基于多信息融合的Mean-Shift跟蹤算法*
2018-10-26 06:11:10郭瑞峰張文輝彭戰奎
傳感器與微系統 2018年11期
關鍵詞:檢測
郭瑞峰, 張文輝, 劉 娜, 彭戰奎
(1.西安建筑科技大學 機電工程學院,陜西 西安 710055;2.西安理工大學 計算機科學與工程學院,陜西 西安 710055)
0 引 言
Mean-Shift算法[1,2]使用目標物的顏色直方圖作為目標模型,對于目標物受部分遮擋表現出一定的魯棒性,但對于長時間跟蹤的目標物受光照變化、尺度變化以及全部被遮擋時,往往會跟蹤失敗。很多學者提出將Mean-Shift與Kalman相結合,可以解決短時間內目標物受遮擋或運動狀態發生變化導致跟蹤失敗的問題,但算法的魯棒性差,難以實現目標物的長時間跟蹤[3]。Kalal Z等人提出跟蹤—學習—檢測(tracking-learning-detection,TLD)跟蹤算法,將機器學習與傳統的跟蹤算法相結合,能夠實現目標物的長時間跟蹤,卻存在算法復雜,實時性差等缺點。[4]
本文借鑒TLD算法的思想,在Mean-Shift+Kalman算法基礎上引入檢測機制和學習機制[5],提出了一種將Mean-Shift跟蹤算法與Kalman濾波器以及在線學習檢測器相融合的算法,可以有效解決光照變化,部分或全部遮擋以及尺度變化等導致目標物跟蹤丟失的問題,實現對目標物較長時間的跟蹤。
1 跟蹤算法研究
所提算法由Mean-Shift跟蹤器、在線學習檢測器、Kalman濾波器組成。在線學習能夠防止檢測器發生“誤檢”和“漏檢”的現象,并更新檢測器參數,使得檢測器具備較好的檢測性能。引入Kalman濾波器將其預測值作為檢測器檢測的初始位置,以此提高檢測效率,此外Kalman濾波器還具有精準估計目標位置的作用。跟蹤目標時,Mean-Shift跟蹤器跟蹤目標并輸出目標位置,成功跟蹤目標后進行,當跟蹤器跟蹤失敗(巴氏系數作為判斷閾值)則啟動檢測器,檢測成功后(相似度系數作為判斷閾值)輸出目標位置并更新跟蹤器的目標模板。跟蹤結果將跟蹤器、檢測器、Kalman濾波器三者信息融合后,以矩形框的形式出現。
1.1 Mean-Shift跟算法
在Mean-Shift跟蹤算法中,通常在視頻流的第一幀中選擇一個待跟蹤目標,并利用其顏色直方圖作為目標模型的特征[6]。設目標區域內n個像素點記為{xi}i=1,…,n,目標模型的概率密度估計為
(1)
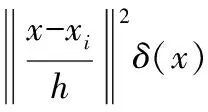
在視頻流第二幀及其以后的每幀圖像中所包含的目標區域稱為候選區域。與目標模型相類似,中心位置為y的候選模型概率密度估計為
(2)
式中ch為標準化的常量系數。nk為候選區域內的總像素個數。
為了使巴氏系數最大,對其在y0點進行Taylor展開,再計算候選區域的中心y0到y的向量
(3)
跟蹤時,按照式(4)進行迭代,并將迭代出來的新值替換y值,當‖y-y0‖<ε時,計算終止
(4)
1.2 級聯檢測器
啟動檢測器可以在搜索窗口中進一步檢查丟失的目標物。采用滑動窗的方法獲得大量的圖像塊Pi(i=1,2,…,n),為了實現分類的時效性,設計一種級聯檢測器來完成分類。級聯分類器由方差濾波器、組合分類器、以及最近鄰分類器(nearest neighbor classifier,NNC)等3部分組成[7]:
1)方差濾波器:識別滑動窗口中目標物和背景區域。
2)隨機蕨組合分類器:通過幾個基分類器(蕨)對由前一級方差濾波器的圖像塊進行像素比較,完成分類。首先在圖像塊中隨機選取Nf個點對,再進行灰度值比較,接下來將Nf個點對分成Mf個蕨。每個蕨中有NS=Nf/Mf個葉子節點。實驗時,選取蕨的數量為10棵,且每棵蕨有13個葉子節點[8]。
3)NNC:對跟蹤器成功跟蹤目標后所輸出的圖像塊計算其匹配概率值,以此判斷是否達到在線學習的閾值要求;作為級聯檢測器中的第三層分類器判斷是否檢測成功。
圖像塊D1和D2的相似度λ2L系數為
2.日本血吸蟲毛蚴 (Schistosoma japonicum miracidium):是日本血吸蟲幼蟲發育中的最早階段,呈梨形或長橢圓形,左右對稱,銀灰色。 大小為(78~120) μm×(30~40) μm,前端有錐形突起,體表具有纖毛。
式中μ1,μ2,σ1,σ2分別為D1和D2的均值和方差;NT為圖像塊的大小。
1.3 P-N在線學習機制
前述的級聯分類器是在離線狀態下由視頻流第一幀標記的數據訓練出來的分類器 (檢測器)不具有很好的泛化能力。另外,在目標跟蹤丟失后,檢測器工作時對正負樣本并不能達到100 %的分類效果,很有可能發生的“誤檢”和“漏檢”的現象,由于誤差的積累,最終可能會導致檢測的失敗。為此,采用P-N在線學習的半監督機制通過時空約束根據跟蹤到的物體產生正負樣本,訓練分類器,更新分類器參數,保證檢測器具有良好的檢測效果[10]。
1.4 Kalman濾波器算法描述
在Mean-Shift算法中,相鄰兩幀圖像中的目標物其偏移量需要小于核函數的帶寬[11],因此,目標物的移動速度直接影響Mean-Shift跟蹤器的跟蹤效果。Kalman濾波器利用系統狀態方程和觀測方程對目標物的運動狀態做出精確預測。Kalman濾波的過程可以被分成兩部分,分別為時間更新和測量更新,二者通過迭代方式完成預測過程。有關Kalman算法可以參考文獻[12]。
1.5 有效檢測區域確定
采用Kalman預測可以確定有效區域[13],從而提高檢測速度,降低時間消耗,其方法如下:
1)Kalman預測當前幀目標物的中心位置;
2)以上述位置畫一個矩形區域,其長寬比與跟蹤框長寬比相同,面積是跟蹤框的4倍;
3)找出所有與規定矩形區域有重疊的子窗口,確定為有效區域,進行檢測器檢測。
1.6 跟蹤器顏色模板更新
檢測器檢測到目標且相似度系數大于設定閾值時,目標物顏色模板以一種賦權重的方式更新,更新公式為[14]
qnew=βq0+(1-β)qk
(5)
式中q0為原始目標顏色直方圖;qk為第k幀檢測器所得到的目標顏色直方圖;β為更新速率因子,取值為0.91。如果目標物變動幅度很大時,應該給檢測器檢測到的目標物顏色直方圖更多的權重,故β取較小值。反之,β取較大值。
2 基于多信息融合的Mean-Shift跟蹤算法
基于以上基礎算法的研究,提出一種多信息融合的Mean-Shift算法,該算法主要是由Mean-Shift跟蹤器、Kalman濾波器、具有半監督學習的檢測器3部分組成
圖1所示為算法的流程,虛線表示通過對圖像塊在線學習后,通過設定參數使得最近鄰分類器得以更新。其中ξZL,ξZLM為相似度閾值。鑒于TLD算法時效性差的特點,從以下方面進行設計:1)跟蹤失敗后再啟動檢測器;2)引入Kalman濾波器,不僅可以提高預測目標物位置的準確度,還可以降低檢測時的復雜度,大大節約了時間開支。
3 實驗與結果分析
實驗進行前需要進行相關參數的設置,其中巴氏系數σBC取0.72,相對相似度的閾值ξZL取0.9(判斷是否能夠進行學習),另一個閾值ξZLM取0.76(判斷是否檢測成功)。
實驗在PC(i5處理器2.30 GHz,8 GB內存)上用MATLAB軟件編程完成。為驗證所提算法的有效性,選用網上公開的3種具有代表性的視頻進行測試。視頻展示了包括目標物部分遮擋或者全部遮擋、長時間消失重現、光照變化、目標大小變化等狀況。對比所提算法與TLD算法和Mean-Shift+Kalman算法(以下簡稱KM算法)分別對視頻流進行處理,觀察跟蹤效果,如圖2所示。其中,1表示MK算法,2表示TLD算法,3表示本算法。

圖2 多信息融合的Mean-Shift算法流程
為評價算法是否具有較長時間的跟蹤性能,圖2所示實驗截圖均為視頻中后段的跟蹤效果,實驗采用的三種跟蹤算法所得部分跟蹤效果對比結果。其中,紅色表示TLD算法,綠色表示本文算法,紅色表示MK算法。
可以看出,本算法在4種場景中跟蹤效果良好。圖2第一列所示為行人運動的場景,此時目標物的形狀比較小。在前面的視頻幀中,3種跟蹤算法表現基本良好。但由于攝像機角度調整,使得目標物在150幀以后消失并在171幀中重新出現,只有本文算法能夠繼續保持良好的跟蹤效果,而MK算法則發生了嚴重的漂移。雖然TLD算法也具有檢測器,但其檢測器是一種窮盡式的檢測方法,而所提算法中的Kalman濾波器不僅能夠精確預測目標位置,還能確定檢測有效區域,因此在目標重現后能夠快速確定目標。圖2第二列所示為David朝前行走的場景,期間伴隨有身體的晃動以及光線的變化。MK算法很快就產生了漂移,導致跟蹤失敗,而本文算法和TLD算法跟蹤效果基本良好。雖然所提算法同樣是基于顏色特征進行跟蹤,但由于在線學習檢測器可以不斷更新目標模板,從而保證跟蹤的連續性。圖2第三列所示為車輛行駛過程中受部分遮擋的場景,TLD算法的目標框消失。此時選目標模板的顏色信息并不充分,因此基于顏色信息的KM算法會發生嚴重的漂移。所提算法可以向跟蹤器提供更新后的顏色模板以及借助Kalman濾波器的預測作用來處理遮擋的情況,因此依然能夠較好地跟隨目標。
為了定量評價跟蹤效果,選用目標重疊度以及每秒傳輸幀數(fps)來衡量[15]。目標重疊度的定義為
(6)
式中RT為跟蹤到的目標位置;RG為目標實際位置。顯然,重疊度越接近1表示跟蹤效果越好。每秒傳輸幀數,其值越大代表算法實時性越好。3種跟蹤算法有關平均成功率及每秒傳輸幀數的對比實驗結果如表1所示。其中,O為目標重疊度,F為每秒傳輸幀數。

表1 3種跟蹤算法跟蹤效果對比
可知,所提算法與TLD算法的跟蹤平均成功率相對較高,數值均在0.70以上,而MK算法的跟蹤平均成功率相對較差。另外,相比較TLD算法,由于本文算法和MK算法均采用基于顏色直方圖跟蹤目標,實時性相對較好。雖然本算法中存在檢測模塊和學習模塊,但處理速度并不遜于MK算法,這是因為算法采用了跟蹤失敗再檢測的流程,且在檢測過程中根據Kalman預測結果確定檢測有效區域,這將大大提高算法實時性。
4 結 論
為了解決Mean-Shift算法目前存在的問題,提出了以Mean-Shift為框架的多信息融合算法。經過實驗對比分析,所提算法具有跟蹤精度高、實時性強等特點,能夠解決在較長跟蹤時間內目標物所發生的尺度變化、光照變化、部分遮擋或者消失重現等目標物跟蹤失敗的問題。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
