采摘機器人自動識別系統研究
——基于英文字母多元信息標簽
2018-08-10 09:23:08王霄
農機化研究 2018年10期
王 霄
(黃河科技學院,鄭州 450063)
0 引言
隨著計算機智能控制、圖像處理及人工智能等技術的飛躍式發展,集成視覺傳感器和圖像采集卡的自動識別系統被廣泛應用于目標識別和圖像特征分析等領域。本文將圖像處理技術應用于水果選擇性采摘中,首先通過人眼對水果成熟度進行判斷并貼上標簽,然后由采摘機器人自動識別系統根據標簽上的等級區別進行采摘,實現了英語字母多元信息識別與水果分級采摘功能。
1 圖像預處理
英文字母等多元信息的自動識別是圖像處理的一項新技術應用。如今,英文字母廣泛應用于信息標簽、車牌號、指示牌等標示,通過對英文字母多元信息的識別,能夠提高對目標對象嵌套的視覺識別和追蹤能力。高效的英文識別在機器人導向、logo設計等領域的應用前景比較寬廣。英文字母的圖像通過視覺傳感器CCD采集獲取,但在圖像獲取的過程中,由于天氣、拍攝角度或者標識牌被污跡遮擋等原因,會影響字符的識別。因此,在字符圖像被獲取之后,需要進行一系列的預處理工作,如灰度化、二值化及邊緣檢測等。預處理作為字符識別的第1個階段,其效果直接決定后續的字符分割和字符識別的成功率。
圖像預處理主要包括英文字母的圖像導入、顏色分割、灰度化、二值化和邊緣檢測等步驟,流程如圖1所示。
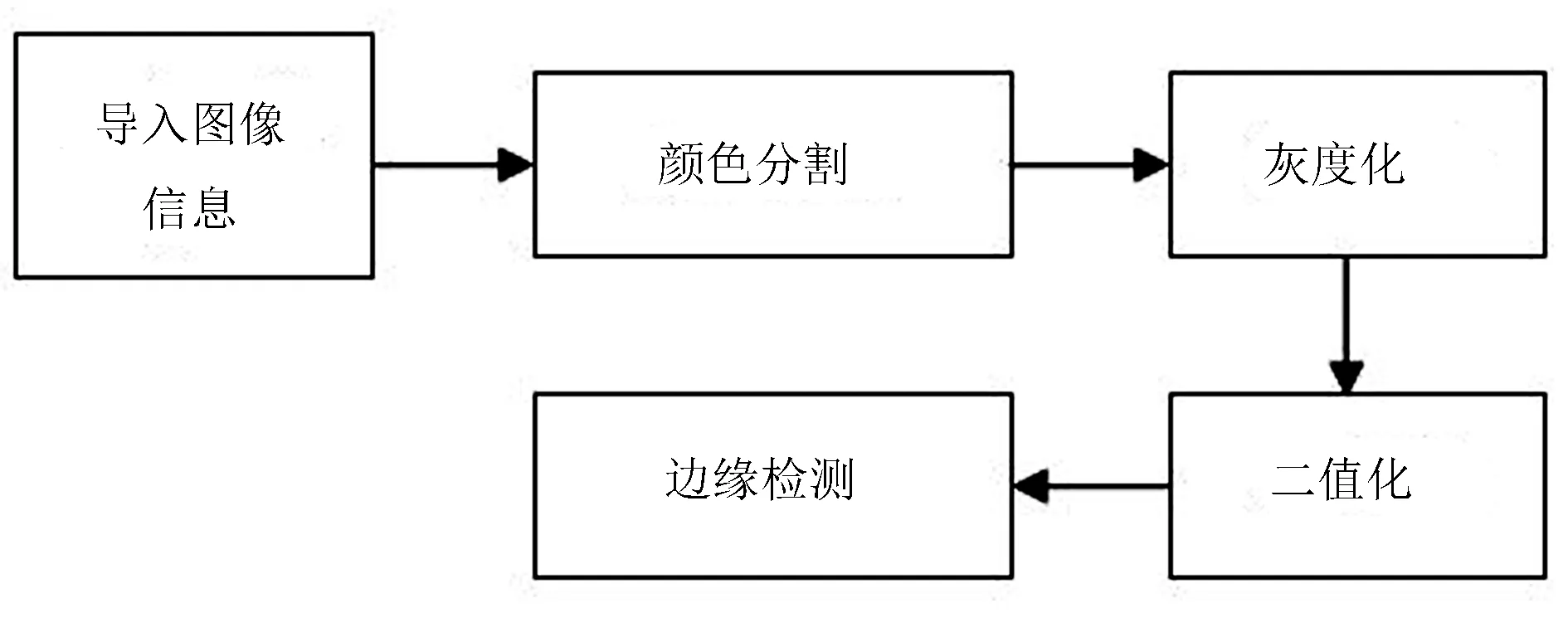
圖1 圖像預處理流程圖
1.1 英文字母的圖像導入
在常見的論述中,圖形和圖像是對物體形態的兩種不同的描述,其存儲結構和表示方法差別很大。圖形是目標對象一種矢量結構的描述方式,而圖像則是一種柵格結構的描述方式。采摘機器人圖像信息獲取的目的是對獲取的信息進行深入的研究,獲取更多的描述信息,為后續的判斷決策做準備。英文字母的圖像包括BMP和JPG兩種,由于本文研究采用OpenCV手段加載圖像,因此對兩種圖像都可以識別,所以兩個種格式都能進行后期的識別操作。
1.2 顏色分割
在進行圖像處理中,有一個環節是圖像灰度化,而進行灰度化必須提前做好顏色分割準備。對圖像進行顏色分割,需要先建立顏色坐標系。本文采用LAB顏色模型進行分割,該模型分布均勻,具有很強的實用性。LAB顏色坐標如圖2所示。
圖2中,LAB顏色空間是在顏色中藍黃不可同時存在的基礎上建立的。其中,L為顏色的明度值;A為顏色的紅、綠值;B為顏色黃、藍值。
圖像進行色彩分割時,通常需要將LAB轉化為LCH顏色模型。其中,LCH顏色模型如圖3所示。
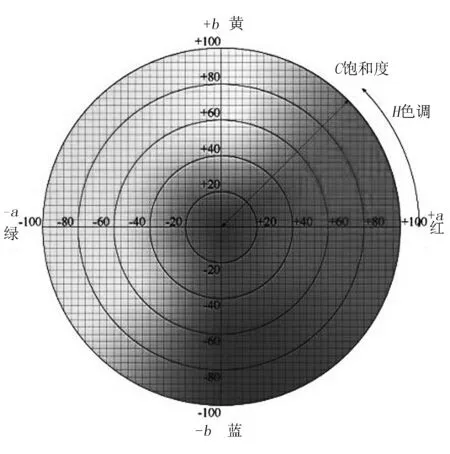
圖2 LAB顏色坐標圖
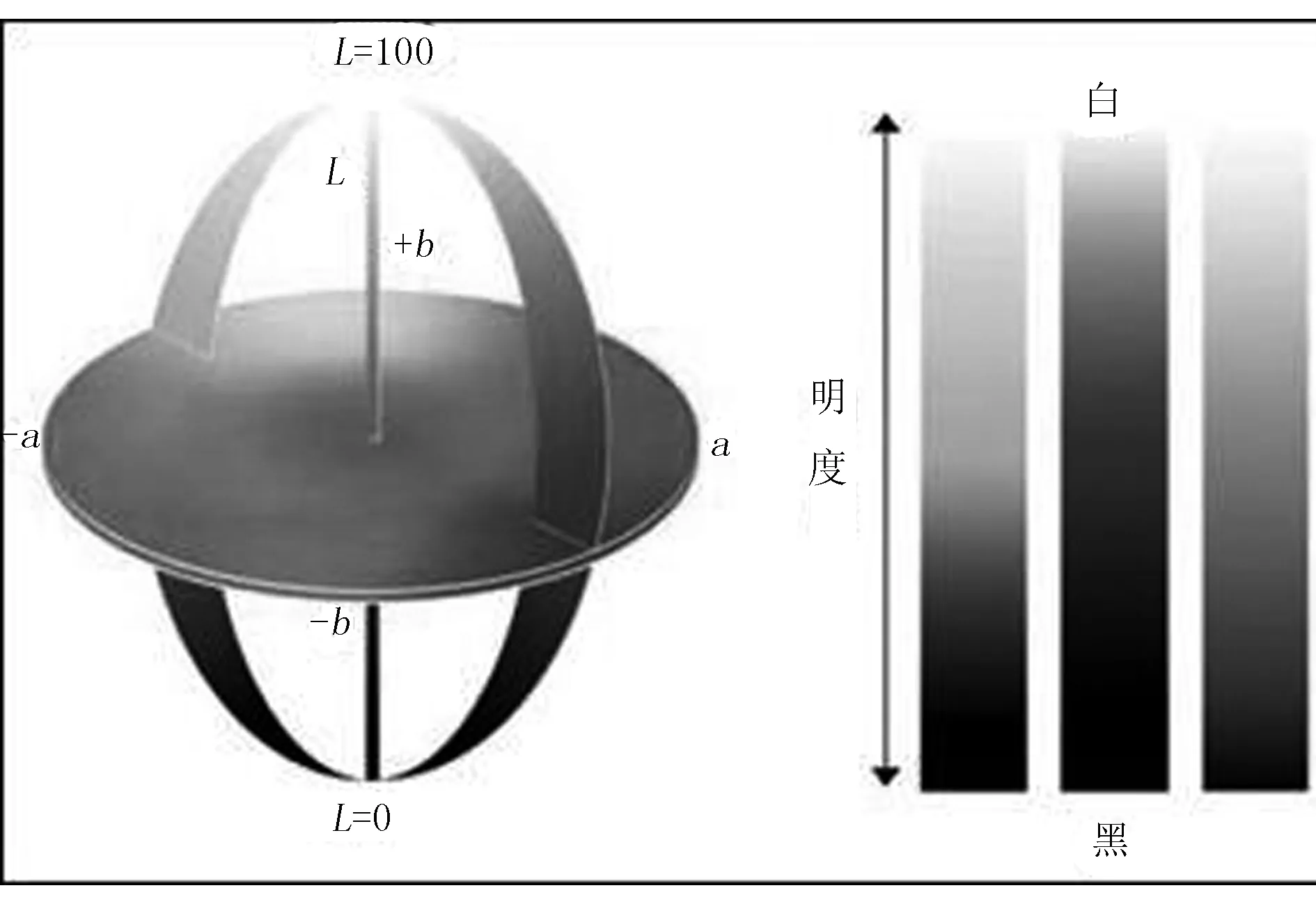
圖3 LCH顏色模型
在LCH顏色模型中,L為明度值,C為飽和度值,H為色調角度值。
RGB轉化為LAB較為復雜,其公式表達式為
(1)
采摘機器人對目標對象圖像進行采集,然后通過LAB的顏色分割,可以得出對象的灰度化初始值和空間坐標信息。
1.3 灰度化
顏色有黑白和彩色兩種。黑白指顏色中,只有黑白之分,沒有其他色彩。在RGB和LCH兩種顏色模型中,如果R/G/B三者值相等,或者L/C/H相等,表示其是黑白色。其中,R/G/B相等(L/C/H相等)稱為灰度值。彩色和黑白色之間能夠通過顏色分割算法進行轉化,彩色轉換為黑白稱為灰度化過程,而黑白轉向彩色稱為偽彩色過程。
從上面的敘述可知:灰度化處理實質上是將RGB等值化的處理過程,其處理方法有最大值、平均值和加權平均值3種。本文采用加權平均值進行圖像灰度化處理。
根據顏色分割重要性和指標給R、G、B的應權值進行賦值,并使三者加權平均,即
R=G=B=WR·R+WG·G+WB·B
(2)
其中,WR、WG、WB為三者的顏色權值。三者去不同的權值便可以得到對應的灰度圖像。加權平均值灰度化處理方法,對英語字符的亮度處理明顯,且不會對對原圖信息造成損失。
1.4 二值化
圖像二值化處理的技術手段有直方圖、最大熵閾值及OTSU法等。為使圖像二值化效果更明顯,灰度直方圖獨立性更強。本文采用最大熵閾值進行二值化算法,使得圖像灰度值各類熵值最大。其算法描述如下:
設P點為灰度值分割閾值點,L0,L1,L2,…,Ln是灰度值等級的概率等級,將其分為兩端,則
(3)
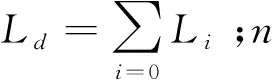
圖像二值化后的熵為
H(S)=EA+EB
(4)
(5)
二值化分割發熱最佳閾值為
H0=argmax(H(S))
(6)
最大熵閾值二值化處理效果如圖4所示。

圖4 最大熵閾值二值化處理效果圖
maximum entropy threshold
1.5 邊緣檢測
邊緣檢測算法中應用比較多的是Rebort、Prewitt和Sobel等,這些算法主要是通過圖像像素值判斷英文字母的邊緣。本文采用線密度算法對字符圖像邊緣進行檢測。算法描述如下:
1)一般英文字母的寬度大約為8-10個像素點,假設(i,j)是邊緣點,那么分別向其左右取N個像素點,如圖5所示。
2)計算(i,j)兩側的邊緣點密度值,即
(7)
其中,E(k)是與(i,j)相差k個像素點的值,則

(8)
2 英文字母的分割與識別
英文字母的分割與識別是采摘機器人根據信息標簽進行采摘作業的基本,是最重要的環節之一。本文研究的英文字母識別算法是針對獨立字符進行識別,因此字符分割和定位就顯得尤為重要。
2.1 英文字母的分割
本文采用連通域法對英文字母進行字符分割,主要步驟如下:①對圖像進行二值化;②將圖像的邊框去除掉;③提出相關區域的連通域;④根據積累的經驗對字符區域進行篩選判斷;⑤對字符區域進行準確定位;⑥對于字符區域進行歸一化處理;⑦對字符進行二值化分割;⑧輸出分割后的字符。英文字母分割流程如圖6所示。
2.2 英文字母的識別
經過前一節英文字母的分割操作,待識別的英文字母圖像已成為獨立的字符個體,此時可以采用SVM向量集對字符的特征模型集進行訓練,然后將特征提取和特征模型集進行對比判斷,識別出字符,最后進行輸出。字符識別示意如圖7所示。
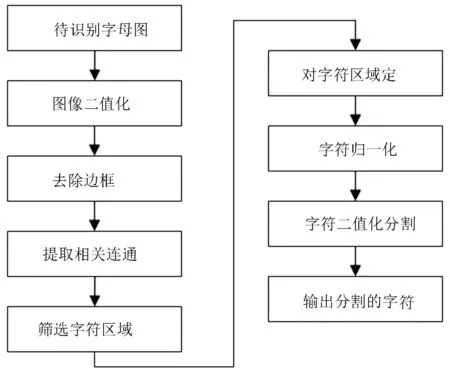
圖6 英文字母分割流程圖
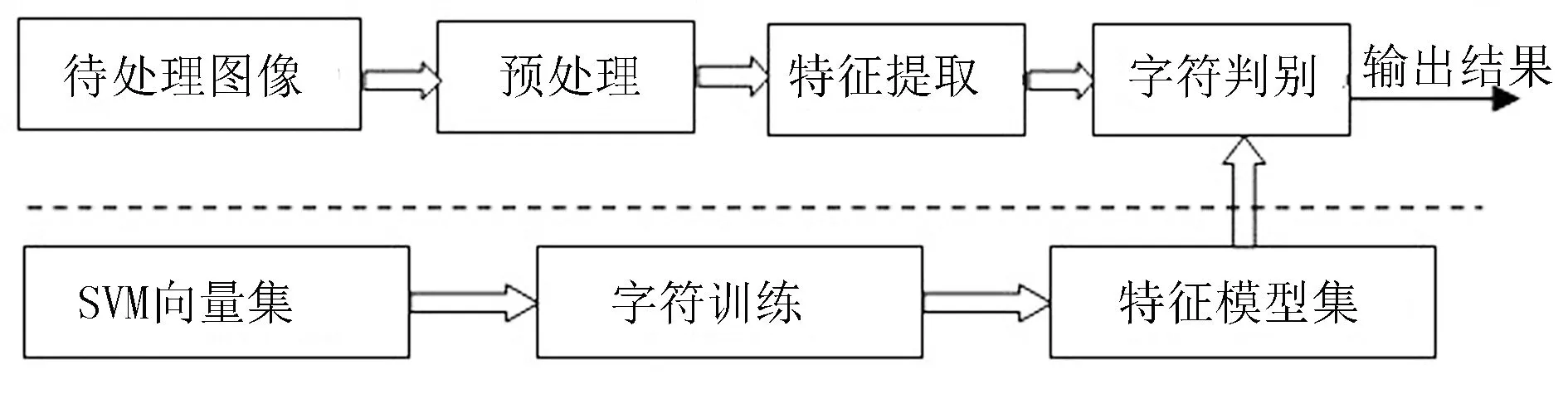
圖7 字符識別示意圖
3 英文字母自動識別系統
英文字母自動識別系統是采摘機器人對目標對象進行采摘的重要手段。首先技術人員人眼判斷并對需要采摘的對象貼上標簽,然后由自動識別系統通過CCD傳感器獲取圖像信息,再根據標簽上的等級區別進行采摘,并分等級進行擺放。
3.1 英文字母自動識別系統硬件的設計
采摘機器人作業過程中,需要對信息標簽上的英文字母信息進行快速判別處理,然后控制采摘機器人靈巧手進行采摘作業。針對以上要求,本文設計了以Exynos4412(Cortex-A9)為核心的硬件平臺,能夠進行實時信息標簽識別、控制靈巧手的采摘作業及采摘狀態的實時顯示。該硬件平臺主要包括CCD視覺傳感器、CD-ROW光驅、圖像采集卡、Exynos4412處理器、圖像處理軟件、CD-ROM、硬盤存儲設備、機械臂和靈巧手等設備模塊。該硬件平臺的系統框架圖如圖8所示。
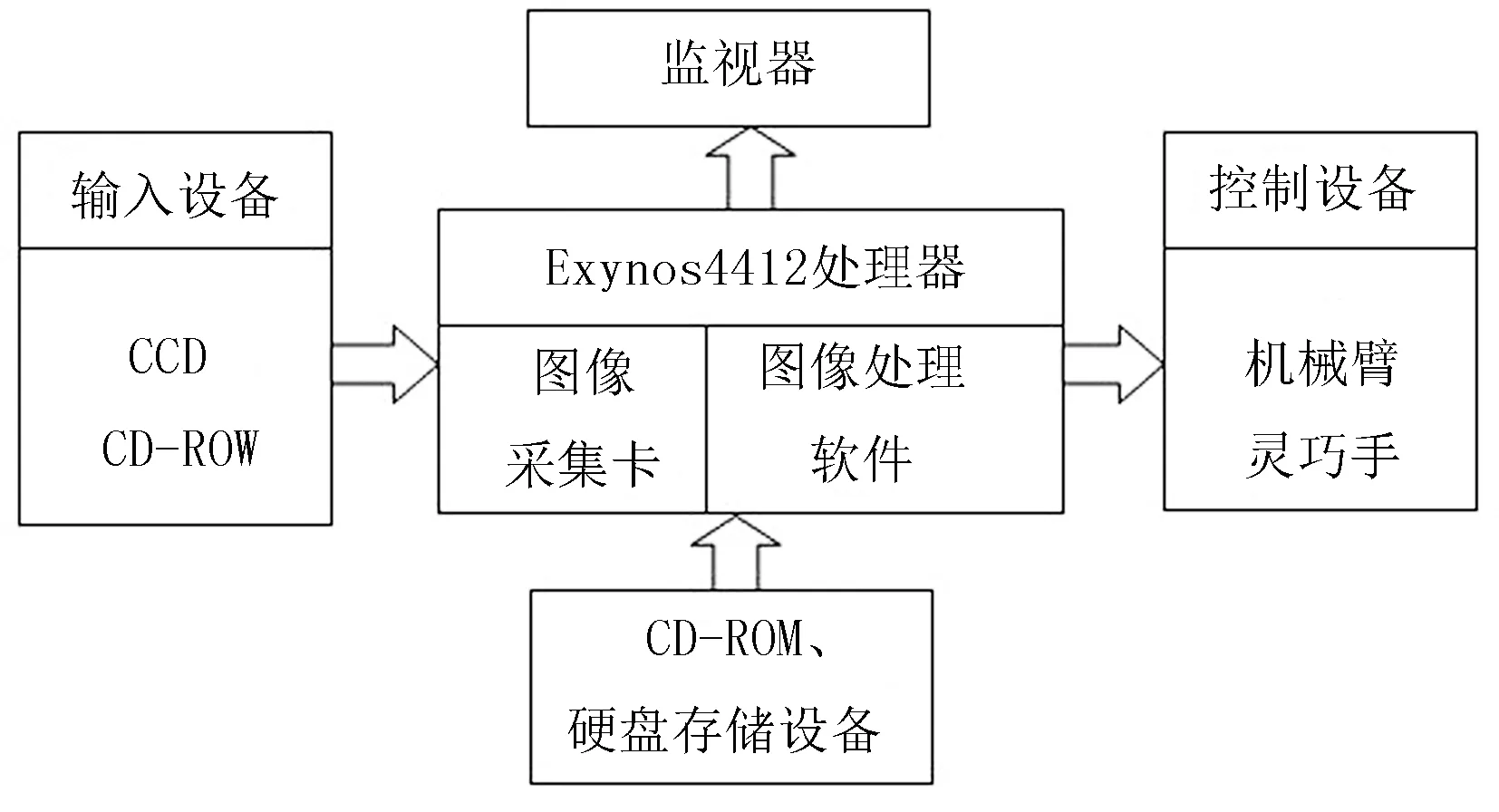
圖8 系統框架圖
3.2 英文字母自動識別系統軟件的設計
硬件部分是英文字母自動識別系統正常運作的平臺,而硬件部分的運行必須依靠底層軟件進行驅動。英文字母自動識別系統軟件設計如圖9所示。
圖9 英文字母自動識別系統軟件設計
system of English alphabet
為了使Exynos4412處理器正常運行,首先必須要有平臺的引導軟甲Bootloader,然后根據Linux 源碼生成可以在硬件平臺運行的Kernel,最后采用Buzybox工具ramdisk 文件系統映象文件。將3個文件采用網絡掛載的方式燒寫到開發板上,才能讓整個平臺正常的運行。
其中,Linux Kernel的移植包括下面幾個部分:
1)修改內核頂層目錄下的 Makefile,將交叉編譯工具改為ARM平臺的arm-none-linux- gnueabi-gcc。
2)修改Driver/net文件配置,進行DM9000網卡驅動的移植。
3)修改Driver/Device/usb.c文件配置,進行USB 驅動的移植。
4)配置內核,進行如下配置。
make menuconfig
[*] Networking support ————>
Networking options ————>
<*> Packet socket
<*> Unix domain sockets
[*] TCP/IP networking
[*] IP: kernel level autoconfiguration
Device Drivers ————>
[*] Network device support ————>
[*] Ethernet driver support (NEW) ————>
<*> DM9000 support
File systems ————>
5)編譯內核和設備樹。
$ make uImage
$ make dtbs
4 測試結果與分析
為了驗證該采摘機器人英文字母自動識別系統的應用性能,進行了實際的采摘仿真測試分析。實驗中,利用QT 5.7搭建仿真平臺,運行 Qt需要的圖像視覺識別函數接口,編譯和加載可視化的界面程序。該實驗仿真識別結果如圖10所示。

圖10 實驗仿真識別結果
由圖10可以看出:采摘機器人英文字母自動識別系統從原始圖像、到處理后的圖像、再到結果的輸出都比較準確,識別率達到了100%。實驗結果表明:該系統可以準確識別信息便簽上的英文字母,并將信息提煉出來,用與采摘機器人進行采摘判斷,能滿足選擇采摘作業要求,具有廣泛的應用前景。
5 結論
本文首先對圖像預處理中顏色分割、灰度化、二值化、邊緣檢測等步驟進行介紹與分析,進而對英文字母的分割與識別算法進行研究,最后設計了英文字母自動識別系統的硬件平臺和軟件移植,實現了英語字母多元信息標簽自動識別的功能,為采摘機器人的選擇采摘提供了便利。測試結果表明:該系統可以準確識別信息便簽上的英文字母,并將信息提煉出來,用于采摘機器人進行采摘判斷。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
特別健康(2018年3期)2018-07-04 00:40:18
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年26期)2016-08-22 03:23:28
電測與儀表(2016年6期)2016-04-11 12:06:38
中外會展(2014年4期)2014-11-27 07:46:46
計測技術(2014年6期)2014-03-11 16:22:12
