基于關鍵信息的問題相似度計算
2018-07-19 11:59:44齊樂張宇劉挺
計算機研究與發展 2018年7期
齊 樂 張 宇 劉 挺
(哈爾濱工業大學社會計算與信息檢索研究中心 哈爾濱 150001) (lqi@ir.hit.edu.cn)
社區問答系統(community question answering, CQA)以其靈活的用戶交互特性能夠滿足人們獲取和分享知識的需求,成為廣受用戶喜愛的只是知識共享平臺[1].與其他社會媒體相比,CQA提供了一種特有的交互方式.首先,提問者將其信息需求以問題的方式提交給系統,并等待其他用戶給出答案.回答者根據其個人興趣、知識水平,選擇適當的未解決問題來回答,以分享自己的知識[1].
在社區問答中,問題相似度計算有著很重要的意義.針對用戶提出新的查詢,我們可以通過判斷問題相似,在歷史紀錄中檢索與之相似的已解決問題,并將這些問題的答案推薦給用戶,從而避免用戶的重復提問,也方便用戶更快速地獲取問題答案[1].
社區問答中的問題通常包括2個部分:1)問題的主題或標題;2)問題的詳細描述.這2部分對于判斷問題相似都有很重要的作用.然而,用戶的提問長短不一,而且由于需求和背景不同,問題描述中可能包含大量對判斷問題相似無意義的背景信息.舉個例子,對于相似問題S和T(來源于QatarLiving①),如表1所示,兩者句子長度相差懸殊,而且問題T中包含大量背景信息.在小規模的語料中,由于訓練語料不足,若將全部文本作為神經網絡的輸入會引入大量噪聲,而神經網絡無法很好地去除這些噪聲,因此會干擾對兩者相似程度的判斷.同時,問題主題是問題全部信息的高度概括,相似問題往往擁有相似的主題,主題不同但問題相似的概率很低,表1中的示例也證明了這一點.因此問題主題也是判斷問題相似的重要依據.

Table 1 A Pair of Similar Questions in QatarLiving表1 QatarLiving中的相似問題
針對上述問題,本文將關鍵詞和問題主題視為問題的關鍵信息,利用這些信息輔助神經網絡模型判斷問題相似,提出了一種基于關鍵詞和問題主題的相似度計算模型(convolutional neural network based on keywords and topic, KT-CNN).該模型在文本間相似及相異信息的卷積神經網絡(convolu-tional neural network, CNN)模型[2]基礎上引入了關鍵詞抽取技術并融入了問題主題間的相似度作為特征.
1 相關工作
在國內外均有大量研究人員進行社區問答中計算問題相似度方面的研究.部分研究人員使用基于翻譯模型的方法判斷問題相似或檢索相關問題.Jeon等人[3]利用答案間語義的相似程度來估計基于翻譯的問題檢索模型的概率;Lee等人[4]基于經驗將非主題詞以及無關詞匯去掉,構造了一個緊湊的翻譯模型.除了詞匯級別的翻譯模型外;Zhou等人[5]提出了一種短語級別的翻譯模型以提取更多的語境信息.基于翻譯模型的可以在一定程度上解決文本相異但語義相近的問題,但其無法獲取問題的結構信息、詞共現信息以及語料中的詞分布信息,而且會被翻譯模型本身的誤差所限制.
除了基于翻譯模型的方法外,還有人利用基于主題模型的方法.Duan等人[6]使用基于最小描述長度(minimum description length, MDL)的樹模型來識別問題主題和焦點,再通過問題主題和焦點來搜索相似問題;Zhang等人[7]認為問題和答案包括相同的主題,提出了一個基于主題的語言模型.該方法不僅對詞項而且對主題進行了匹配;熊大平等人[8]則提出了基于潛在狄利克雷分布(latent Dirichlet allocation, LDA)的算法,該算法利用問句的統計信息、語義信息和主題信息來計算問句相似度.這一類方法主要利用問題主題的信息,其基本思想是主題相似的問題一定相似.其利用主題在語義層次上表示問題,但可能忽略文本中的一些細節問題.
于此同時,基于神經網絡的方法也很流行.dos Santos等人[9]提出了一種將詞袋模型同傳統CNN模型相結合的神經網絡模型,其效果要優于傳統詞頻-逆文檔頻率(term frequency-inverse document frequency, TF-IDF)模型和基于長文本的CNN模型;Lei等人[10]為了解決關鍵信息隱藏在大量細節中的問題,提出了一種循環卷積網絡將問題映射到語義表示.基于神經網絡的模型從文本中自動抽取特征,可以更好地利用文本的語義信息,深層次地考慮文本間的相似性.
與這些模型相比,我們的模型利用了問題的關鍵詞及主題信息,對問題的細節及全局信息進行了建模,能更好地表示問題.
2 模型介紹
我們提出的模型包括關鍵詞抽取、基于關鍵詞相似及相異信息的問句建模、計算主題相似度、問題相似度計算4個模塊.對于輸入的問題S和T,我們進行操作:1)進行一系列的預處理操作,再通過關鍵詞抽取模塊抽取S和T的關鍵詞序列KeyS和KeyT;2)利用KeyS和KeyT間相似及相異信息對問題S和T建模得到S和T的特征向量FS和FT;3)對問題S和T的主題TopicS和TopicT計算相似度Simtopic;4)基于S和T的特征向量FS和FT以及問題主題間的相似度Simtopic計算問題S和T的相似度Simq.模型的結構如圖1所示:
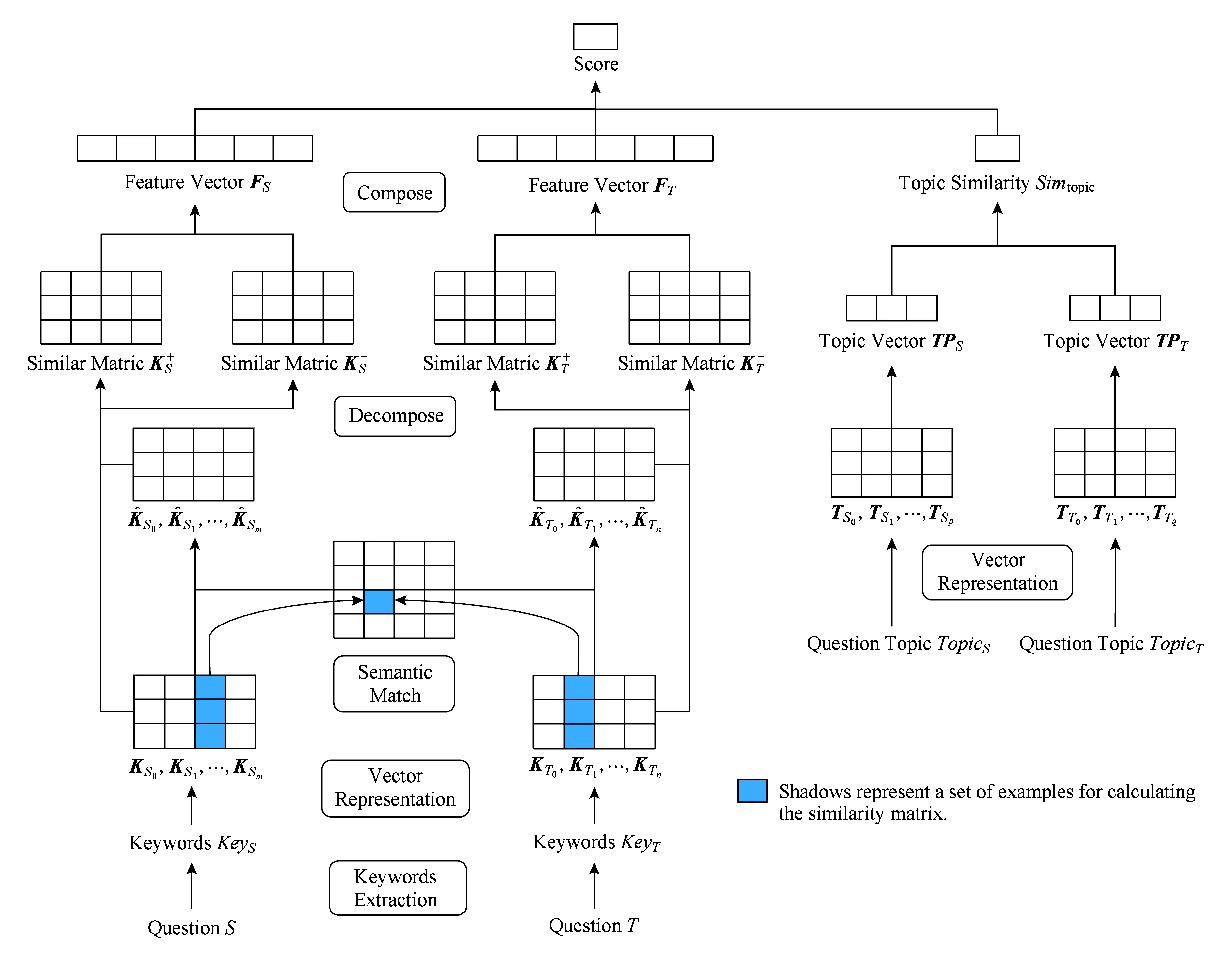
Fig. 1 Model architecture圖1 模型結構
2.1 關鍵詞抽取
我們對問題S和T的主題及描述抽取關鍵詞KeyS和KeyT.由于問題的主題及描述可能包含多個句子,因此我們對問題的每個子句都抽取關鍵詞.我們將其子句的關鍵詞按照得分進行排序,然后再按照子句出現的順序對所有的關鍵詞進行排序,得到問題的關鍵詞序列.
對于每個子句,我們使用了一種無監督的基于依存排序的關鍵詞提取算法.該算法由王煦祥[11]提出,我們在該算法的基礎上進行了一些改進.對于給定的問句,該算法利用統計信息、詞向量信息以及詞語間的依存句法信息,通過構建依存關系圖來計算詞語之間的關聯強度,利用TextRank算法[12]迭代計算出詞語的重要度得分.
算法流程如圖2所示,主要步驟包括構建無向有全圖、圖排序以及選取關鍵詞.
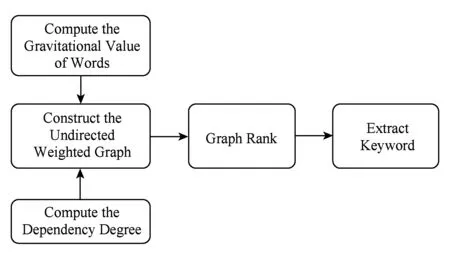
Fig. 2 The flow chart of keywords extraction圖2 關鍵詞提取流程圖
首先,我們根據句子的依存句法分析結果對所有非停用詞構造無向圖.依存句法分析的結果為樹結構,只要去掉根節點并忽略弧的指向便可以得到無向的依存關系圖G=(V,E),V=w1,w2,…,wn,E=e1,e2,…,em,其中wi表示詞語,ej表示2個詞語之間的無向關系.
接著,我們利用詞語之間的引力值以及依存關聯度計算求得邊的權重.
詞引力值得概念由Wang等人[13]提出.作者認為2個詞之間的語義相似度無法準確衡量詞語的重要程度,只有當2個詞中至少有一個在文本中出現的頻率很高,才能證明2個詞很重要.其受到萬有引力定律的啟發,將詞頻看作質量,將2個詞的詞向量間的歐氏距離視為距離,根據萬有引力公式來計算2個詞之間的引力.然而在社區問答的環境中,僅利用詞頻來衡量文本中某個詞的重要程度太過片面,因此我們引入了IDF值,將詞頻替換為TF-IDF值,從而考慮到更全局性的信息.于是我們得到了新的詞引力值公式.文本詞語wi和wj的引力:
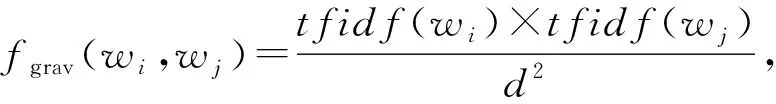
(1)
其中,tfidf(w)是詞w的TF-IDF值,d是詞wi和wj的詞向量之間的歐氏距離.
依存關聯度的概念由張偉男等人[14]提出.無向的依存關系圖保證了問句中的任意2個詞之間都有一條依存路徑,而依存路徑的長短反映了依存關系的強弱.因此,該算法根據依存路徑的長度,計算依存關聯度:
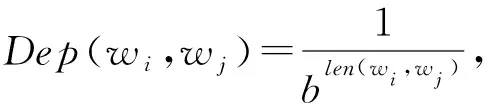
(2)
其中,len(wi,wj)表示詞語wi和wj之間的依存路徑長度,b是超參數.
綜上,2個詞語之間的關聯度,即邊的權重值是2個詞的引力與依存關聯度的乘積:
weight(wi,wj)=Dep(wi,wj)×fgrav(wi,wj).
(3)
最后,我們使用有權重TextRank算法進行圖排序.在無向圖G=(V,E)中,V是頂點的集合,E是邊的集合,頂點wi的得分由式(4)計算得出,其中weight(wi,wj)由式(3)計算得出,Cwi是與頂點wi有邊連接的頂點集合,η為阻尼系數.我們選取得分最高的t個詞語作為句子的關鍵詞:
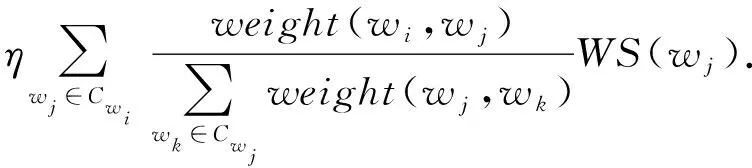
(4)
2.2 基于關鍵詞間相似及相異特征的CNN模型
由于文本間相似信息和相異信息對判斷2段文本是否相似均有重要的作用,因此我們使用了一種基于文本間相似及相異信息的CNN模型[2]對問題的關鍵詞序列進行建模,并在原模型的基礎上進行了改進.
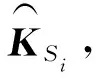
2.2.1 詞向量表示
我們使用基于Pennington等人[15]提出的GloVe模型預訓練的詞向量來表示關鍵詞.對于關鍵詞序列KeyS和KeyT,我們將其表示為矩陣:
KS=(KS0,KS1,…,KSi,KSi+1,…,KSm)
(KT=(KT0,KT1,…,KTj,KTj+1,…,KTn)),
其中,KSi和KTj是關鍵詞的d維詞向量,m和n是KS和KT中包含的關鍵詞數量.
2.2.2 語義匹配
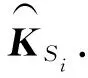
為了計算語義匹配向量,我們先計算KS和KT的相似矩陣Am×n.原論文使用余弦相似度計算詞匯間的相似程度,我們將其替換為皮爾森相關系數,即Am×n中的每個元素ai,j是KSi和KTj的皮爾森相關系數,相對于余弦相似度,皮爾森相關系數考慮了對均值的修正操作,對向量進行了去中心化:
ai,j=Pearson(KSi,KTj),
(5)
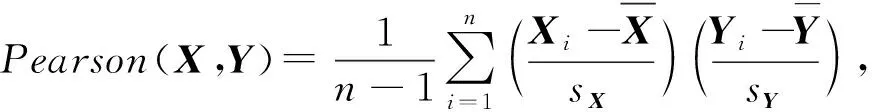
(6)

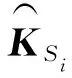
(7)
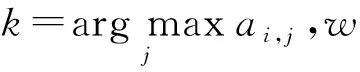
2.2.3 矩陣分解
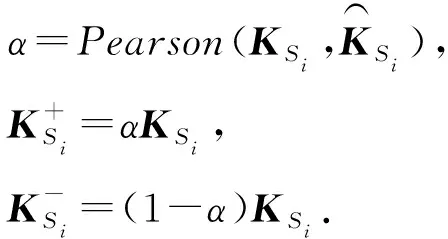
(8)
2.2.4 矩陣合并
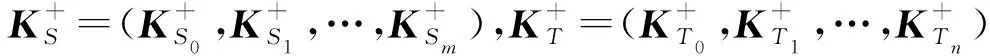
以問題S為例,CNN模型包括2個連續的層:卷積層和最大池層.我們在卷積層設置了1組過濾器{filter0,filter1} ,分別應用在相似通道和相異通道上來生成1組特征.每個過濾器的規模是d×h,d是詞向量的維數,h是窗口的大小,其過程為
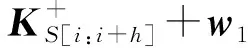
(9)
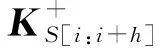
通過卷積層我們得到1組特征co=(co,0,co,1,…,co,l)特征的數量l取決于過濾器的規模以及輸入關鍵詞序列的長度.為了解決特征數量不固定的問題,我們對co進行最大池化的操作.我們選取co中最大的值作為輸出,即co,max=maxco.因此,經過池化操作后,每組過濾器生成1個特征.最后特征向量的維數將取決于過濾器的數量.
2.3 問題主題間的相似度計算
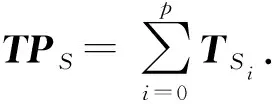
Simtopic=Pearson(TPS,TPT).
(10)
2.4 問句相似度計算
我們依靠基于關鍵詞間相似及相異特征的CNN模型生成的問題S和T的特征向量FS和FT以及問題主題間的相似度Simtopic計算問題S和T的相似度.我們使用一個線性模型將所有的特征加權相加,其中w0,w1,w2是相應的權重,bsig是偏移項,最后我們用sigmoid函數將計算結果限制在[0,1]的區間內:
Simq=sigmoid(w0*FS+w1*FT+
w2×Simtopic+bsig).
(11)
3 實 驗
為了證明我們提出模型的有效性,我們在SemEval2017[16]的評測語料上進行了實驗.SemEval2017的任務3子任務B[16]的主題是社區問答中問題相似度計算.給定一個新提出的問題和10個由搜索引擎確定的相關問題,我們要依據問題間的相似度對相關問題進行重排序.該任務對相關問題設置了3個標簽,分別為:PerfectMatch,Relevant,Irrelevant.我們認為標記為PerfectMatch和Relevant的是正例(不區分PerfectMatch和Relevant),標記為Irrelevant的是負例.對每一組問題的10個相關問題,我們使用模型得出的相似度對其進行重排序,并計算其平均精度,最后計算所有問題的平均精度均值(mean average precision,MAP)值作為系統的評價指標.MAP是反映系統在全部相似問題上性能的單值指標.系統檢索出來的相似問題越靠前,MAP就可能越高.因此我們需要將標記為正例的問題排在標記為負例問題的前面.
SemEval2017的評測語料來自于QatarLiving,訓練集包括270個問題,每個問題包括10個相關問題,共2 700個問題對.開發集包括50個問題,共500個問題對.測試集包括80個問題,共800個問題對.表2展示了1組訓練數據的樣例,每個問題包含問題主題和問題內容.雖然該任務是一個排序任務,但我們仍然按照分類任務對我們的模型進行訓練并得到了很好的結果.

Table 2 The Sample of Training Data表2 訓練數據樣例
3.1 實驗設置
在SemEval的語料中,由于用戶書寫不規范,語料中包含大量的錯誤.在實驗前,我們對其中一些錯誤進行了處理.表3列出了一些錯誤示例以及我們處理后的結果.用戶會將一些單詞中的某些字符重復書寫多次以表達感情,但這對我們處理問題造成了很大的干擾,因此我們將包含多余字符的詞匯進行還原.而有些用戶習慣用分號來分割句子,這會導致我們分句錯誤,因此我們將分號替換為句號.而且重復標點可能造成分詞錯誤或句法分析錯誤,因此我們也將重復的標點去掉.與此同時,我們還將所有的字母全部變為小寫以便后續處理.

Table 3 Error Example表3 錯誤示例
在CNN模型中,我們設置計算語義匹配向量的窗口w=3,卷積層中過濾器的尺寸為300×3,卷積層過濾器的個數為500.我們使用對數似然函數作為損失函數,使用SGD算法對模型進行優化,同時設置學習率為0.005.
在實驗中,我們使用了2種不同的詞向量.在關鍵詞抽取模塊以及CNN模塊中,我們使用斯坦福大學GloVe模型[15]預訓練的300維的詞向量.該詞向量沒有在QatarLiving的語料上進行訓練,更具有通用性,可以在一定程度上防止過擬合.而在基于問題主題的相似度計算模塊中,我們使用了在QatarLiving語料上進行預訓練的200維詞向量[19].該詞向量更具有領域的特殊性,因此更適合用于直接計算相似度.
3.2 結果及分析
首先,我們進行一組實驗證明關鍵詞提取和主題間相似度是有意義的.我們先后去掉基于主題信息的特征和關鍵詞提取模塊進行實驗,接著我們將這2個模塊全部去掉進行實驗.實驗結果如表4所示:

Table 4 Model Comparison Experiment表4 模型對比實驗
實驗證明,基于關鍵詞的模型要優于基于全部內容的模型.我們從3方面分析原因:
1) 由于不同問題包含的詞匯量不同,可能差異很大.這導致將全文作為神經網絡的輸入時,兩者所蘊含的信息量相差懸殊,不利于網絡學習.而抽取關鍵詞則將兩者詞匯量上的差距縮小,所蘊含的信息量的差距也同時縮小,這有利于神經網絡學習到有意義的特征.
2) 由于用戶的背景不同,所提出問題的背景信息有很大差別,這些背景信息會干擾模型判斷問題相似.抽取關鍵詞可以將干擾信息減少,幫助模型判斷問題相似.
3) 理論上,CNN模型可以通過多輪學習自動過濾無用信息,但要達到上述目標需要大量的語料.而由于語料不足,神經網絡模型無法很好地從過長的問題中抽取特征,將全文作為模型的輸入很有可能造成過擬合,而將關鍵詞作為模型的輸入則減輕了這一問題.
實驗也證明了問題主題相似度的特征可以輔助模型判斷問題相似度.我們認為,用關鍵詞序列代替全部文本作為神經網絡的輸入不可避免地會造成一些信息的流失,關鍵詞提取本身也會造成級聯錯誤.于是我們可以人為添加一些對判斷問題相似度有幫助的特征輔助模型進行判斷.而大量的研究表明問題主題可以幫助我們判斷問題相似,因此我們選擇了問題主題相似度作為輔助判斷的依據.
我們用實驗證明關鍵詞提取模塊中,使用TFIDF而非詞頻來判斷詞的重要程度是更優的選擇.實驗表明引入全局信息有助于表示詞的重要程度.結果如表5所示:
Table5ComparisonoftheFeatureUsedinComputingtheGravitationalValueofWords

表5 詞引力值使用特征對比實驗
同時,我們的模型中多次計算向量間的相似度.因此我們設計了一組實驗來證明在我們的模型中皮爾森相關系數要優于余弦相似度,皮爾森相似度可以更好地表示向量之間的相關程度.我們在語義匹配和矩陣分解以及主題相似度計算模塊中分別嘗試了余弦相似度以及皮爾森相關系數,實驗結果如表6所示:

Table 6 Comparison of Cosine Similarity and Pearson’s Correlation Coefficient表6 余弦相似度與皮爾森相關系數對比實驗
從表6可知,除了當主題相似度計算模塊使用余弦相似度時,在CNN模型中使用皮爾森相關系數的結果略差于余弦相似度且差距不大外,其他任何情況中皮爾森相關系數均優于余弦相似度.因此可以認為在我們的模型中,皮爾森相關系數要優于余弦相似度.
最后,將我們提出的模型同SemEval2017的評測結果進行比較,實驗結果如表7所示:

Table 7 The Experimental Results in SemEval2017表7 SemEval2017評測語料實驗結果
表7中名稱均為參加評測的隊伍名稱,我們選擇了評測中排名前3的模型進行比較.KeLP[20]系統基于SVM(support vector machine),使用具有問題間關系鏈接的句法樹內核以及一些文本間的相似性度量計算問題間相似度.Simbow[21]系統在余弦相似度中融入了關系度量,其使用多種關系度量計算余弦相似度,最后使用邏輯回歸模型計算問題相似度.LearningToQuestion[22]系統用神經網絡模型生成特征再使用SVM或邏輯回歸模型計算問題相似度.從表7中我們可以看出,我們的模型要優于評測中最好的模型,更遠遠優于基于IR(information retrieval)的基礎模型.但是,我們的模型仍有一些不足:1)由于關鍵詞提取技術的準確度不夠,我們無法保證是否有關鍵信息遺漏;2)以關鍵詞序列作為神經網絡的輸入破壞了問題的結構,我們無法利用問題結構上的信息來判斷問題相似性;3)我們使用用戶提供的問題主題間的相似度作為輔助判斷的依據,但用戶提供的主題可能太過簡略,無法幫助甚至會阻礙我們判斷問題相似.
4 結論及展望
我們提出了一種基于關鍵詞間相似及相異信息的CNN模型去計算社區問答中問題相似度.同時,我們將問題主題間的相似度特征融入到模型中,以輔助模型進行判斷.我們在SemEval2017的評測語料上進行了實驗,并超過了現有的結果.下一步我們將嘗試更多不同的關鍵詞抽取算法以及不同的神經網絡模型.同時,我們還會嘗試在模型中融入主題模型來替代問題主題相似度.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
