基于協同過濾Attention機制的情感分析模型
2018-09-18 09:34:10趙冬梅陶建華顧明亮
中文信息學報 2018年8期
趙冬梅,李 雅,陶建華,顧明亮
(1. 江蘇師范大學 物理與電子工程學院,江蘇 徐州 221116;2. 中國科學院 自動化研究所 模式識別國家重點實驗室,北京 100101)
0 引言
情感分析旨在從文本中挖掘出用戶對某一熱點問題或者產品性能的觀點信息。在實際應用中不僅可以幫助電商企業評估產品的市場價值,也可以幫助政府部門做好輿情監控等任務。因此,文本情感分析越來越受到關注,并成為自然語言處理領域的重要課題之一[1]。
在傳統的情感分析中,研究者們往往只關注評論內容的重要性。根據絕大多數推薦網站上產品評論信息中提供的評價用戶信息及其喜好信息,可以發現同一用戶評論數據的情感極性比來自不同用戶的情感極性更傾向于一致。因此,將用戶及被評價的產品信息融入情感分類的任務中至關重要。
目前已有研究者考慮在模型中加入用戶及產品信息。例如,將用戶、產品以及評論數據特征基于詞袋模型輸入不同的分類器中進行探究[2]。也有使用概率模型獲取用戶的興趣分布和文本內容分布[3]。而隨著深度學習在計算機視覺、語音識別、自然語言處理領域的成功應用,基于深度學習的模型越來越成為情感分析的主流方法。通過神經網絡可以提取出文本中更豐富的語義信息以及包含的用戶、產品信息。但目前大多數模型都是將用戶和產品信息加入文本中一起輸入模型訓練,這樣不僅使評論內容失去原本的語義,且導致用戶個性等信息也沒能被提取出來。
由于成長環境、教育背景等差異,不同用戶的性格習慣存在一定區別。評價產品時,用戶會對喜歡的物品打高分,對不喜歡的物品打低分,但也存在用戶對喜歡或不喜歡的物品都選擇低分或者高分,這就凸顯了用戶的個性信息。本文提出LSTM-CFA模型,通過使用推薦系統中協同過濾算法從用戶和產品信息中提取出用戶興趣分布信息,并將此信息作為模型的注意力機制。在使用層次LSTM模型的過程中,指導詞語級別和句子級別的特征表示,以提高文檔級別的情感分類任務。
本文的創新點主要有以下兩個方面:
(1) 使用協同過濾算法,充分挖掘用戶的個性以及產品信息,將其作為模型的注意力機制。
(2) 使用奇異值分解(SVD)對稀疏矩陣進行優化分解,得到用戶個性矩陣和產品信息矩陣。
1 相關工作介紹
情感分析任務作為自然語言處理領域的重要課題之一,旨在從文本中挖掘出主題或者用戶觀點等情感信息。劃分出的情感類別可以是積極和消極,也可以像影評數據集中那樣使用0—10表示級別。
近幾年,由于神經網絡模型有較好的文本表示能力,開始被引用到自然語言處理領域解決實際問題。Hinton最早提出將非結構化的文本映射到低維實值空間中[4],演變成現在的詞向量。詞向量可以從文本中提取有效的語義信息并計算出詞語之間的相似性。Mikolov提出Word2Vec工具將獲取詞向量方法變得更加方便有效[5],隨后又提出了基于文檔的Paragraph工具,給文檔表示提供了很大的幫助。
在情感分類任務中,Socher等人使用一系列的遞歸神經網絡學習文本表示方法,包括遞歸自編碼模型(recursive autoencoders, RAE)[6]、矩陣向量遞歸神經網絡(matrix-vector recursive neural network, MVRNN)[7]、遞歸神經張量網絡(recursive neural tensor network, RNTN)[8],在斯坦福語料(Stanford sentiment treebank, SST)上獲得5.4%提高。Kim參考圖像領域的卷積神經網絡模型(convolutional neural network, CNN)修改并加入滑動窗口提取不同的文本特征,用來解決文本分類以及情感分類問題,取得很好的效果[9]。Kalchbrenner等人提出動態的CNN模型,使用動態的池化層處理不同句長的句子[10]。另外,循環神經網絡(recursive neural network, RNN)在時序數據上的不俗表現使其在自然語言處理領域廣受歡迎。Tai等人建立了樹結構的LSTM模型用來處理情感分類任務[11]。Tang等人構建層次的LSTM模型來表示不同級別的特征信息,在文檔分類任務中效果較好[12]。注意力模型可以模擬人類注意力運行機制在圖像領域取得不俗的表現,在自然語言處理領域中可以通過注意力機制從詞語或句子中提取出更重要的信息作為特征[13]。
2 模型及算法介紹
對比已有的基于用戶和產品的情感分析模型[14],本文提出了基于協同過濾注意力機制的情感分析模型(long short time memory cooperative filter attention, LSTM-CFA)。使用推薦系統中的協同過濾算法(cooperative filter, CF)以獲得用戶興趣分布矩陣,再將此矩陣作為LSTM模型的注意力機制(attention),模型結構如圖1所示。實驗主要流程為: 首先將訓練好的詞向量作為第一層LSTM模型輸入,將得到的隱藏層結合注意力機制表示成句子向量,再把句子向量通過第二層LSTM模型得到句子隱藏層,然后再次結合注意力機制得到文檔表示特征,通過全連層后利用softmax層完成情感分析工作。
2.1 基于層次LSTM特征表示模型
循環神經網絡可以通過鏈式神經網絡結構傳播歷史信息。在處理時序數據時,它每次能看到當前的輸入xt以及上一時刻輸出的隱藏狀態ht-1。 然而在訓練RNN時,發現反向傳播算法會導致在長距離傳輸過程中梯度彌散,當前信息無法傳遞到時間t以外的節點處,降低對歷史信息的感知力[15]。為了解決這個問題,Hochreiter等提出長短時記憶模型(LSTM)[16],并在自然語言處理領域有著很好的應用效果。
因此,本文使用層次LSTM分別表示句子級別特征和文檔級別特征。首先使用Word2Vec預訓練得到詞向量表示形式,將句中詞語嵌入低維語義空間。每一步中,使用詞向量xt作為輸入,此時的隱藏狀態ht和當前記憶門ct可以由之前的門狀態ct-1和隱藏狀態ht-1更新得到。具體過程如式(1)~式(6)所示。

同理,句子級別特征通過第二層LSTM模型后便可以得到文檔的特征表示。
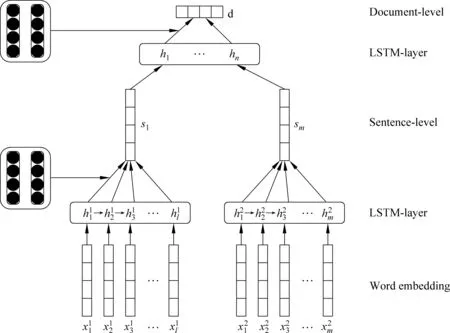
圖1 基于協同過濾的情感分析模型框架
2.2 基于協同過濾的注意力機制模型
協同過濾算法已被成功運用于許多推薦系統中[17]。主要分為,基于用戶相似性的協同過濾算法和基于物品相似性的協同過濾算法。本文使用基于物品相似度的方法,通過用戶對已用的物品評分來計算用戶對與該物品相似的物品評分,以預測用戶偏好分布并推薦物品。
2.2.1 用戶興趣分布矩陣計算
本文希望通過協同過濾算法獲得用戶興趣分布矩陣作為情感分析模型的注意力機制,文中矩陣計算步驟如下。
1) 構建物品之間的共現矩陣
共現矩陣是表示某一用戶喜歡或評分的物品列表集合。如用戶A評分過的物品有a、b、c、d,那么對于物品a而言,b、c、d均與a共同存在過,即在對應的矩陣中標1。同理,可以得到物品數量大小的方陣,其中數值表示兩物品是否在同一用戶下存在過。對于得到的方陣數值只有0或者1表示,為了計算方便,這里使用余弦相似度對共現矩陣做歸一化處理,如式(7)所示。
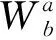
2) 建立用戶對物品的評分矩陣
將用戶對物品的評分構建成矩陣。矩陣行表示用戶,列表示物品,數值是某一用戶對某物品的打分情況。若沒有打分則記為0,打分則記為相應分數,矩陣形式如表1所示,其中ui列表示用戶(i=1…4),pj行表示產品(j=1…5)。
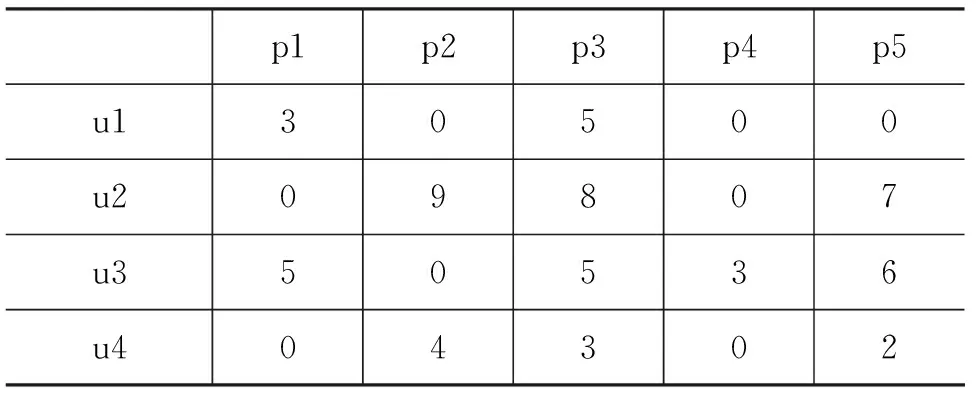
表1 評分矩陣形式
3) 計算得到用戶興趣分布矩陣
根據物品相似度以及打分情況通過式(8)便可以計算出用戶對沒有打分的物品的喜好程度。
其中,rui表示用戶對物品i的打分。
4) 用戶興趣分布矩陣分解優化
根據以上三個步驟便可以計算出用戶興趣分布矩陣,該矩陣維度大小為用戶數量乘以產品數量。當數據較多的情況下高維矩陣不僅會影響計算速度,也會存在稀疏可能。本文使用奇異值分解(SVD)分解法對高維矩陣進行分解處理[18],得到用戶興趣分布矩陣和產品屬性分布矩陣,如式(9)所示。
其中,A表示待分解矩陣,在這里指用戶興趣分布矩陣,U與VT是分解后得到的矩陣。在本文中表示用戶個性矩陣和產品屬性矩陣。
2.2.2 注意力機制模型
注意力機制(attention)是松散的基于人腦注意力的一種機制,在文本中通過自動加權的方法能夠有效的捕捉到文本中重要的信息。本文中使用用戶興趣分布矩陣作為注意力模型從隱藏狀態中提取對句子貢獻較大的詞語,用這些詞表征句子的特征。具體計算如式(10)~式(12)所示。
其中,Wh,Wu,Wp是權重矩陣,b表示偏置值,u,p表示用戶物品分布矩陣,可以通過奇異值分解用戶興趣分布矩陣得到。uij是打分函數,計算詞語的重要程度。通過softmax函數計算uw向量的權重值αij。 最后將αij與對應的隱狀態加權求和得到句子特征。
同理,句子在不同用戶不同物品間表達的意義也會有所不同,對于上述得到的句子特征后采用同樣的權重計算,即可以得到文檔表示特征d,如式(13)所示。
其中,βi表示句子中句子特征中第i個隱狀態hi的權重值,計算方式參考式(11)。
2.3 文檔情感識別
本文使用LSTM-CFA模型對文檔進行情感分析。使用預訓練得到的詞向量作為模型的輸入數據,使用協同過濾得到用戶興趣分布矩陣作為模型的注意力機制。在層次LSTM模型中與隱藏層狀態結合,提取重要信息組成文檔特征。
使用交叉熵損失函數作為優化目標函數,使用反向傳播算法計算并迭代更新模型參數,如式(14)所示。
3 實驗
實驗在三個帶有用戶和產品信息的情感數據集上對提出方法的有效性進行驗證。其中,實驗數據集的預處理部分主要將數據集按8∶1∶1比例分為訓練集、驗證集和測試集。
已有研究表明領域內語料可以讓詞向量擁有更多領域內的語義[19],因此本文使用Word2Vec工具在實驗數據上進行預訓練詞向量。實驗環境具體配置數據如表2所示。
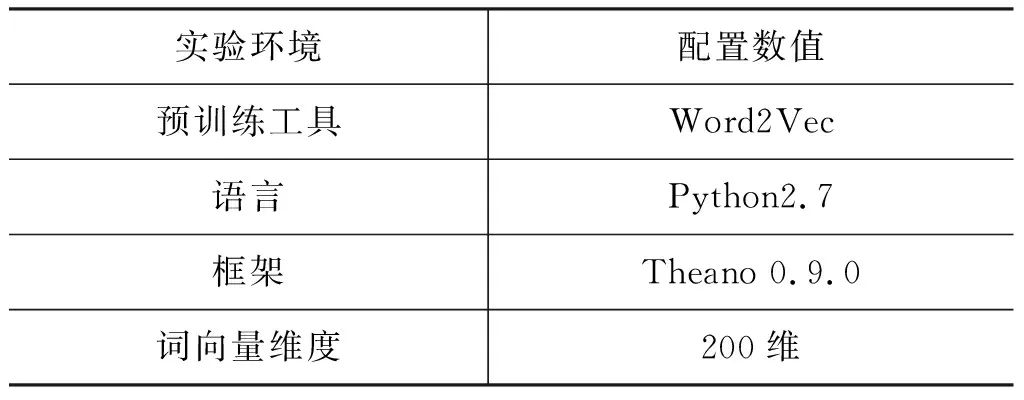
表2 實驗環境配置
3.1 數據集介紹
數據集來自: IMDB,Yelp2013,Yelp2014[20]。其中IMDB數據集是用戶對電影的評價內容,類別是類似豆瓣網站的星級評分制度,由最差1分至最好10分;后兩者是用戶對商家產品的評價信息。類似星級評價共有五個等級,從最差1分至最好5分制。數據集具體信息如表3所示。
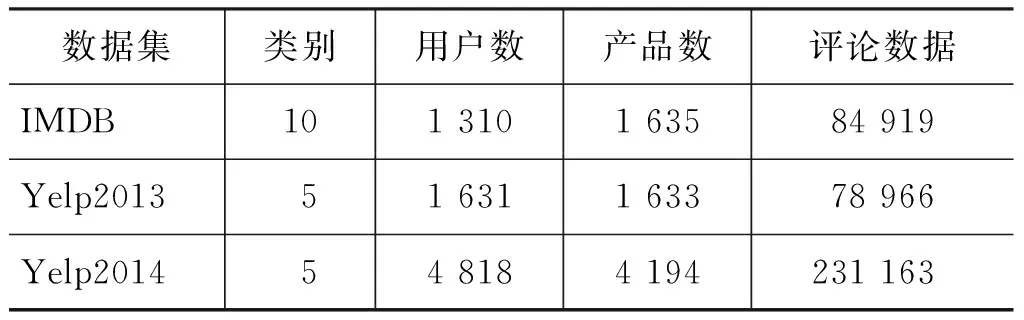
表3 數據集統計信息
3.2 評價指標
本文使用精準率(accuracy)衡量分類的整體效果,用平方根誤差(RMSE)衡量預測值和真值之間的離散程度。計算如式(15)~式(16)所示。
其中,T表示預測正確類別的數量,N表示文檔總數。gy表示預測值,py表示真實值。
3.3 實驗分析
實驗中的對比模型如下:
(1) Majority: 把訓練集中用戶使用主要的情感類別作為測試集數據的情感類別。
(2) Trigram: 使用unigrams、bigrams以及trigrams作為特征,輸入到分類器SVM中。
(3) TextFeature: 人工設計文本特征后使用SVM分類。
(4) AvgWordvec+SVM: 使用Word2Vec學習詞向量平均化后作為分類器SVM輸入數據[21]。
(5) SSWE(sentiment specific word embeddings) +SVM: 使用Word2Vec學習特定的情感詞向量后經過池化層的最大化平均化后輸入SVM中。
(6) Paragraph Vector: 使用PVDM解決文檔分類問題[20]。
(7) RNTN+Recurrent: 使用RNTN表示句子特征然后輸入到RNN中分類[8]。
(8) LSTM: 使用實驗中LSTM模型,沒有加入注意力機制。
(9) UPF(user product feature): 從訓練數據集中提取用戶信息特征和產品特征,然后聯合模型(2)~(3)進行分類[14]。
(10) UPNN(user product neural network): 使用用戶和產品信息輸入CNN模型中分類[22]。
(11) UPDMN(user product deep memory network): 使用深度記憶網絡融合用戶和產品信息[23]。
(12) LSTM+CBA(cognition based attention): 基于注意力的認知模型結合LSTM模型分類[24]。
(13) LSTM-CFA(Cooperative Filter Attention): 本文提出基于協同過濾注意力機制的方法。
表4中實驗結果由兩部分組成,其中第一部分表示模型在只考慮評論內容的情況下進行的驗證,第二部分表示加入用戶信息和產品信息后的實驗結果。從表4中可以看出:
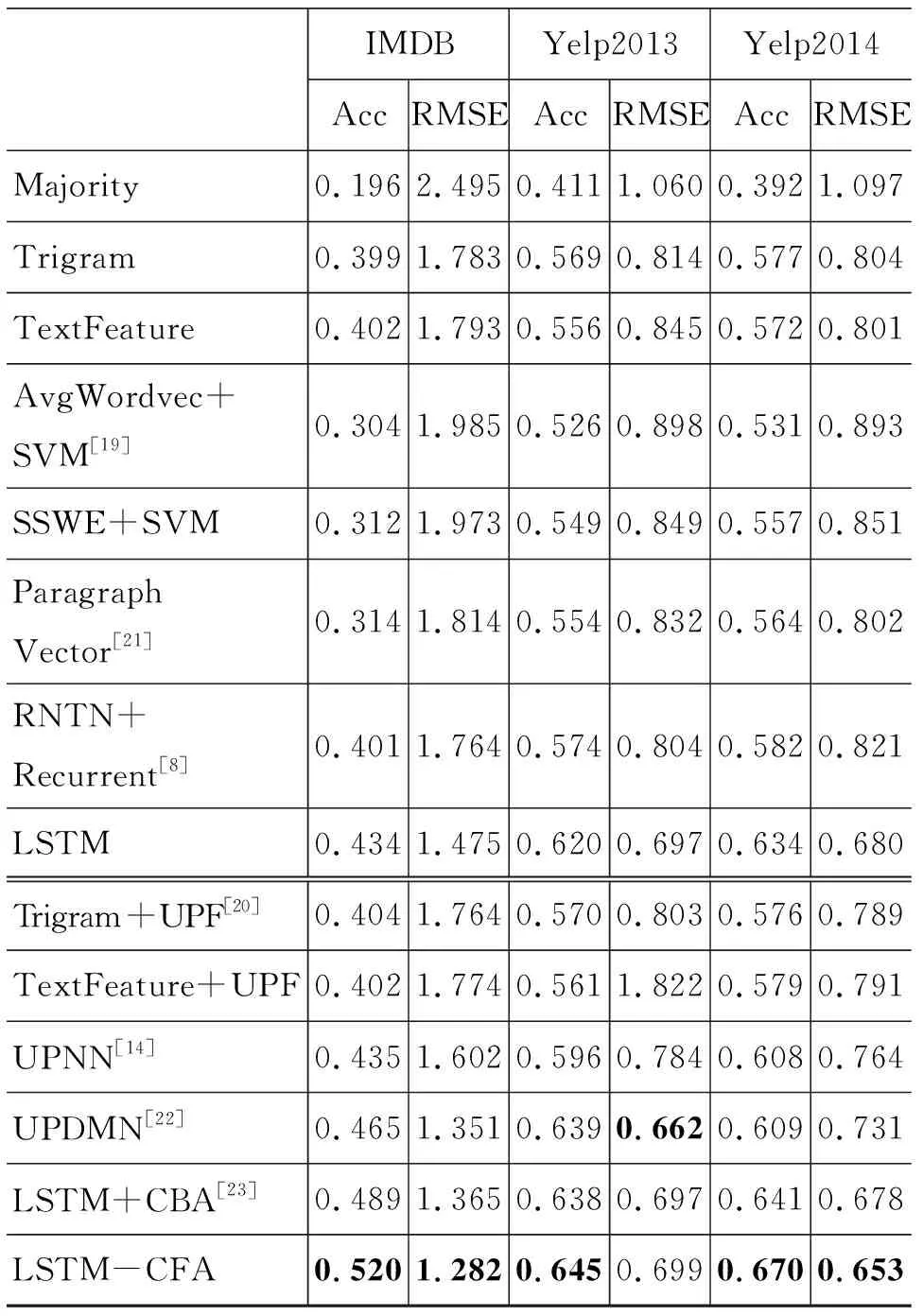
表4 實驗結果與對比
(1) 第一部分模型中既有傳統的機器學習方法也有神經網絡模型。在Yelp2013和Yelp2014數據集上神經網絡效果提升明顯,可以發現神經網絡與傳統機器學習相比可以提取出更多的文本語義信息。第二部分模型中加入用戶信息和產品信息后,神經網絡模型表現更加出色,在三個數據集上均有很大的提升,可見神經網絡模型在處理時序數據時可以表征出更加豐富的文本信息。
(2) 表4中第二部分中LSTM+CBA表示使用認知模型作為注意力機制,在Yelp2014數據集上提升3.2%精準率,可以發現加入模擬人類認知模型對實驗影響較大。本文提出在層次LSTM模型中加入協同過濾方法(LSTM-CFA),從用戶和產品信息中提取出更深層次的用戶個性和產品屬性等信息。在實驗效果中可以發現本文方法在三個數據集上精準率最高提升3.1%,驗證了本文提出方法的有效性。
(3) 表4中LSTM模型表示沒有使用注意力機制的模型。與加入注意力機制模型LSTM-CFA模型相比較,在三個數據集上分類性能均有明顯提升。其中,在IMDB數據集上有8.6%提升。可以發現加入用戶個性信息和產品屬性信息后,模型能夠更加準確地提取出文本中的信息,以表征文檔特征。這既驗證了本文加入注意力機制模型后的有效性,也表明在評論數據集中用戶和產品信息的重要性。
本文針對在協同過濾(CF)算法中得到的用戶興趣分布矩陣中的稀疏問題,進行了優化處理。表5是使用不同方法優化用戶興趣分布矩陣的結果的對比。其中CF-DC(direct cut)表示直接對用戶興趣分布矩陣進行截取,得到用戶信息矩陣和產品信息矩陣;CF-SVD表示直接使用SVD公式中Σ矩陣保留奇異值較大部分后再分別與U和V矩陣相乘,得到不同維度的用戶信息和產品信息;考慮到稀疏矩陣問題,CF-SVDS表示使用基于ARPACK庫進行奇異值分解,該算法主要針對大規模稀疏矩陣或者結構化矩陣進行特征值求解;CF-N(normalization)表示在方法CF-SVDS基礎上對用戶打分數據進行歸一化處理。由表中數據可以看出,在Yelp2013和Yelp2014數據集上方法CF-SVDS提升較明顯,在IMDB數據集上分數數據的歸一化處理效果較為明顯。由此驗證了本文中對用戶興趣分布矩陣進行優化方法的有效性。
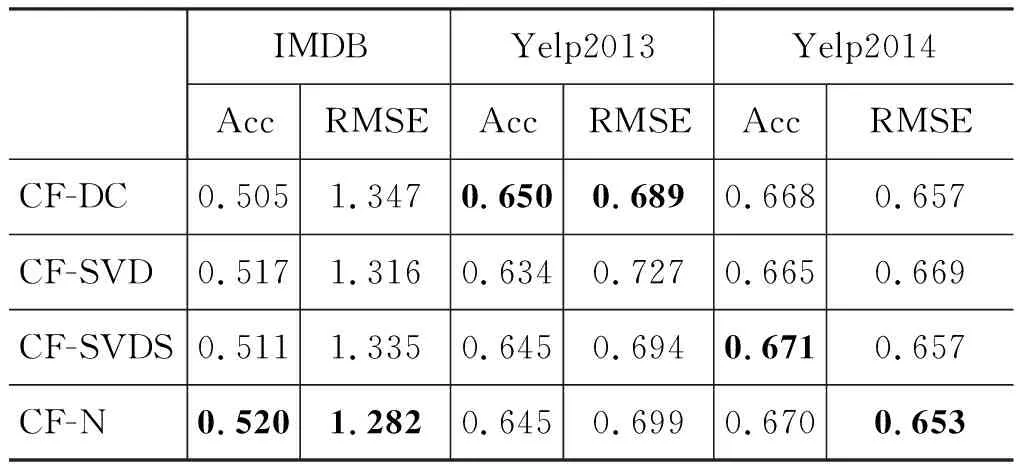
表5 不同優化方法對比
4 結論
本文提出了基于協同過濾Attention機制的情感分析模型。通過協同過濾中基于物品相似性方法構建用戶興趣分布矩陣作為模型注意力機制,并將經過SVD分解優化后的矩陣加入層次LSTM模型中。在詞語級別和句子級別中分別提取語義信息,以便更好地完成文檔級別情感分析任務。根據在三個數據集上實驗結果可以發現在神經網絡模型中加入協同過濾算法后可以表征更加豐富的文本信息,并且驗證了SVD分解優化的重要性。之后的工作我們將著力于進一步提升模型的泛化能力。例如,在小樣本、樣本類別不均衡的特殊情況下,擴展其適用范圍。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
