遺傳算法改進的多模式污染物集成預報
2018-08-17 03:18:30鄧雪晨熊聰聰
計算機工程與設計 2018年8期
鄧雪晨,熊聰聰+,董 昊
(1.天津科技大學 計算機科學與信息工程學院,天津 300222; 2.天津市氣象局觀測與預報處,天津 300072)
0 引 言
目前大氣污染物濃度預報方法主要分為統計預報和數值預報[1]。國內研究大多采用數值預報模式[2]且已經得到廣泛應用[3,4],但由于各個數值模式化學參數化方案等方面存在差異,使得各個模式在預報能力上存在不同,多模式集成技術正是利用各模式中心預報的結果減少模式系統性的偏差[5],現已作為一個重要發展方向。陳煥盛等采用多元線性回歸方法集成各空氣質量模式預報大氣污染物濃度,實驗結果表明,集成預報模式優于單個預報模式[6]。秦珊珊[7]提出針對大氣污染物PM2.5,建立人工智能優化神經網絡模型進行預報。Zhang Ping等[8]利用當地的地理信息資源,提出用改進的BP人工神經網絡進行大氣污染物PM2.5濃度的預報,仿真實驗得出隱含層神經元為20時精度較高。Sun等[9]通過實驗驗證了基于SVM的空氣質量預報模型(PM2.5)能有效應用于大氣污染物濃度預測,但在極端情況下預報精度有所下降。
總的來說,多模式集成預報的研究成果多采用線性回歸、機器學習等方法進行預報。線性回歸針對非線性問題解決能力較差,而神經網絡具有很好的解決非線性問題的能力,但其中BP神經網絡算法缺陷是學習速度較慢、訓練過程會陷入局部最小及不能確定隱層的神經元個數問題;而遺傳算法缺陷是訓練時間較長,訓練過程中容易出現早熟。本文采用多種單模式作為算法輸入層,利用極限學習機優秀的非線性映射能力改進遺傳算法迭代速度慢,容易早熟的缺點,在不斷迭代過程中加快子代種群的搜索速度,達到精度高、收斂快的效果。在氣象局大氣污染物濃度預報數據基礎上,用提出的改進算法與BP、SVM、遺傳等集成方法進行對比實驗,驗證了改進算法的有效性。
1 多模式集成算法
1.1 遺傳算法
遺傳算法作為一種全局優化算法,基本原理是取n維向量x=[x1,x2,…,xn]表示成由xi(i=1,2,…,n)所組成的符號串,符號串中每一個xi看作成一個遺傳基因,則x作為由n個遺傳基因所組成的染色體鏈,多個染色體構成的種群叫作初始種群。將假設的染色體置于問題中,首先設定目標函數對每個個體進行評價,給出適應度以評判染色體的優劣程度。按照適者生存的原則,選出適應度較高的個體進行復制、交叉以及變異,產生適應度更好的新一代種群,個體x適應度越大,越趨近于最優解。隨后,根據適應度選取一定的個體作為下一代種群繼續進化,如此進行多次后,算法收斂于最好的染色體(最優或次優解)。
遺傳算法存在過早收斂、計算時間長等問題。所以針對遺傳算法的改進國內也有很多研究成果。曲志堅等[10]通過自適應方法改進遺傳算法,有效地把握總體的進化方向,提高全局收斂能力。陳璐璐等[11]將遺傳算法與粒子群算法相混合,用粒子群方法優化速度和位置,從而提高運算速度和精度。
1.2 極限學習機
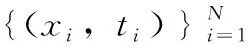
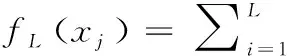
(1)
式中:a=[ai1,ai2,…,ain]即為輸入層與隱藏層間第i個節點的連接權值;βi=[βi1,βi2,…,βin]T即為隱藏層第i個節點與輸出層的連接權值;g(aixj+bi)為第i個隱層神經元的輸出,g(·)為神經元激活函數。單隱層前饋神經網絡模型如圖1所示。
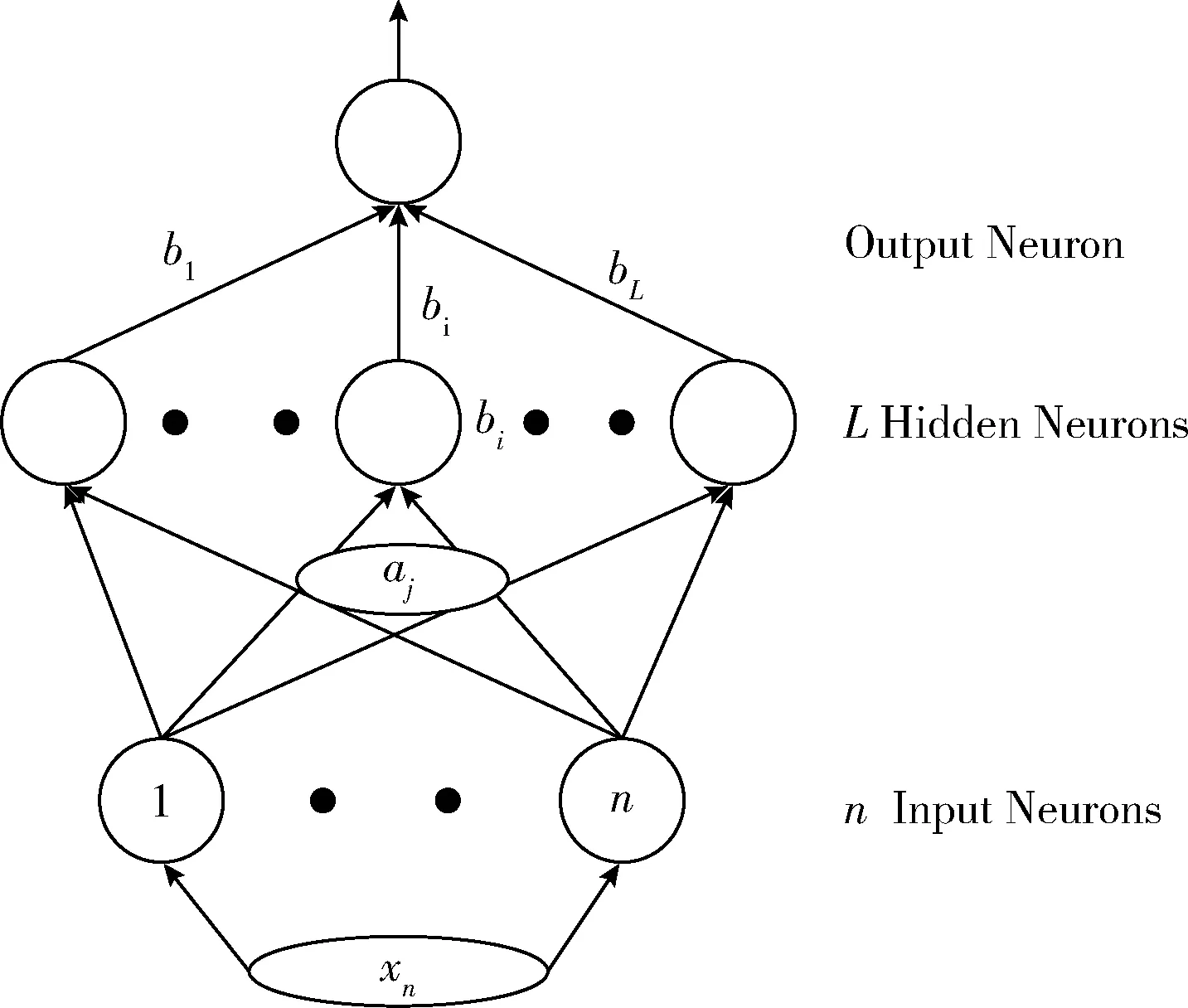
圖1 單隱層前饋神經網絡模型
式(1)還可以表示為
Hβ=Y
(2)
式中:H即為神經網絡的隱含層輸出矩陣,具體形式可以表示為
(w1,…,wL;b1,…,bL;x1,…,xn)=
單隱層前饋神經網絡的隱含層神經元定義請參見文獻[12]。因此,當激活函數無限可微時,隱含層與輸出層的連接權值通過求解最小二乘值獲得
(3)
式中:H+為矩陣H的廣義逆。
2 遺傳算法改進的多模式集成預報模型
構建多模式集成預報模型的目標是實現對天津本地6種大氣污染物(NO2,O3,PM2.5,PM10,CO,SO2)要素進行客觀精細化集成預報。資料時間長度為2015年全年每日預報數據值。
2.1 輸入層對象的選擇
本文采用集成多個單一預報模式的方法,針對春(3月-5月)夏(6月-8月)秋(9月-11月)冬(12月-2月)4個季節分別進行單模式的選取。所用方法在滿足顯著性檢驗基礎上,針對每個季節的8種不同模式以及實況值通過數學公式計算出相對偏差(standard deviation,SD)和相關系數R進行篩選。在此基礎上,將選出的單模式進行主成分分析,選取貢獻率在95%以上的各主成分并判斷各單模式在多個主成分的分析中是否占有一定比重。如式(4)、式(5)所示
(4)
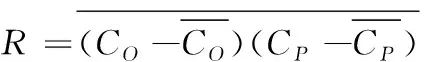
(5)
其中,σo、σp分別表示實況值和模擬值的標準差,CP為模擬值,CO為實況值。
春季或冬季篩選出7種單模式或方案:BREMPS、MADE、MOS、MYJ、MYN3、BL、YSU;夏季4種單模式或方案:MOS、MYJ、MYN3、YSU;秋季8種均符合。采用集成預報的目的不僅在形式上要比單模式預報簡潔,并且還要具備更好的穩定性和精準度。
為了更好地體現各單模式的客觀預報能力,集成過程并不是簡單地平均分配權重,平均分配權重效果并不理想,而是針對單模式的能力給出合理權重,并且權重的分配具體到每個成員在不同時間點的區別。集成預報式(6)如下
(6)
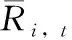
2.2 集成預報算法
模式預報會隨季節變化呈現一定規律,過多選取樣本會造成計算量大且描述預報規律不準確,導致過擬合。最佳方案是在分季節預報基礎上找到預報時刻最近30 d的歷史數據作為訓練樣本,即待集成數據所對應訓練樣本均為滾動更新,每個樣本的實況值為網絡訓練的輸出,所以輸出層神經元為1。注意模型訓練之前要對數據進行歸一化處理。
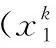
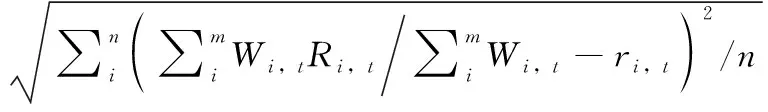
(7)
式中:i為集成預報成員模式;t為預報時間點;m為成員個數;n為一次預報時間點數目;E為集成結果與實際數據的均方誤差;Wi,t為第i個成員模式在第t個時間點上的權重系數;Ri,t為該污染物第i個成員模式在第t個時間點的預報值;ri,t為第i個模式在預報時間點t的實況值,計算使得污染物集成預報均方誤差的倒數達到最大。ELM進化機制公式如下
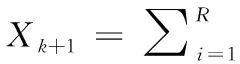
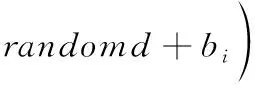
(8)
式中:Wi=[Wi1,Wi2,…,Win]T∈Rn為初始隨機輸入權值,bi=[bi1,bi2,…,bin]T∈Rn為初始隨機輸入偏置值。
訓練樣本的構建是引入遺傳算子的ELM進化機制的關鍵,這里采取遺傳算法對初始種群進行進化,生成的第evolution代子種群和父種群作為訓練樣本,其中父代作為ELM進化機制的輸入,而子代作為輸出。引入的種群進化代數evolution,映射出父代種群和子代種群的復雜非線性關系,獲得更好搜索方向的ELM進化機制。evolution的選擇針對種群進化速度至關重要,選取evolution代數太多,訓練后的ELM進化機制時效性變差;選取evolution代數太少,進化速度變慢。為此,evolution的選擇通過實驗仿真選取,且選取多代父種群和子種群以擴大訓練樣本,避免初始階段進化不顯著的缺點。算法的整體改進克服了傳統遺傳算法中憑經驗確定算子參數的問題,使獲得下一代子種群的機制上更加成熟。步驟如下:首先,將訓練樣本集歸一化處理,將輸入、輸出的單模式權重組成的染色體種群樣本限制在[0,1]區間中,隨機給定初始權重和偏置,指定種群進化代數evolution和隱藏節點數N;然后,通過改進的ELM算法求出網絡輸出權值βi,獲得ELM進化機制。輸入層到隱含層的激活函數采取sigmoid函數
(9)
算法第二部分采取ELM結合改進遺傳算法模型,首先隨機生成單模式權重并用實數編碼組成染色體,形成初始種群。隨后,第一代種群由遺傳算法生成,子種群一部分由遺傳算法生成下一代種群;另一部分由已經訓練好的ELM進化機制來生成下一代種群,從而得到更優的搜索方向和搜索范圍。兩種機制根據計算得到的種群適應度adapt的優劣來判斷下一代子種群的分配比例,具體步驟如下:
(1)初始化種群規模M、隱藏節點n等變量。
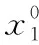
(3)根據第一代初始種群,設定初始分配比例p=0.5。
(4)依據分配比例p,將遺傳算法的子種群進行選擇、交叉、變異算子操作生成下一代種群。
(5)依據種群進化代數及種群擴大數訓練ELM進化機制,根據比例p獲得部分子種群代入ELM訓練機制進行訓練。
(6)分別計算兩種算法的適應度adapt1,adapt2,將下代子種群分配比例進行調整
(10)
(7)計算迭代誤差ek,若ek
(8)達到最優,輸出結果。
2.3 實驗結果與分析
2.3.1 參數選擇
本文篩選了8種模式中符合要求的模式,預報結果采用均方根誤差、絕對誤差等指標,對單模式及多模式集成預報進行效果評估。算法參數見表1。
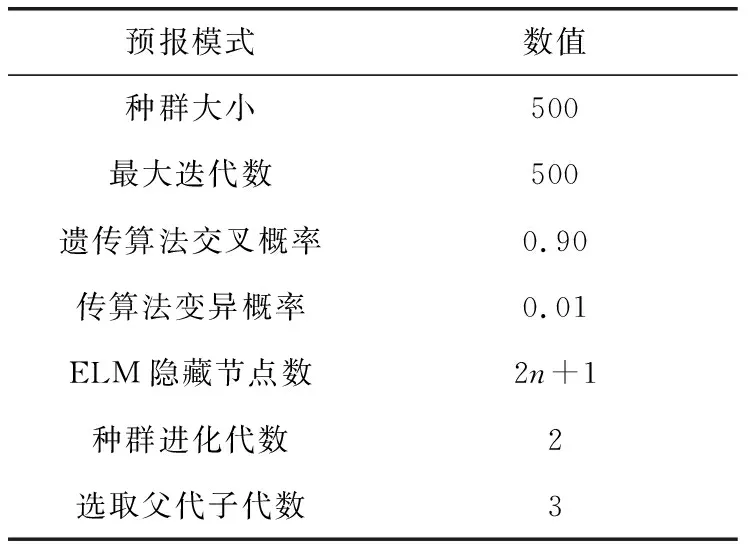
表1 算法參數
2.3.2 數據處理
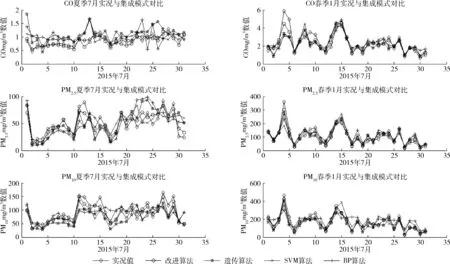
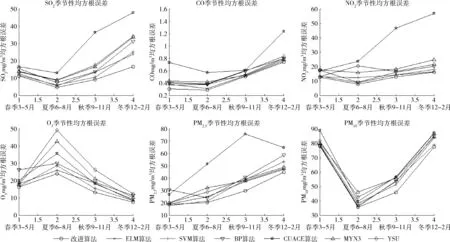
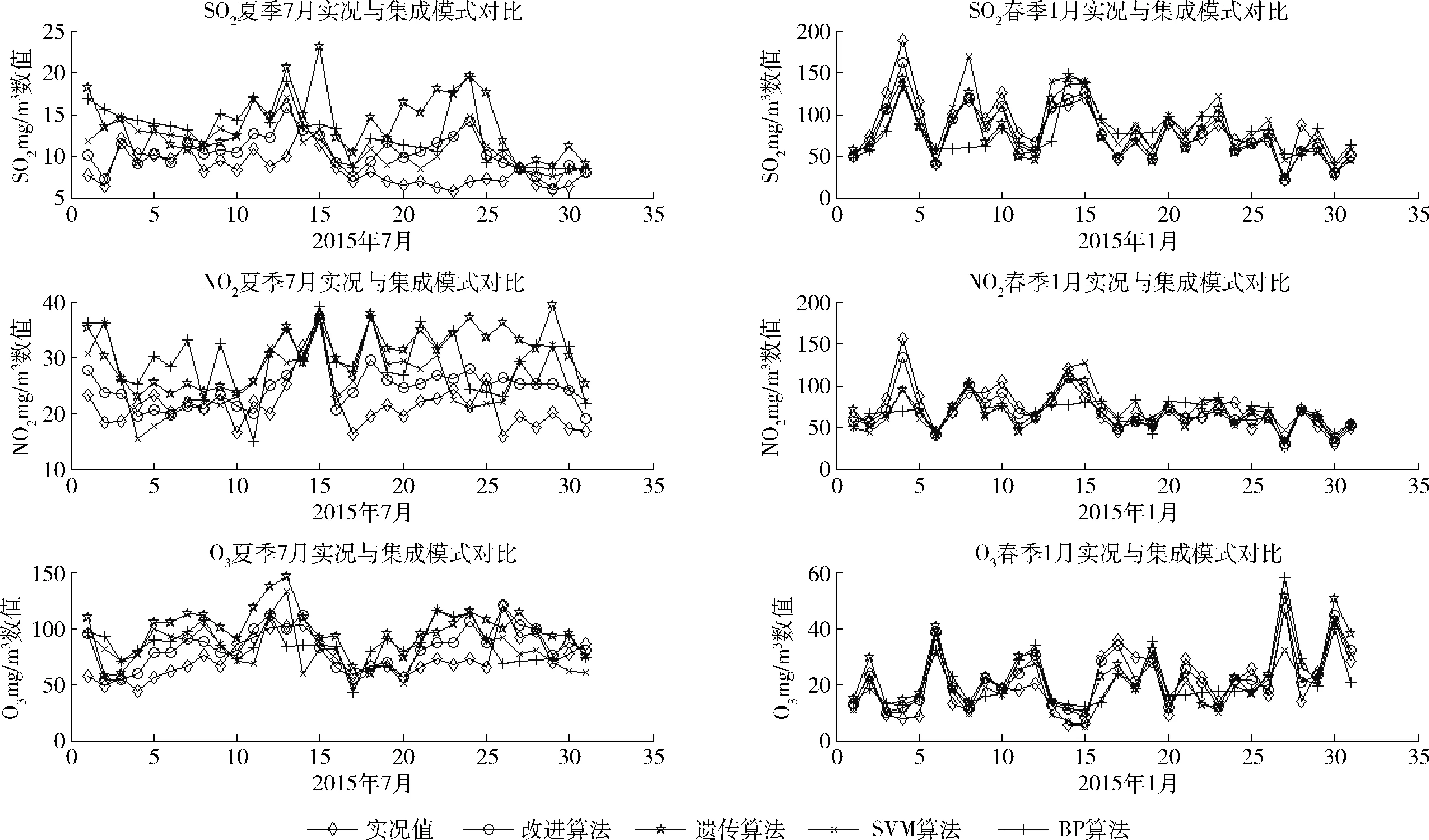
模式的選取采用各模式與實況值的顯著性分析檢驗,顯示P-value大于0.01,小于0.05,表示差異顯著;P-value小于0.01,差異極顯著。針對顯著的模式方案進行相關性R以及偏差T分析,相關性R采用統一標準:取絕對值后0 0.5為低度相關,0.5 如表2所示,在顯著性檢驗低于0.05的顯著性差異基礎上,針對各季節進行偏差及相關性分析,冬季相關性和偏差較高,選取相關性0.8以上且偏差在同范圍的相關模式CUACE、MADE、MOS、YSU、MYJ、BL。 表2 CO冬季單模式方案篩選 2.3.3 ELM改進遺傳算法多模式污染物預報模型檢驗 圖2給出了全年天津站點6種大氣污染物均方根誤差的3種典型單模式以及SVM算法、BP算法、遺傳算法與改進算法的預報結果對比,按照春夏秋冬4個季節進行預報。 圖2 大氣污染物集成預報模式及單模式的均方根誤差比較 由圖2可見,相較于3種單模式,4種集成模式均展現出了較好的均方根誤差能力,而引入遺傳算子的ELM改進遺傳算法模式又比其它3種集成模式更優秀。改進算法的一氧化碳均方根誤差降低到0.46 mg/m3,平均絕對誤差值降低到0.35 mg/m3;二氧化氮均方根誤差降低到12.60 mg/m3,平均絕對誤差值降低到9.36 mg/m3;臭氧均方根誤差降低到17.25 mg/m3,平均絕對誤差值降低到11.7 mg/m3;PM2.5均方根誤差降低到30.21 mg/m3,平均絕對誤差值降低到23.8 mg/m3;PM10均方根誤差降低到60.50 mg/m3,平均絕對誤差值降低到38.9 mg/m3;SO2均方根誤差降低到10.75 mg/m3,平均絕對誤差值降低到7.76 mg/m3。其中冬季預報結果最優,其次是秋季、春季,預報效果最不穩定的是夏季。這與參與集成的多個模式各有優劣且夏天受溫度、風力等氣象因素影響較大相關,導致預報結果RMSE的增長。 圖2已顯示出集成模式預報效果普遍高于單模式且冬季和夏季分別是預報效果最好和最不穩定的季節,圖3采用6種大氣污染物的SVM算法集成模式、BP算法集成模式、遺傳算法集成模式、引入遺傳算子的ELM改進遺傳算法集成模式與實況值的預報結果進行對比分析,選取2015年預報效果最好的冬季單月以及預報較不穩定的夏季單月。 圖3 大氣污染物集成預報模式與實況值的結果比較(1) 由圖3、圖4分析出:①在預報效果最好的冬季,4種集成方法均有良好的精度,但從細節上可以看出改進算法整體上更加貼近實況值;②預報效果最不穩定的夏季,BP算法和遺傳算法因存在收斂不到最優解,整體預報不穩定的缺點,預測曲線與實況值有一定偏差。改進算法集成預報利用ELM改進搜索方向,加快收斂速度,較其它3種集成方法明顯更加貼近實況值且穩定,而SVM雖然有少量預報結果比較貼近實況值,但整體上改進算法精度更好。 在算法的執行時間上,改進算法與遺傳算法相比,30天滾動的分季節遺傳算法在4個季節中平均用時614.98 s,引入遺傳算子的ELM改進遺傳算法集成預報用時281.79 s。后者的執行時間明顯更快,這是因為ELM優良的非線性映射能力,通過進化代數以及父代子代種群的設置讓遺傳算法擁有了更好的搜索方向,擴大了進化機制的搜索范圍。其中迭代總數500次中遺傳算法平均收斂次數為381次,引入遺傳算子的ELM改進遺傳算法網絡為247次。由此可見,引入遺傳算子的ELM改進遺傳算法比遺傳算法迭代次數上的優化使其更加精確快速。引入遺傳算子的ELM改進遺傳算法集成方法可以滿足氣象預報中高時效性的要求,能在盡可能短的時間內提供準確性高的預報結果。 (1)與遺傳算法集成模型相比,改進算法模型改進ELM算法輸入并模擬遺傳算子操作,運用改進的ELM算法與遺傳算法相結合,具有收斂速度快,不易陷入局部最小的缺點,可以較好發揮大氣污染物預報作用。 (2)本文考慮了季節性影響且設置30天動態滾動數據集。結果顯示,冬季預報結果最優,其次是秋季、春季,在預報精度較不穩定的夏天,本文算法也展現了較其它算法更好的預報精度和整體穩定度。 (3)今后研究方向為:①改進算法中選取的父代子代參數變量通過仿真實驗得出,尚未得到理論證明,需要更深入的研究;②集成預報模型的建立受到數據集數量和質量等的影響,后續還需大量數據進行實踐。 圖4 大氣污染物集成預報模式與實況值的結果比較(2)
3 結束語