互聯網軟件錯誤日志聚類
2018-07-05 07:29:02程世文王長進
小型微型計算機系統 2018年5期
關鍵詞:信息
程世文,裴 丹,王長進
1(清華大學 計算機系,北京 100084)2(北京小桔科技(滴滴出行)有限公司,北京 100193)
1 引 言
互聯網服務已經深入到用戶生活的方方面面,用戶對互聯網服務體驗的要求越來越高,這正是互聯網內容提供商所面臨著的巨大的挑戰.互聯網內容提供商在實際運營過程中,所維護的各項服務業務隨時可能會遇到各種各樣的問題,這就需要收集相應的日志,并對錯誤日志進行分析和處理.因此,將問題對應的錯誤日志及時反饋給相應的研發人員是排除問題的首要因素.
在互聯網內容提供商收集日志的過程中,即使采用采樣的方式,收集到的日志的數量也是十分巨大的,往往也是以TB甚至PB為單位.并且,很多錯誤日志是完全相同或者相似的,錯誤日志的不同種類僅占極少數.僅以錯誤日志舉例,本文研究的某互聯網公司每天采樣收集到的錯誤日志量約10-20TB,但其中錯誤日志的不同種類只占到了400-800種左右.將如此巨大數量的錯誤日志直接反饋給研發人員進行逐條人工排錯,顯然是不可行的.因此,對海量錯誤日志進行預先聚類則顯得非常重要.
在實際收集的錯誤日志中,往往具有如下挑戰:
1)日志數量巨大;
2)格式不規范,變量較多,無法全部清洗;
3)干擾數據較多,較難提取特征信息;
4)聚類效果、性能要求較高,難度較大.
在日志聚類方面,國內外的一些研究學者也進行了不少的研究與應用.Xu[1]等人提出了對控制臺日志(Console logs)的預處理,但這些日志是形如“starting:xact (.*)is (.*)”的模板日志,非常規范且種類有限,通過相應的正則表達式即可匹配識別.Qiu[2]等人設計并實現了SyslogDigest系統,提出了對路由設備的syslog的壓縮和提取算法,通過進行詞頻統計分析構建出syslog的模板樹,模板樹中根節點到葉節點的所有路徑就是syslog的模板,也即所有syslog的種類.但syslog詞數有限、日志規范、易模板化,不適應中文,且同一類型下不同形式的日志不能通過該算法區分.
在特征提取方面,目前常用的方法是基于統計的特征選擇方法,包括信息增益方法(IG)、互信息方法(MI)、開方擬合檢驗方法(CHI)、文檔頻率方法(DF)等[3,4].文檔頻率方法與其它方法比較,算法實現簡單、復雜度低,且效果、性能相差不多[5].楊凱峰等[6]實驗結果表明,在進行特征選擇時,高詞頻特征詞對類別的貢獻可提高傳統DF方法的分類性能.
針對以上提到的問題,本文提出互聯網軟件錯誤日志聚類方法.該方法通過引入日志模板提取、日志壓縮方法降低日志規模;通過引入計算文檔頻率提取特征詞方法提高聚類準確性并降低數據維度;結合Canopy聚類和K-means聚類算法提升聚類效果.本文的聚類方法有效地解決了實際運維中海量非規范日志的聚類問題,并在某互聯網公司中進行了實際驗證.
2 錯誤日志介紹
互聯網公司運維部門一般需要將從各個業務收集上來的海量錯誤日志進行聚類處理,將聚類結果及時反饋給相應業務的研發人員,用于排除業務中存在的問題,從而及時止損.本文研究的公司為一個在中國領先的移動出行公司,日訂單量1000萬以上.
2.1 錯誤日志信息
該公司中的日志格式示例如下:
[日志級別][時間戳][擴展區域] 日志信息
其中日志級別用于區分不同的日志類別(嚴重程度),包括FATAL、ERROR、WARNING、INFO、DEBUG,錯誤日志則是日志級別為FATAL、ERROR或WARNING的日志.擴展區域用于自定義,作為擴展字段,可以打印一些用于調試的必要信息等.日志信息記錄了日志的具體信息,如運行時信息、參數信息、狀態信息等.
本文中,錯誤日志的日志信息簡稱為錯誤日志信息,因此,對錯誤日志聚類即是對錯誤日志信息聚類.錯誤日志信息舉例如表1所示.
2.2 錯誤日志分類
由于實際研發過程中并沒有完全統一日志信息規范,所以收集的日志信息形式可能千差萬別并且無法預期.由表1示例,錯誤日志主要分為三類:
1)常量型,如編號1、2、3;
2)變量型,如編號4、5,含少數不重要的變量,比如進程號;
3)任意型,如編號6、7、8、9,常為非規范的、無法預期的結構形式.
2.3 聚類挑戰
由于公司業務的快速發展,帶來日志量急速增長,同時相應的日志規范沒有跟上,以及研發人員素質參差不齊,導致收集的錯誤日志不規范、干擾數據較多.這些都給錯誤日志聚類帶了巨大的挑戰:
1)日志數量巨大
某互聯網公司某運維場景下錯誤日志的收集數量約為150萬條每分鐘,大小約3.3GB每分鐘;以此推算,相應的數據為9000萬條每小時,200GB每小時;21.6億條每天,2.4TB每天.
2)變量較多,無法全部清洗
錯誤日志信息中的變量名、變量名與變量間的格式無法預知,且變量較多,無法通過清洗變量來分析出所有的錯誤日志模板.

表1 某互聯網公司某運維系統下的錯誤日志信息示例Table 1 Error log message examples in an operation system of an Internet company
3)干擾數據較多,難以提取特征信息
錯誤日志信息可能包含如token、id、key、ticket、等md5、base64編碼的干擾數據,此外還有中文、Unicode等干擾,對提取錯誤日志的特征信息造成了很大的難度.
4)聚類效果、性能要求較高,難度較大
對海量非規范的錯誤日志進行聚類,要達到聚類效果較好、性能較高,并且需要經得起公司運維系統的實際驗證,難度較高.
3 解決思路
本文提出,對幾個不同時間段內的錯誤日志數據(每個時間段時間跨度約30分鐘,數量約4500萬條,大小約100GB),分別進行聚類分析,對所有聚類結果計算平均頻度占比,可以得到如下結果:
1)錯誤類別總數約270個;
2)將錯誤類別的頻度由高到低排序,前80個錯誤類別的頻度較高,高于100,長尾的是頻度較低的錯誤類別;
3)前5個錯誤類別的平均占比總和約為57.1%,前10個錯誤類別的平均占比總和約為68.5%,前15個錯誤類別的平均占比總和約為74.2%,如圖1所示.
因此,在短時間內出現的錯誤類別總數較少,同時容易出現大量相同類別的錯誤日志,且頻度較高.
針對前述挑戰和以上錯誤日志特點,本文提出解決思路如下:
1)日志數量巨大
由于錯誤類別總數較少,可以將完全相同或較為相似的錯誤日志進行壓縮合并.常量型的日志可以直接壓縮合并,而變量型和任意型的日志則需要進一步進行清洗處理,提取出日志模板后才能繼續壓縮合并.

圖1 前15個錯誤類別平均頻度占比圖Fig.1 Average frequency ratio of the top 15 error categories
2)變量較多,無法全部清洗
通過對錯誤日志中的變量進行清洗替換處理,可以提取相應的日志模板.提取模板可以大大減少變量對聚類的干擾,但模板中仍然可能存在著無法預期的變量,這個問題可以通過后續特征詞提取來減少甚至避免這類變量造成的聚類干擾.模板提取后再進行日志壓縮,將會得到更好的壓縮效果.
3)干擾數據較多,難以提取特征信息
由于同種類別的錯誤日志在某些特征信息上表現相同或者較為相似,而不同類別的錯誤日志的特征信息則表現完全不同或者相差較大.因此,可以根據特征信息來對錯誤日志進行聚類.由于一條錯誤日志中可能包含干擾的數據項,如變量,它們并不能表征錯誤日志的特征信息,所以不能采用日志的所有信息作為它的特征信息.
本文采用基于文檔頻率的統計方法,來提取日志模板中的特征詞,并用特征詞來表征錯誤日志的特征.其核心思想為:在所有日志中出現頻率越高的詞,越能表征該詞所在日志的類別特征;而在所有日志中出現頻率越低的詞,如變量,則表征日志的類別特征的可能性越低.
然后使用提取的特征詞來建立向量空間模型(Vector Space Model,VSM)[7],從而確定特征向量,并用特征向量來表征錯誤日志的特征.提取特征詞可以有效地減少建立向量空間模型的維度,從而降低計算復雜度.
4)聚類效果、性能要求較高,難度較大
通過日志模板提取、日志壓縮,可以大大減少日志的數據規模.通過文檔頻率的方法來提取日志模板的特征詞,建立特征向量,不但能很好地表征錯誤日志的特征,而且降低了數據維度.
對特征向量進行聚類,采用經典的K-means聚類算法[8],其原理簡單,計算時間短,速度快,聚類效果較好,但需要確定K值和K個初始質心,這里事先采用Canopy聚類算法[9].Canopy聚類算法是無監督的預聚類算法,通常用于K-means算法或層次聚類算法之前的處理階段.相對于傳統的聚類算法,Canopy聚類算法不需要事先指定聚類的個數(如K-means的K值),并且在大規模的高維度數據上速度較快,在實際工程中有很大的價值及優勢.其缺點是聚類精度較低,準確度不高.
因此,可以使用Canopy聚類算法進行粗聚類,得到的聚類數和聚類中心作為K-means的K值和初始質心.這樣可以有效地確定合理的K值,同時可以避免K個初始質心選擇的不合理導致對聚類結果產生較大的影響.
通過上述方法,錯誤日志聚類可以很好地達到聚類效果較好、性能較高的要求.
4 系統架構與實現
4.1 系統架構
錯誤日志聚類系統架構如圖2所示.
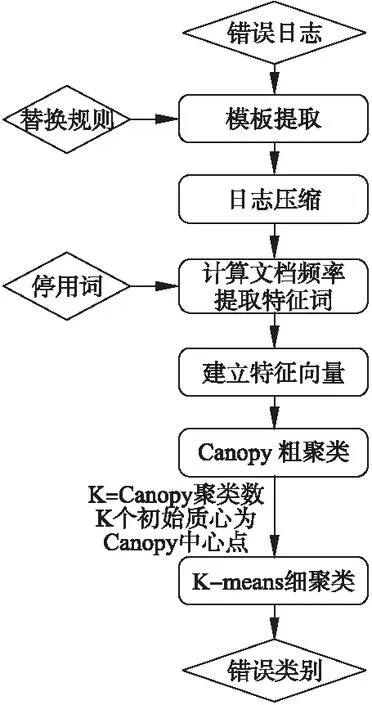
圖2 錯誤日志聚類系統架構圖Fig.2 System architecture of the error log clustering
該系統架構由錯誤日志(數據輸入)、模板提取、日志壓縮、計算文檔頻率提取特征詞、建立特征向量、Canopy粗聚類、K-means細聚類、錯誤類別(結果輸出)組成,各個功能如下:
1)錯誤日志:錯誤日志數據輸入端,每條數據為一條錯誤日志信息.
2)模板提取:根據替換規則,清洗替換掉錯誤日志中不相關、不重要的變量和干擾項,進而提取出日志模板.替換規則可由人工進行配置.
3)日志壓縮:對提取后的日志模板中大量完全相同的模板進行去重壓縮,輸出相應的日志模板條數.
4)計算文檔頻率提取特征詞:使用文檔頻率方法提取出每條錯誤日志模板的一些特征詞,用來表征相應錯誤日志的特征信息.
5)建立特征向量:將所有錯誤日志模板提取出來的特征詞合并成一個集合,其中每一個元素構成向量空間的一個維度,建立向量空間模型,從而每條錯誤日志可以由提取出來的特征詞確定相應的特征向量.
6)Canopy粗聚類:使用Canopy聚類算法先對數據進行粗聚類,得到聚類數和聚類中心后再使用K-means聚類算法進行進一步細聚類.
7)K-means細聚類:取K=Canopy聚類數,并且選擇Canopy粗聚類后的K個中心點作為K個初始質心,使用K-means聚類算法進行細聚類.
8)錯誤類別:錯誤類別數據輸出端,每條數據為一種聚類類別,及其對應的原錯誤日志樣本和錯誤日志數量.
4.2 系統實現
4.2.1 模板提取
根據給定的替換規則,對錯誤日志進行清洗替換,提取出日志模板.替換規則越多,則提取后的錯誤日志模板的質量更好,干擾項數據更少.以下給出部分初始的替換規則,基于正則表達式進行依次替換,如表2所示.

表2 部分初始的替換規則Table 2 Part of the initial replacement rule
例如,“the request url is http://example.com/test”提取的日志模板為“the request url is
4.2.2 日志壓縮
本文采用的壓縮條件為提取后的日志模板完全相同,日志壓縮的實現算法如下:
算法1.日志壓縮算法
輸入:提取后的日志模板列表LOGS
輸出:壓縮后的日志、統計條數鍵值對MLOGS,其中每個條目為
1)MLOGS= HashMap()
2)for log in LOGS:
3)if MLOGS has key log:
4)MLOGS.set(log,MLOGS.get(log)+ 1)
5)else:
6)MLOGS.set(log,1)
4.2.3 計算文檔頻率提取特征詞
本文中,每條錯誤日志模板都視作一篇文檔,每篇文檔進行分詞后都會得到若干詞,其中一些詞可以表征類別特征,它們對聚類有貢獻;另外一些詞,則不能表征類別特征,它們會干擾聚類.因此,應對這些分詞根據一定特征進行選擇,選擇的分詞作為特征詞來表征錯誤日志的類別特征,即從原始的分詞中選取一個子集,將干擾大、表征信息少、不重要的分詞移除,從而得到特征詞集合.對一個特征詞,統計該詞的文檔頻率,即包含該詞的文檔數,則文檔頻率越大,說明該詞越能表征某種類別特征.所以,出現的文檔數越多的分詞被留作特征詞的可能性越大.在文檔頻率方法中,將每篇文檔進行分詞,根據分詞的文檔頻率對分詞進行排序,保留文檔頻率高的前若干個分詞構成特征詞集合.
實際聚類過程中,可能遇到一類詞,其出現次數較多,可能在一部分類別中都會出現,但對聚類幾乎無貢獻、沒有較大的表征意義,如“a”“X”“2”等,其被稱作為停用詞(Stop Words)[10].在提取特征詞過程中,需要對停用詞進行過濾.停用詞支持運維人員調整修改,初始的停用詞為數詞和單字母詞.
計算文檔頻率提取特征詞算法如下:
算法2.計算文檔頻率提取特征詞
輸入:壓縮后的日志、統計條數鍵值對MLOGS
輸出:日志、特征詞鍵值對FWS,其中每個條目為
1)// 分詞、過濾停用詞
2)SWS = HashMap()// Split Words
3)for
4)words = split_words(log)
5)words = unique(words)
6)words = remove_stop_words(words)
7)SWS.set(log,words)
8)// 計算文檔頻率
9)DF = HashMap()// Document Frequency
10)for
11)words = SWS.get(log)
12)for word in words:
13)if DF has key word:
14)DF.set(word,DF.get(word)+num)
15)else:
16)DF.set(word,num)
17)// 提取特征詞
18)FWS = HashMap()// Feature Words
19)for
20)words = SWS.get(log)
21)features = calc_top10_df_words(words)
22)SWS.set(log,features)
4.2.4 建立特征向量
提取出所有錯誤日志模板的特征詞后,設所有特征詞的集合為S={fw1,fw2,…,fwn},并依次構成n維向量空間的各個維度,則對于錯誤日志L及其特征詞集合FWL,其特征向量定義為
VL=[v1,v2,…,vn],其中
所有錯誤日志的特征向量構成特征向量集合D.
4.2.5 Canopy聚類
Canopy聚類算法需要首先設定兩個閾值T1(松散距離),T2(緊湊距離),要求T1 > T2;然后計算數據點之間的距離,會將距離相接近的數據點放入到一個子集中,這個子集被稱作Canopy;最后通過一系列計算得到若干個Canopy,Canopy之間可以重疊,但不會存在某個數據點不屬于任何Canopy的情況.
使用Canopy算法聚類后,結果如圖3所示.

圖3 Canopy聚類結果圖Fig.3 Result of Canopy clustering
其中,T1過大,則會導致較多的迭代次數,形成較多的Canopy;T1過小則效果相反.T2過大,則會導致一個Canopy中的數據較多;T2過小則相反.由于本文使用Canopy聚類算法僅進行粗聚類,即計算出Canopy聚類數,用作下游K-means聚類算法的K值,所以聚類精度要求不高,實際工程中設定T1=2*T2,T2初始值為2.
4.2.6 K-means聚類
K-means聚類算法需要首先設定K值,從數據集中選定K個點作為最初的質心;然后將D中的每個數據劃分到離質心最近的簇中,形成K個簇,并重新計算每個簇的質心;重復上述過程,直到簇不發生變化.
在K-means聚類算法中,取K=Canopy聚類數,并且選擇Canopy粗聚類后的K個中心點作為K個初始質心.
5 評 估
5.1 效果評估
由于聚類沒有統一的評價指標,并且錯誤日志數據量巨大,無法事先人工標注,目前只能根據實際問題和場景,由相應的領域專家和工程師對聚類之后的結果進行確定和評價.

表3 聚類效果部分結果Table 3 Part results of clustering effect
本文經過一段時間對聚類類型和相應的樣本進行了評估,合作的領域專家和工程師認為聚類有效且達到比較理想的效果.某個時間段里聚類效果部分結果如表3所示.
其中類別是聚類類別的編號,總數是這一時間段中相應的錯誤日志總數,日志模板即為提取的日志模板信息.例如,錯誤類別11、日志模板為“stop pay fail ret_info errno errmsg”的一個日志樣例為“errno:80051 errmsg:stop pay fail | ret_info:{″errno″:″80051″,″errmsg″:″\u5173\u5355\u5931\u8d25″}”;錯誤類別12、日志模板為“Warning getBillInfo empty orderId passengerId”的一個日志樣例為“Warning:getBillInfo empty|orderId:3267678|passengerId:159631166”.
5.2 性能評估
本地測試所用硬件環境為一臺雙核i5-3337U,1.80GHz,4GB內存的筆記本電腦,操作系統為Windows 10,所使用的語言為Java和Python2.7.
5.2.1 模板提取性能
語言為Java,部分測試結果如表4所示,在幾個不同場景下的測試結果中,處理速度達到7.31-9.91萬條每秒.處理速度跟日志信息具體內容有較大關系,每條日志信息越長則處理速度較慢,每條日志信息越短則處理速度較快.
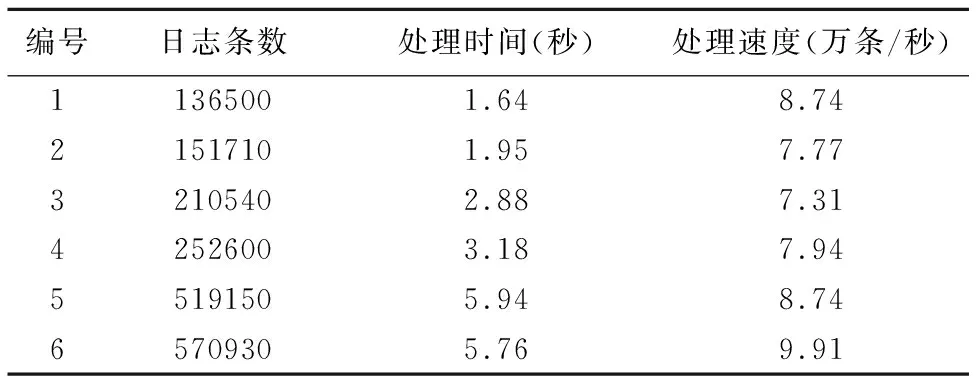
表4 模板提取性能Table 4 Performance of template extraction
5.2.2 日志壓縮性能
語言為Java,部分測試結果如表5所示,在幾個不同場景下的測試結果中,壓縮比達到342.1-1095.8,處理速度達到40.33-85.47萬條每秒.壓縮比跟日志條數大致呈現正相關,即壓縮比隨著日志條數增加而增大.這表明在短時間內錯誤類別數量維持在一定水平,日志條數大幅增加不會使得錯誤類別數量急劇上升.
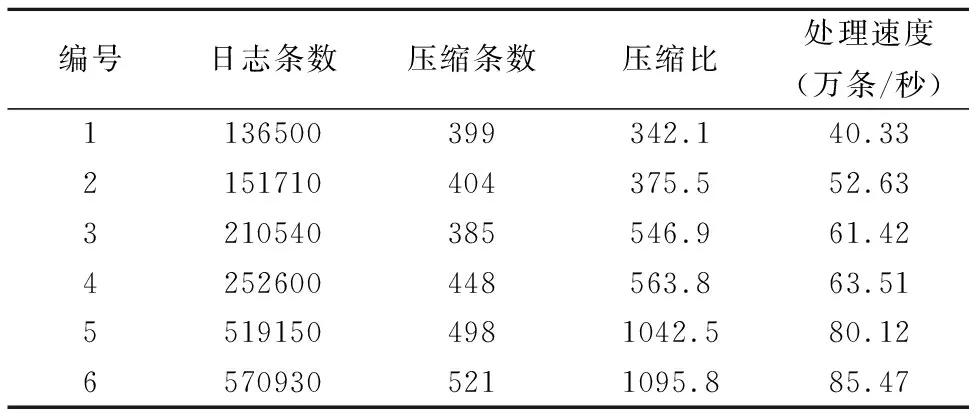
表5 日志壓縮性能Table 5 Performance of log compression
5.2.3 Canopy粗聚類性能
語言為Python2.7,部分測試結果如表6所示,其反映了不同壓縮條數和向量維度下Canopy的處理時間.壓縮條數越大、向量維度越高,處理時間越長.
5.2.4 K-means細聚類性能
語言為Python2.7,使用scikit-learn機器學習庫中的K-means聚類算法,部分測試結果如表7所示,其反映了不同壓縮條數和向量維度下K-means的處理時間.壓縮條數越大、向量維度越高,處理時間越長,但遠遠優于Canopy粗聚類處理時間.
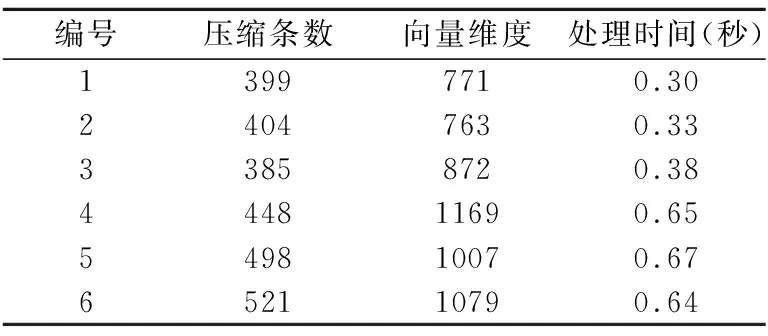
表6 Canopy粗聚類性能Table 6 Performance of Canopy clustering
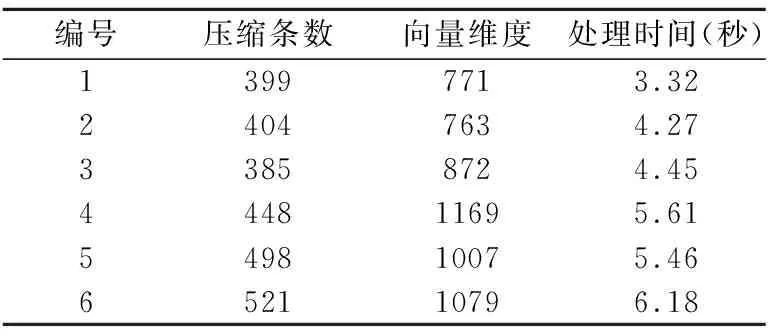
表7 K-means細聚類性能Table 7 Performance of K-means clustering
5.2.5 整體系統性能
實際生產環境中的性能要遠優于本地單機硬件環境.在某互聯網公司某子系統下錯誤日志量產生速度約為2萬條每秒,壓縮后處理時間完全滿足性能要求.
6 結 語
在互聯網公司對海量非規范的錯誤日志進行聚類的過程中,往往會遇到幾大挑戰:
1)日志數量巨大;
2)變量較多,無法全部清洗;
3)干擾數據較多,難以提取特征信息;
4)聚類效果、性能要求較高,難度較大.
針對上述挑戰,本文提出了互聯網軟件錯誤日志聚類方法,通過引入日志模板提取、日志壓縮方法降低日志規模;通過引入計算文檔頻率提取特征詞方法提高聚類準確性并降低數據維度;結合Canopy聚類和K-means聚類算法提升聚類效果.通過在某互聯網公司運維中實際系統的檢驗,本文提出的錯誤日志聚類方法,不但具有比較理想的聚類效果,而且滿足生產環境中的性能要求.
:
[1] Xu W,Huang L,Fox A,et al.Detecting large-scale system problems by mining console logs[C].Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles,ACM,2009:117-132.
[2] Qiu T,Ge Z,Pei D,et al.What happened in my network:mining network events from router syslogs[C].Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement,ACM,2010:472-484.
[3] Galavotti L,Sebastiani F,Simi M.Experiments on the use of feature selection and negative evidence in automated text categorization[C].European Conference on Research and Advanced Technology for Digital Libraries,Springer-Verlag,2000:59-68.
[5] Shan Song-wei,Feng Shi-cong,Li Xiao-ming.A comparative study on several typical feature selection methods for Chinese web page categorization [J].Computer Engineering and Applications,2003,39(22):146-148.
[6] Yang Kai-feng,Zhang Yi-kun,Li Yan.Feature selection method based on document frequency[J].Computer Engineering,2010,36(17):33-35.
[7] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[8] MacKay,David.Chapter 20.an example inference task:clustering[M].Information Theory,Inference and Learning Algorithms,Cambridge University Press,2003:284-292.
[9] McCallum A,Nigam K,Ungar L H.Efficient clustering of high-dimensional data sets with application to reference matching[C].Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2000:169-178.
[10] Rajaraman A,Ullman,J D.Data mining[M].Mining of Massive Datasets,2011:1-17.
附中文參考文獻:
[5] 單松巍,馮是聰,李曉明.幾種典型特征選取方法在中文網頁分類上的效果比較[J].計算機工程與應用,2003,39(22):146-148.
[6] 楊凱峰,張毅坤,李 燕.基于文檔頻率的特征選擇方法[J].計算機工程,2010,36(17):33-35.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
