基于標記信息級聯傳播樹特征的謠言檢測新方法
2018-08-23 03:06:32蔡國永畢夢瑩劉建興
計算機工程與科學 2018年8期
蔡國永,畢夢瑩,劉建興
(桂林電子科技大學廣西可信軟件重點實驗室,廣西 桂林 541004)
1 引言
推特Twitter(http://www.twitter.com/.)和新浪微博Sinaweibo(http://www.weibo.com/.)是兩種典型的社交網絡平臺,它們允許用戶發布小于140個字符的短消息并將信息傳遞給他們的粉絲,這些短消息支持添加圖片、視頻等多媒體數據。粉絲們帶評論或不帶評論的轉發行為促進了這些消息在社交網絡中的傳播。由于消息沒有經過把關,社交網絡容易成為謠言傳播的溫床。不少事實證明,網絡謠言會引起嚴重的公眾恐慌和社會動蕩,如2013年4月23日,推特上的一條關于美國總統奧巴馬在白宮爆炸中受傷的消息導致道瓊斯指數在幾分鐘內下跌140個點。由于謠言的危害性,學者們開始關注社交網絡中謠言的自動檢測問題。
謠言識別通常被視為二分類問題,基于統計方法進行特征檢測是提高分類器性能的關鍵,目前社交網絡謠言檢測研究中,已設計的檢測特征主要分為5類:(1)基于內容的特征,即依據微博文本,考慮文本內容統計特征,例如文本長度、標點符號、是否包含短鏈接、標簽、表情符號或詞性標注等簡單特征[1,2],以及情感分數、詞向量等深層語義特征,如文獻[3]發現,用神經網絡語言模型生成微博的文本向量表示有助于謠言檢測。(2)基于用戶的特征,包括用戶注冊的時間、地點、用戶性別、年齡、用戶名、頭像、是否認證、關注數、粉絲數、描述、主頁、已發微博數等[4,5],也有基于用戶行為特征的相關研究[6]。(3)基于傳播結構的特征,指的是消息傳播樹結構或用戶朋友的網絡結構,比如節點個數、根節點的度[1,5,7]、用戶傳播類型[8,9]、標記傳播樹[10]等。(4)基于時間的特征,即關注消息的發布時間并將其與源微博發布時間或用戶注冊時間相比較[5]。一些模型用時間來檢測群體響應中量的突增或周期的突增[11]。一些研究[8,11]利用時間來計算傳染病模型中各用戶類型之間的變化率。一些研究[1]用時間作為衰減因子來度量響應中情感強度。(5)基于群體響應的特征,即大眾對于一個事件的觀點或態度[12 - 15],如文獻[13]根據謠言帖會存在或多或少的相關質疑帖,基于尋找質疑短語、聚類不包含質疑短語的帖子,并通過計算包含真實消息的可能性將聚簇分類,進而判定是否為謠言。除上述5大類特征外,還有一些其它上下文特征,如發布消息的客戶端類型、發布消息的地點等。
現有的謠言檢測研究中,關注的謠言判別特征集中于微博消息的扁平特征,如消息構成特征、消息發布者特征、轉發特征等,這些特征雖然有助于謠言檢測,但過于簡單化,因為它沒有考察消息傳播的內部時態結構和傳播用戶反應特點。如果謠言檢測時不僅考察消息描述的內容、消息的表達方式,而且還考察被哪些人轉發并做出了何種響應,這將能夠更為準確地判斷微博消息是否是謠言。
針對上述問題,本文在文獻[10]的基礎上提出一種改進的標記信息級聯傳播樹CA-LPT(Labeled CAscad Propagation Tree),并在此模型下定義一種新的意見領袖影響力動態度量方法,然后提出20個特征(其中10個為新特征),并用隨機通路圖核和RBF(Radial Basis Function)核構成的混合核構造支持向量機SVM(Support Vector Machine)分類器,進行微博謠言檢測,并通過實驗驗證謠言檢測的性能。
2 謠言檢測特征構造
根據文獻[10],一棵傳播樹T=〈V,E〉,V中的每個節點m表示微博上的一條文本消息。文本消息m與發布用戶u的元數據〈s,l,f,w,b,k,v〉相關聯,其中用戶元數據包括:性別s、關注數l、粉絲數f、微博數w、互關數b、注冊時間k、是否認證v。傳播樹的根節點稱為“源微博”,傳播樹中所有其它節點被稱為“轉發微博”,可以是轉發評論源微博,也可以是轉發評論其它轉發微博。如果m2是對m1的轉發評論,則從m1到m2有一條定向邊。當一個微博用戶的粉絲數(followers)與關注數(friends)滿足約束條件followers/friends>α,且followers≥1000時,稱此用戶為意見領袖。如果節點微博來自意見領袖,則將節點標注為p,否則標注為n。標注好節點類型的消息傳播樹稱為標記傳播樹LPT(Labeled Propagation Tree)。
基于Twitter的研究表明:在信息傳播過程中,用戶影響力與其粉絲數量呈弱相關[16 - 18]關系。微博中存在一些用戶尤其是造謠者,通過增加粉絲數量來增大其影響力,然而這些粉絲大多是活躍度極低的僵尸粉絲,他們不評論不轉發甚至不登錄,不具有任何傳播信息的能力,因此粉絲數量大只是用戶具有影響力的必要非充分條件。此外,微博中的絕大多數用戶屬于消極的信息消費者[19],他們傾向于瀏覽來自其他用戶的消息卻很少發布或轉發消息。能否調動這些消極用戶分享信息的積極性,才是衡量用戶影響力大小的關鍵因素。因此,在衡量用戶的影響力時需要更加強調用戶影響其粉絲傳播信息的能力,而非僅僅注重其將信息傳播給其受眾的能力。另外,用戶的影響力會隨時間和主題的變化而發生變化,文獻[20]從用戶影響力和活躍度兩方面建立意見領袖影響力體系,發現只有極少的用戶能夠同時成為不同主題的意見領袖。
由此可見,LPT模型中定義的意見領袖度量并不恰當,標記的信息也不能充分反映傳播的動態性,需要進一步改進。
2.1 標記信息級聯傳播樹模型
針對LPT存在的問題,將消息傳播的級聯模型[19]引入LPT中。將用戶轉發或發布消息的時間ti作為節點的一個屬性保留在標記傳播樹中,即把節點標記擴展為(ui,ti),從而允許分析消息傳播的動態過程。在此基礎上重新定義意見領袖度量公式,意見領袖集合按公式(1)計算。這里意見領袖定義為在消息傳播過程中短時間內能夠引起其粉絲大量轉發的用戶,具有較大出度的節點。
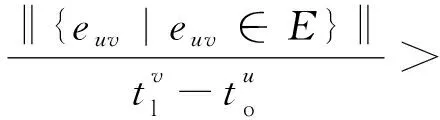
(1)
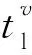
除此之外,本文在LPT的有向邊上標記轉發微博的情感值,即用rj=(δ(a),δ(d),δ(s))標注從mi到mj的邊ej,其中a是mj的贊成分數,表示贊成或同意;d是mj的質疑分數,表示質疑或反對;s是mj的平均情感分數。δ(x)是時間衰減函數,即δ(x)=2-μtx,其中t是源微博與mj之間的時間差,μ是取0~1的參數。一個用戶轉發評論越快,說明情感越強烈。
通過上述改造的LPT稱為標記信息級聯傳播樹模型(CA-LPT),標記完整的CA-LPT模型示例如圖1所示。
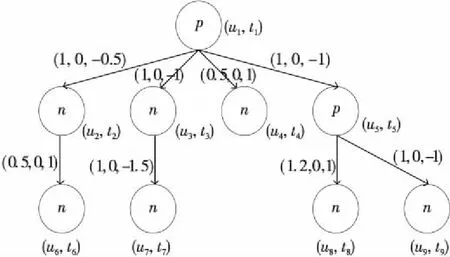
Figure 1 Labeled cascade propagation tree (CA-LPT)圖1 標記信息級聯傳播樹CA-LPT模型
2.2 謠言檢測特征設計
在CA-LPT模型的基礎上,本文提取20個特征來建立特征向量,如表1所示,其中的謠言庫、可疑用戶庫、質疑驚訝反對情感分數等10個是新設計的特征(表1中用粗體顯示),其余10個特征是以往研究中被證實為有效的特征。下面對這些特征分別說明。

Table 1 Description of 20 features
2.2.1 謠言庫特征
通過分析收集的2016年03月01日~2016年05月03日微博不實信息舉報處理大廳公布的437條謠言,發現謠言涉及28個話題,有4個話題只包含一條相關謠言微博,剩下的24個話題均有至少2條謠言微博與之相關;有14%的謠言只發布了一次,近86%的謠言被發布兩次以上。統計結果表明,謠言發布的重復率非常高,即相同話題甚至相同內容的謠言會由不同用戶多次發布,而且過期謠言會被重新發布。因此,可建立一個謠言庫,比較未知微博文本與謠言庫中謠言文本的相似度,如果能夠找到一條謠言庫中的謠言與此微博內容相似,則此微博有很大可能是謠言。本文實驗中謠言相似度值基于Jaccard相似性公式計算。
2.2.2 可疑用戶庫特征
收集2014年04月01日~2016年05月03日微博不實信息舉報處理大廳公布的共2 601條謠言,統計分析顯示:這些謠言共涉及2 031個用戶,也就是說存在一些用戶發布了不止1條謠言;如果把發布了1條謠言的用戶稱為次可疑用戶,把發布了至少2條謠言的用戶稱為超可疑用戶,那么統計結果顯示2 031個可疑用戶中13%發布謠言超過2條,屬于超可疑用戶;超可疑用戶中近一半都發布謠言超過3條,有的甚至發布了10條以上的謠言;近1/3的謠言是由這些少量超可疑用戶發布的。因此,建立一個可疑用戶庫來判斷用戶的可信度,若發布未知微博的用戶存在于可疑用戶庫中,返回true;反之返回false,將返回的布爾值賦值給給定微博的可疑用戶庫匹配這個特征。
2.2.3 質疑驚訝反對率和平均情感分數
已有研究證明,通過判斷一條微博的群體響應(轉發和評論)屬積極情感還是消極情感在一定程度上可以區分謠言與非謠言,然而并不能達到很好的效果。因為一條微博的群體響應情感往往同微博本身的情感息息相關。例如,一條具有消極情感的非謠言微博敘述的是一條令人痛心的社會新聞,其群體響應大都包含“難過”“可憐”“[淚]”等消極情感;一條具有積極情感的謠言微博描述了一則振奮人心的奇聞異事,其群體響應大都包含“驕傲”“碉堡”“[給力]”等積極情感。因此,根據一條微博的群體響應是積極情感還是消極情感判斷其是否是謠言是不完全準確的,積極情感不一定是贊成或同意,消極情感不一定是質疑或反對,應該將情感更具體細化到贊成、質疑、驚訝、反對等能明確表達個人主張的觀點上。
本文通過3步計算一條微博群體響應的情感值:
(1)根據Hownet情感分析詞典中的正負面評價詞和正負面情感詞提取表達質疑、驚訝、否定觀點的情感詞,分別建立質疑情感詞典、驚訝情感詞典和反對情感詞典,還包括新浪微博中表達上述情感的共482個表情符號;
(2)將未知微博下的每條轉發進行分詞、去除停用詞等文本預處理;
(3)分別計算群體響應的質疑率(即Ndoubt/N)、驚訝率(即Nsurprise/N)、反對率(即Noppose/N)。其中,N*是包含情感詞典中的質疑詞驚訝詞反對詞的轉發微博數量,N是所有轉發數量。
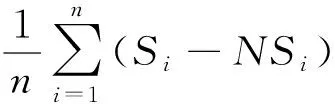
2.2.4 傳播樹深度
謠言微博通常起始于個人或團體,而真實微博會由很多無關個體發起或證明。造謠團體之間的聯結是很緊密的,團體成員之間通過互轉發達到增大轉發量、擴大影響力的目的,同時這會造成傳播結構的深度過大;而正常微博的轉發用戶之間由于通常是無關個體,傳播結構深度不會很大,影響力比較大的新聞事件比如王菲離婚微博發布幾小時后轉發最深僅達到13層。所以,深度過大的微博一般不是正常微博。
2.2.5 意見領袖質量
根據知微平臺(http://www.zhiweidata.com/#a)分析,計算新浪微博2015年影響力最高的100個事件,并綜合賬號影響力、風云榜排名得出1 886個微博意見領袖,統計用戶的身份分布發現:其中86%是名人認證用戶,10%是達人用戶,僅4%是普通用戶。一般參與謠言轉發的用戶的質量都不高,尤其是雇傭僵尸粉、水軍幫轉謠言的,意見領袖的質量也不高,因此可以用所有挖掘出的意見領袖的加V比例(即Vkol/Nkol)來度量一條微博的意見領袖質量,其中Vkol表示一條微博中挖掘出的經過認證的意見領袖數量,Nkol表示挖掘出的所有意見領袖數。
3 基于混合核函數的SVM謠言分類器
支持向量機SVM分類算法在解決小樣本、非線性及高維模式識別中表現出良好性能,并能夠推廣應用到函數擬合等其他機器學習問題中,本文選擇SVM分類算法用于微博謠言的檢測。傳統SVM分類器基于簡單的扁平特征向量,但是實際中很多數據都是結構化的。由于這個原因,常常需要合并混合結構(比如樹和圖)作為SVM的核。通過將異構數據的不同特征分量分別輸入對應的核函數進行映射,使數據在新的特征空間中得到更好的表達,能顯著提高分類正確率。本文采用加權求和核,即式(2)來混合隨機通路圖核與RBF核:
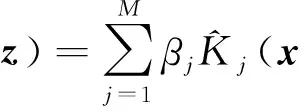
(2)
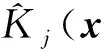
本文用{Xi,yi}表示源微博mi,Xi有20維,yi是類標簽。RBF核定義如式(3)所示:
(3)
由直積圖G×可以得到對應的鄰接矩陣A×,定義A×中的元素[A×](u,u′),(v,v′)=l:
(4)
其中,核函數k度量邊e(u,v)和e(u′,v′)之間的相似度的方法,由式(5)給出:
k((u,u′),(v,v′))=
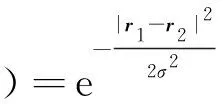
(5)
其中,r1是邊e(u,v)的標簽向量,r2是e(u′,v′)的標簽向量,σ為常數,e表示自然常數。
給定鄰接矩陣A×和權重參數λ≥0,定義標記信息級聯傳播樹T和T′上的隨機通路核為:
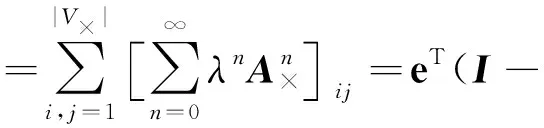
(6)
其中,e表示單位向量,I表示單位矩陣。
此外,每個源微博mi對應一棵傳播樹Ti,為了規范化式(6)中兩棵傳播樹的核函數,將K×(T,T′)除以nn′,其中n和n′分別是T和T′的節點數:
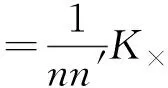
(7)
因此,結合式(3)和式(7),最終微博mi和mj的核函數定義為:
K(mi,mj)=βKG(Ti,Tj)+(1-β)KR(Xi,Xj)
(8)
其中,0<β<1,β決定隨機通路圖核與特征向量核相比的傳播權重。實驗中基于式(8)訓練SVM分類器。
4 實驗與分析
為得到合適的訓練集,收集了2015年04月10日~2016年05月03日微博不實信息舉報處理大廳(SinaWeibo.(2015).Weibo-Misinformation-Declaration [Online].Available:http://service.account.weibo.com/?type=5&status=0)和官方辟謠賬號@微博辟謠(SinaWeibo.(2015).@Weibopiyao [Online].Available:http://www.weibo.com/weibopiyao?from=myfollow_all)公布的共9 834條謠言。由于要考察謠言的傳播結構,而且謠言的一個必要條件是必須有足夠的傳播量,因此保留那些轉發至少100次的謠言,共694條組成謠言集。在真實世界中,新浪微博中的謠言數量遠遠小于正常微博數量,為了避免不平衡數據集達到過高準確率的假象,需要建立一個謠言數與非謠言數大致相等的數據集。隨機選取3 000個沒有被證明是謠言的微博以及它們的轉發微博,手動過濾轉發量小于100的微博,組成1 099條正常微博集。通過新浪微博提供的API抓取這1 793條微博及其所有轉微博,每條微博或者轉發微博都包含它們的作者信息(性別、粉絲數、關注數、微博數等)、時間戳、客戶端等。表2為數據集的基本概況。
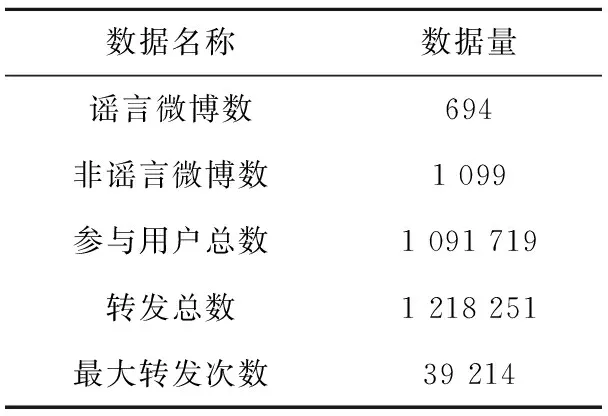
Table 2 Overview of dataset
由于新浪微博提供的API抓取的數據特征稀疏且高度冗余,需要對爬取的原始微博數據進行預處理。對于建立RBF核的20個靜態特征,直接從原始數據表中提取所需的低階特征,或間接提取計算高階特征所需的低階特征;對于建立隨機通路圖核的傳播特征,提取轉發微博的父mid、子mid、轉發時間戳等特征構建標記消息級聯傳播樹模型,計算傳播樹之間的相似度。直積圖最大生成43 498個節點,鄰接矩陣43 498維,用稀疏矩陣存儲,要求有足夠計算資源的硬件支持。本文實驗基于20內核CPU,128 GB內存的服務器,采用SVM開源軟件LibSVM的Java軟件包,并結合WEKA數據挖掘平臺,實現分類器的訓練和測試。實驗基于十折交叉驗證,用傳統的準確率Precision、召回率Recall和F-score來評價本文提出的方法和新特征的有效性。
4.1 CA-LPT模型的有效性
為了驗證改進模型CA-LPT的有效性,用不同的特征子集來訓練SVM分類器。實驗結果如圖2和圖3所示,圖中R表示謠言,N表示非謠言,*+O表示模型*下的圖核與以往研究的靜態特征構成的特征子集;*+O+N表示模型*下的圖核與以往研究的靜態特征加上10個新特征構成的特征集。
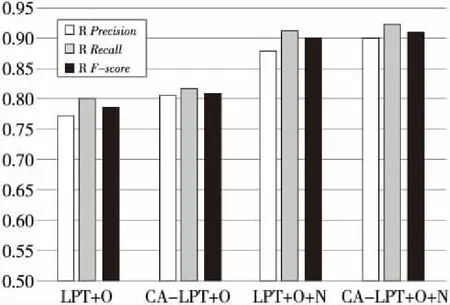
Figure 2 Comparison between LPT and CA-LPT on rumor debunking圖2 LPT模型與CA-LPT模型謠言識別比較
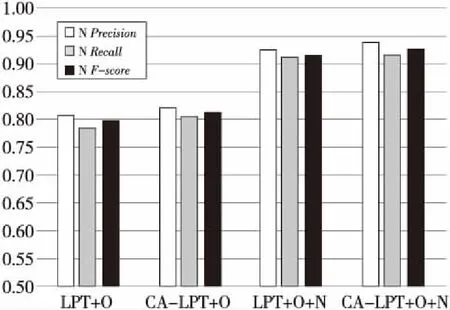
Figure 3 Comparison between LPT and CA-LPT on non-rumor debunking圖3 LPT模型與CA-LPT模型非謠言識別比較
圖2和圖3的結果說明,CA-LPT模型結合新提出的特征子集相比僅考慮粉絲數和關注數等靜態特征的LPT模型確實提升了謠言識別的效果。
本文還與一些經典的謠言檢測算法進行了對比:利用Liang等[6]提出的9個基于用戶行為的新特征和其中7個本文也用到的經典特征訓練第一個SVM分類器;利用Castillo等[5]提出的15個特征訓練第二個SVM分類器;利用Yang等[22]提出的全部20個特征訓練第三個SVM分類器。結果如表3所示。表3結果表明,本文的基于CA-LPT方法性能更優。
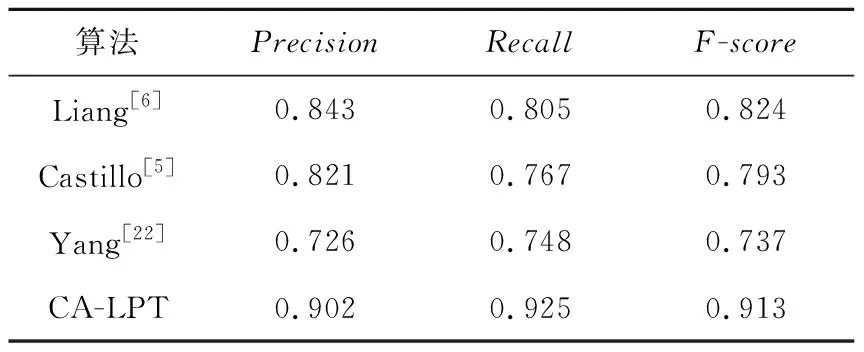
Table 3 Performance comparison among different algorithms
4.2 新特征的有效性
為了驗證新提特征的有效性,用老的特征集結合不同的新特征子集訓練無圖核SVM分類器,結果如圖4所示,其中“(-)*”表示除特征*外的特征子集。
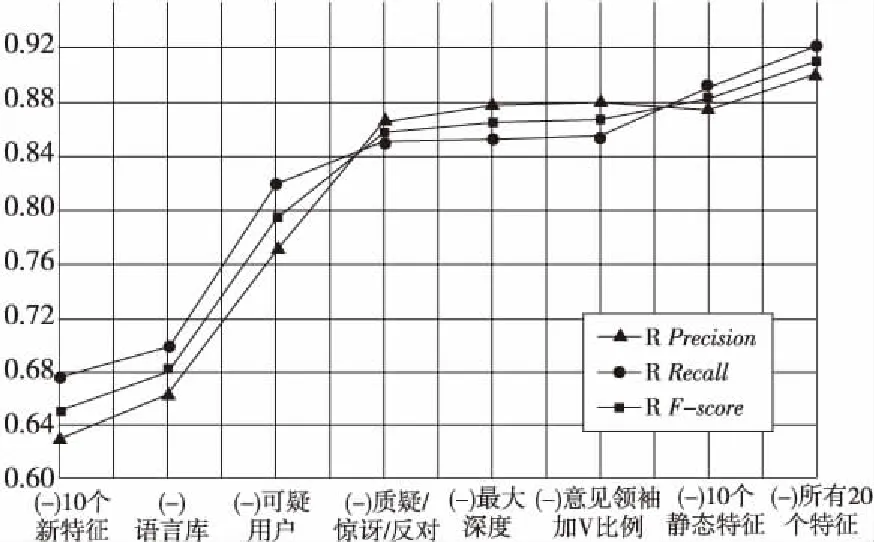
Figure 4 Efficiency comparison among new features圖4 新特征有效性對比
很明顯,謠言庫匹配特征、可疑用戶匹配特征對謠言的識別起到很大作用,傳播樹結構的最大深度和意見領袖加V比例對識別也有所幫助。然而,群體響應中的質疑驚訝反對情感特征的重要性并未達到預期效果,原因可能是質疑驚訝反對的情感詞匯數量有限,情感詞典不夠完善,對每條微博下群體響應內容中的這些情感詞未完全識別,導致情感分數非常稀疏,因此可以考慮進一步完善和自動擴展情感詞典等知識庫來改進。
4.3 檢測方法的時間性能
由于微博數據集規模龐大,算法的時間性能也是一個重要的評價指標。本實驗隨機選取1 793條微博中的60%作為訓練集,其余717條微博作為測試集。算法主體分3步運行:
Step1根據用戶影響力度量方法尋找消息傳播過程中的意見領袖用戶并在消息傳播樹中標記;
Step2生成消息傳播樹之間的直積圖以及對應的鄰接矩陣;
Step3根據鄰接矩陣計算消息傳播樹之間的隨機通路圖核。
其中Step 2需要生成717×1076=771492個直積圖及其對應的鄰接矩陣,Step 3的矩陣逆運算復雜度大且鄰接矩陣最大達到43 498維,因此時間開銷較大。LPT模型與CA-LPT模型的算法運行時間對比如表4所示。
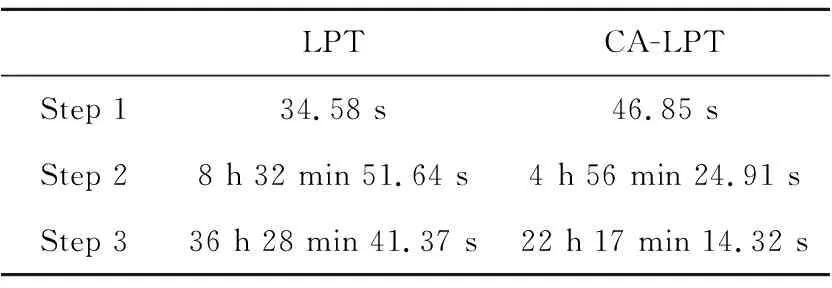
Table 4 Time performance comparisonbetween CA-LPT and LPT
分析表4的實驗結果,由于CA-LPT模型在挖掘意見領袖的過程中做了改進,不再只考慮用戶的粉絲數和關注數,需要挖掘用戶發布微博或轉發的時間戳和節點的總出度,導致Step 1程序運行時間略大于LPT算法;CA-LPT模型賦予意見領袖更嚴格的條件,減少了大量LPT中挖掘的意見領袖數量,合并了大量的非P節點,從而可以大幅縮小傳播樹的規模,最終減小直積圖以及對應的鄰接矩陣的維度,這對于提高計算消息傳播樹之間的隨機通路圖核的效率也有很大幫助,因此Step 2、Step 3的運行時間均有大幅縮短。
5 結束語
本文將消息傳播的級聯模型引入LPT模型中,提出改進的標記信息級聯傳播樹模型CA-LPT:計算單位時間內用戶驅動其粉絲進行轉發的數量來動態度量用戶影響力,而非僅僅考慮用戶的粉絲數和關注數等靜態特征。真實微博數據集上的實驗結果表明,基于CA-LPT模型比基于LPT模型設計的特征可以獲得更高的謠言識別準確率。實驗也表明,謠言庫匹配特征、可疑用戶庫匹配特征以及群體響應中的質疑、驚訝、反對等情感特征能夠顯著提高謠言識別的效果。然而,真實的社交媒體平臺中謠言微博的數量遠遠小于正常微博的數量(通常達到1∶9甚至更少),用處理平衡數據集的理論和方法來處理非平衡數據集顯然不適用,因此考慮謠言檢測中的數據分布不平衡問題、提高算法對少數謠言的識別性能將是下一步待解決的問題。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
