基于運動特征與序列袋的人體動作識別
2018-10-24 03:06:10馮小明馮乃光汪云云
計算機工程與設計 2018年10期
馮小明,馮乃光,汪云云
(1.南京郵電大學 工程訓練中心, 江蘇 南京 210003;2.四川廣播電視大學 工程技術學院, 四川 成都 610073)
0 引 言
對于復雜行為動作的識別具有一定的挑戰性,主要是由于:①復雜動作由較多的子動作組成,具有短期和長期的因果關系,各序列因果關系會增加模型的復雜度,通常需要足夠大的訓練數據;②視角差異與動作類型等因素,動作的變化種類千姿百態[1-4]。
目前,人體動作識別成為當前的一個熱點,取得了一定的成果。尹建芹等[5]設計了基于關鍵點序列的動作識別方案。基于身體關節點變化的節奏,將動作標簽為上肢運動與軀體運動。為了獲得關鍵點,通過C均值聚類提取上肢、中心關節點。并將關鍵點投射到對應的動作路線中,從而得到了初步分類運動的關鍵序列。為了精確識別,通過時序直方圖對關鍵序列構建分類學習函數,將關鍵序列分類學習,完成動作識別。但其忽略了局部特征與運動的光流特征,對相似特征與復雜動作的識別效果不理想。劉長征等[6]設計了復雜背景下定位的動作識別方案。該方法對3D動作采樣,完成對每個姿勢定位從而實現動作識別。此算法能夠較好地完成動作的識別,但在噪聲場景下,隨時間累積,顯著降低了識別性能。Bohick等[7]設計了一種時間模板的動作識別方案,通過對視頻序列中的臨近幀圖像執行差分運算,獲得運動能量圖MEI與運動歷史圖MHI,并通過MEI與MHI共同來描述動作。該方法在簡單運動中獲得了一定的識別效果,但在較復雜場景與攝像頭移動中,動作輪廓很難有效提取,對于存在行為遮擋時,對動作識別的精確度大幅降低。
將視頻分割成固定的時空網格是編碼時間結構最流行的方法之一。這種方法通常與詞袋表示相結合,可以自動學習視覺詞匯和模型,而不需要對動作結構進行任何注釋。然而,對視頻劃分為統一的單元不足以模擬復雜的動作。因此,本文提出了一種序列袋(BOS)模型,能夠考慮復雜的行為有效的類內變化。為了構造BOS模型,首先將視頻表示為原始動作序列。通過將視頻轉換成PA序列,BOS模型可以保持PA的時間順序。然后,使用序列模式挖掘來自動學習動作結構。此時,將挖掘的序列模式稱為序列集。本文的貢獻主要有:①通過動作的序列集描述,BOS模型可以有效地表示了復雜動作的時序結構;②將視頻描述為PA序列,可以使用SPM自動學習動作的時間結構,而不需要任何注釋或行動結構的先驗知識。
1 人體運動特征
對于動作識別技術中,動作特征的提取與表示至關重要。在本文中,為了準確全面的表示動作特征,采用兩個步驟來完成。首先,將一個視頻表示為基礎運動(PA)序列,形成了動作的特征序列。其次,將特征序列變換為PA索引序列。
1.1 特征序列
設訓練視頻集{(Vn,yn)|n=1,2,…,N},其中,Vn為一個視頻,yn∈[1,2,…,C]為動作類別標簽。提取改進的密集軌跡(improved dense trajectory,IDT),并將每個視頻分成25個幀段,每個幀分別與前一段、下一段有五幀重疊。對每一幀段,分別計算每個軌跡的運動邊界直返圖(motion boundary histograms,MBH)、方向梯度直方圖(HOG)、光流直方圖(histograms of oriented optical flow,HOF)描述符并被編碼為Fisher向量[8]。然后,視頻Vn表示為特征序列Xn,定義如下
(1)
1.2 PA仿射傳播
PA是短動作模式,設一個PA集表示為ι={pi|i=1,…,Np},Np為PA集的數量。第i個PA稱為Pi,定義為
Pi={fi,Mi,τi}
(2)
式中:fi為第i個PA的特征;Mi為PA檢測器;τi為檢測閾值。
為了計算fi,首先對所有的訓練特征序列{X1,…,XN}進行仿射傳播,以獲得具有代表性的幀段并聚類所有幀段的索引[9],仿射矩陣A表示為
(3)
然后,對每個簇i,訓練一個PA探測器Mi。通過引入SVM與核函數定義式(3),則簇內的片段為正樣本,其余為陰性樣本。利用libsvm庫學習PA探測器[10],對于每個PA探測器Mi,通過設置檢測閾值τi來建立訓練數據序列,從而避免了含噪聲序列模式的被挖掘。
PA可以通過無監督進行學習,在訓練階段,PA信息是無需注釋的。此外,具有相似部分的運動可以共享相同的PA(例如跳高和跳遠的跑動部分)。
1.3 序列索引
設一個特征序列為Xn,PA集為ι,將Xn轉換為PA索引序列表示為
(4)
1.4 序列集學習
一個序列集表示了一個動作的局部結構,定義為R={Rj|j=1,…,NR},通過SPM從索引的訓練序列[I1,I2,…,IN]中挖掘出R,第j個序列Rj定義如下
Rj={cj,sj,xj,wj}
(5)
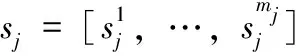
為計算sj,首先收集培訓數據索引Gc={n|yn=c},c∈[1,2,…,C]為表示特定運動類別c的標簽。然后使用PrefixSpan算法[11]從收集到的訓練索引序列{IGc(1),…,IGc(Nc)}計算序列模式,Nc為被標記為動作類別c的視頻數量。算法中唯一的參數是支持率閾值η,sj的支持率vj可表示如下
(6)
式中:fj為在{IGc(1),…,IGc(Nc)}中出現sj的數量。當vj≥η時,PrefixSpan算法的輸出是一個序列模式sj的集合。由于通過PrefixSpan算法所采集的子序列之間存在著相同的模式。因此需要對其進行后處理,將這些模式合并。除去其長度超過3的過度擬合模式。所以,序列集xj的特征可定義如下
(7)
式中:xj為在sj中對應索引的PA特征的序列。由于相同的序列模式可以從兩個動作類中挖掘得到,所以設定一個權重wj
(8)
對于模式sj,wj表示sj的相對支持率。如果同樣的模式發生在兩個以上的動作類型,那么兩序列集權重減少。反之,如果一個模式值出現在一個類型中,權重將達到最大值1。
每個序列集表示一個特定的動作類型,其包含了中層時間結構,對特定的動作類型具有重要作用。然而,相對于語法模型,序列集通過自動學習,無任何注釋或先驗知識的動作結構。圖1為序列集學習顯示。圖1中數字為每個圖像代表的PA索引,括號中的值表示每個序列集的權重。

圖1 序列集學習
2 本文復雜動作識別算法設計
為了構造一個BOS模型,將視頻表示為一個基本動作(PA)序列,形成一個序列集,從而保持其時間順序。一個序列集是一個內容豐富的子序列,描述了動作的局部結構并保留了PA的時間關系。因此,BOS模型既有內容也有時序屬性,對于類別多樣性與視角變化,其可有效地模擬復雜的行動。設測試視頻VT,序列集R,一個動作c的評分函數可表示為
(9)
式中:αj,c,βj,c,γj,c為在動作類別c中第j個序列集的參數。IT為序列索引,XT為VT的特征序列,φa(IT,sj)、φf(XT,xj)、φr(wj)分別為序列比對特征、表觀匹配特征、序列集特征。詳細介紹如下所述。
2.1 序列比對特征
φa(IT,sj)的作用是測量測試視頻和序列集之間的結構相似性,設初始值F(n,0)=0,n∈[0,L];F(0,m)=-m,m∈[0,mj],L為在IT中幀段的數量。因此,聯配分數矩陣F定義如下
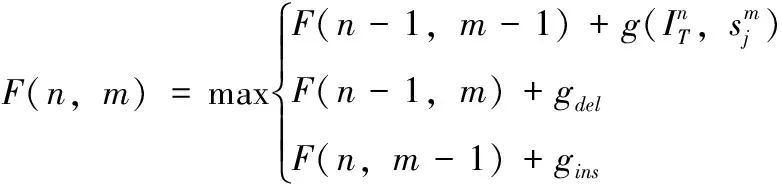
(10)
(11)
對于IT與sj的序列對比特征,當sj與測試序列相匹配時,φa(IT,sj)具有最大比對得分
(12)
2.2 表觀匹配特征
φf(XT,xj)的目的是衡量測試視頻與序列集間的視覺相似度,其表示如下
(13)
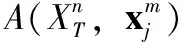
2.3 序列集特征
φr(wj)表示在特定動作類序列集的重要性,其定義為
(14)
當測試視頻與序列集之間的結構相似性大于0時,選取其得到的值作為序列集的重要性。
2.4 BOS模型學習
根據上面的描述,式(9)可定義為
Sc(VT,ζ)=wc.ψ(VT,ζ)
(15)
式中:wc為αj,c、βj,c、γj,c的串聯;ψ(VT,ζ)為φa、φf、φr的串聯。對此,引入SVM對不平衡數據執行參數wc,c∈[1,…,C]測量,因此,優化問題變成
(16)
式中:C+、C-分別為正、負類別的正則化參數,學習之前,φa,φf為正則化為零均值和單位標準偏差。隨著φa的變化,φf具有很大不同。通過對φf乘以常數λ來確保特征具有相似的范圍。
2.5 分類學習
為了準確快速完成多動作的理解與識別,引入了一種有效的線性判別分析(LDA)[12]。LDA作為分類的思想是:希望獲得的類間耦合度低,類內的耦合度高。意思就是要求類內散布矩陣Sw越低越佳;同時類間散布矩陣Sb越高越佳,這樣才能達到最優的分類性能。對此,引入Fisher函數J
(17)
式中:φ為一個n維列向量。Fisher通過選取使J(φ)最大的φ為投影方向,投影后獲得了最大Sb和最小Sw。根據Fisher的優化優計算,選擇一組最佳判別矢量來建立投影矩陣W,表示為
(18)
在LDA學習中,利用PCA降維運算,消除冗余信息。
本文算法的過程如圖2所示。將視頻表示為多個PA序列,編碼形成了PA的特征序列。然后通過仿射傳播,將特征序列變換為PA索引序列。且將PA索引序列通過SPM形成不同的BOS,一個BOS描述了動作的局部結構并保留了PA的時間關系。在BOS模型中,一個動作可通過一個序列集來表示,無需對動作結構進行任何注釋或先驗知識,可以實現序列集自動學習。通過對BOS模型進行學習,計算其序列比對特征、外觀匹配特征、序列集特征。最后,引入LDA學習,完成識別任務。
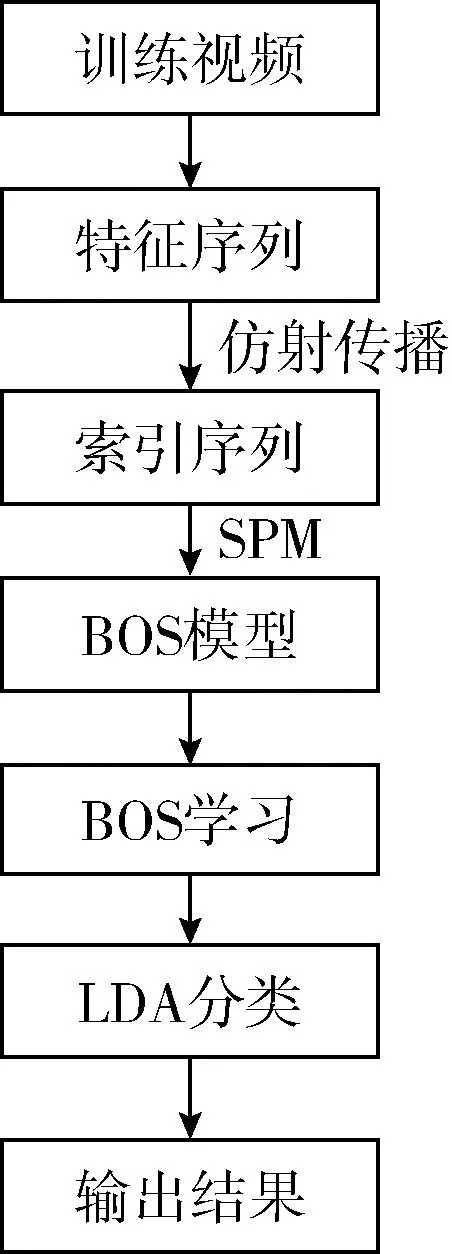
圖2 本文算法框架
3 實驗仿真與分析
3.1 實驗準備與參數設置
為了評估算法的性能,選取2個常用數據集進行測驗:MSR3D與UCF-Sport。測試環境為:Core I3,3.50 GHz CPU,4 GB運行RAM,Win7操作系統PC。開發工具:QT Creator+OpenCV。為了顯示本文方案的優越性,通過將當前流行的動作識別方法進行對比,分別為:文獻[5]算法、文獻[6]算法和文獻[7]算法,為便于書寫,簡寫為A、B、C算法。為了獲得最優的性能,通過多實驗得到了參數值:σ=-1,Np=360,支持率閾值η=0.005,NR=1,λ=17.5,C+、C-分別為0.005、0.005/Nc,ρ=80。
3.2 數據集
MSR 3D是通過深度照相機獲取的深度序列的動作樣本[13]。MSR 3D通過10個演員表演20種不同動作。每種動作通過每個演員表演2到3次,共557幅序列組成。為便于測試,將20種動作分成3個子集,如表1所示。在每個子集中,50%數據用于訓練,50%用于測試。
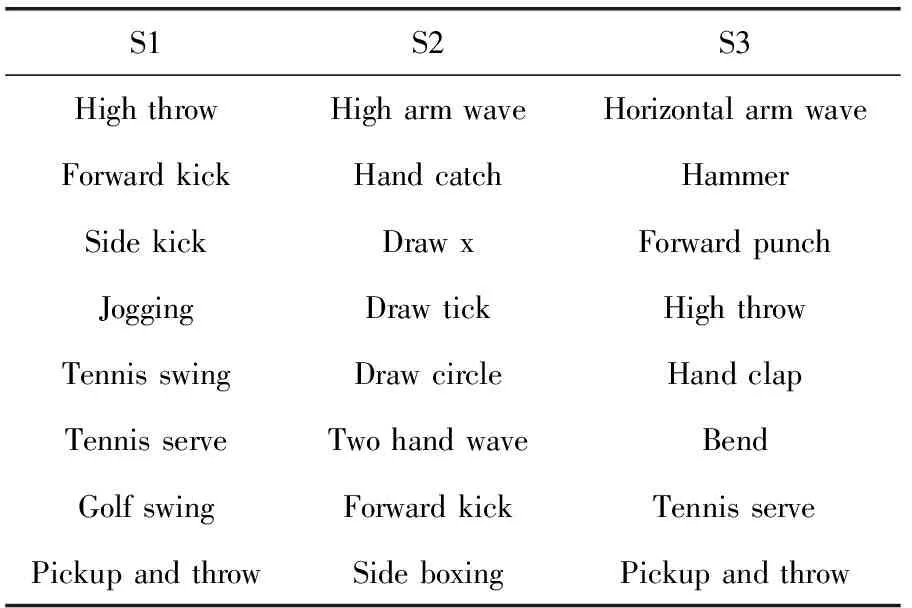
表1 MSR3D數據集分類
UCF Sport數據庫主要從BBC/ESPN的收集的各種運動數據和YouTube中下載得到的數據組合[14]。UCF主要包含的動作類型有:basketball shooting、biking、diving、golf swinging、horse riding、soccer juggling、swinging、tennis swinging、trampoline jumping、volleyball spiking、walking with a dog。UCF含有的服飾、運動,相機移動、光照變化、背景等千奇百態,類似于現實生活。因此,對于動作識別具有一定的挑戰性。UCF Sport數據集顯示如圖3所示。
表2為本文進行測試所用到的數據集與方法。表2中包含了每種數據種的動作類型,動作種類與樣本大小,并且給出了其對應的實驗方法。
3.3 實驗結果
表3、表4與表5是在S1、S2和S3中通過提出的算法測量的混淆矩陣。從表中得出,絕大部分的動作類型能準確識別與理解,識別率高達95%以上。少部分動作識別率相對低一些,例如S1中的High arm wave易被誤判斷為Two hand wave、Forward kick。S2中的Golf swing易被誤判斷為Side kick。S3中的Tennis serve易被誤判斷為Golf swing。原因是這些動作軌跡相似較高,差異較小。
表6為在UCF Sport中利用本文算法獲得的混淆矩陣。依據表6看出,本文算法在UCF Sport中具有優異的識別率。對biking、diving、horse riding、soccer juggling、swinging、trampoline jumping、walking with a dog“golf swinging的正確率高達95%以上。golf swinging、tennis swinging、volleyball spiking等的識別率相對較低。主要是這幾種動作較復雜,變化速度快。

圖3 UCF Sport數據集

表2 實驗數據集與方法
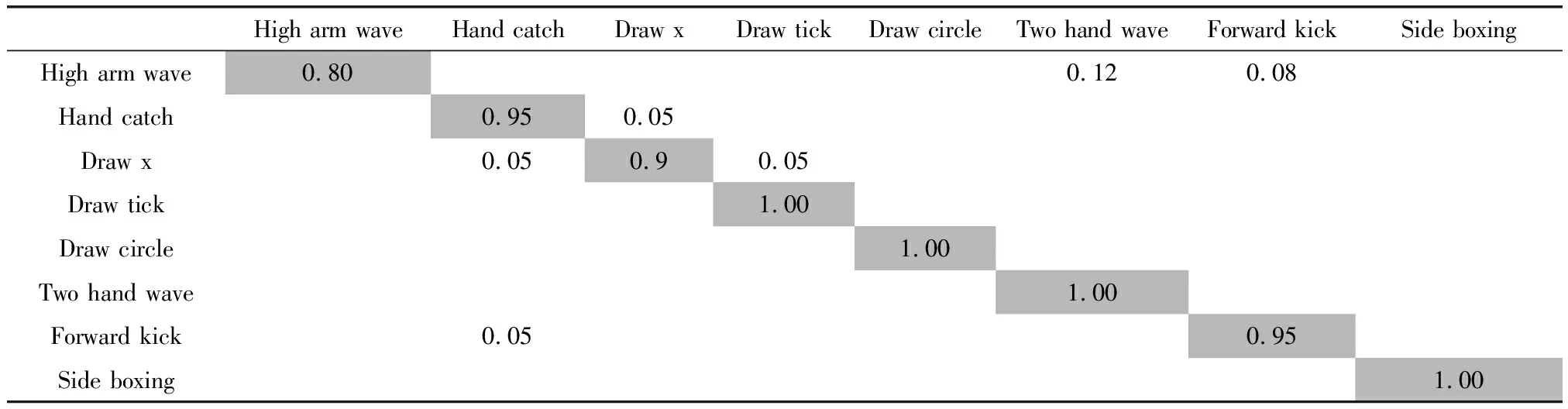
表3 S1子集的混淆矩陣
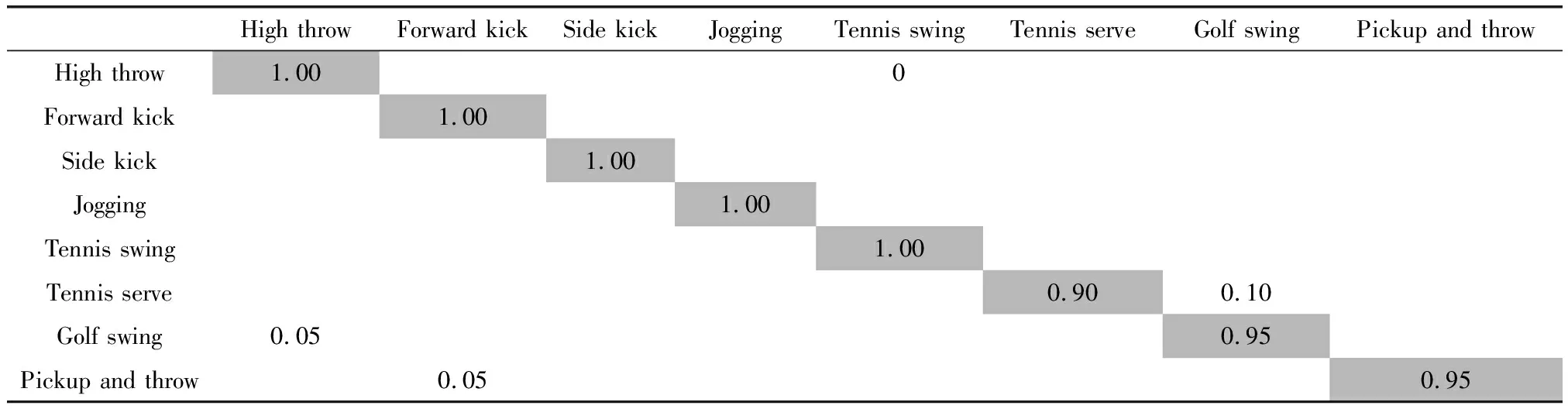
表4 S2子集的混淆矩陣
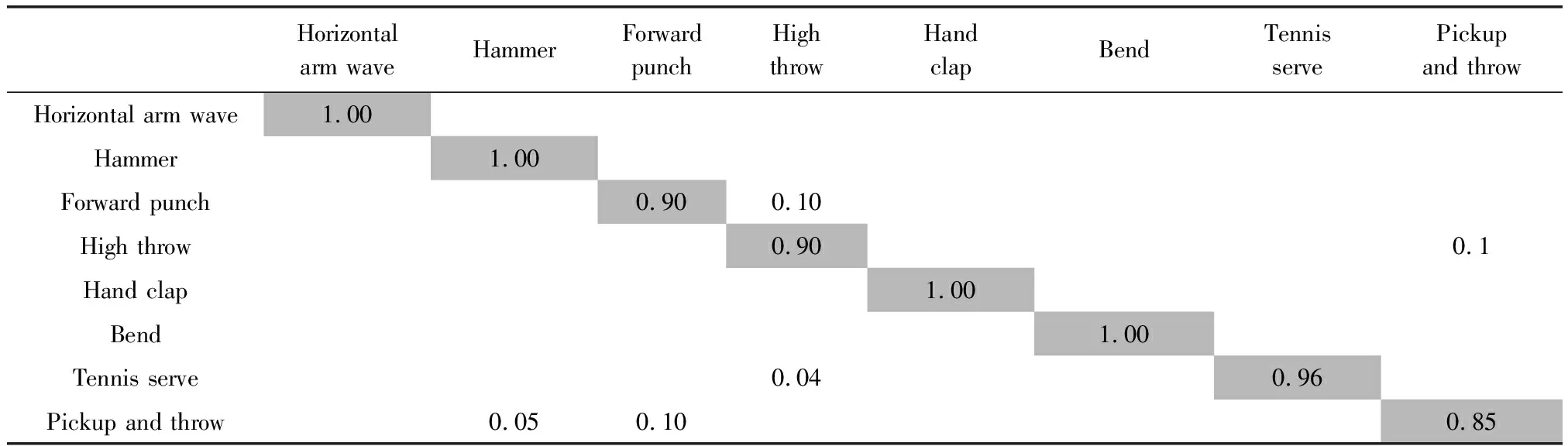
表5 S3子集的混淆矩陣
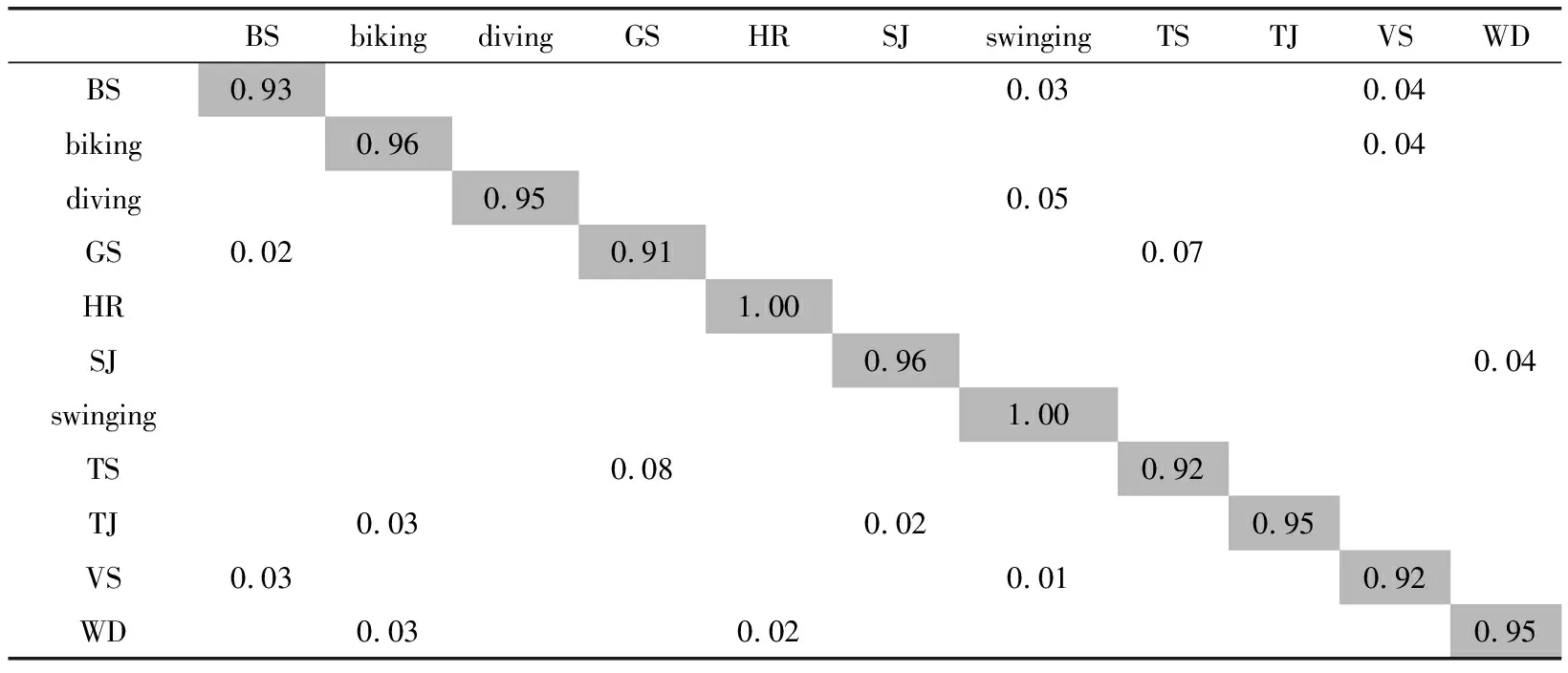
表6 UCF Sport數據集混淆矩陣
圖4顯示了在MSR 3D與UCF Sport數據集中,得到了A、B、C與本文算法分別動作的平均識別精度統計。根據圖4中看出,在表2的數據集中,本文方法取得了優異的識別率,在MSR 3D與UCF Sport中分別達95.2%、94.5%,相對A、B、C方法取得了較好的表現。對于動作較簡單的MSR 3D中,4種算法獲得了一定的識別效果。但是在動作復雜的UCF Sport中,3種對照組算法明顯處于劣勢,而本文算法同樣取得了優異的成績,說明提出的算法對復雜動作識別同樣有效。
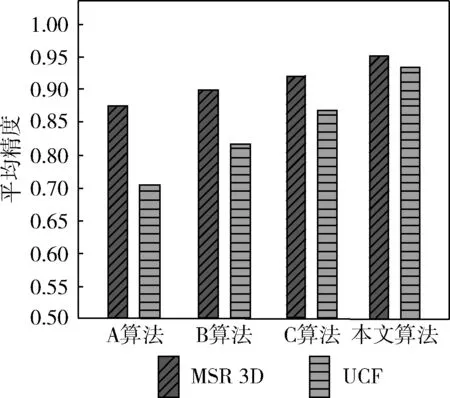
圖4 兩個數據集中平均識別精度比較
圖5顯示了在MSR 3D與UCF Sport數據集中利用A、B、C與本文算法測量的Precision-Recall曲線[15]。從圖5中看出,在4種算法中,本文方法法曲線表現最優,特別是對于復雜動作的UCF Sport中,本文方法的優勢更明顯,說明了本文算法性能相對對照組算法更優秀,能夠較好適應復雜動作的識別。
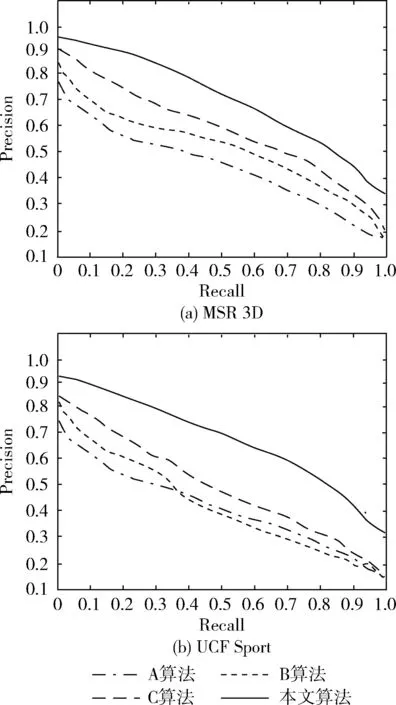
圖5 不同算法的P-R曲線
本文算法在MSR 3D與UCF Sport取得了優良的效果,對復雜人體動作識別同樣有效。主要是本文通過將視頻轉換為PA索引序列,通過SPM將得到的序列建立了BOS模型,利用構建的BOS模型能夠有效描述動作的局部結構并保留了PA的時間關系。通過對BOS模型的學習,定義了動作的評分函數,從而無需對動作結構進行任何注釋或先驗知識,實現了序列集自動學習。有效地完成了對復雜動作的特征表示。最后引入LDA,根據動作的評分值進行分類學習,完成了動作的識別。而對照組A、B、C算法中在MSR 3D取得了較好的識別效果,但是對于復雜動作UCF Sport中識別效果不佳。
4 結束語
為了提高復雜動作識別的準確度,如體育賽事中的各種動作,本文設計了基于連續運動動作的復雜人體動作識別方案。利用PA索引序列對動作特征進行描述,并通過SPM構建了BOS模型。BOS有效描述動作的局部結構并保留了PA的時間關系,考慮了復雜動作的成分和時間特性,無需任何注釋或行動結構的先驗知識,從而使得BOS模型具有可擴展性。通過對BOS模型學習,建立了復雜動作的評分值,再根據LDA分類學習,實現對復雜動作的識別與理解。在MSR 3D與UCF Sport數據集測試表明了提出算法對復雜動作識別的有效性。
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
