基于K V M虛擬化平臺的輕量級H A機制研究
2018-07-04 06:34:42四川中電啟明星信息技術有限公司研發中心佘文魁田富強
電子世界 2018年12期
四川中電啟明星信息技術有限公司研發中心 佘文魁 袁 亮 田富強 喻 梅
1 引言
如今,虛擬化成為一種成熟的技術,允許用戶創建自己的私有云,并為許多領域的網絡服務提供虛擬機(VM)。由于云上的計算節點通常執行多個虛擬機,否則任何崩潰計算節點的故障可能會導致一組虛擬機失敗。這意味著計算設備的可靠性在云時代比以往任何時候都更加重要。因此,有必要使用基于軟件的高可用性(HA)機制來保護計算節點上的虛擬機。
2 相關技術
A.QEMU和KVM
QEMU 是可以的軟件組件模擬硬件設備,由FabriceBellard編寫。因為它通過軟件模擬CPU,性能有限。為了提高QEMU的性能,新版本的QEMU通常帶有KVM,通常稱為“QEMU-KVM”。KVM(基于內核的虛擬機)是一個開源項目;它是Linux x86硬件的完全虛擬化解決方案。目前,KVM還與QEMU-KVM一起運行,這是一個特殊版本的QEMU。為了提高速度,QEMU-KVM使用不同的方法來模擬CPU。QEMU-KVM將通過KVM模塊將由VM生成的所有CPU指令發送到實體CPU,以運行。
B.Libvirt
Libvirt用于在使用虛擬化技術時解決各種管理不便問題。它支持多種虛擬機管理程序,如KVM,Xen和VMware ESX。它還為各種語言(如C,Python和Java)提供遠程過程調用。使用遠程API,系統管理員可以輕松地控制另一個計算節點上的虛擬機。
Libvirt通常用于管理KVM的虛擬機,其中Libvirt可以創建通信通道以連接到計算節點上的KVM監視器。通過此通道,Libvirt可以向VM發送命令。此外,當VM進程意外關閉時,節點操作系統還可以向Libvirt守護程序發送錯誤消息。
C.相關高可用技術研究
許多商業服務器虛擬化軟件,軟件包支持高可用性功能。例如,VMware ESXi也在其設計中采用集群管理的概念。 VMware ESXi使用心跳作為主要的故障檢測方法。如果主HA服務器在給定時間段內無法從VM接收心跳線,則主服務器將嘗試驗證VM是否正忙于在VMware ESXi群集的數據存儲服務器中執行I / O。如果答案為否,主HA服務器將會觸發恢復過程。
3.系統設計與實現
LW-HA的基本原理與流程如圖1所示,控制端對HA的檢測與處理各個環節均采用事件監聽方式,可支持大規模并發故障處理。這里采用瞬時事件觸發和任務輪循并行的方式,即保證檢測與恢復的時間最小化,同時又能保證各個環節失敗后能自動重試。多點并發啟動時,虛擬機啟動采用“排它鎖”,確保誰優先搶到虛擬機啟動鎖,由誰執行啟動操作,避免兩線程同時執行虛擬機啟動引起腦裂。

圖1 HA總體流程圖
計算節點在采集主機注冊信息時,將所有網卡設備信息緩存起來。檢測時從緩存中遍歷所有已配IP的網卡信息,采用命令“ethtool網卡設備名”檢測,從輸出結果中找到link detected 項的值,如果非”yes”(忽略大小寫)則判定為連接中斷。計算節點在通信異常時,通過向探測ip清單中所有ip發起通信請求來確認自身是否已成為通信孤島。
為了提升虛擬機的可用性,減少虛擬機服務停機時間,系統將檢測并在盡可能短的時間內將服務中斷的虛擬機恢復運行。LW-HA主要對以下六類場景進行設計與實現,如表1所示。

表1
通過對場景的共性進行分析,實際上是解決兩類問題,一是虛擬機宕機;二是資源池斷電。
3.1 虛擬機宕機
(1)前置條件
控制節點及服務運行正常,通信正常。
宿主機運行正常,通信正常。
(2)故障認定
虛擬機宕機認定條件為,同時符合以下四個條件:
主機心跳均正常情況下,主機前一次心跳信息中某虛擬機domain存在,本次主機正常心跳情況下該虛擬機domain不存在。
數據庫中記錄的宿主機仍為當前主機(排除剛遷移成功或遷移失敗,已解鎖)。
虛擬機為運行狀態(排除剛強制關機成功,已解鎖)。
虛擬機未被鎖定為“停止中”或“跨主機遷移中”(排除正在停止或正在跨主機遷移)。
(3)調度流程(如圖2所示)

圖2 主機宕機HA流程圖
3.2 資源池斷電
(1)前置條件
控制節點已啟動,控制服務已運行,通信正常。
虛擬機原宿主機已啟動,并已成功發送心跳至
控制節點。
(2)故障認定
資源池斷電后,數據庫中仍然保存有虛擬機的運行狀態與宿主機信息,當數據庫和控制節點啟動后,由控制節點周期性輪循檢測關系在宿主機上,但無心跳的虛擬機。
(3)調度流程(如圖3所示)

圖3 資源池斷電HA流程圖
以上就是LW-HA的原理及針對典型場景的分析與實現。下一節將通過實驗驗證該方案。
4.測試結果分析
測試環境:
分別使用3臺物理機部署VMware ESXi6.0與LW-HA系統,主機配置信息為IBM3550環境,雙Intel(R) Xeon(R) CPU E5-2640 V3 @2.60GHz,共32核,內存64G;虛擬機配置信息為4vcpu,4G內存,虛擬機gustos統一為centos7.1mini。
測試場景一:
在兩套系統中創建并運行單臺虛擬機,通過系統命令強制關閉,模擬虛擬機故障關閉場景。
測試場景二:
在兩套系統中某一主機上創建并運行8臺虛擬機,通過對運行虛擬機的主機掉電的方式模擬主機故障。
通過日志記錄虛擬機恢復時間間隔,對兩種場景進行10次測試采樣。
測試結果如下圖4,5所示:

圖4 單臺虛擬機HA測試記錄
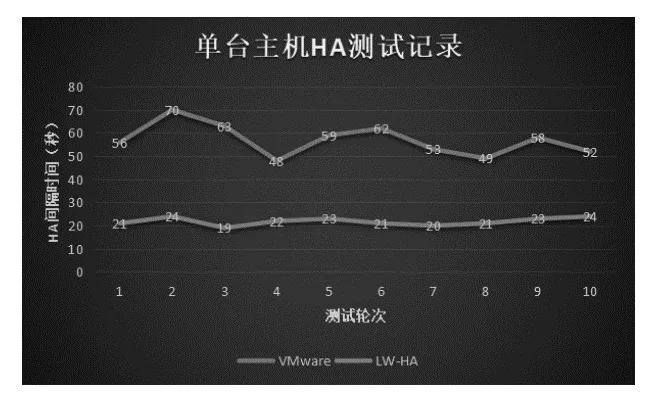
圖5 單臺主機HA測試記錄
可以看到單臺虛擬機HA間隔時間VMware平均4.1秒,LW-HA平均間隔2.4秒;單臺主機HA間隔時間VMware平均57秒,LW-HA平均間隔21秒。可以看到LW-HA方案對比VMware具有同樣的穩定性和更高的敏感度。
5.結論
本文在KVM虛擬化平臺上,提出一種輕量級的高可用機制(LW-HA),并給出了在不同場景下的實現原理與機制,最后通過實驗得出該LW-HA機制在虛擬機宕機恢復及宿主機宕機虛擬機恢復方面均優于商業軟件,是一種完美替換商業軟件HA的方案,也可以為虛擬機故障恢復機制方面提供一些參考。
[1]KVM官方網站[OL] http://www.linux-kvm.org/page/Main_Page.
[2]QEMU官方網址[OL] http://wiki.qemu.org/Main_Page.
[3]復旦大學并行處理研究所著.系統虛擬化[M].北京:清華大學出版社,2009
[4]倪華婓.虛擬化技術下高可用大規模集群系統HARing的設計和實現,浙江大學,2012.
[5]耿新民,王少峰,許飛.基于VMware的高可用性集群在電力信息系統中的應用[J].上海電力學院學報,2010,26(2):193-196.
[6]熊夢,楊松,莫展鵬等.一種虛擬機高可用機制:,CN 103729280 A[P].2014.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
