基于學生消費行為與成績的分析研究
2018-09-05 02:05:30
許昌學院學報 2018年8期
(許昌學院 信息化管理中心,河南 許昌 461000)
近年來,隨著高校信息化程度的不斷提升,校園一卡通系統發展迅速.一卡通系統可以為師生提供了很大的便利,可以方便他們進行購物,簽到等等,這些行為都會產生大量的相關數據.用機器學習算法在數據中發現隱藏的關聯性,可以對學校的管理工作提供一定的參考和幫助.在國內已經有很多高校開始了對相關數據的研究分析.王德才[1]等人利用SVM和Apriori關聯規則算法分析學生校園一卡通消費行為數據;羅擁軍[2]等人采用基于FP-Growth算法尋找學生的貧困程度與一卡通數據之間關聯關系的依據;徐劍[3]等人利用決策樹算法對一卡通的消費數據進行了聚類分析,并用關聯規則算法分析了學生的消費數據與學生成績之間的關聯關系;黎旭[4]等人使用決策樹為依據對消費行為的因素進行了建模和實現.
本文研究的是學生消費數據與學生成績之間是否具有隱藏的關聯性.首先對學生的消費成績進行規范化的處理,之后采用機器學習的算法對數據進行處理建模,根據模型和歷史數據對學生的成績進行預測,并和真實數據進行對比.
1 實驗數據預處理
一般而言,在數據中心存的數據都是沒有處理過的原始數據,可能會有各種各樣的問題,例如數據缺失,數據冗余等等造成對數據質量的影響.而數據質量又是會直接影響到模型訓練結果的關鍵因素.所以需要對原始數據進行處理.另一方面,隨著支付寶等移動支付的興起,越來越多的學生開始使用手機進行支付,這也導致了數據的缺失,這一問題可以從其他的維度想辦法考慮解決.
機器學習需要一個訓練集和一個測試集,訓練集用來訓練模型,測試集用來測試模型預測結果.把消費數據和成績化分為訓練集和測試集,以此來構建模型.首先來看原始數據.消費數據如表1所示,這一條數據包含某個卡號(ECARDNO)在某一天(OPDATE)消費了什么(CONPTYPE),吃飯的話吃的是哪一餐(DINTYPE)和消費數額(TOTALACCOUNT).成績數據如表2所示,每條數據包含學號(XH),科目名稱(KCMC),課程類別(KCXZ)和考試成績(QMCJ).
由于原始數據提供的信息有限,所以這里的想法是先對消費數據進行處理.按照機器學習的一般思路是將數據整理成一個學生一條數據,后面的字段則是某一時間段的消費信息,按照早中午飯分開計算平均消費和總消費,此外還要區分周末和平時的情況.這些年由于外賣的發展,所以肯定會造成有很多人出現沒有消費的情況,如果貿然使用這些數據可能會對預測的結果產生影響,所以這里會把沒有消費也當做一種類型來計算,如此生成訓練集數據.如表3所示.這里篇幅有限只列出了早上時段的所有數據.

表1 消費數據表單

表2 成績數據表單
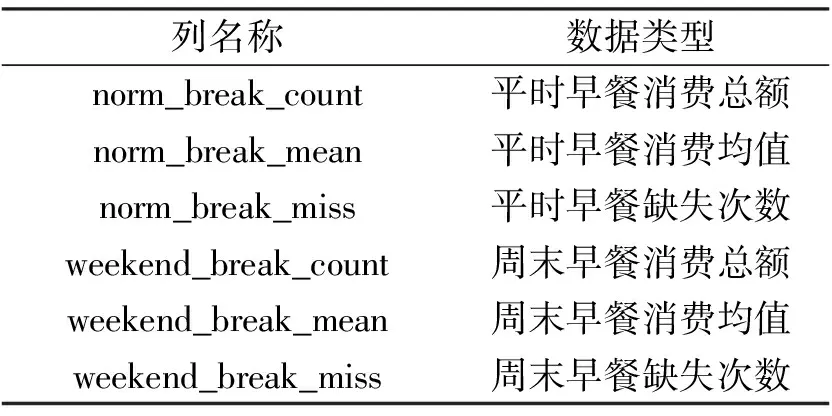
表3 處理后樣本數據
處理完數據之后,如圖1所示.首先看norm平時的數據,無論是總值count還是均值mean都有很多的數值為0.這有兩種可能,一是學生沒有去吃早飯,二是叫了外賣或者之前買的其他東西.這部分由于無法做交叉對比,所以不能確定是哪一種.但是可以將數值為0也當做一種類型,可以認為這個學生比較懶/沒時間,使用支付寶等等.Miss表示的是沒有吃早飯的次數,原因和上面一樣.Weekend周末的數據則有更多為0的數據,這也是符合學生周末出去吃飯的習慣的.這部分處理后的數據當做訓練集數據.
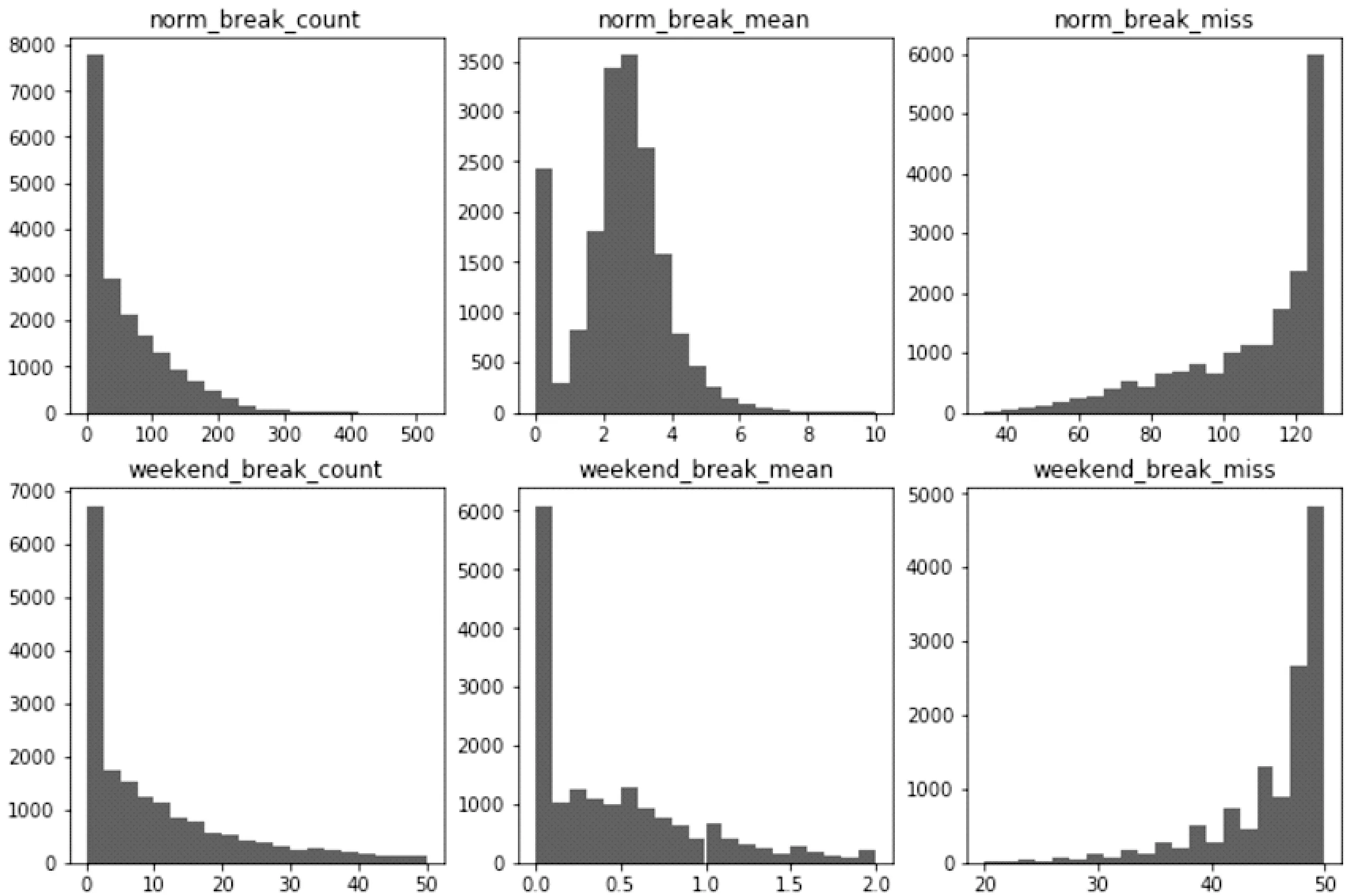
圖1 部分樣本數據分布圖
然后處理測試集數據,如表2,不同的學生可能有不同的課程和課程數量,所以需要一個統一的度量指標來衡量不同學生的差異.選用平均成績和掛科率這兩項可以比較好的對不同的學生進行比較.圖2中標有(origin)表示的是原始平均分和掛科率,如圖2可以看出平均分是一個長尾分布,一般來說長尾分布的數據是沒有意義的異常數據,結合掛科率的圖表來看,可以將這些數據去掉.圖2標有(processed)是處理過之后的數據,如圖可以看出平均分基本符合正太分布,掛科率則呈現了一個下降的趨勢.需要注意的是這里掛科率的橫軸是科目的數量.
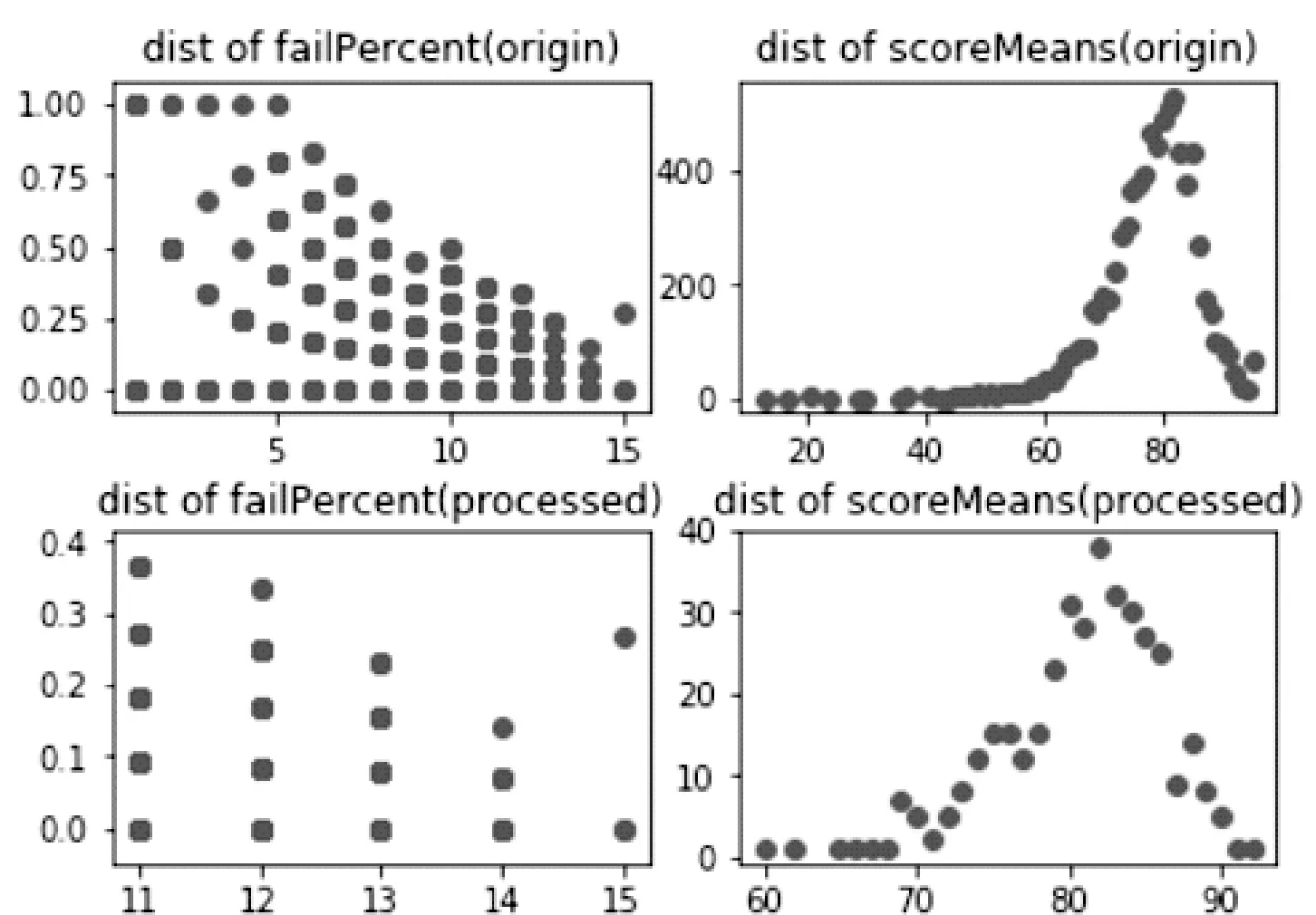
圖2 成績數據分布表
2 數據建模
本文是要研究學生消費數據與成績之間的潛在關聯性.所以以學生的掛科率和平均分這兩項作為研究對象.使用回歸和分類的算法,對數據處理建模來分析不同特征的重要性.回歸可以直接預測數值目標,而分類只能預測不同的類別,所以使用分類算法時候需要將數據處理一下,改成類別數據[5].將0~10%作為1類,10%~20%作為2類,以此類推最后90%~100%作為10類,這樣將預測問題轉換成一個多分類的問題.這里會出現精度的損失,如果需求更高的精度可以用 5個百分點作為一個類別來分類.
本文主要使用線性回歸(LinearRegression)來預測和隨機森林(RandomForest)來進行分類.下面簡單介紹一下這兩種算法.
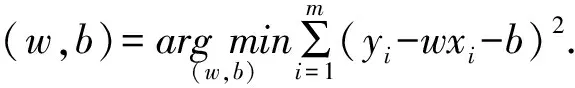
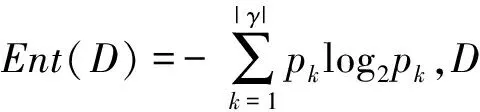
實驗使用python的sklearn工具進行模型的訓練和測試.使用前面說過使用平均成績和掛科率來對作為預測的結果.然后將數據分為訓練集和測試集.
首先使用線性回歸來訓練模型.將樣本數據和成績數據合在一起,按照75%來劃分訓練集,剩下的是測試集.之后調用sklearn的線性回歸模型來進行訓練,之后進行預測.線性回歸模型一般使用RMSE來評價預測結果的好壞.
它的值越小表示預策的精度越高,所以一般用它來衡量線性回歸預測結果.表4是線性回歸的RMSE得分.圖3是真實值和預測值的圖,實線是預測值,虛線是真實值.
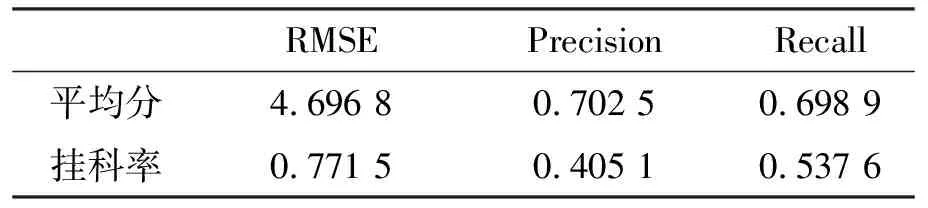
表4 預測結果評估結果
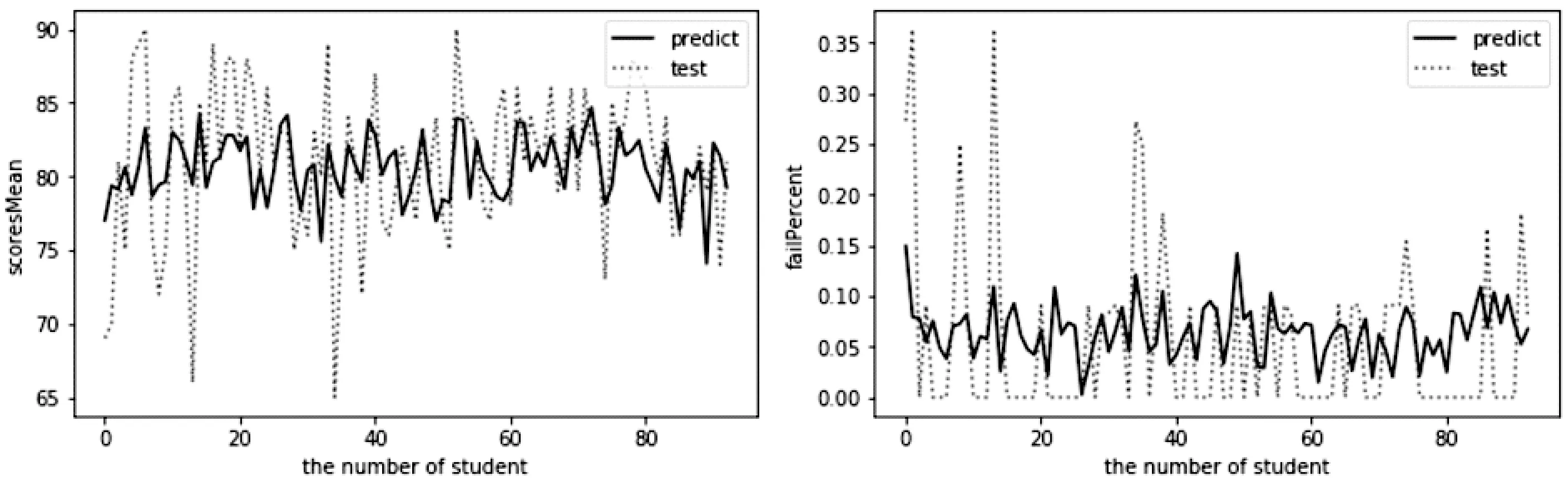
圖3 線性回歸預測結果圖
然后使用隨機森林訓練模型.由于隨機森林是一個分類的算法,所以需要把預測結果改成類別型數據.上面說過這里不再闡述.同樣將樣本數據和改成類別型數據的成績數據合在一起,按照75%來劃分訓練集和測試集.然后使用隨機森林模型訓練,之后進行預測.分類模型一般會使用召回率(Recall)和精準率(Precision)來檢驗預測效果的好壞[5].
綜合來看對于掛科率的預測使用線性回歸的效果較好,RMSE有0.771 5左右,而平均分效果略差一些.如果改為類別型數據,則只有平均分的效果較好,召回率和精準度均在70%左右,而掛科率的效果則不好.
3 結語
本文研究了學生消費行為和成績之間的關系,并嘗試使用了線性回歸和隨機森林算法對學生的成績進行預測.效果不錯,預測的評估結果均在可以接受的范圍之內.研究只限于消費行為,如果有其他合適的數據例如學生出入,或者是上課簽到數據等,那么相信效果會進一步提升.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
核科學與工程(2015年4期)2015-09-26 11:59:03
