密度峰值快速聚類算法優化研究
2018-08-23 03:06:50王鵬飛楊余旺柯亞琪
計算機工程與科學 2018年8期
王鵬飛,楊余旺,柯亞琪
(1.南京理工大學計算機科學與工程學院,江蘇 南京 210094; 2.南京農業大學園藝學院,江蘇 南京 210095)
1 引言
近年來隨著數據的不斷增長和累積,如何從這些大數據中挖掘出有用的信息成為了當前的研究熱點,聚類就是一種能夠從大數據中挖掘出有用信息的有效方法[1]。聚類是聚類分析的簡稱,是一種無監督的學習過程[2]。聚類是在無先驗認知的條件下,根據發現的數據對象的相似性,將對象分組,從而達到對數據的深刻理解,獲得有用信息或者壓縮數據的目的[3,4]。
聚類分析現在已經應用于諸多領域,如:數據庫知識發現、計算機視覺、圖像處理、生物信息學等[5]。正因為聚類分析的實用性,許多聚類算法已經被人們提出,其中比較經典的有K-means算法、模糊C-means算法、具有噪聲的基于密度的聚類方法DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法等,近幾年又提出了近鄰傳播AP(Affinity Propagation)算法和CFSFDP(Clustering by Fast Search and Find of Density Peaks)算法[6]。這些聚類算法都旨在解決不同情況下的大數據聚類問題。K-means算法是一種基于距離的迭代式算法,其旨在將數據點劃分到距離最近的聚類中心所在的簇中,但K-means算法需要提前指定聚類中心的個數,且對于非球形的數據集很難取得令人滿意的聚類結果[7]。基于數據點的密度進行聚類的算法,如經典的DBSCAN算法,則擺脫了對數據集形狀要求的束縛,它可以得到任意形狀的類簇。DBSCAN算法需選擇一個密度閾值,密度高于該閾值的點則成為“核心點”,之后將所有“密度相連”的點聚合為一個類[8]。DBSCAN算法不需要事先確定聚類中心的個數,且能夠很好地排除噪聲點和離群點。但是,該算法對于密度分布不均勻的數據集所取得的效果并不理想,且該算法最終的結果對所選擇的密度閾值十分敏感,這使得對于密度閾值的選擇有一定的困難。除了上述兩個問題外,DBSCAN算法的計算復雜度也很高,這也導致它很難運用于高維數據環境[9]。
Rodriguez等人[10]于2014年在《Science》上提出了一種基于密度峰值的空間聚類算法,該算法可以對任何無規則的數據集進行聚類[11]。快速尋找密度極點聚類算法CFSFDP算法首先通過使用一截斷距離來計算每個點的局部密度,然后計算各數據點與局部密度高于它們的數據點之間的最小距離;然后根據計算出的每個點的局部密度和最小距離繪制決策圖,接著在決策圖中人工選取聚類的中心,之后將剩余的非聚類中心的數據點劃分到與之距離最近的聚類中心所在的簇中;最后再將所得到的各個簇劃分為簇核心和簇光暈,從而得到最終的聚類結果。使用CFSFDP算法進行聚類時只需要計算一次距離,并且不需要進行迭代,因此算法的計算速度很快。但是,該算法選擇聚類中心的時候需要在決策圖中人工選取,這增加了算法的冗余性,不利于算法的自動化,且在最后將簇劃分為簇核心和簇光暈時會將簇邊緣的本屬于簇核心的一些點劃分到簇光暈中,影響最終的聚類效果。
針對CFSFDP算法上述兩個不足點,本文引入了一種聚類中心的自動選擇策略,通過使用異常檢測的思想自動計算得到數據集的聚類中心,從而避免了CFSFDP算法需要在決策圖中人工選擇聚類中心,影響算法自動化的問題。并且在得到初步的聚類結果后進行簇核心和簇光暈的劃分時,引入了簇內局部密度的概念,改進了CFSFDP算法原本的劃分方法,使得簇核心和簇光暈點劃分結果更為合理。實驗結果表明,本文提出的算法可以有效地提高CFSFDP算法的自動化程度,并且最終得到的聚類結果與CFSFDP算法相比更為準確合理。
2 CFSFDP算法
CFSFDP算法進行聚類時首先需要確定類的中心點,其假設簇的聚類中心的局部密度高于其周圍數據點的局部密度,并且聚類中心與那些局部密度更高的數據點之間的距離較大。對于一個給定的數據集,CFSFDP算法需要為每個數據點計算兩個量化值:數據點的局部密度ρi和它與局部密度比其高的數據點之間的距離δi。
數據點xi的局部密度ρi有兩種計算方式:基于截斷核的計算方式和基于高斯核的計算方式。使用截斷核計算局部密度ρi的公式為:
χ(δij-dc)
(1)
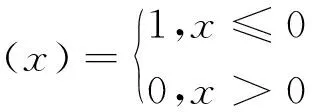
使用高斯核計算局部密度ρi的公式為:
(2)
其中,δij為數據點之間的距離,Is為i的值域,dc為截斷距離即距離閾值。使用該計算方式得到的局部密度ρi仍然滿足與數據點xi的距離小于dc的點越多,局部密度ρi就越大的結論。使用截斷核計算局部密度和使用高斯核計算局部密度這兩種計算方式的區別在于使用截斷核計算得到的結果為離散值而使用高斯核計算得到的結果為連續值。因此,相對而言,使用高斯核計算得到的數據點具有相同的局部密度的概率比使用截斷核計算得到的數據點具有相同的局部密度的概率要小,使用高斯核計算局部密度ρi更方便比較數據點局部密度之間的大小關系。
數據點之間的距離δi是通過計算數據點xi與比該數據點局部密度高的其他數據點的距離得到的,數據點之間的距離δi可以根據公式(3)計算得到。
(3)
一般而言,數據點之間的距離δi為數據點i與比該數據點局部密度ρi更高的其他數據點的所有距離中的最小值,但對于局部密度ρi最高的點,數據點之間的距離δi為其他數據點與之距離的最大值。
CFSFDP算法根據數據點之間的距離δi與數據點的局部密度ρi的各自的大小關系繪制決策圖,通過在決策圖中人工選取簇的聚類中心,其決策圖如圖1所示。算法將δi值大且ρi值較大的點認定為簇的聚類中心,即在決策圖中處于右上角與其他點分離明顯的部分點。在確定簇的聚類中心之后,便將其他剩余的數據點劃分到局部密度比其高且與之距離最近的聚類中心所在的簇中。
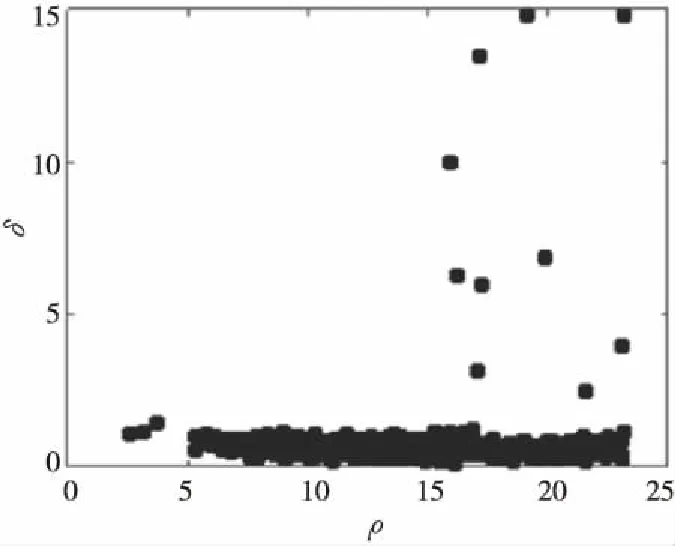
Figure 1 Decision graph of CFSFDP圖1 CFSFDP算法決策圖
CFSFDP算法不同于DBSCAN等聚類算法,其對于較低密度的簇類點沒有引入噪聲的概念,而是為每一個簇引入了一個光暈的概念,簇的光暈中則包含了其他算法中所定義的噪聲以及數據集中的離散點。CFSFDP算法將一個簇劃分為簇核心和簇光暈,屬于簇核心中的數據點的局部密度ρi較大,而屬于簇光暈中的數據點的局部密度ρi較小,局部密度ρi較小的點則包含了簇的噪聲點以及數據集的離散點。為了劃分簇的簇核心與簇光暈,CFSFDP算法引入了“邊界區域”的概念,它的定義為:數據點屬于該簇,但在與該數據點的距離小于dc的范圍內存在屬于其他簇的數據點,由這些點構成的區域范圍稱為該簇的“邊界區域”。在取得每個簇的“邊界區域”后,將“邊界區域”中局部密度最大的點的局部密度值作為該簇的簇核心與簇光暈的分割閾值ρb。最后根據該簇中的數據點的局部密度ρi與該簇的密度閾值ρb的關系將該簇數據點劃分到簇核心或者簇光暈中,若該簇內的數據點的局部密度ρi大于ρb,則該數據點劃分到該簇的簇核心中,否則將其劃分到該簇的簇光暈中。經過將各簇進行簇核心與簇光暈的劃分之后便得到了CFSFDP算法最終的聚類結果。
3 CFSFDP算法改進
CFSFDP算法在選擇聚類中心時需要人工輔助選擇,選擇方式為在決策圖中,將右上角的點作為起點,向左下方拉矩形,利用矩形框選擇與其它點差異最大的一組點,該組點即為聚類中心。該過程因為需要人工參與,使得算法的冗余性增加,并且人工選擇具有一定的主觀性,選擇結果的不同將會影響最終聚類的結果,這不利于最終結果的準確性以及算法的自動化。除此之外,CFSFDP算法在劃分簇核心和簇光暈時,會將一些處于簇邊緣的數據點劃分到簇光暈中,使得最終得到的聚類結果的準確性降低。本節針對CFSFDP算法上述兩個不足點提出了優化方案,使得算法可以自動選擇聚類中心且對于簇核心與簇光暈的劃分更為合理,從而獲得更合理的聚類效果。
3.1 聚類中心的自動選擇
通過對CFSFDP算法的介紹可知,CFSFDP算法有兩個基本立足點:
(1)聚類中心的局部密度很大。
(2)聚類中心與其他局部密度更大的數據點之間的距離相對較大。
根據這兩個基本立足點可知,聚類中心的局部密度ρi和與局部密度比其高的數據點之間的距離δi這兩個值都是比較大的。鑒于此,本文提出的聚類中心自動選擇的策略為:使用標準化的局部密度ρi和相鄰距離δi的乘積來評測聚類點之間的差異度,然后對于該乘積使用高斯分布進行異常檢測的方法得出其中的異常點,對于需要進行聚類的數據集而言,這些異常點即為聚類中心。高斯分布是非常適合做異常檢測的一個模型,分布在兩端的小概率事件可認為是異常點,利用這一點可以得到數據集的聚類中心。
首先引入一個簇中心權值的概念,定義一個數據點的簇中心權值γi為:
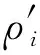
(4)
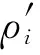
(5)
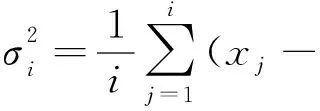
(6)
接著對于每個γi,根據公式(7)分別計算它們各自的概率密度。
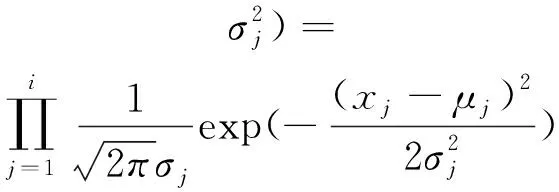
(7)
最后根據p(γi)與給定的一個閾值ε的關系來判斷數據點是否為異常點即聚類中心,ε為一個較小的常數,本文選取的閾值為0.005。對于交叉驗證集可以嘗試多個ε,并基于該ε計算交叉驗證集上的F1值,取最高者返回。F1的定義如下:
(8)
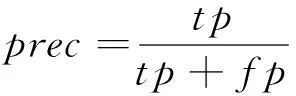

Figure 2 3-spiral dataset圖2 三螺旋數據集
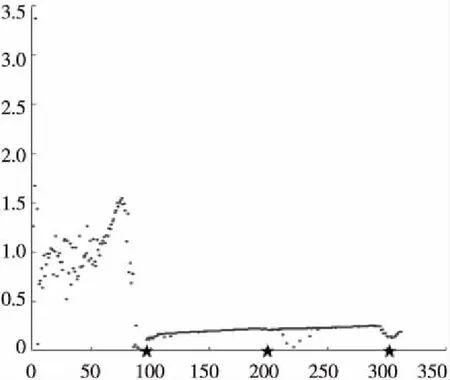
Figure 3 Clustering center obtained from anomaly detection圖3 異常檢測所得的聚類中心圖
算法1給出了聚類過程中簇的聚類中心自動選擇的具體步驟。
算法1聚類中心自動選擇策略
步驟1將每個數據點的局部密度ρi和數據點間的距離δi標準化。
步驟2求取每個點的簇中心權值γi。
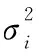
步驟4求取每個點的概率密度p(γi)。
步驟5判斷p(γi)與閾值ε的大小關系,若滿足p(γi)<ε,則該數據點為簇中心,否則不是聚類中心。
3.2 簇核心與簇光暈的分割優化

χ(διj-dc),ci=cj
(9)
算法2給出了在得到初步的聚類結果后,所得到的簇的簇核心與簇光暈分割的具體步驟。
算法2簇核心與簇光暈分割策略
步驟1確定簇的“邊界區域”。
步驟2求取“邊界區域”內每個數據點的簇內局部密度。
步驟3計算“邊界區域”的平均簇內局部密度。
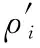
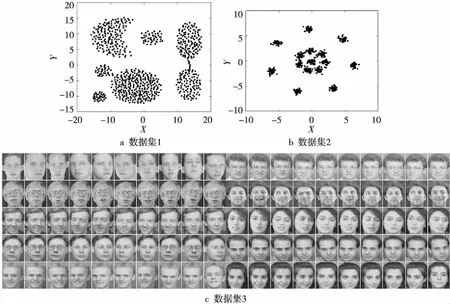
Figure 4 Three types of classical datasets圖4 三種典型的數據集
4 仿真實驗
為了表明本文所提算法的有效性,使用Matlab進行數據仿真得到聚類結果。選用三個具有代表性的數據集:數據集1來自文獻[13],是一組模擬的二維數據集,如圖4a所示,共有788個數據點,該數據集的數據分布較為密集,各區域間的分隔較為明顯,一般該數據集根據數據點的聚集情況被劃分為7類;數據集2來自文獻[14],是一組由15個相似的二維高斯分布組成的模擬數據集,如圖4b所示,共有600個數據點,該數據集中,四周的數據分布較為稀疏,中間部分的數據分布較為密集且各區域之間粘連較多,一般該數據集根據數據點的聚集情況被劃分為15類;數據集3是一組選自Olivetti人臉數據集(Olivetti Face Database)中的部分圖像,圖中每一行為同一個人的不同表情的圖像,同一個人的不同圖像之間有細微的差別,是一組真實的數據集,如圖4c所示。
圖5為使用原始CFSFDP算法對數據集1和數據集2進行聚類時得到的決策圖,圖中灰色的點為人工選擇得出的數據集的聚類中心,點的個數即為數據集聚類時類的個數,這些點是多次人工選擇聚類中心進行實驗后選出的最為合理的聚類中心點。圖6為使用本文所提出的異常檢測方法所得到的數據集中的聚類中心,圖中灰色的點為算法自動計算得出的聚類中心。
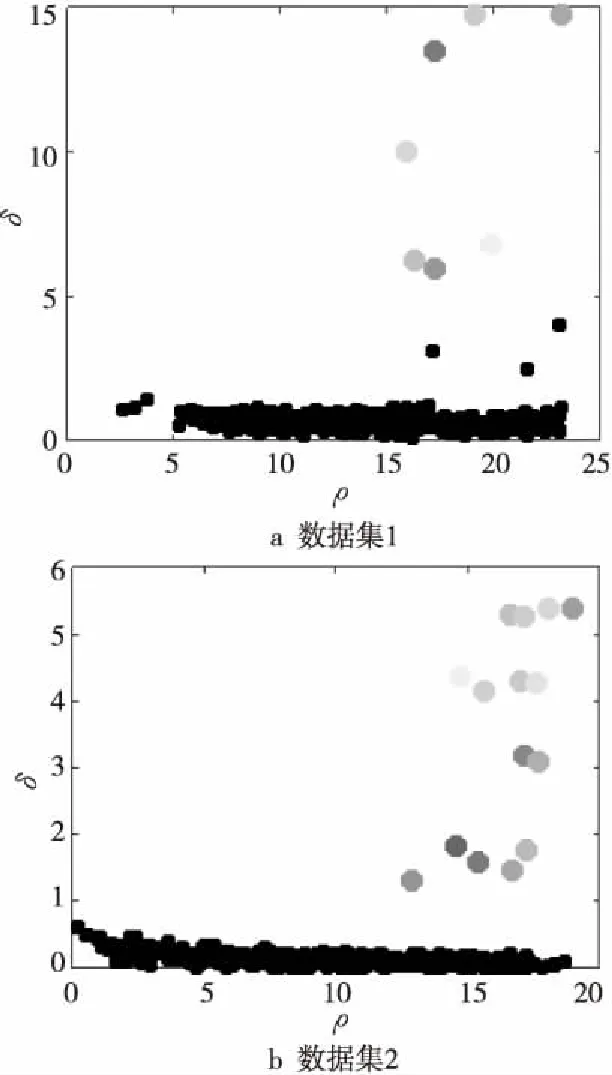
Figure 5 Decision graphs obtained by CFSFDP圖5 利用原始CFSFDP算法獲得的決策圖

Figure 6 Clustering center obtained from improved CFSFDP anomaly detection圖6 改進的CFSFDP算法異常檢測得到的聚類中心圖
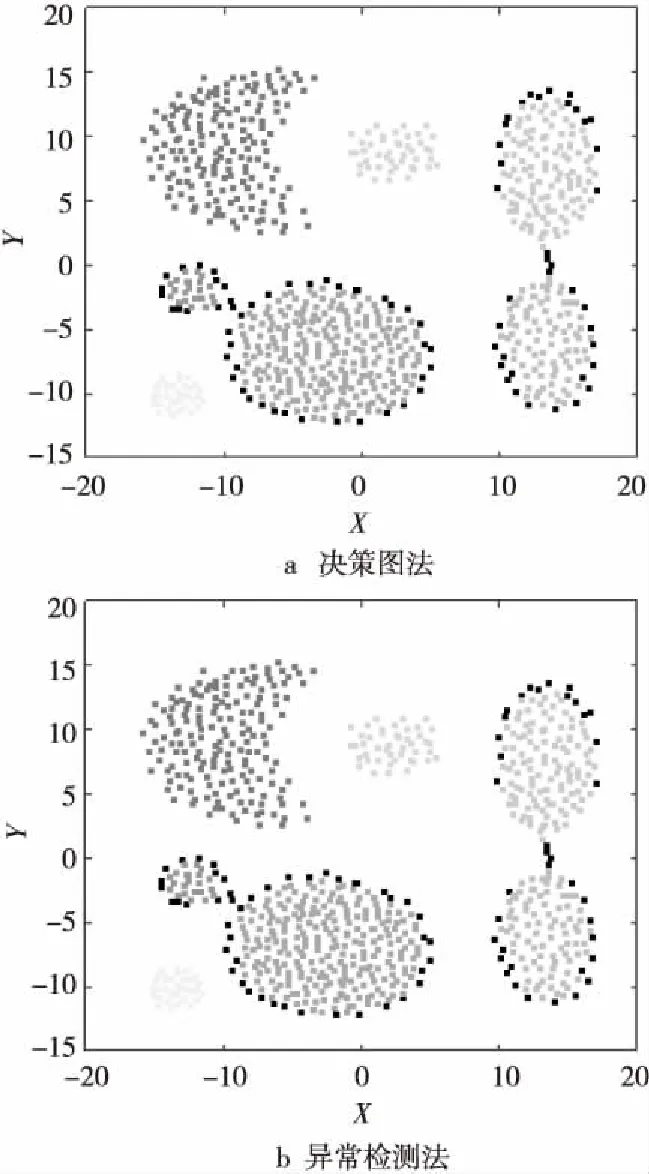
Figure 7 Comparison of decision graph and anomaly detection of datasets 1圖7 數據集1決策圖法與異常檢測法實驗結果對比
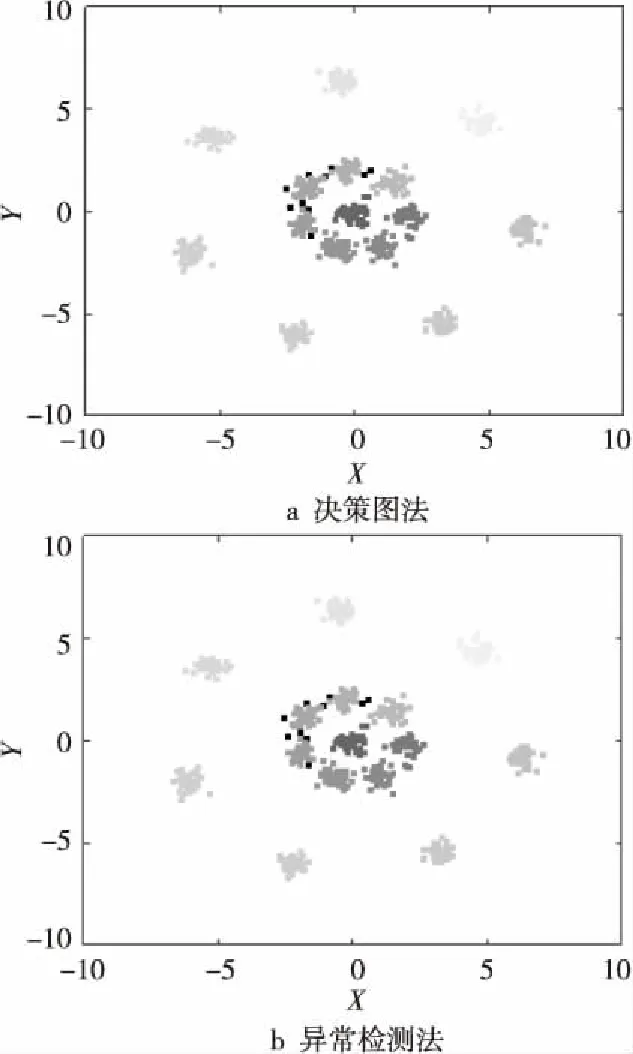
Figure 8 Experimental result comparison between decision graph and anomaly detection of datasets 2圖8 數據集2決策圖法與異常檢測法實驗結果對比
圖7和圖8為對數據集1和數據集2使用CFSFDP決策圖方法得到的聚類結果與使用改進的CFSFDP算法的異常檢測方法得到的聚類結果,圖中每種灰度代表一個簇,黑色的點則為各簇的簇光暈部分。圖7和圖8中使用異常檢測法得到的聚類結果中,簇核心與簇光暈的劃分使用的是原始CFSFDP算法中簇核心與簇光暈的劃分方法。從圖7和圖8對比可以看出,使用改進的常檢測方法得到的聚類結果與使用原始決策圖法得到的聚類結果完全相同,這表明使用改進的CFSFDP算法得到的聚類中心較為準確,可以代替使用原始CFSFDP算法的決策圖法人工選擇聚類中心,實現對CFSFDP算法的進一步自動化。
在得到初步的聚類結果后,對得到的簇進行簇核心與簇光暈分割優化后的實驗結果如圖9所示,圖中黑色的點為分割后的簇的簇光暈部分。通過圖9a與圖7a的對比以及圖9b與圖8a的對比可以看出,使用本文提出的簇核心與簇光暈優化分割方法得到的實驗結果,將簇的邊緣部分本屬于簇核心部分的數據點劃入簇光暈中的幾率變小,只有簇之間粘連部分的數據點以及數據集中的離散點被劃入了簇光暈中,得到的最終實驗結果與CFSFDP算法得到的實驗結果相比更為合理。
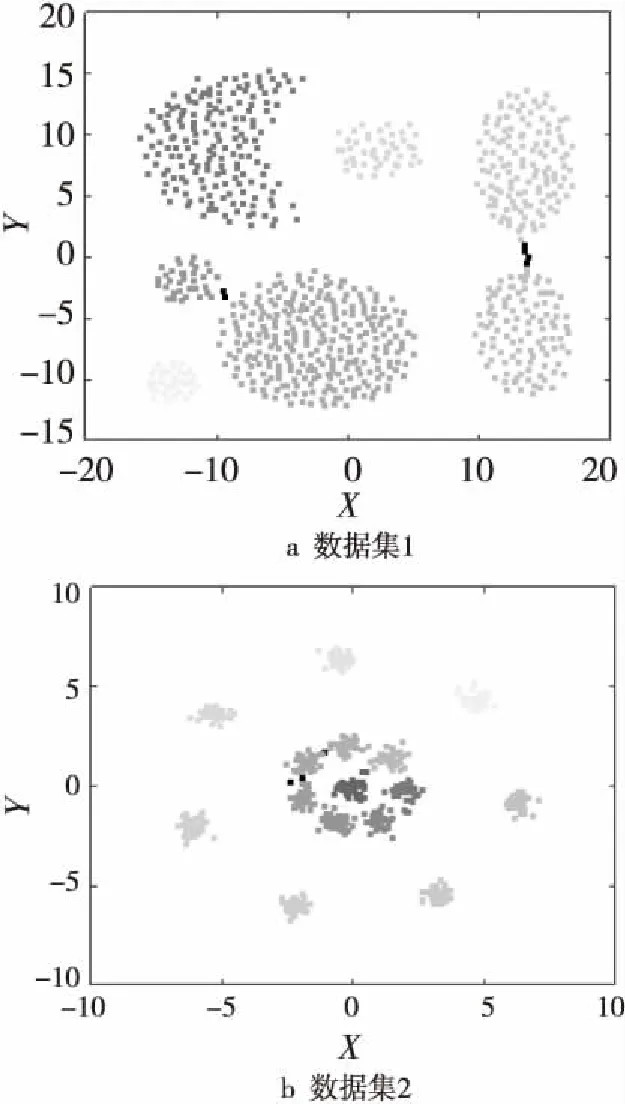
Figure 9 Division optimization results of cluster core and cluster halo圖9 簇核心與簇光暈分割優化實驗結果圖
圖10為對數據集3的Olivetti人臉數據集聚類后的結果,圖10a為使用CFSFDP算法得到的聚類結果,圖10b為使用本文改進的CFSFDP算法得到的聚類結果。圖10中的人臉小圖的右上角使用圓點標記的為算法所選擇的聚類中心,人臉小圖左下角的每種小圖標代表一個簇,左下角未被小圖標標記的人臉小圖則不屬于任何一個簇。從實驗結果可以看出,本文改進的CFSFDP算法自動選取的聚類中心與原始CFSFDP算法人工選取的聚類中心相同,從聚類的結果來看本文改進的方法略優于原始的CFSFDP算法。

Figure 10 Clustering result comparison between CFSFDP and the optimized CFSFDP 圖10 原始CFSFDP算法與本文改進的CFSFDP算法對Olivetti人臉數據集進行聚類的實驗結果圖
從上述對比實驗可以看出,本文提出的方法可以有效地提高CFSFDP算法的自動化程度,且聚類效果更準確有效。
5 結束語
本文提出的算法是對CFSFDP算法的兩點不足進行的優化改進。針對CFSFDP算法需要在決策圖中人工選擇聚類中心,導致算法的準確性和自動化受到影響,本文采用改進的CFSFDP算法的異常檢測方法自動計算出聚類中心,針對CFSFDP算法最后進行簇核心與簇光暈分割時會將簇的邊緣數據點劃入簇光暈中,影響實驗結果,本文通過引入簇內局部密度,根據簇內數據點的局部密度與簇內局部密度的平均值的關系劃分簇核心和簇光暈。仿真實驗對比結果表明,本文提出的算法是有效可行的,其實驗結果比原始CFSFDP算法的實驗結果更為準確合理。
