場景識別與PnP結合的視覺室內定位技術研究
2018-07-16 11:54:06甘興利祝瑞輝李雅寧
無線電工程 2018年8期
李 爽,甘興利,祝瑞輝,李雅寧
(衛星導航系統與裝備技術國家重點實驗室,河北 石家莊 050081)
0 引言
近年來,隨著商場、車站和展覽館等場所建筑規模的不斷擴大,人們對室內位置服務的需求也越來越迫切。例如在監獄內定位犯人、在醫院定位病人、在火災現場定位消防戰士或在倉庫內定位重要物品等。全球衛星定位系統已經能提供精確、穩定的室外位置服務,但由于衛星信號無法穿透鋼筋混凝土結構墻體,因此無法提供室內定位服務,由此研究人員開始尋求其他定位方法來實現室內的位置導航服務。目前室內定位技術主要包括紅外、藍牙、超聲波、Wi-Fi和超寬帶等,但是由于室內建筑格局各不相同,環境復雜多變,且存在多種不同類型的噪聲干擾,因此現有的室內定位方法仍然存在精度較低、穩定性不高等問題,限制了室內位置服務的推廣與應用[1]。基于視覺的定位方法具有定位精度高、能夠提供豐富的場景信息且價格便宜、攜帶方便等優勢,逐漸成為室內定位技術研究的熱點[2]。基于視覺的定位技術作為一項基礎技術,不僅可以應用于室內位置服務,還可以應用到其他領域,比如移動機器人導航、虛擬現實、航天器空間交互對接、無人機自主著陸和無人車自動駕駛等[3]。
本文提出了一種結合場景識別和透視n點投影問題的室內定位方法,其中場景識別利用卷積神經網絡(CNN)實現,透視n點投影問題利用基于虛擬控制點的PnP方法求解[4],并通過實驗對該方案進行驗證。
1 基于深度學習的場景識別分類
早期的場景識別分類技術主要研究基于圖像底層特征的分類方法。文獻[5-9]中采用的方法主要包含2部分:提取圖像特征,包括顏色、紋理和形狀等;對分類器進行訓練分類,常用的分類器有支持向量機、貝葉斯分類器和神經網絡等。隨著對場景分類技術研究的不斷深入,研究人員發現基于低層特征的場景分類方法無法適應不同場景的分類任務。因此,場景分類研究的重點開始逐漸轉向對圖像特征進行建模處理的方法,該類方法利用模型來描述待分類的圖像,使分類準確率得到進一步提高。學者們提出視覺詞袋(Bag of Words,BoW)模型場景圖像描述方法。詞袋模型即通過視覺單詞對圖像進行描述,視覺單詞是通過提取場景圖像底層特征后聚類生成的,該方法在一定程度上提高了圖像分類的泛化能力。
在2012年的比賽中,Alex Krizhevsky等提出AlexNet卷積神經網絡模型,首次將深度學習應用于大規模圖像分類,錯誤率為16.4%,相對于傳統的分類方法,在分類準確率上有巨大的提高,并因此開始引起研究人員的廣泛關注[10]。此后,基于深度卷積神經網絡的模型逐漸成為圖像分類領域研究的主要方法,一系列基于卷積神經網絡的改進方法不斷被提出,分類錯誤率也隨之在不斷下降[11]。
AlexNet是一個8層的卷積神經網絡,前5層是卷積層,接下來的2層為全連接層,最后一層為輸出層,采用softmax分類器進行分類[12]。該模型采用Rectified Linear Units(ReLU)來取代傳統的Sigmoid和tanh函數作為神經元的非線性激活函數,并提出了Dropout方法來減輕過擬合問題。本文對AlexNet網絡最后一層進行修改,根據分類場景的種類,將輸出單元個數進行修改,網絡結構如圖1所示。
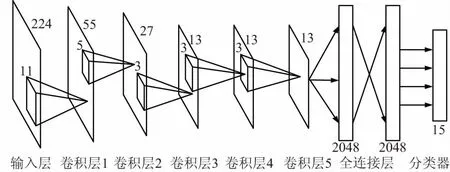
圖1 AlexNet網絡結構
采用正負樣本的訓練方式對AlexNet網絡進行訓練。正樣本為屬于該類別的2幅圖像,負樣本包括一幅屬于該類的圖像和一幅隨機選取的不屬于該類的圖像,正負樣本個數相同,訓練過程如圖2所示。
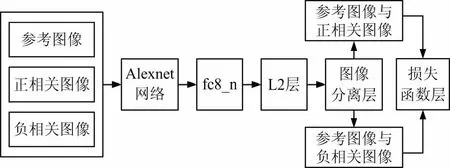
圖2 AlexNet訓練過程
訓練過程包含2步: ① 自底向上的無監督學習。首先使用無標簽訓練樣本對網絡按照自下而上的順序逐層訓練,學習數據特征,并將上一層的輸出作為下一層的輸入,通過這種方式可以分別訓練學習得到各層的參數。非監督學習類似于神經網絡的隨機初始化,但與神經網絡不同之處是深度學習是通過學習輸入數據的結構而得到各層參數,而不是隨機初始化的。這樣得到的初值更接近全局最優值,能有效地加快網絡訓練速度[13]。② 自頂向下的有監督學習。在完成第一階段訓練后,就要采用有標簽的數據訓練網絡模型,誤差自頂向下傳輸。通過有監督學習完成對網絡模型參數的微調,獲得整個網絡多個層參數的最優值。
2 基于特征點的定位
2009年Lepetit和Moreno提出的高精度快速位姿估計算法EPnP(Efficient Perspective-n-Point),其核心思想是將空間參考點都通過4個虛擬控制點來表示,再通過空間參考點和對應投影點之間的關系求解虛擬控制點的攝像機坐標,然后求得所有空間點在相機坐標系下的坐標,最后用Horn絕對定位算法求得旋轉矩陣和平移向量[14]。楊森和吳福朝提出了加權DLT算法和加權EPnP算法,雖然算法的時間復雜度略有增加,但位姿估計的精度進一步提高[15]。
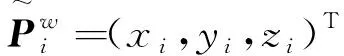
(1)
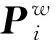
(2)
f=fu=fv為相機的焦距;(u0,v0)=(0,0)為光心坐標。
首先在世界坐標系下選取4個非共面虛擬控制點,虛擬控制點及其投影點的關系如圖3所示。
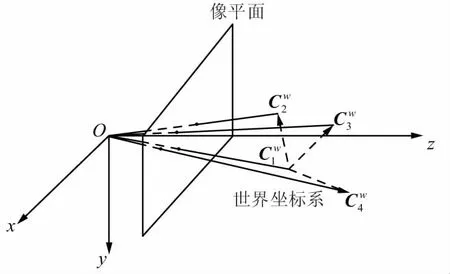
圖3 虛擬控制點及其投影點對應關系
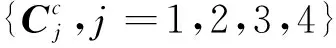
(3)
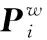
(4)
(5)
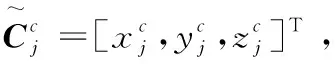
(6)
得到方程:
(7)
(8)
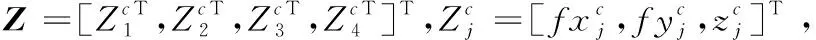
MZ=0,
(9)
式中,Z的解是矩陣M的核空間,即
(10)
式中,Wi為MTM對應零特征值的特征向量;N為MTM核空間的維數;βi為待定系數。對于透視投影模型,N的取值為1,得
Z=βW,
(11)
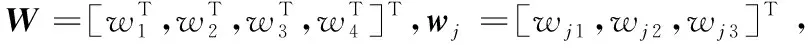
(12)
式(12)中求解得到的4個虛擬控制點圖像坐標和標定過程中求得的相機焦距,帶入絕對定位算法中即求出旋轉矩陣和平移向量[16]。通過上述計算過程得到相機的旋轉矩陣和平移向量初始值,構建所有對應特征點的誤差函數,采用高斯—牛頓法或L-M法迭代尋找最優解,得到最終的旋轉矩陣和平移向量[17]。本文采用的方法流程如圖4所示。
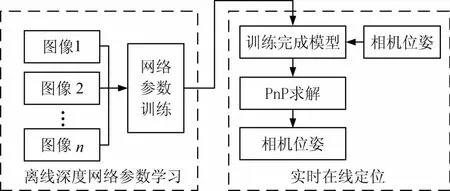
圖4 本文方法流程
3 實驗及結果分析
實驗分為室內場景識別和PnP定位2部分。實驗平臺為:Inter(R) Core(TM) i5-4460 CPU,主頻:3.20 GHz,內存大小:8.00 GB;
3.1 室內場景識別分類實驗
本部分實驗場景分為2類:MIT_indoor室內場景數據集和自采集室內場景數據集。MIT_indoor測試圖像庫:該圖像庫由Lazebnik等人建立,共有15類場景圖像,每類有200~400個灰度圖像(含有少量的彩色圖像),圖像的平均尺寸大小為300×200像素。該數據庫是廣泛應用于場景分類算法測試。部分場景圖片如圖5所示,其中4行依次是臥室、廚房、客廳和辦公室。
自采集場景圖像數據集,實驗場合:常規實驗室,利用攝像頭采集,圖像大小為320×240,24位彩色。該數據集共包含15類室內場景,每類包含100幅圖像,部分場景圖片如圖6所示。

圖5 MIT_indoor測試集的部分圖像

圖6 自采集場景部分圖像
對比實驗方法包括:基于詞袋模型、基于深度置信網絡和基于卷積神經網絡的方法。采用準確率作為指標評價分類算法性能優劣[18]。準確率是對分類結果的總體評價,等于被正確分類的場景個數與測試場景總數的比值,準確率越高說明算法的分類效果越好,設準確率為P,則計算公式為:
(13)
式中,Ni為分類正確的場景圖像個數;N為場景圖像總數。實驗結果如表1所示。
表1實驗結果

實驗數據集BoWDBNCNNMIT_indoor測試集0.5560.5820.836自采集場景0.5590.9000.933
通過表1實驗數據可知,基于CNN的場景分類方法,在Scene_15數據集和真實場景的分類準確率分別達到0.836和0.933,均高于基于詞袋模型和基于DBN的分類方法。通過在2個數據集上的實驗驗證,卷積神經網絡可以更加有效地提取場景特征,訓練出的網絡模型具有較強的泛化能力和較高的分類準確率。通過對錯誤分類的圖像的分析,發現場景中包含窗戶的圖像容易被錯誤分類,如圖6中第3行中的圖像,導致分類錯誤的原因主要是因為光照強度變化范圍較廣,相機無法有效采集窗外信息,可用于識別分類的信息量太少。
3.2 PnP定位實驗
實驗場合:常規實驗室,房間大小6.6 m×5.9 m,如圖7所示。實驗相機:羅技C270網絡攝像頭,提前標定好。測量工具:卷尺。手持攝像頭在實驗室內行走,在共記25個位置采集周圍環境圖像,圖像像素為320×240,其中圖像包含的空間參考點的世界坐標已知。
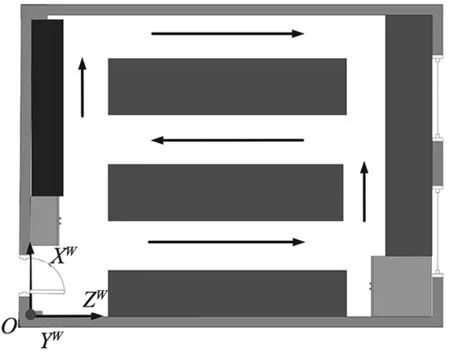
圖7 實驗室環境地圖
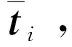
(14)
式中,Et為平移向量誤差占真實平移距離的百分比[19]。
真實軌跡和各方法估計移動軌跡如圖8和圖9所示。由圖9實驗數據可得,RPnP平均定位定位誤差為0.33 m,EPnP平均定位誤差為0.19 m,本文算法平均定位誤差為0.10 m,最大誤差為0.3 m,且定位誤差變化幅度小,穩定性高。
圖8 各位置估計誤差
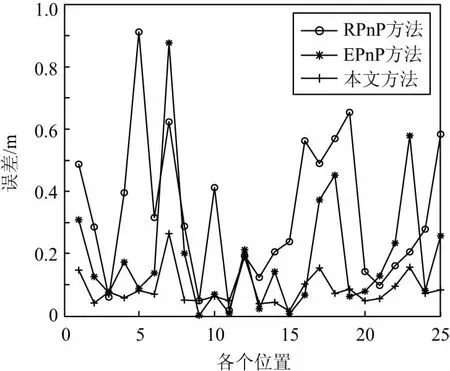
圖9 各位置估計誤差
4 結束語
首先利用卷積神經網絡對場景進行識別,然后根據對應特征點計算位置的技術應用于室內定位領域,且具有定位精度高、成本低和攜帶便捷等優勢[20]。實驗結果表明,本文提出的方法平均定位精度達到分米級,且抗噪聲能力強、魯棒性好,基本滿足室內定位需求。不足之處為在真實環境實驗中采用的場景規模較小,環境復雜度不高,下一步應針對規模更大、內容更加復雜的場景進行實驗,并對方法進行改進。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
