引入詞性標記的基于語境相似度的詞義消歧
2018-09-18 09:18:54孟禹光周俏麗張桂平蔡東風
中文信息學報 2018年8期
孟禹光, 周俏麗, 張桂平, 蔡東風
(沈陽航空航天大學 人機智能中心, 沈陽 遼寧110136)
0 引言
確定文本中某單詞的實際含義,即詞義消歧,簡稱WSD,是自然語言處理領域中歷史久遠的問題,有著廣泛的應用。目前可分為有監督方法、無監督方法和基于知識的三類方法。雖然已發表的有監督詞義消歧系統在提供特定語義的大規模訓練語料時有很好的表現,但缺乏大規模標注語料是其存在的主要問題。使用預訓練的詞向量可以在一定程度上解決這個問題。因為使用預先在大規模語料上訓練的詞向量,包含了較多的語義語法信息,用它來訓練有監督系統,會使性能得到提升。而想要對句中的詞義做推斷,目標詞和目標詞的語境都需要清楚地表示出來。我們將語境定義為從一個句子中去掉目標詞之后剩余的部分。為了更好地計算語境相似度,語境也需要以向量的形式進行表示。
在此前的消歧任務中[1],語境只是簡單地對目標詞在一定窗口內的詞向量求和或者加權平均來表示。但是由于目標詞和其整體語境之間具有的內在聯系,使用這種方法預訓練的詞向量所包含的信息十分有限。而想要對句中的詞義做推斷,目標詞和目標詞的語境向量都需要包含整個句子的信息。目前很多消歧系統共同的缺點是不包含語序信息。而長短期記憶網絡(LSTM),尤其是雙向長短期記憶網絡(BLSTM),克服了以上缺點,可以對目標詞周圍的所有詞進行建模,并將語序考慮進去。然而目前BLSTM模型都將一個詞的不同詞性,看做一個詞來進行建模,顯然不是十分正確的,因為同一個詞如果詞性不同會有不同的含義。
本文提出的方法是在訓練之前,把詞性加入到語料中,在訓練的過程中把不同詞性區分出來。把同一個詞的不同詞性,映射到語義空間的不同位置,可以更好地提取語境中所包含的信息。本文對三種不同的詞性特征加入方法進行實驗,即細分類詞性特征、粗分類詞性特征和只用實詞的詞性特征。通過實驗找到了一種最為合適的詞性特征引入方法,得到的消歧準確率在2004年的SE-3(Senseval-3 lexical sample dataset)測試集上達到了75.3%,并在SemEval-13和SemEval-15測試集上對比了加入詞性前后系統的消歧效果,加入詞性之后,消歧性能均有所提升。
本文結構安排如下: 第一部分介紹相關工作;第二部分介紹模型;第三部分介紹實驗設置;第四部分討論實驗結果;第五部分總結并介紹未來工作。
1 相關工作
一般來說,有監督的詞義消歧方法比其他詞義消歧算法效果更好,但是需要更大的訓練集以達到這種效果,而獲得大的訓練集代價很大。本文證明,不需要使用大量的訓練語料也可以達到很好的消歧效果。
使用大規模語料訓練的詞向量可以在一定程度上彌補有監督詞義消歧對訓練集要求過高的缺點。詞向量能夠在緊湊低維空間表示中包含詞的語義語法信息,在很多NLP任務中都得到了很好的應用。在詞向量研究中最具有代表性的就是Word2vec[2]和GloVe[3]。而這些技術的主要目的是在低維空間中對詞的語義、語法信息進行表達,還沒有對句子及語境中包含的信息進行低維表示。
最近幾年,用神經網絡訓練詞向量并建立語言模型,在情感分析、機器翻譯和其他的自然語言應用中都取得了很大發展。對于詞義消歧而言,Rothe和Schütze[4]將詞向量擴展到了語義向量,并用語義向量作為特征訓練了一個支持向量機分類器[5]。就像詞向量一樣,語境也可以以向量的形式表示,研究發現,在計算句子相似度[6]、詞義消歧[1]、詞義歸納[7]、詞匯替換[8]、句子補全[9]等任務中,語境的向量表示取得了較好的效果,但他們的語境只是簡單地對目標詞一定窗口內的詞向量求和或者加權平均來表示,起到的作用有限。
2016年Google[10]使用LSTM進行消歧,使用了1 000億詞新聞語料訓練模型,在SemEval-2015測試集上達到了最好的消歧效果,它的消歧方法是使用一個詞的語境預測目標詞來進行消歧。LSTM模型是一種特殊的循環神經網絡(RNN)模型,在1997年由Hochreiter 和Schmidhuber[11]提出,它可以使RNN在對序列建模時更好地提取長距離信息。但是單向LSTM只能提取句子中位于目標詞之前的信息。而語境向量模型(Context2vec)[12]使用了BLSTM訓練,僅用了20億詞的語料作訓練就在SemEval-2015測試集上達到了比Google的單向LSTM模型消歧高0.1%[13]的結果,它的目的是訓練詞向量和語境向量,利用得到的語境向量和詞向量進行消歧,而且可以在其他的語言任務中得到較好的應用,從某種方面來說,BLSTM的性能更好。BLSTM[14]每個時刻的狀態都包含了兩個LSTM的狀態,一個從左到右,另一個反之。這就意味著一個狀態既可以包含前面的詞的信息,也可以包含后面詞的信息,在很多情況下,這對選擇一個詞的語義是非常必要的。本文中,通過向Context2vec中加入詞性特征,進而訓練得到語境向量,這種語境向量可以很好地提取語境中的語義語法信息。在得到的語境向量基礎上,使用簡單的k近鄰算法進行消歧,實驗證明本文的詞義消歧系統不需要大量的訓練語料,也可以達到很好的效果。
2 Context2vec
2.1 模型綜述
Context2vec可以對目標詞的語境進行學習,得到一個獨立于特定任務的向量表示。這種模型基于Word2vec的連續詞袋模型(CBOW)(圖1),圖中左側計算目標詞submitted的語境向量,僅考慮目標詞周圍一定大小窗口內的詞,paper被忽略了,將John和a的詞向量進行簡單的加權平均得到submitted的語境向量,將右側的目標詞向量與得到的目標詞的語境向量輸入目標函數,訓練模型。Context2vec用更有效的BLSTM替代了原來模型中固定窗口內詞向量取平均的建模方式,如圖2所示。
雖然兩個模型的本質都是同時在低維空間學習語境和目標詞的表示,但基于BLSTM的Context2vec可以更好地提取句子語境中的本源信息。
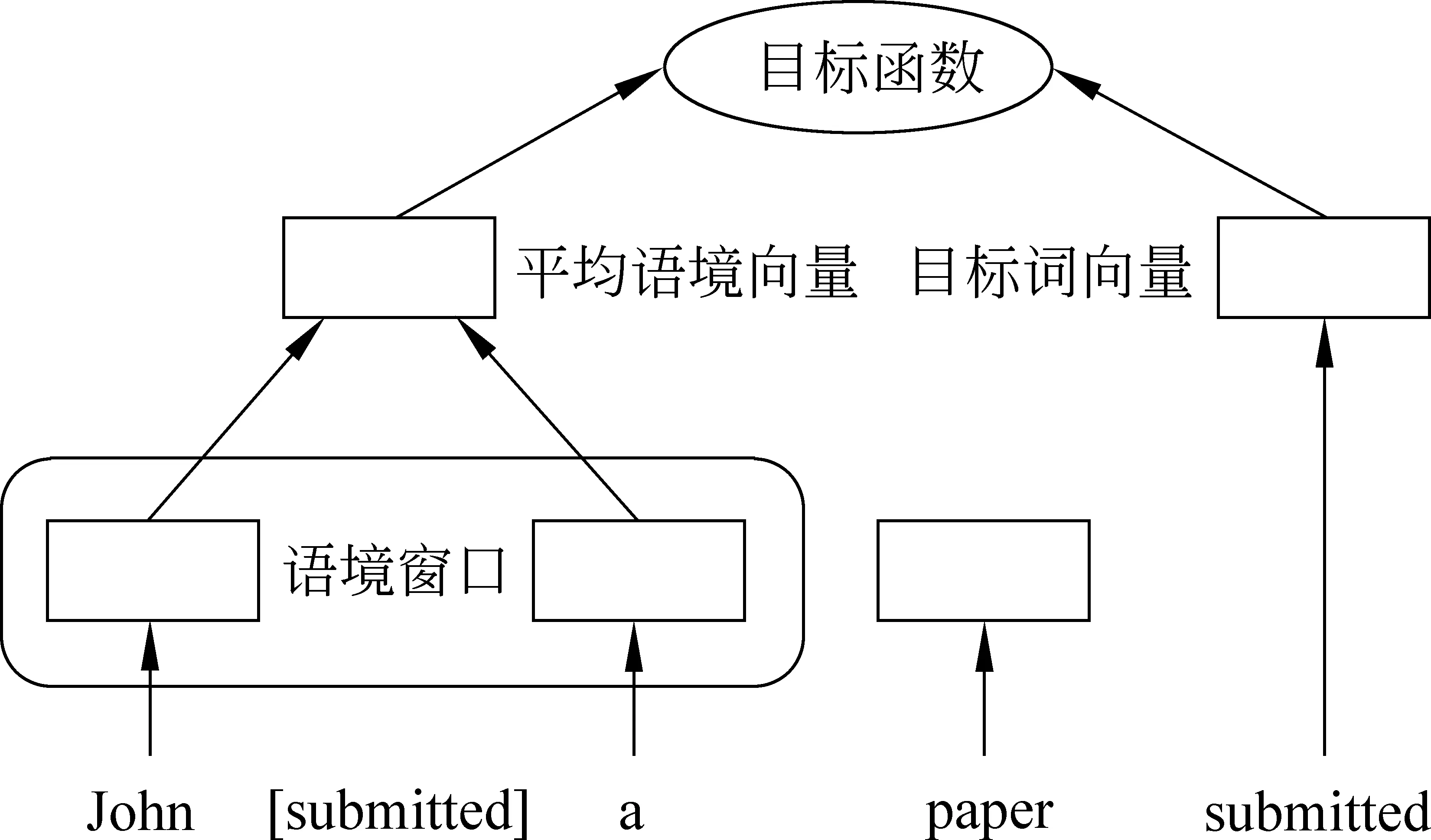
圖1 Word2vec模型
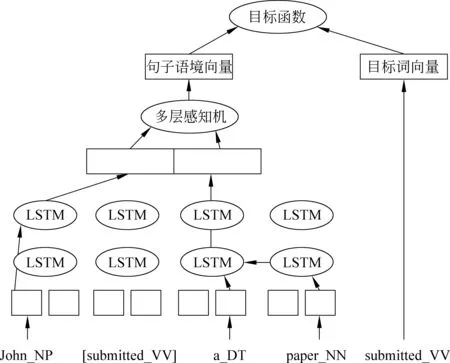
圖2 加入詞性的Context2vec模型
圖2左側說明Context2vec是如何表示句子語境的。使用BLSTM循環神經網絡,將句中的詞從左到右輸入一個LSTM,另一個從右到左進行輸入。這兩個網絡的參數是完全獨立的,包括一個從左至右和一個從右至左的語境向量。為表示句子中目標詞的語境( John_NP [submitted_VV] a_DT paper_NN ) ,首先將LSTM輸出的左—右語境John_NP的向量表示和右—左語境a_DT paper_NN的向量表示拼接,這樣做的目的是獲得目標詞語境中的相關信息。下一步將拼接后的向量輸入到多層感知機中,就可以將兩個方向的語境向量有機融合。將此層的輸出作為目標詞的句子語境表示。同時,目標詞用它自己的向量表示(圖2右側),它的維度和句子語境向量的維度相同。我們注意到Context2vec和Word2vec模型之間的唯一的差別是Word2vec模型是將目標詞的語境表示為周圍一定窗口內語境詞的簡單平均,而使用了BLSTM的Context2vec則將整句話有機結合起來表示語境,不僅考慮了距離遠一些的詞,還考慮到了語序信息。
Word2vec模型在內部使用語境建模,并將目標詞的向量表示作為主要輸出,Context2vec更關注語境的表示。Context2vec通過給目標詞和目標詞的語境指定相似的向量來進行建模。這就間接地導致了給具有相似句子語境的目標詞指定了相似的詞向量,相反地,給相似目標詞的語境也指定了相似的向量表示。
2.2 語境向量計算公式
我們使用Context2vec[12]來得到一個句子級別的語境表示。lLS表示從左到右讀取句子的LSTM,rLS表示從右到左讀取句子的LSTM。給定一個有n個詞(w)的句子(w1:n),那么目標詞wi的語境就可以表示為兩個向量的連接,如式(1)所示。
其中l1:i-1和rn:i+1分別表示句中從左向右和從右向左輸入到lLS和rLS中的詞向量。下一步,對左右兩側語境表示的拼接輸入到以下非線性函數,如式(2)所示。
其中MLP代表多層感知機,ReLU是修正線性單元激活函數,而Lj(x) =Wjx+bj是一個全連接線性操作。則在句中位置i處的單詞的語境表示定義如式(3)所示。
將目標詞和語境向量用相同維度的向量表示。模型訓練使用Word2vec中所用的負采樣方法。
2.3 特征選擇
詞性是一種很重要的語義語法信息,由于本文訓練的Context2vec所使用的ukWaC[15]語料提供詞性標注版本,我們直接在詞的后面用下劃線將詞和詞性結合,將其看作一個詞,輸入到Context2vec模型中進行訓練,這樣所得到的詞向量,就會將同一個詞的不同詞性區分開。

圖3 加入詞性后,語義空間中的點的變化
從圖3中可以發現,在加入詞性之前,plane的動詞原型、名詞單數和形容詞三種用法,都通過plane一個點表示,將三種不同的語義語法信息看作同一個點,顯然是不合理的,這種情況在各種語言,尤其是英文中非常普遍。在加入詞性之后,可以將不同的詞性分別建模,plane的形容詞(plane_JJ)、名詞單數(plane_NN)、動詞原型(plane_VV)等含義都在空間中重新分配了屬于自己語義的點。通過這種方式,更好地捕捉語義語法信息,避免了語義上的混淆。
為了證明詞性在Context2vec中的作用,我們還對三種不同的詞性標注方式分別進行了實驗: 細分類詞性標記、粗分類詞性標記、單獨用實詞的詞性標記。從中選擇最好的詞性特征加入方式。
2.4 模型說明
由于在模型的訓練過程中要求語境和目標詞更加接近,所以可以用一個語境向量求出和它余弦相似度最大的詞向量,得到可以填補到空缺位置的詞。得到的詞越符合語義語法,說明模型訓練得越好,和消歧準確率一樣可以判斷一個模型的好壞,用這種指標和準確率一起作為衡量模型質量的參考。
Context2vec在提出之時作者用k=1的近鄰法消歧,得到了較好的效果,在實驗過程中發現,使用k=1做開發集的實驗,并不能完全說明模型的好壞。為了說明k值的選取過程,我們列出了加入詞性前后在不同訓練輪數e下得到的模型對給定語境的預測詞,同時將模型在SE-3進行消歧達到的準確率進行對比(表1)。
如表1所示,對比2、4號相同訓練輪數下加入詞性前后的消歧準確率及預測詞,雖然2號的消歧準確率高于4號,但是2號預測的目標詞并不如4號預測的符合語義語法。同樣對比1、3號結果,1號的消歧準確率雖然低于3號,但是預測的詞比3號的更符合語義語法。這是由于表中使用k=1的k近鄰法消歧得到的準確率,并不能完全說明模型的好壞,不能將其作為絕對的評價標準。我們對不同k值進行了測試,結果發現在給定模型的情況下,
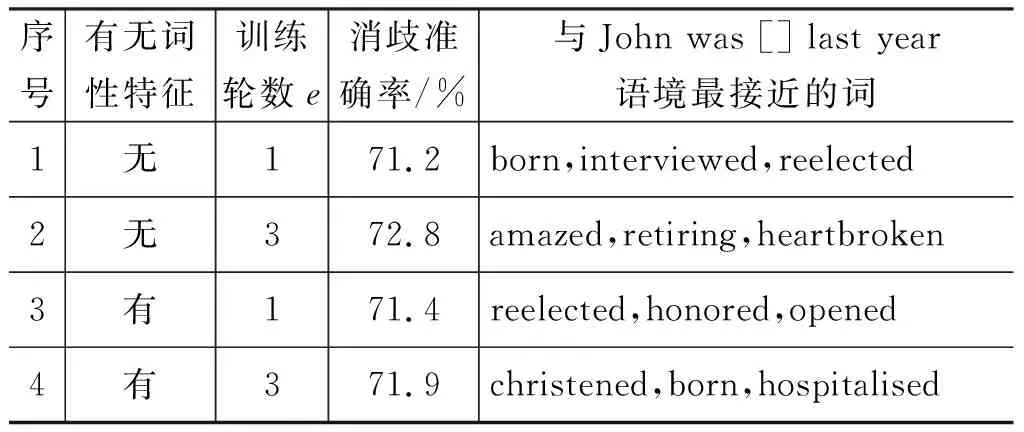
表1 語境的預測詞和SE-3測試集消歧結果
用k=5的k近鄰法進行消歧,效果最好。因此本篇文章中,取k=5的k近鄰算法進行消歧做對比實驗。
3 實驗
Context2vec模型可以訓練得到高質量的語境向量和詞向量,在多種自然語言處理任務中都有很好的應用。用于詞義消歧也取得了較好的效果,為了測試加入詞性特征后訓練的模型的性能,進行了以下實驗。
3.1 Context2vec訓練語料
我們使用20億詞的ukWaC語料[15]的詞性標注版本來訓練模型,詞性由TreeTagger自動標注,此工具的標注準確率約為95%,并將詞性和詞結合在一起,例如,apple我們將其寫成了apple_NN構成一個新的詞。這樣可以將詞性信息加入模型一同訓練。用得到的模型求目標詞的語境向量,就包含了這些詞性信息。為加速訓練過程,且方便和baseline實驗作對比,并沒有使用句子長度大于64的句子,這使得語料規模減小了10%。將所有的詞都小寫化并且把出現次數少于最小詞頻t的詞看作未登錄詞,其中t取了不同的數值,做對比實驗。實驗證明不同的最小詞頻對實驗結果有一定影響。
3.2 消歧方法
使用Python中的Chainer[16]工具包訓練模型,用Adam[17]進行優化。為加速訓練過程,使用了mini-batch訓練,這樣每次就只會將相同長度的句子加入同一個小的訓練過程。
3.2.1 有監督詞義消歧
Context2vec可以生成給定語境的語境向量,利用這些語境向量進行消歧,需要標注好語義的目標詞的例句集合作為訓練集。在消歧過程中,首先將訓練集中包含目標詞的多個例句的語境輸入,得到每個語義若干例句的語境向量,然后計算待消歧句語境向量和這些語境向量的余弦相似度,將與待消歧句語境向量相似度最高的語境向量所對應的語義作為目標詞的語義,得到消歧結果。
我們用的是2004年的Senseval-3 lexical sample dataset作為標注詞義消歧數據集,其中包含了 7 860個訓練樣本、57個目標詞和3 944個測試樣本。
在參數調優過程中,使用了留一法進行交叉驗證,在訓練出Context2vec模型之后,假如某個詞在訓練集中有N個樣本,每次從訓練集取出一個句子作為測試樣本,其他N-1個樣本作為訓練樣本,使用有監督詞義消歧對測試樣本進行消歧,對訓練集中的7 860個句子進行以上操作,就得到了開發集的消歧結果。測試集是官方評測提供的,與開發集和訓練集是完全獨立的數據集。
還使用SemEval-13 task 12 和 SemEval-15 task 13兩個公開評測集測試消歧準確率,目的是用最新的測試集驗證這種方法的效果,這兩個任務均為詞義消歧任務,但是只提供了測試集,所以我們使用標記的SemCor和SemCor+OMSTI(One million sense-tagged instances)[18]中的例句作為訓練集,其中SemEval-13共有621個目標詞、1 442個測試樣本。SemEval-15共有451個目標詞、924個測試樣本。
3.2.2 消歧流程
在消歧之前,使用非詞性標注語料和詞性標注語料分別訓練兩個語境向量模型,記為M、MP。其中M用于未加詞性特征的句子消歧,MP用于加入詞性特征的句子消歧。
對于待消歧句Sen: Sodalities have an important role in 【activating】 laity for what are judged to be religious goals both personally and socially .
加入詞性特征后句子為SenP: Sodalities_NN have an important_JJ role_NN in 【activating_VV】 laity_NN for what are judged_VV to be religious_JJ goals_NN both personally_RB and socially_RB .
對應的語境向量分別為V、VP,目標詞在【】中,此目標詞有五個不同的語義S1、S2、S3、S4、S5,各語義對應解釋如下:
S1:to initiate action in; make active.
S2:in chemistry, to make more reactive, as by heating.
S3:to assign (a military unit) to active status.
S4:in physics, to cause radioactive properties in (a substance).
S5:to cause decomposition in (sewage) by aerating.
訓練集包含了此目標詞的228個例句,由于官方給出的語義粒度過小,具有某些重疊,每個例句對應1或2個語義,若對應兩個語義,則每個語義的權重為0.5,否則為1,將例句語境輸入到語境向量模型M、MP中得到每個例句的語境向量,通過語境向量之間的余弦相似度,并應用k=5的k近鄰法,分別得到與Sen、SenP語境最接近的五個例句,如表2所示。
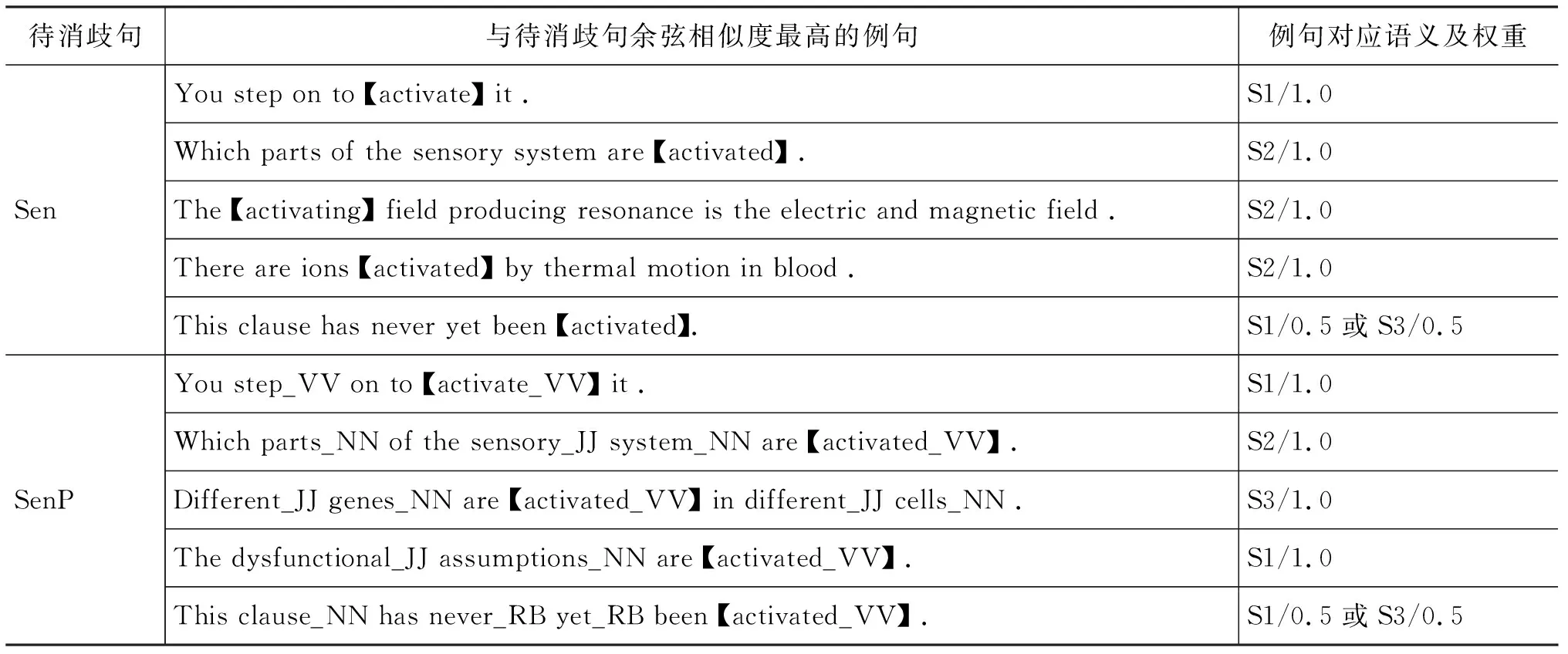
表2 與待消歧句語境最接近的例句和語義
表2中,通過計算句子的語境向量之間的相似度,能夠得到與待消歧句語境接近的例句,而這些例句是標記好的,通過這些例句對應的語義出現的次數及權重,加權求和得到每個語義的打分:
Sen: Score(S1)=1.5、Score(S2)=3.0、Score(S3)=0.5、Score(S4)=0、Score(S5)=0
SenP: Score(S1)=2.5、Score(S2)=1.0、Score(S3)=1.5、Score(S4)=0、Score(S5)=0
根據得到的打分,加入詞性前選擇的語義為S2,加入詞性后選擇的語義為S1,顯然加入詞性通過計算語境相似度,我們得到了正確的語義。
4 實驗結果
為找出最有效的詞性特征引入方法,本文使用了三種不同的詞性標注方式訓練模型: 細分類詞性標記、粗分類詞性標記和單獨用實詞的詞性標記。
實驗中所使用的模型參數如表3所示。我們每次的最小取樣數是850,在ukWaC語料訓練一輪的時間大約是24小時。
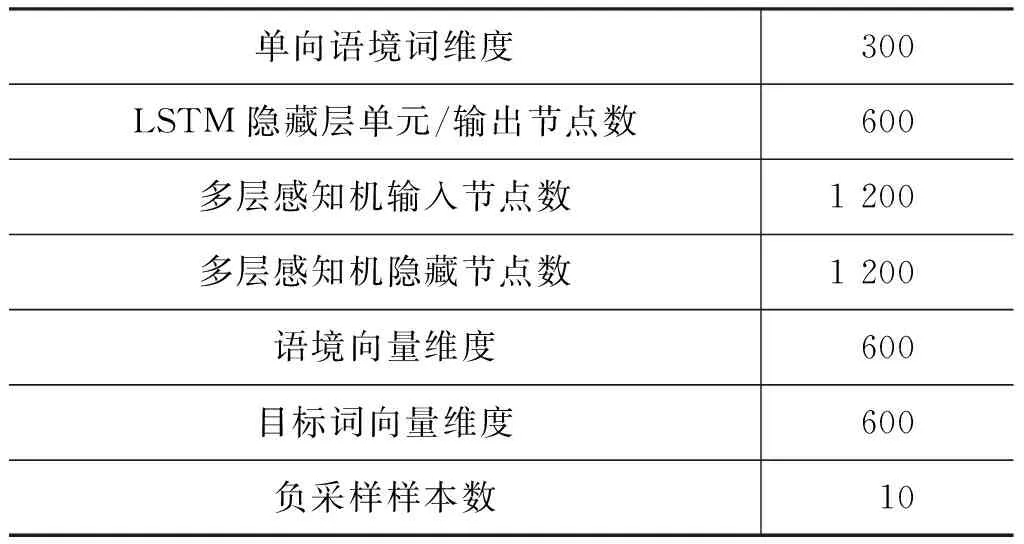
表3 模型參數
4.1 細分類詞性標記
使用TreeTagger標注的ukWaC語料,進行訓練。找到在開發集中消歧效果最好的模型用來測試,開發集在最小詞頻t=100,訓練輪數e不同時對應的結果如表4所示。

表4 細分類詞性標記下的開發集結果
序號3所訓練的模型最好,與加入詞性前效果最好的模型作對比,結果如表5所示。

表5 細分類詞性標記下的語境預測詞和消歧結果對比
由表5中的結果對比可以發現,雖然1號的消歧準確率高于2號,但是它語境預測的目標詞并不十分符合語義,甚至是語法(加入詞性后,可以將詞性一同預測出來,為了方便對比,此處并不列出)。而加入詞性之后,可以看到2號可以較好地預測出目標詞。說明詞性的加入,還是對模型起到了較好的作用。雖然加入詞性后,語境預測詞的效果較好,但是在詞義消歧任務上的準確率并沒有達到加入詞性之前的效果,究其原因可能是因為我們所使用的TreeTagger的詞性標記種類(表6)過多。
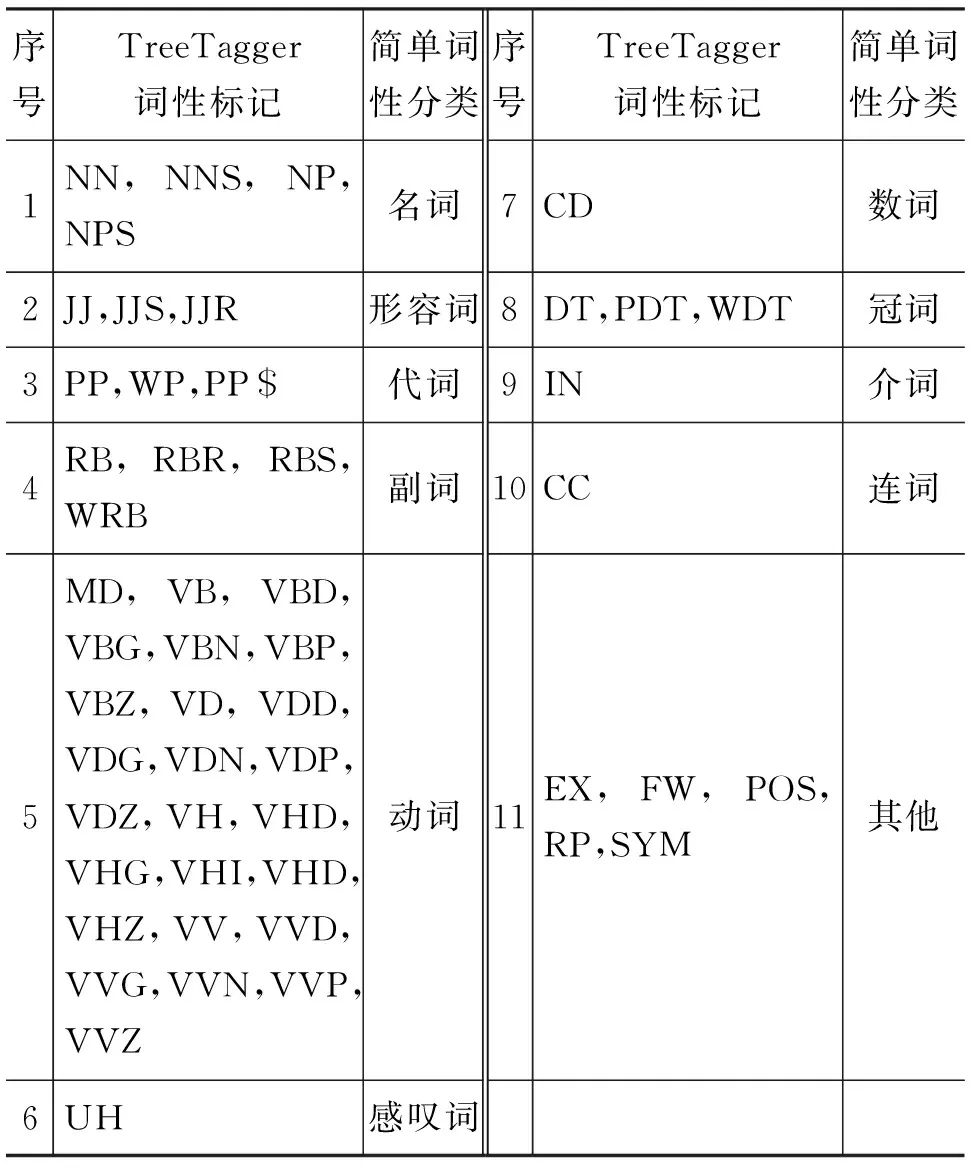
表6 細分類詞性標記
由表6的詞性標記方式可以發現,其中一個詞的同一詞性的不同時態也會有不同的標記,而這顯然是沒有必要的,這導致詞表過大,降低了訓練模型的效率,也影響了詞性標注的準確率,進一步也影響了消歧的準確率。
4.2 粗分類詞性標記
由于細分類的詞性標記準確率的影響,消歧效果并沒有得到提升。改用表7中的詞性映射方式,對同一類簡單詞性不再進行區分。
根據語言學知識,并沒有將TreeTagger中的助動詞進行映射,因為某些助動詞對應的實意動詞已經映射為了VV,而助動詞沒有映射,就可以將其區分開。
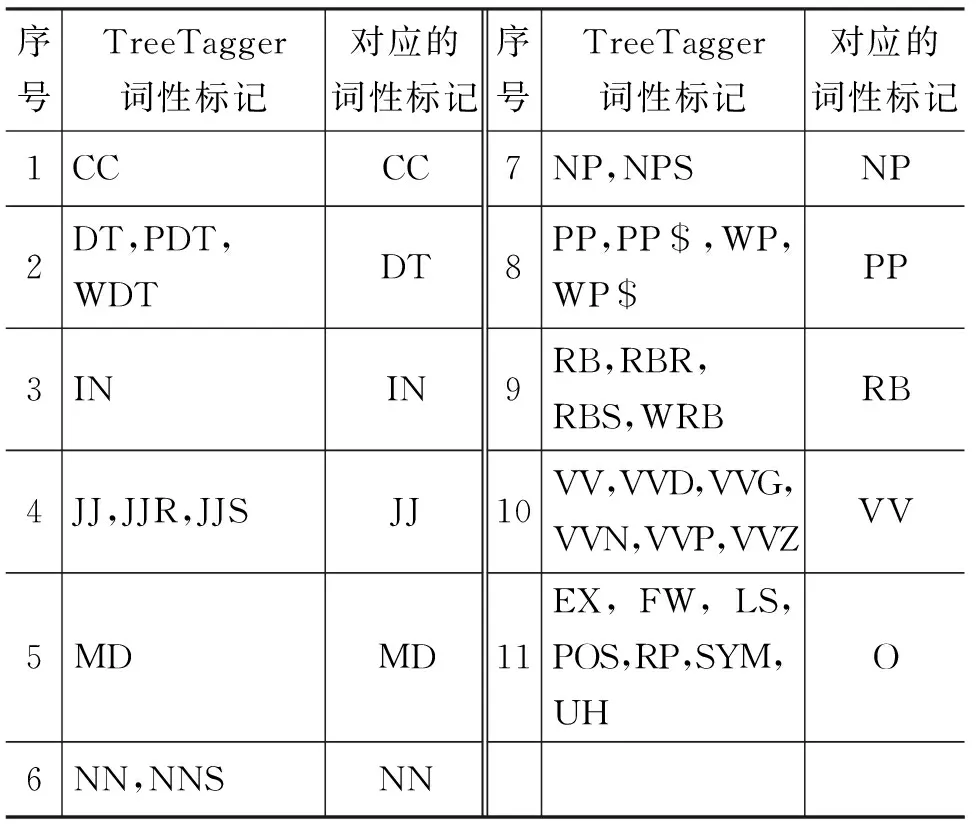
表7 粗分類詞性標記
為了使詞表和加入詞性之前盡量一致,把原始Context2vec中沒有用到的低頻詞都替換為
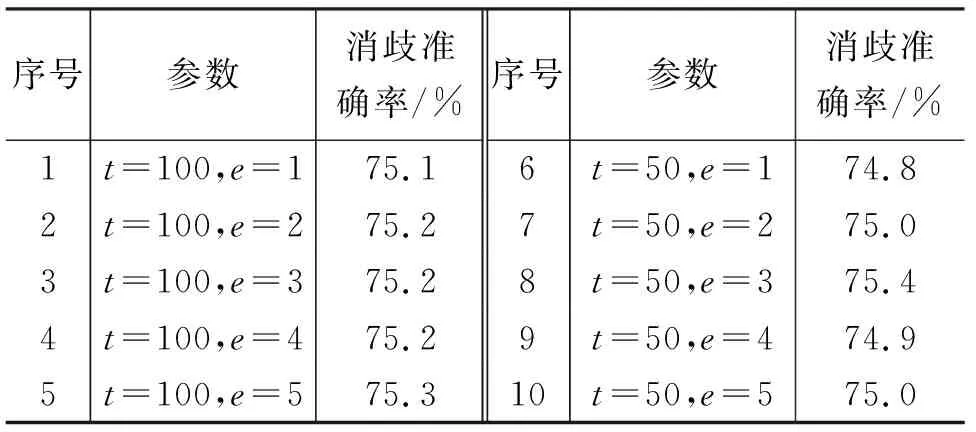
表8 粗分類詞性標記的開發集結果
選取開發集表現最好的模型作測試,結果如表9所示。
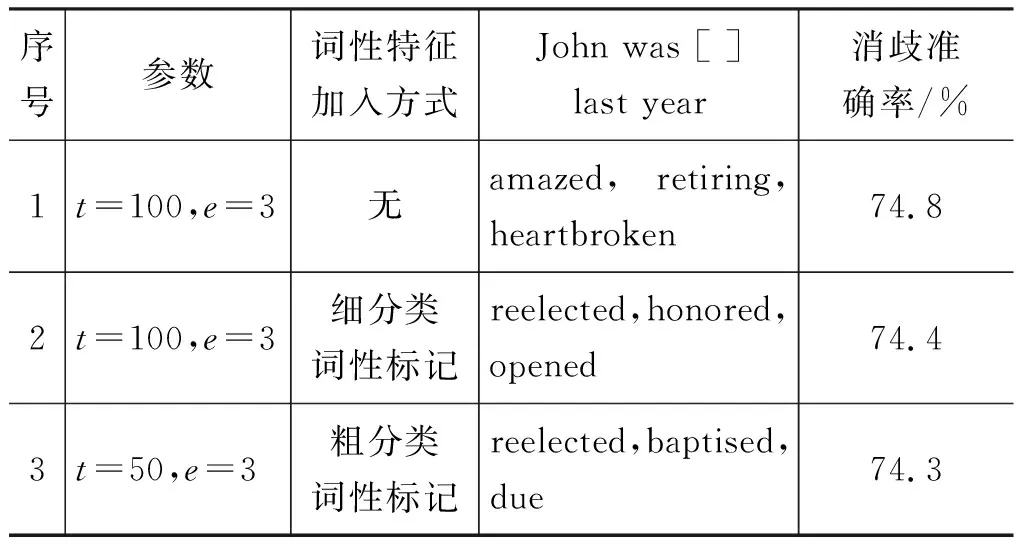
表9 粗分類詞性標記下的語境的預測詞和消歧結果對比
對表9的結果進行對比,發現加入粗分類的詞性標記后,3號并沒有達到1號的消歧效果,只是語境預測詞更符合語義語法。而根據2號和3號的結果對比,消歧準確率和語境預測詞都十分接近。這是因為兩種詞性標記方式都對虛詞進行了標注。對訓練語料進行檢查發現,其中有些本該標注為DT的that標注成了IN,本該標注成IN的upon標注成了RP。這種虛詞雖然數量有限,但是每一個虛詞在訓練語料中出現的頻率都很高,一般用來構成句子框架,這些詞如果標注錯誤,對語義空間所造成的影響更大。
4.3 實詞的詞性標記
基于4.1節和4.2節的實驗結果,決定只使用實詞對訓練語料進行標注。實詞,有實在意義,在句子中能獨立承擔句子成分。我們選擇了幾種對語義影響較大的實詞,而代詞和數詞也屬于實詞,但是它們一般只具有單一詞性,而且不同詞性表達的語義也是相同的。其他的虛詞不再進行標注,如表10所示。
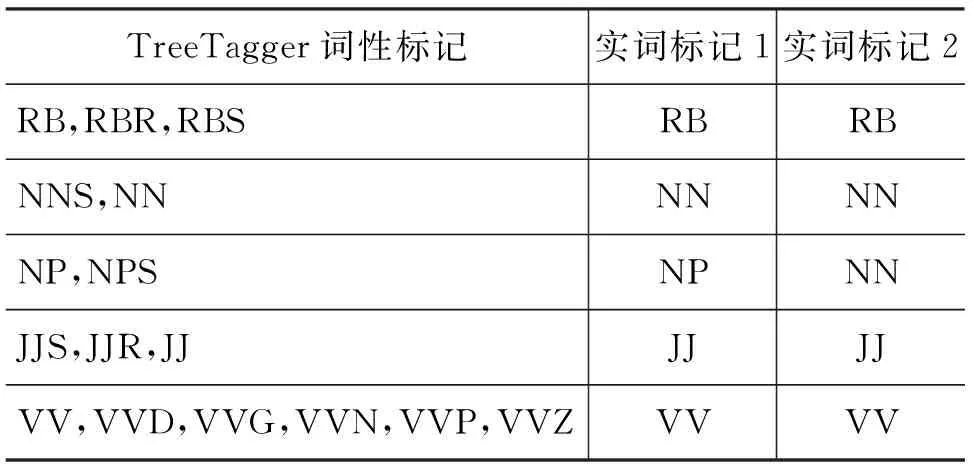
表10 實詞的詞性標記
表10列出的兩種實詞標記方式,分別取名為實詞標記1和實詞標記2。它們的區別僅在于是否將名詞細分為普通名詞(NN)和專有名詞(NP)。這是因為,某些普通名詞同時還有專有名詞的含義,如plane既有普通名詞飛機,又有專有名詞作為人名的作用。同時在實驗中我們發現,有些在命名實體中出現的普通名詞,TreeTagger工具將其標記為了NP。到底是應該將所有的名詞都標記為NN還是將NN和NP區分標記能達到更好的消歧效果,我們需要通過實驗來進行判斷。
為保證訓練速度和詞表大小,將實詞標記2實驗中的最小詞頻t取10,將實詞標記1中的最小詞頻t取50,此時詞表大小均為22萬左右,訓練效率接近。若實詞標記2取t=50,則詞表大小為19萬,會相比t=10減少3萬低頻詞,我們還對取相同的t值(100)訓練的模型的消歧結果進行了對比,此時實詞標記1詞表大小為19萬,實詞標記2詞表大小為17萬。實詞標記1下的開發集結果如表11所示,實詞標記2下的開發集結果如表12所示。
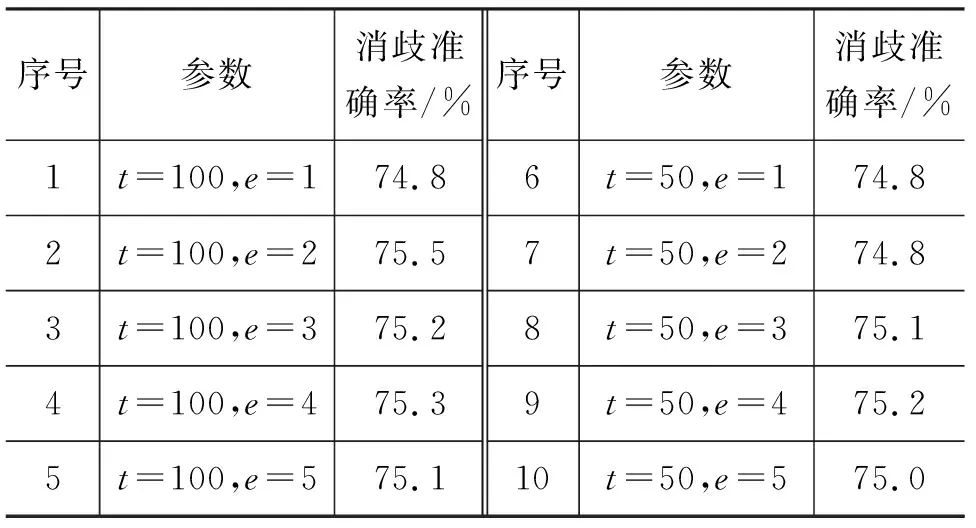
表11 實詞標記1下的開發集結果
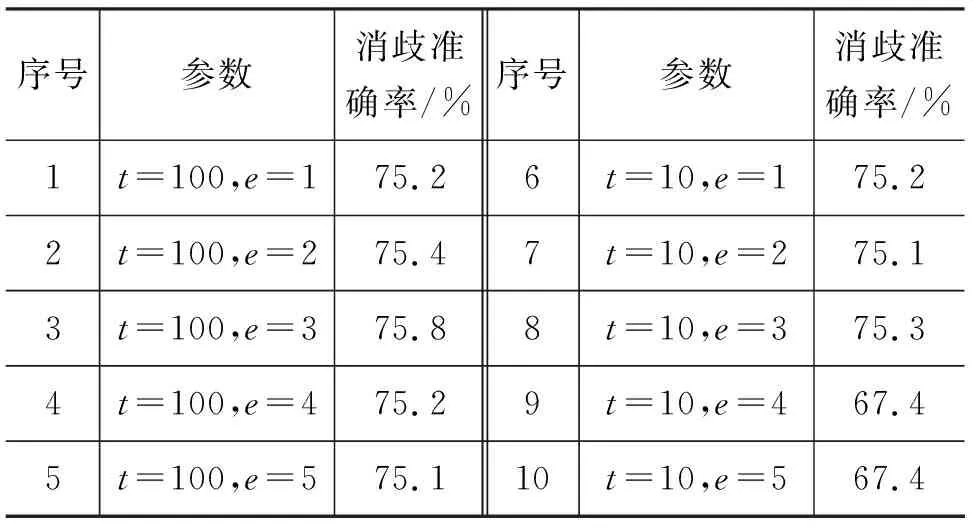
表12 實詞標記2下的開發集結果
從表12可以看出,用實詞標記2標注的訓練語料所訓練的模型效果普遍高于實詞標記1。對于表12中的9、10號實驗結果準確率突然降低的現象,在Context2vec達到最優點之后均會出現這種過擬合現象,由于此時參數t取10,相比t取50而言,詞表中包含了三萬個出現頻率高于10低于50的低頻詞,導致這種現象過早地出現。因為命名實體中的普通名詞數量遠遠高于有專有名詞含義的普通名詞。如: 在訓練語料中,如果將名詞細分為NP和NN,會出現Valley_NP Park_NP,Web_NP Author_NP Dr._NP Walton_NP等詞語,其中的人名雖然被區分出來,但是也將本應屬于普通名詞范疇的詞標記為了專有名詞,把原本語義空間中的一個點強行劃分為了兩個點,導致了消歧效果的降低。
把此方法得到的最好模型與其他詞性標注方式得到的最好模型的消歧結果和語境預測詞作對比,如表13所示。

表13 實詞標記2下的語境的預測詞和消歧結果對比

續表
由表13的結果可以看出,序號4不管在預測詞還是消歧效果上,都要好于之前三種方法訓練的模型。通過兩種指標的對比,我們可以得出結論: 使用實詞標記2標注的訓練語料訓練Context2vec模型,模型性能得到了提升。
以上的結果都是用單一的k值得到的結果進行對比,不一定具有代表性。為了進一步說明結果所具有的代表性,我們將序號4得到的模型和序號1模型使用不同的k值(1~10)進行消歧得到的結果進行對比,通過對比發現,在不同的k值下,消歧效果基本都有所提升,符合我們之前得到的結論。
我們還和在SE-3做過消歧的其他系統進行了比較,結果如表14所示。

表14 不同系統在SE-3測試集的結果/%
從表14可以看出,最好的結果是由Ando[19]達到的,他使用了一種交替結構優化的半監督方法,過程十分繁瑣。而我們比它提升了1.2%,且方法簡單很多,僅僅需要在模型訓練好之后,應用一次k近鄰算法。而第二好的結果由Rothe 和Schutze[4]達到,他們通過向已有的系統中加入詞向量特征達到此結果,他們的主要目的是訓練詞義向量,沒有對詞義消歧做過于深入的研究,因此沒有達到超過Ando的消歧效果。SE-3評測的前兩名結果分別為2004 Grozea、2004 Strapparava。2006年達到了74.1%準確率之后,除了2015年達到了較好的效果之外,一直沒有超過Ando的消歧系統。2016 Melamud 提出的Context2vec模型使用k=1的k近鄰法得到的結果為72.8%,這是因為Melamud 提出的Context2vec在多種自然語言處理任務中都能得到較好的應用,沒有單獨對詞義消歧進行深入研究,我們將Context2vec在消歧上的應用進行了擴展,Ours-1是我們用未加詞性的Context2vec模型通過開發集選取參數k,取參數k=5時消歧效果最好,可以達到74.8%,Ours-2在Ours-1的基礎上加入了詞性特征,選取同樣的k值,可以看出,加入詞性特征之后,消歧準確率提高了0.5%。
在這一部分,我們使用了三種不同的詞性標記方式來標注訓練語料并訓練模型。其中前兩種無法達到未加詞性之前的效果,分析原因是虛詞在訓練語料中出現次數很多,它們是組成句子框架的主要成分,它們的詞性標記錯誤會給建模帶來更大的影響,而且這些詞的不同詞性表示的語義往往是相同的。而實詞標記2得到了比不加詞性更好的效果。
我們還在其他的測試集中對此方法進行了驗證,如SemEval-13 task 12 和 SemEval-15 task 13,由于此任務沒有提供每個消歧詞的例句,我們使用標記的SemCor和SemCor+OMSTI(One million sense-tagged instances)[18]中的例句作為訓練語料進行消歧。而Raganato[20]使用Context2vec和其他系統使用相同的訓練語料進行了比較,其中Context2vec在多個公開評測集中均取得了非常好的消歧效果。我們使用了與之相同的訓練語料,但是由于參數不同的原因,無法達到和Raganato相同的準確率。我們使用自己的參數,進行了對比實驗。只對加入實詞標記方法2的詞性特征前后的消歧結果進行對比。結果如表15所示。
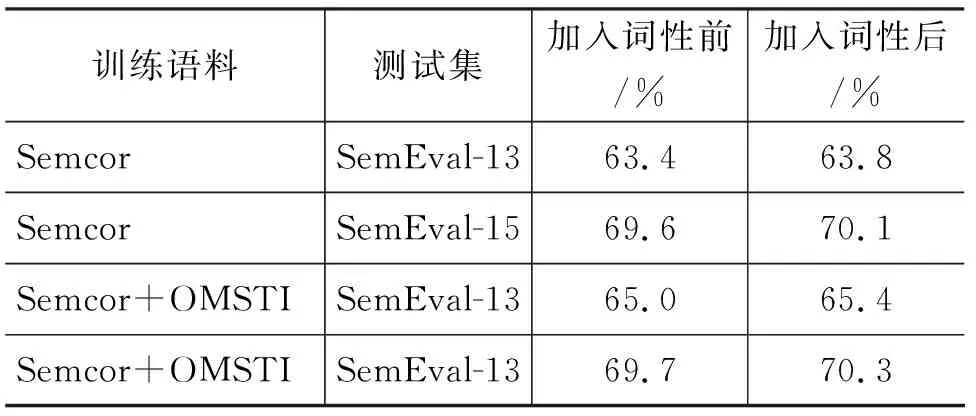
表15 加入詞性前后消歧結果對比
由表15中的結果我們可以發現,相比加入詞性之前,使用我們的方法加入詞性特征的消歧效果在兩個公開的測試集上也都得到了提升。其中SemEval-13和SemEval-15測試結果分別提升了0.4%和0.3%。提升效果不明顯的原因主要有兩個,首先每個目標詞對應的例句數量較少,其次是詞性標注的準確率限制了這種方法的作用。
5 結束語
我們通過實驗,提出了一種將詞性特征加入到Context2vec中建模的方法,更好地對語義進行建模,在消歧任務中達到了更好的效果,其中最好的結果已經比未加詞性之前提高了0.5%,并在多個國際公開評測集中有所提升。虛詞和代詞在句子中出現頻率很高,它們的詞性標注準確率對 Context2vec是否能在語義空間上正確建模起著至關重要的作用。而且虛詞的不同詞性語義是基本相同的,不需要在語義空間中分配多個點進行建模。由于詞性標注的準確率無法達到100%,而且同一詞性之間的細分準確率更低,限制了這種方法的作用。這種語境相似度消歧的方法依賴例句的質量和數量,可以考慮使用標簽擴展(LP)算法對例句進行擴展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
