基于雙流卷積神經網絡的改進人體行為識別算法
2018-08-24 07:51:38,
計算機測量與控制 2018年8期
,
(南京理工大學 自動化學院,南京 210094)
0 引言
人體行為識別的目的是分析并理解視頻中的人體的動作和行為,與靜態圖像中二維空間的物體識別不同,行為識別主要研究如何感知目標對象在圖像序列中的時空運動變化,將人體行為的表現形式從二維空間拓展到了三維時空。人體行為識別有著重要的理論意義且在很多領域有著重要的應用價值,如智能監控、視頻檢索和人機交互等[1]。
隨著大規模數據集的涌現,傳統算法已經很難滿足如今大數據處理的需求,深度學習成為近幾年國內外的研究熱點。深度學習是機器學習領域的重點研究問題,它模擬人腦認知機制的多層次模型結構,通過組合低層特征形成更為抽象的高層特征來獲得數據更有效的特征表示,相比于傳統的人工提取特征更適合目標的檢測和識別。
卷積神經網絡是深度學習模型的典型代表,應用最為廣泛,已經成為目前圖像識別和語音分析等領域的一個應用熱點。在人體行為識別方面,基于卷積神經網絡的研究也有很多新進展。Ji等人[2]在傳統CNN基礎上加入時間信息構成三維CNN,將灰度、垂直和水平方向梯度、垂直和水平方向光流信息作為多通道輸入,對于多個連續幀通過三維卷積操作實現視頻數據在時間和空間維度的特征計算;Karpathy等人[3]提出雙分辨率的CNN模型,使用原始分辨率和低分辨率的視頻幀分別作為輸入,學習兩個CNN模型,并在最后兩個全連接層實現數據融合,以實現視頻的最終特征描述用于后續識別;Karen等人[4]提出雙流CNN模型,將視頻數據分成空間靜態幀數據流和時域幀間動態數據流,分別將原始單幀RGB圖像和多幀堆疊的光流圖像分別作為兩個CNN模型的輸入進行特征提取,最后使用SVM分類器進行行為識別;Chéron等人[5]提出使用根據人體姿勢的關節點分割的單幀RGB圖像和光流圖像分別作為兩個CNN模型的輸入進行特征提取,并使用特征融合策略將視頻數據轉換為固定維度的特征向量,最后使用SVM分類器進行行為識別。
本文借鑒文獻[4]中雙流卷積神經網絡模型中的“雙流”概念,提出了一種基于改進雙流卷積神經網絡的人體行為識別模型,將VGGNet_16模型應用于雙流卷積神經網絡的空間流CNN,替換原始的類AlexNet模型,從而加深網絡結構;將Flow_Net模型應用于雙流卷積神經網絡的時間流CNN,替換原始的類AlexNet模型,使得模型更適用于提取光流圖的特征,然后將空間流CNN模型和的時間流CNN模型的輸出結果進行加權融合后作為雙流CNN模型的輸出結果,最終得到一個多模型融合的人體行為識別方法。
1 雙流卷積神經網絡
1.1 卷積神經網絡
卷積神經網絡[6]是一種特殊設計的深層模型,最早應用于圖像識別領域。CNN模型通過卷積和下采樣操作自動學習圖像特征,并把特征提取和分類輸出合并為一個整體,從而獲得更高的識別效率和更佳的性能表現。CNN的核心思想是局部感受野、權值共享以及空間下采樣,這使得網絡的權值參數個數大幅減少,并獲得了對圖像位移、尺度、形變的不變性。典型的CNN網絡結構如圖1所示。
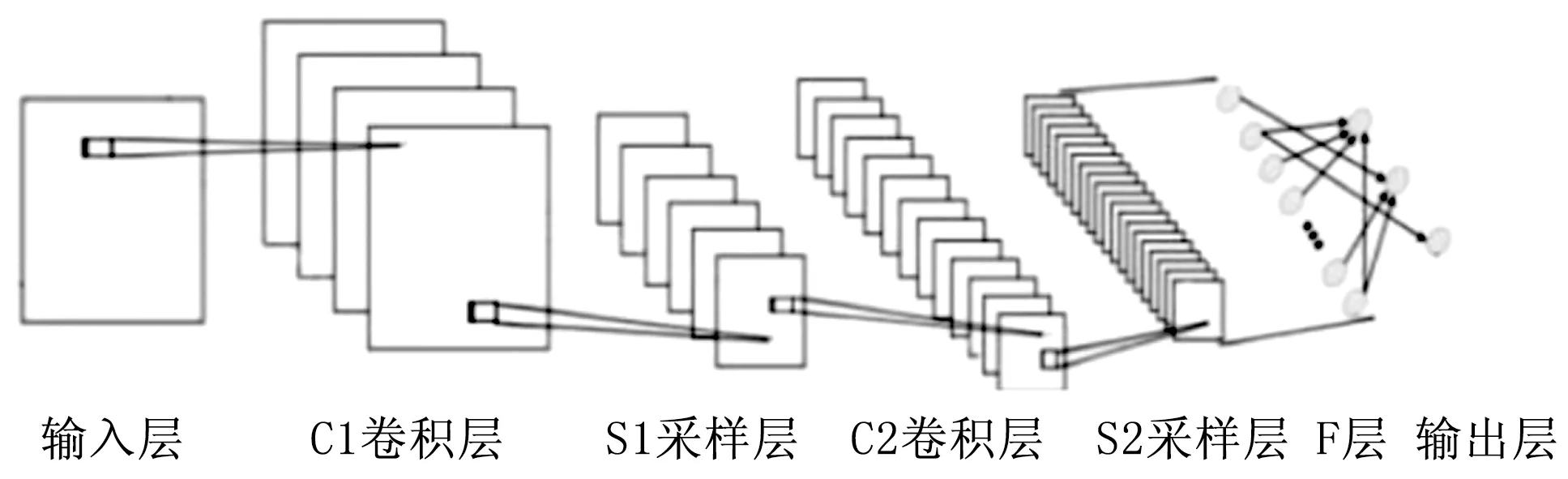
圖1 卷積神經網絡結構示意圖
1.1.1 卷積層
卷積層是通過多個不同的卷積核對上一層的輸入做卷積運算得到多個輸出,即多個特征圖。卷積公式如式(1)所示:
(1)
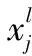
1.1.2 下采樣層
下采樣層是對上一層的特征圖進行采樣操作,從而減小特征圖的分辨率。采樣操作是指對采樣范圍區域內所有像素點求平均值或最大值作為該區域采樣后的值,從而實現卷積特征的降維并獲得具有空間不變性的特征。本文采用最大值下采樣操作,采樣公式如式(2)所示:
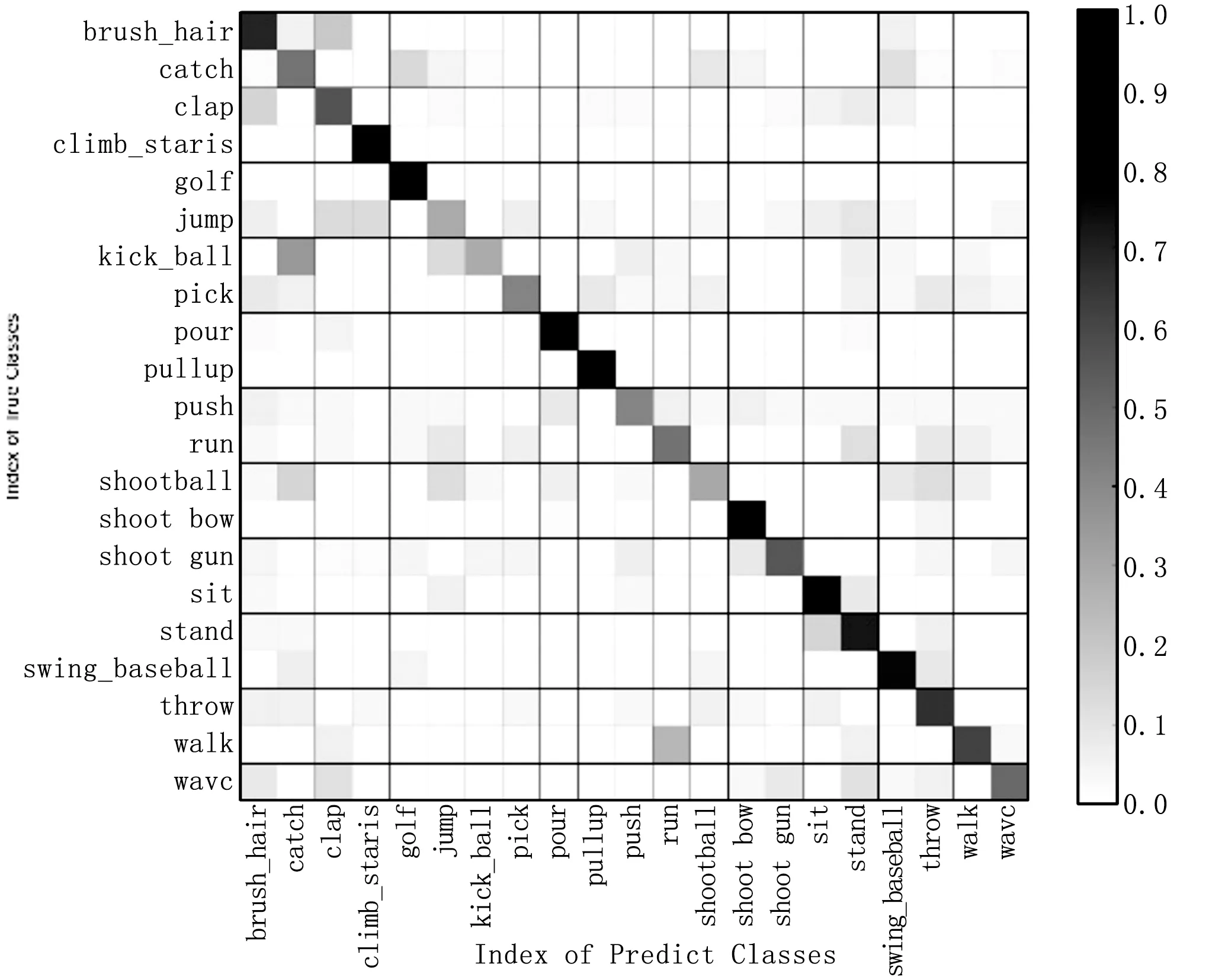
yij=max0 (2) 其中:H,W表示采樣窗口的長和寬,x表示二維輸入向量,y表示采樣的輸出值。 1.1.3 Softmax分類器 深度學習網絡常用的分類器包括多分類SVM以及Softmax分類器。本文選擇使用Softmax作為特征提取后的多分類器。對于一個k分類任務,包含m個樣本的訓練集可表示為: T={(x(1),y(1)),...,(x(m),y(m))} (3) 其中:"x(i)∈Rn+1表示一個n維向量的樣本,y(i)∈{1,2,...,k}是類別標簽。對于輸入樣本x,計算它屬于每一個類別的概率: P(y=j|x),(j=1,...,k) (4) Softmax輸出即為樣本x(i)屬于每個類別的所有概率值構成的一個k維的向量,計算函數如式(5)所示: 再者,美國對伊朗的制裁規則較一般法律文件具有更強的靈活性。這主要是考慮到制裁涉及的外交和政治復雜性,要為美國政府留下操作空間。例如,在判斷構成受到制裁的“重大交易”問題上,制裁規則要求財政部綜合考慮交易的數量、金額、頻率等因素做出判斷,并沒有規定明確的判斷標準③Iranian Financial Sanctions Regulations, 31 C.F.R. §561.404.。同時,其制裁方式也具有多樣性。例如,在違反“次級制裁”的情況下,國務卿和財政部有從12項懲罰措施中任意選擇5項對相關主體進行制裁的權力。 (5) 其中:θ是模型參數。 雙流卷積神經網絡的結構示意圖如圖2所示,該模型的核心在于空間流 CNN和時間流CNN構成的“雙流”結構,其中:空間流CNN 以視頻的單幀RGB 圖像作為輸入,實現人體在空間域上表觀信息的特征描述;而時間流CNN 則是以多幀疊加后的光流圖像作為輸入,得到關于行為的運動特征表述,從而達到時間和空間互補的目的。針對給定的視頻行為樣本,首先分別通過時間流CNN和空間流CNN 進行特征提取,最終將兩個分支的分類結果進行加權融合,以得到關于視頻中人體行為類別的最終決策結果。 圖2 雙流卷積神經網絡模型結構示意圖 原始雙流卷積神經網絡模型結構設計基本上和AlexNet模型是同一種思路,包括5層卷積層和3層全連接層,網絡的輸入圖像尺寸被固定為224×224。與AlexNet相比,原始雙流CNN包含更多的卷積濾波器,第一層卷積層的卷積核尺寸縮小為7×7,卷積步長減小為2,其他層次的參數都與AlexNet相同。 隨著對深度學習研究的深入,現在的網絡結構發展呈現出層次結構更深,卷積核尺寸更小,濾波器數量更多,卷積操作步長更小的趨勢,這些轉變應用在物體檢測任務上并獲得了較好的效果。目前應用較廣泛的深層次卷積神經網絡結構有GoogleNet和VGGNet和ResNet等。 本文選用VGGNet-16模型作為空間流CNN模型,VGGNet-16是在數據庫ImageNet上訓練得到的具有1000個分類的模型,在2014年大規模視覺識別挑戰賽(ILSVRC)中獲得了第二名的成績。VGGNet-16模型繼承了AlexNet模型的網絡框架,采用了16層的深度網絡,包含13個卷積層和3層全連接層,與AlexNet模型相比,VGGNet-16模型使用了更深的網絡,且所有卷積層都使用大小為3×3的卷積核,卷積步長也縮小到1,能夠模仿出更大的感受野,且減少了自由參數數目。VGGNet-16模型結構如表1所示。 表1 VGGNet-16網絡結構 另外,時間流CNN用來提取光流信息,因此本文采用在光流圖像上預訓練的Flow_Net[8]模型,Flow_Net模型是在包含13320個視頻101類行為的UCF101數據庫上訓練光流圖得到的模型,適合于用來進行光流圖像的特征描述。Flow_Net模型的網絡結構如表2所示。 表2 Flow_Net網絡結構 為避免因訓練樣本數量不足出現深度網絡學習過擬合的情況,本文采用遷移學習的方法。遷移學習[9-10]是指利用已學習到的知識解決不同但類似問題的方法,本文利用預訓練好的模型初始化用于人體行為識別的雙流卷積網絡模型。 原始雙流卷積神經網絡只在空間流CNN上使用預訓練,本文在空間流和時間流上分別使用VGGNet-16和Flow_Net預訓練模型初始化網絡參數,并利用目標任務數據庫對網絡進行精調,得到目標任務網絡模型。對于空間流CNN,輸入為RGB圖像,而VGGNet-16模型由ImageNet數據庫中的RGB圖像訓練得到,該數據庫包含各種物體和生物,模型能夠很好地獲取圖像低級、局部的特征,將其遷移到其他圖片數據上的泛化性非常好,適合進行人體行為識別;而對于時間流CNN,輸入為光流圖像,因此使用UCF101數據庫上光流圖像訓練得到的Flow_Net模型初始化時間流模型。另外,需要調小模型訓練初始的學習率,并根據訓練的迭代次數對學習率實時進行調整,隨著迭代次數的增多,減小學習率。 通過雙流卷積神經網絡獲取視頻幀的RGB特征以及光流特征后,需要將空間流CNN和時間流CNN的Softmax輸出進行加權融合得到最終概率輸出,選取概率最大的類別作為分類結果。 對于人體行為識別的分類任務,模型的輸入是單幀圖像,而樣本是以單個行為視頻為單位的,因此需要對視頻中所有圖像對應輸出的概率矢量進行融合,得到某個視頻單個模型的預測概率矢量,再將時間流以及空間流模型所得到的概率矢量以不同的權值相加,得到預測樣本屬于各個類別的概率向量Vec: (6) 其中:λ是一個介于(0,1)的常量,n是視頻幀數。 本文實驗基于Caffe和GPU,GPU型號為NVIDIA Titan X,該顯卡的顯存容量大小為12G。 為驗證模型的有效性,采用JHMDB人體行為數據庫進行模型的性能測試,JHMDB數據庫是HMDB51的子數據集,包含21類行為,共有928個視頻片段,視頻幀分辨率為320×240,其提供了訓練集和測試集的劃分,共有3個splits。為滿足網絡訓練需求,抑制過擬合,本文對圖像樣本做了一系列的數據擴充,通過對視頻幀進行隨機剪裁、隨機旋轉、水平翻轉、對比度變化、亮度變化、加噪和模糊等處理,將圖像樣本擴充了10倍,同時增強了樣本數據的多樣性。 根據JHMDB數據庫包含的行為類別數將VGG-16模型和Flow_Net模型的最后一個Fc層分類參數設置為21;將RGB圖像尺寸規范化到224×224,光流圖根據文獻[10]計算得到,并將尺寸規范化到227×227,每三幀光流圖疊加作為一個輸入樣本,然后將單幀RGB原圖和光流圖像分別輸入到VGGNet-16模型和Flow_Net模型中,VGGNet-16模型的初始學習率設為0.001,每經過10000次迭代學習率降為原來的10%,總共迭代60000次,Flow_Net模型的初始學習率設為0.001,每經過2000次迭代學習率降為原來的10%,總共迭代10000次,用測試集分別測試VGG-16模型和Flow_Net模型。將兩個模型得出的預測值進行融合,通過選取5種不同的權重融合,得出最終識別結果,表3為不同權重融合下得到的對JHMDB數據庫中行為識別準確率的對比。 表3 不同權重融合的效果比較 從表3可以看出,時間流CNN比空間流CNN模型識別效果好,而經過模型融合得到的識別效果與不同模型預測結果的所占比重有關,總的來說,使用模型融合的方法要比單模型的分類效果好,且當()即空間流CNN模型和時間流CNN模型的輸出以1/3和2/3的比重進行融合時,得到的最終分類結果效果最好,在JHMDB數據庫split1上測試混淆矩陣如圖3所示。 圖3 JHMDB-split1雙流CNN混淆矩陣 從圖3可以看出,改進的雙流CNN通過在新的數據庫上進行微調,可以有效實現人體行為識別。其中,golf的識別率最高,而kick_ball的識別率最低,很容易被錯分為catch或jump。 本文提出的方法與其他人體行為識別方法的準確度進行對比,比較結果如表4所示。 表4 與其他方法的效果比較 從表4可以看出,本文提出的改進雙流卷積神經網絡相比于原始的雙流卷積神經網絡和文獻[8]的方法在人體行為識別任務上的識別率略有提高。 本文提出了一種改進的雙流卷積神經網絡模型,將VGGNet_16模型應用于空間流CNN,替換原始的類AlexNet模型,從而加深網絡結構;將Flow_Net模型應用于時間流CNN,替換原始的類AlexNet模型,使得模型更適用于提取光流圖的特征,然后將空間流CNN和的時間流CNN的Softmax輸出進行加權融合作為雙流CNN模型的輸出結果,最終實現人體行為識別。為了避免由于訓練樣本不足而出現模型過擬合現象,本文采用了訓練樣本集擴充和遷移學習的方法。最后,基于JHMDB數據庫的實驗得到改進的雙流卷積神經網絡模型的識別率達到60.14%,證明了其在人體行為識別任務上的有效性。1.2 雙流CNN網絡結構
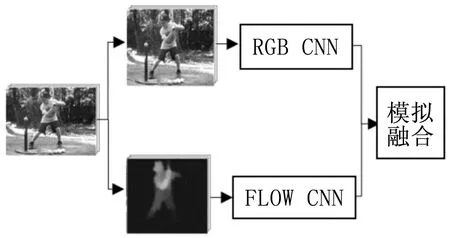

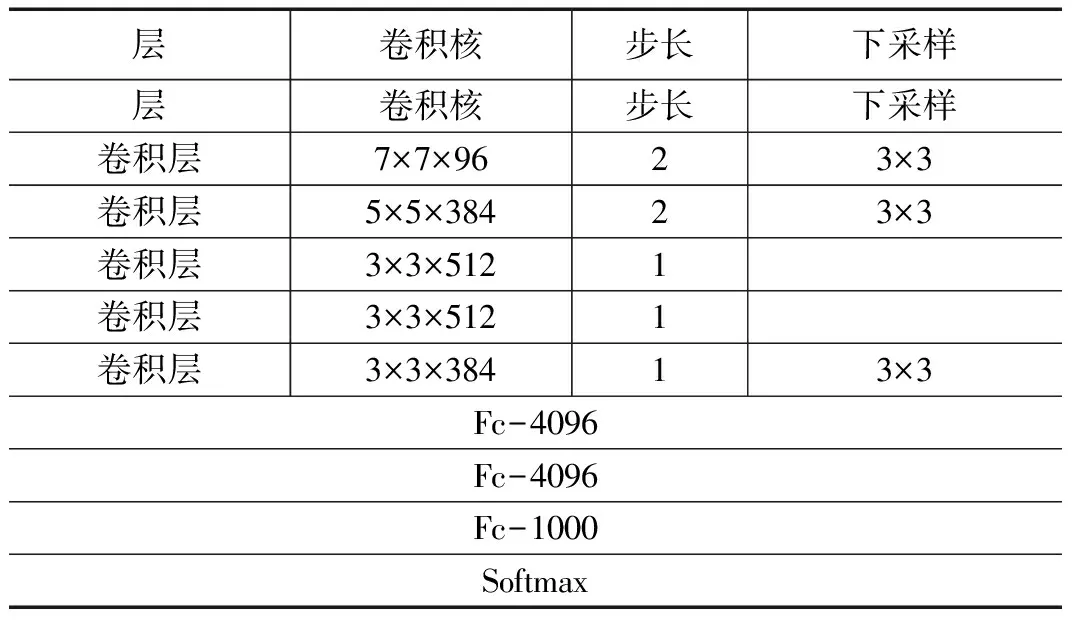
1.3 基于遷移學習的模型訓練
1.4 模型融合
2 實驗結果與分析
2.1 實驗平臺與數據庫
2.2 模型訓練與結果分析


3 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
核科學與工程(2015年4期)2015-09-26 11:59:03
