改進Adaboost下BP神經網絡并行化訓練方法
2018-07-04 13:12:18吳正江陳如校張霄宏
小型微型計算機系統 2018年5期
關鍵詞:實驗
吳正江,陳如校,張霄宏
(河南理工大學 計算機科學與技術學院,河南 焦作 454003)
1 引 言
人工神經網絡被廣泛應用于模式識別和數據挖掘領域,例如圖像信號處理[1],語音識別等.BP神經網絡是目前各個領域使用的最廣泛的人工神經網絡之一,能夠通過學習,無限接近任意曲面的邊界而無需事先知道具體的數學方程[2].
早期,BP神經網絡的訓練都是在單機下進行.隨著數據的增大,單機下的訓練變得越來越耗時,可能需要幾天,一周甚至無法完成模型的訓練.因此,提高BP神經網絡面向大規模數據集時的訓練速度,具有重要的意義[3].
并行化是解決上述問題的方案之一.基本上BP神經網絡的并行化有兩種方式:結構并行化與數據并行化.在結構并行化時,將BP網絡結構中的各個節點映射到集群中的各個節點上.這種方式的缺點是各個節點之間頻繁的進行通信協調,只適用于小數據量的復雜神經網絡的并行化.而在數據并行化方式下,整個數據集被切分成各個小的子數據集,由集群中的各個子節點并行處理屬于自己的那部分子數據集.同時,在訓練過程中存在兩種對連接權值進行更新的模式:逐個更新和批更新.在逐個更新模式下,神經網絡每讀取一個樣本進行處理之后便對網絡連接權值進行更新;而在批更新模式下,在所有的數據處理一遍之后再一次性對權值進行更新.
隨著近些年大數據平臺Hadoop的普及,基于Hadoop平臺下的BP神經網絡并行化得到了很大的發展.目前大多數在Hadoop下實現的對BP神經網絡并行化的研究都采用數據并行化下的批更新操作[4-10].其中[4]通過對大規模移動數據的分類,采用Adaboost算法對BP神經網絡進行優化,實現了BP神經網絡的并行化,[5,6]通過對[4]中提出的MBNN算法訓練過程中產生過多的中間結果問題通過添加combiner函數,減少中間結果來加快網絡的訓練速度.[7,8]分別通過在進行經典的BP算法之前利用遺傳算法,深度信念網絡對BP神經網絡的連接權值的初始化進行優化,加快BP神經網絡的收斂速度.
然而上述均采用Hadoop來對BP神經網絡進行并行化實現,由于Hadoop是基于磁盤的,因而在訓練反復迭代過程中,每一次迭代都需要讀取磁盤上保存上次迭代結果的信息.[7,9,10]對上述問題進行了一定程度的改善,通過在Mapper階段根據局部數據訓練得到局部收斂的BP神經網絡后,在Reducer階段再進行不同策略的整合.雖然[7,9,10]對迭代過程中讀取磁盤進行了一定程度的優化,但還是避免不了多次讀取磁盤,且由于BP神經網絡容易陷入局部最優解的問題使得最終得到的BP神經網絡結構正確率不一定達到要求.
本文提出的方法在[4]中MBNN的基礎之上,對[4]方法中采用的Adaboost算法進行改進,以使Adaboost算法更好的與BP神經網絡算法進行結合,同時采用同樣基于MapReduce思想實現的基于內存的Spark平臺進行算法實現.最后實驗結果表明在保證正確率的情況下,本方法更優于[4]中提出的MBNN算法且縮短了算法訓練時間.
2 神經網絡算法
人工神經網絡(Artificial Neural Network,ANN),是在模擬生物神經網絡的基礎上構建的信息處理系統,具有強大的信息存儲和處理能力.至今已開發出了一系列的算法的不同分支,其中以反向傳播網絡,即BP神經網絡模型應用最為廣泛.BP算法以其良好的非線性逼近能力,泛化能力以及實用性成為了人工神經網絡訓練算法中應用最為廣泛的算法.BP神經網絡算法的基本思想是重復的使用鏈式法則計算出每一個網絡權值對網絡最后的結果誤差E的影響:
(1)
這里wij表示神經元j與神經元i的連接權值,si是輸出,neti是神經元i的加權和.一旦求出所有的權值的偏導數,就可以通過簡單的權值下降法讓誤差取得最小值:
(2)
通過公式(2)不斷迭代網絡連接權值,最終達到終止條件,得到收斂的分類器.
3 Adaboost算法
Adaboost[11]的結構如下所示:
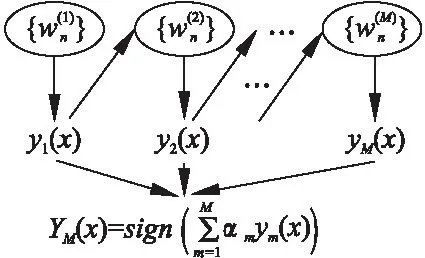
最后的分類器YM由多個弱分類器聯合組成.相當于M個弱分類器聯合決定樣本屬于哪個類,而且每個弱分類器的重要性αm不同.具體過程如下:
1)初始化所有樣本的權重w1,i為1/N,其中N為樣本總數.
2)對于1到M個弱分類器 do
a)訓練弱分類器ym,使其最小化權重誤差函數
(3)
其中tn為樣本所屬真正的類別.
b)計算出該弱分類器的重要性αm
(4)
c)更新樣本的權重wm+1,i
(5)
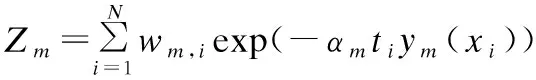
3)得到最后的分類器
(6)
在上述Adaboost算法中,每產生一個弱分類器ym之后,對樣本權值進行更新,并通過抽樣的方式對樣本進行抽樣,得到新的樣本來訓練新的弱分類器ym+1.
4 基于改進Adaboost的BP神經網絡算法
在上述Adaboost過程中,存在一個嚴重的問題:當處理的數據量變得非常大的時候,每次訓練得到一個弱分類器后,得出訓練下一個分類器所需要的樣本變得十分的耗時困難.
本文中,將BP神經網絡作為基分類器進行訓練,并且采用批更新對網絡連接權值進行更新.在訓練得到ym分類器后,不進行抽樣過程.而是通過(5)對每個樣本的權重進行更新,得到每個樣本都帶有權值wm+1,k的一個樣本集合.在對ym+1這個分類器進行訓練的時候,對樣本集合中的每一條數據代入上一次得到的BP神經網絡中,計算出每一條記錄對相應的BP神經網絡連接權值更新值Δwij,通過下式算出每一條連接總的權值更新值:
(7)
通過將(7)式計算出來所有的樣本加權后的BP網絡連接權值的更新值對BP神經網絡進行更新.
在這一過程中,由于省去了抽樣的過程,大大提高了最終分類器YM的訓練時間.
5 Spark
Spark*http://hadoop.apache.org.是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用并行框架.Spark有Hadoop幾乎所有的優點,并且在處理過程中,中間結果不是寫入到磁盤上而保留在內存中,非常適合于頻繁迭代算法的設計,運行原理圖如圖1所示.
在Spark集群運行期間,應用程序提交后,Client端初始化并構建SparkContext對象,由SparkContext與集群資源管理者master取得聯系,注冊程序并申請所需資源:CPU和core,即Executor.Executor接收資源管理者的命令從文件系統中讀取數據形成RDD[12]并進行處理,Executor可以并行運算,運算的邏輯一樣,但處理的數據不一樣.在SparkContext初始化的過程中生成了DAGScheduler對象和TaskScheduler對象,DAGScheduler根據shuffledependency將應用程序分割成一個個的stage,每一個stage包含一個或者很多個task,這
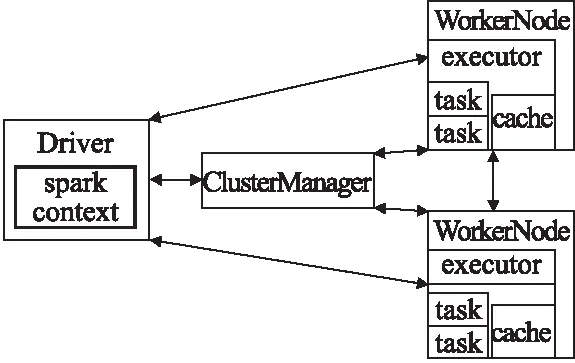
圖1 Spark工作原理Fig.1 Spark works
些task之間可以進行并行執行,而所有的stage順序運行.接著,SparkContext將應用程序的代碼廣播給每個Executor,同時SparkContext根據數據本地性和每個處理機的處理能力將任務分配給每個Executor,之后Executor開始執行分配給自身的任務.
6 算法并行化
Spark采用典型的master-worker并行模式,一般擁有一個master節點和多個worker節點,即計算節點.Master節點協調整個訓練任務的執行,而訓練的實際執行者為很多個worker節點.在運行之前訓練集被切分成很多個block存儲在分布式文件系統HDFS上.每個計算節點根據數據本地性讀取屬于自己的那部分block進行獨立訓練誤差,具體的并行算法實現偽代碼如下:

具體算法過程和流程圖如下:
1)程序提交后主進程進行初始化,通過SparkContext.textFile()函數從分布式文件系統HDFS中依據Spark自身具有的數據本地性讀取訓練所需的數據形成RDD;
2)通過調用RDD.map(string2Tuple(_))方法將讀取進來的每行記錄轉換成BP網絡訓練時需要的輸入格式.其中string2Tuple方法封裝了對于每一條記錄的解析業務邏輯;
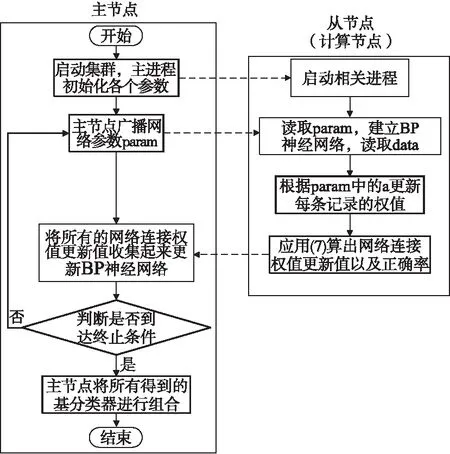
圖2 數據并行BP算法流程圖Fig.2 Data parallel BP algorithm flow chart
3)將BP網絡訓練連接權值wij,αt等參數以BroadCast變量的形式傳遞給各從進程;
4)各從進程讀取傳過來的BroadCast參數,并構建神經網絡結構;
5)根據任務調度策略的優先順序PROCESS_LOCAL、NODE_LOCAL、NO_PREF,RACK_LOCAL、ANY,優先根據PROCESS_LOCAL選取出RDD中對應自身的Partition進行計算,對每一條記錄先根據BroadCast過來的上一次得出的正確率計算出的Δwij更新記錄權值.
6)計算出各條記錄通過BP神經網絡后連接權值更新值并將每個連接權值與對應記錄的權值進行相乘得出每條記錄的對BP神經網絡連接權值的加權更新量.

圖3 并行計算方法示意圖Fig.3 Parallel computing method
7)再將對應一個Executor的所有樣本的權值更新值進行本地reduce,得出總的權值更新值并計算出對應executor對應記錄的正確率和記錄條數.
8)主節點將從節點上的連接權值更新值,每個executor對應的記錄正確率和記錄條數收集過來.
9)主節點對BP神經網絡進行批更新更新并計算出則整體的正確率以及αt.
10)判斷是否達到終止條件,若達到則終止訓練;若沒有達到,則轉到3)步進行新一輪的循環.
到達終止條件后,主節點將根據Adaboost計算出的多個分類器依據(4)計算出來的權重αm進行加權集成,為了更好的理解,從數據的角度觀察整個過程如圖3所示:
7 實驗設計與結果分析
7.1 實驗環境與實驗方案
7.1.1 實驗環境
實驗中所使用到的集群環境配置屬性信息詳見表1.

表1 節點信息表Table 1 Node information table
7.1.2 實驗方案
對于并行算法,我們最關心的是算法的運行時間和正確率,除此之外還要考慮并行算法相對于串行算法對于計算速度的提升.
本文選取UCI里的Magic Gamma Telescope Data Set數據集作為實驗數據,為了解決實驗數據的數據量問題,通過原有數據經過代碼生成技術在原有的數據量下生成1000萬條數據,進行分類驗證并行BP算法的可行性.
7.2 算法參數
輸入層和輸出層的神經元個數,由輸入和輸出向量的維數來確定.在此,根據數據集的特點可以確定出輸入輸出層神經元個數分別為10,2.對于隱含層數的確定,Hornik等早已證明[13]:若輸入層和輸出層采用線性轉換函數,隱含層采用Sigmoid轉換函數,具有一個隱含層的BP網絡可以實現對任意函數的任意逼近.因此文中BP神經網絡采取1個隱含層.同時實驗結果表明選取隱藏層節點數為10時,網絡模型穩定且可獲得較理想結果.
實驗結果分別用一臺處理機和多臺處理機對BP網絡進行訓練,統計訓練的時間,正確率等,結果如表2-表5所示,其中表3,表4的迭代次數表示局部迭代次數,全局迭代次數為1:
從表2-表5可看出來總的運行時間隨著處理機的個數的增加而減少,四種算法均獲得了可觀的加速比,證明了算法具有良好的加速性能,同時如圖1所示,在相同的實驗條件下,BP-Spark算法明顯比[4]中提出的方法獲得了更好的加速比,且同樣比[9],[10]中提出的算法在達到局部收斂時獲得更好的加速比.而正確率結果如圖5所示,由于使用Adaboost算法進行集成的弱分類器隨著迭代次數(相對于[9][10]來說為全局迭代次數)的增加,得到的弱分類器越多,最終得到的組合分類器正確率逐步提高,說明了算法的有效性,而[9],[10]中提出的算法由于局部數據逐漸減小,訓練的單分類器正確率反而有所下降.最后通過在選取5臺處理機的情況下對訓練集的數據量逐步增大,如圖6所示,由圖可看出,模型的訓練時間和訓練集數據量基本上呈線性關系,由此表明了BP-Spark算法的良好的可伸縮性.

表2 本文提出的方法串行與并行的實驗結果Table 2 Experimental results of a method proposed in this paper of serial and parallel mode
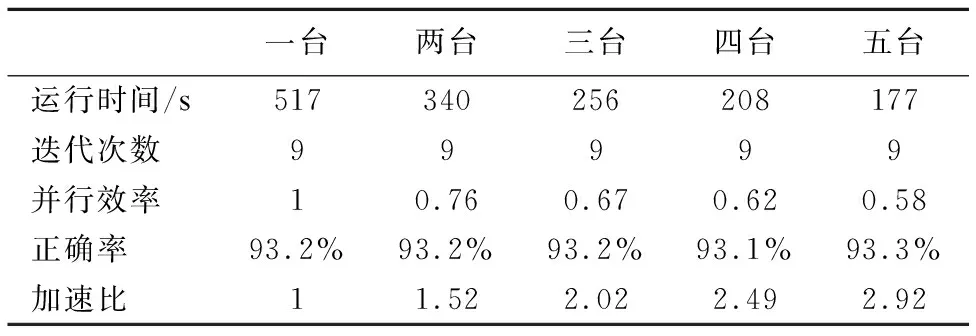
表3 [4]中提出的方法并行的實驗結果Table 3 [4] proposed in parallel with the experimental results
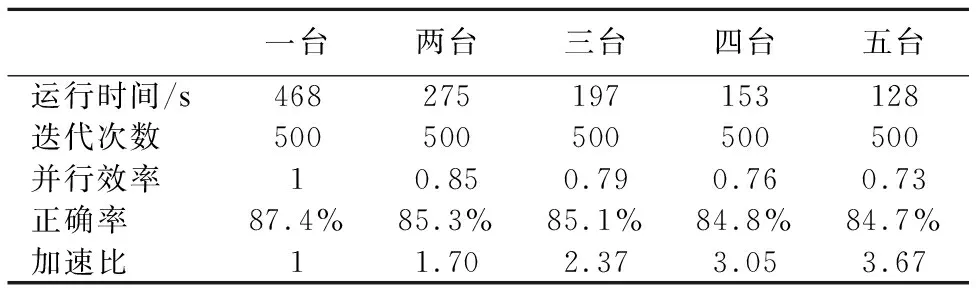
表4 [10]中提出的方法并行的實驗結果Table 4 [10] proposed in parallel with the experimental results
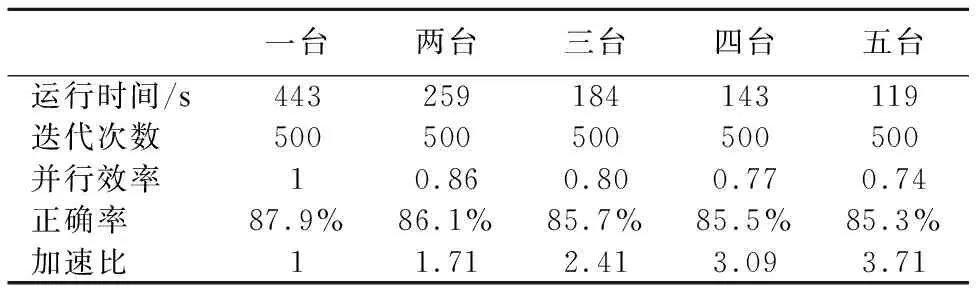
表5 [9]中提出的方法并行的實驗結果Table 5 [9] proposed in parallel with the experimental results
加速比與處理機個數的實驗結果如圖4.
8 結 語
人工神經網絡對于信息處理有很強的魯棒性和容錯能力,善于聯想和概括,具有自學習能力.BP網絡以其良好的數據處理性能在大量的實際工程中得到了廣泛的應用.但是傳統的BP算法存在學習速度慢等缺點.本文分析了BP算法的局限性,改進了BP算法在并行的基礎上,提升了網絡的收斂速度.然而仍然存在不足,在訓練BP神經網絡時如何選取最合適的初始化參數,如何將多個神經網絡分類器以更好的策略組合起來等.因此,需要針對這部分做進一步研究與改進.
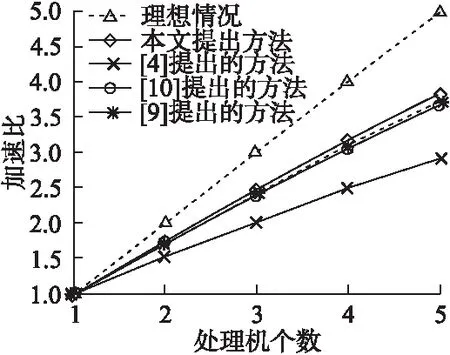
圖4 加速比與處理機個數的實驗結果Fig.4 Speed ratio and the number of experimental results of the processor
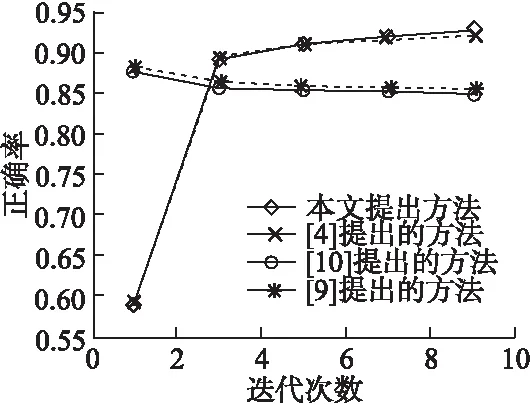
圖5 正確率與迭代次數的實驗結果Fig.5 Eexperimental results of correct rate and iteration times
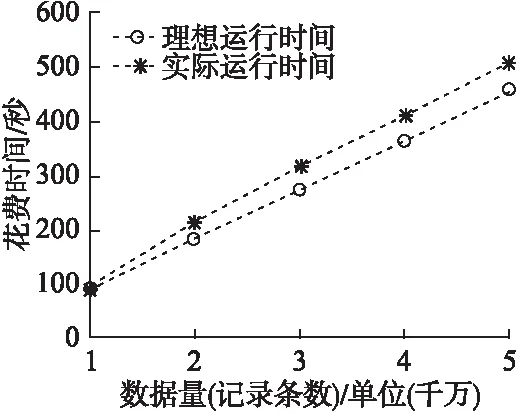
圖6 處理時間與數據量關系的實驗結果Fig.6 Experimental results of the relationship between processing time and data volume
正確率與處理機個數的實驗結果如圖5.
五臺處理機下,處理時間和數據量的實驗結果如圖6.
:
[1] Vesel,Karel,Burget L,et al.Parallel training of neural networks for speech recognition[C].International Conference on Text,Speech and Dialogue.Springer-Verlag,2010:439-446.
[2] Hecht-Nielsen.Theory of the backpropagation neural network[C].International Joint Conference on Neural Networks.IEEE Xplore,1989:593-605.
[3] Gu R,Shen F,Huang Y.A parallel computing platform for training large scale neural networks[C].IEEE International Conference on Big Data,IEEE,2013:376-384.
[4] Liu Z,Li H Y,Miao G.MapReduce-based backpropagation neural network over large scale mobile data[C].International Conference on Natural Computation,ICNC 2010,Yantai,Shandong,China,10-12 August.DBLP,2010:1726-1730.
[5] Cui J M,Ye Y X.Data Mining with BP neural network algorithm based MapReduce[J].Applied Mechanics & Materials,2013,380-384:2915-2919.
[6] Zhang H J,Xiao N F.Parallel implementation of multilayered neural networks based on Map-Reduce on cloud computing clusters[J].Soft Computing,2016,20(4):1471-1483.
[7] Zhu C,Ruonan R.The improved BP algorithm based on MapReduce and genetic algorithm[C].International Conference on Computer Science & Service System,IEEE,2012:1567-1570.
[8] Sun K,Wei X,Jia G,et al.Large-scale artificial neural network:MapReduce-based deep learning[J].Computer Science,2015,(1):1-9.
[9] Chen Wang-hu,Yu Mao-yi,Ma Sheng-jun,et al.The BP neural network MapReduce training based on the evolution of local convergence rights[J].Computer Engineering and Applications,2016,38(12):2425-2433.
[10] Zhou B,Wang W,Zhang X.Training backpropagation neural network in MapReduce[C].CCIT14,2014.
[11] Schapire R E,Freund Y,Barlett P,et al.Boosting the margin:a new explanation for the effectiveness of voting methods[C].Fourteenth International Conference on Machine Learning,Morgan Kaufmann Publishers Inc.,1997:322-330.
[12] Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C].Usenix Conference on Networked Systems Design and Implementation,USENIX Association,2012:2-2.
[13] Li Jun-hua.Computation and some numerical descaling algorithm MapReduceization study[D].Chengdu:University of Electronic Science and Technology of China,2010.
附中文參考文獻:
[9] 陳旺虎,俞茂義,馬生俊,等.基于局部收斂權陣進化的BP神經網絡MapReduce訓練[J].計算機工程與科學,2016,38(12):2425-2433.
[13] 李軍華.云計算及若干數據挖掘算法的MapReduce化研究[D].成都:電子科技大學,2010.
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
