深度學習的方法論辨析
2018-07-10 06:26:34張玉宏秦志光
重慶理工大學學報(社會科學) 2018年6期
張玉宏,秦志光
(1.電子科技大學 網絡與數據安全四川省重點實驗室, 四川 成都 6100542;2.河南工業大學 信息科學與工程學院, 河南 鄭州 450001)
近年來,深度學習(Deep Learning)在諸多領域都有著很多驚人的表現[1]。例如,它在棋類博弈、計算機視覺、語音識別及自動駕駛等領域,表現得跟人類一樣好,甚至更好。在2013年,深度學習被麻省理工學院的《MIT科技評論》(MITTechnologyReview)評為世界十大突破性技術之一[2]。
2016年3月,代表人類圍棋頂級水平的李世石九段,以1∶4負于谷歌公司研發的阿爾法圍棋(AlphaGo),這標志著人工智能在圍棋領域已經超越人類,一時震驚四野。而在背后支撐AlphaGo具備如此強悍智能的技術之一,就是深度學習算法。一時間,深度學習,這個本專屬于計算機科學的術語,成為包括學術界、工業界甚至風險投資界等眾多領域的熱詞,它對我們的工作、生活甚至思維都已產生深遠的影響。
當前,學者多從技術或工程實現的角度來研究這個議題,而從科技哲學的角度,尚未有深入的討論。在深度學習備受矚目的背后,我們不禁思考,人工智能的技術本質是什么,深度學習的技術哲學特性是什么,它成功背后的方法論又是什么?本文著重對以上幾個問題進行討論。
一、人工智能的技術本質
從宏觀的視角來看,人類科學與技術的發展一路走來,主要依靠兩條腿的“并駕齊驅”:一條腿是能量傳輸,從生火、燒柴、燒煤、蒸汽機,到火電、風電、太陽能及核聚變;另一條腿就是信息傳輸,從語言、文字、烽火臺、穿孔卡、磁帶、無線電,到硬盤、電子計算機、量子通信,它們大致都遵循著這樣的規律:發現現象、深入認識和人工模擬(或重現)。
20世紀40年代以后,腦科學、神經科學、心理學及計算機科學等眾多學科,取得了一系列重要進展,使得人們對大腦的認識相對“深入”,從而為科研人員從“觀察大腦”到“重現大腦”搭起了橋梁,哪怕這個橋梁到現在還僅僅是個并不堅固的浮橋。而所謂的“重現大腦”,在某種程度上,就是目前的研究熱點——“人工智能”。
1958年,神經生物學家大衛·休伯爾(David Hunter Hubel)與托斯坦·威澤爾(Torsten N.Wiesel)在動物視覺信息處理的研究中發現,對于視覺的信息處理,動物大腦皮層是分級、分層處理的[3-4]。正是因為這個重要的生理學發現,二人獲得了1981年的諾貝爾醫學獎。而這個科學發現的意義,并不僅僅局限于生理學,它還間接促成了人工智能在50年后的突破性發展。
休伯爾和威澤爾等人的研究表明(由于我們對大腦的認識非常有限,所以他們的研究也并非定論),大腦的工作過程是一個不斷迭代、不斷抽象的概念認知過程。動物視覺系統的信息處理就是這樣分級完成的。這種分層次結構的感知系統,由于逐層抽象迭代,使大腦的視覺系統需要處理的數據量大大減少,但卻保留了判別物體所需的最有用信息。
在人工智能領域,正是受到生物神經網絡的啟發,自20世紀80年代起,人工神經網絡開始興起,而且在很長一段時間,都是人工智能領域的研究熱點。
簡單來講,人工智能就是為機器賦予與人類類似的智能。由于目前機器的核心部件是由晶體硅構成,所以可歸屬為“硅基大腦”。而人類的大腦主要由碳水化合物構成,因此可稱之為“碳基大腦”。因此,從技術本質上來講,現在的人工智能,大致就是用“硅基大腦”模擬或重現“碳基大腦”的過程[5]。
二、深度學習的技術哲學特性
從大腦對視覺信息處理的機理中,我們可以提煉出兩個重要的特征:(1)迭代抽象;(2)分層處理。而這兩點正是當前深度學習的核心特征。
2006年,加拿大多倫多大學的資深機器學習教授杰弗里·辛頓(Geoffery Hinton)在世界著名學術刊物《科學》(Science)上發表了一篇關于深度學習的開山之作[6]。在這篇文章中,辛頓給出了兩個重要結論:(1)具有多個隱層的人工神經網絡具備更佳的特征學習能力,多層網絡之間,每一層都是以前一層提取的特征作為輸入,并對其進行特定形式的變換,得到更加抽象的表達。而且這種層次化的特征提取過程可以疊加,從而讓深度神經網絡具備強大的特征提取能力;(2)可通過逐層初始化(layer-wise pre-training)方式來克服訓練上的困難,而逐層初始化是通過無監督的自主學習完成的。
由此可以看出,深度學習的關鍵在于建立并模擬人腦進行分析學習的神經網絡,它模仿人腦的機制來解析數據(如聲音、圖像和文本等)。深度學習可視為一種自動的特征學習方法,它把海量原始數據通過一些簡單的但非線性的模型,轉變成為更高層次的、更加抽象的表達[7]。
具體來說,深度學習的基本工作模式就是,除了輸入層和輸出層,中間還堆疊多個隱含層,前一層的輸出作為下一層的輸入。網絡中每一層,都由無數神經元構成,而每個神經元都有一組“權值”和一個控制其輸出啟動的“激活函數”。神經網絡的訓練涉及到調整神經元的權值,使特定的輸入產生我們需要的輸出。通過這樣的分層框架,就可以實現對輸入信息進行分級表達。
深度學習中的“深度”,可理解為更大規模的網絡,而“更大規模”可簡單理解為包括“更多隱含層”,而“更多隱含層”在某種程度上也可理解為能夠提取更高抽象層次的特征,因為每一層都可視為上一級網絡的數據抽取變換,層數越多就越抽象,表達能力(如分類能力)也就越強。
深度學習之所以備受矚目,是因為從最原始的輸入層開始,到中間每一個隱含層的數據抽取變換,到最終的輸出層的判斷,所有特征的提取,全程都是一個沒有人工干預的訓練過程。這個自主特性,在機器學習領域是革命性的。
知名深度學習專家吳恩達(Andrew Ng)曾表示:“我們沒有像通常(機器學習)做的那樣,自己來框定邊界,而是直接把海量數據投放到算法中,讓數據自己說話,系統會自動從數據中學習。”谷歌大腦項目(Google Brain Project)的計算機科學家杰夫·迪恩(Jeff Dean)則說:“在訓練的時候,我們從來不會告訴機器說:‘這是一只貓’。實際上,是系統自己發明或者領悟了‘貓’的概念。”
因此,深度學習不僅僅只是一種電子算法的升級,更是一種全新的思維模式。我們完全可以利用深度學習,通過對海量數據的快速處理,消除信息的不確定性,從而幫助我們認知世界。它帶來的顛覆性在于,將人類過去癡迷的算法問題演變成數據和計算問題[8]。
三、深度學習的方法論
任何一個事物的成功,都需要一個比較成熟的方法論做指導,深度學習也不例外。為什么早期的人工神經網絡屢屢折戟沉沙,而現在的深度學習卻大獲成功,這不僅要歸功于計算機硬件性能的提升和大數據的累積,還要歸功于人們在方法論認知上的改變。
(一)傳統人工智能學派與還原主義
在過去,包括神經網絡在內的大部分的人工智能系統,主要分為如下3個流派,如表1所示。

表1 人工智能的流派
傳統的人工智能學派,事實上,大多希望遵循一種“還原主義(reductionism,或稱還原論)”的思想來推動科學的發展。而“還原主義”,就其英文詞根“reduction”的本意而言,就有“減少”“簡化”等含義,意思就是把一種形式變化為另外一種更加簡單的形式。在18世紀的科學術語中,“reduction”含義就是把化合物變化為相對簡單的元素[9]。
僅從字面的定義就可以看出,“還原主義”里有一種“追本溯源”的含意包含其內,即一個系統(或理論)無論多復雜,都必須能夠還原到邏輯原點。在意象上,最終可簡單地從一個或幾個簡潔而漂亮的基本法則推導而出。比如說,很多經典力學問題,不論形式有多復雜,最后都可通過牛頓的三大定律得以解決。再比如,在電磁學領域,麥克斯韋方程組也異常簡略完美。
隨著伽利略、牛頓等科學巨匠開創近代意義上的科學以來,“還原論”在科學發展中發揮了巨大的作用。面對非線性復雜現象,經典科學家們總是設法忽略非線性影響因素,進而用線性模型來描述,甚至把能夠構建出線性模式作為科學研究獲得成功的標志,但這一標志也漸顯疲態。例如,當代著名物理學家弗里曼·戴森(Freeman Dyson)在其著作《反叛的科學家》(TheScientistasRebel)一書中就提到,一些特別有成就的頂級科學家(比如愛因斯坦、奧本海默等),在功成名就之后,就特別容易犯一個“錯誤”,即抱負極大,總想用極少的幾個基本原理解釋世界上的一切事物[10]。
“還原論”的確雄心很大,試圖一勞永逸地解決科學發展中的問題,并達到對未來的準確預測。可結果如何呢?事實上,并不樂觀!戴森指出,愛因斯坦在美國苦苦研究幾十年的統一場理論,沒有新的發現,還對同時代的最新實驗結果和物理發現視而不見,錯過了太多的東西,實屬遺憾。那么,問題出在哪里呢?
當代著名物理學家斯蒂芬·霍金在一次演講中說:“除了非常簡單的情況,我們無法準確解出這些理論的方程,在牛頓萬有引力理論中,我們甚至連三體運動的問題都無法準確解出。在運用數學方程來預測人類行為上,我們極少成功。所以,即使我們確實找到了基本定律的完整集合,在未來的歲月里,仍然存在發展更好的方法,使我們在復雜而真實的情形下,完成對可能結果的有用預言的智慧,這是極富有挑戰性的任務。”[11]
其實,早在19世紀,馬克思、恩格斯等人就通過辯證法批判了還原論,將其總結為是孤立、靜止地看世界。現代科學技術的發展表明,我們不能把事物的復雜性全部歸因為認識過程不充分、不到位,而是必須承認復雜性的客觀存在,它并不隨著認識的深入而變得簡單,變得可還原。1984年,諾貝爾物理學獎獲得者蓋爾曼(Murray Gell-mann)、諾貝爾物理學獎獲得者安德森(Philip Anderson)、經濟學獎獲得者阿羅(Kenneth Arrow)深感還原論的局限性,提出超越還原論的口號,成立了圣塔菲研究所,專門從事復雜性科學的研究。1999年,美國著名學術期刊《科學》(Science)推出復雜性科學專刊,這標志著復雜性科學得到了國際科學共同體的認可[12]。霍金認為,復雜性科學是21世紀的科學[13]。我們應把復雜性當作復雜性來處理,其言外之意就是說我們應以復雜性本來的面目研究,而不要徒勞地把復雜性簡單化、還原化,這或許是解決復雜性科學問題的最有效的方法論[14]。
(二)深度學習與復雜性理論
各類機器學習算法的解析過程,揭示出知識發現更可能是一個非線性的混沌過程[15]。倘若我們依然從傳統的“還原論”出發,依靠單純的線性組合思維(亦稱為結構化思維)進行研究,勢必會導致人工智能系統的設計功能過于簡單,難以描繪智能的復雜內涵。
深度學習是人工智能的一個典型應用場景,它可視為是人類大腦思考過程的物化和工程化。如果我們希望模擬的是一個“類人”復雜系統,那么追求簡化的還原論,自然就無法有效指導深度學習達到目標。具體說來,有如下兩個方面的原因:
(1)這個世界(特別是有關人的世界)本身是個紛紜復雜的系統,問題之間互相影響,形成復雜的網絡,這樣的復雜系統,很難利用一個或幾個簡單的公式、定理來描述和界定。
(2)在很多場景下,受現有測量和認知工具的局限,很多問題在認識上根本就不具有完備性。因此,難以從一個“殘缺”的認知中,提取適用于全局視角的公式和定理。柏拉圖在《理想國》里就講到了一個經典比喻——“洞穴之喻(Allegory of the Cave)”[16]。猶如洞穴人受限于鏈鎖一樣,會誤把他們所能感知到的投影于洞壁的影像(二維世界),當作真實的世界(三維世界),洞穴人怎能基于一個二維世界觀測的現象,來歸納出一個適用于三維世界的規律呢[17]?
但幸運的是,我們已到了大數據時代,大數據為我們提供了一種認知紛繁復雜世界的無比珍貴的資源——多樣而全面的數據。有學者就認為,大數據時代之所以具有顛覆性,就是因為目前一切事物的屬性和規律,只要通過適當的編碼(即數字介質),就可以傳遞到另外一個同構的事物上,得以“無損”全息表達[18]。
但對于這個復雜的世界,直接抓住它的規律并準確描述它,是非常困難的。在一個復雜系統中,由于非線性因素的存在,任何局部信息都不可能代表全局。大數據時代有個典型的特征就是,“不是隨機樣本,而是全體數據(n=all)”[19](這里,n代表數量大小),而“全體數據”和復雜性科學中的“整體性”,在一定程度上是有邏輯對應關系的。深度學習所表現出來的智能,也正是“食”大數據而“茁壯成長”起來的,其智能所依賴的人工神經網絡模型,還可隨數據量的增加而“進化”或改良[20]。因此,深度學習可視為是在大數據時代遵循讓“數據自己發聲”的典范之作。如果說“大數據思維是一種復雜性思維”[21],那么深度學習就是這個思維體系結出的碩果。
(三)深度學習與自主性
在計算機科學領域,傳統的計算機電子算法是將人類的知識和洞察轉化為一行行結構化的程序。而現有的人工智能——具體體現為各種機器學習算法,表現大大不同,它們是由計算機自行從數據中發掘規律。這種自主性,讓計算機不再仰仗人類的智慧,至少不全部依賴于人的經驗。舉例來說,AlphaGo的升級版AlphaGo Zero(譯作阿爾法元),通過自我訓練,以100∶0的戰績擊敗AlphaGo,便是一個有力的佐證。
復雜性科學認為,構成復雜系統的各個要素都自成體系,擁有自己的目標和行為,也就是說,它們具有獨立的自主性和主動性,不像機械系統一樣只會被動接受。復雜性科學資深學者普利高津(Prigogine)更是認為“復雜性就是自主性的別稱”[22],他把復雜性等同于自主性。如前文所述,深度學習最具有革命性的特征,神經網絡層次之間的特征抽取完全是自我學習完成的,這正是復雜性網絡自主性和適應性的最好例證。
有學者證明,大數據與復雜性科學在世界觀、認識論和方法論等諸多方面都是互通的[9]。復雜性是大數據技術的科學基礎,而大數據是復雜性科學的技術實現。而深度學習是一種數據饑渴型(data-hungry)的數據分析系統,天生就和大數據捆綁在一起[5]。在某種程度上,大數據是問題,而深度學習就是其中的一種解決方案。
深度學習為我們提供了一種新的機器學習范式(paradigm),即“端到端(end-to-end)”學習方法,它把特征提取和分類任務合二為一,完全交給深度學習模型,直接學習從原始輸入到期望輸出的映射。這里“端到端”說的是,輸入的是原始數據(始端),然后輸出的直接就是最終目標(末端)。整個學習流程并不進行人為的子問題劃分,而是完全交給深度學習模型,直接學習從原始輸入到期望輸出的映射。比如,基于深度學習的圖像識別系統,其輸入端是圖片的像素數據,而輸出端直接就是或貓或狗的判定。這個“end-to-end”的映射就是:像素→判定。再比如,“端到端”的自動駕駛系統,輸入的是攝像頭視頻信號(其實也就是像素),而輸出的直接就是控制車輛行駛的指令(方向盤的旋轉角度)。這個“end-to-end”的映射就是:像素→指令。實際上,這種“端到端”的機器學習范式,就是深度學習作為復雜系統所體現出來的“整體性”。
表2所示的就是幾個流行的深度學習項目中的參數細節。我們知道,還原主義的實質就是試圖通過研究各組成部分來理解整體。但從表2可見,深度學習網絡本身就是一個訓練數據量巨大、調節參數數量巨多的復雜網絡。這些網絡之間的參數,呈現出“剪不斷、理還亂”的不可分割狀態,因此它無法滿足“從部分認識整體”的認知范式[23]。
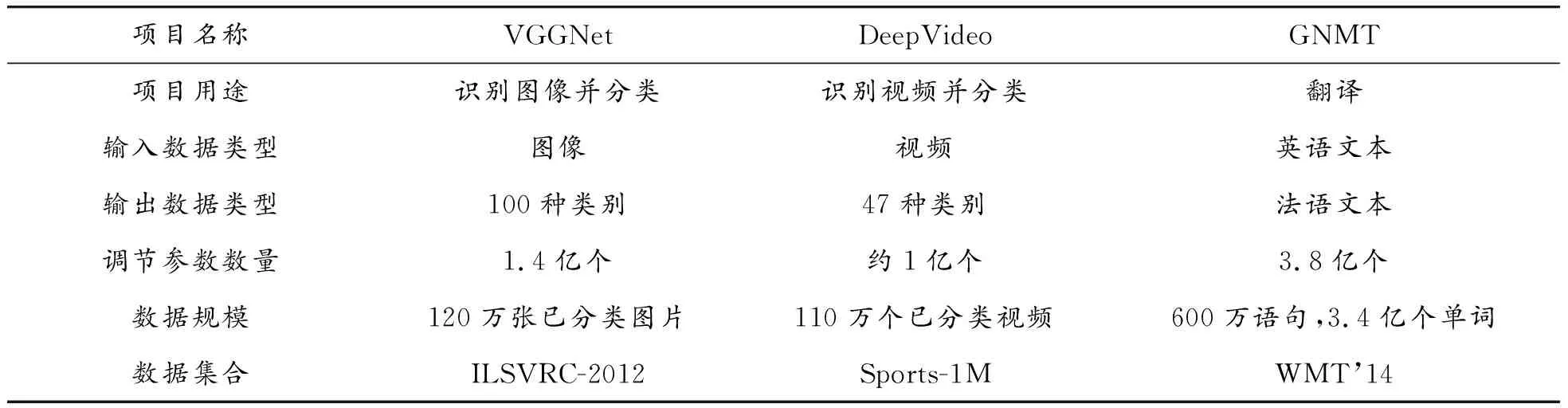
表2 深度學習項目中的數據規模與網絡節點參數調整數量
此外,在復雜系統中,各要素之間緊密相連,構成一個巨大的關聯網絡,存在著各種各樣的復雜聯系,各種要素組合起來會帶來新結構、新功能的涌現,也就是說,整體往往會大于部分之和。而這個特性,與以“整體等于部分之和”的還原論背道而馳。
從上面的分析可知,深度學習具備特征抽取的自主性、網絡節點的多關聯性(難以找到一個線性結構描述上億級別的參數)、智能提升的涌現性等特征,這些都表明它是復雜性科學里面的一種技術實現。
四、結語
如今,我們之所以如此重視大數據,本質上是因為大數據為我們提供了一種了解紛繁復雜世界的可貴資源。但是,倘若要從浩瀚的數據資源中挖掘出信息甚至智慧,則需要強有力的利器為我服務,而深度學習技術就是這眾多利器中的一種。目前,我們已經步入到一個數據驅動的人工智能時代,在這個時代,數據成為智能模型的“燃料”,如何有效地燃燒這些“燃料”以獲取騰飛的動力,迫切需要科學的方法論來為之指導,否則就可能“南轅北轍”,工具越先進,距離目標越遠。目前,在復雜性科學理論指導下的深度學習技術,依靠大數據資源,打造出了對這個世界理解的更加深刻的智能認知模型。
但我們也要看到,深度學習是腦科學的一種“仿生”和類比,而腦科學的理論體系本身還遠遠沒有完整構建起來,因此由這種殘缺式“仿生”帶來的智能,天生就不具備十足的代表性。此外,深度學習的可解釋性不足,也是其備受詬病的問題之一。因此,對腦科學研究成果的多樣性解讀還必須深入[23],對更佳科學方法論的追尋還必須繼續。只有這樣,才能更好地引領以深度學習為代表的人工智能的研究與發展。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
小小藝術家(2019年6期)2019-06-24 17:39:44
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
小康(2017年16期)2017-06-07 09:00:59
南風窗(2016年19期)2016-09-21 16:51:29
今古傳奇·故事版(2016年15期)2016-09-07 06:57:32
