片上網絡在多核公鑰處理器中的應用研究*
2018-07-09 06:45:06楊瑞瑞
通信技術 2018年6期
何 濤,楊瑞瑞
(成都三零嘉微電子有限公司,四川 成都 610041)
0 引 言
隨著萬物互聯的信息發展,現有的公鑰處理器芯片已無法滿足接入認證服務器的性能需求。橢圓曲線密碼算法的運算量巨大,造成單核性能的提升空間有限。近年來,提出的片上網絡技術可以提供強大的多核互聯能力,具有良好的擴展性,非常適用于高速公鑰處理器芯片的多核設計。
1 算法特點簡述
公鑰算法的特點是所需的傳輸數據量小,但計算時間長。以國家密碼局推薦的商秘SM2算法為例,推薦的曲線域寬是256 bit,曲線參數是p、a、b、Gx、Gy、n這六個基本參數。它們一般是在初次分發時就確定下來,除非全系統升級才可能進行更換。因此,片上網絡設計時不需考慮曲線參數的傳輸性能。
在進行簽名運算時,所需傳遞的數據有:隨機數k、私鑰d、消息雜湊值m,總數據量為256×3=768 bit。考慮到每個數據具有32 bit的標識位,因此總的輸入數據量為864 bit,對應的輸出數據為簽名結果(r,s),共512 bit。
在進行驗簽運算時,所需傳遞的輸入數據有:公鑰坐標(Px,Py)、簽名結果(r,s)、消息雜湊值m,總數據量為256×5=768 bit。同樣,按每個數據具有32 bit標識位估算,總的輸入數據量為1 440 bit。對應的輸出數據為簽名通過與否的標識,為32 bit。
考慮到實際應用中數字簽名驗簽操作會交替進行,因此數據輸入性能需求按最大數據量1 440 bit進行評估。
2 網絡性能分析
片上網絡中所需運算核的數目和數據路徑的性能決定于芯片的整體性能期望。假設芯片上共有M個運算單核,單核的單次簽名計算耗時計為Tcalc,則理論上的芯片整體簽名性能應為單核的數據輸入耗時計為Tin,單核的結果輸出耗時計為Tout,考慮芯片僅有一個輸入接口和一個輸出接口,則多核運行耗時如圖1所示。可以看到,數據傳輸所消耗的Tin和Tout會造成整體性能的損失。
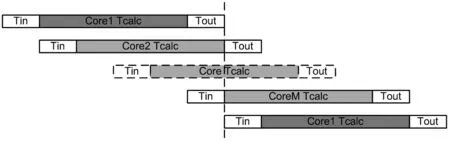
圖1 多核運行耗時情況
為了讓M個核均達到滿負荷工作,需滿足條件該條件下,每個
從圖1可得,芯片整體的運算性能為單核的當前結果輸出后,可緊接著輸入下一個運算任務。按進行估算,則得到單核數據傳輸時間和單核運算性能的關系為Tin≤Tcalc/(M-2)。該公式給出了多核網絡滿負荷工作對數據傳輸性能的要求。
結合上述分析,在滿足全部運算核滿負荷工作所需的最低數據傳輸速率的前提下,芯片整體性能和單核性能的關系為該公式給出了滿足目標性能所需多核數量的計算方法。假設芯片簽名的期望性能是30 000次/s,單核的簽名性能為1 000次/s,那么單核數目應為32個。
根據公式得到單核數據傳輸時間不應大于33 μs。單次運算所需數據量為1 440 bit,那么每個運算單核的輸入端的數據速率為1 440 bit/33 μs=43 Mb/s。通常來說,芯片具有唯一的輸入接口,多個任務數據均依次從該輸入接口進入,再分發到每個運算單核,那么芯片輸入接口到每個核的傳輸速率應不低于43 Mb/s。
3 片上網絡設計方法
3.1 網絡拓撲與路由設計
由于單個運算核的面積較大,網絡節點數目多,并有擴展需求,因此選用規整的Mesh結構[1]作為網絡拓撲,以最低的布線成本實現多核互連,避免因核數增加而帶來的布線擁塞。
Mesh拓撲確定了網絡中的路由器具有5個端口——東、南、西、北和本地端,如圖2所示。
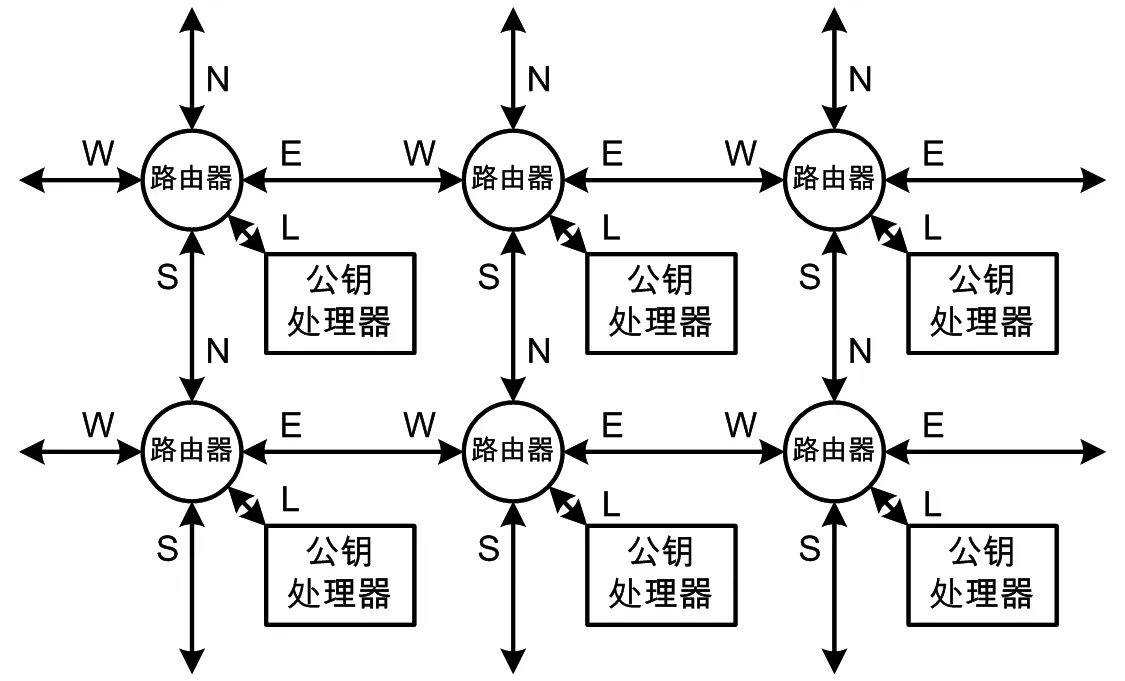
圖2 路由器結構
Mesh網絡采用維序路由算法,實施方法是:每個路由器用橫縱坐標標識自己在網絡中的位置,對比自身坐標與數據包目的坐標,其中優先比較橫坐標;若不等,則選擇橫坐標接近目的坐標的方向進行傳遞;若橫坐標相等,再比較縱坐標,若不等則選擇縱坐標接近目的坐標的方向進行傳遞;如果橫縱坐標均相等,則將數據包轉到本地端口,送至公鑰處理器。
3.2 傳輸鏈路設計
在數據傳輸鏈路設計方面,核心是解決如何讓數據從任意源節點傳輸到任意目標節點,并兼顧邏輯資源的最小化和傳輸效率的最大化。
如圖3所示,數據采用蟲洞傳輸[2]方式,將待傳輸的數據包進行分片。從源節點到目標節點的傳輸路徑上,每個中間節點僅保存一個分片,以降低節點緩存的開銷,極大地節省了面積。但是,當該點到點的傳輸未完成時,將會持續占用該傳輸路徑上的所有節點。考慮到數據傳輸耗時與公鑰計算耗時相比可忽略,且數據傳輸量小,因此該方式完全適合公鑰計算特點。

圖3 數據包分片
片上網絡中傳輸的數據分片分為三種類型:頭分片、載荷分片和尾分片。頭分片包含目標節點的地址信息,用于路由器選擇傳輸數據的方向,且該方向將會被該數據包獨占,直到傳輸完成。尾分片用于釋放在數據傳輸路徑上的所有路由器節點,使得路由器可以為其他數據包服務。
以32 bit的數據分片為例,鏈路上的每個節點使用寄存器緩存一級32 bit數據即可。考慮相鄰的兩個網絡節點,下游節點需要知道何時有從上游節點傳來的新數據,而上游節點也需要知道下游節點有沒有將上一筆數據取走。因此,在節點間加入了full信號和new信號。new信號由上游節點驅動,以向下游節點聲明是否有新數據;full信號由下游節點驅動,以向上游節點聲明是否能鎖存新數據。
如圖4所示,網絡中一個數據包的傳輸描述如下。初始時,網絡中所有節點的new和full均為無效狀態;若源節點產生了新數據,那么它將new置為有效;下一個時鐘沿,下游節點看到上游節點的new有效,且自身為空狀態,那么下游節點將鎖存新數據,且在下一個時鐘沿將自己的full置為有效,同時上游節點在該時鐘沿看到下游節點的full為無效,那么它知道本次數據已經被下游節點鎖存,因此在該時鐘沿將自己的new置為無效。
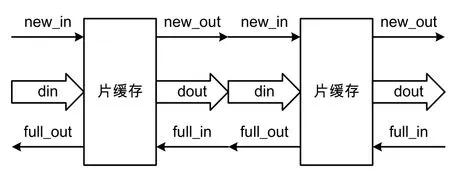
圖4 相鄰節點傳輸結構
從上述流程可以看到,數據包分片在網絡中的傳輸是由源節點的new信號驅動,并一級一級傳導下去。這種相鄰節點握手的傳輸方式,避免了長線信號的存在,可有效提高片上網絡的工作頻率。
如圖5所示,數據DATA0從節點N0的輸入端抵達節點N1的輸出端,需要使用2個時鐘周期。后續的DATA1由于full信號的握手,需要花費2個時鐘周期才能傳輸到下一個節點。假設兩個節點的距離為N,數據包的分片數為M,那么數據包在兩個節點間傳輸所需的時鐘周期數為個。8×4的Mesh網絡中,兩個最遠的節點距離為10。以輸入數據為1 440 bit計算,共45個載荷分片。一個數據包的傳遞最壞情況下,需要花費100個時鐘周期。傳輸時延要求為不超過33 μs,那么得到片上網絡的傳輸時鐘頻率不低于3 MHz即可。
3.3 輸入輸出節點選擇
考慮如圖6所示的8×4 mesh網絡。
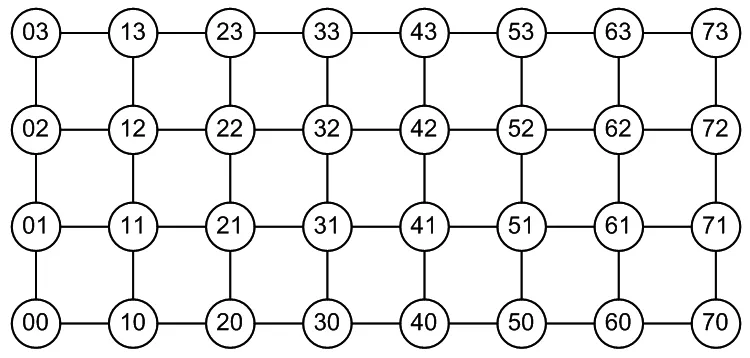
圖6 8×4 mesh網絡
圖6中,每個圓圈代表一個網絡節點,數字為橫縱坐標的組合。首先需要選取最優的輸入節點和輸出節點,使得:
(1)輸入節點到網絡中32個節點的路徑之和最短;
(2)網絡中32個節點到輸出節點的路徑之和最短。
該選取方式可以使任務加載和結果收集的數據傳輸效率最高,并降低工作功耗。
由于輸入節點和輸出節點僅僅是數據傳輸的方向相反,因此該問題可簡化為尋找網絡中某一個節點到其他所有節點的路徑之和最短[3-4]。
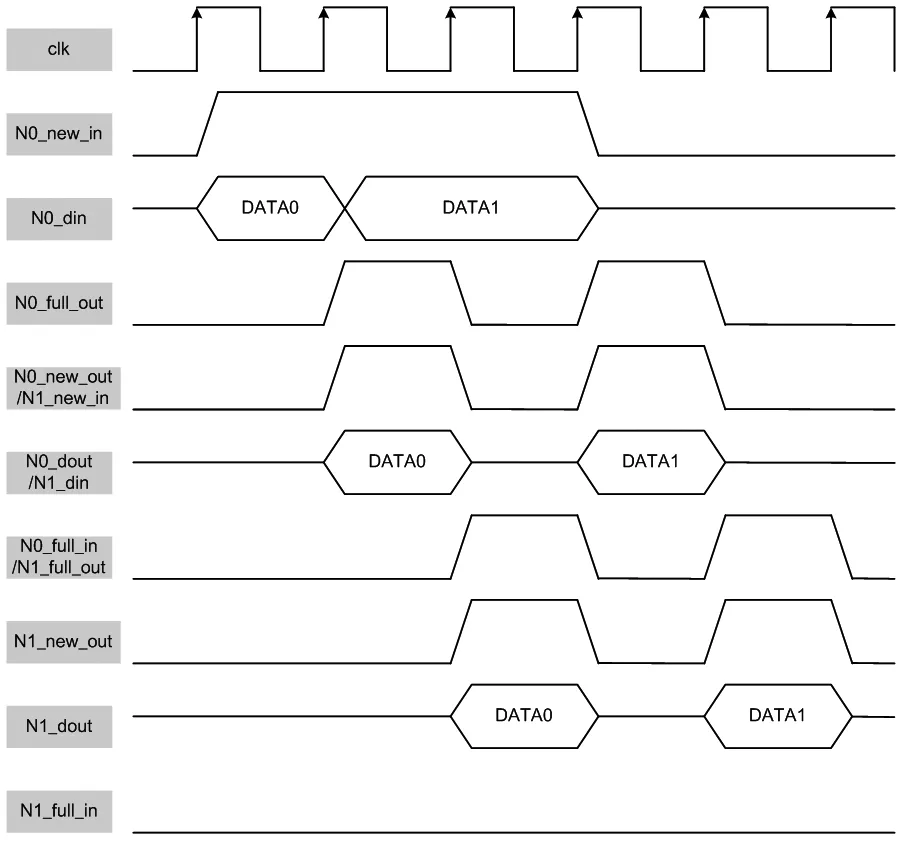
圖5 相鄰節點數據傳輸時序圖
采用等勢線作圖的方法進行分析,如圖7所示。
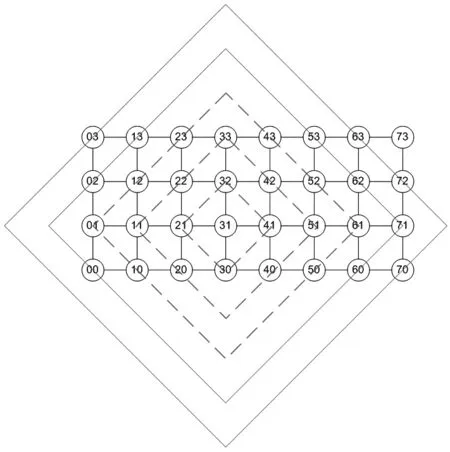
圖7 網絡等勢線分析圖
以源節點“31”為例,圖中每一條虛線都稱為該源節點的等勢線,即指同一條虛線框所連接的節點到源節點的距離均相等。因此,選定一個節點,畫出其等勢線。若距離越短的等勢線包含的節點越多,則該節點就是最優節點。不難看出,節點“31”即是一個最優節點,它到其他31個節點的距離之和為:4×1+7×2+8×3+7×4+4×5+1×6=72。
再將圖形按軸對稱和旋轉對稱進行翻轉,不難發現節點“32”“41”“42”均是和“31”等效的最優節點。所以,輸入節點和輸出節點從這四個最優節點中任意選取即可。本文將節點“31”作為輸入輸出節點進行設計。
3.4 任務分發和回收設計
在選定了輸入輸出節點的基礎上,考慮任務的分發和結果的回收順序。為了降低應用復雜度,本文中采用任務的先入先出機制,即最先進入的任務,其結果也最先輸出。
任務輸入時,根據節點坐標,按照從左到右、從上到下的固定順序,依次進行任務分發。結果輸出時,由于不同節點的運算核可能承擔不同類型的運算,且參與運算的參數權重各異,從而造成各個節點的運算耗時長短不一,有可能較晚啟動的運算任務比較早啟動的運算任務領先完成,因此結果輸出時,不能采用哪個節點有運算完成就輸出的策略。為此,引入了令牌機制。全網絡中僅有一個輸出令牌,當且僅當運算節點擁有輸出令牌時,才能向輸出節點傳輸結果數據。同時,全網絡中也僅有一個輸入令牌,當且僅當運算節點擁有輸入令牌時,才能向輸入節點請求任務數據。
如圖8所示,初始化時,節點“03”同時擁有輸入令牌和輸出令牌。該節點檢測到自己擁有輸入令牌且運算核狀態為空閑,則主動向輸入節點發出包含自身坐標的請求命令(圖8中a曲線)。輸入節點響應該命令,并根據坐標信息將運算任務發送至節點“03”(圖8中b曲線)。該節點的任務接收完成后,主動將輸入令牌傳遞給相鄰的節點“13”(圖8中c曲線)。節點“13”重復相同動作,實現了輸入令牌的依次傳遞,達到了每個節點依次主動向輸入節點申請運算任務的效果。
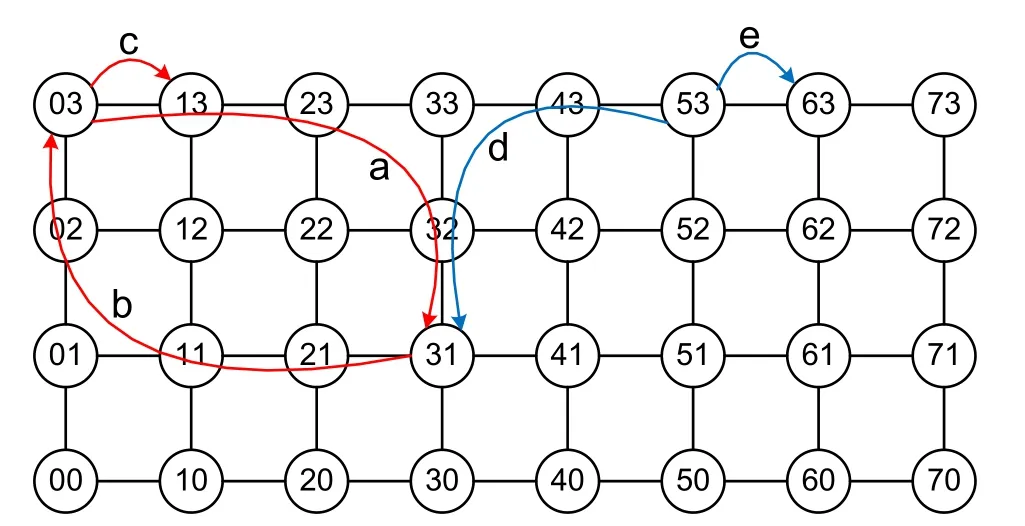
圖8 任務分發和回收
當節點“53”檢測到自己擁有輸出令牌且運算核狀態為運算完成時,則主動向輸出節點傳輸結果數據(圖8中d曲線)。當結果傳輸完成后,主動將輸出令牌傳遞給相鄰的節點“63”(圖8中e曲線)。節點“63”重復相同動作,實現了輸出令牌的依次傳遞,達到了每個節點依次輸出運算結果的效果。
采用這種令牌機制,也可以方便地實現容錯設計。多核芯片往往面積較大,由于工藝缺陷會造成芯片良率較低。可以采用屏蔽部分故障運算核的方式,使得有缺陷的芯片也可以降低性能使用。僅需在輸入節點的任務分發邏輯上,做一個可配置的設計,用于指定輸入令牌和輸出令牌的傳遞方式即可。
4 結 語
本文介紹了片上網絡技術在多核公鑰處理器設計中的應用方法,給出了多核性能分析方法、物理鏈路設計方法和最優輸入輸出節點的選取方法,提出了基于令牌的任務分發和回收機制,解決了片上網絡技術實施過程中的關鍵問題。本文提出的片上網絡結構應用于某款高速公鑰芯片中,集成了32個運算核。經芯片實測,SM2算法256 bit數字簽名性能達到了30 000次/s,符合預期設計。
[1] 朱曉靜.片上網絡的結構設計與性能分析[D].合肥:中國科學技術大學,2008.ZHU Xiao-jing.Structural Design and Performance Analysis of On-chip Network[D].Hefei:University of Science and Technology of China,2008.
[2] 張劍賢.高性能片上網絡關鍵技術研究[D].西安:西安電子科技大學,2012.ZHANG Jian-xian.Research of Key Technology of High Performance NoC[D].Xi'an:Xidian University,2012.
[3] YANG Lei,FoToNoC:A Folded Torus-Like Networkon-Chip Based Many-Core Systems-on-Chip in the Dark Silicon Era[J].IEEE Transactions on Parallel and Distributed Systems,2017,28(07):1905-1918.
[4] Reza H.Customizing Clos Network-on-Chip for Neural Networks[J].IEEE Transactions on Compute rs,2017,66(11):1865-1877.
