基于ListNet排序學習的特征處理方法
2018-09-22 05:38:34李偉寧
計算機技術與發展 2018年9期
李偉寧,王 磊
(1.南京郵電大學 計算機學院,江蘇 南京 210003; 2.南京郵電大學 電子科學與工程學院,江蘇 南京 210003)
0 引 言
排序是信息檢索系統的一個重要組成部分,為了提高用戶檢索的準確性,將更為相關有效的查詢頁面返回給用戶,如何提高搜索的排序質量就顯得尤為重要。隨著搜索引擎的發展,對于某個網頁進行排序需要考慮的因素越來越多,Google目前的網頁排序公式考慮200多種因子,如TFIDF、BM25、PageRank、HITS以及基于點擊數據的用戶行為的特征等,此時機器學習的作用即可發揮出來[1]。
特征以及特征的組合方式對于任何以機器學習算法為依托的任務來說都是至關重要的,并與機器學習算法結合形成了復雜的算法體系[2]。當前對排序學習的特征處理的研究較少,文中的研究重點是對特征進行有效的處理,從而在新的特征集合上構建更加有效的排序函數。
1 相關研究
排序學習嘗試用機器學習的方法解決排序問題,已得到深入研究并廣泛應用于不同的領域,如信息檢索、個性化推薦、文本挖掘、生物醫學等[3-5]。排序學習算法根據其數據形式的不同主要分為三類:Pointwise型,如基于感知器的Prank算法[6],將問題轉換為單個文檔的分類和回歸問題;Pairwise型,如用神經網絡模型結合梯度下降算法去優化排序損失函數的RankNet算法[7]和使用支持向量機的RankingSVM算法[8-9];Listwise型,如基于神經網絡和梯度下降優化方法,應用概率模型來構造損失函數的ListNet算法[10]和基于直接優化信息檢索評價方法的LambdaMART算法[11]。研究表明[12],Listwise方法的排序效果一般要優于Pointwise及Pairwise方法。因此,文中采用Listwise型中經典的ListNet算法進行比較研究。
在排序學習領域,已經提出了很多方法來提高排序的準確率,例如提出一種新的排序學習算法[13],構建一種新的優化函數,設計新的特征。然而,在排序技術較為成熟的基礎上,如果僅靠改進排序學習算法來提高排序結果已經變得越來越難。那么添加由原始特征生成的新特征是否會提升準確率,一些學者進行了研究。Amini等[14]假設若找到一個與已標注文檔最為相似的未標注的文檔,那么就認為這個未標注的文檔與已標注的文檔的相關性條件也是相似的,使用這些文檔實例來擴展訓練數據集。Duh和Kirchhoff[15]應用基于核的主成分分析方法對測試集合抽取新的特征集合,利用測試集合的特征來擴展訓練集合,獲得了好的效果。林等[16]將訓練集與測試集進行合并后的集合進行奇異值分解,提取新的特征集合加入訓練集,在RankBoost排序算法上提高了排序效果。
特征選擇是從一組特征集中挑選出一部分最有效的特征以降低特征空間維數的過程[17]。特征選擇對排序學習有兩大優點:第一,可以提高排序學習的精確度;第二,可以提高訓練的效率。文中綜合利用PCA方法擴展數據集,并在擴展后的數據集上進行排序算法隱含的特征選擇。
2 基于排序學習的特征處理
2.1 基于PCA的數據集擴展
查詢和文檔集的特征組成的特征向量X=(x1,x2,…,xn),求取特征向量X的自相關矩陣Rx,根據PCA原理對Rx進行特征分解,得到特征向量矩陣Λ和特征矩陣U,其中特征矩陣U為:
令Y=UX,Y即為X的K-L變換。其中,U的每一列向量均包含了X的相關信息,將其作為X的組合特征。選取最大特征值對應的特征向量作為X的融合特征添加到原始數據集中,在擴展訓練數據集的同時達到特征融合的目的。算法思想如下:
輸入:訓練集D,驗證集V,測試集T;
輸出:新的訓練集D',新的驗證集V',新的測試集T'。
(1)對訓練集所對應的特征矩陣進行主成分分析,選取前k個主元;
(2)用選取的前k個主元對原訓練集、驗證集、測試集進行主成分分析,分別得到它們的前k個特征向量集Dk,Vk,Tk;
(3)D∪Dk?D',V∪Vk?V',T∪Tk?T',添加后的特征向量維度比原始維度大k。
文中綜合排序訓練時間和排序效果選擇加入合適的特征向量數目。
2.2 基于排序學習的特征選擇
在基于PCA擴展之后的數據集上進行排序算法隱含的特征選擇,算法思想如下:
輸入:特征集合X=(x1,x2,…,xn+k);
輸出:特征子集S=(s1,s2,…,sm),m≤n+k。
(1)對基于PCA方法擴展之后得到的訓練集和驗證集使用排序學習算法得到排序函數;
(2)將上述得到的排序函數的特征系數的絕對值作為對應特征的權重;
(3)做五組實驗,對五組實驗得到的特征權重求和取平均值,權重從大到小排序;
(4)取前m個特征構建新的訓練集、驗證集和測試集。
2.3 排序學習算法
Listwise型排序學習方法是將整個文檔序列看作一個樣本[18]。其中,ListNet方法是將排序問題建模為概率模型,然后選取交叉熵衡量由模型訓練出的文檔排序和真正的文檔排序之間的差異,通過最小化這個差異值來完成排序。ListNet定義了一個置換概率:

(1)
其中,π為作用于n(qi)個文檔的置換;Φ()為一個遞增、恒正的函數;S為一個計算文檔與查詢相關度評分的函數;Sπ(j)為在置換π中第j個位置的文檔的評分值。
以交叉熵的形式定義損失,優化目標的公式如下:

(2)
3 實 驗
3.1 實驗數據
實驗采用的是微軟亞洲研究院(MSRA)提供的LETOR4.0[19]數據集中的MQ2007和MQ2008兩個數據集。LETOR4.0采用了Gov2的網頁集作為原始數據,使用從百萬查詢跟蹤TERC2007和TERC2008的兩個查詢集,每個查詢有許多相關聯的文檔。其中,每個查詢-文檔對的相關度標注為三個等級(2,1,0),分別對應非常相關、部分相關和不相關。對數據集抽取了基于鏈接、內容等的46個特征。
在實驗過程中,采用了交叉驗證的方法。數據被平分成五份,用S1、S2、S3、S4、S5表示。做五次訓練,再取五次結果的平均數,這樣做可以避免數據過擬合的情況,保證結果的可信度。數據集劃分見表1。
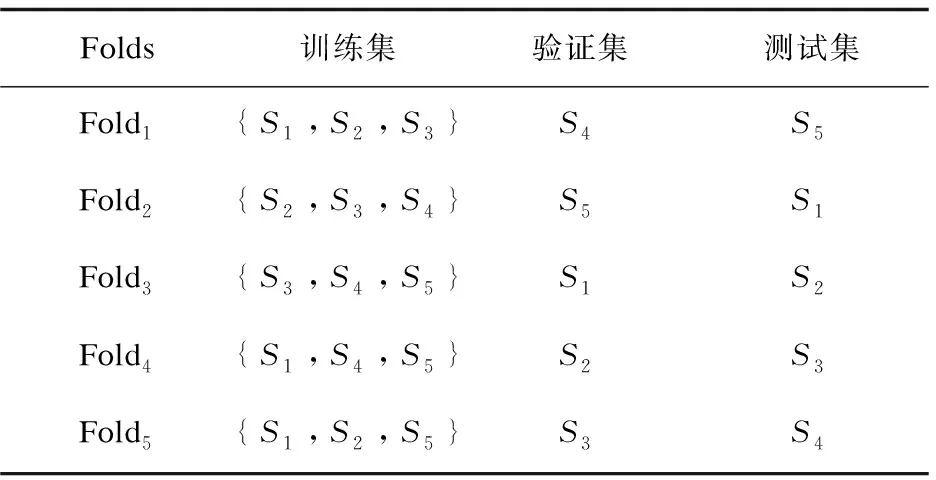
表1 五折交叉驗證數據集劃分
3.2 評測函數
為了衡量排序函數性能的優劣,應用兩種常用的排序性能評測函數:MAP和NDCG@n。
MAP(mean average precision)的衡量標準單一,q與d的關系非0即1,核心是利用q對應的相關的d出現的位置來進行排序算法準確性的評估。系統檢索出來的相關文檔越靠前,MAP值就可能越高。對于一個查詢qi,其平均查準率的計算公式為:
(3)
其中,j表示排序序列的位置;M表示返回的文檔總數;Rj表示第j個查詢的相關文檔數目;precision(j)表示第j個檢索到的文檔的查準率;pos(j)定義為:
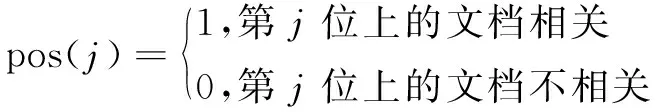
(4)
用NQ表示查詢數量,平均查準率的均值MAP為:
(5)
NDCG(normalized discount cumulative gain)是用來評估排序結果中頂部序列的準確性的評價指標,NDCG的值越高,表示排序結果中的頂部序列的貢獻越大,排序的結果也就越好,可以接受多種相關度的評分。給定查詢qi以及對應的返回文檔序列,其折扣累積增益(DCG)定義為:
(6)
其中,r(j)是第j個文檔的等級,文中n=1,3,5,7,10。
為使不同等級上的搜索結果的得分值容易比較,需要對DCG做歸一化處理,歸一化的DCG值叫做NDCG。計算公式定義為:
(7)
其中,IDCG為理想的DCG,即通過人工對查詢的搜索結果進行排序,排到最好的狀態后,計算得出的這個排列下本查詢的DCG。
3.3 實驗結果及分析
隨著向原始數據集添加PCA處理得到的主特征個數的增加,兩個數據集的MAP值的變化如圖1所示。考慮到模型的訓練時間,這里最多只添加15個主特征。從圖中可以看出,雖然隨著添加個數的增加,MAP值出現了下降的趨勢,但最終的排序效果仍要優于原始的排序結果。
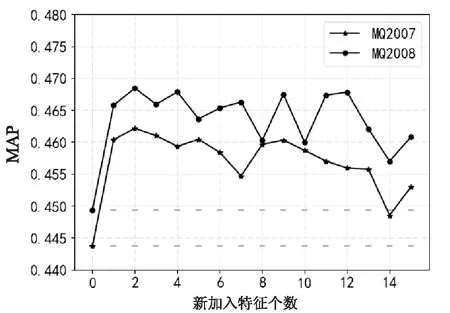
圖1 新加入的特征個數對排序結果的影響
加入較多的PCA主特征向量會增加排序模型的訓練時間,引入較少的特征向量則會因數據特征信息丟失過多導致最終的排序結果改善不明顯。綜合考慮排序效果和模型訓練時間,選擇添加前4位主特征向量。在擴展后的數據集上進行排序算法隱含的特征選擇,隨著新加入特征個數的逐漸增加,排序函數在兩個測試集上的MAP值的變化趨勢如圖2所示。
從圖中可以看出,隨著選擇的特征個數的逐漸增加,查詢集的排序精度并不是一直增高,甚至有所下降,這也驗證了進行特征選擇的必要性。在MQ2007數據集,特征大小為25時,MAP值就達到了特征選擇之前的效果,并趨向于穩定,選擇特征集合的大小為31。MQ2008數據集上的特征大小為7時就達到了特征選擇之前的效果,但波動較大,大小為29之后趨于穩定,選擇特征集合的大小為33。
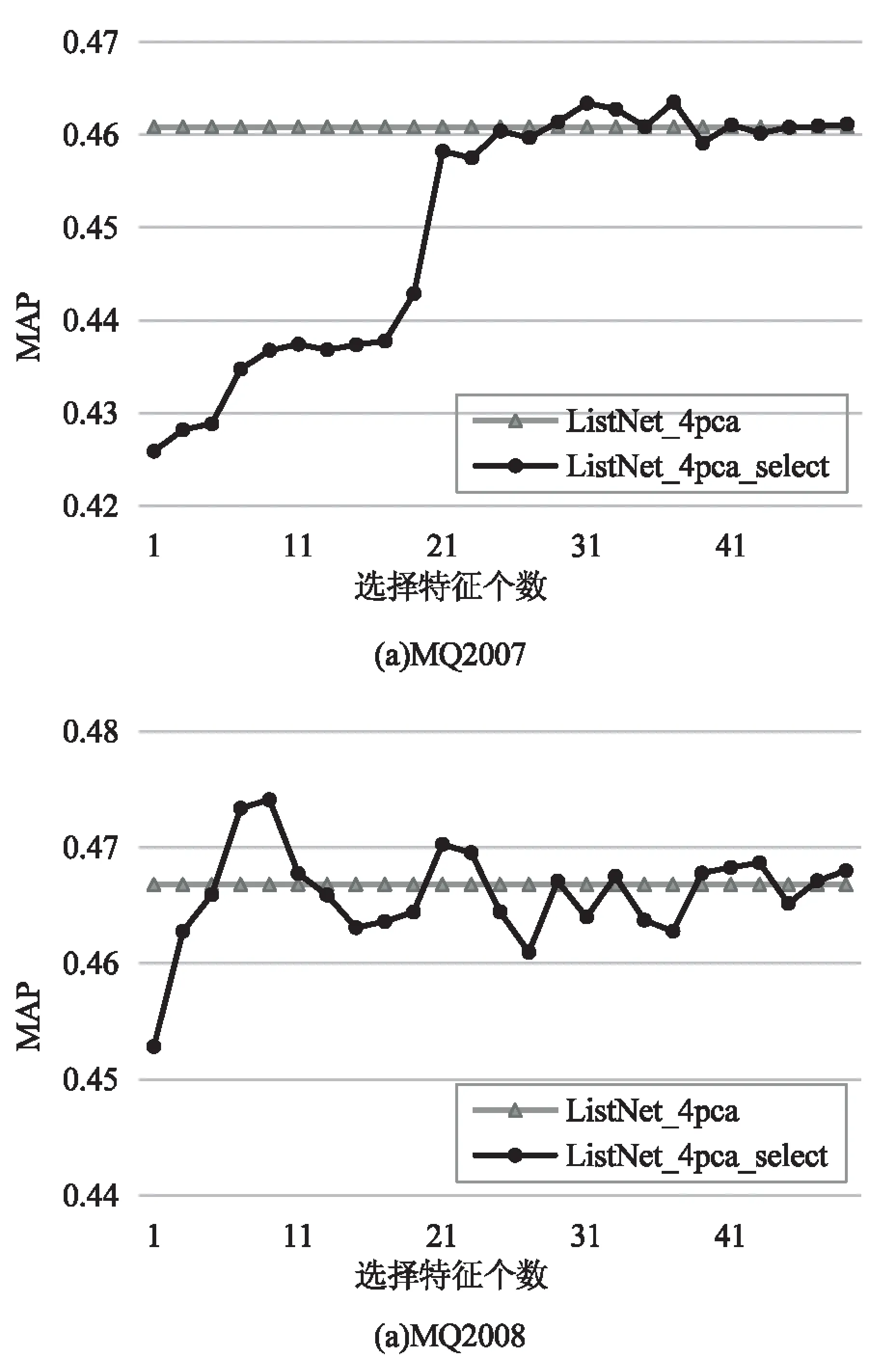
圖2 特征子集的大小對MAP值的影響
確定了要選擇的特征個數,在基于擴展的數據集上進行特征選擇的實驗結果如圖3所示,其中ListNet表示不進行特征處理,ListNet_select表示只進行特征選擇,ListNet_4pca表示只添加前4位主特征向量,ListNet_4pca_select表示在數據集擴展的基礎上進行特征選擇。
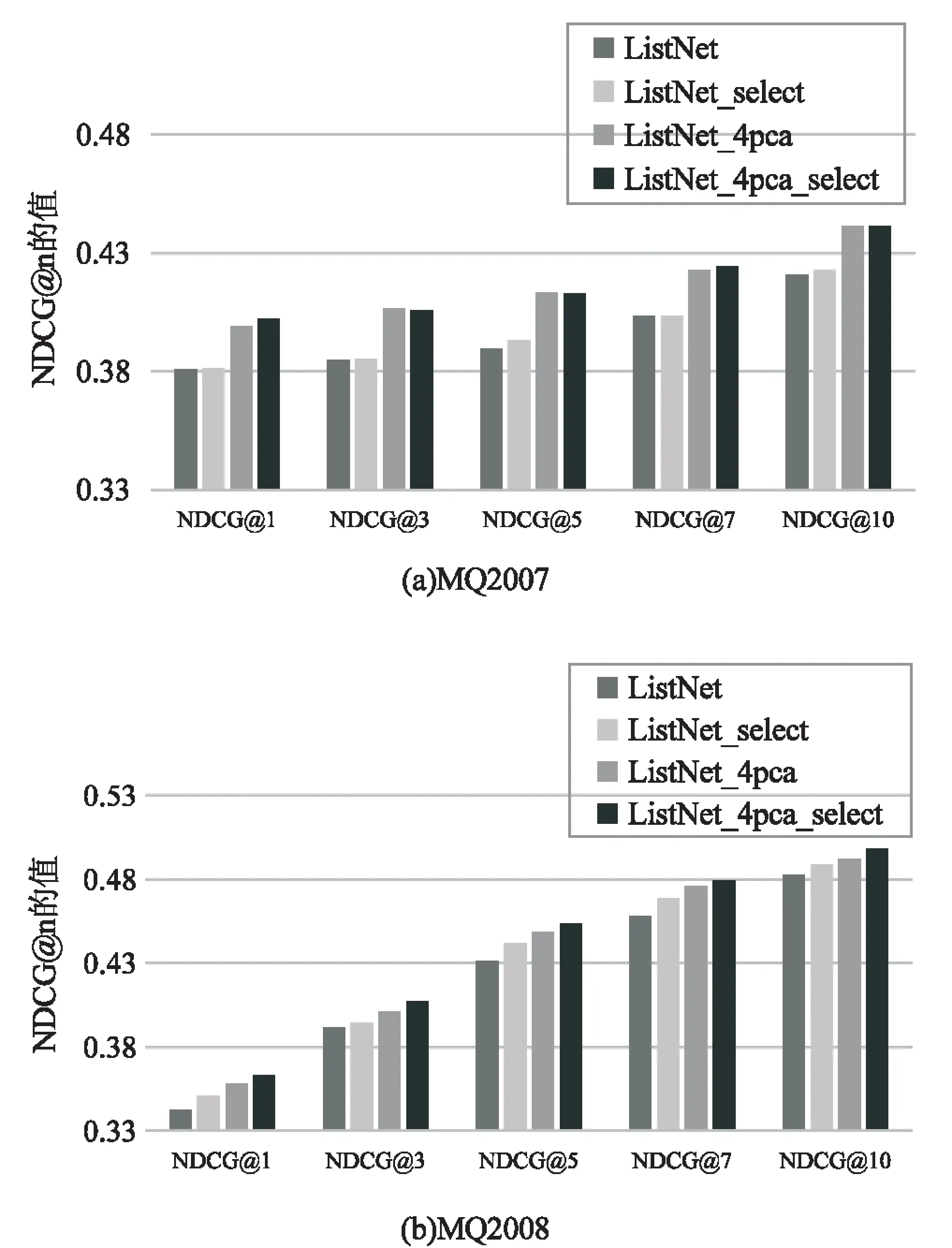
圖3 應用特征選擇的排序結果對比
從圖3可以看出,三種特征處理的方法基本都使排序結果有所提高。在基于PCA特征重組方法擴展后的數據集上進行排序算法隱含的特征選擇之后得到的排序效果總體上是最優的,雖然在MQ2007數據集上NDCG@3的值要略低于特征選擇之前的值,但是顯著優于原始的排序函數得到的效果。
4 結束語
使用特征處理方法對構建排序函數的特征進行處理,并用排序學習算法ListNet進行驗證,實驗結果表明,經過特征處理后,對排序學習的排序結果的提高有積極意義。
在特征選擇算法中一個很難解決的問題是什么樣的特征子集是最優的。希望用盡量少的特征,得到最好的輸出結果。文中沒有對選擇的特征子集的大小做分析,只是簡單地增加選擇的特征個數。在后面的工作中,將繼續研究如何在特征數和輸出精度中得到一個很好的平衡。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
