基于學習算法SSD的實時道路擁堵檢測
2018-09-04 09:37:16李超凡陳慶奎
軟件導刊 2018年6期
李超凡 陳慶奎

摘 要:隨著人們生活水平的不斷提高,道路車輛擁堵情況愈發嚴重。如何實時、精確地檢測出道路車輛,對于解決道路擁堵問題具有重要意義,GPU和人工智能技術的飛速發展為其提供了可靠的解決方案。研究分析傳統目標識別算法、基于候選區域深度學習的目標提取算法RCNN和基于回歸的深度學習目標檢測YOLO,最終確定采用基于卷積神經網絡的實時目標檢測算法SSD。首先調用VGG16網絡模型在ILSVRC CLS-LOC數據庫上預訓練生成初始網絡模型,進而設置超參數并在自身數據集上進行再訓練,生成新的網絡檢測模型,然后將訓練和測試部署到深度學習框架Caffe上加以實現。通過在數據庫COCO、VOC2012上的測試結果表明,該模型檢測精度為76%左右,處理速度為26FPS。同時通過道路路口的實地車輛檢測,顯示該算法能夠實時、精確地檢測出道路車輛,為道路擁堵情況判定提供可靠數據。
關鍵詞:GPU計算;擁堵檢測;卷積神經網絡;車輛檢測;SSD
DOI:10.11907/rjdk.173313
中圖分類號:TP302
文獻標識碼:A 文章編號:1672-7800(2018)006-0008-05
Abstract:With the continuous improvement of the people′s living standard, the congestion of road vehicles becomes more and more serious. How to accurately detect road vehicles in real time is of great significance to solve the problem of road congestion. The rapid development of GPU and artificial intelligence provides a reliable solution. We analyse the traditional target recognition algorithm, target extraction algorithm RCNN based on the candidate region deep learning and regression-based deep learning target detection YOLO, and finally we adopt the real-time target detection algorithm SSD based on convolutional neural network . First we call the VGG16 network model to pre-train the initial network model on the ILSVRC CLS-LOC database to set up hyper-parameters and retrain on their own data sets to generate a new network detection model and then deploy training and testing to the deep learning framework Caffe. Tests on the database COCO, VOC2012 showed that the model detection accuracy reached about 76%, the processing speed reached 26FPS. the final road junctions The field of vehicle detection in the road junctions proves that the algorithm can realise real-time accurate detection of road vehicles so as to provide reliable data about road congestion.
Key Words:GPU computing; congestion detection; convolutional neural network; vehicle detection; SSD
0 引言
隨著大數據、云計算、GPU等技術的發展,人工智能領域的相關技術和應用也不斷深入。圖像識別是人工智能領域的關鍵應用之一,其中基于視頻流的視覺目標檢測與靜態圖片視覺目標檢測是目前計算機視覺領域的研究熱點。隨著人們生活水平的提高,越來越多電子設備應用于人們生活中,其中數字圖像已成為不可或缺的重要信息媒介,時刻都在產生大量圖像數據[1]。如今對圖像中的類別進行精確識別和分類已變得越來越重要,而且不是僅對目標圖片進行簡單分類,而是希望將圖像中感興趣的區域提取出來并且作出精確判斷,例如現在比較流行的鑒黃軟件、十字路口的電子貓眼、犯罪分子的人臉識別等相關應用都離不開目標檢測技術的支持。因此,目標視覺檢測有著廣闊的應用前景[1],除智能視頻監控、機器人導航、汽車無人駕駛、嵌入式電子產品、數碼相機、人臉識別等技術外,目標檢測也為更高級的人體行為識別、圖像語義分割、事件檢測等提供了技術支持。本文即是應用相關目標檢測算法對道路路口車輛進行實時識別檢測。
1 相關工作
目前目標檢測領域相關算法主要分為3大類:①傳統目標檢測算法,例如HOG[2](Histogram of Gradient)+SVM(Support Vector Machine)、SIFT[3](Scale-invariant Feature Transform)、前景提取等;②RCNN系列基于候選區域的深度學習目標檢測算法,如RCNN[4]、FAST-RCNN[5]、FASTER-RCNN[6]、RFCN[7];③基于回歸方法的深度學習目標檢測算法,如YOLO[8]、SSD[9]等。目標檢測算法大致分類如圖1所示。
(1)HOG、SVM、DPM等傳統目標識別算法不需要訓練,但檢測精度不高,而且處理速度非常慢。
(2)RCNN系列基于候選區域的深度學習目標檢測算法,從RCNN[4]、Fast-RCNN[5]、Faster-RCNN[6]、RFCN[7]速度依次變快,而檢測精度相差不大。RCNN檢測精度略高,但該算法存在的一個最大問題是處理速度慢,每秒大概5幀,無法達到實時性要求,而且需要分開訓練,處理復雜,步驟耗時,生成的圖片文件占用磁盤空間較大。如圖2所示為基于候選區域的深度學習檢測算法基本流程。
(3)基于回歸的深度學習目標檢測算法,主要包括YOLO[8]、YOLO2和SSD[9]等相關算法,其中YOLO[8]算法實際上是結合RCNN系列算法作出的改進,即在犧牲精度的情況下提高了處理速度。YOLO的處理速度在每秒30幀左右,精度為65%左右,相比于RCNN的75%降低了不少;SSD算法網絡模型進行的目標檢測,與YOLO相比,在保持速度不變的情況下提高了精度,其精度甚至比RCNN系列更高。SSD使用卷積神經網絡對圖像進行卷積后,在不同層次的特征圖上生成一系列不同尺寸與長寬比的邊框,該網絡對于每一個邊框中物體類型的可能性進行了預測,并且可以調整邊框形狀,以適應相應的目標物體形狀大小。最后在PASCAL VOC、MS COCO和ILSVRC數據集上進行測試,實驗顯示其平均精度在75%左右。而本文即針對預訓練的SSD網絡模型進行改進,并在自己數據集中訓練生成新的網絡模型,并進行實地的檢驗測試。實驗結果表明,該方法能夠準確提取出道路車輛特征,檢測出道路擁堵情況。
2 SSD基礎原理
2.1 車輛目標任務構建
本文任務是通過在道路十字路口安裝攝像頭,實時采集視頻,即通過視頻流方式實時檢測路口車輛。
2.2 SSD網絡模型
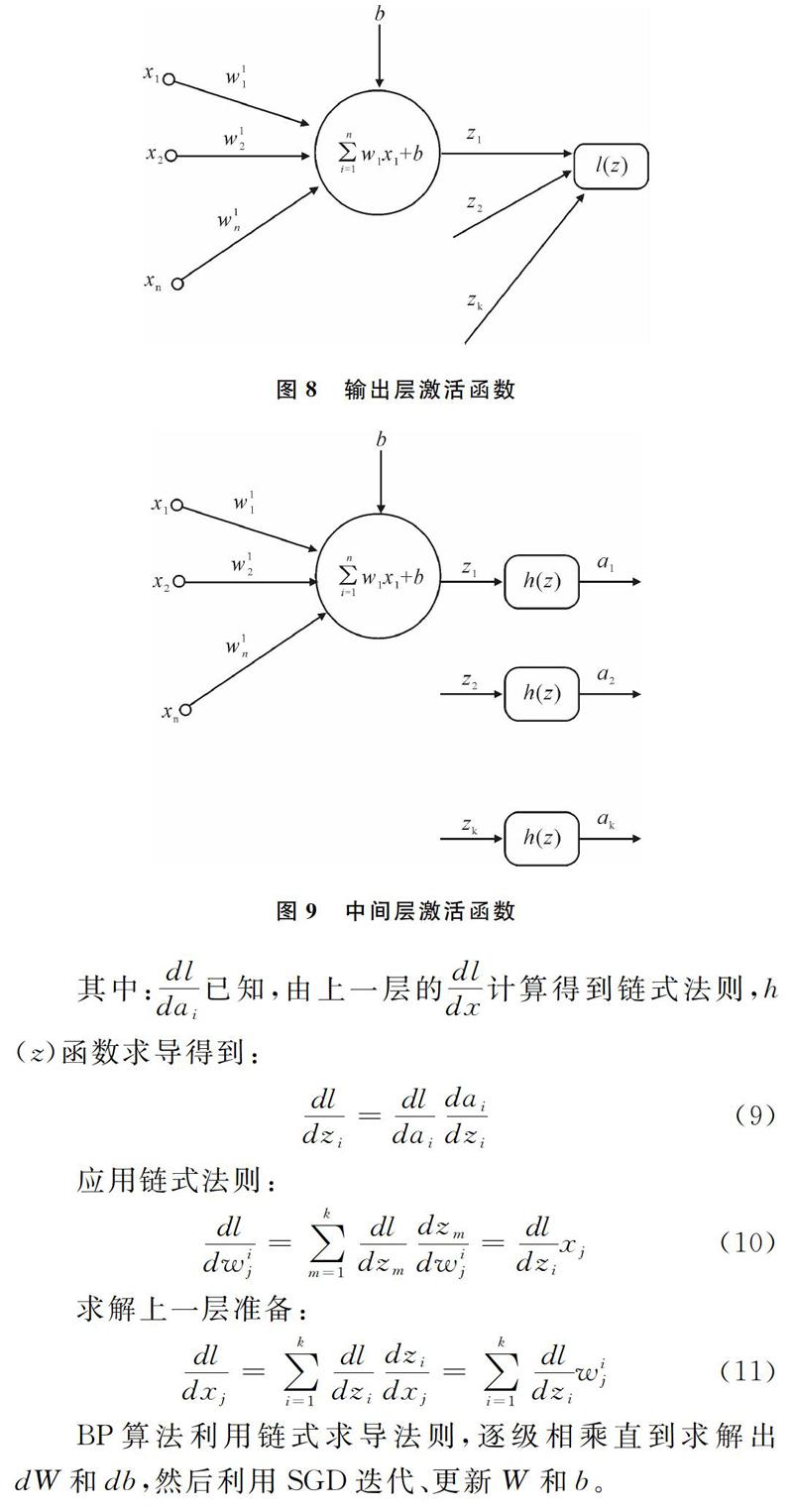
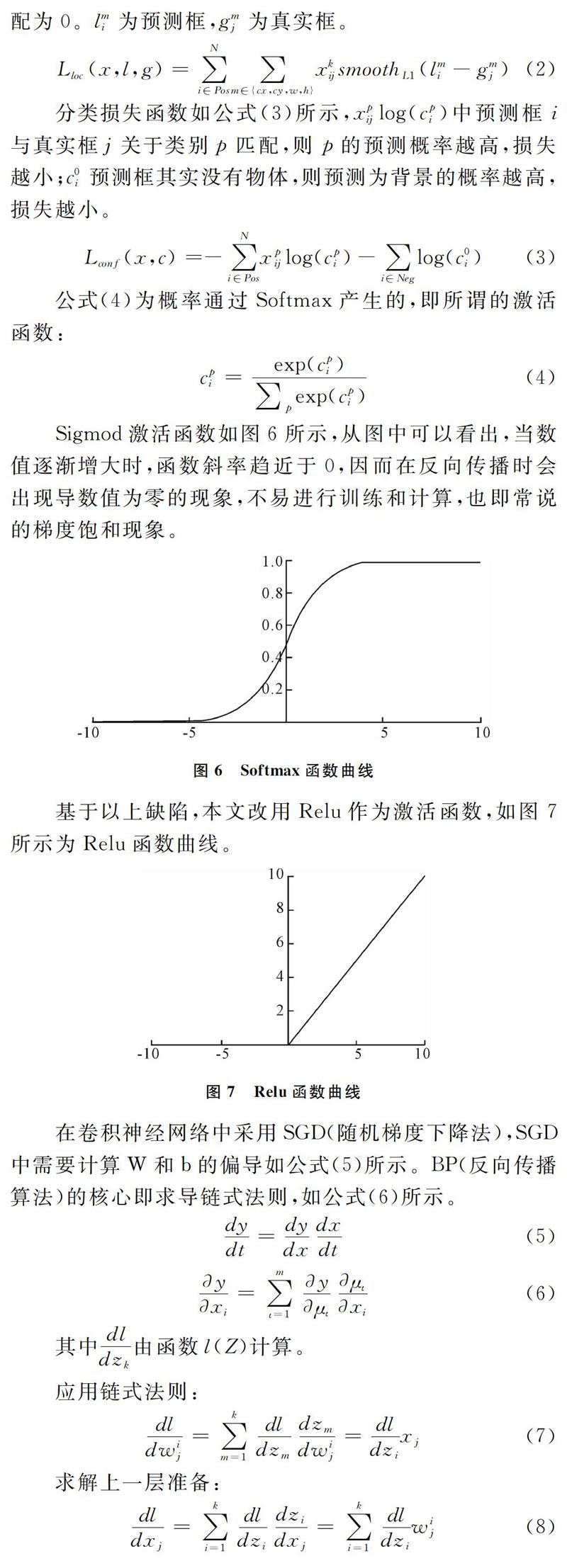
SSD(Single Shot MultiBox Detector)是一個單一的檢測器,能夠識別多個物體,其核心是預測固定集合的類別分數和盒偏移,并使用應用于特征映射的小卷積濾波器的默認邊界框。如圖4所示為一張圖像中含有多個特征圖在不同比例下的檢測框,在訓練期間,SSD只需要一個輸入圖像和地面實框圖。在卷積中,評估一個小集合在具有多個特征圖的情況下,每個位置處不同縱橫比的默認框。對于每個默認框,預測所有對象類別((c-1,c-2,…,c-p))的形狀偏移和置信度,訓練時首先將這些默認框與實際框圖進行匹配。例如,本文匹配了兩個默認框貓和狗,它們被視為感興趣區域,其余作為不感興趣區域。另外,模型損失是本地損失(例如平滑L-1[10])和置信損失(例如Softmax)之間的加權和。
SSD方法是基于前饋卷積網絡,在這些框中的實例有一個固定大小的邊界框集合和用于存在對象類的分數,最后通過非最大抑制步驟產生最終檢測結果。之前的網絡層基于標準架構用于高質量圖像分類,如圖5所示為SSD網絡結構,SSD通過使用VGG-16-Atrous作為基礎網絡,Conv8_2 Conv9_2 Conv10_2 Conv11_2作為特征提取層。SSD與YOLO的不同之處是,除在最終的特征圖上進行目標檢測外,還在之前選取的5個特征圖上進行預測。如圖5所示為SSD網絡預測示意圖,檢測過程不僅在添加特征圖(conv8_2, conv9_2, conv_10_2, pool_11)上進行,為了保證網絡對小目標的檢測效果,檢測過程也在基礎網絡特征圖(conv4_3, conv_7)上進行。
2.3 SSD訓練算法介紹
訓練算法和一般的機器學習訓練算法相同,首先定義損失函數,即衡量與實際結果間的差距,然后找到最小化損失函數的W和b。根據SSD訓練網絡結構,可以知道GT標簽在分特征圖上生成priorbox,再將所有priorbox組合為mbox_priorbox,作為所有默認框的真實值。
預測過程會在選取的特征圖上進行兩個3×3卷積,其中一個卷積層輸出每個默認框的位置(x, y, w, h)4個值,另一個輸出每個默認框檢測到不同類別物體的概率,輸出個數為預測類別個數。再將所有默認框位置整合為mbox_loc,并將所有默認框預測類別的向量組合為mbox_conf。mbox_loc、mbox_conf為所有預測默認框,將其與所有默認框的真實值mbox_priorbox進行損失計算,得到mbox_loss。SSD的損失函數如公式(1)所示,由每個默認框的定位損失與分類損失構成。
Sigmod激活函數如圖6所示,從圖中可以看出,當數值逐漸增大時,函數斜率趨近于0,因而在反向傳播時會出現導數值為零的現象,不易進行訓練和計算,也即常說的梯度飽和現象。
基于以上缺陷,本文改用Relu作為激活函數,如圖7所示為Relu函數曲線。
在卷積神經網絡中采用SGD(隨機梯度下降法),SGD中需要計算W和b的偏導如公式(5)所示。BP(反向傳播算法)的核心即求導鏈式法則,如公式(6)所示。
BP算法利用鏈式求導法則,逐級相乘直到求解出dW和db,然后利用SGD迭代、更新W和b。
2.3 SSD訓練過程
本文采用一個SSD預訓練模型,將預訓練模型在自己的數據集上進行訓練,生成全新的檢測模型。
首先,準備原始數據。數據集要滿足以下格式:–Annotations ***.xml(標注的物體信息文件);--Images ***,jpg(圖片集);--ImageSets test.txt(測試集) train.txt(訓練集);--results (null)(作為保留結果)
其次,生成訓練數據集。具體步驟為:
(1)將VOC0712目錄下的create_data.sh labelmap_voc.prototxt create_list.sh三個文件復制到數據集目錄下。
(2)修改create_data.sh內容。
root_dir=/home/sea/caffe (指定SSD目錄)
data_root_dir="MYMHOME/caffe/data/Fruit4"(指定原始數據集路徑)
dataset_name="Fruit4"(將要生成的數據集名稱)
mapfile="MYMroot_dir/data/MYMdataset_name/labelmap_fruit4.prototxt"(標簽映射,注意labelmap_***.prototxt與自己修改的文件名稱相對應)
(3)修改create_list.sh內容。
root_dir=MYMHOME/caffe/data/Fruit4(原始數據集路徑)
sub_dir=ImageSets(保存train.txt和test.txt目錄名稱)
sed -i "s/^/\Images\//g" MYMimg_file(保存圖片目錄名稱)
sed-i"s/^/\Annotations\//g"MYMlabel_file (保存標注目錄名稱)
if [ MYMdataset == "test" ](這里對應test.txt)
if [ MYMdataset == "train" ](這里對應train.txt)
(4)修改labelmap_***.prototxt內容。
沒有順序要求,background不需要更改,打開文件即知如何修改。
(5)運行create_list.sh,會看到數據集目錄下生成test.txt train.txt test_name_size.txt。
(6)運行create_data.sh,可看到數據集目錄下生成文件中指定的新數據集(例如Fruit4),該目錄下保存了lmdb文件,并在example/Fruit4目錄下生成lmdb軟鏈接。
最后開始訓練。首先復制一份example目錄下的ssd文件夾,修改ssd_pascal.py內容,然后運行python example/fruit4/ssd_pascal.py,可以看到網絡已開始訓練,訓練模型保存在models/fruit4_models_fruit4_300×300目錄下。
3 實驗結果與分析
本文實驗都是通過基礎網絡VGG16[11],在ILSVRC CLS-LOC[12] 數據庫預訓練得到初始模型,然后在自己數據集上再次進行訓練得到最終的車輛檢測網絡模型。與DeepLab-LargeFOV[13]相似,本文將fc6和fc7轉換為卷積層,并且從中抽取樣本參數,將pool5 從2*2-s2變為3*3-s1;使用trous算法填充漏洞,并且刪除所有的dropout層和fc8層;設置初始學習速率為0.001,動量為0.9,重量衰減為0.000 5,batch size為32,每個數據集的學習速率衰減策略略有不同;然后針對自己的數據集進行訓練,完整的訓練和測試代碼均建立在深度學習框架Caffe[14]下進行;最終生成訓練好的網絡模型,在coco數據庫中檢測精度為76%。
本實驗使用的處理器為Intel(R)Core(TM)i7-3770,4核8線程,主頻3.4GHz,內存32G;顯卡采用NVIDIA GTX970,顯存4G;操作系統ubuntu16.04,CUDA版本8.0,OpenCV版本為2410,Python版本為Anaconda 3.6,實驗圖片規格統一為300*300。
因為SSD是一個目標檢測網絡模型,可以檢測多種目標,如圖10所示為上海金橋中心某一路口檢測車輛的情況。
如圖11所示同為金橋中心某一路口的檢測情況,其中將檢測到的類別用方框框出并標出具體類別和置信度。在試驗中設置了檢測車輛和行人兩種類別,檢測結果顯示,其基本能夠識別出行人和車輛。
如圖12所示為上海延安路某一路段的檢測情況,該實驗不僅標出了類別與置信度,而且顯示出運行速度。速度大概為每秒26幀,可達到實時處理要求。
4 結語
本文對現階段相關的目標檢測算法及其相應的設計、訓練難度、檢測效果、價值可用性等方面進行了全方位對比,提出一種基于學習算法SSD的實時車輛檢測模型,并給出該模型搭建、損失函數求解、訓練過程實現及測試等相關步驟,然后將模型的訓練測試代碼在深度學習框架Caffe上加以實現,最后在不同路口場景下進行實驗分析。實驗結果表明,該目標檢測模型可實時對道路車輛擁堵情況進行精確檢測,精度為76%左右。系統具有安裝方便、檢測精度高、性價比高等優點,對于后續道路路口車輛的擁堵檢測研究具有一定參考價值。
參考文獻:
[1] 張慧,王坤風,王飛躍.深度學習在目標視覺檢測中的應用進展與展望[J].自動化學報,2017,43(8):1290-1304.
[2] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C].Computer Vision and Pattern Recognition, 2005:886-893.
[3] LOWE D G.Distinctive image features from scale-invariant keypoints [J].International Journal of Computer Vision, 2004,60(2):91-110.
[4] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutionalnetworks for visual recognition [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2015,37(9):1904-1916.
[5] GIRSHICK R. Fast R-CNN [C].Proc of IEEE International Conference on Computer Vision,2015:1440-1448.
[6] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C].Advances in Neural Information Processing Systems,2015:91-99.
[7] DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks [C].Neural Information Processing Systems, 2016:379-387.
[8] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, realtime object detection [C]. Proc of IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[9] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C].Proc of European Conference on Computer Vision, 2016:21-37.
[10] GIRSHICK R. Fast R-CNN[C].ICCV,2015:1440-1448.
[11] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. NIPS,2015.
[12] RUSSAKOVSKY O, DENG J, SU H,et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision , 2014,115(3):211-252.
[13] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]. Computer Science, 2014(4):357-361.
[14] 深度學習:Caffe實戰[N].中華讀書報,2016.
(責任編輯:黃 健)
