狀作為初始的anchor boxes會(huì)加快訓(xùn)練模型的收斂。算法使用文獻(xiàn)[11]定義的新的距離公式d(box,centroid)=1-IOU(box,centroid)
步驟4:對步驟2生成的13×13×1024特征卷積獲取最后網(wǎng)絡(luò)輸出特征圖的卷積操作的卷積核深度filters=k*(classes_num+5),其中k為上一步得到的an?chor boxes的數(shù)目,classes_num為預(yù)測類別數(shù),5表示每一個(gè)bounding box預(yù)測5個(gè)值,其中前四個(gè)是坐標(biāo)參數(shù),第五個(gè)是每個(gè)bounding box的置信度。經(jīng)過這一層的卷積降采樣得到網(wǎng)絡(luò)的最終特征圖。
步驟5:在最終的13×13特征圖上根據(jù)步驟3得到的anchor boxes信息和直接位置預(yù)測(Direct Location Prediction)算法[12]預(yù)測 bounding boxes,對得到的每個(gè)bounding box利用其置信度和判別框閾值進(jìn)行比較,丟棄小于閾值的,然后再利用非極大值抑制算法(Non-Maximum Suppression)對留下的bounding boxes進(jìn)行篩選,去除冗余。
步驟6:根據(jù)步驟5預(yù)測到的bounding boxes和步驟1獲得的實(shí)際目標(biāo)框信息計(jì)算損失值,并利用反向傳播算法優(yōu)化網(wǎng)絡(luò)參數(shù),訓(xùn)練中根據(jù)訓(xùn)練結(jié)果動(dòng)態(tài)的改變學(xué)習(xí)率,在網(wǎng)絡(luò)收斂后,輸出數(shù)據(jù)集X的特征檢測器模型。
3 實(shí)驗(yàn)
本文使用開源的Google神經(jīng)網(wǎng)絡(luò)框架Tensor?Flow,分別以YOLOv2、YOLOv2-E作為訓(xùn)練網(wǎng)絡(luò),訓(xùn)練行人檢測器。選用推薦的沖量系數(shù)0.9,衰減系數(shù)0.0005,每次迭代的圖片數(shù)量64。初始學(xué)習(xí)率為0.0001的動(dòng)態(tài)學(xué)習(xí)率設(shè)置策略,在迭代次數(shù)為100、20000、40000次時(shí)學(xué)習(xí)率依次發(fā)生改變(steps=100,20000,40000),學(xué)習(xí)率變化的比.0、0.1、0.1,與steps中的值對應(yīng)。
3.1 實(shí)驗(yàn)及數(shù)據(jù)準(zhǔn)備
(1)由于國內(nèi)外沒有公開可獲取的密集人群場景的行人數(shù)據(jù)集,所以本文使用工作中采集的8000張密集人群場景的行人圖片,并將分辨率歸一化為416×416。首先對圖片進(jìn)行人工標(biāo)注頭肩框,然后將標(biāo)注好的數(shù)據(jù)轉(zhuǎn)換為YOLOv2網(wǎng)絡(luò)要求的數(shù)據(jù)格式。本文選出6000張圖片作為訓(xùn)練數(shù)據(jù)樣本,剩下的2000張作為測試數(shù)據(jù)樣本。
(2)對本文使用的數(shù)據(jù)集的標(biāo)注框進(jìn)行聚類來獲取最優(yōu)的anchor boxes數(shù)目k和形狀信息。聚類結(jié)果如表1所示。
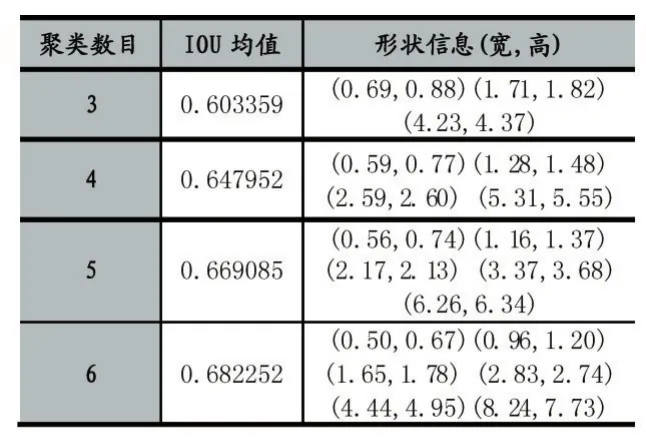
表1 訓(xùn)練數(shù)據(jù)集頭肩框聚類結(jié)果
表1中的聚類數(shù)目也就是anchor boxes數(shù)目。IOU(Intersection-Over-Union)值就是檢測網(wǎng)絡(luò)預(yù)測得到的bounding box和ground truth的交并比。本文表中的IOU均值越大,表示聚類得到的一系列的bounding box的形狀越符合行人的頭肩框的形狀,網(wǎng)絡(luò)收斂速度越快。雖然聚類數(shù)越多準(zhǔn)確率越高,但是考慮模型復(fù)雜度,所以綜合考慮,取k值為5。
3.2 訓(xùn)練和結(jié)果分析
利用上文3.1小節(jié)中獲取的訓(xùn)練數(shù)據(jù)、anchor boxes信息和相同的訓(xùn)練配置信息分別使用YOLOv2網(wǎng)絡(luò)和YOLOv2-E網(wǎng)絡(luò)進(jìn)行訓(xùn)練。
本文改進(jìn)網(wǎng)絡(luò)的目的是增強(qiáng)對人體局部區(qū)域和小目標(biāo)的識別效果,也就是改善YOLOv2網(wǎng)絡(luò)對行人細(xì)粒度特征利用不充分而造成對那些被遮擋的行人和小目標(biāo)的漏識。綜合考慮,本文采用通用的每張圖片漏識率誤識率(Miss Rate against False Positives Per Image,MR-FPPI)曲線來比較兩種網(wǎng)絡(luò)生成的檢測模型在數(shù)據(jù)集上的效果。
(1)模型在圖片數(shù)據(jù)集上的測試分析
漏識率和誤識率都跟預(yù)測框判別閾值相關(guān)。網(wǎng)絡(luò)生成的多個(gè)bounding box,每一個(gè)都有一個(gè)表示該框中是否含有目標(biāo)的置信度,針對每一個(gè)bounding box,將其置信度值和該判別閾值進(jìn)行比較,只有大于該閾值的bounding box才會(huì)留下進(jìn)行下一步的檢測。低閾值會(huì)產(chǎn)生低漏識率和高誤識率,高閾值會(huì)會(huì)產(chǎn)生高漏識率和低誤識率。經(jīng)過多次實(shí)驗(yàn)發(fā)現(xiàn),在預(yù)測框判別閾值為 0.70和0.75時(shí),YOLOv2和YOLOv2-E的FPPI分別降為0。此后,隨著閾值的增加,F(xiàn)PPI始終不變,對考察兩種網(wǎng)絡(luò)效果的意義不大。所以本文僅使用從0開始,每次0.05,到0.75結(jié)束的不同的閾值來檢測兩種網(wǎng)絡(luò)的效果。
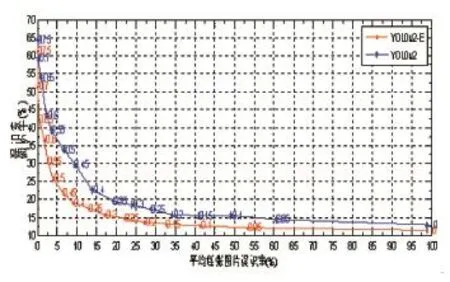
圖3 YOLOv2和YOLOv2-E網(wǎng)絡(luò)檢測效果對比圖
結(jié)果如圖3所示。曲線上的點(diǎn)顯示的數(shù)字就是得到當(dāng)前誤識率和漏識率值時(shí)采用的判別閾值。通過曲線圖可以看出在相同的閾值條件下,YOLOv2-E網(wǎng)絡(luò)的漏識率和誤識率有了明顯的降低。檢測效果如圖4所示。

圖4 頭肩模型和全身模型檢測效果圖
(2)模型在監(jiān)控視頻中的測試分析
實(shí)驗(yàn)采用兩臺(tái)海康DS-2CD7046F-(A)槍型網(wǎng)絡(luò)攝像機(jī),視頻分辨率和幀率設(shè)為1280×720,30幀每秒。分別使用YOLOv2和YOLOv2-E生成的檢測模型在學(xué)校人流密集時(shí)間段進(jìn)行測試,將模型的預(yù)測框判別閾值設(shè)為0.35。
對兩種模型檢測過的視頻中出現(xiàn)行人較為密集的某個(gè)相同區(qū)間的100幀圖像進(jìn)行統(tǒng)計(jì),共出現(xiàn)3185個(gè)行人,平均每幀有31.85個(gè)行人。從最終實(shí)驗(yàn)結(jié)果中人工統(tǒng)計(jì)出漏識人數(shù)和誤識別人數(shù)。兩種模型的檢測結(jié)果如表2所示。
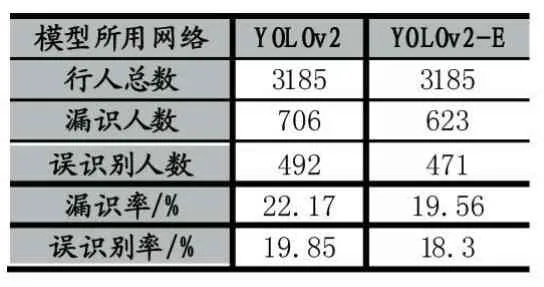
表2 部分幀行人檢測結(jié)果
由表2的結(jié)果可以看出YOLOv2-E網(wǎng)絡(luò)在監(jiān)控視頻流中檢測行人的效果相比原始的YOLOv2有了提升,即降低了檢測的漏識率和誤識別率。
4 結(jié)語
將“頭肩”模型結(jié)合改進(jìn)的YOLOv2網(wǎng)絡(luò)應(yīng)用于密集人群場景的行人檢測,充分利用了行人相對穩(wěn)定的頭肩區(qū)域信息,最大程度地避免了行人其他部位的形態(tài)改變和被遮擋造成的信息丟失對檢測效果的影響。但是頭肩模型在考慮檢測目標(biāo)時(shí),未能充分利用目標(biāo)所提供的全部信息。而且,僅使用頭肩部位的特征信息,對于監(jiān)控場景中出現(xiàn)的特征信息與行人頭肩信息比較相近的物體時(shí),檢測系統(tǒng)將其誤識為行人的概率會(huì)進(jìn)一步加大。下一步的研究重點(diǎn)是怎樣更好地挖掘和利用行人表達(dá)出來的有效特征信息,使檢測模型可以應(yīng)對所有的復(fù)雜場景并提高行人檢測準(zhǔn)確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
