基于神經網絡的微博情緒識別與誘因抽取聯合模型
2018-10-16 08:23:48姬東鴻
計算機應用 2018年9期
張 晨,錢 濤,姬東鴻
(1.武漢大學 國家網絡安全學院,武漢 430072; 2.湖北科技學院 計算機學院,湖北 咸寧 437100)
0 引言
情緒分析[1-2]是自然語言處理領域特別是社交媒體領域非常重要的研究內容之一,主要研究文本所蘊含的情緒及與情緒相關的深層信息。目前文本的情緒分析主要集中在情緒識別任務上,如文本的情緒極性分析,Li等[3]對文本的正負面情感程度進行了研究;或判斷文本的情緒是高興、喜歡、討厭等,黃磊等[4]就對微博文本的情緒分類進行了探索。
為了實現深層次的文本情緒理解,情緒誘因抽取[5]已成為情緒分析中新的熱點問題,所謂情緒誘因抽取就是針對文本中出現的被描述者的情緒,抽取出被描述者情緒產生的原因信息。當前對情緒誘因的抽取主要分為兩類方法:一類是基于規則的方法[6],主要是通過語法規則構造情緒誘因與情緒之間的模板進行情緒誘因的抽取;還有一類是基于統計的方法[7],主要通過條件隨機場(Conditional Random Field, CRF)和支持向量機(Support Vector Machine, SVM)分類器等方法進行情緒誘因的抽取。
這些誘因抽取方法假設情緒已經被識別出來,即把情緒識別和誘因抽取看作是兩個獨立的任務,容易引發錯誤在任務間傳播的問題。情緒識別及誘因抽取是相互關聯的:一方面,情緒識別依賴于誘因;另一方面,誘因抽取要求知道情緒類別。因此聯合誘因抽取和情緒識別是自然的,能有效緩解串行模型所導致的錯誤傳播問題。
微博目前已成為使用最廣泛的社交媒體之一,其已成為情緒分析的主要對象之一[8]。微博不同于規范文本采用文本表達情緒,它通常采用表情符來表達情感或情緒。如下兩則微博:

在這兩則微博中,情緒通過表情符來表達。在微博①中表情符表達了作者“高興”的心情,子句2為其誘因,在微博②中,表情符表達了作者“悲傷”的心情,子句1為其誘因,顯然誘因與表情符的所表達的情緒有著直接關聯。此外,已有研究[9]顯示,表情符也存在歧義表達,如上面例子,同一表情符在不同誘因下表達不同的情緒,因此對表情符的情緒消歧或識別也是非常重要的。
基于微博文本的特點,本文提出情緒誘因抽取和表情符情緒識別的聯合模型,該模型把情緒誘因抽取和表情符情緒識別形式化為一個統一的序列標注任務。模型采用雙向長短期記憶(Bi-directional Long Short-Term Memory, Bi-LSTM)模型[10]與條件隨機場(CRF)模型[11]聯合進行訓練,充分利用了遠距離信息及全局特征,同時避免了復雜的特征工程。為了訓練和評測模型,本文同時構建一個基于微博的情緒誘因語料庫。
1 相關工作
情緒誘因任務由Lee等[12]在2010年首次提出,他們使用的方法是基于規則模板的方法,對于數據集出現的情緒誘因的語法結構進行規則集的構造,從而進行誘因的提取。Chen等[13]和Russo等[14]開始在基于規則模板的基礎上又加上了情緒誘因與情感表達之間的位置關系。然而,規則很難覆蓋所有的語言現象,而且規則之間很容易出現難以發現的矛盾,最重要的是規則往往針對于某個特定領域的文本而難以適用于其他領域的文本。隨著統計學的方法在自然語言處理領域任務表現越來越好,袁麗[15]通過對語言學線索詞、句子距離、候選詞詞法等特征構建特征向量,應用支持向量機分類器和條件隨機場對文本的情感原因進行了判別。Ghazi等[16]在2015年使用了條件隨機場來進行情緒誘因的抽取,但是局限于必須含有情感表達的描述且描述內容與情緒誘因在同一個子句當中。最近,基于神經網絡的方法被應用在該任務,Gui等[17]將情緒誘因任務看作一個問答系統(Question-Answer, Q-A)的問題,采用了深度卷積神經網絡的模型來進行訓練,得到了不錯的結果。慕永利等[18]則采用了集成的卷積神經網絡的模型將情感誘因看作子句級別上的分類問題進行訓練與測試,在自己的標注的數據集上得到了超過普通方法的結果。
誘因抽取通常可看作是一個序列標注任務,當前對序列標注采用的方法通常是隱馬爾可夫模型(Hidden Markov Model, HMM)[19]、CRF等,特別是CRF充分利用上下文信息及全局優化達到了較好性能,但CRF模型通常采用人工設計的特征,可能導致復雜的特征工程,并且不能充分利用遠距離信息。當前循環神經網絡(Recurrent Neural Network, RNN)模型由于減緩了復雜的特征工程及充分利用上下文信息已廣泛應用于序列標注問題。特別它的變種Bi-LSTM與CRF結合所結合成的雙向長短期記憶條件隨機場(Bi-LSTM CRF, Bi-LSTM-CRF)模型[20]結合了二者的優點,在序列標注問題如命名實體識別、詞性標注、句法解析等取得了最好效果。
當前,研究人員已建設了一些情緒誘因語料[21],但它們都是針對規范文本,而對社會媒體如微博等缺少相關誘因標注語料。本文針對微博文本情緒表達的特點,構建一個較大模型的標注語料,并采用機器學習進行誘因及情緒聯合分析。
2 微博情緒語料的構建
由于缺少公開基于中文微博的關于情感誘因抽取的數據集,因此本文將通過人工標注方式建立了一個情緒誘因及表情符情感的微博數據集。本章將首先介紹標注方案,然后給出標注語料的統計信息。
2.1 標注方案
慕永利等[18]在對規范文本標注時把誘因抽取看作是子句的識別,即把含有誘因表達所在的子句整體標注為誘因,本文也采用此標注方案。此外由于微博通常用表情符來表達情緒,對微博的情緒識別可看作是對表情符的情緒識別,因此把情緒標注在表情符上。情緒標簽采用常用的情緒分類法,分為7類,包括:高興(happiness)、悲傷(sadness)、驚訝(surprise)、害怕(fear)、厭惡(disgust)、憤怒(anger)和無情感(none)。
例子①、②的標注格式分別如下:
其中cause標簽內文本表示誘因,其中emoji屬性表示它所屬于哪個emoji的誘因,emoji標簽表示表情符,其包含兩個屬性:id及情緒label。
2.2 語料構建
首先在新浪微博上隨機爬取了2017年7月至2017年10月期間的微博文本共27 000篇,將文本長度小于5個字(英文以單詞計數不包括標點符號)的文本、不包含表情符的文本、廣告性質的文本和重復的文本剔除后獲得了5 771篇待標注的微博文本。對篩選后的6 771篇微博文本進行人工標注,每一處表情符的分類由兩名標注者進行標注,不統一的再由第三名標注者進行判定,然后由決定了表情符分類的標注者標注該表情符對應的情感誘因,情感誘因以子句為單位進行標注。最后得到一個語料數據集。該數據集包含9 386個表情符,29 061個子句,其中誘因子句數為10 465。表1顯示了不同情緒類別下的表情符個數與誘因。

表1 不同情緒類別下的表情符個數與誘因統計
由于表情符存在歧義表達,即使同一種表情符在不同的語境中很有可能表達出不同的情緒,因此本文對數據集中出現次數最多的10個表情符的情緒類別進行了統計,結果如表2所示,從表中可以看出表情符往往包含超過一種情緒,這說明表情符表達出的情感除了自身的意義外很大程度上受上下文中的情緒影響,從一定程度上能夠反映出上下文的情緒,而上下文的情緒與情緒誘因之間是相互關聯的。

表2 表情符情緒類別分布 %
3 基于Bi-LSTM-CRF的聯合模型
3.1 CRF模型
已有研究大多將情感誘因抽取看作一個子句層級上的分類問題[16],但分類問題會割裂子句與子句之間的全局關聯。本文提出把誘因抽取看作是一個標注問題,從詞級別可設置為三個標簽B-Cause、I-Cause、O,其中B-Cause、I-Cause聯合來標注誘因子句,B-Cause表示誘因子句的第一個詞,I-Cause表示誘因子句的其他部分,O表示非誘因子句。對表情符的情感識別也可看標注問題,其標簽即是情緒類別,可分別表示為:Happiness、Sadness、Fear、Anger、Surprise、Disgust、None。綜合兩類標注問題,可自然將其統一為一個標注問題,其標簽即為兩類標注問題的標簽集合。對例②其標注結果見圖1。
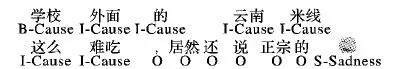
圖1 微博例②的標注結果
因此可將誘因抽取與情緒識別形式化為聯合的條件隨機場(CRF)模型[18],CRF模型更多關注的是一個序列的整體性,它通過考察序列的聯合概率來進行判別,因此能夠有效地考慮到上下文的標簽信息和全局信息。對于例②,圖2給出基于CRF的網絡結構圖。
3.2 Bi-LSTM-CRF模型
CRF模型利用遠距離和全局特征優化,在序列標注問題中得到廣泛應用,但需要復雜的特征工程。LSTM避免了復雜的特征工程。當前Bi-LSTM-CRF結合了Bi-LSTM模型與CRF模型的優點,在序列標注問題如命名實體識別、詞性標注、句法解析等取得了較好效果。本文將采用Bi-LSTM-CRF作聯合誘因抽取與情緒識別。圖3給出該模型對于微博例②的框架。

圖2 微博例②的CRF網絡結構
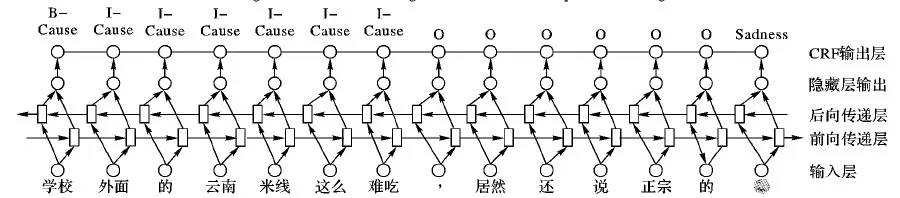
圖3 微博例②Bi-LSTM-CRF模型結構
在聯合誘因識別與情緒分類任務中,其輸入微博由單詞和表情符序列組成,記作X=(x1,x2,…,xn);輸出為Y=(y1,y2,…,yn),即輸入單詞和表情符所對應的標簽。
基于Bi-LSTM-CRF的聯合模型分為三層,分別為輸入層、Bi-LSTM層、CRF層。
輸入層 輸入層之前會將微博通過Word2Vec預先訓練好的詞向量集合進行轉換,將每個詞語和表情符變成一個低維的空間向量xt,它們的集合即模型的輸入X=(x1,x2,…,xn);
Bi-LSTM層 為雙向長短時記憶模型。這是一種特殊循環神經網絡(RNN)模型,主要目的用來處理序列數據,其在自然語言處理中取得了廣泛應用。LSTM能夠提升神經網絡接受輸入信息及訓練數據的記憶機制,讓輸出結果得到大幅度的提升。對于短文本中的第t個單詞wt,首先將wt映射到一個詞向量xt∈Rd,一個LSTM單元的輸入為:單詞xt,上一輸出隱狀態ht-1,上一內存狀態ct-1,輸出為ht、ct。具體公式如下:
it=σ(Wixt+Uiht-1+bi)
ft=σ(Wfxt+Ufht-1+bf)
ct=ft⊙ct-1+it⊙ct
ot=σ(Woxt+Uoht-1+bo)
ht=ot⊙tanh(ct)
對于普通的LSTM,其存在一個缺點,即只能正向讀取文本,因此本文使用能夠雙向讀取文本的Bi-LSTM模型。Bi-LSTM包含一個正向的LSTMforward,由x1讀取到xT,以及一個反向的LSTMbackward,由xT讀取到x1:
xt=Wewt;t∈[1,T]

CRF層 該層將上一層得到的輸出H作為輸入,得到觀測序列X和與其標注序列T的預測輸出。假設CRF層的狀態轉移矩陣為A,其中Ai, j表示從第i個狀態轉移到第j個狀態的概率,Bi-LSTM神經網絡的輸出為H,其中Hi, j表示觀測序列中的第i個詞標記為第j個標簽的概率。因此對于觀測序列X=(x1,x2,…,xn)和對應的標注序列Y=(y1,y2,…,yn)的預測輸出為:
3.3 訓練過程
模型訓練采用最大條件似然估計,對于輸入x預測其標簽y的概率表示為:
給定一個訓練集{xi,yi},其優化目標就是最大化其對數似然估計函數:
模型使用隨機梯度下降方法來進行前向傳播和后向傳播的訓練過程,具體算法如下:
輸入:數據集{xi,yi},單詞向量集V,參數θ, 迭代次數k;
輸出:參數θ。
1)
for 1 tok
2)
for每一個訓練微博子集
3)
①Bi-LSTM模型的前向傳播:
4)
正向LSTM過程傳播
5)
反向LSTM過程傳播
6)
輸出隱層變量H
7)
②CRF層將H作為輸入進行前向傳播和后向傳播
8)
③Bi-LSTM模型的后向傳播:
9)
正向LSTM過程傳播
10)
反向LSTM過程傳播
11)
④更新模型參數θ
4 實驗與分析
4.1 數據參數設置
實驗數據為本文前面所提人工標注數據集,共6 771個實例。實驗評估方式以常用的序列標注評價指標準確率、召回率、F值作為評價標準。需要說明的是,本文假設情感誘因以子句為基礎單位,所以在計算情感誘因的指標時,將模型計算得到的序列按子句進行拆分,覆蓋超過2/3子句長度的部分會補全成整個子句,補全完成后再進行上述指標的計算。實驗過程中,對數據集中的數據采用十折交叉檢驗的方法,求得各個指標的值。
模型的輸入采用Word2Vec來表示文本的詞向量,訓練過程中采用反向傳播方法進行參數調整,損失函數采用交叉熵損失函數。通過進行大量實驗及參數調整后,獲得的超參數設置如下:詞向量維數d為200,隱藏層單元數hidden為300,學習率lr為0.01,dropout的百分比為50%,迭代次數為80。
4.2 實驗結果
實驗中采用以下模型與本文模型作比較:
1)串行Bi-LSTM-CRF模型。將情緒誘因抽取和表情情緒識別看作兩個單獨的序列標注問題,使用Bi-LSTM-CRF模型先進行表情符情緒識別,再作誘因抽取。
2)串行標注-分類模型。將情緒誘因抽取看作序列標注問題,表情情緒識別看作分類問題,先使用CNN分類模型進行表情符情緒識別,再使用Bi-LSTM-CRF模型進行誘因抽取。
3)聯合CRF模型。將情緒誘因抽取和表情情緒識別看作統一的序列標注問題,使用CRF模型進行訓練和標注。其特征包括上下文、詞性、句法、語義、情感詞等特征。
已有研究顯示[22]Bi-LSTM-CRF模型在序列標注任務中達到了最好性能,因此本文未與其他如HMM、支持向量機(Support Vector Machine, SVM)等模型作比較。
表3給出了實驗結果。從表中可以看出,本文所提聯合Bi-LSTM-CRF模型達到了最好性能。比較串行Bi-LSTM-CRF模型,本文模型在情緒識別F值提升17.12個百分點,在誘因抽取F值提升5.82個百分點。情緒識別的F值提升明顯,說明了情緒誘因對于表情符的情緒類別有著相當大的影響,同時誘因抽取F值的提升說明了表情符的情緒表達有助于情緒誘因的抽取,減緩了串行模型所導致的錯誤傳播問題。比較聯合CRF模型,情緒識別F值提升8.32個百分點,在誘因抽取F值提升11.82個百分點,主要是Bi-LSTM較有效利用遠距離信息,同時也避免了復雜的特征工程。此外,對比兩個串行模型,CNN模型相較于Bi-LSTM-CRF模型在情緒識別任務上F值高出了12.13個百分點,而隨后的誘因抽取都使用的是Bi-LSTM-CRF模型,前者也比后者高出了2.89個百分點,說明了情緒表情符的情緒類別對誘因抽取有著一定的影響。
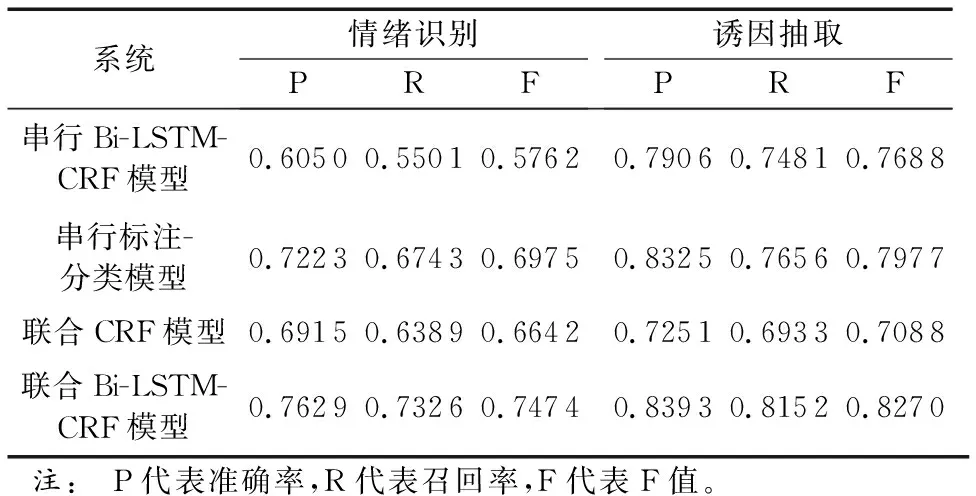
表3 不同方法的實驗結果比較
為了進一步比較聯合模型與串行聯合的不同,在實驗中分別給兩種模型中不同情緒類別的F值。表4給出了實驗結果。聯合模型比串行模型性能更好。特別是如高興、悲傷的情緒識別與誘因抽取的F值明顯高于串行模型。可能是高興、悲傷的語料最多,使得模型訓練效果更好。


表4 在不同模型中各個情緒類別的F值比較
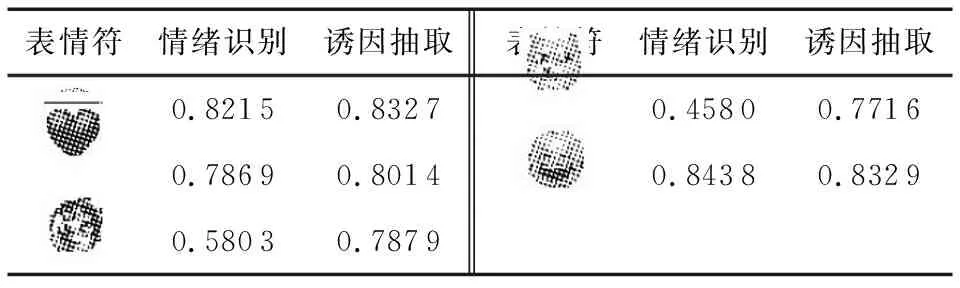
表5 不同表情符在聯合模型中的F值對比
4.3 討論分析
實驗結果顯示聯合模型比串行模型性能有較大提升,主要是因為聯合模型充分利用兩者的信息,減緩了串行模型所產生的錯誤傳播問題。圖5給出聯合Bi-LSTM-CRF模型與串行Bi-LSTM-CRF模型的識別結果,其中聯合Bi-LSTM-CRF模型的識別結果為正確結果,而串行Bi-LSTM-CRF模型由于表情符錯誤識別為Sad,從而誘因抽取錯誤。這里可以看出,能否正確地識別出表情符的情緒類別對誘因抽取的結果有著相當大的影響。

圖4 模型輸出實例結果比較
5 結語
情緒誘因是情緒分析中相當重要的一項內容,能夠進一步理解文本中的情緒特征,而微博文本中的表情符可以表達出這一部分文本的情緒。本文針對微博的文本特征,提出一個聯合的情緒誘因和表情符情緒識別模型,該模型把情緒誘因和表情符情緒識別統一成一個序列標注任務,采用Bi-LSTM-CRF模型,不僅避免了復雜的特征工程,而且充分利用遠距離信息和全局信息,與串行模型相比在誘因抽取任務上F值提高了5.82個百分點,在表情符情緒識別的任務上F值提高了17.12個百分點的性能。結果顯示聯合模型充分解決串行服務的錯誤傳播問題,有效地提高了系統的性能,對下一步進行更深層的文本情緒分析提供了幫助。不過模型仍有不足,現在本文對于情緒誘因只能夠進行粗粒度的抽取,下一步,將從語義事件的角度深度分析誘因的構成與情緒類別的關系。
[15] 袁麗.基于文本的情緒自動歸因方法研究[D].哈爾濱:哈爾濱工業大學,2014:49-60.(YUAN L. The Study on Text-based Emotion Cause Detection[D]. Harbin: Harbin Institute of Technology, 2014: 49-60.)
[16] GHAZI D, INKPEN D, SZPAKOWICZ S. Detecting emotion stimuli in emotion-bearing sentences [C]// Proceedings of the 2015 International Conference on Intelligent Text Processing and Computational Linguistics, LNCS 9042. Berlin: Springer, 2015:152-165.
[17] GUI L, HU J, HE Y, et al. A question answering approach for emotion cause extraction [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: EMNLP, 2017: 1593-1602.
[18] 慕永利,李旸,王素格.基于E-CNN的情緒原因識別方法[J].中文信息學報,2018,32(2):120-128.(MU Y L, LI Y, WANG S G. Emotion cause detection based on ensemble convolution neural networks [J]. Journal of Chinese Information Processing, 2018, 32(2): 120-128.)
[19] RABINER L R. A tutorial on hidden Markov models and selected applications in speech recognition [J]. Readings in Speech Recognition, 1990, 77(2): 267-296.
[20] 張子睿,劉云清.基于BI-LSTM-CRF模型的中文分詞法[J].長春理工大學學報(自然科學版),2017,40(4):87-92.(ZHANG Z R, LIU Y Q. Chinese word segmentation based on bi-directional LSTM-CRF model [J]. Journal of Changchun University of Science and Technology, 2017, 40(4): 87-92.)
[21] GUI L, WU D, XU R, et al. Event-driven emotion cause extraction with corpus construction [C]// Proceedings of the 2016 Conference on Empirical Methods on Natural Language Processing. Austin: EMNLP, 2016: 1639-1649.
[22] HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging [EB/OL].[2017- 12- 27]. https://arxiv.org/pdf/1508.01991.pdf.
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
小學教學參考(2015年20期)2016-01-15 08:44:38
