大數據處理下的水面艦反潛魚雷發現概率計算模型構設?
2018-08-28 02:50:34劉杰
艦船電子工程 2018年8期
劉 杰
(中國人民解放軍91388部隊91分隊 湛江 524022)
1 引言
水面艦反潛魚雷發現概率是水面艦反潛作戰能力的一個重要指標,發現概率的高低直接決定了水面艦打擊潛艇的效果。魚雷出管后,能否發現目標,受到多方面因素的影響,主要包括發射時刻敵我態勢、本艦和目標運動參數、魚雷射擊諸元和預設定參數、魚雷性能、海洋環境、目標潛艇類型、目標是否采取對抗措施、系統解算誤差、魚雷航行誤差等。在水面艦綜合反潛火控設備顯控臺上能夠看到魚雷攻擊潛艇的實時發現概率,對指揮員的指揮決策起到輔助作用,但是目前由于受到計算方法的限制,可參考性不強。
大數據分析算法就是對海量的各種各樣的數據進行計算,找出數據之間的相關關系,與針對“小數據量”的傳統算法相比,避免了在采樣過程中信息的丟失以及算法本身的誤差。利用水面艦在試驗、訓練、演習等過程中收集的有關使用魚雷反潛的大量數據進行分析計算,能夠更加準確地預測當前條件下水面艦反潛魚雷的實時發現概率。
2 大數據
大數據的定義為無法在一定時間內用常規軟件工具對其內容進行抓取、管理和處理的數據集合。是信息網絡技術發展的一個必然產物,其沖擊對于任何領域和行業都無法避免,軍事領域也是如此[1~4]。
2.1 大數據的特點
大數據的第一個特點就是“大”,即數據總量巨大。數據大小通常都在PetaBytes到ExaBytes,至少在GigaBytes;第二個特點是數據高速增長。隨著信息技術的發展,任何事物都可以被數據化,數據量呈現爆炸式的增長,數據更新速度非常快,因此,對很多實時數據要進行快速處理,平衡數據量和處理速度之間的關系也是大數據分析的一個難點;第三個特點是數據種類繁多,關系復雜。隨著數據收集能力的提高,收集到的數據類型也越來越多,質量參差不齊,各種數據之間都相互作用,簡單地剔除較差的數據會導致數據的大量浪費;第四個特點是有價值數據占的比例較小,即價值密度較低。
上述四個典型特點可以用4V表示,分別為總量(volume)、速度(velocity)、多樣性(variety)、價值(value)[5]。
2.2 數據挖掘
由于大數據的特點,傳統的統計學方法無法對其進行處理,因此,出現了一系列的大數據處理技術,即系列使用非傳統的工具來處理大量的結構化、半結構化和非結構化數據,從而獲得分析和預測結果的一系列數據處理技術[6]。
數據挖掘也稱為現代統計學,是對大數據進行分析處理的一門方法,是對傳統統計方法的延伸和擴展,最早是由Fayyad在1995年[7]知識發現會議上所提出來的他認為數據挖掘是一個自動或半自動化地從大量數據中發現有效的、有意義的、潛在有用的、易于理解的數據模式的復雜過程。數據挖掘的核心任務是對數據特征和關系的探索、建立。根據要探索的數據關系是否有目標,可以將數據挖掘的功能分為兩大類,一類稱為有指導的學習,是對預設目標的概率學習和建模,主要由分類、估計和預測三方面的功能構成,其中分類是較為基礎的,用于概念的識別,估計是對概念量的認識,預測則是對未知情況的判斷;另一類是無指導的學習,旨在尋找和刻畫數據的概念結構,主要由關聯分組、聚類和可視化三方面的內容構成,主要任務是提煉數據中潛在的模式,探索數據之間的聯系和內在結構[8~12]。本文的數據模型主要采用聚類的方法找出影響魚雷發現概率的所有因素之間的聯系。
3 發現概率計算模型的構設
3.1 水面艦反潛魚雷發現概率
發現概率是對魚雷出管后,按照預設定參數和設定的射擊諸元進行動作,發現目標情況的定量描述。
影響水面艦反潛魚雷發現概率的因素可分為本艦、目標、魚雷、探測系統、環境等五個方面,每一方面都包含多種因素,具體如下所示:
本艦:類型、工作狀態、運動參數、發射時刻與目標的相對態勢、系統解算誤差、系統工作方式等;
目標:類型、性能、運動參數、是否采取對抗等;
魚雷:類型、性能、發射方式、預設定參數、射擊諸元、航行(飛行)誤差等;探測系統:類型、性能、使用方式、使用狀態等;環境:水文、氣象、海況、海區深度、海底底質等。
3.2 模型構設
魚雷發射出去后能否發現目標主要由發射時魚雷射擊諸元是否正確、發射后魚雷的執行能力、目標的性能及是否采取對抗等決定,因為對反潛武器系統來說,目標是否會采取對抗措施以及采取何種對抗措施,在實際作戰中很難提前預料,所以,本文在模型構設時假定目標不采取對抗措施。
水面艦每發射一條魚雷,就用一個特征向量P表示魚雷攻擊目標的過程數據,形式如式(1)所示。
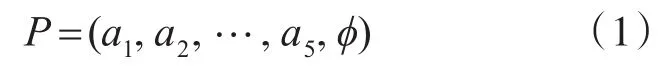
式中a1,a2,…,a5分別表示上述影響魚雷發現目標的五個方面,即本艦、目標、魚雷、探測系統和環境,每個方面包含的因素都用一個變量表示,?表示本次魚雷發射后是否發現目標,0表示未發現,1表示發現。
設訓練樣本集為X,共包含n個特征向量,每個特征向量用 Pi=(ai1,ai2,…,ai5,?i) 表示,其 中(i=1,2,…,n),使用歐式距離來計算系統魚雷發現概率。
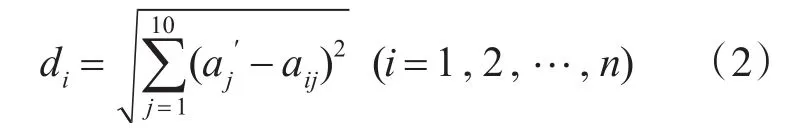
對所有di<β(β是一個判斷樣本相似性的閾值,根據實際使用進行確定)的數據按式(3)統計魚雷發現概率δ:
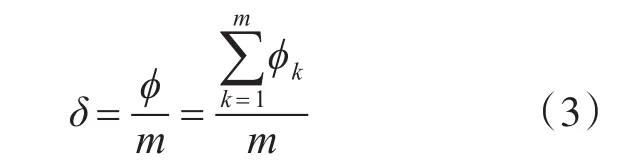
式中m表示di<β的特征向量總數,?k表示其對應的發現目標情況(是否發現)。
歐式距離判斷方法需要對樣本集中的每個樣本進行計算,計算效率比較低,不適用于大規模數據集。當訓練樣本集中的樣本量非常大時,可以采用聚類分析(二分k-均值算法或BIRCH算法等)的方法先將訓練樣本集劃分成K類(K根據實際使用進行確定)[8],聚類的原則是使類內樣本的相似度達到最大,而類間樣本的相似度達到最小,然后計算與每個類的聚類中心的歐式距離,選擇距離最小的類作為的類別,再按式(3)計算魚雷發現概率δ,此時式中的m表示所屬類別中特征向量的總數。計算流程詳見圖1所示。
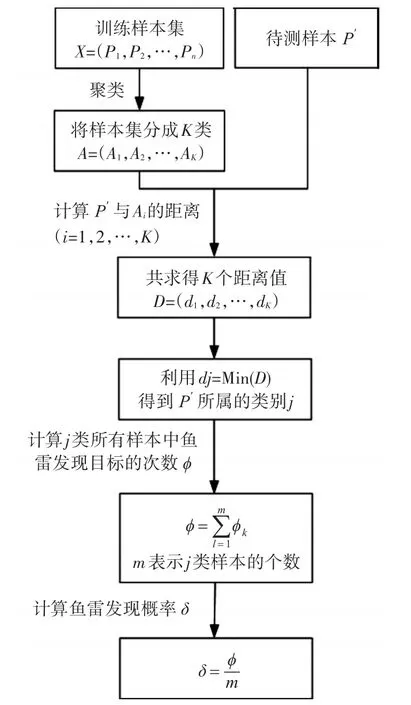
圖1 魚雷發現概率計算流程圖
3.3 可行性和存在困難
本文的計算模型是否可行,主要受數據和數據處理方法兩個方面的影響。目前基于互聯網的大數據分析技術已經在不同領域得到了應用,并取得了很好的效果,數據挖掘方法日趨完善,能夠很好地對大規模數據進行組織、分析和存儲。近年來,我海軍艦船數量迅速增加,外出執行訓練、演習、試驗以及其他任務頻繁,發射了大量的反潛魚雷,期間產生的數據量急劇增加,多年來積累了大量與魚雷發現目標相關的數據,因此,從理論上來說,本文計算模型可行。
但是想在水面艦反潛武器系統中實現該模型,還存在計算量和訓練樣本集實時更新的難題,要實現對大數據的實時處理,需要大量的存儲設備和處理設備,目前互聯網中解決該問題的方式主要是采用云計算,通過大眾參與的方式來處理大規模數據。因此,海軍艦船可以參考云計算的概念,通過某種方式將所有艦船上的計算和存儲設備進行共享,充分利用各艦船閑置的存儲和處理數據的能力,實時處理大規模數據,得到反潛魚雷發現概率以及更新訓練樣本集的目的。同時隨著計算機處理和存儲數據能力的提升,將來大數據實時處理的難題應該能夠得到更好的解決。
4 結語
數據就是信息,如何利用日益增加的數據來提升我軍裝備的戰斗力,是一個需長期研究的過程。數據是客觀的,當數據量足夠大時,就一定能夠從中找出我們需要的信息。本文提出的計算模型是基于大數據的預測能力,充分利用了艦船在執行各項任務期間所產生的有用數據,但是在實際作戰中,魚雷的發現概率還會受到人為的影響,尤其是聲納兵的能力,且本文的模型未考慮目標機動的情況,這些都是下一步需要研究的重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
核科學與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年23期)2014-02-27 14:18:43
