一種改進模糊kNN的云計算故障檢測方法
2018-10-17 12:25:36劉誠誠
小型微型計算機系統 2018年10期
劉誠誠,姜 瑛
1(云南省計算機技術應用重點實驗室,昆明 650500)
2(昆明理工大學 信息工程與自動化學院,昆明 650500)
1 引 言
故障檢測主要研究如何對系統中出現的故障進行檢測、分離和識別,即判斷故障是否發生,定位故障發生的位置和種類,以確定故障的大小和發生的時間等[1],避免或減少系統失效所帶來的損失,保障了系統性能和可靠性[2].
隨著云計算的應用越來越廣泛,大規模高動態性的云平臺以及大量的惡意攻擊和管理人員的不規范操作,引起部分甚至所有服務的失效,已經成為一種常態而非罕見事件[3].一旦云計算發生異常,產生故障,將會給社會、企業、個人造成難以估量的損失.例如2014年1月Gmail出現大范圍的宕機,來自歐洲、美國、加拿大、印度和其他國家的報道顯示,谷歌的電子郵件服務已經關閉1;2011年4月Amazon EC2的彈性塊儲存(EBS)出現故障,受影響的EBS影響了EBS API,并導致在整個美國東部地區EBS對API的調用出現高的錯誤率和延遲率2.目前,保證云計算系統可用性是云計算面臨的一個重要的挑戰[4].因此,有效的云計算故障檢測成為保障云計算可用性的關鍵.
2 相關工作
故障數據檢測實質上是一種模式識別問題,通過已有的故障數據建立故障檢測模型,并以此對未知的故障數據進行識別[5].將機器學習方法應用于云計算故障檢測,能使系統具有更強的適應性、自學習性和魯棒性,是目前云計算故障檢測的一個重要方向,國內外相續有眾多學者提出一系列用于云計算故障檢測的方法.為了提升故障檢測的準確性,Song Fu等[6]提出了一種云環境下基于貝葉斯與決策樹的主動云計算故障管理方法,首先利用貝葉斯模型預測出故障行為,系統管理員對其進行標記,然后利用標記的故障樣本點作為訓練樣本構建決策樹,最后對未標記的樣本點進行故障預測.Chirag N.Modil等[7]將貝葉斯和Snort檢測系統用于云計算故障檢測,貝葉斯分類器通過觀察先前存儲的網絡事件預測給定事件是否攻擊,而Snort用于檢測已知攻擊.實驗結果表明,此方法降低了誤檢率,降低了計算成本.Stehle E等[8]利用計算幾何學方法來檢測系統故障,分為訓練和檢測兩個階段,在訓練階段,搜集系統正常運行時多維度監測數據,建立幾何閉包以表示系統的運行狀態空間,在檢測階段,將不能包含在計算幾何閉包內的監測數據判斷為異常狀態.
但是,上述基于監督學習的云計算故障檢測方法存在兩個主要問題:首先,未對訓練樣本做處理,忽略了訓練樣本中噪聲數據對檢測準確性的影響,由于云計算故障數據通常是監測系統采集或者人工標注,這種狀況下,不可避免的會出現噪聲數據,如果不對噪聲數據進行處理,將會影響檢測準確性;其次,訓練樣本得不到更新,沒有識別未知類型故障的能力,由于云計算系統是動態多變的,訓練集并不能完全的體現每個云計算故障類型的特點,這就需要不斷的完善每個類別的訓練樣本,否則也會影響檢測的準確性.
為了解決上述問題并提高故障檢測速度,本文定義了云計算故障模型并提出一種改進模糊kNN的云計算故障檢測方法.首先,該方法為了區別出初始云計算故障數據訓練集中噪聲數據,利用基于密度聚類的方法對訓練集進行預處理,計算每條數據屬于對應類別的模糊度量并給噪聲數據更小的隸屬度;其次,為了區分故障特征的重要程度,采用模糊熵與互信息相結合方法進行故障特征加權;然后,為了讓模糊kNN更適用云計算故障檢測且提高檢測準確性和速度,采用云計算故障特征加權以及分層檢測的方法改進模糊kNN,確定待檢測云計算數據的近鄰訓練樣本;最后利用基于最大隸屬度的自學習確定待檢測云計算數據檢測結果,檢測結果包括待檢測云計算數據故障類型、未知類型故障數據、訓練集的更新樣本.
3 定義云計算故障模型
分層模型的基本思想是根據所述類別的不同對已知樣本進行分層,并根據模型對未知樣本進行分類.云計算系統內部可以看作是一組服務的集合,這些服務主要分為三層[9,10]:基礎設施即服務層(Infrastructure as a Service,IaaS)、平臺即服務層(Platform as a Service,PaaS)、軟件即服務層(Software as a Service,IaaS),其中每層涉及的內容、包含的功能各不相同.本文根據分層模型的基本思想并結合云計算系統內部結構,按照云計算故障所屬的層次,將云計算故障分為IaaS 層云計算故障、PaaS層云計算故障、SaaS層云計算故障,并根據各層的架構、組件對各層云計算故障次進一步劃分.圖1按照云計算故障所屬層次對云計算故障進行分層,圖中共分為三層.
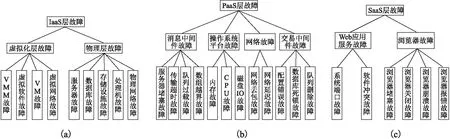
圖1 云計算故障模型Fig.1 Cloud computing fault model
云計算故障模型的分層檢測將從圖1第一層開始判斷,如果待檢測云計算數據屬于其中的一種或幾種云計算故障,則只需沿著對應云計算故障類型的分支進行檢測.而傳統的方法需要對所有云計算故障類型進行比較,可以看出使用本文提出的云計算故障模型可以提升檢測速度,并能對云計算故障進行定位.
由圖1可以看出云計算故障數據存在數據量大、數據源多樣的特點,且實際的云計算故障數據還具有數據更新速度快、類域交叉或重疊、數據存在噪聲等特點[11,12].
4 基于改進模糊kNN的云計算故障檢測方法
本節針對云計算故障數據的特點并結合基于監督學習的云計算故障檢測方法的不足,提出一種改進模糊kNN的云計算故障檢測方法,該方法分為云計算故障數據預處理、云計算故障特征加權、云計算故障檢測三個部分,其中云計算故障檢測包括確定待檢測云計算數據的近鄰訓練樣本和確定待檢測云計算檢測結果.檢測的流程圖如圖2所示.

圖2 云計算故障檢測流程圖
4.1 云計算故障數據預處理
云計算故障檢測中,如何提高檢測準確性是普遍關注的問題,而云計算故障數據訓練集的質量是影響檢測準確性的一個重要因素,云計算故障數據訓練集類別越準確,內容越全面,檢測的準確性就越高.噪聲數據常常位于類邊緣附近,影響了檢測的準確性.
本節將針對云計算故障數據存在噪聲數據問題進行預處理.通過基于密度聚類的方法,區別出噪聲數據,并給每個訓練樣本屬于對應云計算故障類型的隸屬度,且對噪聲數據賦予較小的隸屬度.假設T={(xi,ci)|i=1,…,N}為包含一個云計算故障類型的初始云計算故障數據訓練集,其中N為樣本的個數,ci為xi對應的故障類型,每個訓練樣本xi都是一個p維的向量.首先,計算T每個樣本的密度,得到一個密度為標準的集合G;然后,在G的基礎上進行類中心的選取,并根據樣本間的最大密度差確定噪聲數據;最后,根據訓練樣本到類中心的距離計算每個訓練樣本的隸屬度.具體的方法如下:
1)根據距離公式(1)計算T中訓練樣本xi的K個最近鄰樣本;
(1)
其中xil表示訓練樣本xi的第l個云計算故障特征,xj為T中的樣本,j≠i,j=1,…,N.
2)根據(1)獲得的xi的K個最近鄰樣本并結合公式(2)計算T中每個訓練樣本的分布密度,并對密度進行點排序,從而得到密度點的集合G;
(2)
其中,α為密度參數(α>1),pij為連接樣本點xi和xj之間的所有路徑,l為連接樣本點xi和xj路徑中訓練樣本的個數,d(xk,xk+1)為xk與xk+1之間的歐式距離公式.
3)選取密度最大的一個樣本點xmax并通過歐式距離公式計算出與其最近的樣本點xb;通過這兩個點構造類中心a:
a=0.6×xmax+0.4×xb
(3)
4)根據公式(4)中確定的R值區別出噪聲數據,當T中訓練樣本xi到類中心的距離d(a,xi)大于R,則該樣本為噪聲數據.
R=xj-a,xj滿足max(density(xj)-density(xj+1))≤ε
(4)
其中,j≤N-1,density(xj)∈G,ε為調節閾值.
5)根據公式(5)計算T中訓練樣本的隸屬度,并給噪聲數據較小的隸屬度.
(5)
通過對T的預處理得到云計算故障數據訓練集D=(xi,ci,μ(xi))i=1,…,N,本節對噪聲數據賦予較小的隸屬度,能夠有效地將噪聲數據與有效訓練樣本區分開能,減少噪聲數據對故障檢測準確性的影響.
4.2 云計算故障特征加權
得到云計算故障數據訓練集D后,將對云計算故障數據特征進行加權.文獻[13]根據模糊熵值越大不確定性越大的原則進行特征的選取,目的是為了保證分類的正確率的同時減小分類時間.文獻[14]以特征的模糊熵值統一確定權值,并不能很好的體現每個類特征的特點,且忽略了特征與特征之間的關系.
本文為了更好的區別云計算故障數據特征的重要程度,首先,去除D中的噪聲數據得到集合D*=(xi,ci,μ(xi))i=1,…,n;然后,提出模糊熵值和互信息[15,16]相結合的方法構造云計算故障特征的權值,其中互信息常用來度量2個特征相關程度的方法[17].利用模糊熵和互信息相結合的特征權值計算步驟如下:
1)對D*中訓練樣本歸一化,找出能代表集合D*的理想向量idt,本節理想向量通過每個云計算故障類型中所有樣本的均值確定;
2)計算D*中訓練樣本xi與該云計算故障類型理想向量idt每個特征的相似度:
(6)
其中,xil表示集合D*中第i個訓練樣本的第l個云計算故障特征,idtl表示訓練樣本xi對應類別的理想向量的第l個特征.該類樣本得到一個n×p的相似度矩陣,記為S.
(7)
3)根據S計算出每個云計算故障特征的模糊熵值,將每個云計算故障特征對應的相似度作為隸屬度帶入式(8)中得到對應的模糊熵值;
(8)
其中l=1,…,p為訓練樣本的第l個云計算故障特征.
4)根據公式(9)計算D*中訓練樣本第l特征與其他特征之間的互信息和;

(9)
其中,r=1,2,…,p,I(l)表示D*中訓練樣本第l特征與其他特征之間的互信息之和,H(r)表示D*中訓練樣本第r個故障特征模糊熵值,H(l,r)表示訓練樣本第l個特征和第r個特征的聯合模糊熵值.
(10)
5)根據公式(11)計算各個云計算故障特征的權值.
(11)
其中,wl表示D*中訓練樣本的第l特征的權值.
通過上述云計算故障特征加權方法,可以確定每個云計算故障類型的每個云計算故障特征的權值.
4.3 云計算故障檢測
本節首先確定待檢測云計算數據的近鄰訓練樣本,然后確定待檢測云計算數據的檢測結果.
4.3.1 確定待檢測云計算數據的近鄰訓練樣本
由于kNN方法是靠近鄰來確定數據所屬類別,因此對于存在類域交叉或重疊的數據來說,kNN方法較其他方法更合適[18].本節使用模糊kNN判斷待檢測云計算數據的近鄰訓練樣本,并根據云計算故障數據自身的特點以及模糊kNN的不足,對模糊kNN進行改進.
針對云計算故障數據自身的特點以及傳統模糊kNN的不足,主要在以下方面進行改進:
1)采用加權距離判斷待檢測云計算數據的近鄰訓練樣本.傳統的歐氏距離并沒有體現特征對于檢測的貢獻不同的規律,本文采用基于模糊熵和互信息相結合的特征賦權方法.
2)根據基于云計算故障模型的分層結構進行分層檢測.針對云計算數據量大、數據源多樣的特點,本文根據云計算故障模型構建樹狀分層結構,首先對高層進行檢測,然后依據高層比較結果的不同,再依次對下一層次進行檢測,相比直接對所有云計算故障類型中訓練樣本進行計算,提高了檢測速度,并能對云計算故障進行定位.
具體的步驟如下:
(1)將云計算故障數據訓練集D中的故障類型按照云計算故障模型進行分層,構建成m(m≤3)層樹狀模型.
(2)計算待檢測云計算數據與前m層云計算故障類型類中心的加權距離(前m層處理方式相同,以下以第1層做具體說明):
1)根據第4.2節提到的方法計算第1層所有云計算故障類型的特征權值,對歐式距離進行加權,加權歐式距離公式為:
(12)
其中,xs表示待檢測云計算數據,atl表示第1層上第t個云計算故障類型類中心at的第l個特征,wtl表示第1層上第t個云計算故障類型的第l個特征的權值.
2)根據加權距離,在第1層的云計算故障類型中選出與待檢測云計算數據最近的k1(k1≤對應層云計算故障類型數)個近鄰.
(3)在前m層中,判斷k1個近鄰云計算故障類型中是否存在葉子節點且非全部葉子節點,如果存在,則保留該葉子節點,并和k1中非葉子節點對應的下一層故障類型一起作為待檢測云計算數據的“訓練樣本”;如果不存在,則沿著k1個云計算故障類型對應的下一層故障類型進行檢測,以此獲得第m層的k1個近鄰云計算故障類型;如果k1個近鄰云計算故障類型全部是葉子節點,則從k1個云計算故障類型對應的訓練樣本中選取k2個近鄰訓練樣本.
(4)根據第m層獲得k1個近鄰云計算故障類型,從k1個云計算故障類型對應的訓練樣本中選取k2個近鄰訓練樣本.
通過改進模糊kNN方法可以獲得待檢測云計算數據的近鄰訓練樣本.
4.3.2 確定待檢測云計算數據檢測結果
由于云計算數據具有更新速度快的特點,及時更新云計算故障數據訓練集才能提升云計算故障檢測準確性.本節根據得到的待檢測云計算數據xs對應的k2個近鄰訓練樣本,通過基于最大隸屬度的自學習分析k2個近鄰訓練樣本的隸屬度來確定待檢測云計算數據檢測結果.
1)計算k2個云計算故障數據中最大的隸屬度umax:
(13)
其中,i=1,2,…,k2表示待檢測云計算數據的第i個近鄰,μ(xi)表示近鄰xi屬于對應類別隸屬度,wil表示近鄰xi對應云計算故障類型的第l特征的權值.
2)根據umax大于閾值σ1且待檢測云計算數據與umax對應訓練樣本所屬云計算故障類型的理想向量的距離小于匹配閾值ρ來確定該待檢測云計算數據的類別為umax對應云計算故障數據所屬云計算故障類型,并將該待檢測云計算數據及其類別信息加入去除噪聲數據的初始云計算故障數據訓練集T*;
3)根據umax小于閾值σ2來確定待檢測云計算數據為未知類型故障,并將該待檢測云計算數據和其類別信息加入去除噪聲數據的初始云計算故障數據訓練集T*;
4)跟據umax小于閾值σ1且umax大于閾值σ2來確定待檢測云計算數據的類別為umax對應訓練樣本所屬云計算故障類型.
根據云計算故障檢測,可以獲得待檢測云計算數據的故障類型、云計算故障數據訓練集的更新樣本以及待檢測云計算數據中屬于未知類型故障的數據,并將T*作為新的初始云計算故障數據訓練集.
5 實 驗
5.1 實驗環境
為了驗證本文提出方法的有效性,本文應用eclipse4.3.0實現了相關方法,在win7系統下進行實驗,并搭建基于Hadoop的云平臺用以采集實驗數據.其中搭建Hadoop集群包含3臺主機,其中2臺是從節點,1臺式主節點.主機的配置如表1所示.

表1 主機配置情況Table 1 Host configuration
5.2 實驗數據采集及分析
本文的云計算故障數據通過故障注入[19,20]產生,并使用基于Ganglia的性能數據采集工具收集云計算系統的性能數據,包括系統的CPU占用率、內存占用率、網絡利用率、I/O占用率等屬性,采集的時間間隔為5分鐘.云計算故障數據采集主要是在系統運行時人為的注入故障(網絡延遲故障、內存故障、CPU故障、磁盤IO故障).實驗數據共用23888條數據,其中正常類別數據樣本4917個,PaaS層故障樣本18971個,PaaS層故障及其子故障類型、樣本數如表2所示.

表2 PaaS層故障及其子故障類型、樣本數
本次實驗從表2和正常類別數據中隨機選取1500個正常樣本、1500個網絡故障樣本、4500個操作系統平臺故障樣本(包括1500個CPU故障樣本、1500個內存故障樣本、1500個磁盤IO故障樣本)作為云計算故障訓練樣本,使用包含各個類別的16388個樣本作為待檢測云計算數據.本文實驗相關參數設置為K=7,ε=0.013,σ1=0.93,σ2=0.27.
5.3 實驗結果及分析
實驗1.實驗1就本文方法的檢測準確性進行實驗.檢測準確性評估指標使用常用的真正率(True Positive Rate,TPR)、真負率(True Negative Rate,TNR)以及正確檢測率(Correct Detection Rate,CDR).
(14)
(15)
(16)
其中,TPR刻畫的是被檢測為正常樣本的正常樣本數占所有正常樣本的比例;TNR刻畫的是被檢測為故障樣本的故障樣本數占所有故障樣本的比例;CDR為TPR與TNR和的均值;TP表示被檢測為正常樣本的正常樣本數;TN表示被檢測為故障樣本的故障樣本數;FN表示被檢測為故障樣本的正常樣本數;FP表示被檢測為正常樣本的故障樣本數.
實驗中設置參數k1=2、k2=1~20,并將本文方法與經典的模糊kNN方法、本文方法1(加入更新訓練樣本)、文獻[6]中決策樹方法進行檢測準確性對比,其中,文獻[6]提出的方法是以提升檢測準確性為目的;更新訓練樣本為本文方法運行產生的云計算故障數據訓練集的更新樣本,包含正常樣本29個、內存故障樣本33、CPU故障樣本26個、未知類型故障樣本6個.本文方法與模糊kNN、本文方法1、文獻[6]決策樹方法的實驗結果如圖3到圖6所示.


圖3 本文方法與模糊kNN、本文方法1的真正率 Fig.3 TPR of this paper's method,fuzzy kNN and this paper 's method 1圖4 本文方法與模糊kNN、本文方法1的真負率Fig.4 TNR of this paper's method,fuzzy kNN and this paper's method 1圖5 本文方法與模糊kNN、本文方法1的正確檢測率Fig.5 CDR of this paper's method,fuzzy kNN and this paper's method 1圖6 文獻[6]決策樹方法的TPR、TNR、CDRFig.6 TPR,TNR and CDR of the decision tree method in literature [6]
從圖3到圖6可以看出,本文方法的檢測準確性明顯高于模糊kNN方法、文獻[6]決策樹方法,本文方法1的檢測準確性略高于本文方法.

表3 四種方法的檢測結果
如圖6所示,文獻[6]決策樹方法實驗結果的橫坐標表示的值為隨機選取訓練樣本的百分比,與圖3-圖5其他三種方法實驗結果的橫坐標表示的值不一致,因此未將文獻[6]決策樹方法的實驗結果放在圖3-圖5中比較.四種方法的最高真正率(TPRmax)、最高真負率(TNRmax)、最高正確檢測率(CDRmax)如表3所示.
從表3可以看出,本文方法相對于模糊kNN,最高CDR提升了2.99%,相對文獻[6]決策樹方法,最高CDR提升了2.14%,本文方法1相對本文方法的最高CDR提升0.13%.說明本文方法的檢測準確性要好于模糊kNN方法、文獻[6]決策樹方法,且本文的基于最大隸屬度的自學習是有效的.

表4 識別未知類型故障的實驗結果Table 4 Fault,sub fault type and sample number of PaaS layer
實驗2.實驗2就本文方法識別未知類型故障的效果進行實驗.在云計算故障訓練樣本中任意刪除所構成云計算故障模型葉子節點上的一個云計算故障類型,并在待檢測云計算數據中保留該云計算故障類型的1000個樣本作為未知類型故障故障,其中參數k1為2.記錄本文方法識別未知類型故障的情況,實驗結果如表4所示.
由表4可以看出,當未知類型故障為內存故障時,識別率最高達到90.3%,對未知類型故障的平均識別率為87.82%,說明本文的方法具有識別未知類型故障的能力.
實驗3.實驗3就本文方法的檢測速度進行實驗.本次試驗分別使用本文方法與本文方法2(不包含基于云計算故障模型的分層檢測的本文方法)、模糊kNN方法對待檢測云計算數據進行檢測,記錄其檢測用時并進行比較,分別運行N(N=5)次求平均時間,實驗結果如表4所示.

表5 故障檢測時間比較Table 5 Comparison of fault detection time
由表5可以看出,本文方法在時間上比傳統的模糊kNN方法時間縮短了28.68%,本文方法用時比本文方法2提升了43.01%,且本文方法2比模糊kNN方法用時多出871ms,分析原因,是由于本文方法對訓練集進行了預處理以及對特征進行了加權.綜上可以看出,本文的方法是一種對云計算故障檢測效果較好且速度較快的檢測方法.
6 總 結
本文提出了一種改進模糊kNN的云計算故障檢測方法.首先采用基于密度聚類方法來對云計算故障數據訓練集進行預處理,給噪聲數據賦予更小的隸屬度,減小噪聲數據對檢測效果的影響.其次對模糊kNN進行改進,使其更適合云計算的云計算故障檢測.最后根據基于最大隸屬度的自學習方法,不斷的更新云計算故障訓練樣本集,識別未知云計算故障.實驗表明本文方法在云計算故障檢測方面是有效的.但是本文方法還有不足的地方,沒有充分考慮云計算故障轉移,今后將針對這個問題進行持續研究.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
