基于Paragraph Vector模型的科研熱點(diǎn)發(fā)現(xiàn)方法
2018-10-24 07:46:16郭佳羅森林陳倩柔
電子設(shè)計工程 2018年20期
郭佳,羅森林,陳倩柔
(北京理工大學(xué)信息系統(tǒng)及安全對抗實驗中心,北京100081)
隨著互聯(lián)網(wǎng)信息時代的到來,信息在各個領(lǐng)域呈現(xiàn)爆炸式快速增長的態(tài)勢。在互聯(lián)網(wǎng)上幾乎可以找到任意所需的信息,尤其是互聯(lián)網(wǎng)搜索引擎的出現(xiàn),更是大幅提升了信息查找的過程;但由于信息過多,從這些海量信息中去除冗余,挖掘有價值的信息較為困難。同樣對于科學(xué)研究者而言,情況也是類似的。科學(xué)研究者不僅需要時刻把握領(lǐng)域內(nèi)研究內(nèi)容的變化趨勢,還需要具備快速了解并掌握一個新方法的能力。閱讀相關(guān)領(lǐng)域的論文是科研工作者快速掌握知識的主要途徑,然而由于每個領(lǐng)域均有大量已發(fā)表的論文。同時,新論文的發(fā)表也層出不窮。這使得科學(xué)研究者快速了解研究內(nèi)容、跟進(jìn)研究熱點(diǎn)變得困難。緩解該問題有效、可行的方法是利用熱點(diǎn)發(fā)現(xiàn)方法對一個領(lǐng)域隨時間變化的研究熱點(diǎn)做出檢測與總結(jié)。
1 相關(guān)工作
科研熱點(diǎn)發(fā)現(xiàn)是話題發(fā)現(xiàn)的一個分支。話題發(fā)現(xiàn)起源于話題檢測與跟蹤(Topic Detection and Tracking,TDT)[1]。近年來,國內(nèi)外諸多學(xué)者針對科研熱點(diǎn)話題做出了眾多研究工作。稅等[2]使用Single-Pass聚類算法進(jìn)行話題識別,并對已聚類的報道進(jìn)行周期分類,提高了聚類的準(zhǔn)確類。為了取得更好的聚類效果,路等[3]利用一個兩層的K-means和層次聚類算法,并結(jié)合LSI話題模型,檢測并抽象出文本數(shù)據(jù)中的熱點(diǎn)話題。隨著研究的深入,文獻(xiàn)[4-5]引入了模擬數(shù)學(xué)模型改進(jìn)聚類算法提高了話題發(fā)現(xiàn)效果。Oladimeji[6]利用一種融合k-means聚類和神經(jīng)網(wǎng)絡(luò)的NED檢測算法,通過k-means與神經(jīng)網(wǎng)絡(luò)的融合方法能提高事件的檢測速率。宋[7]提出一種基于SOM聚類的話題發(fā)現(xiàn)方法,結(jié)合詞向量模型抽取數(shù)據(jù)的特征和改進(jìn)的SOM進(jìn)行話題聚類。Daniel等[8]利用Labeled-LDA模型,將文本數(shù)據(jù)的話題標(biāo)簽應(yīng)用于話題建模,并結(jié)合4S分類模型對話題進(jìn)行細(xì)維度劃分。Weng等[9]針對社交數(shù)據(jù)短小的問題,將同一用標(biāo)簽的數(shù)據(jù)整合成一個長文檔,然后利用LDA進(jìn)行主題挖掘。L Qiu[10]等提出LDA+K-means的聚類方法,通過LDA主題模型補(bǔ)充語義信息提高聚類效果。Chen[11]等人提出一種基于隨機(jī)森林和圖結(jié)構(gòu)的OTD算法,提升語料語義信息的挖掘,比詞袋模型表示的話題更優(yōu)。EI-Kishky[13]利用關(guān)聯(lián)算法快速得到短語集,結(jié)合短語袋主題模型挖掘主題-短語的分布信息,生成主題短語來表述話題。方等[14]利用K-means對文本聚類,然后通過LDA模型對每個類建模,并結(jié)合詞頻、詞長和詞跨度計算每個話題詞的權(quán)重。
基于聚類的話題發(fā)現(xiàn)方法存在文本特征語義表達(dá)能力不深的缺點(diǎn)。同時,稀疏表示法在解決實際問題時經(jīng)常會遇到維數(shù)災(zāi)難,且語義信息無法表示、無法揭示詞之間的潛在聯(lián)系等問題。本文針對以上問題,引入深度學(xué)習(xí)的Paragraph Vector(PV)模型表達(dá)文本特征。采用PV向量,緩解維數(shù)災(zāi)難問題,且挖掘詞之間的關(guān)聯(lián)屬性,優(yōu)化向量語義上的準(zhǔn)確度。
2 科研熱點(diǎn)發(fā)現(xiàn)方法
2.1 算法框架
本方法首先對文本集合提取正文,獲得正文集合后進(jìn)行句子清洗,去停用詞后得到預(yù)處理結(jié)果。接著對預(yù)處理結(jié)果使用PV模型構(gòu)建向量表示,得到文本的語義表示向量。然后對語義表示向量計算相似度,進(jìn)行聚類分析得到研究主題。對主題熱度排序時加入文獻(xiàn)的引用信息,選擇前N個主題作為研究熱點(diǎn),原理如圖1所示。
2.2 引用信息提取
引用信息提取指基于文本數(shù)據(jù)的結(jié)構(gòu)化特征獲取文本的引用信息,即引用次數(shù)。例如,Radev等[15]發(fā)布了AAN(ACL Anthology Network)語料。ANN中包括論文ID、作者信息、發(fā)表年份、論文來源和論文被引用信息。ANN中記錄如下:
C08-3004==>A00-1002
說明論文編號C08-3004的論文引用了ACL中另一篇編號為A00-1002的論文。利用這些信息可統(tǒng)計論文被引次數(shù),及被引時間的變化趨勢。
2.3 Paragraph Vector分析
Paragraph vector[16]模型是一種無監(jiān)督的且不定長文本的連續(xù)分布式向量表示方法。PV模型的框架,如圖3所示。每個段落對應(yīng)一個向量,對應(yīng)段落表示矩陣D中的一行。每一個詞也對應(yīng)一個唯一的向量,對應(yīng)詞表示矩陣W中的一行。段向量和詞向量加權(quán)共同預(yù)測語境中的下一個單詞。圖3輸入Paragraph ID 的段落向量,以及單詞“the”、“cat”和“sat”的詞向量,PV模型訓(xùn)練后可預(yù)測出下一個單詞為“on”。PV模型的推斷過程及參數(shù),如式所示。

ω1,ω2,...,ωt+k表示訓(xùn)練語料中的單詞,按詞序排列。yi是單詞ωi非標(biāo)準(zhǔn)化對數(shù)概率,計算方法如式(2)所示。
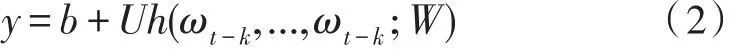
b,U是softmax函數(shù)中的參數(shù),h由段落表示矩陣D和詞表示矩陣W共同計算得出。

圖2 PV模型框架
2.4 主題檢測
本文采用余弦夾角定義兩個向量之間的距離,余弦值越大代表兩個文檔之間越相似。向量dx={x1,x2...xn}和向量dy={y1,y2...yn}分別表示文檔dx和dy,相似度計算公式如式(3)所示。

文中采用K-means聚類算法檢測主題,該算法的優(yōu)點(diǎn)是簡單實用、時間復(fù)雜度較低適合大數(shù)據(jù)聚類,且適合高維度的文本聚類。
2.5 主題熱度排序
主題熱度與兩方面因素有關(guān):1)該主題下包含的文本數(shù),數(shù)目越多說明研究者越多,該主題研究熱度也越高;2)該主題下文本的平均被引次數(shù),文本的平均被引次數(shù)越多說明文本的影響力越大,該研究主題越重要。根據(jù)主題內(nèi)文本的數(shù)量和平均被引次數(shù),主題熱度的打分策略如式(4)所示。

式中:H(Ci)為主題熱度,NCi為主題Ci的文本數(shù)量,表示主題Ci的平均被引次數(shù),參數(shù)θ用于調(diào)整主題內(nèi)文本數(shù)量與平均被引次數(shù)的權(quán)重。本文取θ=0.5。
3 科研熱點(diǎn)發(fā)現(xiàn)方法對比試驗
3.1 實驗?zāi)康暮蛿?shù)據(jù)源
為了驗證本方法通過利用PV補(bǔ)充語義信息,能夠提高話題發(fā)現(xiàn)的效果。本實驗采用ANN語料庫中ACL正刊會議集2012年收錄的168篇會議論文作為實驗數(shù)據(jù)。
3.2 評價方法
3.2.1 ARI方法
蘭特指數(shù)(Adjusted Rand Index,ARI)計算方法如下。

RI如式(6),TP表示同一類的樣本對被分到同一個簇的個數(shù);TN表示不同類的樣本對,被分到不同簇的個數(shù);FP表示不同類的樣本對,被分到同一個簇的個數(shù);FN表示同一類的樣本對,被分到不同簇的個數(shù)。
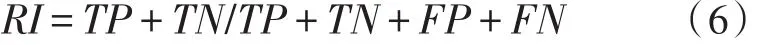
3.2.2 同質(zhì)性,完整性和V-measure
同質(zhì)性(homogeneity,h)是指,每個類簇只包含一個真實類別的樣本。完整性(completeness,c)是指,所有屬于同一個類別的樣本均被劃分到同一類簇中。同質(zhì)性和完整性的調(diào)和平均值為V-measure。已知數(shù)據(jù)集的真實聚類結(jié)果為C,實驗聚類結(jié)果為K。計算方法如下。
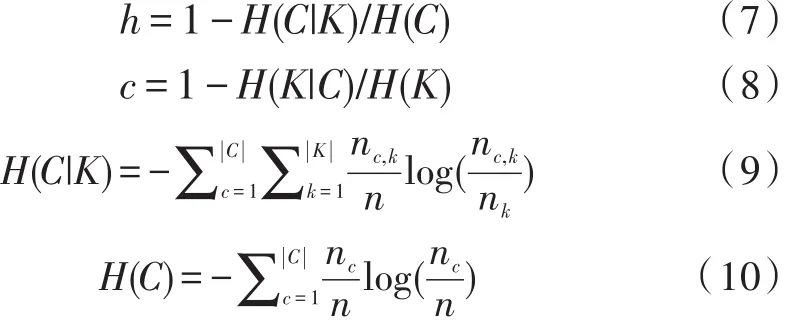
H(C|K)是已知聚類結(jié)果K,求真實類別標(biāo)記的條件熵,C)是類別的熵[17],其中,nc和nk分別表示真實類別c和聚類類別k中樣本的個數(shù),nc,k表示從類別c被分配到類別k的樣本個數(shù),H(k|C)和H(K)使用相似的定義方法。
V-measure的計算方法,如式(11)所示。

h、c和v取值范圍為[0,1],越接近1說明聚類效果越好。
3.3 實驗結(jié)果和結(jié)論
3.3.1 向量長度和窗口長度選擇實驗
L表示PV模型生成向量的維度,W表示上下文詞的個數(shù)。采用網(wǎng)格法調(diào)整參數(shù),L從25~200步進(jìn)為25調(diào)整,W從3~11步進(jìn)為2調(diào)整。實驗結(jié)果,如圖3所示。
由圖3可知,當(dāng)L=100,W=3時,聚類結(jié)果最優(yōu)。當(dāng)L不變,W增大時,實驗結(jié)果呈下降趨勢。說明詞與周圍詞的關(guān)聯(lián)度較大,W過長會引入較大的噪聲,導(dǎo)致結(jié)果下降。

圖3 參數(shù)選擇實驗
3.3.2 聚類個數(shù)選擇實驗
在向量長度為100,窗口長度為3的條件下,調(diào)整聚類個數(shù)。聚類個數(shù)K從3開始,以2為步長到81為止,結(jié)果如圖4所示。

圖4 聚類個數(shù)實驗
當(dāng)K值在[13,49]范圍內(nèi)變動時,ARI的值在0.45左右略微浮動。一方面因本實驗所用語料文本規(guī)模較小,主題劃分粒度不宜過細(xì);另一方面是因?qū)τ贏RI評價方法而言,當(dāng)聚類個數(shù)增多時[18],ARI的值有趨向于1的趨勢。因此,本文K取13。
3.3.3 對比分析實驗
本方法與2012年程輝提出的基于VSM的研究熱點(diǎn)發(fā)現(xiàn)方法以及基于LDA的話題發(fā)現(xiàn)方法進(jìn)行比較。
在聚類個數(shù)為13,聚類方法為K-means的條件下,得到實驗結(jié)果如表1所示。

表1 對比實驗結(jié)果
由表1可知,基于PV的熱點(diǎn)發(fā)現(xiàn)方法相比基于LDA及VSM的方法,無論在ARI評價標(biāo)準(zhǔn)或是HCV評價標(biāo)準(zhǔn)下,效果均有優(yōu)勢,發(fā)現(xiàn)話題更為精準(zhǔn)。原因在于:首先,本文利用PV模型優(yōu)化向量語義上的準(zhǔn)確度。VSM基于詞性詞頻構(gòu)建文檔特征,不僅無法表示語義信息且還存在維數(shù)災(zāi)難的問題。LDA引入隱藏層,構(gòu)建基于語義維度的文檔表示向量,然而由于LDA基于詞袋假設(shè)構(gòu)建模型,忽略了詞語上下文的信息,故語義表達(dá)能力仍有欠缺。PV低維空間表示法,緩解了維數(shù)災(zāi)難問題,通過挖掘詞之間的關(guān)聯(lián)屬性,優(yōu)化向量語義上的準(zhǔn)確度,從而提高了話題發(fā)現(xiàn)的準(zhǔn)確度。其次,本文將論文的被引信息作為論文語義特征的補(bǔ)充。論文的被引次數(shù)及被引趨勢,說明論文的研究價值與意義,進(jìn)一步提高了話題發(fā)現(xiàn)的準(zhǔn)確率。
4 結(jié)束語
研究熱點(diǎn)發(fā)現(xiàn)可以幫助科學(xué)研究者快速掌握當(dāng)前研究熱點(diǎn)、研究內(nèi)容的變化趨勢,這對研究工作起到了更好的參考指導(dǎo)作用。針對研究熱點(diǎn)發(fā)現(xiàn)語義特征維數(shù)過高,且無法表示語義信息的問題,本文利用深度學(xué)習(xí)的PV模型表達(dá)文本特征。PV模型的低維空間表示法,不但緩解維數(shù)災(zāi)難問題,且還能挖掘詞之間的關(guān)聯(lián)屬性,優(yōu)化向量語義上的準(zhǔn)確度。同時,本文挖掘文本的引用信息,將論文被引特征作為內(nèi)容表示的補(bǔ)充,從而提高了話題發(fā)現(xiàn)的準(zhǔn)確度,并降低了漏檢率。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
外語學(xué)刊(2011年1期)2011-01-22 03:38:33
