基于SVM的洋河張家口段水質評價
2018-08-31 04:50:10郭美葉
水利科技與經濟 2018年1期
郭美葉
(河北省張家口水文水資源勘測局,河北 張家口 075000)
1 概 述
水是人類生存發展和維系生態系統正常運轉的基質[1],也是地球陸地表層生物、物理、化學能量與物質遷移轉化最活躍的場所之一[2],水環境質量對環境變化及人類活動的響應十分敏感。在全球變化的背景下,水質量受環境污染、氣候變化、水侵蝕、人類不合理開發利用的干擾愈來愈烈。水體質量評價主要反映了水體的生物、化學、物理等綜合條件狀況,為水質量的優化管理提供依據。
隨著機器學習、神經網絡等現代數據挖掘算法的應用與推廣,就水環境質量評價方法而言,逐漸由傳統的模糊隸屬度函數評價法轉化為模式識別法。學者對灰色GM模型、可拓分析、BP和RBF神經網絡等評價方法進行了嘗試,并取得一定成果[3-6]。但傳統評價方法注重回歸分析和時間序列模型分析,不能全面、科學地反映各項要素之間內在機理,損失信息量較大,難以取得較好的評價效果,而神經網絡方法又不能很好解決小樣本、非線性、高維數和局部極小等問題[7]。支持向量機(Support Vector Machine,SVM)作為一種新的機器學習方法,避開了從歸納到演繹的傳統過程,實現了從訓練樣本到預報樣本的“轉導推理”[8],而且其采用的風險最小化準則有效克服了神經網絡的固有缺陷,已被很多學者運用于圖像解譯、語音識別、文本分離,并取得了良好效果。據此,本研究嘗試運用SVM分類模型,以陜西省為例,對其水質發展趨勢予以模擬與評價,以期為陜西省土地生態規劃提供實踐經驗和理論依據。
2 材料與方法
2.1 研究區概況
洋河為桑干河支流之一,是北京官廳水庫重要水源。其貫穿張家口多個縣區,流域跨度介于E113°50′~E116°30′,N39°30′~N42°10′。區域屬于低山向階地、盆地過渡區,海拔在500~800 m之間,高程相差不大。由于地形抬升和盆地效應,在迎風坡段降水較豐,多年均降水量為330~400 mm。洋河張家口段水源補給主要為降水和地下水,由于區域暖干化趨勢加劇,地表水域萎縮、水流活性下降。近年來,隨著張家口城鎮化、工業化發展日趨深入,工業三廢、農用污水、生活廢物排放增多,對地表徑流、地下水造成一定污染,當前眉縣段渭河水質質量堪憂。
2.2 采樣分析
為了便于全面掌握洋河張家口段水環境質量概況,按照全局性、均勻性、一般性的布點原則,并且考慮河段附近的土地利用類型、工業分布、支流狀況等,在河段干流上設置45個監測面。監測時間為2016年10月,在每個監測點約10 m2的范圍進行隨機采集3~5水體樣本,混合均勻后帶回實驗室進行化驗分析,同時應用GPS儀記錄樣點的經緯度坐標。監測的指標有溶解氮(DO)、高錳酸鉀指數(COD)、氨氮(NH4-N)、總磷(TP)、總氮(TN)。其中按照《水質高錳酸鹽指數的測定》(GB/T 11892-1989)對各項指標測定, DO以硫酸鉀濕氧化法測定,COD以草酸鈉法測定,氨氮(NH4-N)以納氏劑分光光度法,TP以碳酸氫鈉浸提—鉬銻抗比色法,總氮以半微量凱氏法測定[9]。
2.3 支持向量機算法
支持向量機(Support Vector Machine,SVM)是由Vapnik[10]提出的基于統計學習理論的一種新的機器學習方法,其利用某一種預先選擇的非線性映射將輸入向量映射到一個高維特征空間, 并在該高維特征空間構造出最優分類超平面, 最后利用該超平面進行擬合或分類。SVM評價分析則是利用其回歸算法。對于樣本數據[xi,yi],其中i= 1,2 …,n,n為樣本數據總數,xi∈Rn為樣本輸入,yi∈R為樣本輸出期望值。SVM的回歸函數描述如下:
f(x)=ω·φ(x)+b
(1)
φ∶Rn→G,ω∈G
對優化目標函數求極值:
(2)
式中:C為懲罰系數;Remp(f)為損失函數;設定ε不敏感函數為損失函數,則ε定義如下:
Lε(d,y)=|f(xi)-yi|-ε
(3)
其中,|f(xi)-yi|>ε

(4)
s.t.yi-[ω·φ(xi)+b]≤ε+ξi

(5)
將上式帶入SVM回歸方程,即可得到相關樣本輸出值,即:
(6)
由于SVM理論只考慮高維特征空間的點積運算K(xi,x)=φ(xi)·φ(x),不直接使用映射函數,所以式(6)表達為:
式中:K(xi,x*)為核函數。
常用的核函數有:線性核函數、多項式核函數、RBF核函數和Sigmoid核函數等。
2.4 基于支持向量機模式識別水體質量評價模型
應用支持向量機算法對16個監測樣點的水質進行模式識別,其關鍵在于基于水體測定的單一指標豐度與水質等級之間的聯系構造分類規則,建模過程如下:
Steep1:依據地表水環境質量分級標準(GB 3838-2002)[11]確定區域水體單一指標與水體質量的綜合評價分級準則,見表1。由于該分級標準為國家標準,因而具有廣闊的適用性和客觀性、規范性。另外,以DO、COD、NH、TP、TN等單一指標組建的水體質量評價體系代表了水體絕大部分性質,能夠較好地反映水體綜合質量。

表1 地表水環境質量的分級標準Table 1 The classification standard of five kinds of the evaluated soil nutrients
Steep 2:基于樣本地表水環境分級標準生成樣本數據與確定模型準則。樣本數據的生成應用runif函數,在各等級區間進行內插,每個區間生存100組數據,其中每一個等級內均包含該等級內水體單一指標數據。各單一指標如果隸屬于同一類別,則表明該水質也屬于這個級別,以此確定模型準則,這是應用支持向量機算法進行水體質量模式識別的主要內涵。
Steep 3:模型參數優化選擇。 客觀來講,模型參數對于模型的精度有著顯著影響,為了提供保證評價效果,對模型參數調優是極有必要的。由于該SVM模型屬于非線性分類,需要確定懲罰因子cost和核參數gamma。根據訓練誤差最小原則,選取最優cost為16,最優gamma為2,見圖1。

圖1 SVM模型表現與參數Fig.1 The performance and parameters of SVM
Rank一二三四五一1000000二0100000三0010000四0001000五000199
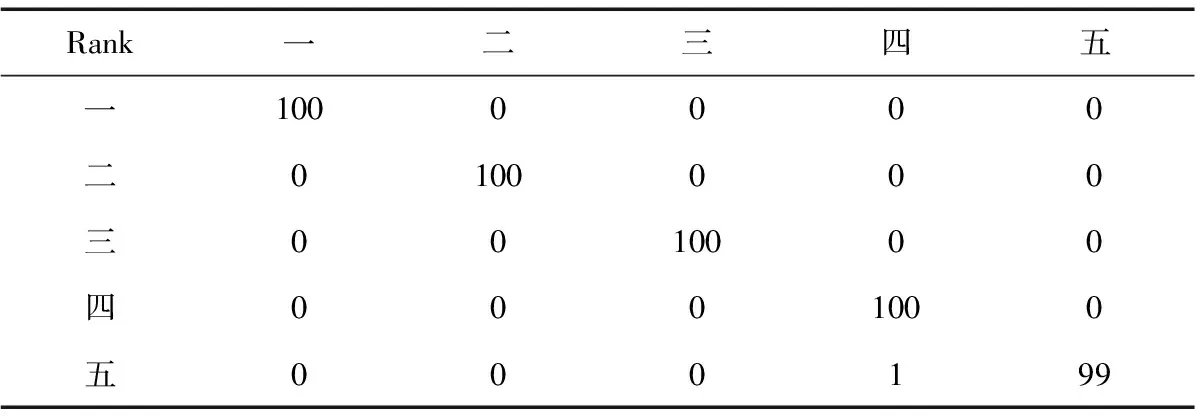
Steep 4:模型精度評價。表2中,對角線中數字為分類正確的樣本數,矩陣中其他數字為分類錯誤的樣本數。SVM算法內含判別函數,能夠直接顯示模型分類精度的結果,SVM模型對各級水化學肥力的判別正確率為999.9%。綜合而言,SVM模型分類精度較高,具有良好的模式識別能力,能夠用于對新的樣本數據進行分類評價。
Steep 5。將訓練好的水質評價模型對研究區16組水養分數據進行識別,以綜合評價研究區水化學質量。
2.5 其他數據處理與空間制圖
水體化學指標描述性分析與相關性分析在SPSS19.0中進行。基于支持向量機模式識別的水體質量評估模型的數據生成在R3.3.1中運用runif函數完成,模型構建與分類識別R3.3.1軟件中Support vector machine包中進行。此外,將SVM機器學習模型評價識別的洋河張家口段16個水樣點進行分類。
3 結果與討論
3.1 水體單一指標描述統計分析

3.2 水體各項監測指標間相關性分析
見表4。
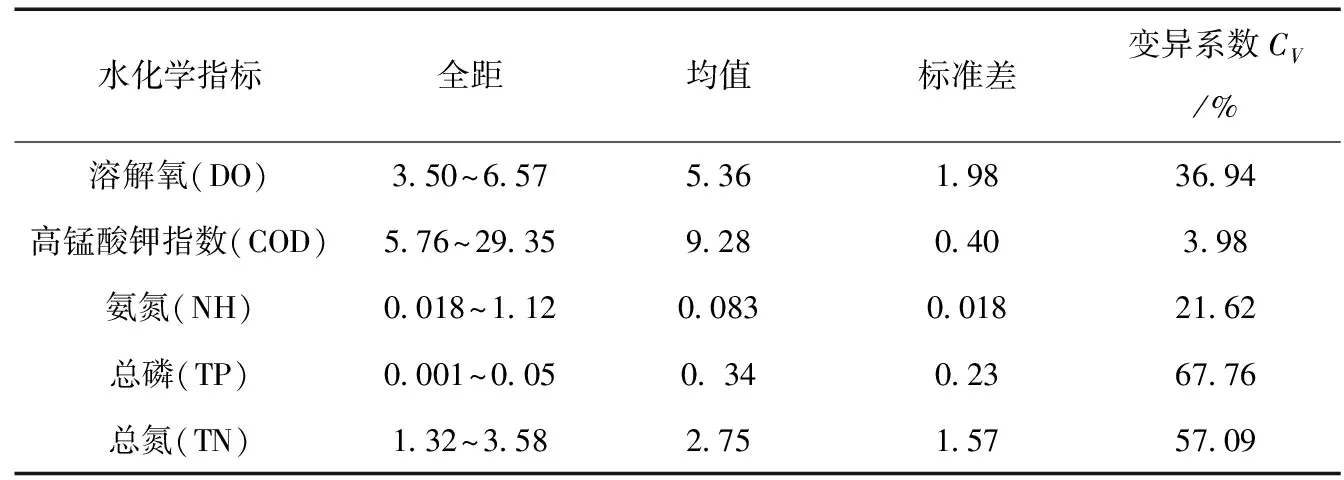
表3 水化學指標描述統計Table 3 Descriptive statistics of soil chemical indicators

表4 水體化學指標相關性分析Table 4 The relationships between water chemical indicators
相關性分析能夠幫助我們推斷水體中各物質之間遷移轉化機理及其來源是否相同。皮爾遜(Person)相關分析表明(表4),DO與COD、 DO與NH、 DO與TN、DO與TP呈正相關關系,并在0.01水平上(雙側)達到極顯著程度,說明它們的水污染源相近,可能由工農業污染、生活排污產生。由于DO是COD的重要的物質源,因此DO與COD之間的相關系數高達0.935。TN與DO在0.01水平上是反向關系,表明它們具有逆向分布特性,與營養元素之間的化學過程有關。
3.3 應用隨機森林的洋河張家口段水體質量評價
應用SVM的模式識別是在因變量的幾個分類水平明確的條件下,依據多個自變量性質表現,通過判別每個自變量的類別歸屬,進而達到對因變量模式類別區分的目的。本研究中,因變量為水體質量,其具有(I、II、III、IV和V)5個類別特征,自變量為DO、COD、NH、TP、TN。16個水體樣點評價結果見圖2。

圖2 16個水質樣點評價結果Fig.2 The evaluation result of 16 water quality samples
由圖2可知,洋河張家口段水體質量等級分布不均勻。16個監測點中,2個點水質屬于I等,5個點屬于II等,6個點屬于III等,3個點屬于1V等,0個點屬于V等。總體來說,洋河張家口段水體質量一般,仍須加強保護。
4 結 論
應用指出向量機模式識別將水體質量評價轉化模式識別問題,支持向量機中的核函數能夠模擬各指標與肥力量級間的多分類非線性映射關系,經過充分訓練獲得水質量級識別能力,不僅解決了線性不可分的問題,還確保了評價結果的客觀性。在模型構建中,機器學習模型維數擴充靈活,能夠根據需要調節自身形態特征與屬性特征,因而具有廣闊的適用性。
研究經驗表明,基于中國地表水環境質量分級標準與支持向量機分類算法的水體質量評價模型,訓練精度高、運算速率快,非線性識別能力好,能夠應用于水體質量評價的研究中。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電子測試(2017年23期)2017-04-04 05:06:50
智能系統學報(2017年5期)2017-01-22 11:21:30
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
智能系統學報(2015年3期)2015-01-29 15:20:12
河南科技(2014年5期)2014-02-27 14:08:35
