移動機器人在復雜環(huán)境中的在線路徑規(guī)劃
2018-10-23 01:49:42高佳佳陳超波
自動化與儀表 2018年9期
曹 凱,高佳佳,高 嵩,陳超波
(西安工業(yè)大學 電子信息工程學院,西安 710021)
目前,許多移動機器人平臺變得越來越流行,它們的應用已經從靜態(tài)實驗室場景轉移到人與機器人之間復雜交互的高度動態(tài)環(huán)境中,使得找到合適的路徑變得更加困難,同時可能需要處理周圍可移動的物體,因此移動機器人的路徑規(guī)劃顯得尤為重要。路徑規(guī)劃是在靜態(tài)和動態(tài)環(huán)境、模型約束以及不確定性的情況下,自動生成到達預定目標點的可行和最佳路徑的過程[1]。
目前,尚未有一種“通用算法”可以解決任何條件、任何配置環(huán)境下出現的問題,例如:路徑的最優(yōu)性,機器人的運動學和動力學約束,有限的或無效的環(huán)境信息,計算負荷和效率等。在此,著重分析路徑規(guī)劃問題不同的解決方法,分別研究了A*,人工勢場(APF),BRRT和PRM等4種路徑規(guī)劃算法的工作原理、存在的局限性以及相應的改進算法,然后利用設計的模擬器,在不同的場景下對4種方法分別進行在線仿真試驗。通過分析試驗結果,針對每種方法的性能表現給出了適用的場景和改進方法。
1 路徑規(guī)劃算法的分類與概述
1.1 路徑規(guī)劃算法分類
目前,路徑規(guī)劃存在很多不同的算法,可以大致分為基于圖形、基于智能仿生和基于采樣等規(guī)劃算法。
基于圖形的規(guī)劃算法是將狀態(tài)空間定義為占據網格,障礙物定義為不可訪問的網格點。如果網格分辨率足夠,搜索可用的網格點就可以保證產生解決方案,如可視圖法、人工勢場、A*以及D*等[2-6],較多用于城市環(huán)境探索、多智能體協作探索。然而,此類方法依舊存在著局限性,例如:人工勢場容易陷入局部最小;A*和D*算法在網格分辨率較小時,搜索效率低,計算時間長的問題尤其明顯。
基于智能仿生的規(guī)劃算法通過研究自然界的一些社會行為,并且根據它們的原理歸納總結運動規(guī)律,最終模仿結構、行為,達到求解問題的目的。如蟻群算法、遺傳算法、粒子群算法、神經絡等[7-10],目前大多用于機器人協調控制、電力系統優(yōu)化、網絡路由優(yōu)化問題。但是,此類方法本身的算法結構比較復雜,應用于復雜動態(tài)環(huán)境時會導致計算量激增,因而影響收斂速度,無法快速給出解決方案。
基于采樣規(guī)劃SBP算法具有簡單通用、高效和概率完備的特點,是目前最受歡迎和最具影響力的路徑規(guī)劃算法[11-12]。它可以在沒有明確的障礙物信息情況下,選擇非結構有限數量的點相互建立連接并構建出可行軌跡的路線圖,如概率路線圖(PRM),快速隨機探索樹(RRT)以及變種算法RRT*,雙向RRT(BRRT)等[13-16]。此類算法常應用于飛機機身清潔維護,高維空間環(huán)境探索,無人車輛的三維航跡規(guī)劃以及具有非完整性運動約束的環(huán)境。
1.2 算法概述
(1)A* 算法
A*算法由斯坦福研究所的 Peter Hart,Nils Nilsson和Bertram Raphael于1986年提出,它在Dijkstra算法的基礎上加入了啟發(fā)式信息,解決了盲目遍歷搜索的問題,并找到了解決從原點到目標的最小成本解決方案。啟發(fā)式信息使啟發(fā)搜索過程朝著可能“最快的”方向擴展,直至達到目標點。
A*算法流程可以概括為:
1)指定機器人的允許動作。
2)定義成本函數
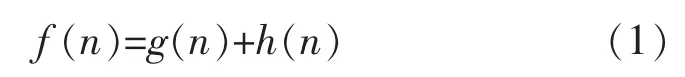
式中:g(n)為移動成本,即對應于將當前位置放入到某個鄰居位置的成本;h(n)為啟發(fā)式成本,即對應于從實際位置移動到目標位置的成本。
3)評估總成本f(n),并移至最低值的單元格。
4)重復1~3步驟,直到達到目標位置。
5)達到目標時,以最低成本計算最終路徑。
A*算法的優(yōu)點:如果解決方案存在,A*將根據其成本函數找到最優(yōu)解;該算法在概念上簡單且易于實現,且計算效率高。A*算法的缺點是,A*必須存儲整個地圖,內存要求較大,依賴于網格分辨率的大小,故在大型場景或高維操作空間中可能會出現問題。
文獻[17]將分層策略應用到A*算法中并對其進行改進;文獻[18]通過改進A*算法中的數據結構來提高效率。同時,也可將這些改進的策略結合起來以相互彌補不足,如雙向搜索與方向誘導相結合、雙向搜索與分層搜索相結合等。
(2)人工勢場 APF
人工勢場APF在1986年由Oussama Khatib提出,被廣泛應用于機器人避障和路徑規(guī)劃。APF將環(huán)境(地圖)建模為吸引或排斥機器人的場地,所有障礙物以與距離成反比的幅度排斥機器人,相反,它吸引了目標位置。勢場總和可以定義為

式中:Utot為總的勢場;Uattra為引力場;Urep為斥力場;X,Y,Xg,Yg分別為機器人的當前位置和目標位置;Di為物體對機器人的影響距離;Rd為到最近的障礙物的距離。
雖然APF方法快速有效,但也有以下缺點和局限性:①容易陷入局部最小;②緊密間隔的障礙物之間不能形成路徑;③在狹窄通道的情況下容易發(fā)生振蕩。
APF的局部最小問題已被廣泛研究,并有一些避免的方法,例如增加一個虛擬障礙來逃離局部最小值,使用模擬退火或自適應地調整障礙物勢場函數以改進排斥場模型,使得機器人從局部最小值中逃脫。
(3)快速探索隨機樹RRT
快速探索隨機樹RRT算法由Steven Lavalle于1998年開發(fā),它通過隨機探索自由空間,構建一棵從初始狀態(tài)開始尋找朝向目標狀態(tài)的可行路徑的樹。
RRT算法的探索流程如下:①在搜索空間中選取一個隨機樣本;②找到該樣本的最近鄰節(jié)點;③從鄰近節(jié)點中選擇一個朝向隨機樣本的節(jié)點進行擴展;④根據鄰近節(jié)點擴展的結果創(chuàng)建一個新節(jié)點;⑤將新的節(jié)點添加到現有樹中并將其連接到其鄰近節(jié)點;⑥當節(jié)點到達目標位置時停止循環(huán)。
RRT算法在過去的20年間陸續(xù)出現了許許多多的 變 種 , 例如 RRT*,RRT*-Smart,Bidirectional-RRT等。RRT*通過考慮最小長度成本以顯著降低路徑成本,表現出漸近最優(yōu)性;RRT*-Smart旨在提高RRT*的收斂速度,產生最佳或接近最佳的路徑,從而縮短執(zhí)行時間;RRT-connect和Bidirectional-RRT分別從起始位置和目標位置創(chuàng)建兩棵樹,當兩棵樹相遇時找到解決方案;Expand-RRT使用新的隨機采樣點和無效路徑中的節(jié)點概率性地重新規(guī)劃路徑。
RRT算法在低維、高維空間中均可進行規(guī)劃,均勻采樣可以有效地避免陷入局部最小,并且無需考慮運動目標的完整性和運動約束條件。但是隨機采樣也導致生成的路徑并不是最優(yōu),從而導致路徑成本、時間成本可能高于其他方法。
(4)概率路線圖PRM
1996 年,Kavraki和Svestka開發(fā)了概率路線圖PRM算法,該算法在配置空間中隨機抽取樣本并相互連接,然后使用基于圖搜索的算法來確定起始點和目標點之間路徑。
PRM算法主要分為2個階段:
1)采樣階段(構建離線路線圖)在工作區(qū)中繪制圖形,方法是隨機選擇不在障礙物內部的點,并使用直線連接所有頂點對,檢查所有頂點和邊緣是否無碰撞。
2)學習階段(在線規(guī)劃)由于圖形已經明確,因此可以使用基于圖搜索的算法進行路徑規(guī)劃,定義連接點之間的歐式距離作為本地成本,歐幾里德距離目標作為啟發(fā)式成本,然后從起始點到目標點搜索出一條最優(yōu)路徑。
PRM方法是概率完備的,這意味著當時間趨于無窮時,它一定會找到解決方案。該算法在沒有障礙物明確信息的情況下,也可以構建出可行軌跡的路線圖。但是,當采樣點太少或分布不合理時,可能無法找到最優(yōu)解。計算具有復雜幾何圖形的精確解或大型場景規(guī)劃時,所需時間可能呈指數倍增。
2 試驗仿真與結果分析
為了分析前述4種算法,使用MatLab 2016開發(fā)了一種在線模擬器工具,它允許更改某些設置,如地圖場景、算法類型和模擬類型。
該模擬器的GUI界面如圖1所示。使用模擬器對不同的場景分別進行4種算法的測試,以便闡明并解釋算法的主要特點。
圖1 模擬器的GUI界面Fig.1 GUI interface of simulator
2.1 場景1
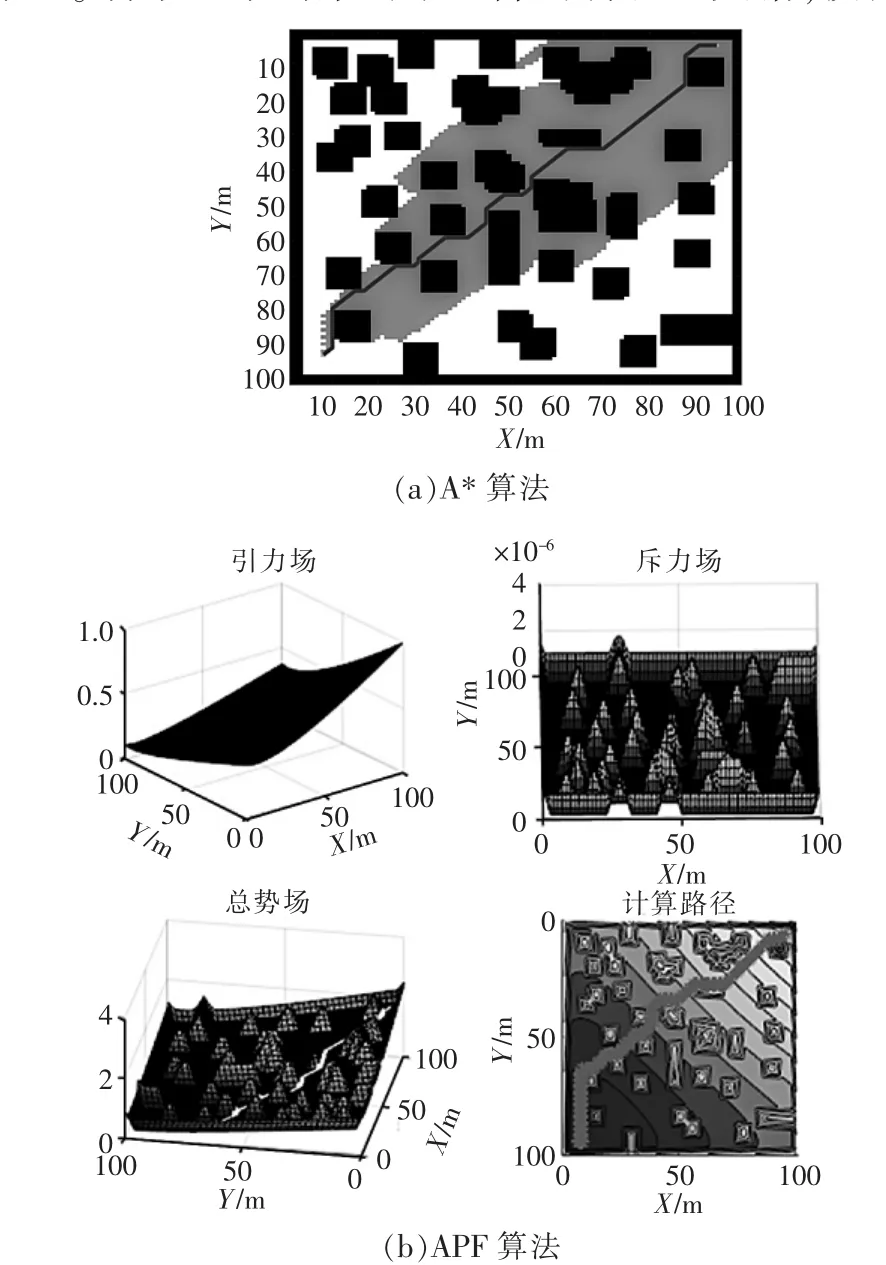
圖2 場景1的模擬規(guī)劃Fig.2 Simulation plan for scenario 1
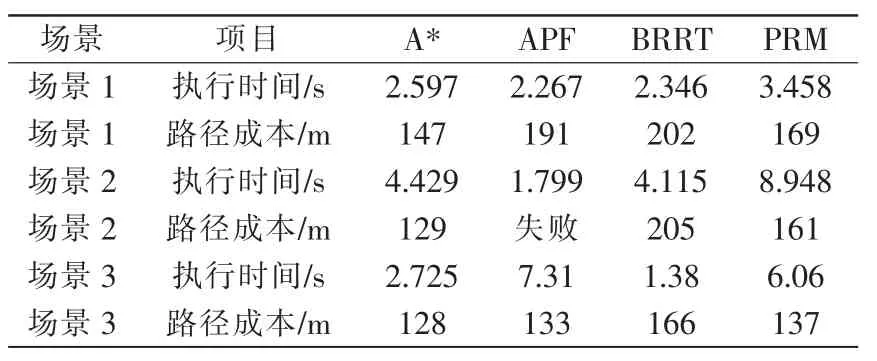
表1 仿真結果Tab.1 Simulation results
場景1的模擬規(guī)劃如圖2所示,其仿真結果見表1。場景1中密集的小型障礙物相互交錯,模擬移動機器人在行進過程中的傳感器動態(tài)交叉采集的情況。由圖可見,4種方法均可找到可行路徑,其中APF的計算時間最短,表明APF對于局部避障具有良好的性能。
2.2 場景2
場景2模擬了結構對稱的凹形障礙物,該場景模擬規(guī)劃如圖3所示,仿真結果見表1。由圖可見,A*算法給出了最佳路徑,雖然執(zhí)行時間相比于BRRT多0.276 s,但是路徑成本遠遠小于BRRT。而APF在該結構化地圖中,由于虛擬力的分布都是對稱的,因此找不到可行路徑。

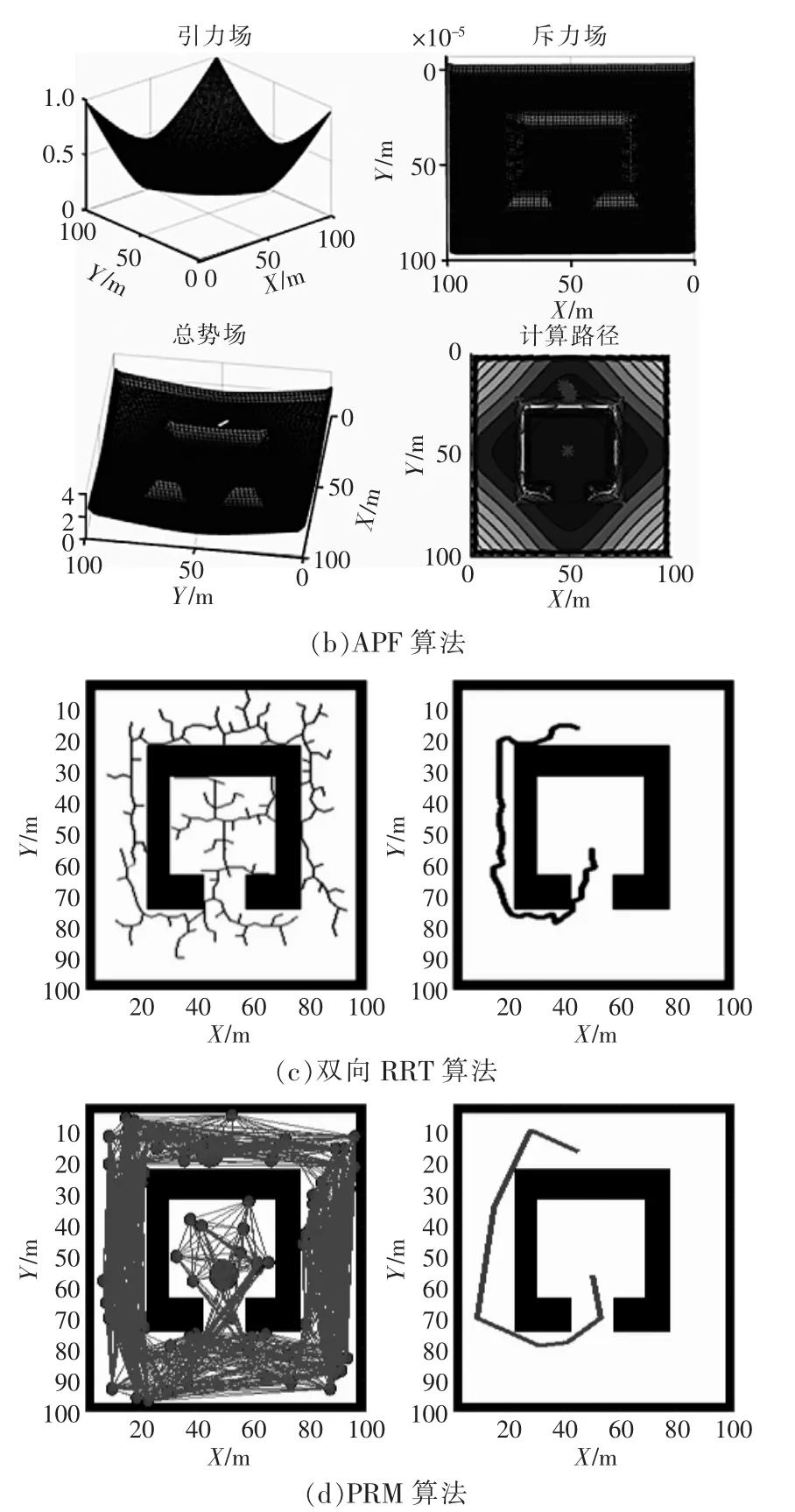
圖3 場景2的模擬規(guī)劃Fig.3 Simulation plan for scenario 2
2.3 場景3
場景3考慮了結構對稱的室內走廊環(huán)境,該場景模擬規(guī)劃如圖4所示,仿真結果見表1。由圖可見,最佳路徑由A*和PRM給出,但這2種方法的計算時間相對較長:APF雖然跳出局部最優(yōu),并找到可行路徑,但是執(zhí)行時間較長;BRRT的執(zhí)行時間最少,但路徑不平滑導致路徑成本較大。如果對BRRT算法的路徑進行優(yōu)化,可大大降低路徑成本。
在考慮算法、地圖和機器人位置之間的不同場景和組合之后,可以得出以下結論:
1)A*算法的收斂速度較慢,但可以保證最佳路徑。可以通過降低地圖分辨率來加速計算時間,但是如果分辨率太小,則A*無法保證最終路徑的可行性和最佳性。
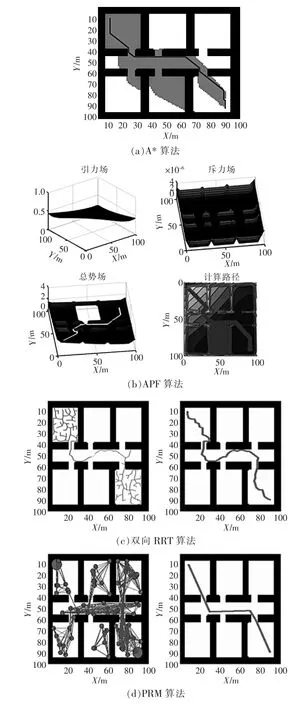
圖4 場景3的模擬規(guī)劃Fig.4 Simulation plan for scenario 3
2)APF算法通常計算時間較短,但是在充滿狹窄通道的場景下,或當某個點的引力和斥力大小相等、方向相反時,APF方法往往容易陷入局部最優(yōu)或出現震蕩。因此,在控制環(huán)中加入一種局部避障算法,可以有效地解決APF存在的問題。
3)同為概率采樣方法,PRM生成的路徑比BRRT的路徑更平滑和更短,一方面是BRRT節(jié)點擴展預定義的最大步長和盲目探索,都會影響路徑優(yōu)化。另一方面,PRM在整個空間中隨機采樣,并基于它的隨機點可以找到最短距離。當然,由于這2種算法都存在隨機性,因此也會存在BRRT比PRM更優(yōu)的情形。
3 路徑規(guī)劃算法的發(fā)展趨勢
在路徑規(guī)劃的研究中,每個規(guī)劃算法都有適用的場景,但是也存在一些不足之處,因此路徑規(guī)劃的研究重點依然是研究新的、高效的改進路徑規(guī)劃算法。此外混合路徑規(guī)劃也將成為未來路徑規(guī)劃研究發(fā)展的方向。具體表現在以下幾方面:
(1)傳統算法與隨機算法相結合。
a.利用A*的啟發(fā)式特性引導RRT進行目標偏向采樣,以減少執(zhí)行時間、擴展節(jié)點數量以及路徑成本;b.RRT的隨機性可以幫助APF跳出局部最優(yōu)解,并快速找到成本較低的路徑。
(2)遺傳算法與神經網絡相結合。
利用神經網絡控制機器人的運動規(guī)則和神經元感知器獲取未知環(huán)境的信息,再利用遺傳算法實現神經網絡的權值設置,實現未知環(huán)境下的機器人路徑規(guī)劃。
(3)蟻群算法與人工神經網絡相結合。
將蟻群算法與人工神經網絡相結合,可以減少空間復雜度,同時提高路徑規(guī)劃準確率。
(4)多機器人合作的路徑規(guī)劃。
多機器人合作進行路徑規(guī)劃已經成為新的研究熱點之一,如何劃分未知環(huán)境,如何對機器人進行分功,如何設置機器人的體系結構及機器人間的通信方式等成為新的研究問題,這些問題的解決能夠更好地減少機器人間的沖突問題,以便進行更好的路徑規(guī)劃。
4 結語
路徑規(guī)劃算法通常都有很多變種,因為它們一般不能同時滿足所有要求,這也就意味著沒有任何一種算法可以適用于任何場景,且快速、低成本的規(guī)劃出最優(yōu)路徑。全局路徑規(guī)劃和局部路徑規(guī)劃結合使用就可以保證一個相對快速而且最優(yōu)的路徑,并且在復雜的動態(tài)場景、高維環(huán)境以及非完整和運動約束環(huán)境中均是有效的。路徑算法混合使用不僅可以利用彼此的優(yōu)勢,還可以彌補自身所存在的缺點,以此提高路徑規(guī)劃的效率和魯棒性。期望本文對于從事相關問題研究的相關人員和未來的發(fā)展具有一定的參考價值。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
河南電力(2021年5期)2021-05-29 02:10:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
電影(2018年12期)2018-12-23 02:18:48
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛(wèi)生(2016年2期)2016-11-12 13:22:16
中國工程咨詢(2016年4期)2016-02-14 07:28:28
