深度神經網絡壓縮與加速綜述
2018-09-21 03:32:58紀榮嶸林紹輝吳永堅黃飛躍
計算機研究與發展 2018年9期
紀榮嶸 林紹輝 晁 飛 吳永堅 黃飛躍
1(廈門大學信息科學與技術學院 福建廈門 361005) 2(福建省智慧城市感知與計算重點實驗室(廈門大學) 福建廈門 361005) 3(上海騰訊科技有限公司優圖實驗室 上海 200233)(rrji@xmu.edu.cn)
近年來,隨著GPU的快速發展及大數據時代的來臨,深度神經網絡(deep neural networks, DNNs)已席卷人工智能各個領域[1],包括了語音識別[2]、圖像理解[3-5]、自然語言處理[6]等在內的廣泛領域.不僅如此,這些深度神經網絡在復雜的系統中也得到了廣泛使用,如自動駕駛[7]、癌癥檢測[8]、復雜游戲的策略搜索[9]等.深度神經網絡在很多識別任務中已大大超越了人類識別的準確率,同時突破了傳統的技術方法(如手工設計的(hand-crafted)特征SIFT[10]和HOG[11])帶來的巨大的性能提升.這些性能的提升是因為深度神經網絡擁有對大數據高層(high-level)特征提取的能力,從而獲得對輸入空間或數據的有效表示.另外,相比傳統在CPU平臺上的計算,強大的GPU計算能力大大提高了深度神經網絡的計算效率,使得模型的訓練速度得到大幅度提升.如果能將計算平臺小型化,即把深度神經網絡強大的識別性能移植到移動嵌入式設備中(如手機、機器人、無人機、智能眼鏡等),這樣不管在軍事方面的搶險救災、敵情勘探,還是在民事方面的移動智能識別、便民出行等都起到重大的促進作用.
伴隨著深度神經網絡模型的性能增加,神經網絡的深度越來越深,接踵而來的是深度網絡模型的高存儲高功耗的弊端,嚴重制約著深度神經網絡在資源有限的應用環境和實時在線處理的應用,特別是智能化移動嵌入式設備、現場可編程門陣列(field-programmable gate array,FPGA)等在線學習和識別任務.例如8層的AlexNet[3]裝有600 000個網絡節點、0.61億個網絡參數,需要花費240 MB內存存儲和7.29億浮點型計算次數(FLOPs)來分類一副分辨率為224×224的彩色圖像.同時,隨著神經網絡模型深度的加深,存儲的開銷將變得越大.同樣來分類一副分辨率為224×224的彩色圖像,如果采用擁有比8層AlexNet更多的16層的VGGNet[12],則有1 500 000個網絡節點、1.44億個網絡參數,需要花費528 MB內存存儲和150億浮點型計算次數;ResNet-152[13]裝有0.57億個網絡參數,需要花費230 MB內存存儲和113億浮點型計算次數.對于移動終端設備、FPGA等弱存儲、低計算能力特點,無法直接存儲和運行上述如此龐大的深度網絡.
一方面,擁有百萬級以上的深度神經網絡模型內部存儲大量冗余信息,因此并不是所有的參數和結構都對產生深度神經網絡高判別性起作用;另一方面,用淺層或簡單的深度神經網絡無法在性能上逼近百萬級的深度神經網絡.因此,通過壓縮和加速原始深度網絡模型,使之直接應用于移動嵌入式設備端,將成為一種有效的解決方案.
一般情況下,壓縮和加速深度神經網絡是2個不同的任務,兩者之間存在區別,但又緊密聯系.例如卷積神經網絡(convolutional neural networks,CNNs)分2種類型的計算層,即卷積層和全連接層.1)卷積層,它是計算耗時最大的層,也是卷積神經網絡能夠獲得高層語義信息重要層.在卷積層內,可以通過權值共享,減少了對權值的大量存儲.2)全連接層,不同于卷積層的局部感知,在全連接層中,每一個輸出單元都與所有輸入單元相關,通過密集的權值進行連接,因此需要大量的參數.因為卷積層與全連接層內在的本質區別,通常把卷積層的計算加速和全連接層的內存壓縮認為是2種不同的任務.這2類計算層之間又是緊密聯系的,卷積層為全連接層提供分層的高層特征,全連接層通過分類指導卷積層的高判別力特征提取.在本文中,我們總結與回顧近幾年來壓縮和加速深度神經網絡方面的相關工作,相關算法與解決方案涉及多門學科,包括機器學習、參數優化、計算架構、數據壓縮、索引、硬件設計等.
主流的壓縮與加速神經網絡的方法可以分成5種:1)參數剪枝(parameter pruning);2)參數共享(parameter sharing);3)低秩分解(low-rank decom-position);4)緊性卷積核的設計(designing compact convolutional filters);5)知識蒸餾(knowledge dis-tillation).參數剪枝主要通過設計判斷參數重要與否的準則,移除冗余的參數.參數共享主要探索模型參數的冗余性,利用Hash或量化等技術對權值進行壓縮.低秩分解利用矩陣或張量分解技術估計并分解深度模型中的原始卷積核.緊性卷積核的設計主要通過設計特殊的結構化卷積核或緊性卷積計算單元,減少模型的存儲與計算復雜度.知識蒸餾主要利用大型網絡的知識,并將其知識遷移到緊性蒸餾的模型中.
如表1所示,簡要介紹了上述主流的5種壓縮與加速深度神經網絡的方法,一般來說,除了緊性卷積核的設計只能用于卷積核外,剩余的4種均能應用于卷積層和全連接層.低秩分解與緊性卷積核的設計能夠在CPU/GPU下簡單實現端對端(end-to-end)訓練,然而參數共享、參數剪枝需要多步或逐層完成壓縮與加速任務.關于訓練過程中是否需要重新開始訓練還是依賴于預訓練模型的問題上,參數共享、低秩分解都較為靈活有效,既能適應重新訓練也能適應于預訓練模型.然而緊性卷積核的設計和知識蒸餾只能支持重新訓練,另外參數剪枝只能依賴于預訓練模型.從上述方法能否相應組合方面,緊性卷積核的設計方法和知識蒸餾還不能結合其他方法,參數剪枝與參數共享或低秩分解方法結合甚密,通過2種方法的互相融合,能夠在一定程度進一步壓縮與加速深度網絡.
在本文中,主要集中分析在圖像處理中的卷積神經網絡的壓縮與加速,特別是對于圖像分類任務.本文先回顧近年來較為經典的深度神經網絡,然后詳細介紹上述壓縮與加速方法、相應的特性及缺點,進而分析深度模型壓縮與加速的評測標準、相應數據集及性能表現,最后總結并討論不同壓縮與加速方法的選擇問題,并分析了未來發展趨勢.
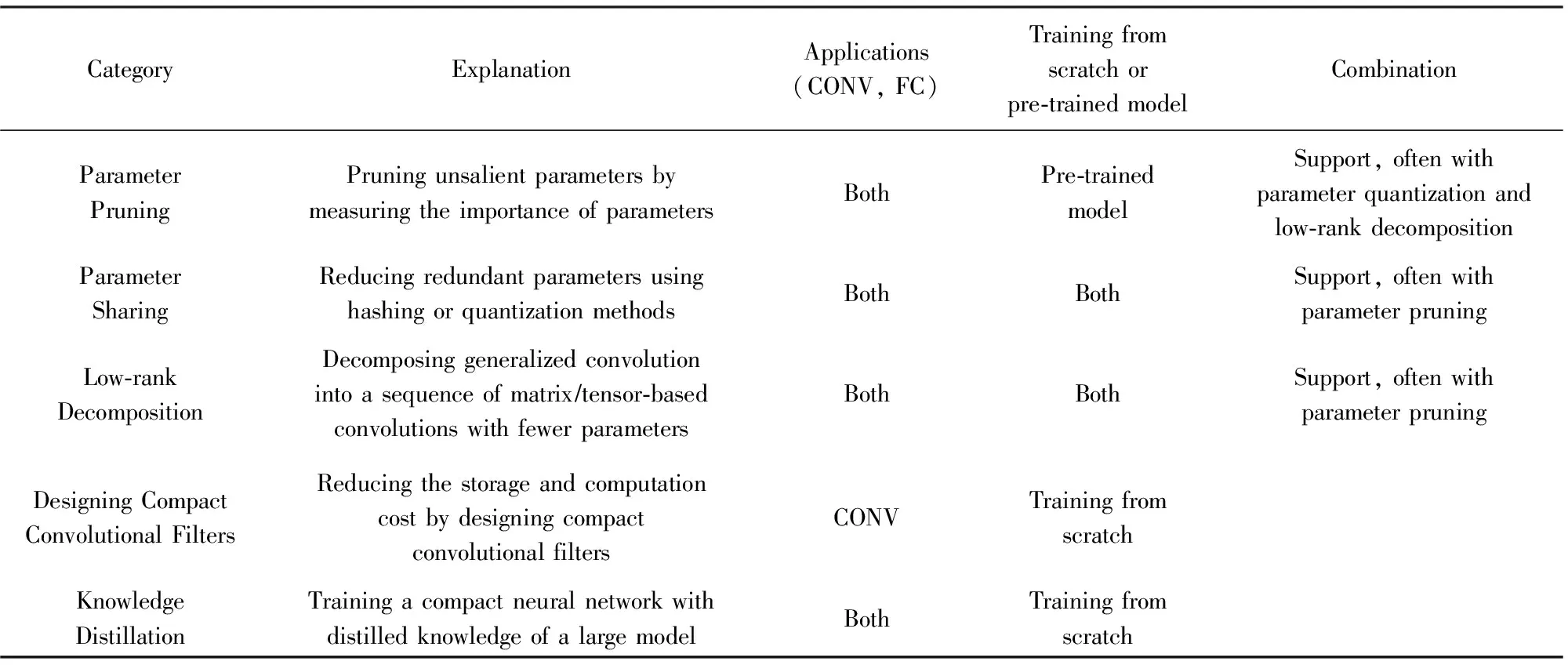
Table 1 Summarization of Different Methods for DNN Compression and Acceleration表1 不同深度神經網絡壓縮與加速方法總結
1 深度神經網絡相關概念與回顧
在本節中,我們主要介紹了深度神經網絡的發展歷史,以及深度神經網絡中前饋網絡(feed forward networks)代表卷積神經網絡的核心組件和經典網絡模型.
1.1 深度神經網絡發展歷史
雖然20世紀40年代神經網絡已經被提出,但一直沒能得到實踐應用,直到20世紀90年代,LeCun等人提出了LeNet模型[14],并成功地將該模型用于手寫體字符識別任務上,后續在ATM機上得到了廣泛的應用.在此之后神經網絡發展遇到瓶頸,直到2006年,Hinton等人[15]提出了一種有效的訓練深度神經網絡的策略,不僅提升了模型的準確率,同時還極大地推動了非監督學習的發展.到了2010之后,深度神經網絡得到了廣泛的應用,特別是2011年微軟公司的語音識別系統[2]突破了傳統語音識別技術及2012年AlexNet[3]的問世給整個圖像識別領域帶來了巨大突破,也使得深度神經網絡席卷整個人工智能領域埋下伏筆.如表2所示,簡要總結了深度學習的重要發展里程碑.
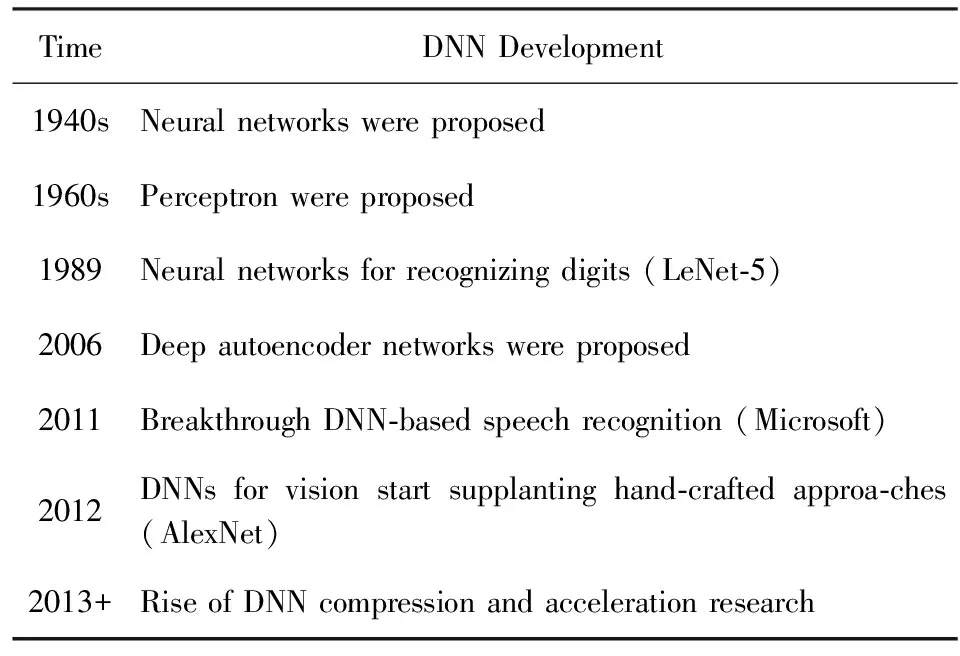
Table 2 The Development History of DNN表2 深度神經網絡的發展歷史
深度學習技術之所以能夠在近幾年來取得巨大突破,主要有2個原因:
1) 硬件設備計算能力的增強.半導體設備和計算架構的提高(如GPU),大大縮短網絡計算的時間開銷,包括訓練(training)過程與推測過程(inference).
2) 訓練數據集的不斷擴充.如圖1所示,表示了不同時期公共數據集的數據規模.從圖1中可以看出,2010年之前數據量規模停留在萬級及以下,到了2010年之后大規模數據集的公開與使用,特別是大規模圖像識別比賽(ILSVRC)[17]的成功舉辦,ImageNet數據集[18]得到廣泛的使用,給深度神經網絡提高了數據支持,也使得擁有百萬級以上參數的深度網絡訓練不易出現過擬合問題(overfitting).
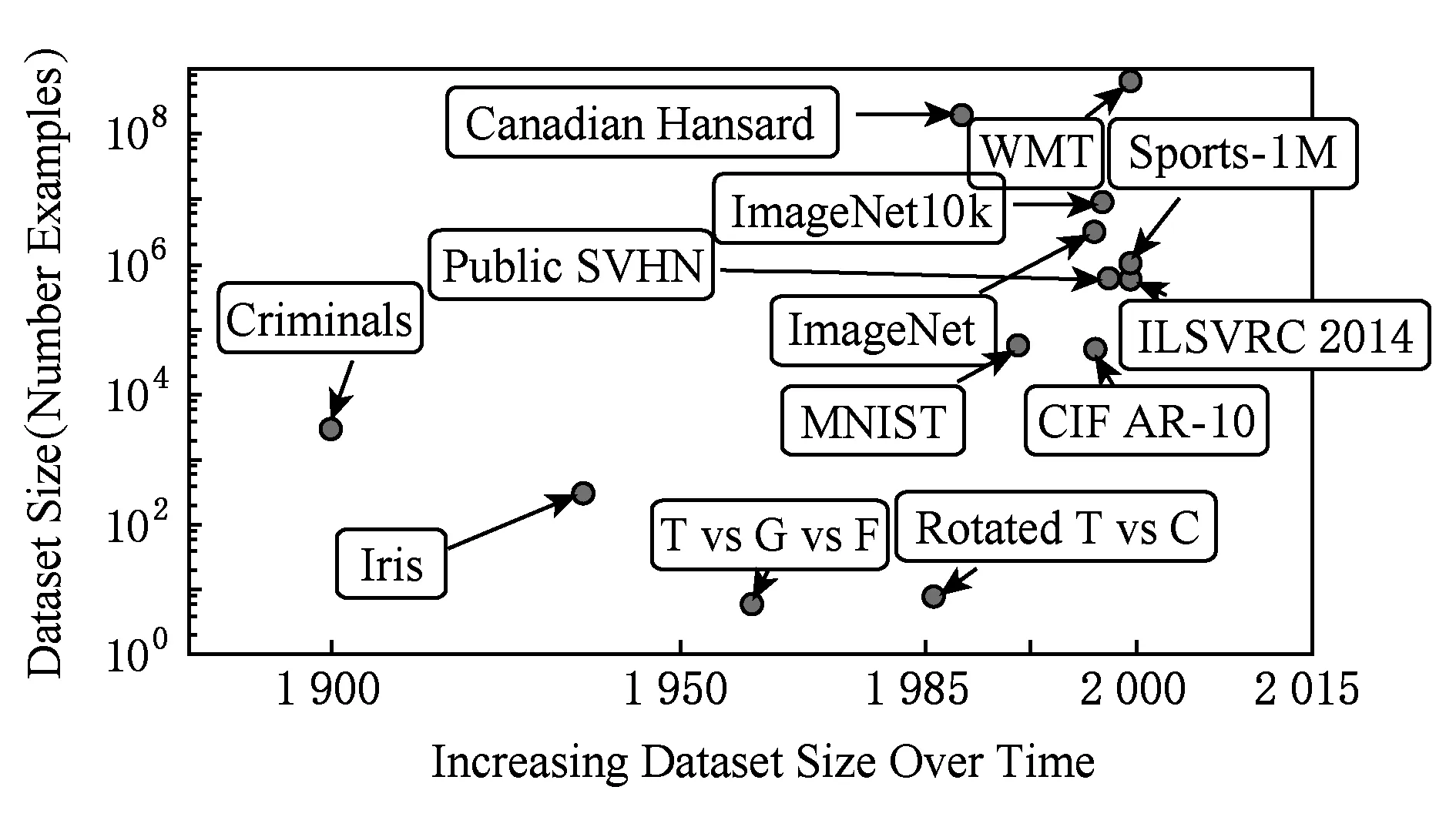
Fig.1 The number of public training dataset over different years[16]圖1 不同時期公共訓練數據集的規模
結合以上2個原因,深度學習在各個人工智能領域大放異彩,特別在圖像識別領域表現更加出眾.如圖2所示,描述了在ILSVRC上的最好識別性能及所用的網絡模型對比.一方面,在2012年以前,所用的模型采用淺層網絡表示(如支持向量機(SVMs)),獲得25%及以上的識別誤差率;2012年,AlexNet利用深度學習技術將分類錯誤率較原來的淺層模型降低了近10%.自此以后,深度學習技術成為提高性能的主流與趨勢.特別是2016年,何凱明等人[13]提出了ResNet,獲得了3.57%的top-5分類錯誤率(errtop-5),成功超越了人類所能達到的5%的分類錯誤率.另一方面,隨著分類錯誤率逐年降低,深度網絡模型的層數越來越深,模型存儲量大、計算復雜度高也越發明顯,這觸發了工業界及學術界對深度網絡壓縮與加速的關注與研究.
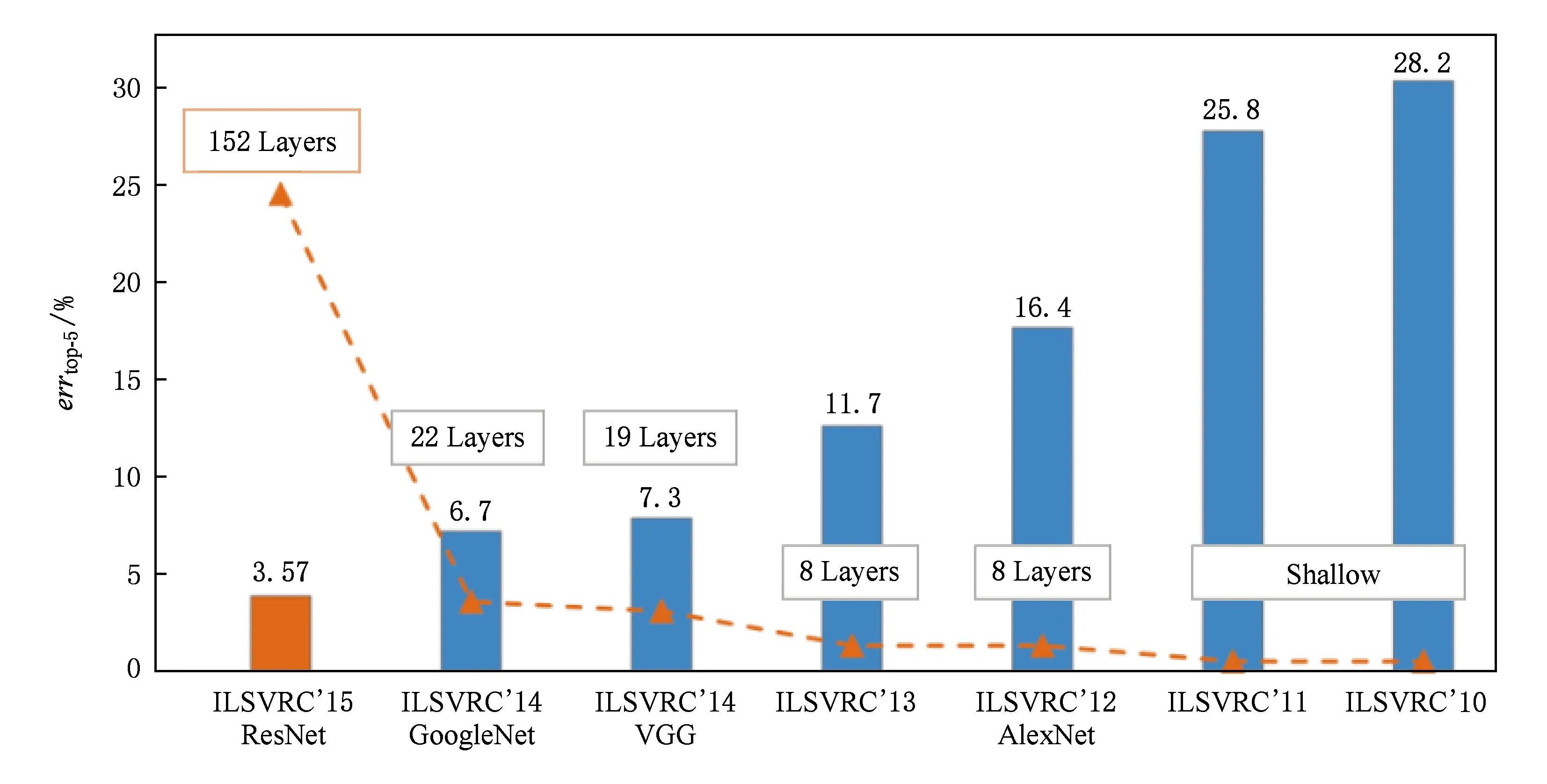
Fig.2 Comparison of the best performance over different years using various CNNs in ILSVRC[9]圖2 不同年份ILSVRC上的最好性能及所用的網絡模型對比
1.2 卷積神經網絡的相關術語及核心部件
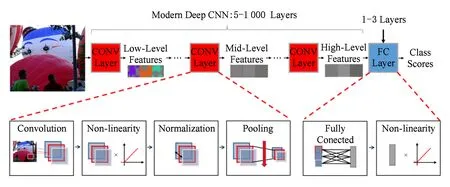
Fig.3 Convolutional neural networks圖3 卷積神經網絡
卷積神經網絡由多個卷積層(CONV layers)和全連接層(FC layers)組合而成.如圖3所示,在該網絡卷積層中,每層產生了對輸入圖像的高層抽象表示的結果,稱之為特征圖(feature map,Fmap).底層的特征圖能夠獲得輸入圖像的細節信息(如邊緣、角點、顏色等),越往頂層越能獲得輸入圖像的整體信息(如形狀、輪廓等),正是卷積神經網絡利用了此分層特性,取得了很好的性能提升.
如圖4所示,顯示了每個卷積層包含了復雜的高維卷積計算.輸入中包含了一些列的2-D輸入特征圖(input feature maps,IFmaps),其中每一個特征圖稱之為通道(channel).每一個輸出特征圖(output feature maps,OFmap)是由所有的輸入特征圖與3-D卷積核/濾波(filter)卷積計算的結果,每一個3-D卷積核形成一個輸出特征圖.
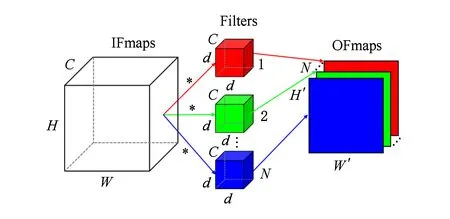
C,H,W,D,N,H′ and W′ are defined in Equation (1).Fig.4 High-dimension convolutional operator圖4 高維卷積計算
具體地,計算過程可以用表示為
(1)
在全連接層中,不像卷積層的權值共享,全連接層的輸入與輸出之間存在密集連接(dense connec-tion),需要保存大量訓練參數.其中核心的計算單元是矩陣與矩陣之間的乘法,具體可由式表示:
Z=WX,
(2)
其中,X∈d×b為輸入矩陣,W∈h×d為權值,Z∈h×b為輸出矩陣.一般情況下,若將全連接層中的權值變量變換成卷積核空間4階張量形式,并將空間維度設為1×1,那么全連接的矩陣計算可以轉換成卷積計算.
另外,在卷積層與全連接層中還存在許多可選層及一些其他重要操作,如非線性變換(non-linearity)、池化(pooling)、正則化(normalization)等,對于網絡性能的提升起到非常重要的作用.
1.3 經典的深度神經網絡模型
在過去的幾十年里,已經提出了很多經典的深度神經網絡模型,每個模型擁有不同的網絡結構,主要體現在層數、層類型、層形狀(即卷積核大小、通道及濾波個數)、層內連接等.在本節中,我們回顧近幾年在ImageNet競賽上使用的冠軍模型以及手寫體字符識別網絡模型LeNet.這些預訓練模型(pre-trained model)都已公開,模型的相關參數與總結如表3所示.第1行的top-1分類錯誤率(errtop-1)和第2行的top-5分類錯誤率errtop-5均為ImageNet競賽上常用的2個分類評價指標,所有數值均采用簡單的裁剪驗證集(validation dataset)圖像中間部分作為輸入,得到分類的結果.本文將對LeNet[14],AlexNet[3],VGGNet[12],GoogLeNet[22]和ResNet[13]進行介紹.
1) LeNet[14].在1998年LeNet作為最早使用的卷積神經網絡之一,被LeCun等人提出用于識別手寫體字符.作為經典的版本——LeNet-5包含了2個卷積層和2個全連接層.每1層的卷積計算都使用了5×5的空間維度,第1層使用了20個3-D卷積核,第2層使用50個卷積核.每個卷積之后加入Sigmoid非線性變換作為激活函數,然后接著使用2×2的平均池化(average pooling)降采樣特征圖.整個網絡分類1張圖像總共需要6萬個參數、34.1萬浮點型計算次數.LeNet是第1個被成功應用的卷積神經網絡,它被廣泛使用在ATM機上,應用于支票存款任務中識別手寫體字符.
2) AlexNet[3].它是ImageNet競賽上第1個利用深度學習獲得冠軍的卷積神經網絡,同時該模型也為后續的深度學習的廣泛應用奠定堅實的基礎.該模型由5個卷積層和3個全連接層組成.第1個卷積層使用了96個維度為11×11×3的3-D卷積核,第2層使用了256個維度為5×5×96的3-D卷積核,后續的卷積層使用了空間維度為3×3的卷積核.AlexNet引入了多種加速訓練與提高模型分類準確率的技巧,如:①引入了ReLU非線性激活函數[20],代替原始的Sigmoid或tahn非線性激活[21].②在每個最大池化(max pooling)之前加入局部響應正則化(local response normalization,LRN),用于統一輸出激活的數據分布.在AlexNet中,LRN應用于第1,2和5卷積層.③利用2個GPU加速訓練.④通過擴充訓練樣本數和引入Dropout方法,防止模型訓練過程過擬合.AlexNet在ImageNet 驗證集上獲得了42.3% top-1分類錯誤率和19.1% top-5分類錯誤率,且需要0.61億個參數、7.29億浮點型計算次數處理尺寸大小為227×227的彩色圖像.
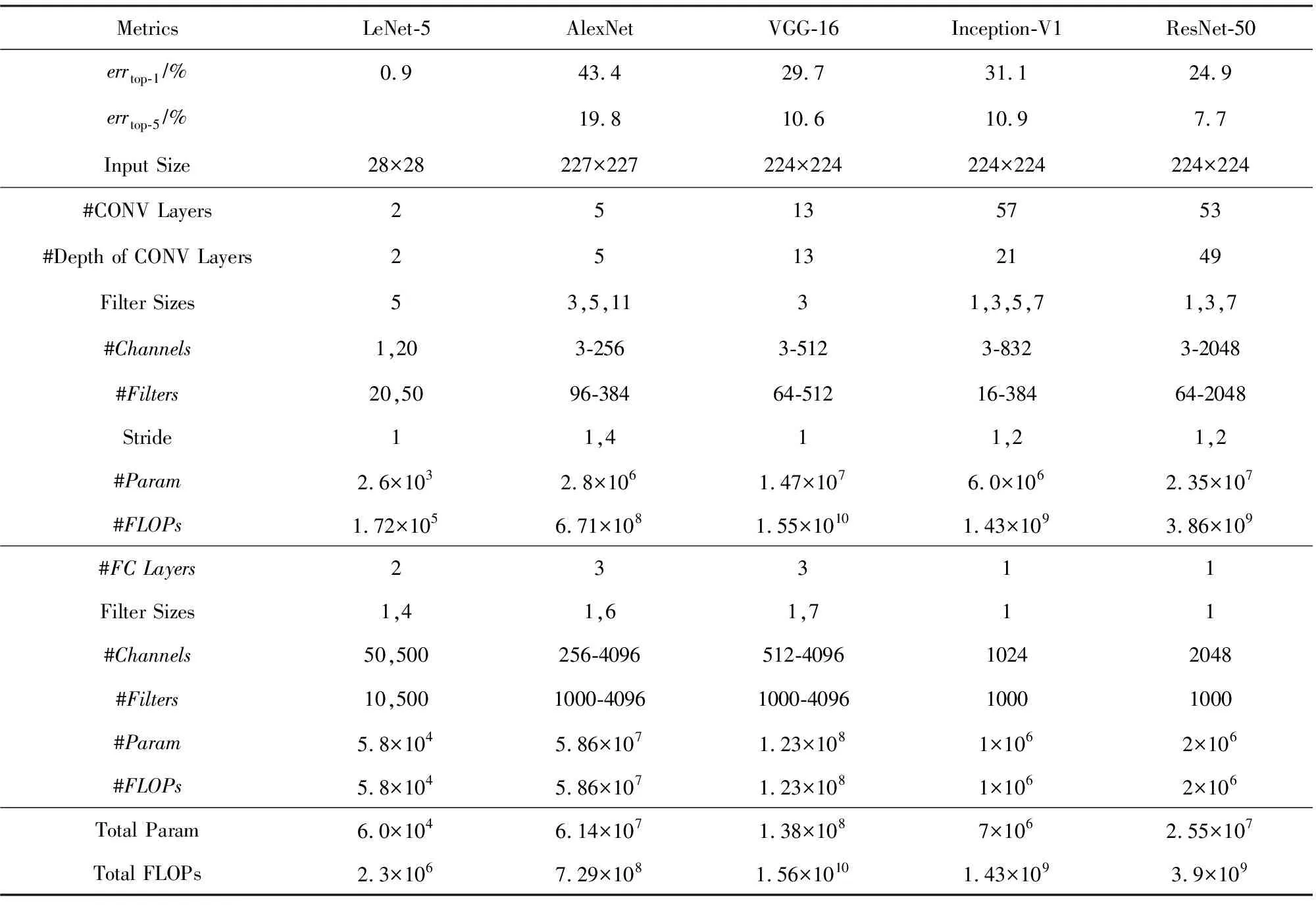
Table 3 Summary of Popular DNNs[19]表3 常用深度神經網絡的總結[19]
3) VGGNet[12].它取得了2014年ImageNet競賽的分類項目第2名、定位項目第1名.VGGNet擁有強拓展性,體現在由很強的泛化能力、穩定的卷積特征和較好的表達能力.具體而言,VGGNet有2種形式,即VGG-16和VGG-19.VGG-16由13個卷積層和3個全連接層構成的16層網絡.不同于AlexNet,VGG-16利用多個小空間維度的卷積核(例如3×3)代替原始大的卷積核(例如5×5),獲得相同的接受域(receptive fields).在VGG-16中,所有的卷積層都采用了空間維度為3×3的卷積核.為此,VGG-16分類1張大小為224×224的彩色圖像,需要1.38億個參數、156億浮點型計算次數.雖然VGG-19比VGG-16低0.1% top-5分類錯誤率,但需要1.27倍浮點型計算次數于VGG-16.
4) GoogLeNet[22].它取得了2014年ImageNet競賽的分類項目的冠軍.Inception擁有多種版本,包括Inception-V1[22],Inception-V3[23]和Inception-V4[24]等,其中Inception-V1也稱為GoogLeNet.我們詳細介紹Inception-V1,它擁有22層深的網絡結構,引入了核心組件——Inception module.如圖5所示,展示了Inception module主要組成部件,它由平行連接(parallel connection)構成.在每個平行連接中,使用了不同空間維度的卷積核,即1×1,3×3,5×5,并在每個卷積后緊跟3×3最大池化(其中一個1×1卷積核除外),所有卷積核輸出結果全串在一起(concatenate)構成該模塊的輸出.GoogLeNet利用3種不同的尺度卷積和最大池化,增加網絡對不同尺度的適應性,同時可以讓網絡的深度和寬度高效率地擴充,提升準確率且不會過擬合.22層的GoogLeNet包括了3個卷積層、9個Inception層(每個Inception層擁有2層深的卷積層)和1個全連接層.由于采用了全局平均池化[23](global average pooling, GAP),并采用1個全連接層取代傳統的3個全連接層,大大縮小了模型的存儲空間.對于分類一張224×224的彩色圖像,GoogLeNet需要700萬個參數、14億浮點型計算次數.

Fig.5 Inception module in GoogLeNet圖5 GoogLeNet的Inception模塊
5) ResNet[13].它是首次在ImageNet競賽上超過人類所能達到的識別精度(即低于5% top-5分類錯誤率).ResNet能夠克服訓練過程中梯度消失問題,即在反向傳播(back-propagation)中梯度不斷衰減,影響了網絡底層的權值更新能力.如圖6所示,ResNet的核心組件是殘差塊(residual block),每個殘差塊中引入了快捷模塊(shortcut module),該模塊包含了恒等連接或線性投影連接,并且學習殘差映射(F(x)=H(x)-Wsx),而不是直接學習權值層(weight layers)函數F(x).同樣地,ResNet使用了1×1卷積核減少參數個數,并在每個卷積后加入批量正則化[22](batch normalization,BN).ResNet有很多種結構表現形式,以ResNet-50為例,它包含了1個卷積層,緊接著16個殘差塊(每個殘差塊擁有3層深的卷積層),及1個全連接層.對于分類一張224×224的彩色圖像,ResNet-50需要0.25億個參數和39億浮點型計算次數.
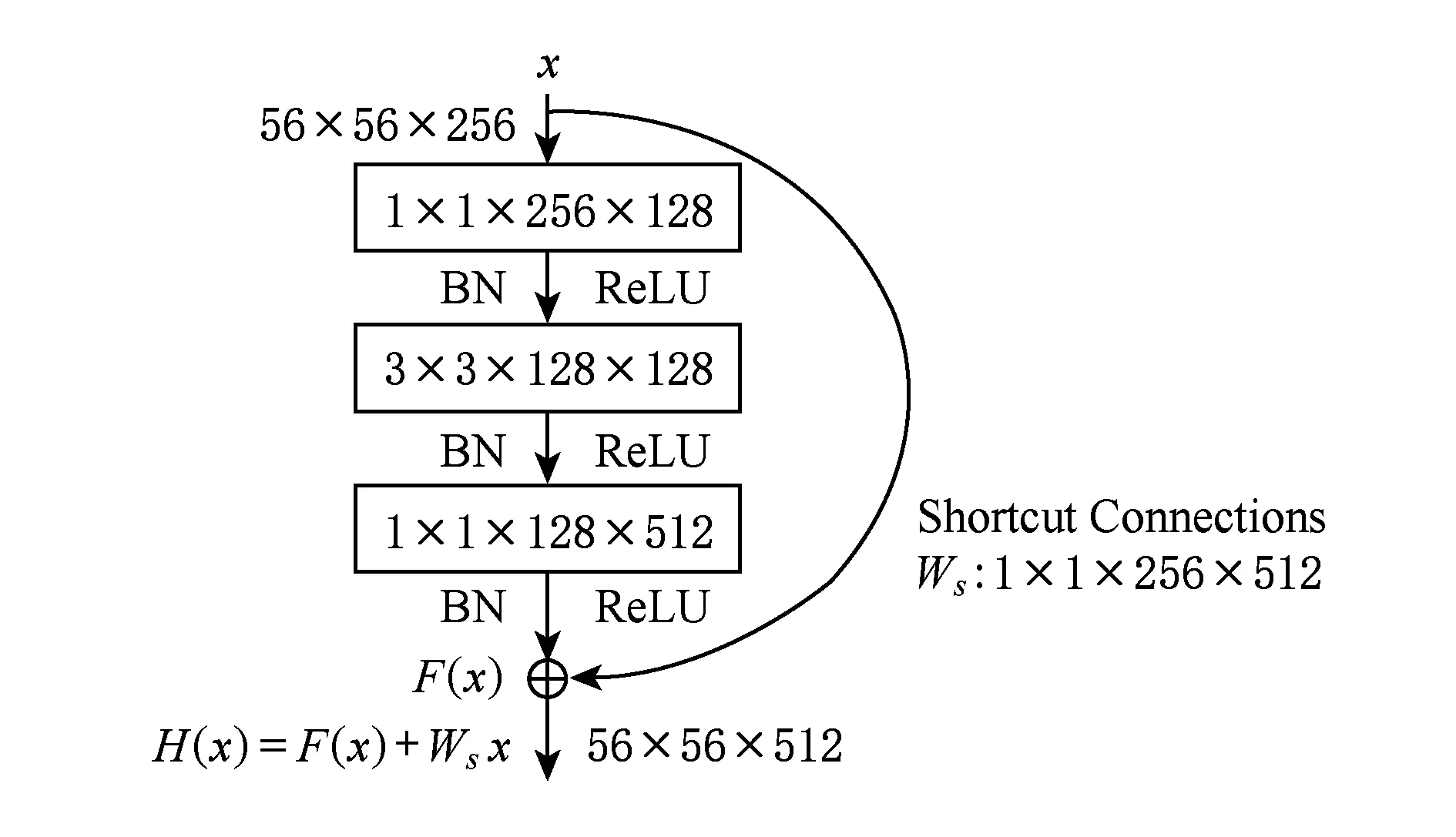
Fig.6 Residual block in ResNet圖6 ResNet的殘差塊
如表3和圖2所示,隨著模型的深度和寬度的增加,深度網絡取得更好的性能提升,但是卷積層的高度復雜的浮點計算及全連接層的高內存存儲,嚴重阻礙深度模型應用于移動設備端.因此,壓縮與加速深度神經網絡將愈發重要.
2 深度神經網絡壓縮與加速算法
在本節中,我們主要介紹了主流深度神經網絡壓縮與加速算法,以及相關算法的優缺點.
2.1 基于參數剪枝的深度神經網絡壓縮與加速
網絡/參數剪枝是通過對已有的訓練好的深度網絡模型移除冗余的、信息量少的權值,從而減少網絡模型的參數,進而加速模型的計算和壓縮模型的存儲空間.不僅如此,通過剪枝網絡,能防止模型過擬合.以是否一次性刪除整個節點或濾波為依據,參數剪枝工作可細分成非結構化剪枝和結構化剪枝.非結構化剪枝考慮每個濾波的每個元素,刪除濾波中元素為0的參數,而結構化剪枝直接考慮刪除整個濾波結構化信息.
早在20世紀末,LeCun等人[27]提出了最優化腦損失(optimal brain damage)算法,大大稀疏化多層網絡的系數,同時保證模型預測精度依然處于零損失或最小量損失狀態.其實這種學習方式模仿了哺乳動物的生物學習過程,通過尋找最小激活的突觸鏈接,然后在突觸刪減(synaptic pruning)過程中大大減少連接個數.利用相似的思想,Hassibi 和Stork[28]提出了最優化腦手術(optimal brain surgeon)剪枝策略,利用反向傳播計算權值的二階偏導信息(hessian矩陣),同時利用此矩陣構建每個權值的顯著性得分,從而刪除低顯著性的權值.不同于最優化腦手術剪枝策略,Srinivas等人[29]提出了不依賴于訓練數據(data-free pruning)和反向傳播,直接構建并排序權重的顯著性矩陣,刪除不顯著冗余的節點.由于不依賴于訓練數據及后向傳播計算梯度信息,因此該網絡剪枝過程較為快速.韓松等人[30-31]提出了一種基于低值連接的刪除策略(low-weight con-nection pruning),該剪枝方法包括3個階段,即訓練連接、刪除連接、重訓練權值.第1階段通過正常訓練,學習重要的連接;第2階段通過計算權值矩陣的范數,刪除節點權重的范數值小于指定的閾值的連接,將原始的密集網絡(dense network)變成稀疏網絡;第3階段通過重新訓練稀疏網絡,恢復網絡的識別精度.以上剪枝方法通常引入非結構化的稀疏連接,在計算過程中會引起不規則的內存獲取,相反會影響網絡的計算效率.
近幾年,基于結構化剪枝的深度網絡的壓縮方法陸續被提出,克服了非結構化稀疏連接導致的無法加速問題[27-31].其核心思想依靠濾波顯著性準則(即鑒定最不重要的濾波的準則),從而直接刪除顯著性濾波,加速網絡的計算.2016年,Lebedev等人[32]提出在傳統的深度模型的損失函數中加入結構化的稀疏項,利用隨機梯度下降法學習結構化稀疏的損失函數,并將小于給定閾值的濾波賦值為0,從而測試階段直接刪除值為0的整個卷積濾波.溫偉等人[33]通過對深度神經網絡的濾波、通道、濾波形狀、網絡層數(filters, channels, filter shapes, layer depth)的正則化限制加入到損失函數中,利用結構化稀疏學習的方式,學習結構化的卷積濾波.Zhou等人[34]將結構化稀疏的限制加入目標函數中,并利用前向后項分裂(forward-backward splitting)方法解決結構稀疏化限制的優化問題,并在訓練過程中直接決定網絡節點的個數與冗余的節點.另外,近年來,直接測量濾波的范數值直接判斷濾波的顯著性也相繼被提出[35],例如:直接刪除給定當前層最小L1范數的濾波,即移除相應的特征圖(feature map),然后下一層的卷積濾波的通道數也相應地減少,最后通過重訓練的方式提高刪減后模型的識別精度.由于大量的ReLU非線性激活函數存在于主流的深度網絡中,使得輸出特征圖高度稀疏化,Hu等人[36]利用此特點,計算每個濾波所對應輸出特征圖的非零比例,作為判斷濾波重要與否的標準.NVIDIA公司Molchanov等人[37]提出一種基于全局搜索顯著性濾波的策略,對需要刪除的濾波用0值代替,并對目標函數進行泰勒公式展開(taylor expansion),判斷使目標函數變換最小的濾波為顯著濾波.通過卷積計算方式,可以建立當前層的濾波與下一層的卷積濾波的輸入通道存在一一對應關系,利用此特點Luo等人[38]探索下一層卷積核的輸入通道重要性,代替直接考慮當前層濾波,并建立一個有效的通道選擇優化函數,從而刪除冗余的通道以及相應的當前層的濾波.以上基于結構化剪枝的深度網絡的壓縮方法,通過刪除卷積層的整個濾波,沒有引入其他額外的數據類型存儲,從而直接壓縮網絡的同時加速整個網絡的計算.
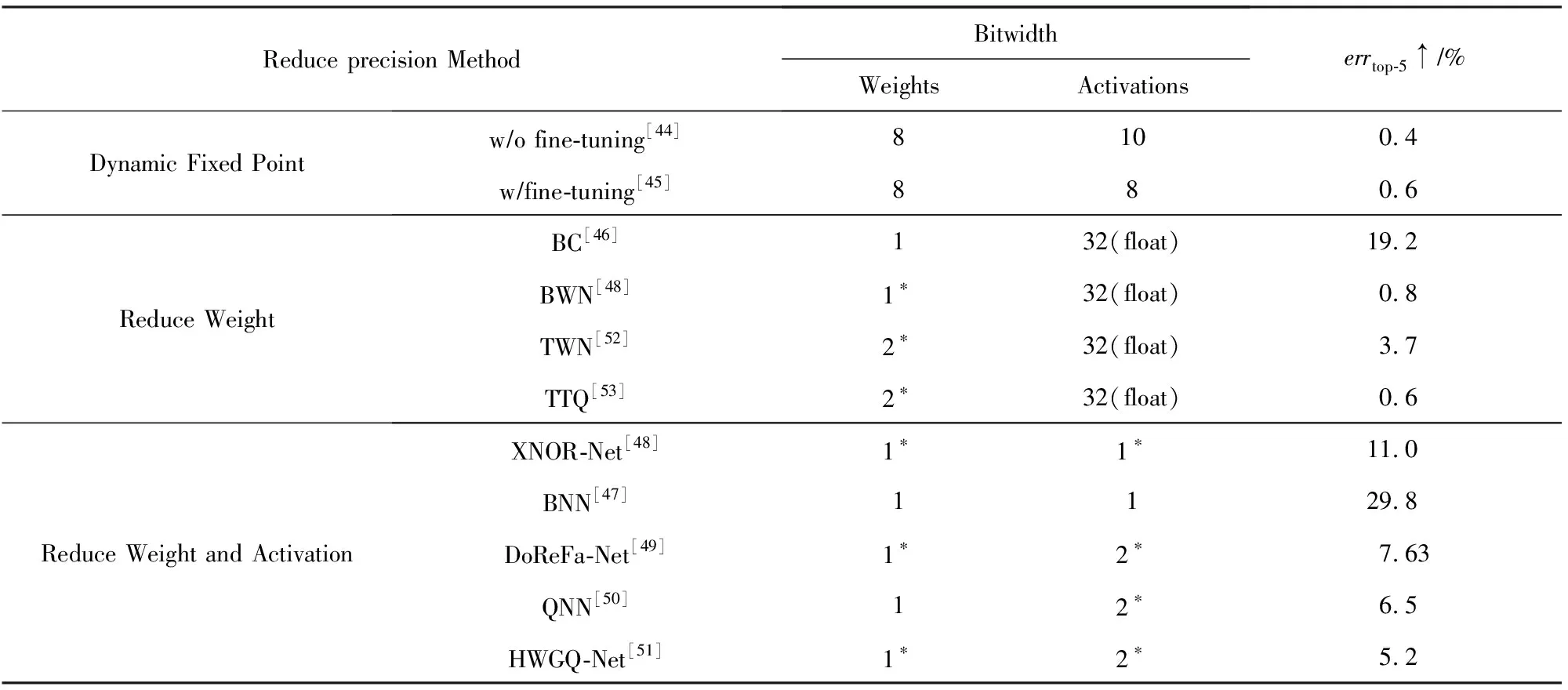
Table 4 Comparison of Methods to Reduce Precision on AlexNet[19]表4 不同量化方法在AlexNet上的對比[19]
Notes: “*” denotes the method is not applied to first and/or last layers, and “↑” denotes increase.
參數剪枝的缺點在于,簡單利用非結構化剪枝,無法加速稀疏化矩陣計算.雖然近年來,相關軟件[39]與硬件[40]已被利用進行加速計算,但依靠軟硬件的非結構化剪枝方案還無法在所有深度學習框架下使用,另外硬件的依賴性會使得模型的使用成本提高.結構化剪枝不依賴軟硬件的支持,且能很好地嵌入目前主流的深度學習框架,但逐層固定的剪枝方式(layer-by-layer fixed manner)導致了網絡壓縮的低自適應能力、效率和效果.此外,上述的剪枝策略需要手動判斷每層的敏感性,因此需要大量的精力分析及逐層微調(fine-tuning).
2.2 基于參數共享的深度神經網絡壓縮與加速
參數共享是通過設計一種映射將多個參數共享同一個數據.近年來,量化作為參數共享的最直接表現形式,得到廣泛的應用.此外,Hash函數和結構化線性映射也可作為參數共享的表現形式.
參數量化壓縮與加速深度網絡模型主要的核心思想是利用較低的位(bit)代替原始32 b浮點型的參數(也可記為全精度權值(full-precision weight)).龔云超等人[41]及Wu等人[42]利用向量量化的技術,在參數空間內對網絡中的權值進行量化.近年來,利用低比特位的量化被提出用于加速與壓縮深度神經網絡.Gupta等人[43]將全精度浮點型參數量化到16 b固定長度表示,并在訓練過程中使用隨機約束(stochastic rounding)技術,從而縮減網絡存儲和浮點計算次數.使用動態固定點(dynamic fixed point)量化,在量化AlexNet網絡時,幾乎可以做到無損壓縮.例如,Ma等人[44]將權值和激活分別量化到8 b和10 b,且沒有利用微調權值.隨后Gysel等人[45]利用微調,將權值和激活全部量化到8 b.
為了更大程度地縮減內存和浮點計算次數,對網絡參數進行二值表示已被大量提出.其主要思想是在模型訓練過程中直接學習二值權值或激活.BinaryConnect(BC)[46]通過直接量化權值為-1或1,只需要加和減計算,減少了卷積計算,但因激活為全精度,無法大幅度加速網絡計算.為此,通過同時量化權值和激活為-1和1,Courbariaux等人[47]提出了BNN,將原始的卷積計算變成Bitcount和XNOR,大幅度加速和壓縮深度網絡.但在壓縮和加速深度網絡時(如AlexNet),分類精度大大降低.為了減少精度的丟失,Rastegari等人[48]分別提出了BWN和XNOR-Net引入了尺度因子(scale factor),用于縮小量化誤差,并保留第一層和最后一層的權值和輸入為32 b的浮點型.同時,改變卷積和正則化的順序,即先執行正則化、后卷積,減少了激活的動態幅度范圍.伴隨著這些改變,BWN和XNOR-Net分別獲得了相對于原始AlexNet 0.8%和11%的分類錯誤率增加.在近期的工作中[49-50],通過增加激活的位數(大于1),并探索不同的低比特權值與激活的組合量化全精度權值和激活,提高量化后的網絡在ImageNet數據集分類上的效果.但是在訓練這些量化網絡中,會出現梯度不匹配問題.Cai等人[51]通過分析權值和激活的分布情況,設計一種新的半波高斯量化器(half-wave Gaussian quantizer)及其BP過程中不同的梯度近似,提出了HWGQ-Net,有效地解決了訓練過程中梯度不匹配問題.
由于權值近似分布于均值為0的高斯分布,即W~N(0,σ2),進一步考慮0作為量化后的值,可能減少量化誤差.基于此思想,三元權值網絡(ternary weight nets,TWN)[52]將全精度權值網絡量化到三元網絡(即-w,0和w),其中w通過統計估計得到的量化值.通過改變對稱的w,訓練的三元量化[53](trained ternary quantization,TTQ)引入了不同的量化因子(即-w1,0和w2),且通過訓練得到該因子,在量化AlexNet時分類錯誤率只增加了0.6%.如表4所示,列出了以上量化網絡的性能比較及相應的量化比特數比較結果.
對于傳統網絡(如AlexNet和VGG-16),全連接層的參數存儲占整個網絡模型的95%以上,所以探索全連接層參數冗余性將變得異常重要.利用Hash函數和結構化線性映射相繼提出,可用于實現全連接層的參數共享,大大減低模型的內存開銷.Chen等人[54]提出了HashNet模型,利用2個低耗的Hash函數對不同的網絡參數映射到相同Hash桶中,實現參數共享.Cheng等人[55]提出基于一種簡單有效的循環投影方法,即利用存儲量極小的循環矩陣代替原始矩陣,同時使用快速傅里葉變換(fast Fourier transform,FFT)加速矩陣的乘積計算.另外,Yang等人[56]引入了新的Adaptive Fastfood變換,重新定義了全連接層的矩陣與向量之間的乘積計算,減少了參數量和計算量.
量化權值,特別是二值化網絡,存在以下缺點:1)對于壓縮與加速大的深度網絡模型(如Goog-LeNet和ResNet),存在分類精度丟失嚴重現象;2)現有方法只是采用簡單地考慮矩陣近似,忽略了二值化機制對于整個網絡訓練與精度損失的影響;3)對于訓練大型二值網絡,缺乏收斂性的理論驗證,特別是對于同時量化權值和激活的二值化網絡(如XNOR-Net,BNN等).對于限制于全連接層的參數共享方法,如何泛化到卷積層成為一個難題.此外,結構化矩陣限制可能引起模型偏差,造成精度的丟失.
2.3 基于低秩分解的深度神經網絡壓縮與加速
基于低秩分解的深度神經網絡壓縮與加速的核心思想是利用矩陣或張量分解技術估計并分解深度模型中的原始卷積核.卷積計算是整個卷積神經網絡中計算復雜度最高的計算操作,通過分解4D卷積核張量,可以有效地減少模型內部的冗余性.此外對于2D的全連接層矩陣參數,同樣可以利用低秩分解技術進行處理.但由于卷積層與全連接層的分解方式不同,本文分別從卷積層和全連接層2個不同角度回顧與分析低秩分解技術在深度神經網絡中的應用.
在2013年,Denil等人[57]從理論上利用低秩分解的技術并分析了深度神經網絡存在大量的冗余信息,開創了基于低秩分解的深度網絡模型壓縮與加速的新思路.如圖7所示,展示了主流的張量分解后卷積計算.Jaderberg等人[58]利用張量的低秩分解技術,將原始的網絡參數分解成2個小的卷積核.利用相同簡單的策略,Denton等人[59]先尋找對卷積層參數的低秩近似,然后通過微調的方式恢復模型的識別精度.此外,利用經典的CP分解[60],將原始的張量參數分解成3個秩為1的小矩陣.相似地,利用Tucker分解[61],將原始的張量分解成3個小的張量的乘積.Tai等人[62]提出了新的低秩分解張量算法,同時也提出了引入批量正則化,從頭開始訓練有低秩限制的卷積神經網絡.Ioannou等人[63]利用卷積核的低秩表示,代替分解預訓練的卷積核參數,并設計了一種有效的權值初始化方法,從頭開始訓練計算有效的卷積神經網絡.同樣地,代替直接分解預訓練的模型參數,溫偉等人[64]從訓練的角度探討如何更有效地聚集更多參數于低秩空間上,提出了新的強力正則化項(force regularization),迫使更多的卷積核分布于更為低秩空間中.以上低秩分解卷積核的方法,雖然減少了卷積核的冗余性,即考慮了卷積神經網絡內部結構的冗余性,但全盤接受了視覺輸入的全部,極大地影響了模型加速比.為此,林紹輝等人[65]提出了ESPACE卷積計算加速框架,考慮了視覺輸入的冗余性,即從輸入計算空間和通道冗余性2方面移除低判別性和顯著性的信息.
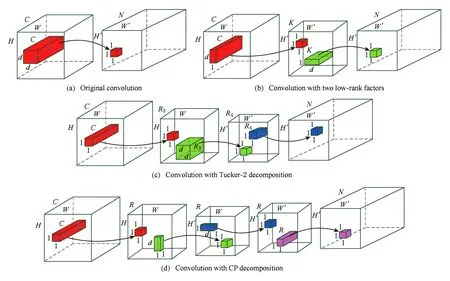
K, (R3, R4) and R are the corresponding rank of low-rank decomposition, Tucker-2 decomposition and CP decomposition respectively.Fig.7 Convolution with several low-rank factors圖7 擁有若干個低秩因子的卷積計算
對于全連接層特定的2D矩陣形式,雖然可以通過轉變2D矩陣計算為1×1的卷積計算,從而利用上述低秩分解技術進行應用,但對于特定的全連接層也存在相關低秩分解方法.Denil等人[57]利用了低秩分解方法減少了深度神經網絡中的動態參數個數.林紹輝等人[66]分析了直接對層內參數低秩分解壓縮無法獲得高精度分類效果的缺點,提出考慮層間的各種非線性關系,參數層間的聯合優化,代替單層的優化,構建全局誤差最小化優化方案.
基于低秩分解的深度網絡模型壓縮算法,在特定場景下取得良好的效果,但增加了模型原有的層數,極易在訓練過程中造成梯度消失的問題,從而影響壓縮后網絡的精度恢復.另外,逐層低秩分解優化參數,無法從全局進行壓縮,延長了離線分解時間開銷.
2.4 基于緊性卷積核的深度神經網絡壓縮與加速
對深度網絡模型的卷積核使用緊性的濾波直接替代,將有效地壓縮深度網絡.基于該思想,直接將原始較大的濾波大小(如5×5,3×3)分解成2個1×1卷積濾波,大大加速了網絡的計算同時獲得了較高的目標識別性能.
2016年,SqueezeNet[67]的提出是將原始的卷積結構替換成為Fire Module,即包括Squeeze層和Expand層.在Squeeze層將3×3的卷積濾波替換成1×1的卷積濾波,并在Expand層中加入1×1和3×3的卷積濾波,同時減少3×3的卷積濾波個數,減少池化(pooling),從而簡化網絡復雜度,降低卷積網絡模型參數的數量,同時也達到AlexNet識別精度.最終的模型參數降低了50倍,大大壓縮了深度網絡模型.另外,Google公司Howard等人[68]提出了MobileNets,利用計算和存儲更小的深度分割卷積(depthwise separable convolution)替代原始的標準卷積計算.Zhang等人[69]提出ShuffleNet,利用組卷積(group convolution)和通道重排(channel shuffle)兩個操作設計卷積神經網絡模型,從而減少模型使用的參數.一般情況下,使用組卷積會導致信息流通不當,通過通道重排改變通道的序列,得到與原始卷積相似的計算結果.Chollet[70]提出Xception網絡結構,在原始Inception-V3的基礎上引入深度分割卷積計算,不同于原始MobileNet中的深度分割卷積,Xception先進行1×1的點卷積計算(point convolution),然后再逐通道卷積,提高了模型的計算效率.在同參數量情況下,分類效果優于Inception-V3.
基于緊性卷積核的深度神經網絡壓縮與加速采用了特定的卷積核的設計或新卷積計算方式,大大壓縮神經網絡模型或加速了卷積計算.但壓縮與加速方法的擴展性和結合性較弱,即較難在緊性卷積核的深度神經網絡中利用不同壓縮或加速技術進一步提高模型使用效率.另外,跟原始模型相比,基于緊性卷積核設計的深度神經網絡得到的特征普適性及泛化性較弱.
2.5 基于知識蒸餾的深度神經網絡壓縮與加速
知識蒸餾(KD)的基本思想是通過軟 Softmax變換學習教師輸出的類別分布,并將大型教師模型(teacher model)的知識精煉為較小的模型.如圖8所示,展示了簡單的知識蒸餾的流程.2006年,Buciluǎ等人[71]首先提出利用知識遷移(knowledge transfer,KT)來壓縮模型.他們通過集成強分類器標注的偽數據(pseudo-data)訓練了一個壓縮模型,并重現了原大型網絡的輸出結果,然而他們的工作僅限于淺層網絡.近年來,知識蒸餾[72]提出了可以將深度和寬度的網絡壓縮為淺層模型,該壓縮模型模仿了復雜模型所能實現的功能.
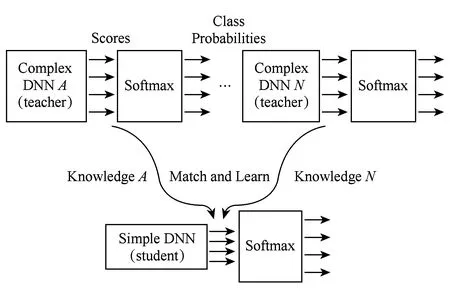
Fig.8 Knowledge distillation圖8 知識蒸餾
Hinton等人[73]提出了知識蒸餾的壓縮框架,通過軟化教師網絡輸出指導和懲罰學生網絡(student network).該框架將集成的深度網絡壓縮成為相同深度的學生網絡.為此,利用教師軟輸出的結果作為標簽,訓練壓縮學生網絡.Romero等人[74]提出了基于知識蒸餾的FitNet,通過訓練窄且深網絡(學生網絡),壓縮寬且淺網絡(教師網絡).
近幾年,知識蒸餾也得到了改進和拓展,例如:Balan等人[75]通過在線訓練的方式學習帶有參數的學生網絡近似蒙特卡洛(Monte Carlo)教師網絡.不同于原來的方法,該方法使用軟標簽作為教師網絡知識的表達,代替原來的教師網絡的軟輸出.Luo等人[76]利用高層隱含層神經元的輸出作為知識,它比使用標簽概率作為知識能保留更多的知識.Zagoruyko等人[77]提出了注意力遷移(attention transfer,AT),通過遷移注意力圖(attention maps),松弛了FitNet的假設條件.
雖然基于知識蒸餾的深度神經網絡壓縮與加速方法能使深層模型細小化,同時大大減少了計算開銷,但是依然存在2個缺點:1)只能用于具有 Softmax 損失函數分類任務,這阻礙了其應用;2)模型的假設較為嚴格,以至于其性能可能比不上其他壓縮與加速方法.
2.6 其他類型的深度神經網絡壓縮與加速
在1.3節介紹GoogLeNet時,為了減少全連接層的參數個數,全局均勻池化代替傳統的3層全連接層,減少了全連接層的參數.在近幾年提出的最新的網絡結構中,全局均勻池化方法廣泛其中,例如Network in Network(NIN),GoogLeNet,ResNet,ResNeXt[78]等,在很多基準(benchmark)任務中取得了最優的(state-of-the-art)性能.但該類型結構在ImageNet數據集上學習到的特征很難直接遷移到其他任務上.為了解決此問題,Szegedy等人[22]在原始結構的基礎上加入了線性層.
此外,基于卷積的快速傅里葉變化[79]和使用Winograd算法[80]的快速卷積計算,大大減少了卷積計算的開銷.Zhai等人[81]提出了隨機空間采樣池化(stochastic spatial sampling pooling),用于加速原始網絡中的池化操作.但是這些工作僅僅為了加速深度網絡計算,無法達到壓縮網絡的目的.
3 數據集與已有方法性能
3.1 數據集
在深度神經網絡壓縮與加速中常見并具有代表性的數據集主要包括MNIST[14],CIFAR-10/100[82],ImageNet[18],如表5所示,羅列了這些數據集的基本統計信息.
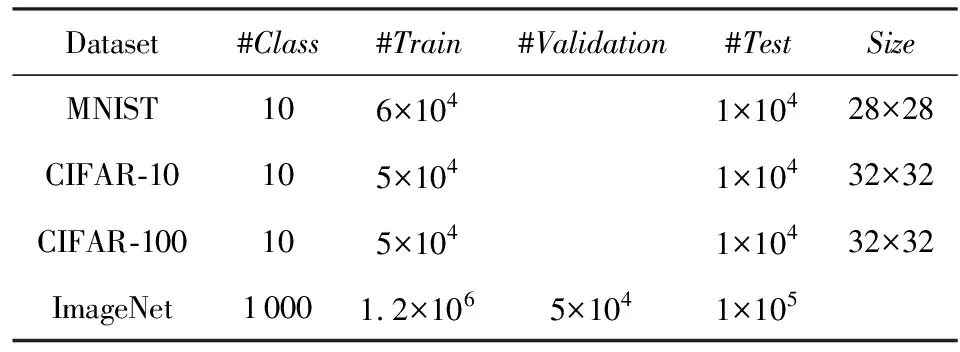
Table 5 Comparison of the Widely Used Dataset for DNN Compression and Acceleration表5 常見深度神經網絡壓縮與加速數據集統計信息
MNIST是用于手寫字符分類被廣泛使用的數據集.在1998年,該數據集被公開作為字符識別算法評測的公共數據集.在該數據集中,包含了來自10個類別(即手寫體數字0~9),像素為28×28的手寫體字符灰度圖,總計有6萬張訓練圖像和1萬張測試圖像.LeNet-5作為經典模型在MNIST上分類錯誤率達到0.9%.MNIST已作為簡單且公平的數據集用于評測深度神經網絡壓縮與加速性能.
CIFAR是用于分類小圖像的數據集,它是8千萬張 Tiny Image數據集的子集.在2009年,該數據集被公開作為分類小型彩色圖像算法評測的公共數據集.CIFAR數據集有2個版本,分別為CIFAR-10和CIFAR-100,包含了像素均為32×32的自然彩色圖像.在CIFAR-10數據集中,包含了來自10個互不交叉的類別,總計有5萬張訓練圖像(每類5千張)和1萬張測試圖像(每類1千張).在CIFAR-100數據集中,包括了100個類別不同的圖像,其中5萬張訓練圖像(每類500張)和1萬張測試圖像(每類100張).在不引入任何數據擴展方法時,經典模型NIN 在CIFAR-10和CIFAR-100分類錯誤率達到10.41%和35.68%.
ImageNet是一個大尺度圖像數據集.2010年首次被提出,并在2012年得到穩定使用.該數據集包含1 000個類別彩色圖像,且一般先縮放至像素大小為256×256.不同于以上2種數據集,該數據集的類別標簽可用字網絡(WordNet)表示,即由主類別標簽詞表示并包含相同目標的近義詞,相當于詞匯的分層結構.該數據集總計約有0.13億張訓練圖像(每個類別數量在732~1 300之間),10萬張測試圖像(每類100張)和5萬張驗證圖像(每類50張).由于測試數據集標簽未公開,一般情況下,測試該數據集性能時通過驗證集上性能作為測試依據.另外,top-1分類錯誤率和top-5分類錯誤率是判斷ImageNet分類準確率指標.top-1指的是得分最高的類別剛好是標簽類別時,分類正確;top-5指的是得分前5的類別中包含正確標簽時,分類正確.AlexNet,VGG-16,ResNet-50作為ImageNet數據集上經典的網絡模型,分別獲得了42.24% top-1分類錯誤率和19.11% top-5分類錯誤率、31.66% top-1分類錯誤率和11.55% top-5分類錯誤率以及24.64% top-1分類錯誤率和7.76% top-5分類錯誤率.
綜上所述,MNIST是較為簡單的小型數據集,而ImageNet是一個大尺度類別多樣的復雜數據集,充滿著挑戰.另外,對于同一個網絡,在不同數據集下表現出不一樣的性能,因此判斷網絡性能時一般需要考慮所采用的數據集.
3.2 評價準則
率失真(rate-distortion)作為評價深度神經網絡壓縮與加速性能標準,既考慮了模型的壓縮與加速比,同時需要計算壓縮與加速后的模型分類誤差率.為了計算模型的壓縮與加速比,我們假設λ和λ*分別為原始模型M和壓縮后模型M*所有參數所占的內存開銷,那么模型的壓縮比Cr可計算為
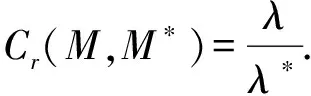
(3)
相似地,假設γ和γ*分別為原始模型M和壓縮后模型M*推測(inference)整個網絡的時間,那么模型的加速比Sr可定義為
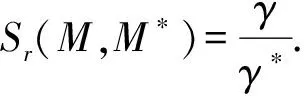
(4)
關于分類誤差率需要根據不同的數據集,如上述所述的數據集中,MNIST和CIFAR只存在top-1分類錯誤率,而ImageNet有top-1和top-5兩種分類錯誤率.根據數據集不同,選擇相應模型性能評價標準.一般情況下,好的深度神經網絡壓縮與加速方法表現出:壓縮與加速后的模型具有相似于原始模型的分類錯誤率,同時伴隨著少量的模型參數和計算復雜度.因此模型的錯誤率和壓縮比(或加速比)需要統一考慮.
目前深度學習框架層出不窮,包括Caffe[83],Tensorflow[84],Torch等.為了公平評測各壓縮模型的實際速度,對于深度神經網絡壓縮與加速領域,采用Caffe作為主流的深度學習框架.
3.3 代表性的深度神經網絡壓縮與加速方法性能
目前已有工作的實驗所用數據集一般是3個數據集:MNIST,Cifar,ImageNet,使用模型包括LeNet-5,AlexNet,VGG-16,ResNet等.下面我們比較代表性深度神經網絡壓縮與加速方法在不同模型上的壓縮與加速效果.
如表6所示,列出了包括剪枝與參數共享在內的壓縮與加速方法在LeNet-5上的比較結果.#FLOPs表示浮點型計算次數個數,#Param表示模型中參數的數量,errtop-1↑表示相比較于原始模型,壓縮后的模型top-1分類錯誤率增加值.從整體上看,在該模型上壓縮與加速取得了較好的結果.從壓縮與加速2方面比較,非結構化剪枝[31]在壓縮模型參數上能取得12×更好的結果,而結構化剪枝SSL[33]在加速模型上取得3.62×的結果,基本保證模型不丟失精度.

Table 6 Results of Different DNN Compression and Acceleration on LeNet-5表6 不同壓縮與加速方法在LeNet-5上的結果
Note:↑denotes increase.
如表7和表4所示,主要比較了不同壓縮與加速方法在AlexNet上的結果.如表7所示,主要比較了不同低秩分解技術在AlexNet上加速效果(除SSL[33]外).從比較結果可以看出,LRA[64]不僅在準確率和加速比高于傳統的CPD[60]和TD[61],而且在加速比(4.05×vs.3.13×)上也高于SSL,top-5分類錯誤率增加幾乎一樣(1.71% vs.1.66%).如表4所示,主要列出了關于量化網絡在AlexNet上的性能比較.原始的權值和激活的保存形式為32 b浮點型,通過用低比特位數量化網絡,減少模型存儲和計算開銷.增加比特位的位數,模型的性能得到提升,量化到8 b幾乎無損壓縮模型,如利用動態固定點量化[44-45].若只對模型的權值進行量化,保持激活位數不變,BWN[48],TWN[52],TTQ[53]能夠較好地控制模型誤差增加(除了BC[46]外),但加速效果有限.通過進一步量化激活,特別是量化激活為2 b時,HWGQ-Net[51]取得了top-5分類錯誤率增加僅為5.2%.
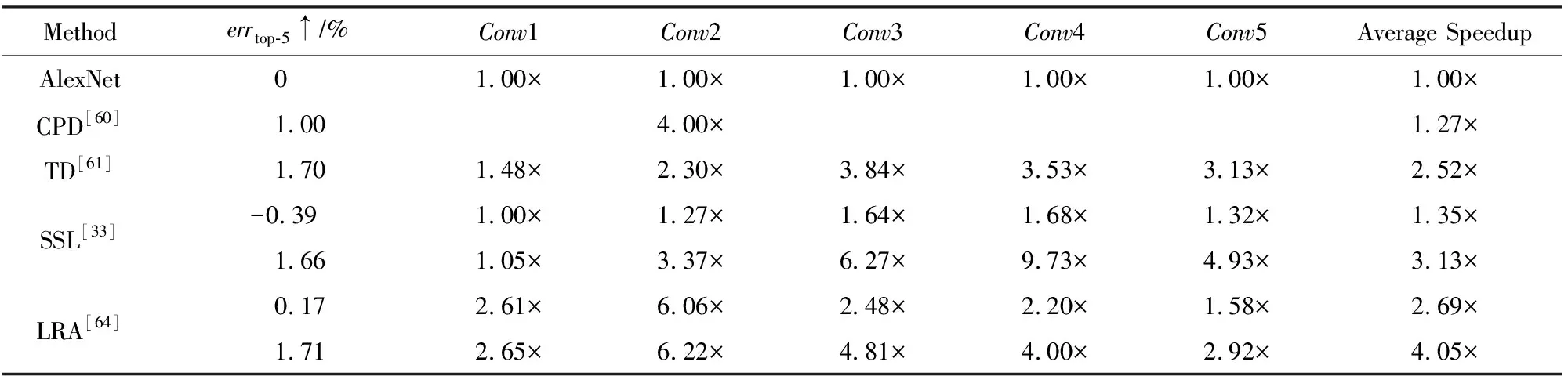
Table 7 Comparison of Different CNN Acceleration Methods on AlexNet[64]表7 不同卷積神經網絡加速方法在AlexNet上的對比
Note:↑ denotes increase.
在壓縮與加速VGG-16上,如表8所示,展示了部分比較有代表性的剪枝算法的評測結果.為了進一步壓縮VGG-16,借鑒NIN[25]全局均勻池化,代替原始模型中的3層全連接層.我們把壓縮后的模型記為“X-GAP”,指的是利用“X”方法剪枝完所有的卷積層后,加入GAP進行微調整個壓縮后的網絡.特別地,VGG-GAP不刪除任何卷積層的濾波,反而取得了較高的分類錯誤率,即top-1分類錯誤率和top-5分類錯誤率分別為37.97%和15.65%.另外,ThiNet[38]較其他方法,取得了較低的分類錯誤率增加(即top-1分類錯誤率和top-5分類錯誤率分別增加為1.00%和0.52%),但加速和壓縮比相對較低于L1[35],APoZ[36].通過進一步增加剪枝卷積核的數量(記為“ThiNet-T”),取得106.5×壓縮比和4.35×加速比,但壓縮后模型的top-1分類錯誤率和top-5分類錯誤率分別增加了9%和6.47%.
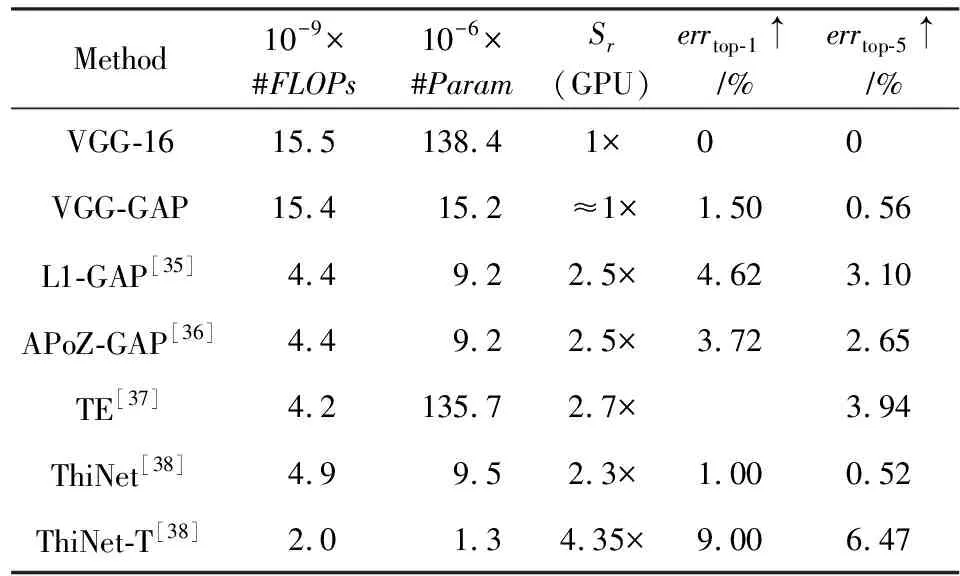
Table 8 Comparison of Parameter Pruning Methods for Compressing and Accelerating VGG-16表8 參數剪枝方法在壓縮與加速VGG-16上的對比
Note:↑denotes increase.
如表9所示,展示了主流的二值量化方法在ImageNet數據集上壓縮與加速ResNet-18的比較結果.全精度的ResNet-18能達到30.7% top-1分類錯誤率及10.8% top-5分類錯誤率.雖然BWN[48]
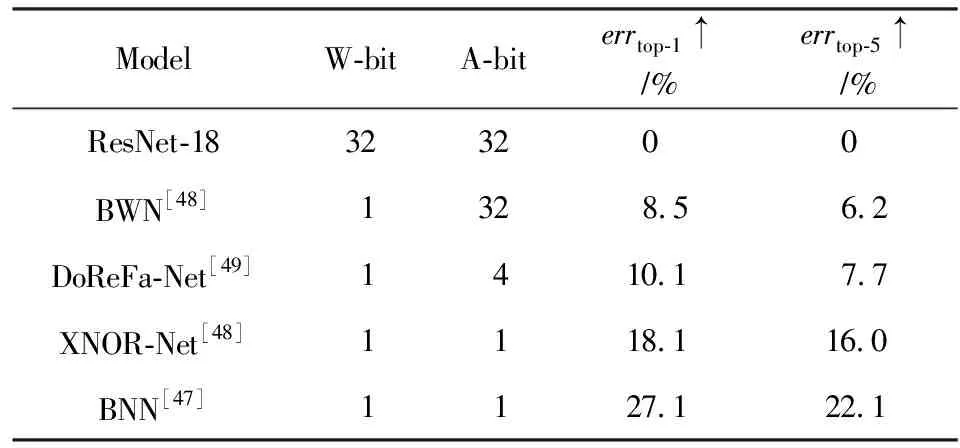
Table 9 Results of Binary Network on ImageNet for Compressing ResNet-18表9 二值網絡在ImageNet上壓縮ResNet-18的結果
Note:↑ denotes increase.
和DeReFa-Net[49]取得較好的分類性能,但它們分別使用了全精度的激活和4 b的激活.若同時二值化權值和激活,計算卷積時,只需要bitcount和XNOR計算,大大提高卷積計算效率,但降低了模型的分類效果,例如BNN[47]和XNOR-Net[48]分別增加了27.1%和18.1%的top-1分類錯誤率.
如表10所示,比較MobileNet[68]和ShuffleNet[69]在ImageNet上性能比較結果.aMobileNet-224指的是在基準模型框架下(即1 MobileNet-224),以a倍縮放基準結構的每層卷積核濾波個數;ShuffleNetb×,g=c指的是在組的個數為c的情況下,以b倍縮放基準結構(即ShuffleNet 1×)的每層卷積核濾波個數.通過不同層次的浮點型計算復雜度對比結果,可以明顯得出ShuffleNet的性能優于MobileNet.特別值得注意的是,在小的浮點型計算復雜度情況下(如0.4億浮點型計算次數),ShuffleNet取得了更好的分類結果,即高于相同復雜度等級的MobileNet 6.7%分類錯誤率.
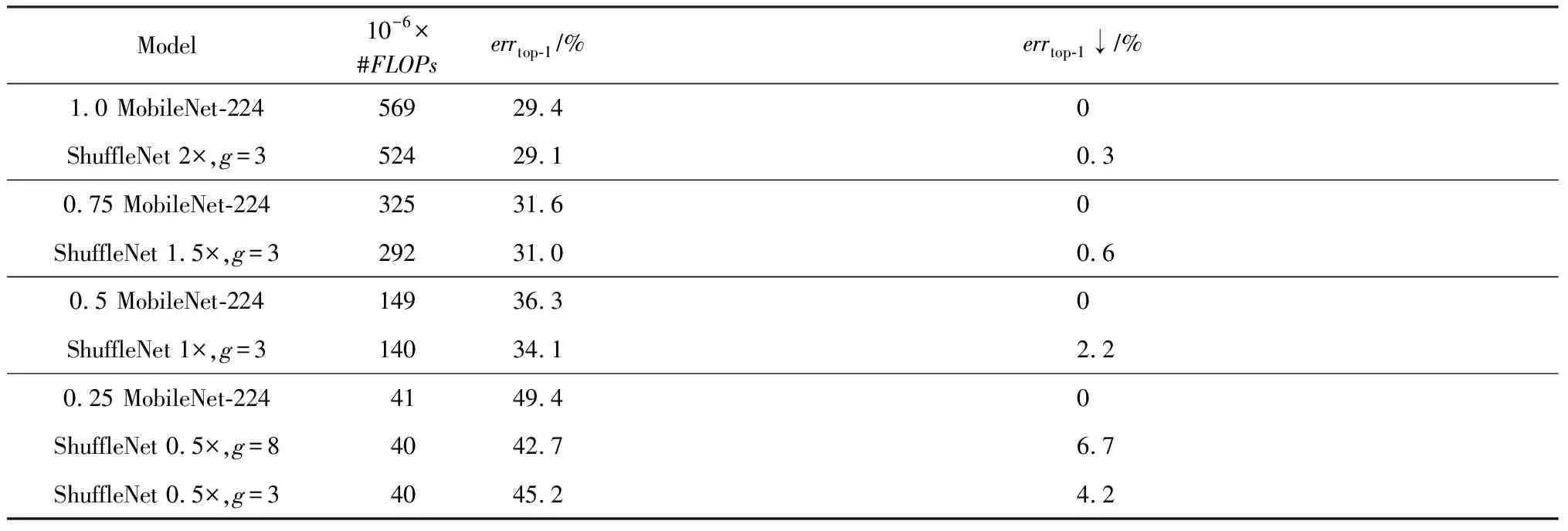
Table 10 Comparison of MobileNet and ShuffleNet on ImageNet Classification[69]表10 MobileNet和ShuffleNet在ImageNet分類上比較[69]
Note:↓ denotes decrease.
4 討論:壓縮與加速方法選擇
在第2節中,我們回顧與總結深度神經網絡壓縮與加速算法,但如何選擇不同的壓縮與加速算法成為一個難題.為此,在本節中,我們將進行詳細討論選擇深度模型壓縮與加速策略.
事實上,上述介紹的5種主流的深度神經網絡壓縮與加速方法各有優缺點,也沒有固定和可量化的準則來判斷哪種方法是最優的.所以壓縮與加速方法的選擇依賴于不同的任務和需要.總結出壓縮與加速方法選擇的6條意見:
1) 對于在線計算內存存儲有限的應用場景或設備,可以選擇參數共享和參數剪枝方法,特別是二值量化權值和激活、結構化剪枝.其他方法雖然能夠有效的壓縮模型中的權值參數,但無法減小計算中隱藏的內存大小(如特征圖).
2) 如果在應用中用到的緊性模型需要利用預訓練模型,那么參數剪枝、參數共享以及低秩分解將成為首要考慮的方法.相反地,若不需要借助預訓練模型,則可以考慮緊性濾波設計及知識蒸餾方法.
3) 若需要一次性端對端訓練得到壓縮與加速后模型,可以利用基于緊性濾波設計的深度神經網絡壓縮與加速方法.
4) 一般情況下,參數剪枝,特別是非結構化剪枝,能大大壓縮模型大小,且不容易丟失分類精度.對于需要穩定的模型分類的應用,非結構化剪枝成為首要選擇.
5) 若采用的數據集較小時,可以考慮知識蒸餾方法.對于小樣本的數據集,學生網絡能夠很好地遷移教師模型的知識,提高學生網絡的判別性.
6) 主流的5個深度神經網絡壓縮與加速算法相互之間是正交的,可以結合不同技術進行進一步的壓縮與加速.如:韓松等人[30]結合了參數剪枝和參數共享;溫偉等人[64]以及Alvarez等人[85]結合了參數剪枝和低秩分解.此外對于特定的應用場景,如目標檢測,可以對卷積層和全連接層使用不同的壓縮與加速技術分別處理.
5 未來發展趨勢
就目前研究成果而言,深度神經網絡壓縮與加速還處于早期階段,壓縮與加速方法本身性能還有待提高,合理壓縮與加速評價標準還需完善,為深入地研究提供幫助.
合理的性能評價標準的建立.雖然率失真率能同時考慮壓縮或加速、分類性能分布情況,但不同壓縮與加速方法無法統一到同一指標下,即同一壓縮與加速率下判斷分類性能的優劣,或同一分類性能下判斷壓縮與加速比.在后續的評測標準中,特別對不同壓縮與加速方法的合理評價將得到補充和完善.
壓縮與加速的模型多樣性得到推廣.目前深度神經網絡壓縮與加速的模型多使用卷積神經網絡,這肯定了卷積神經網絡強大的特征表示能力及應用覆蓋面.除卷積神經網絡外,還存在大量其他不同結構的網絡,如遞歸神經網絡(recurrent neural network,RNN)、長短期記憶網絡(long short-term memory,LSTM),廣泛應用于人工智能領域.在未來一段時間內,對于遞歸神經網絡、長短期記憶網絡等不同于卷積神經網絡結構的網絡,是否可以使用上述介紹的壓縮與加速方法進行處理,這將有待于研究.
更多深度神經網絡壓縮與加速技術嵌入終端設備,實現實際應用落地.隨著深度神經網絡壓縮與加速方法的快速推進與發展,對于分類任務的壓縮與加速方面已取得較大進步,但對于其他視覺任務較少涉及.設計基于視覺任務(如目標檢測、目標跟蹤、圖像分割等)為一體的深度神經網絡壓縮與加速,將成為深度神經網絡壓縮與加速方法真正植入智能終端設備,實現實際應用落地的研究熱點.
6 總 結
本文首先描述了深度神經網絡壓縮與加速技術的研究背景;然后對深度神經網絡壓縮與加速相關代表方法進行詳細梳理與總結;其次回顧了目前主流壓縮與加速算法所使用的數據集、評價準則及性能評估;最后討論了相關深度神經網絡壓縮與加速算法的選擇問題,并分析了未來發展趨勢.隨著深度神經網絡壓縮研究的不斷深入,希望本文能給當前及未來的研究提供一些幫助.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
