結(jié)合半監(jiān)督學(xué)習(xí)和LDA模型的文本分類方法
2018-10-24 03:06:28王春華
計算機工程與設(shè)計 2018年10期
韓 棟,王春華,肖 敏
(1.黃淮學(xué)院 信息工程學(xué)院,河南 駐馬店 463000;2.武漢理工大學(xué) 計算機科學(xué)與技術(shù)學(xué)院,湖北 武漢 430063)
0 引 言
為了使文本分類效率進一步提高,必須提供足夠多的已標記樣本來訓(xùn)練分類器。然而,在很多實際情況中,已標記樣本可能很少,但卻有大量的未標記樣本。為此,可以使用半監(jiān)督學(xué)習(xí)(semi-supervised learning,SSL)方法[1],通過學(xué)習(xí)將未標記樣本進行歸類,擴大初始標簽集,用作傳統(tǒng)機器學(xué)習(xí)算法的輸入。
主題模型(topic modeling)[2]是一種對文字中隱含主題進行建模的方法,由于其考慮了上下文關(guān)系,能夠顯著減少特征的數(shù)量并能夠壓縮文本表示。有研究表明,在訓(xùn)練集數(shù)據(jù)量較少時,主題模型在監(jiān)督學(xué)習(xí)環(huán)境中的性能優(yōu)于傳統(tǒng)表示方法[3,4]。其中,以隱含狄利克雷分配(latent Dirichlet allocation,LDA)[5]概率主題模型作為文本相似性度量時,比基于詞頻的TF-IDF表示方法具有更高的效率[6]。
基于上述分析,為了解決在較少初始標簽集環(huán)境下的文本分類問題,提出一種結(jié)合SSL和LDA主題模型表示法的訓(xùn)練集構(gòu)建方法(SSL-LDA)。使用LDA主題模型表示文本特征,使用一個基于SSL的自訓(xùn)練模型來學(xué)習(xí)分類未標記文本,擴展標記文本集,以此解決具有少量標記樣本集的場景。另外,為了獲得SSL-LDA模型的最優(yōu)參數(shù)組合,首先,通過方差分析(analysis of variance,ANOVA)統(tǒng)計測試方法來確定各種參數(shù)的影響能力,找出影響最小的參數(shù)并確定其值,以此降低參數(shù)維度。然后,通過一種簡化粒子群算法(simplified particle swarm optimization,SPSO)來獲得其它參數(shù)的最優(yōu)組合。最后,基于擴展的訓(xùn)練集來訓(xùn)練樸素貝葉斯(NB)分類器實現(xiàn)文本分類。
1 基于LDA主題模型的文本表示
僅僅依靠特定單詞不足以描述一個文本,也不能有效地對文本進行區(qū)別。也就是說,具有相同內(nèi)容的兩個文本可以使用包含相似含義的不同單詞來進行表述。因此,需要在一個共同的語義空間中表示文本,這種表示的最基本技術(shù)是潛在語義分析(latent semantic analysis,LSA)[7]。LSA方法中,對文本矩陣進行奇異值分解,并將其表示為低維語義空間中的潛在概念。概率潛在語義分析(PLSA)是一種改進LSA方法,這種方法提升了對主題的解釋,將其考慮為多詞分布。由于PLSA方法基于對給定文本的極大似然估計,所以容易出現(xiàn)過擬合現(xiàn)象。
為了解決上述問題,學(xué)者引入LDA方法。使用LDA方法,可以將文本表示為多個主題的分布,主題可以作為類似集群的更高層次的概念。這一算法基于這樣一個假設(shè):集合中的每個文本都是由幾個潛在主題創(chuàng)建的,其中每個主題都以混合的單詞呈現(xiàn)[8]。文本的主題表示過程描述如下:
(1)對于每個文本m∈M,主題分布θm都是Dirichlet分布Dir(α)的一個抽樣;
(2)對于文本m中的每個單詞占位符n:
1)根據(jù)抽樣得到的主題分布θm隨機選擇一個主題zm,n;
2)從主題zm,n的多項式分布φk中,隨機選擇一個詞wm,n。
在LDA模型中,為了獲得文本中各種主題的分布,可采用期望最大化(expectation maximization,EM)方法、期望變分法以及Gibbs抽樣方法[9]。然而,EM方法容易陷入局部最優(yōu)。為此,本文采用了Gibbs抽樣方法。這種方法基于Markov鏈蒙特卡洛算法(MCMC),估計出文本中每個單詞的主題分布(即文本-主題分布θ)和文本集中所有單詞的主題分布(主題-單詞分布φ),并以此來計算單詞屬于某個主題的概率,從而更新該詞的主題。Gibbs抽樣方法步驟描述如下:
(1)設(shè)定訓(xùn)練文本集中文本數(shù)量為M,單詞數(shù)為I,主題數(shù)為T,Gibbs抽樣迭代次數(shù)為N。
(2)初始化主題分布,即對于每個單詞wi,i∈I,將其隨機賦給一個主題t,表示為zi=t,t=random(T)。
(3)在每次迭代中,根據(jù)下式計算單詞wi屬于主題t的后驗概率
(1)
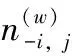
(4)通過對每個文本中主題數(shù)量的統(tǒng)計,計算θ和φ,表示如下
(2)
在Gibbs抽樣算法中,需要設(shè)定α和β參數(shù)、主題數(shù)量T以及估計θ和φ的迭代次數(shù)N。根據(jù)相關(guān)研究[10],參數(shù)α和β可以設(shè)定為固定值,即:α=50/K,β=0.01。其它參數(shù)對主題模型的性能影響較大,為此需要獲得最優(yōu)參數(shù)組合值。這將在第三章中進行詳細描述。
2 提出的SSL-LDA標記文本擴展模型
2.1 半監(jiān)督學(xué)習(xí)
半監(jiān)督學(xué)習(xí)(SSL)方法是有監(jiān)督學(xué)習(xí)方法的延伸,其將未標記樣本作為整個訓(xùn)練集的一部分,而不是僅用已標記樣本,從而獲得一個更好的分類器。首先,使用少量的已標記樣本Dl訓(xùn)練得到一個基分類器。然后,使用該分類器對未標記樣本Du進行分類。根據(jù)分類預(yù)測結(jié)果,將一些可信度最高的未標記樣本歸類到特定標簽中。重復(fù)整個過程直到達到停止條件[11]。
在文本分類中,由于SSL方法是基于標記文本和未標記文本之間的相似性度量對文本進行劃分,因此文本的表示是至關(guān)重要的。對于非結(jié)構(gòu)化內(nèi)容的表示,通常使用向量空間模型(vector space model,VSM)進行表示[12]。其中,特征是以單詞為基本單元來構(gòu)建的,特征值由不同的加權(quán)算法計算得到,例如常用的詞頻-逆文本頻率(TF-IDF)方法[13]。但是,這種方法忽略了單詞的順序及其含義。此外,這種方法得到的單詞矢量是稀疏的,具有非常高的維度。所以,為了提高SSL方法擴展訓(xùn)練集的準確性,需要一種有效的內(nèi)容表示模型。為此,本文將LDA與SSL相結(jié)合。文本的LDA表示能夠產(chǎn)生數(shù)量較少且包含語義信息的主題特征,能夠為SSL提供高效輸入特征,從而可提高其對未標記樣本進行標記的準確性。另外,由于LDA是一種無監(jiān)督學(xué)習(xí)過程,其主題與文本類別的對應(yīng)關(guān)系存在不確定性,將SSL與LDA結(jié)合,構(gòu)成半監(jiān)督LDA可以降低這種不確定性。
2.2 提出的SSL-LDA模型
為了實現(xiàn)在標記樣本數(shù)量較少情況下的樣本分類,本文構(gòu)建了一種用于擴展標記樣本集的自訓(xùn)練模型:SSL-LDA模型。SSL-LDA模型由3個部分組成:①文本LDA主題模型表示,其是系統(tǒng)的基礎(chǔ),產(chǎn)生了整個系統(tǒng)的輸入;②用于擴大初始標記樣本集的自訓(xùn)練模型,其是整個系統(tǒng)的核心,實現(xiàn)較少樣本集的擴展;③基于SPSO的參數(shù)優(yōu)化模型,其是系統(tǒng)的促進劑,能夠提高自訓(xùn)練模型的性能。
基于LDA主題模型,利用主題分布來表示樣本。使用少量已標記樣本和更多非標記樣本構(gòu)建一個初始樣本集,這些非標記樣本具有和已標記樣本相似的主題分布,作為SSL-LDA方法的輸入。
SSL-LDA中,首先對給定的任意樣本集合,使用LDA主題模型生成主題分布,并將所有樣本用這一分布進行表示。然后,根據(jù)已標記樣本來測試不同參數(shù)組合下的SSL-LDA性能,通過參數(shù)優(yōu)化模型來獲得最優(yōu)參數(shù)。接著,將初始標記樣本集合以及未標記樣本集合(規(guī)模相比標記樣本集合大得多)一并提供給最優(yōu)參數(shù)的SSL-LDA自訓(xùn)練模型。之后,執(zhí)行自訓(xùn)練過程,自訓(xùn)練模型的輸出為擴大后的標記樣本集合。最后,基于該擴大后的標記樣本集合,通過任何監(jiān)督分類方法訓(xùn)練分類器,并將該分類器對其它未標記樣本進行分類。整個過程如圖1所示。
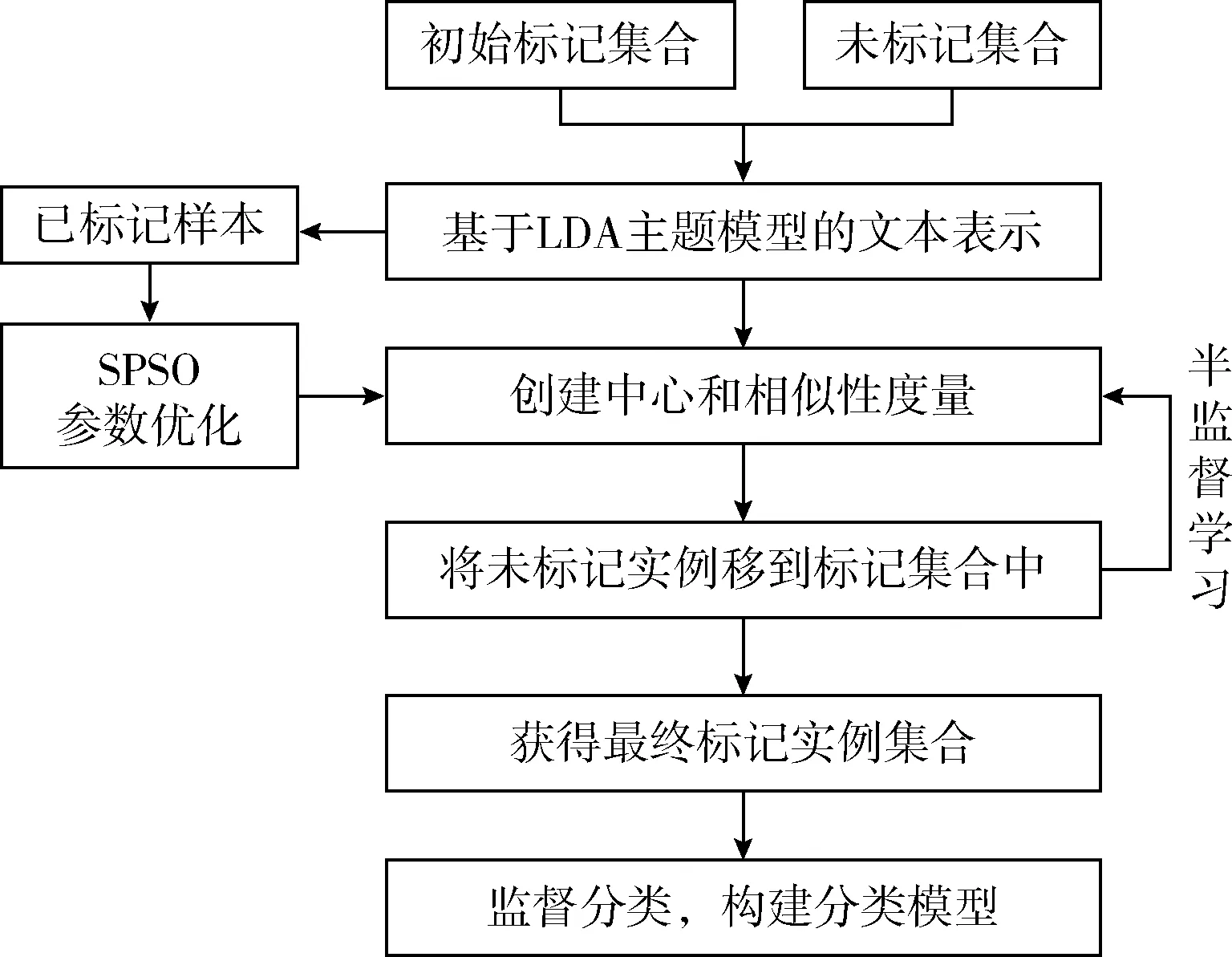
圖1 所提出的SSL-LDA方法框架
自訓(xùn)練模型由兩個階段組成,用于擴大初始標記樣本集合。第一階段的目標是獲得標記和未標記樣本基于主題的表示。將所有的樣本組合成一個集合,然后在該集合上進行主題建模。構(gòu)建LDA模型時使用了Gibbs采樣方法,使得每個樣本都可以用LDA主題分布表示。
在第二階段,未標記樣本通過迭代逐漸地被移到標記樣本集合中,直至達到預(yù)定的閾值。為了使最可靠的未標記樣本被移動到標記集合中,定義了一種語義相似性度量,這種度量基于主題分布和余弦相似性度量來計算。由于在訓(xùn)練過程中計算每個未標記樣本和標記樣本的距離是相當耗時的,因此,本文為每個類計算得到一個質(zhì)心,并基于這些質(zhì)心來測量相似性距離。每次迭代依次執(zhí)行以下兩個步驟:
(1)對于每個類別,都分別創(chuàng)建一個質(zhì)心向量,其值為給定類別中已標記樣本的平均值。然后,計算未標記樣本與質(zhì)心向量間的余弦距離,如下式所示
(3)
(2)將未標記樣本按其可靠性進行排序,可靠性根據(jù)未標記樣本與其兩個最近質(zhì)心距離的差定義。其值越大,表示樣本更加接近其中一個質(zhì)心。然后,將最可靠的未標記樣本移動到標記集合中,并基于距離度量將這一樣本標記為最近質(zhì)心所代表的類別。在選擇未標記樣本時,還考慮了類的平衡/不平衡性質(zhì),使得在可能的情況下,標記集合服從均勻分布。為此,首先計算所有類的不平衡率。然后將平衡參數(shù)值(R)減去每個類別的不平衡率(r),以便可以使得R-r個樣本能夠移動到特定的類中。
對于所以未標記樣本,當其對于兩個最近質(zhì)心的距離之間的差都小于預(yù)定義的相似性閾值(ST)時,迭代過程結(jié)束,得到最終的標記集合。通過使用平衡參數(shù),在一次迭代中移動的樣本數(shù)量也被確定下來。該過程的如算法1所示。
算法1:提出的SSL-LDA自訓(xùn)練模型
輸入:
Dl:標記樣本;
Du:未標記樣本;
D=Du∪Dl;Du?Dl;//對于D中的每個分類,都至少具有一個樣本在Dl中(即D中至少有1個標記樣本)
ST:相似度閾值;
R:平衡參數(shù);
T:主題數(shù);
GI:Gibbs迭代次數(shù);
輸出:
初始化:
基于參數(shù)T和GI,將D中所有樣本以主題分布的方式表示。
自訓(xùn)練過程:
Whileε>STdo
(1) 為標記樣本Dl的每個類創(chuàng)建質(zhì)心C=c1,…,cm,每類都具有一個類標簽lci;
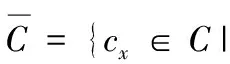
(4) 定義ε的值:ε=max{dif1,dif2,…,difn};
(5)If(ε>ST)
1)計算每類中Dl樣本所占比率r,為每類選擇R-r個difk最大的未標記樣本Du放入各類中;
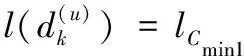
Endif
Endwhile
3 SSL-LDA中的最優(yōu)參數(shù)選擇
3.1 ANOVA參數(shù)重要性分析
在提出的SSL-LDA模型中,涉及4個參數(shù),即相似度閾值ST;平衡參數(shù)R;主題數(shù)T和Gibbs迭代次數(shù)GI。為了使SSL-LDA模型具有最好的性能,需要設(shè)定合適的參數(shù)組合。參數(shù)組合可以使用傳統(tǒng)網(wǎng)格搜索方法來獲得。在這種情況下,對于每種可能的參數(shù)組合,都分別進行評估。然而,如果在不同樣本集下,對每種參數(shù)組合都進行實驗驗證,則需要消耗大量的資源,這是不切合實際的。因此,本文首先采用了Castillo等[14]提出的方差分析(analysis of variance,ANOVA)統(tǒng)計測試方法,來確定各參數(shù)對分類方法性能的影響,以此來減少參數(shù)組合中參數(shù)數(shù)量。
ANOVA是數(shù)據(jù)分析中常用的一種統(tǒng)計方法,其從結(jié)果變量的方差入手,研究諸多控制變量中哪些變量對結(jié)果變量有顯著影響。ANOVA依靠F-分布為機率分布的依據(jù),基于平方和(sum of square)與自由度(degree of freedom)計算的組間與組內(nèi)均方值(mean of square),并以此來估計F值。
在這一部分,所有的實驗都是在預(yù)定義的訓(xùn)練集上進行的,其中所有樣本都已被分配標簽。為了測試SSL-LDA模型擴展樣本標簽的準確性,去除了已標記樣本集中80%的樣本標簽,使其成為未標記樣本。通過這種方式,在訓(xùn)練集上以每種可能參數(shù)組合的SSL-LDA模型來擴展樣本標簽,根據(jù)擴展準確性來驗證參數(shù)組合的效果。
參數(shù)值的范圍根據(jù)經(jīng)驗進行設(shè)定。對于相似性閾值ST,設(shè)定范圍為[0.1,0.9],增量為0.1。對于平衡參數(shù)R,設(shè)定范圍為[20,200],增量為10。對于主題數(shù)量T,設(shè)定范圍為[20,200],增量為10;對于Gibbs采樣迭代的次數(shù)GI,設(shè)定為500、750、1000、1250和1500。
通過這種方式,本文測試了16 245種不同的參數(shù)組合,用來確定哪些參數(shù)對結(jié)果影響最大。其中,使用未標記樣本標簽擴展的精度作為評估指標。
使用ANOVA統(tǒng)計測試來確定參數(shù)值的變化對標簽擴展性能的影響是否顯著。對于每種參數(shù),分別統(tǒng)計了其平方和、自由度、均方值、F統(tǒng)計量以及顯著性水平,ANOVA統(tǒng)計結(jié)果見表1。
根據(jù)ANOVA統(tǒng)計分析結(jié)果,從F統(tǒng)計量來看,相似性閾值ST對標簽擴展性能是最敏感的,主題數(shù)量T和平衡參數(shù)R對性能的影響也較高。而Gibbs迭代次數(shù)GI的重要性最低,且遠遠低于其它3個參數(shù)。盡管Gibbs迭代次數(shù)的增加可以提升主題模型的質(zhì)量和穩(wěn)定性,但它并不能顯著的影響性能。另一方面,GI參數(shù)對時間復(fù)雜度有著較大影響。因此,將GI參數(shù)值設(shè)定為可接受范圍內(nèi)的最小值是合理的。另外,在其它不同訓(xùn)練集上的ANOVA分析結(jié)果也表明,GI的影響很小。
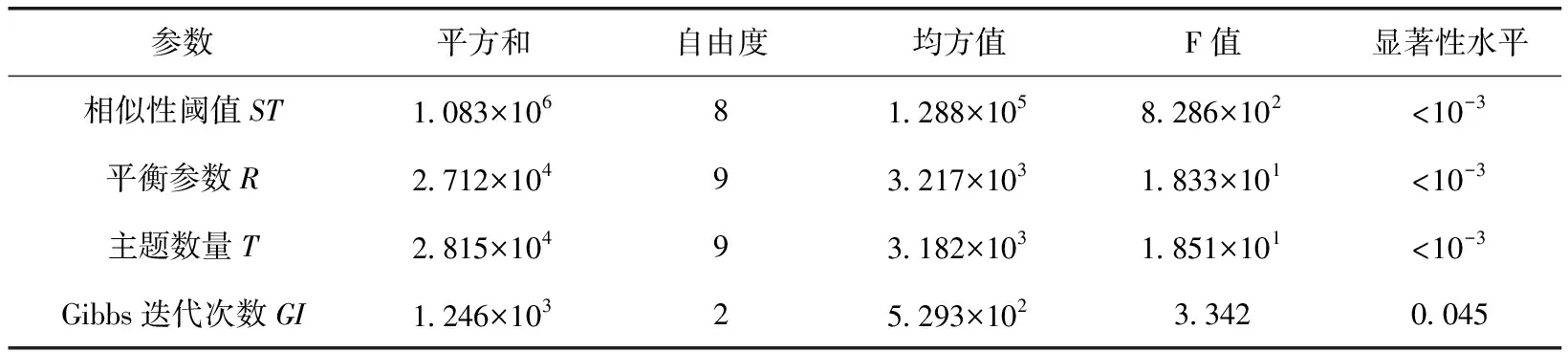
表1 不同參數(shù)對標簽擴展準確性影響的ANOVA
為此,本文將Gibbs迭代次數(shù)GI固定為500。這樣需要確定的4個參數(shù)就減少為3個參數(shù),參數(shù)組合空間縮小為原來的1/5,為3249種。這有助于提高空間搜索算法的收斂速度。
3.2 基于SPSO的參數(shù)優(yōu)化
為了進一步獲得剩余3個參數(shù)的最優(yōu)組合,本文采用了一種收斂速度較快的簡化粒子群優(yōu)化算法(SPSO)算法[15]。將粒子編碼為3個參數(shù)的值,以基于該參數(shù)組合下SSL-LDA擴大標記樣本集合的準確性作為粒子的適應(yīng)度,以此進行尋優(yōu)。
傳統(tǒng)粒子群優(yōu)化(PSO)算法中,粒子位置是根據(jù)全局最優(yōu)和當前最優(yōu)位置來動態(tài)更新,表示為
(4)
(5)
式中:i=1,2,…,N表示粒子編號,xid表示粒子i中第d維的位置值,vid為移動速度,pid和pgd分別為全局最優(yōu)和當前最優(yōu)位置。c1和c2為比例參數(shù),取值為c1=c2=2。r1()和r2()為[0,1]內(nèi)的隨機值。w為慣性權(quán)重。為了使其適應(yīng)迭代收斂過程的變化,本文采用遞減型動態(tài)慣性權(quán)重。
簡化粒子群優(yōu)化(SPSO)算法中,其認為傳統(tǒng)PSO中尋優(yōu)過程的收斂性與粒子速度無關(guān)。在一些情況下,粒子速度的更新會增加算法復(fù)雜度和優(yōu)化時間。為此,省略了傳統(tǒng)PSO位置更新中的速度項,將二階位置更新方程簡化成為一階形式,表示為
(6)
簡化后的位置更新過程加快了收斂過程,使其能夠快速的在解空間中搜索最優(yōu)參數(shù)組合。
4 實驗及分析
4.1 實驗設(shè)置
將提出的分類算法在WEKA開源機器學(xué)習(xí)環(huán)境上,使用JAVA語言編程實現(xiàn)。為了建立LDA主題模型,還使用了MALLET工具箱。
本文使用了3個公共數(shù)據(jù)集進行了實驗:Newsgroups、Reuters-10和Ohscal數(shù)據(jù)集。Newsgroups數(shù)據(jù)集由大約20 000個樣本組成,分為20個類別的新聞樣本。這些樣本都是從UseNet上收集的。Reuters-10數(shù)據(jù)集來源于基本的Reuters-21578數(shù)據(jù)集,其由Reuters-21578 中樣本數(shù)量最多的10個類的樣本組成。Ohscal數(shù)據(jù)集是一個包含醫(yī)學(xué)期刊中文獻標題和摘要的數(shù)據(jù)集。其包含了9121個樣本,分為10個不同的醫(yī)學(xué)領(lǐng)域類別。
對于每個數(shù)據(jù)集,都進行了一些簡單的預(yù)處理,包括將所有字母都轉(zhuǎn)換為小寫,刪除了停用詞以及長度少于3個字符的單詞,并將其余單詞都使用Porter Stemmer算法進行修剪。各個數(shù)據(jù)集的樣本數(shù)量、類別數(shù)量以及預(yù)處理后的單詞數(shù)量見表2。
基于上述數(shù)據(jù)集,構(gòu)建訓(xùn)練集和測試集,其大小比例為6∶4,并盡可能使訓(xùn)練集和驗證集中各類別樣本的均勻分布。其中,訓(xùn)練集中已標記的樣本比例為20%,其它樣本都為未標記樣本。測試集中都為未標記樣本。
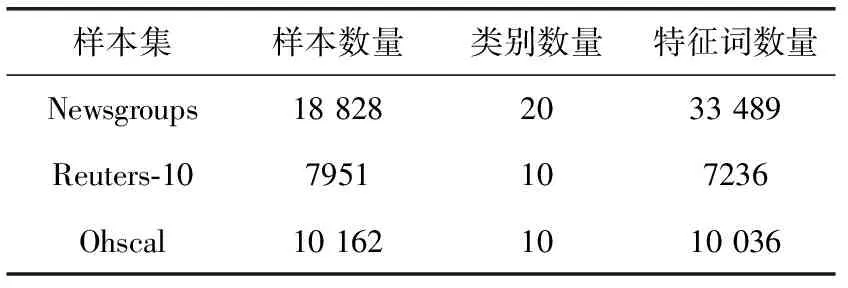
表2 實驗數(shù)據(jù)集的基本屬性
4.2 性能度量
(1)準確性(accuracy)
準確性由查準率(precision)和召回率(recall)這兩個度量計算得到,用來表示算法的整體正確分類性能。表示如下
(7)
式中,tpos為正確分類的陽性樣本,pos為陽性樣本總數(shù),tneg為正確分類的陰性樣本,neg為陰性樣本總數(shù)。準確性表示為
(8)
(2)AUC面積
感受性曲線(ROC)是以真陽性率和假陽性率為坐標的曲線,曲線與X坐標軸之間的面積則為AUC面積,取值為0.5到1之間,用來反映分類器的效果。其值越大說明分類效果越好。
4.3 參數(shù)優(yōu)化的性能驗證
在提出的SSL-LDA模型中,需要合理設(shè)定3個參數(shù)。為了驗證提出的參數(shù)優(yōu)化方法的有效性,將估計出的最優(yōu)參數(shù)與通過網(wǎng)格搜索方法獲得最優(yōu)參數(shù)進行比較。網(wǎng)格搜索方法是遍歷所有3249種參數(shù)組合,根據(jù)該參數(shù)組合下的分類準確率來找到最優(yōu)參數(shù),該方法非常耗時,但較為準確,所以可作為基準。在兩種方法獲得參數(shù)組合下,在3個數(shù)據(jù)集上的訓(xùn)練集上進行標簽樣本擴展實驗,其中以擴展樣本的標簽準確性作為性能指標,結(jié)果見表3。
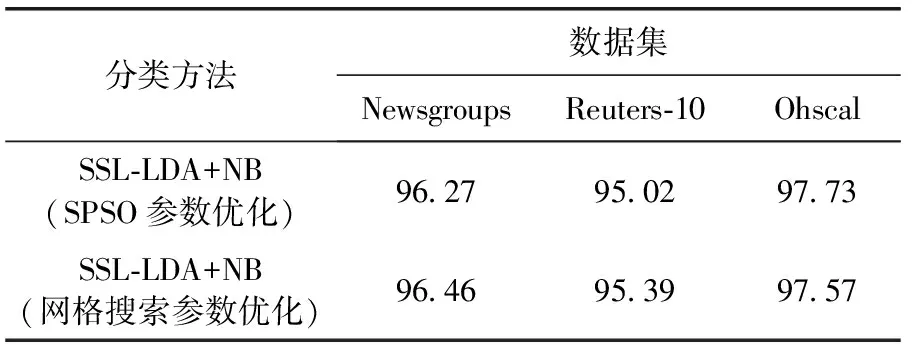
表3 基于兩種參數(shù)優(yōu)化方法的樣本標簽擴展準確性/%
可以看出,基于SPSO參數(shù)優(yōu)化獲得的擴展訓(xùn)練集與基于網(wǎng)格搜索的參數(shù)所獲得擴展訓(xùn)練集的準確性相近,這說明了提出的參數(shù)優(yōu)化算法所獲得的參數(shù)組合幾乎為最優(yōu)參數(shù)組合,驗證其有效性。另外,SPSO算法只需要迭代搜索約50次左右即可得到最優(yōu)解,而網(wǎng)格搜索需要遍歷所有3249種參數(shù)組合,這就大大降低了參數(shù)優(yōu)化過程的計算時間。
4.4 樣本分類的性能比較
本文使用SSL-LDA方法構(gòu)建訓(xùn)練集,之后使用樸素貝葉斯(NB)分類器進行分類訓(xùn)練,構(gòu)建稱為SSL-LDA+NB的樣本分類方法。將提出的SSL-LDA訓(xùn)練集構(gòu)建方法與其它相關(guān)方法進行了比較,分別為基于TF-IDF加權(quán)文本表示的自訓(xùn)練方法(SSL-TF-IDF)、基于期望最大化(EM)的自訓(xùn)練方法。SSL-TF-IDF方法中的學(xué)習(xí)過程與提出的SSL-LDA相似,區(qū)別在于其使用了詞包和TF-IDF權(quán)重,而不是本文采用的LDA主題表示。EM方法是一種用于進行不完整數(shù)據(jù)優(yōu)化的方法,使用分類器從已標記樣本中估計參數(shù),然后將概率加權(quán)的類標簽分配給未標記樣本,迭代執(zhí)行直到收斂。與SSL-LDA算法不同,這種方法的結(jié)果完全是確定的,但其缺點是可能收斂于局部最優(yōu)點。為了公平比較,這些方法都采用NB作為分類器。另外,還和只包含NB分類器的監(jiān)督學(xué)習(xí)算法進行了比較,用來驗證本文融合半監(jiān)督學(xué)習(xí)算法的可行性。
在每個數(shù)據(jù)集上執(zhí)行10次實驗,并計算分類準確性和AUC面積的平均值,結(jié)果如表4和表5所示,其中最佳性能值由粗體突出表示。
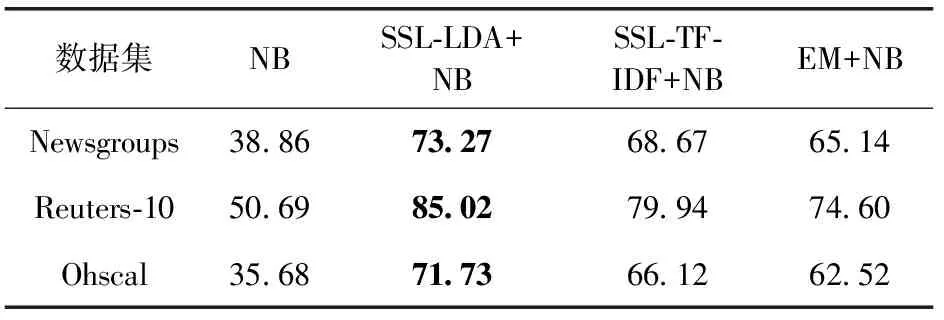
表4 各種方法在數(shù)據(jù)集上的分類準確度/%

表5 各種方法在數(shù)據(jù)集上的AUC面積
結(jié)果表明,提出的SSL-LDA+NB方法的準確性和AUC面積結(jié)果都明顯優(yōu)于其它方法。在初始標記樣本較小的情況下,傳統(tǒng)監(jiān)督學(xué)習(xí)方法(如NB分類器)則不能實現(xiàn)良好性能,準確性很低。而本文通過SSL-LDA模型擴展訓(xùn)練集后,則能夠明顯提升分類性能,這說明了SSL-LDA模型的有效性。另外,與SSL-TF-IDF訓(xùn)練集擴展方法的結(jié)果表明,LDA主題表示樣本比TF-IDF權(quán)重更為有效。
5 結(jié)束語
在標簽集較小情況下的文本分類中,半監(jiān)督學(xué)習(xí)方法比監(jiān)督學(xué)習(xí)方法更為合適。本文提出了一種基于主題模型的半監(jiān)督學(xué)習(xí)模型:SSL-LDA,對一些未標記樣本進行分類,以此來擴展標記樣本集。為了實現(xiàn)更好的SSL-LDA模型,通過ANOVA分析了模型中各種參數(shù)的重要性,并通過SPSO算法來獲得最優(yōu)參數(shù)組合。最后,在擴展后的訓(xùn)練集上訓(xùn)練NB分類器。在只具有20%已標記樣本的訓(xùn)練集上進行了實驗,根據(jù)與其它相關(guān)方法的分類結(jié)果比較,證明了提出方法的優(yōu)越性。
在今后的工作中,將研究其它主題模型來表示文本,并結(jié)合半監(jiān)督學(xué)習(xí),對未標記樣本做出更準確的標記,得到一個更加完美的標記樣本集。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
