近紅外光譜多核并行譜區選擇任務調度策略研究
2018-10-20 06:43:44劉廣昊吳習宇祝詩平
農業機械學報 2018年10期
關鍵詞:分配
黃 華 朱 潔 劉廣昊 吳習宇 祝詩平
(1.西南大學工程技術學院, 重慶 400716; 2.西南大學食品科學學院, 重慶 400716)
0 引言
近紅外光譜(Near infrared spectroscopy, NIRS)廣泛應用于稻谷、小麥和玉米等農產品的含水率無損檢測中[1-3]。在近紅外光譜定量分析模型中偏最小二乘法(Partial least squares, PLS)[4]應用最為廣泛。從原始光譜數據中選擇特征譜區用于PLS建模有利于提高預測模型的精度。常用的譜區選擇算法[5-6]有4種:分段間隔偏最小二乘法(Interval partial least squares, iPLS)[7-9]、組合分段偏最小二乘法(Synergy interval partial least squares, siPLS)[10]、反向分段偏最小二乘法(Backward interval partial least squares, biPLS)[11]、滑動窗口偏最小二乘法(Moving window partial least squares, mwPLS)[12-14]。黃華等[9]研究表明這4種特征譜區選擇算法中mwPLS和biPLS算法預測精度較高,但其程序運行的時間都較長。如果從提高單核芯片的速度來縮短譜區選擇程序運行時間,存在兩方面問題[15]:①熱量問題,會使芯片產生的熱量超過處理器所能承受的極限。②性價比問題,速度快的處理器,其價格都很高、導致單核處理器的性價比很低。因此目前主要采用多核芯片并行執行來縮短程序運行時間。
本文以近紅外光譜法定量分析稻谷含水率為例,在16核的云計算平臺下,首先分析順序分配法、等間距法和排序法等3種任務調度策略對并行iPLS算法性能的影響;然后將并行性能最好的任務調度策略應用到siPLS、biPLS和mwPLS等并行算法中,分析它們的相對加速比、并行算法的效率和負載均衡等性能指標。
1 實驗材料
1.1 光譜數據
利用Bruker MPA型近紅外光譜儀采集364份稻谷樣品光譜。工作波數范圍為3 598.71~12 493.30 cm-1,掃描次數32次,分辨率為3.85 cm-1,共2 307個波數點。隨機選取其中的210個樣品作為校正集;154個樣品作為預測集。
1.2 云平臺配置及并行性能參數
云計算服務器配置如下:處理器Intel Xeon E5-2650 v3,主頻2.30 GHz、CPU核數16核、內存16 GB,操作系統Microsoft Windows Server 2012 R2 Datacenter Version 6.3 (Build 9600),所用軟件為Matlab 8.5 (R2015a)。
為了衡量并行算法性能,通常使用相對加速比、并行算法的效率和負載平衡等性能指標[15-16]。
相對加速比為
(1)
式中t1(n)——單核運行時間
tP(n)——多核運行時間
一般情況下,t1(n)>tP(n)。
并行算法的效率為
(2)
式中p——處理器核數
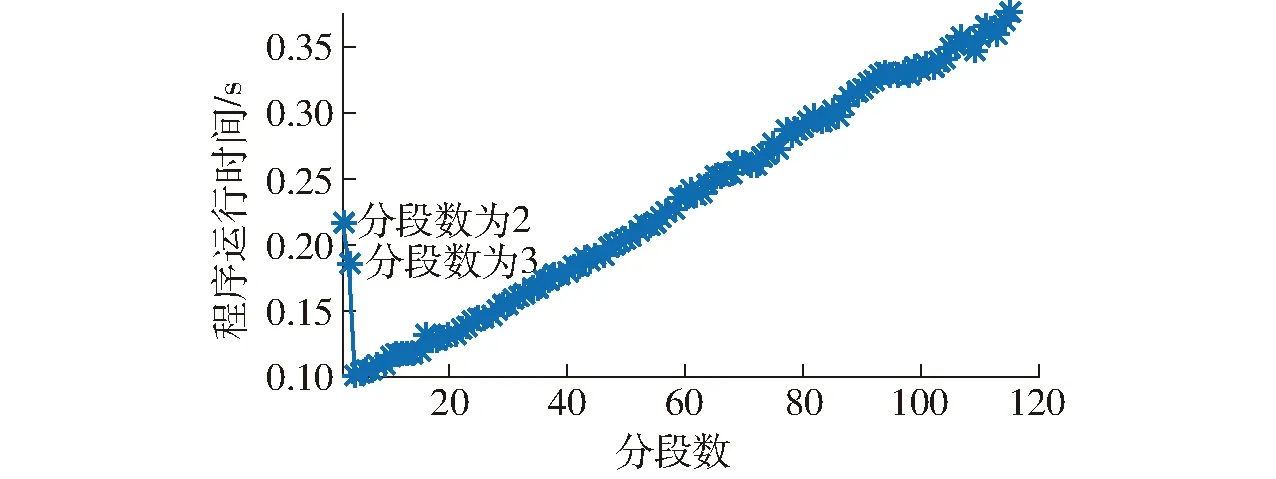
SP(n)≤p,所以有0 并行算法的負載均衡百分比為 (3) 式中Ti——第i個進程執行時間 分段間隔偏最小二乘法(iPLS)首先將原始光譜波數分成2~N段,取每一小段分別用于最小二乘法(PLS)建模,并計算其預測集的均方根誤差(Root mean square error of prediction, RMSEP),然后根據RMSEP最小的原則統計計算結果,從分段中選取具有最佳預測性能的光譜區域。iPLS算法計算復雜度參照文獻[9]。iPLS譜區選擇示意圖如圖1所示。 圖1 iPLS譜區選擇示意圖Fig.1 Diagram of iPLS wavelength selection 在云計算平臺下采用傳統的單核串行程序運行iPLS算法。程序連續運行10次,計算每種分段情況下iPLS算法的平均程序運行時間,如圖2所示。 圖2 單核串行iPLS算法程序運行時間Fig.2 Runtime of iPLS serial algorithms on signal core 由圖2可以看出,iPLS程序的運行時間與分段數和光譜數據量有關。當分段數為2和3時程序的運行時間較長,這主要是因為這兩種分段情況下用于單次PLS建模的數據量較大。如分段數為2時,將2 307個波數點分成兩段,每一段有1 153個波數點用于PLS建模。隨著分段數的增加程序運行時間呈上升趨勢,這主要是由于分段數越多程序運行PLS算法的次數越多。在單核下iPLS串行算法程序平均運行總的時間為26.80 s。 在多核處理器下實現特征譜區選擇的并行算法流程如圖3所示。 圖3 近紅外光譜譜區選擇算法并行化流程Fig.3 Flow chart for parallel wavelength selection 由于iPLS算法具有分離性,即可以根據各分段數單獨調用PLS算法,因此可以將串行的iPLS譜區選擇算法轉換成并行算法在多核計算機中運行。在圖3中,將串行的算法分配到各個處理器上并行執行,關鍵的問題是如何對各個處理器進行合理的任務分配,使各個處理器的負載平衡,減少各處理器的開銷時間和處理器間的通信時間,從而提高并行效率。 在單核串行算法中,運行iPLS程序會根據分段數調用各自的iPLS算法,即 fori=2:N分段數為2~N段 iPLS(i) 根據分段數調用iPLS算法 end 在Matlab中提供了parfor關鍵字實現將串行的for循環轉換為并行執行[17-18],for關鍵字改為parfor即可實現并行算法。 Matlab中parfor采用client和worker模式,如圖4所示。 圖4 Matlab并行計算資源池Fig.4 Matlab parallel computing resource pool 在多核處理中,其中一個核為client端,其余的多個核為worker端。在client端編寫和啟動并行代碼,Matlab的串行部分程序代碼在client端運行,在程序的執行過程中client端根據并行代碼的關鍵字parfor尋找需要并行執行的代碼,并將這部分代碼分配到各個worker端,然后各個worker端并行執行,并將計算結果返回給client端。若計算機的核數為p(即有p個worker端),循環次數為n,若n/p為整數,則循環將會被均勻分配;如果n/p不為整數,則各個worker端的任務分配將會不均勻。本文分析比較了3種任務調度策略對并行性能的影響。 (1) 順序分配法任務調度策略 順序分配法任務調度策略將按自然數的順序為各個核平均分配任務。例如在4核處理器上運行n為1~115段的iPLS程序(n=1表示用全譜建模,為了與全譜進行比較,n的最小值取為1),1~115段被順序平均分成4組:第1組為第1~28段;第2組為第29~56段;第3組為第57~84段;第4組為第85~115段。client端將這4組分段數據隨機分配給4個核處理器并行執行。 (2)等間距法任務分配調度策略 等間距法任務分配調度策略以處理器核數p為間隔值為每一個核從分段數中抽取分段數索引。例如在4核處理器上運行n為1~115的iPLS程序,以4間隔將1~115段分成4組:第1組為1、5、…、113段;第2組為2、6、…、114段,第3組為3、7、…、115段,第4組為4、8、…、112段。然后將這4組隨機分配給4核處理器并行執行。 (3)排序法分配調度策略 排序法分配策略會根據各個核任務執行的進程來分配任務,任務先完成的核將首先獲得下一次執行任務。任務分配按由重到輕的原則進行。同樣以在4核處理器上運行1~115共115段的iPLS程序為例。第1次分配首先將115乘以2/3除以核數4,即115×2/12=19.16,取整為20。空閑的前一半核首先獲得20段的計算任務。以此類推繼續給空閑的核分配任務,直到所有的任務被分配完。 在16核云計算平臺下,分別對順序分配法、等間距法、排序法等3種任務調度策略并行計算性能進行測試。在Matlab中通過parpool關鍵字設置CPU核數分別為1~16等16種情況下運行iPLS算法。這3種任務分配策略的程序運行時間、相對加速比、并行效率和負載均衡情況如圖5、6所示。 圖5 3種分配策略程序運行時間與相對加速比Fig.5 Runtime and speedup ratio for three task scheduling strategies 圖6 3種分配策略并行效率和負載均衡比較Fig.6 Parallel efficiency and load balance for three task scheduling strategies 由圖5可見,隨著并行核數的增加程序運行時間成比例減少,相對加速比呈上升趨勢。排序法分配策略的相對加速比性能最佳。由圖6可見,順序分配法負載均衡性能最差。以4核并行iPLS算法為例,由圖2可見,當N大于3以后隨著分段數的增加計算iPLS程序的運行時間增大。在4核處理器上實驗測試結果表明:在順序分配法中程序運行時間最長為9.75 s,最短時間為3.47 s,最快的核有64.50%的空閑時間用于等待最慢的核完成任務。由圖6可見,隨著并行核數的增加負載均衡性能和并行效率都呈下降趨勢。 綜上所述,在以上3種分配策略中,排序法分配策略并行性能最佳,后文將排序法分配策略應用到組合分段偏最小二乘法、滑動窗口偏最小二乘法和反向分段偏最小二乘法等3種譜區選擇并行算法中。 組合分段偏最小二乘法(siPLS)[9,12]是在分段間隔法的基礎上,從分段中取出L段組合成一個新的光譜數據集,用于PLS建模;然后根據RMSEP最小的原則確定最佳組合光譜區域。 在16核云計算平臺下采用排序法分配策略,siPLS算法的運行結果如表1所示。 表1 在1~16核下siPLS并行算法運行結果Tab.1 Result of siPLS parallel algorithm from 1 to 16 cores 從表1可見,利用2核并行運行siPLS算法時相對加速比為1.91,程序運行時間由單核的20.70 min縮短至10.84 min,節省了47.83%的程序運行時間。從2~16核的并行運行結果來看,隨著核數的增加程序運行時間進一步減小。并行效率和負載均衡性能隨著并行核數的變化有一定的波動,核數為2時并行效率最高,為95.45%,負載均衡性能也最佳,達到95.31%。11核并行時并行效率最低,為77.98%,負載均衡性能也最差,百分比為80.03%。 反向分段偏最小二乘法(biPLS)[9]首先將原始光譜的波數分成n段,然后去掉其中的任意一段,得到由n-1段光譜組合成的新光譜數據集,用于PLS建模;計算其在不同主成分數下的RMSEP,再對保存下來n-1段光譜數據重復上述進程,直到最后只剩下1段光譜為止。最后根據RMSEP最小的原則確定最佳組合光譜區域。 在16核云計算平臺下采用排序法分配策略,biPLS算法的運行結果如表2所示。 表2 在1~16核下biPLS并行算法運行結果Tab.2 Result of biPLS parallel algorithm from 1 to 16 cores 從表2可見,利用2核并行運行biPLS算法時相對加速比為1.85,程序運行時間由單核的9.22 h縮短至4.98 h,節省了45.99%的程序運行時間。從2~16核的并行運行結果來看,隨著核數的增加程序運行時間進一步減小。然而并行效率隨著并行核數的增加卻減少,2核并行時并行效率最高,為92.64%。2~16核的負載均衡性都能較好,百分比均介于85%~94%之間。 滑動窗口偏最小二乘法(mwPLS)[19-20]是以某一點為中心,按一定的窗口長度從原始光譜中取出一段連續的光譜數據集,用于最小二乘法建模;然后根據RMSEP最小的原則確定最佳光譜中心點和窗口長度,從而獲得最佳特征光譜區域。 在16核云計算平臺下采用排序法分配策略,mwPLS算法的運行結果如表3所示。 表3 在1~16核下mwPLS并行算法運行結果Tab.3 Result of mwPLS parallel algorithm from 1 to 16 cores 從表3可見,利用2核并行運行mwPLS算法時相對加速比為1.91,程序運行時間由單核的55.51 h縮短至29.03 h,節省了47.70%的程序運行時間。從2~16核的并行運行結果來看,2核并行時并行效率最高,為95.62%。負載均衡百分比均大于94%。 在近紅外光譜分析中偏最小二乘法獲得了廣泛的應用。從全部光譜中選擇最佳特征譜區可以提高PLS算法的預測精度,目前廣泛使用的譜區選擇算法有mwPLS、biPLS、siPLS、iPLS等4種。在單機單核下這4種算法程序的運行時間分別為55.51 h、9.22 h、20.70 min、26.80 s。在不改變算法精度的情況下,在云計算平臺下采用排序任務分配策略多核并行算法有較好的負載均衡性能,可以縮短程序的運行時間,提高近紅外光譜譜區選擇效率。如采用2核并行時,mwPLS和biPLS算法分別節省了47.70%和45.99%的程序運行時間。隨著核數的增加,程序運行時間會進一步減小,但并行效率不與核數成正比,從2~16核的并行運行結果來看,2核并行算法具有最高的并行效率。目前普通的計算機至少具有2核處理器,在考慮并行效率和計算成本條件下,利用2核并行計算具有經濟性和實用性。2 單核串行iPLS算法效率分析
2.1 單核串行iPLS算法計算復雜度分析
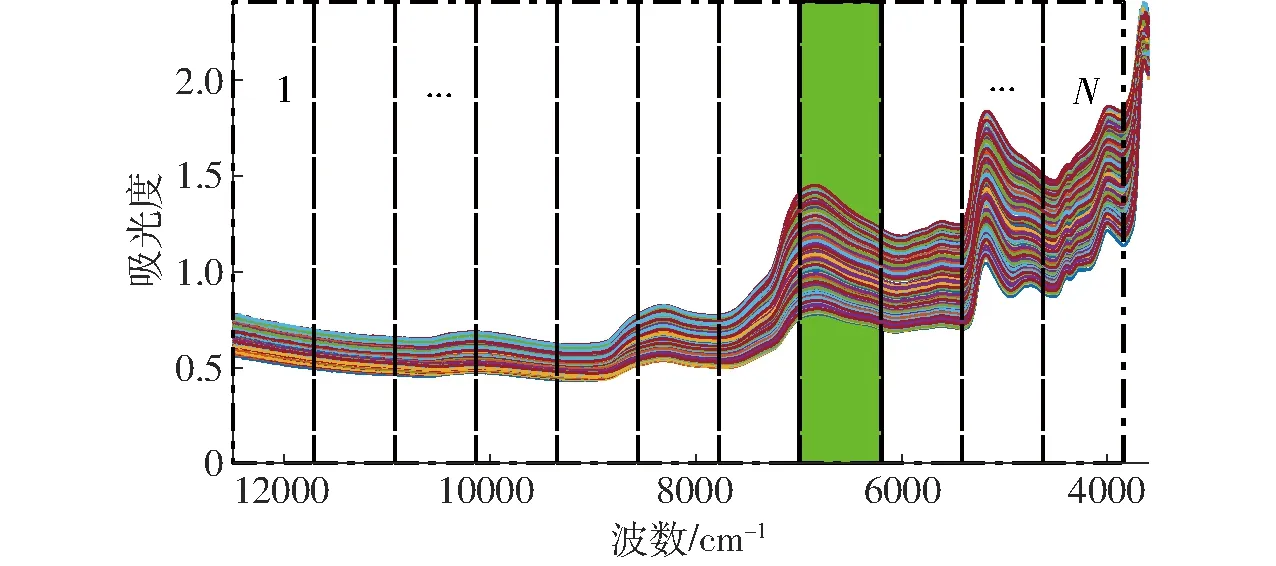
2.2 單核串行iPLS算法運行結果分析
3 云計算平臺下多核并行iPLS算法任務調度策略
3.1 基于parfor關鍵字的多核任務調度策略


3.2 多核并行iPLS算法運行結果分析


4 在云計算平臺下多核并行譜區選擇算法應用
4.1 siPLS 算法多核并行運行結果

4.2 biPLS算法多核并行運行結果

4.3 mwPLS 算法多核并行運行結果

5 結束語
猜你喜歡
天水行政學院學報(2022年4期)2022-11-18 09:02:36
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
漢語世界(The World of Chinese)(2019年3期)2019-07-01 02:37:48
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
中學生數理化·中考版(2018年10期)2018-12-07 00:44:52
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
中央社會主義學院學報(2017年1期)2017-04-16 05:34:07
中國衛生(2014年12期)2014-11-12 13:12:40
