改進模板匹配的通信目標識別技術
2018-10-29 01:39:40于小紅程嘉遠
現代防御技術 2018年5期
于小紅,程嘉遠
(1.江蘇自動化研究所,江蘇 連云港 222006;2.長春理工大學 電子信息工程學院,吉林 長春 130022)
0 引言
在軍事通信對抗中,只有識別出敵方目標并采取正確的應對措施,才能取得主動權。所以說通信信號的識別是通信對抗的前提和關鍵。
歷史上人們曾經普遍采用口令、暗號、圖符等目標識別方法,水面艦艇則采用旗語、信號燈等識別方法。這些識別方法主要依靠視聽手段來識別近處目標的外部特征,不能識別遠距離目標、小目標和電磁頻譜等無形目標。隨著技術的發展,電子偵察能夠發現的目標距離遠遠超過了目視范圍,上述識別方法已不適用。人們不斷研究和提出新的目標識別方法,技術越來越復雜,識別的目標距離越來越遠,識別出的目標類型也越來越精確。
通信目標識別是指根據通信偵察設備偵測到的目標通信信號參數,識別、確定通信目標的類別、種類和屬性的過程。它是通信對抗要解決的首要問題,同時也是通信干擾的前提和基礎。近年來,通信目標識別受到通信對抗人員的高度重視,相繼提出了多種識別方法,如模式識別、模糊模式識別法[1]、DS證據理論目標識別法[2-6]、模板匹配法[7-8]等。將觀測到的目標模式與已知的模式進行比較、配準,判斷目標類屬的過程就是模式識別。模糊模式識別即模式識別的模糊集方法,是在模式識別中引入模糊數學理論對目標進行更為有效的分類與識別方法。DS證據理論是基于基本概率分配函數的一種不確定性推理方法。
模板匹配法是一種最基本的模式識別方法。它是一種基于統計的識別方法,將直接觀測到的數據與數據庫中的原始數據進行對比,計算輸入模式與數據庫中各個模式的匹配度據此進行目標識別。對通信對抗來說就是識別出敵方可能的通信設備型號。模板匹配法因為相對簡單,在實際工作中得到了較為廣泛的應用。但在實際的通信對抗中,偵察數據基本上都存在誤差或不完整,對基于模板匹配的通信目標識別帶來了很大困難。為此,本文提出了一種改進的模板匹配方法,提高了數據誤差或參數缺失情況下的通信目標識別率。
1 通信目標識別基本思路
圖1為基本的通信目標識別過程。
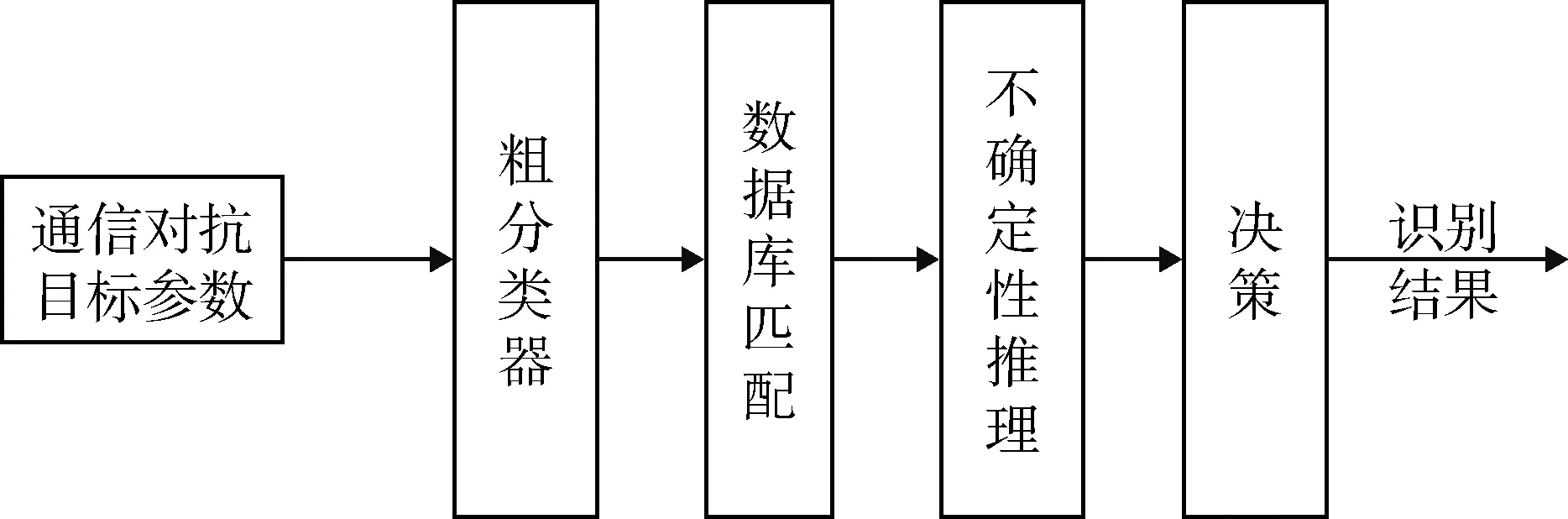
圖1 通信目標識別過程Fig.1 Communication object recognition process
圖中各部分說明如下:
(1) 通信對抗目標參數:通信偵察設備獲取的目標通信參數。
(2) 粗分類器:根據通信偵察設備偵測到的目標參數,識別該通信信號的工作體制,進行通信目標信號的粗分類。
(3) 數據庫匹配:根據粗分類器的識別結果,把偵測到的目標參數與數據庫中該體制下所有的通信特征參數進行比對分析,計算每個特征參數的匹配度,選取大于閾值的匹配度對應的模式作為一個證據。當證據有多個時,形成證據集,為后續的不確定性推理服務。
(4) 不確定性推理:采用不確定推理技術對多個證據進行推理及組合。若系統不進行不確定性推理而直接進行決策,可將具有最大匹配度的模式作為最終的識別結果。
(5) 決策:確定通信目標識別的最終結果,一般選取最大可信度的通信型號為最終識別結果。
2 改進模板匹配的通信目標識別方法
2.1 參數歸一化
為了發揮數量級差別較小的目標參數在目標識別中的作用,通常需要對目標參數進行歸一化處理。目標參數歸一化主要對參數進行從有量綱到無量綱的一個處理,保證每個參數在同一個區間上取值。常用的參數歸一化方法有線性歸一化、非線性歸一化。非線性歸一化又分為對數法、指數法等。
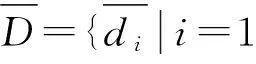
(1) 線性歸一化
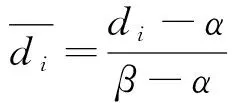
(1)
(2) 對數法
(2)
式中:C=lnγ,γ為滿足αγ≥1的常數。對數中的常數γ是為了保證小數據取對數后為正值。因為自然對數函數是增函數,所以可以保證比α大的小數據取對數后為正值。
(3) 指數法
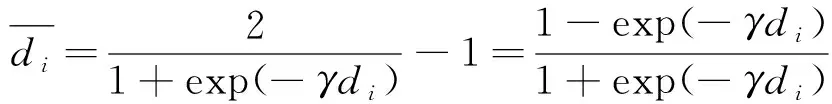
(3)
式中:γ須滿足βγ≤k,k為常數,一般取k=20。
線性歸一化對小數據的區分能力不強;指數法對大數據的區分能力不強;只有對數法歸一化后的數據分布較均勻,易于數據的分離[9]。
2.2 模板匹配法
把測量模板與樣本模板進行比對的過程,稱為模板匹配。測量模板即偵測數據,樣本模板即數據庫中的特征參數。偵測數據與數據庫中的特征樣本匹配的好壞,取決于偵測數據各單元與數據庫中對應的各特征參數匹配的好壞。
為了使模式空間中的點X,Y,Z的距離能作為這些樣本之間相似度的度量,所選的距離函數應滿足下列條件:
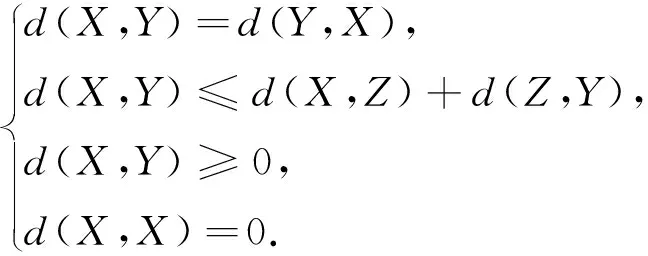
(4)
這里列舉出若干種滿足以上距離條件的函數[10]:
(1) Manhattan 距離
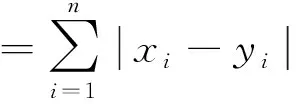
(5)
(2) Euclidean 距離
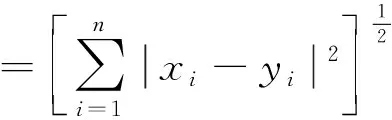
(6)
(3) “City-Block”距離
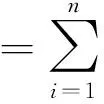
(7)
式中:ωi為第i個特征參數在識別中所占的權重。
2.3 改進的模板匹配法
經過理論計算,使用City-Block距離比使用Manhattan距離和Euclidean距離有更高的目標識別率,因此通常選擇City-Block距離作為通信目標識別的數據庫匹配方法。但是,由于City-Block距離不能很好地解決通信參數誤差大或缺失情況下的目標識別問題,本文提出了一種修正“City-Block”距離方法。
文獻[9,11]也提出了一種改進的“City-Block”距離方法,如式(8)所示。但對式(8)進行分析發現:①當偵測數據或模板數據為0時,并不能保證歸一化后的數據在[0,1]之間;②當xi>2,yi>0時,歸一化后的數據大于1;③當xi-yi相同時,不論xi>yi或yi>xi,結果卻完全不同。
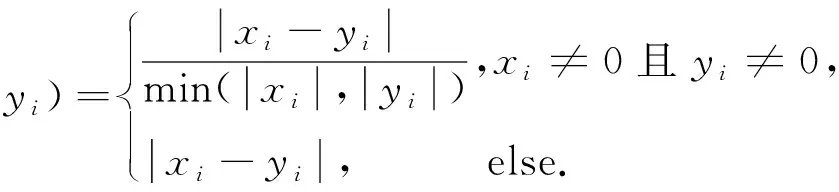
(8)
本文提出的修正“City-Block”距離方法,通過對數歸一化,并選擇最大的特征參數值進行歸一化,解決了上述問題。
根據先對數歸一化然后計算距離誤差的原理,根據式(2)和式(7)可得到下列公式
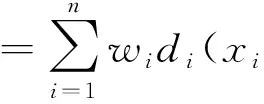
(9)
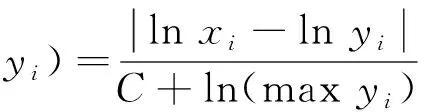
(10)
式(9)中的d越大,說明兩者之間的差異越大,相似程度越小;反之d越小,說明兩者之間的差異越小,相似程度越大。其中,d(X,Y)為待匹配測量模板數據與數據庫中模板數據之間的距離,X為通信偵察設備的測量數據,xi為測量數據中第i個特征參數;Y為數據庫中的模板數據,yi為模板數據中第i個特征參數,maxyi為第i個特征參數的最大值;ωi為第i個特征參數在識別中所占的權重。
通信信號特征參數有頻率、帶寬、電平、調制方式[12]等,由于通信頻率、信號調制方式、信號帶寬、頻點個數、頻率范圍等各類通信參數對目標的區分能力不同,因此它們對目標識別的貢獻率也有所不同,不同的貢獻率賦予不同的權重。權重的計算方法有專家經驗法[13]、層次分析法[14]、熵值計算法[15]等。專家經驗法主觀性強,不同的專家經驗不同,選擇的權重系數不同,造成的識別結果也不同。層次分析法通過比較兩兩特征參數對目標識別的重要性,建立判斷矩陣,通過計算判斷矩陣的特征值求解權重系數。熵是信息論中的一個重要概念,熵值的大小用來表示該特征參數的影響系數。熵值越大,越不能很好地區分目標之間的差異,識別結果越不穩定,對識別結果的貢獻就越小。反之熵值越小,識別結果就越趨于穩定,對識別結果的貢獻就越大。熵值計算法算法簡單、實現速度快。
設數據庫中共有m個通信目標型號,有n個特征參數,P為數據庫歸一化的特征參數矩陣,則第i個特征參數的熵值可以用式(11)計算。
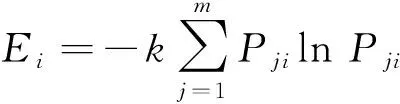
(11)
式中:k>0。
定義第i個特征參數的權重系數為
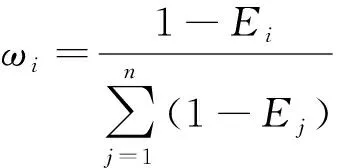
(12)
令S表示偵察數據X與Y數據庫中模板數據之間的相似度,如式(13)所示,S越大,相似程度越大;反之,則相似程度越小。
S(X,Y)=1-d(X,Y).
(13)
3 仿真分析
3.1 仿真條件
由于在通信偵察過程中,參數很難完全獲得,往往會出現參數不完整的情況。因此仿真計算過程分參數完整和參數不完整2種情況分別進行仿真。分別假設識別數據庫有30個和200個通信目標類型,每個目標類型的通信參數包括設備的常用頻率、最小頻率、最大頻率、頻點個數、信號調制方式、信號帶寬、信號電平等。
3.2 仿真結果
(1) 參數完整時4種識別方法的識別正確率比較
當參數完整時,各特征參數匹配法在不同誤差下的識別率如圖2,3所示。圖2為數據庫有30個通信目標類型的識別率,圖3 為數據庫有200個通信目標類型的識別率。
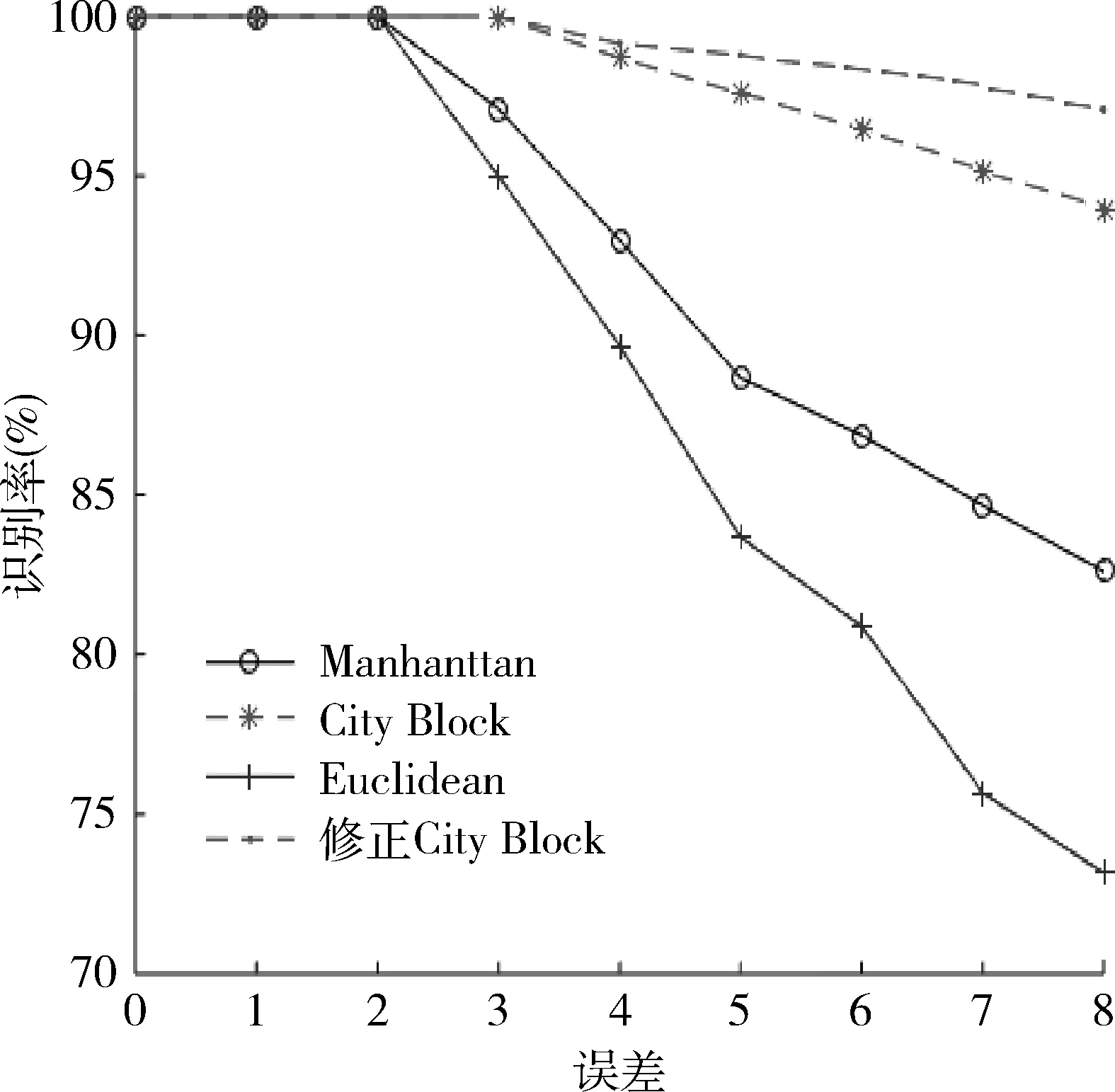
圖2 數據庫有30個通信目標類型的識別率 Fig.2 Recognition rates with 30 types of communication object in database
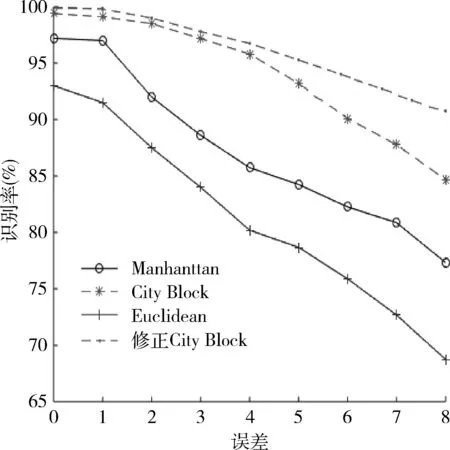
圖3 數據庫有200個通信目標類型的識別率Fig.3 Recognition rates with 200 types of communication object in database
從圖2,3可以看出,測量誤差為3%時,Manhattan 匹配法和Euclidean匹配法識別率下降明顯,前者的識別率為88%,而后者的識別率為83%左右;測量誤差為8%時,Euclidean 匹配法識別率下降更快,識別率只有70%左右,City-Block識別率達到了85%,修正City-Block在2種情況下,識別率都達到90%以上。在4種方法中,修正City-Block識別率最高。
(2) 參數不完整時4種識別方法的識別正確率比較
在通信對抗中,往往存在著偵察反偵察、對抗反對抗的交鋒。通信環境復雜、交錯、多變。因此在現實情況中,很難完全獲得敵方的通信參數,經常會出現通信參數不完整的情況。
當待識別的參數數據有一個特征參數缺失時,這4種特征參數匹配法在不同測量誤差下的識別率如圖4,5所示。圖4是頻點個數缺失下4種方法的識別率,圖5是信號調制方式缺失下4種方法的識別率。
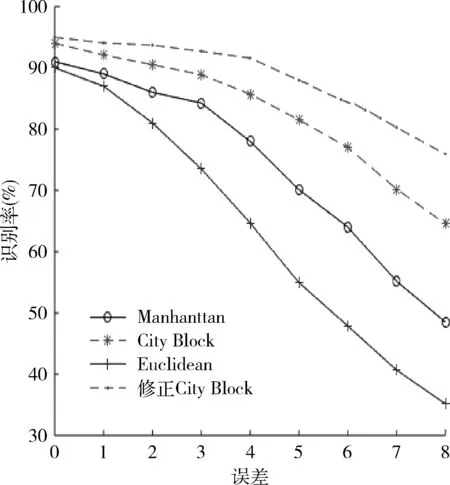
圖4 頻點個數缺失下的識別率Fig.4 Recognition rates with missing number of frequency points
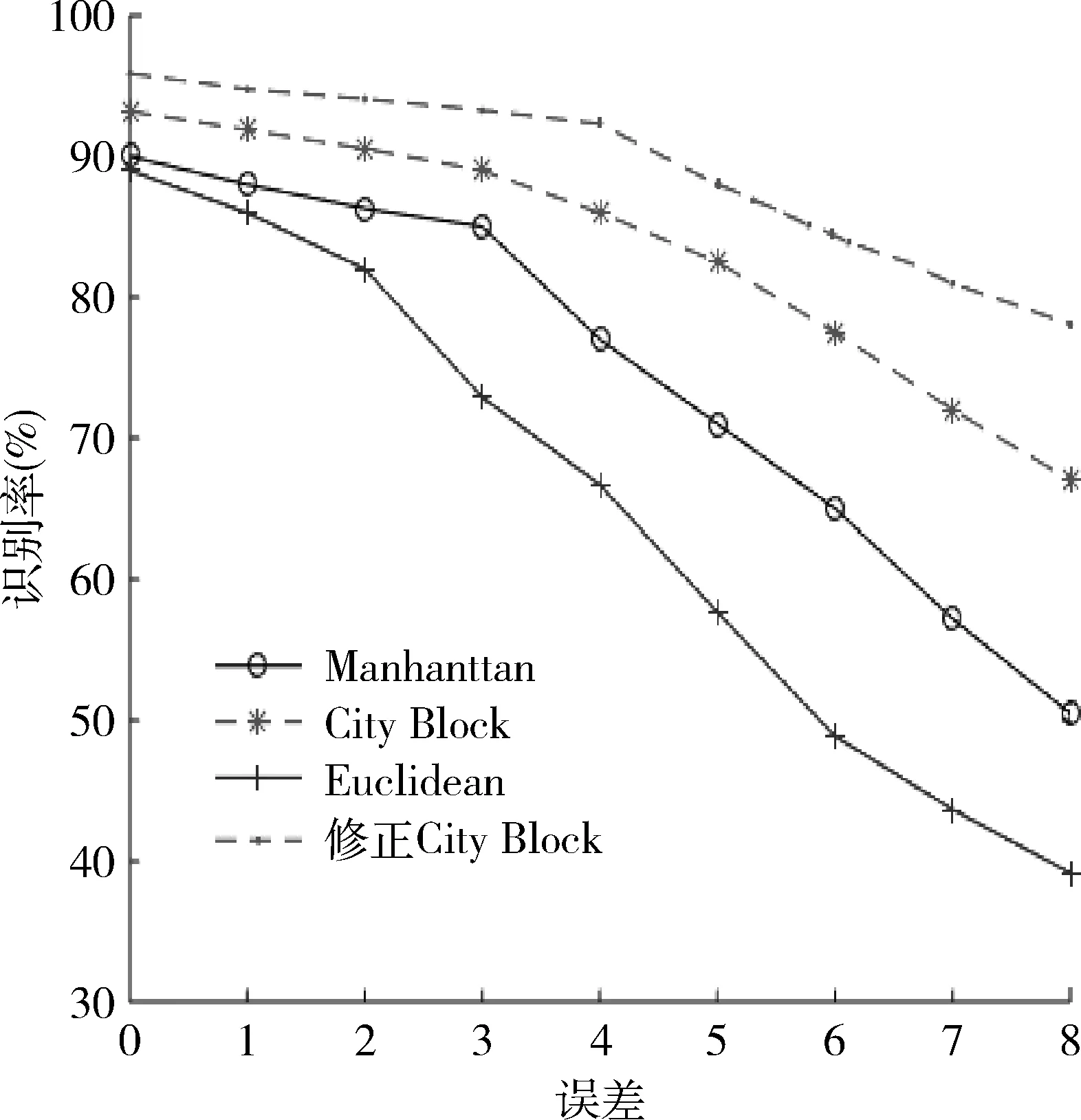
圖5 信號調制方式缺失下的識別率Fig.5 Recognition rates with missing signal modulation modes
從圖4,5可以看出,測量誤差大于3%時, Manhattan 匹配法和Euclidean匹配法識別率下降明顯,前者識別率為84%,后者識別率為77%;測量誤差為8%時,Euclidean 匹配法識別率下降更快,識別正確率只有35%。而City-Block和修正City-Block方法在測量誤差為3%時,識別率分別為88%和92%。隨著測量誤差不斷增大達到8%時,City-Block方法的識別率為64%,而修正City-Block方法識別率為76%。
總之,無論參數完整還是部分缺失,修正City-Block方法在4種方法中識別率都最高。但該方法僅適用于識別數據庫里已存有通信目標類型的目標識別情形,對新增通信目標類型的目標識別有待提高。
4 結束語
在信息化作戰條件下,作戰環境十分復雜。作戰雙方都會采用偽裝、隱蔽、欺騙和干擾等手段和技術,進行識別和反識別的交鋒,從而造成目標識別信息的不精確、不完整、不可靠等。本文針對實戰條件下可能出現的偵察數據誤差大和通信參數缺失的情況,提出了一種修正City-Block模板匹配方法。通過仿真計算,無論參數完整或缺失,修正City-Block匹配方法都實現了較高的通信目標識別正確率,同時還具有較好的容錯性。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
