基于GA-LM-BP神經網絡的鋰離子電池預測研究
2018-07-27 05:15:12,
計算機測量與控制 2018年7期
關鍵詞:優化
,
(海軍工程大學 電子工程學院,武漢 430033)
0 引言
鋰離子電池具有效率高、放電量少以及自適應性強等優勢,目前在電動汽車、新能源發電和儲能電站等領域得到了廣泛的應用,如何對鋰離子電池進行預測已經成為當前電子設備PHM的關鍵方面。通過分析鋰離子電池的狀態退化的機理,得到對鋰離子電池進行預測的依據。本文針對對傳統BP算法的不足,本文采用遺傳算法優化網絡初始的權值閾值及LM算法的改進型BP神經網絡,并應用于鋰離子電池的預測研究中。
1 鋰離子電池狀態退化機理
鋰離子電池在結構上可以分為正極、負極和電解質。其中,電解液通常是有機碳酸酯,負極材料是石墨,正極材料是鋰鐵磷酸鹽。鋰離子電池的正負極在充放電的過程中進行接收和釋放鋰離子,并完成相應的能量轉換。鋰離子的充放電化學反應公式是:
充電過程:正極反應公式:LiFePO4→Li1-xFePO4+xLi++xe-
負極反應公式:xLi++xe-+ 6C→LixC6
放電過程:正極反應公式:Li1-xFePO4+xLi++xe-→LiFePO4
負極反應公式:LixC6→xLi++xe-+ 6C
充電時,電池是將電能轉換成化學能,而放電時將化學能轉換成電能[1]。在鋰離子電池的充放電過程中,內部發生了不可逆的化學反應,從而導致電極上的Li+的流失,使內部電阻提高。這些內部電阻的變化就是反映電池性能退化的主要參數。
實現鋰離子電池RUL預測的重要環節就是建立其壽命退化模型。但是在實際應用中能夠比較準確的建立電池退化的物理模型是困難的。NASA的PCoE研究中心依據大量的實驗數據[2],提出了一個簡單可行的電池等效模型,并以此來估計鋰離子電池的RUL,等效模型如圖1所示。

圖1 等效模型
其中:CDL表示雙電層電容,RCT表示電荷轉移電阻,RW表示Warburg阻抗和RE表示電解質電阻。NASA的研究人員對數據分析后發現,RW和CDL對壽命退化所起的作用微不足道,可以忽略,而與RCT+RE成高度的線性關系,并驗證了鋰離子電池容量和阻抗參數之間成高度的線性相關性。Saha等人提出了如下的經驗模型來描述鋰離子電池[3]。
Ck+1=ηCCk+β1exp(-β2/Δtk)
(1)
其中:Ck是第k個循環周期的鋰離子電池容量,Δtk是兩個相鄰充放電周期之間的休息時間,β1和β2是電池經驗模型的特定參數。ηC是庫侖效率,用來表示電池釋放的電荷總量與沖入電荷總量之間的百分比。在鋰離子電池中,充放電后增加電池的休息時間,就能夠使下一次充電周期的電池容量有所增加。
由以上分析不難看出,電池容量會隨著鋰離子電池的老化而逐漸降低,每次充電的電池容量基本上是逐步遠離標稱容量的,所以可以利用鋰離子電池容量退化來預測剩余壽命。
實驗數據來源于美國馬里蘭大學CACLE開展的鋰離子電池退化實驗。在實驗中,采用的是Arbin BT2000的鋰電池實驗系統,并以Excel格式保存電池退化的數據,共有兩組鋰離子電池數據,標準容量分別是1.35 Ah和1.1 Ah。本文采用容量是1.1 Ah的測試數據。整個實驗數據在構成上主要是由充電、放電和電池容量等部分,其中充電實驗數據包含阻抗數據、充電電壓數據和充電電流數據,放電實驗數據包含阻抗數據、放電電壓數據和放電電流數據,以及相應的環境溫度、測試時間等信息。
針對傳統BP算法的不足,采用遺傳算法優化網絡初始的權值閾值及LM算法的改進型BP神經網絡,并應用于鋰離子電池的預測研究中。
2 GA-LM-BP神經網絡建模
BP神經網絡的誤差后向傳播過程是通過一個目標函數最小化完成的,而目標函數是:
(2)
傳統上是根據如式(2)的梯度下降法來調整權重系數的。
(3)
權值會順著與誤差梯度相反的方向變化,直到誤差達到最小值。這種BP神經網絡的訓練時間較長,迭代次數也比較多,具有陷入局部最小值的缺點[4]。針對上述問題,本文采用LM算法對網絡進行訓練,并克服這些缺陷。
2.1 LM-BP神經網絡建模
LM(Levemberg Marquardt,LM)算法是了融合高斯-牛頓法和梯度下降法優點的快速算法,既具有快速收斂特性,又具有全局搜索的優勢[5]。假設使用ω(k)表示第k次迭代的權值形成的向量,那么新的向量ω(k+1)由下式可以得到:
ω(k+1)=ω(k)+Δω
(4)
神經網絡的輸入誤差指標函數E(ω)表示如下,
(5)
接著,通過最小二乘法求解BP神經網絡的誤差函數得到調整規則是:
Δ(ω)=-[▽2E(ω)]-1▽(ω)
(6)
▽2E(ω)是輸入誤差E(ω)的Hessian矩陣,E(ω)是梯度,針對▽2E(ω)進行近似推導,可以得到,
▽(ω)=JΤ(n)e(n)
(7)
▽E2(ω)=JΤ(n)e(n)+S(n)
(8)

(9)
(10)
其中,修正為高斯—牛頓法是:
Δ(ω)=-[JT(n)J(n)]-1J(n)e(n)
(11)
LM算法可以將高斯—牛頓法改進如下,
Δ(ω)=-[JT(n)J(n)+μI]-1J(n)e(n)
(12)
其中:I是單位矩陣,μ是比例系數,而且大于零。當距離一個解值比較近時,μ值是逐漸遞減的,權值調整與高斯—牛頓法相似;當距離一個解值比較遠時,μ值是逐漸增加的,權值調整與梯度下降法相似。其的下降速度比梯度法要快很多,并且經實驗證明,下降速度比梯度法提高了幾十到一百倍,極大地改善了神經網絡的性能[6]。
LM-BP神經網絡的模型實現步驟如下:
1)首先是確定LM—BP神經網絡的訓練誤差允許值ε,系數β,初始權值μ和閾值ω(0),并令,μ=μ0,k=0;
2)對LM-BP神經網絡的輸出進行計算;
4)按照式(11)和式(4)計算Δω和E(ω(k));
5)如果E(ω(k))>ε,按ω(k+1)作為權值和閾值計算誤差函數E(ω(k+1));否則結束計算。
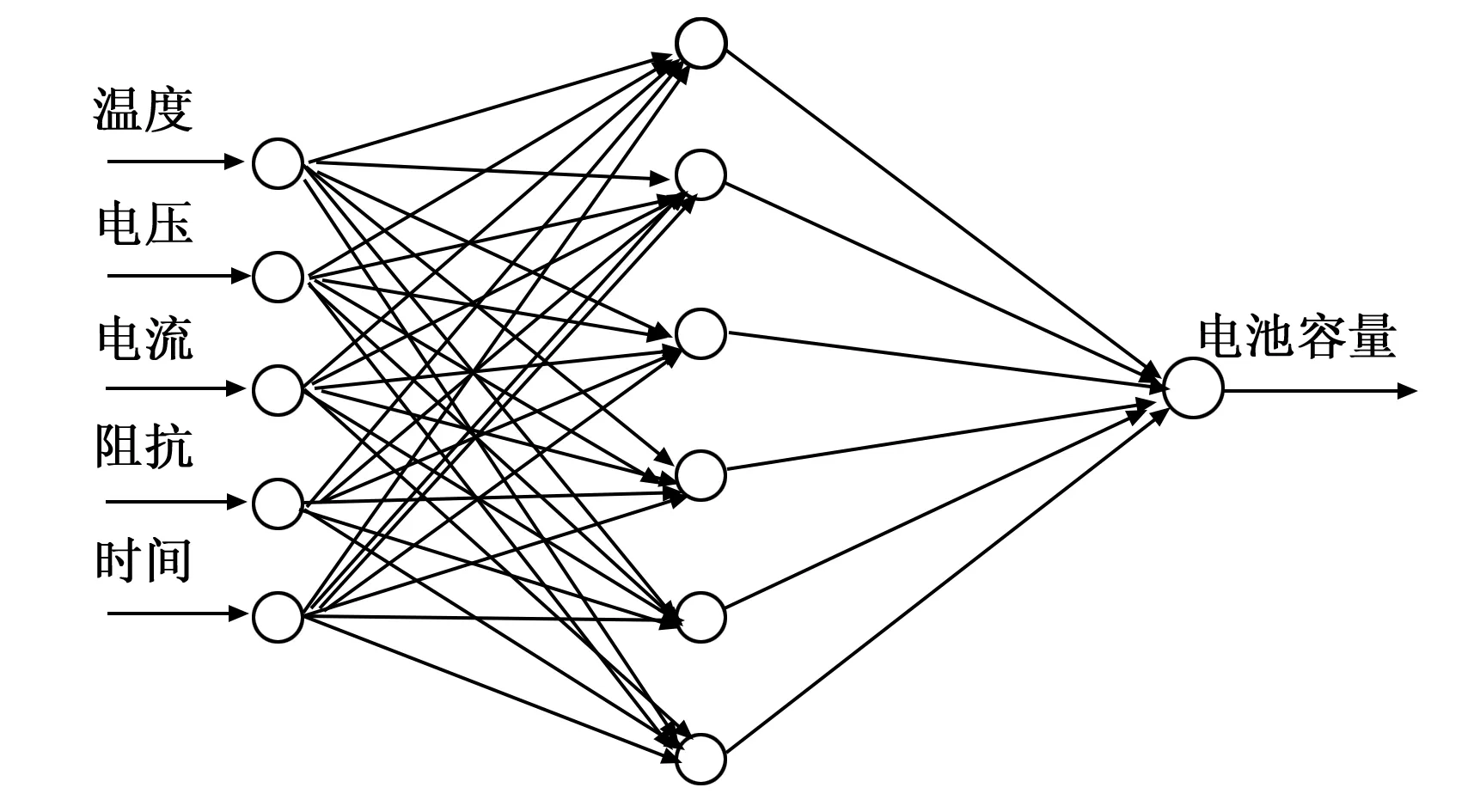
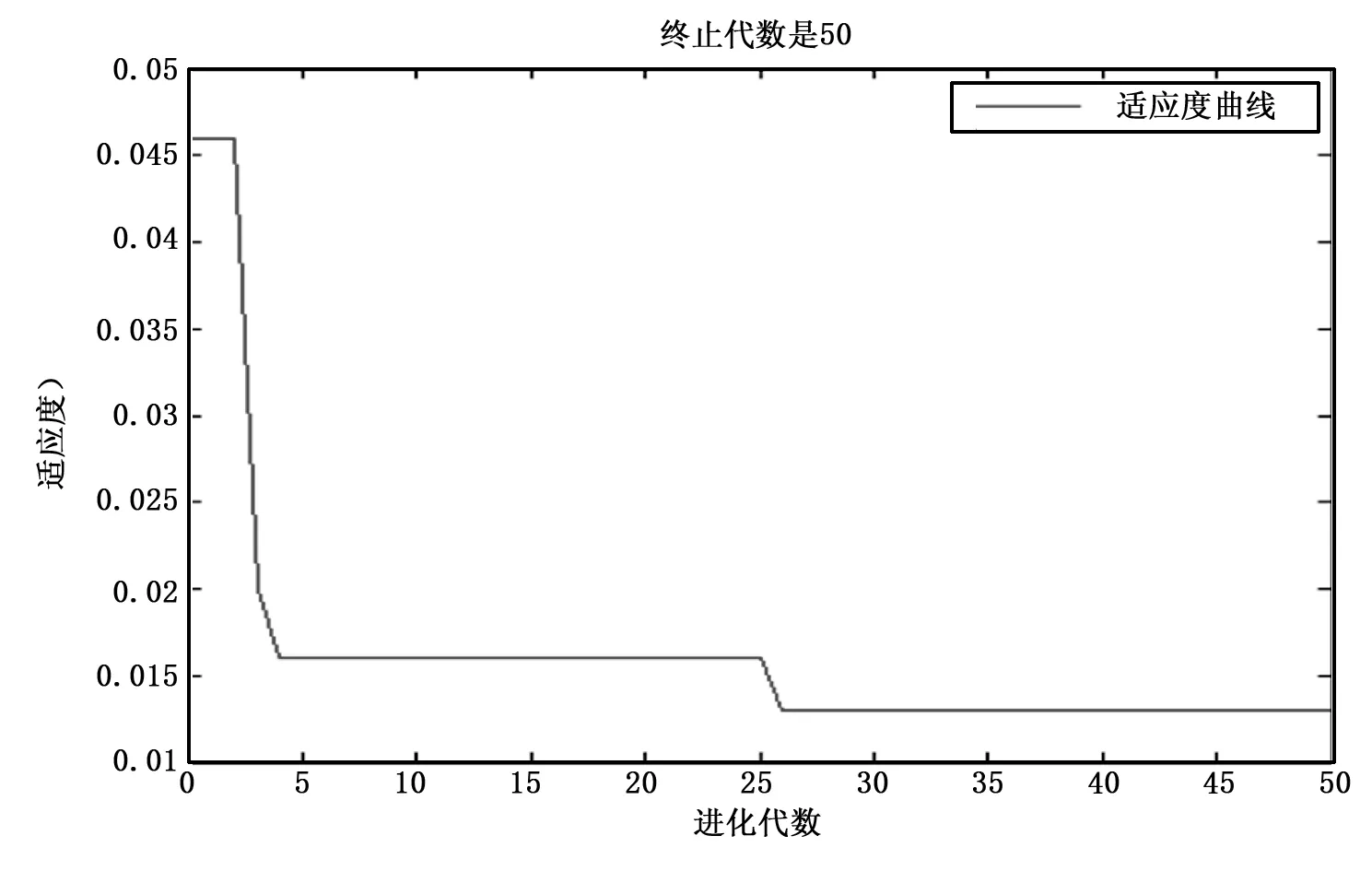
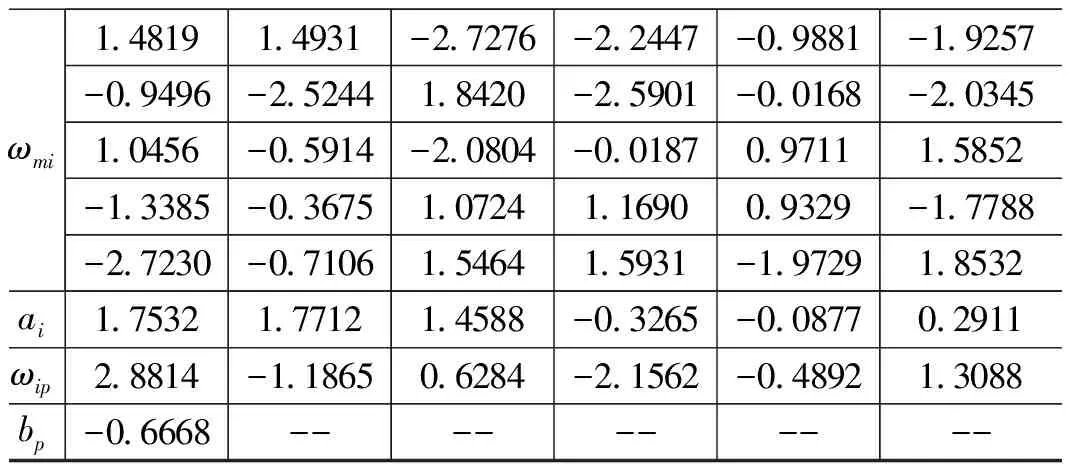
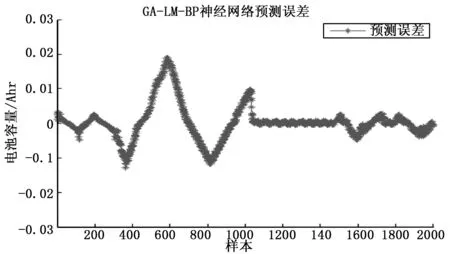
6)如果E(ω(k+1)) 7)結束計算。 BP神經網絡的權值和閾值一般是在[-0.5 0.5]之間的隨機數,但是這些參數對神經網絡的訓練效果影響很大,而且是無法準確獲取[7]。針對這個問題,本文采用GA優化來得到最佳的初始權值和閾值。GA是利用自然界中適者生存的選擇原理,是一種面向全局的優化搜索人工智能算法,且具有魯棒性強的優勢[8]。 GA優化LM-BP網絡主要分為三部分:網絡拓撲結構的確定、GA優化初始權值和閾值、更新權值和閾值后的網絡進行預測。具體的實現流程如圖2所示。 圖2 GA優化LM—BP神經網絡流程 步驟1:確定LM-BP神經網絡拓撲結構。一旦確定LM-BP神經網絡絡的拓撲結構(三層網絡結構應用的比較多),初始權值和閾值也就確定了。 步驟2:種群初始化。任意產生LM-BP神經網絡的初始權值和閾值Xi=(ωmi,ωip,ai,bp),其中m,i,p分別是三層網絡的節點數,創建初始種群PX={X1,X2,…,Xn},n是種群大小,然后使用實數對種群個體進行編碼。 步驟3:將LM-BP神經網絡訓練的誤差定義為適應度函數F,染色體的適應度越小,其成為下一代的概率就越大。 (13) 其中:dp是GA-LM-BP在p節點的理想值;yp是GA-LM-BP在p節點的預測值;k表示系數,取值區間是[0,1]。 步驟4:選擇操作。利用輪盤賭法形成“交配池”。這樣,個體被選擇的概率和適應度大小就是成正比的,形式如下: (14) 步驟5:從上面的“交配池”中選擇任意兩個染色體進行交叉操作。通過比較父、子染色體適應度函數的大小。如果求得的適應度是減少的,則繼續保留父染色體,否則就用子染色體替換父染色體。 步驟6:從“交配池”中以相應的概率任意選擇一個染色體進行變異操作,生成子染色體。如果子染色體的適應度大于父染色體,則保留子染色體。否則就是保留父染色體。 步驟7:一旦迭代次數達到最大值,就得到最優權值和閾值,否則跳轉到步驟3,繼續進行優化。 步驟8:采用上面GA優化得到權值和閾值參數對網絡的訓練樣本進行學習,從而得到LM-BP神經網絡預測模型。 步驟9:將測試樣本集輸入到LM-BP神經網絡預測模型,對預測準確率進行驗證,預測準確率達到要求就結束,否則跳到步驟1進行重復執行。 依據Kolmgorov定理,三層的BP網絡就能夠滿足所有精確性要求實現對連續函數數值逼近[9],本文采取三層網絡拓撲結構對鋰離子電池的容量進行預測。測試數據采用馬里蘭大學CACLE的鋰離子電池數據,測試數據中包含充/放電壓、充/放電流、阻抗、溫度和測試時間等信息,這些測試數據都會明顯影響到電池的容量。所以把他們都作為神經網絡的輸入變量。需要預測的電池容量作為的BP神經網絡的輸出變量。采用黃金優選方法來確定中間隱含層的神經元節點數。BP網絡的輸入層節點數是m,輸出層節點數目是p,則理想的隱含層節點數目i的取值范圍是: (5+1+10)=16=b (15) 根據上述分析,確定BP神經網絡如圖3所示的5-6-1三層結構。 圖3 BP神經網絡拓撲結構 使用該BP神經網絡結構,根據上述的拓撲結構的計算方法,不難得到共有42個權值和閾值,在后續GA的個體編碼長度就是42,其中輸入層到隱含層是30位,隱含層是6位,隱含層到輸出層是6位,輸出層數1位,如表1所示,并采用實數對個體進行編碼。 表1 初始權值和閾值位數 采用的是Arbin BT2000的鋰電池實驗系統,并以Excel格式保存電池退化的數據,本文主要是采用容量是1.1 Ah鋰離子電池的數據進行訓練和測試。 針對三層BP網絡的參數進行100次調試,確定迭代次數是100,學習率是0.1,訓練目標是0.004%。針對測試數據進行濾波處理,濾除噪聲信號,并進行歸一化處理。隨機選取2000組數據,1900組作為訓練數據,用于網絡訓練,100組作為測試數據,按照設計要求構建BP神經網絡預測模型,用于樣本的訓練學習。再將測試集輸入到BP神經網絡模型,對輸出值進行預測,對于選擇的測試數據集,BP神經網絡的預測誤差如圖4所示。 圖4 BP神經網絡預測誤差 由圖4不難看出, BP神經網絡的整體輸出結果還是比較不錯的,但是還是存在一定的預測誤差,主要是是集中在預測的剛開始階段,此時主要是用于訓練學習的,而且誤差還是有點大,最大達到了0.029 7;而到了中后期誤差會小很多。 圖5 BP神經網絡樣本預測誤差 由圖5不難看出,按照給定的BP神經網絡結構對訓練樣本進行學習,整體的預測效果還是不錯的,最高誤差是0.03。在訓練樣本數達到1200個以后,預測誤差越來越小,并且比較穩定,波動性很小,這就體現出BP神經網絡的優勢。 針對BP神經網絡誤差大的缺點,引入前面GA優化LM-BP神經網絡進行狀態預測。首先確定BP神經網絡是5-6-1的三層網絡結構,GA個體的編碼長度是42位,GA的進化代數是50,種群規模大小是30,采用輪盤賭法交叉操作,交叉概率是0.8,變異概率是0.01,適應度函數是BP網絡的預測誤差F。按照GA-LM-BP神經網絡的建模步驟進行訓練學習,GA優化過程中的適應度函數的變化值曲線是隨著代數的增加而下降的。如圖6所示,表明預測誤差越來越小,并且經過50代進化后得到的最優權值和閾值如表2所示。 圖6 適應度變化曲線 表2 最優初始權值和閾值 將表2中的最優權值和閾值賦值給BP神經網絡,再利用優化后的網絡進行訓練,并預測整個系統的輸出,就可以得到GA-LM-BP網絡預測的輸出,GA-LM-BP網絡預測誤差如圖7所示。 圖7 GA-LM-BP網絡預測誤差 由圖7不難看出,GA-LM-BP神經網絡在非線性函數的擬合上比BP神經網絡的能力更強,預測誤差明顯減少,精度提高。 圖8 GA-LM-BP神經網絡的輸出預測誤差 由圖8不難看出,GA-LM-BP神經網絡的輸出預測效果更好,預測誤差最高是0.019 5,平均誤差是0.004 5。通過對比BP神經網絡和GA-LM-BP神經網絡的預測輸出效果,使用了GA優化了初始權值和閾值后在預測結果方面更準確,穩定性提高,預測誤差顯著提高而且全局收斂性好,達到了比較理想的結果。 利用LM算法融合高斯-牛頓法和梯度下降法優點的快速性,并充分利用遺傳算法全局隨機搜索強的優勢,構建了三層5-6-1型的GA-LM-BP神經網絡結構,優化BP神經網絡的初始權值和閥值,減少了BP神經網絡陷入局部極小值的幾率。對鋰離子電池數據進行了實驗表明,GA-LM-BP神經網絡GA-LM-BP神經網絡預測結果方面更準確,穩定性提高,預測誤差顯著提高而且全局收斂性好,實驗結果驗證了該方法預測的有效性。2.2 GA優化LM-BP神經網絡建模

3 基于GA-LM-BP神經網絡的鋰離子電池狀態預測
3.1 確定BP神經網絡的拓撲結構

3.2 BP神經網絡預測研究


3.3 GA優化LM-BP神經網絡的預測研究

4 小結
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
