基于反向策略和柯西分布的粒子群優化算法
2018-09-05 02:05:00
許昌學院學報 2018年8期
(內江師范學院 數學與信息科學學院,四川 內江 641112)
粒子群優化[1](PSO)是模擬鳥類捕食行為的仿生算法.該算法具有容易實現、收斂速度快等優點,在組合優化、聚類分析、神經網絡訓練等方面應用廣泛.但該算法易陷入局部最優,所以諸多學者利用余弦函數的對稱性對學習因子進行改進[2],或采用遞減指數和迭代閾值[3]、自適應方法[4]、柯西分布[5]等對慣性權重進行改進,均促進了算法的發展.為加快算法的收斂速度和提高全局搜索性能,本文提出基于混沌和反向策略產生初始解,利用柯西密度函數和柯西分布函數對算法進行改進,通過4個經典函數進行測試,并與文獻[2]、文獻[6]進行對比,仿真結果表明:改進算法的收斂速度更快,搜索結果更有效.
1 粒子群優化算法
在D維搜索空間中,由m個粒子組成,第i個粒子表示空間向量xi=(xi1,xi2, …,xiD)(i=1,2, …,m),即第i個粒子在D維搜索空間中的位置是xi,其速度為vi=(vi1,vi2, …,viD).記第i個粒子搜索到最好的位置為Pi=(pi1,pi2, …,piD),整個群體搜索到最好的位置為Pg=(pg1,pg2, …,pgD).粒子的速度-位置方程描述為
(1)
(2)
其中,w是慣性權重,c1和c2為學習因子,c1是“自身認知”,是對自身信息的利用;c2是“社會認知”,是群體間信息共享;r1,r2為[0,1]中服從均勻分布的隨機數.
2 基于反向策略和柯西分布的粒子群優化算法
2.1 基于混沌的反向策略機制
利用混沌運動的特點(初值的高度敏感性、遍歷性、隨機性)[7]進行初始化,可以使種群多樣化,避免過于早熟.文章采取Logistic映射進行混沌初始化,其表達式為
Xn+1=μ·Xn·(1-Xn),n=0,1,2,…,N,
其中,0 反向學習[8]指在搜索過程中,同時考慮當前解和它的反向解,當前解有一半的概率比它的反向解更遠離最優解,因此,采用基于當前解與反向解的精英選擇策略來進行初始化. 綜合以上改進,對改進辦法進行實驗:方法一,混沌與反向學習策略進行初始化;方法二,采用式(3)進行調整;方法三,采用式(4)對進行調整;改進算法,綜合方法一、二、三進行調整. 對于上述方法,通過4個典型測試函數來測試: 采用MatlabR2010b,環境:CPU為Intel(R)Xeon(R) E5,2.6 Ghz,內存為8GB,操作系統為Windows7SP1. 分別對方法一、方法二、方法三以及標準PSO進行測試,各運行1 000次后取平均值及標準差,規定:慣性權重為0.5,學習因子都為2,粒子數為30,空間維數為30,結果見表1、2.由表1可知,方法一對單峰函數的尋優效果較好,對多峰函數表現一般;方法二對4個函數的尋優效果都有一定的提高;方法三在Sphere、Griewank的尋優中表現良好.由表2可知,三種方法對解的穩定性均有改進,說明該算法有效. 表1 各方法的最優平均值 表2 各方法下的最優值的方差 參數設置為:文獻[6]中,c1,c2:1.5~2.5,w=1;文獻[2]中采用余弦公式進行參數更新;本文的改進算法采用之前的設置值.實驗結論如下:(1)針對單峰函數Sphere,改進算法每次都能找到最優值,但求解Rosenbrock時的改進算法弱于文獻[6],優于文獻[2];(2)針對多峰函數Rastrigin和Griewank,改進算法能夠找到最優值(表3),優于文獻[2]和文獻[6];最優值的方差優于文獻[2]和文獻[6](表4),這說明算法更加穩定.綜上所述,改進算法在收斂精度上有明顯提高,能夠避免陷入局部最優. 表3 不同粒子群優化算法的搜索結果比較 表4 測試函數的最優值的方差比較 針對算法易陷入局部最優的缺點,采用混沌和反向策略產生初始解,能使算法更好地覆蓋解空間,產生較好的初始解;利用柯西密度函數對慣性權重進行調整,利用柯西分布函數對位置更新公式進行調整,通過實驗來驗證三種調整方法的有效性.改進算法在尋優中表現更好,特別是在多峰函數中.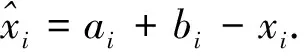
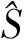
2.2 基于柯西密度函數的慣性權重調整

2.3 基于柯西分布函數的粒子位置更新
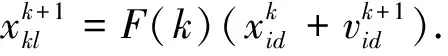
3 實驗結果與分析
3.1 測試函數與配置
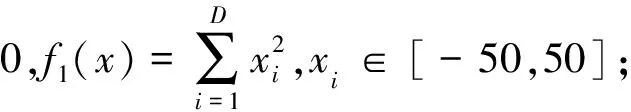


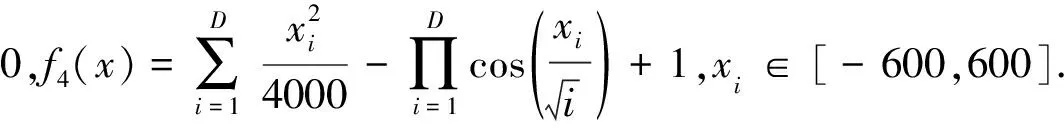
3.2 改進方法的有效性測試


3.3 改進算法的比較實驗


4 結語
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
