基于MPI的數據融合并行化容錯技術研究?
2018-08-28 02:50:12張路青
艦船電子工程 2018年8期
張路青
(海軍駐中南地區光電系統軍事代表室 武漢 430223)
1 引言
數據融合是對來自多源的信息和數據進行檢測、關聯、相關、估計和綜合處理,以得到精確的狀態和身份估計,以及完整、及時的態勢、威脅和重要程度的估計[1],是去粗取精、去偽存真、由此及彼、由表及里的過程。隨著計算機、電子技術的高速發展,現代戰場情報探測手段更加豐富,信息量都有了很大的增長,可用的情報來源(岸、海、空、天、潛等)和情報種類(電磁、紅外、光電、水聲等)越來越多。同時,對信息感知和信息融合能力的要求也越來越高。單機難以負擔大規模數據的實時、精確計算,需要引入并行計算技術,采用高性能并行并行融合方法。目前,MPI(Message Process Interface)是科學計算領域中廣泛使用的標準化并行編程環境,具有移植容易、擴展性好、結構簡單高效等多種優點[2],但在容錯性方面還達不到融合系統并行化的要求隨著并行計算集群節點數的增加,融合系統發生故障的概率也迅速增大,對于擁有幾萬個處理器的大規模并行融合系統,平均故障時間可達小時級[3],因此必須考慮容錯機制。本文先分析MPI容錯的研究進展,再根據數據融合系統的特點提出一種在融合系統中引入MPI容錯的解決方案。
2 基于MPI的容錯技術的研究進展
系統并行計算系統的錯誤主要來自于節點失效、進程異常、終止和網絡故障這三個方面。實現MPI的容錯方法有很多,有硬件容錯和軟件容錯。硬件容錯實時性好,糾錯速度快,但是可擴展性不好,需要額外的軟件支持,可能與消息傳遞機制不兼容[4]。軟件容錯又可以分為回卷恢復和副本冗余兩種。
2.1 回卷恢復
回卷恢復也就是在系統正常運行的適當時刻設置檢查點,保存未出錯時的狀態,當出現故障時,MPI應用程序回卷到最近的一次檢查點時的狀態,恢復狀態后繼續執行。現階段回卷恢復主要包括檢查點/回卷(CRR,Checkpoint-based Rollback Re?covery)和日志/回卷(LRR,Log-based Rollback Re?covery)兩種。LRR也依賴于檢查點,只是增加了消息日志,日志由進程歷史上發生的事件組成,保存了日志就可以重新運行位于最近的檢查點和錯誤發生點之間的那部分程序。日志又分為樂觀日志、悲觀日志和因果日志[5~7]。檢查點/回卷可以分為系統(內核)級檢查點[4,6~7]和應用(用戶)級檢查點[8~10]。常用的系統級檢查點工具有Epckpt、Crak、BLCR等,基于用戶層開發的工具有Condor、Libckpt等工具[8]。
檢查點無論是串行還是并行,同步或者異步,協同設置或者獨立設置,都必須考慮全局一致性狀態。一個消息傳遞系統的全局狀態包括所有參與進程的狀態信息以及通信通道的狀態[11]。只有檢查點或者日志記錄的是回卷時全部必要的狀態信息,回卷才能正確的恢復MPI程序。全局一致性狀態的必要性是保存的全局狀態中不包含孤立消息。孤立消息也就是消息的接收事件被記錄,但是發送事件卻沒有被記錄。如圖1所示,P1,P2,P3是三個MPI進程,圖中消息m1在P1處已經記錄發送,雖然在P2處沒有收到,但是消息被保存于消息信道里面(這樣的消息被叫做中途消息)。如果程序運行到B點發生故障回卷到CK0,則不會造成不一致狀態。圖中消息m4已經從P2發送到P3中,但是P2并未記錄(這樣的消息被叫做孤立消息)。如果程序運行到C點發生故障,回卷到CK1,則P2會再發送一次m4消息給P3,造成全局不一致狀態。
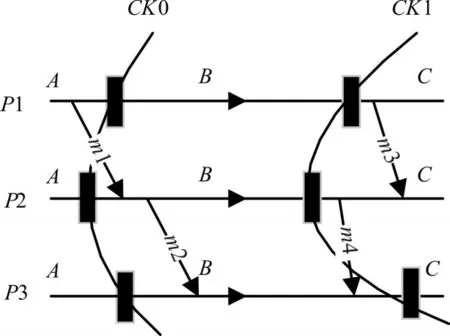
圖1 一致性狀態與不一致性狀態
文獻[4]介紹了回卷恢復和CO-CRR協議,通過對每個進程設置檢查點廣播的方式避免孤立消息,但是相關性能還需進一步測試。文獻[5]提出的MPI容錯系統采用了基于發送方儲存的樂觀消息日志,通過運用Venkatesan算法獨立異步的為每個進程設置檢查點,然后通過基于消息計數的協同式檢查點協議恢復到檢查點。文獻[7]首先介紹了基本的系統是檢查點協議(CO-CRR)并進行了開銷分析,然后利用可重建的全局檢查點設計了一個基于可重建檢查點的非阻塞協同式檢查點協議。文獻[8]主要利用容錯RAID的數據布局方法,在應用級做檢查點,對每個MPI進程的計算數據做內存編碼,文中提出的內存檢查點方法可以有效防止系統出現數據存取錯誤。文獻[10]提出了使用檢查點的源到源轉換工具ALEC在期望保存點設置預編譯指令的方法,通過預編譯確定需要保存的關鍵數據。這種方法可以有效的減小檢查點文件的大小,減少了系統設置和恢復檢查點的開銷。文獻[11]采用了基于消息驅趕的協調式檢查點協議設置檢查點,分別論述了檢查點設置、基于MPD的錯誤探測、處理及恢復流程。
BLCR是伯克利實驗室未來技術組的研究者為Linux操作系統設計實現了一種Checkpoint/Restart技術。它使用戶不需要修改應用程序的源碼就能讓絕大部分應用軟件擁有執行Checkpoint/Restart能力。新版的MPI不再使用MPD進程管理,而是采用Hydra進程管理器。Hydra進程管理器使BLCR可以作為MPI的一個可擴展用戶空間插件自動編譯到MPI系統中。為了在編譯MPI使加入BLCR功能,需要在編譯前將BLCR的路徑加入到MPI的配置選項里,例如在configure命令后面添加--with-blcr=<BLCR_INSTALL_DIR>即可。
在MPI中,當程序出錯時,會返回一個錯誤代碼,默認的錯誤返回代碼是MPI_ER?RORS_ARE_FATAL。MPI會把任何返回這個代碼的錯誤,不管能處理還是不能處理,都當成致命性的錯誤,從而導致錯誤進程所在通信域的所有進程集體退出。可以在編譯配置時加入“-disable-au?to-cleanup”選項,使進程只返回錯誤代碼。
MPI支持兩種主要的設置檢查點的方式—定時設置和用戶指定設置。通過使用指令mpiex?ec-ckpointlib blcr-ckpoint-prefix/tmp/app.ckpoint-ckpoint-interval 3600-f hosts-n 4./app,可以以3600S的定時間隔設置檢查點。用戶還可以通過給mpiexec發送SIGUSR1信號通知BLCR設置檢查點。
2.2 副本冗余
副本冗余,也就是為正在運行的程序設置副本。副本冗余也包含很多層級和機制。譬如,按照層級分為集群冗余、節點冗余、進程冗余[12~13],按照機制分為計算冗余[12~13]和通信冗余[14]等等。
文獻[12]主要研究了三模冗余進程機制(并行MPI程序的任意一個進程P0都存在兩個冗余的副本P1和P2,P0與其對應的冗余副本P1和P2進行完全相同的運算,發送和接收完全相同的消息。稱由這樣3個進程構成的整體為三模冗余進程簇),介紹了一種面向MPI大規模并行計算的可擴展三模冗余容錯機制,主要從傳統TMR的開銷角度計算分析出傳統三模冗余進程機制的局限性,對三個作業進程之間的通信和數據比較選擇進行了優化,減少了數據通信和比較的開銷。文獻[13]提出了一種基于進程冗余的MPI程序容錯機制REDReP,REDReP為運行并行程序的每個MPI進程創建一個冗余副本,當該進程需要與其他進程通信時,先比較兩個冗余進程的結果,如果相同才繼續執行后續任務。文獻[12]和文獻[13]都從冗余進程之間數據通信、數據比較等角度分析并優化了開銷。
文獻[14]主要介紹了一種基于故障接管的網絡容錯策略。文中認為并行計算主要的顧慮是消息是否到達,所以為主通信協議(精簡通信協議RCP)設計了一個備份通信協議(以太網),并設計了協議虛擬接口層實現協議的無縫切換,整個體系結構由消息接口層、容錯協議層、多協議層和守護控制進程組成。
3 數據融合系統的并行容錯分析
3.1 數據融合系統的結構特點
系統并行計算系統的錯誤主要來自于節點失效、進程異常、終止和網絡故障這三個方面。實現MPI的容錯方法有很多,有硬件容錯和軟件容錯。硬件容錯實時性好,糾錯速度快,但是可擴展性不好,需要額外的軟件支持,可能與消息傳遞機制不兼容[4]。軟件容錯又可以分為回卷恢復和副本冗余兩種。
數據融合系統主要包括數據配準、數據相關、數據濾波與合成。具體到航跡融合,主要是時空配準、數據預處理、航跡濾波、航跡相關、航跡合成等功能模塊(如圖2所示)。時空配準將各傳感器探測到的目標位置轉換到同一坐標系,探測到目標的時間也建立統一時序,并估計傳感器的系統誤差和參數。數據預處理剔除異常數據和虛假目標。航跡濾波是對一個觀測序列進行數據處理,以獲得更精確的態勢估計與預測的過程。航跡相關是信源間的航-航互聯過程,其目的是確定哪些航跡數據來源于同一個目標,為去除重復信息、進行目標信息提純奠定基礎。航跡合成就是對不同信源相關后的航跡進行合成,以獲得更精確的態勢估計與預測的過程。從圖2可以看出,整個航跡融合流程邏輯序貫性強,數據之間的耦合性大,這些都對融合的并行及容錯造成了很大的困難[15]。
3.2 數據融合系統中引入并行容錯架構分析
由圖2可知,航跡融合系統中各功能模塊序貫性強,且有相對嚴格的處理順序,所以試圖從流程方面進行并行任務劃分效率不會很高。本文采用文獻[15]和文獻[16]中論述的基于網格劃分的方法。即將多部雷達輸出的航跡信息根據空間位置關系和航跡間的模糊關聯關系動態聚類成多個不同的區域,區域內的航跡間具有相關性,不同區域內的航跡相互獨立。從而可以將相同區域內的航跡分配到同一個任務節點進行處理,這樣各任務節點就具有獨立性,可以充分發揮并行處理的優勢。并行融合架構如圖3所示。
圖3 以區域為單位進行并行任務劃分
綜合2.1節的分析可知,基于回卷恢復的容錯機制主要包括保存檢查點狀態和恢復繼續執行兩個步驟。檢查點保存和恢復的開銷與集群系統規模和所設置檢查點的時間和數量都有關系[9]。融合程序屬于計算密集型的程序,設置協調式檢查點的性能要優于獨立設置檢查點,本文選擇使用系統級檢查點設置工具BLCR。一般來說,采用回卷恢復進行容錯設計比較耗時,而指控系統需要的情報信息不僅要求準確可靠,更要求快速及時,所以單純靠回卷恢復并不能滿足系統容錯的設計需求。本文在回卷恢復的基礎上提出了回卷恢復與層級冗余任務進程相結合的機制。層級冗余任務也就是根據任務在整個融合程序中的處理次序和重要性進行劃分。根據任務類型結構進行冗余既減輕了硬件開銷,又充分利用了冗余容錯的機制,提高了整個系統的可靠性和靈活性。
4 基于任務冗余的MPI并行架構設計的實現
通過前面的分析可知,航跡融合程序一般包括時空配準、數據預處理、航跡濾波、航跡相關、航跡合成等功能模塊。這幾個模塊比較耗時和容易出錯的是航跡濾波、相關和合成,所以并行的設計和相關容錯的設計圍繞這三個功能模塊展開。具體過程如圖4所示,從多源傳感器輸出的航跡先經過報文接收放到融合程序里進行時空配準,然后通過簡單的預處理去掉錯誤異常數據和虛假目標。把預處理后的數據根據網格聚類劃分為若干處理區域,再將各個區域通過數據分發模塊分發到指定的任務節點上進行濾波、相關和合成。航跡濾波、航跡關聯和航跡合成任務節點設一個冗余處理進程。這個冗余處理進程是通過數據分發模塊進行切換的,如果沒有任務節點出錯,則不將數據推送到冗余進程。如果系統的心跳進程檢測到某個處理單元出現錯誤或者負載太大,就會分發數據到冗余進程,出錯任務進程執行檢查點/重啟技術恢復進程,這時重啟恢復后的進程變為冗余進程,等待下一次程序出錯。為了保證程序進程切換時不出現數據丟失,要求數據分發進程保留發送到各任務節點的最后一次數據的拷貝。狀態檢測進程一旦發現某個節點出現錯誤,切換到冗余任務節點后,將上一次分發給出錯進程但是沒有處理完的數據再次發送一遍。
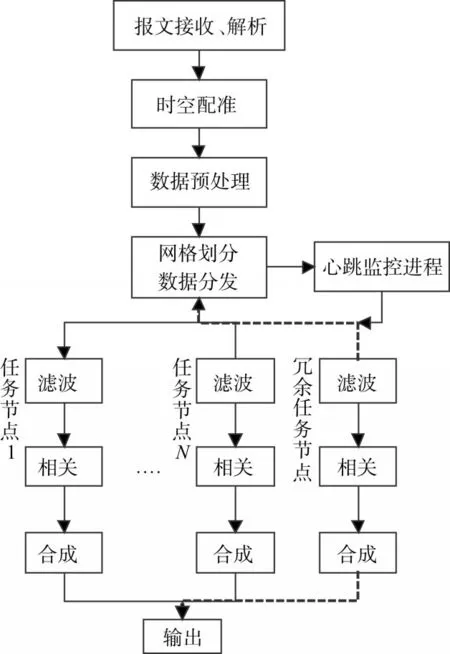
圖4 MPI并行容錯設計架構
錯誤處理與恢復流程:
1)心跳監控進程檢測到某個任務節點出現異常或者其它故障,心跳進程向數據分發任務進程發送封裝了故障任務節點信息的消息報。
2)數據分發任務進程停止向故障任務節點分發數據。數據分發進程通過比較分發到故障節點輸入和輸出的數據確定正在故障節點中處理尚未輸出的數據。并將這部分數據重新分發到冗余任務節點,冗余任務節點開始接收數據并正常工作。數據分發進程不再向故障任務節點分發數據,也不再接收故障任務進程輸出的數據。
3)任務節點管理進程向故障任務節點發送重啟進程的指令。故障任務節點開始尋找最近的檢查點位置,然后重新啟動進程,丟掉進程正常工作時的中間數據,開始等待分發數據。
4)這時,原故障進程就變為冗余任務進程。如果再一次故障,繼續回到1)~3)進行處理。
5 仿真驗證與分析
為了測試驗證所設計的并行容錯算法,將基于MPI的航跡融合程序部署在使用交換機連接的局域網系統中。局域網有三臺配置相同的計算機(主頻3.4GHZ的i7 2600,2G內存,操作系統為Solar?is11)組成。接入4部掃描周期2s的雷達,實際處理目標1500批。將融合后的輸出接入態勢軟件顯示。在相同時間內,串行處理效果如圖5(a)所示,加入并行容錯的執行效果如圖5(b)所示。由圖可看出,串行的融合算法執行效率低,相同數據量輸入條件下,串行的程序將大部分數據放入緩沖區,航跡融合速度慢,航跡拖尾短;而并行則能快速執行算法,占用內存少,航跡拖尾長。

圖5 相同時間內算法執行累積輸出對比
MPI程序沒加入容錯時,進程域中某個進程出現錯誤就會導致所有進程全部退出。通過手動停止某個進程的方式可以驗證冗余任務進程是否在進程出現故障時接手工作,但是基于檢查點和冗余任務進程相結合的容錯效率則需要進一步的驗證。
6 結語
數據融合系統并行化雖然有很多的困難,但是對并行化和相關容錯的需求很迫切。本文首先通過文獻中關于MPI并行的論述和分析數據融合系統并行化所存在的困難,提出一種適合航跡融合系統的并行容錯解決方案,即通過網格聚類劃分并行任務,通過檢查點和任務進程冗余相結合的方法設計容錯方案。整個設計有一定的實用性,不過容錯效果有待進一步的驗證和改進。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
少先隊活動(2021年4期)2021-07-23 01:46:22
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中國外匯(2019年20期)2019-11-25 09:54:58
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
民主與科學(2014年3期)2014-02-28 11:23:03
都市快軌交通(2014年4期)2014-02-27 08:35:05
