一種網絡廣告點擊欺詐檢測的SVM集成方法
2018-07-04 13:12:14劉學軍
小型微型計算機系統 2018年5期
張 欣,劉學軍,李 斌,郭 漢
(南京工業大學 計算機科學與技術學院,南京 211816)
1 引 言
網絡在線廣告 (Online Advertising)是指通過圖片、視頻、文字等方式將產品展示給互聯網用戶的一種廣告投放形式[1].目前越來越多的企業和商家利用網絡廣告的方式來拓展自己產品知名度,但同時也需要為此行為向廣告發布商支付廣告費,其中按點擊付費(Cost Per Click,CPC)模式因計費方式簡單方便、計量準確,成為了目前網絡在線廣告界比較受青睞的廣告計費模式[2].隨著CPC模式在網絡在線廣告中的廣泛應用,也帶來一些潛在的問題,即出現為提高點擊數量而進行人為故意的點擊行為來獲取更多的利益的現象,這就是所謂的點擊欺詐(click fraud)[2].
點擊欺詐對提供產品或者服務的廣告主來說沒有真正的利益,反而會給支付廣告費用的廣告主帶來巨大的經濟損失[3].據統計,如保險、借貸、抵押等投放在google上的廣告可能需要廣告主為每次點擊支付超過50美元費用,但是對于惡意的點擊來說可能只需支付給雇傭的人0.1美元*http://www.wordstream.com/blog/ws/2011/07/18/most-expensive-google-adwords-keywords,所以很多廣告發布商進行惡意的點擊來提高廣告主投放廣告的費用從而增加自己的收益.目前點擊欺詐已經成為網絡在線廣告平臺的健康發展亟待解決的關鍵問題之一,因此,行之有效的點擊欺詐檢測方法是網絡在線廣告生態系統和諧發展的重要保障.
支持向量機(SVM)模型因其良好的分類結果和泛化能力,是目前最為常用、效果較好的分類算法之一,在入侵檢測和點擊欺詐等領域也有了一定的應用[4,5].但很多點擊欺詐特征與正常點擊比較相似,導致欺詐點擊的特征具有一定的弱隨機性,而集成方法能夠提升算法的泛化能力,在訓練樣本有限的條件下保持較小的誤差,所以可以在點擊欺詐檢測中引入集成方法來提高分類器的性能[5,6].因此本文利用Boosting-SVM集成方法來進行點擊欺詐的檢測,Boosting在提高分類精度的同時也不會產生過擬合現象.本文的貢獻可歸納為:
1)系統分析點擊欺詐問題,利用用戶行為特征進行點擊欺詐檢測,具體描述數據預處理過程中廣告發布商的行為特征值的獲取與計算,構造出發布商特征-標簽對;
2)因欺詐與非欺詐是兩類不平衡數據,對目前很多分類方法而言具有極大的挑戰性[7],利用欠抽樣(RUS)對非欺詐發布商樣本進行抽取以及合成少數類過抽樣技術(SMOTE)算法對欺詐樣本進行增加的方法對不平衡數據集進行處理,得到多個平衡數據集;
3)在每個平衡數據集上利用Boosting算法對訓練得到的基SVM分類器迭代得到多個強分類器,最后將多個強分類器以投票方式進行集成得到最終的檢測模型;
4)利用真實的數據集驗證提出方法的有效性.
2 相關工作
點擊欺詐是指為獲取商業利潤或其他利益,利用腳本、計算機程序和雇傭自然人的方式,模仿正常網絡用戶,對網絡廣告進行惡意點擊并且達到一定規模的行為[1].目前有多種檢測與防范機制來保護廣告主的利益,其中文獻[8]采用基于圖形驗證碼預防點擊策略,雖然能夠對軟件自動多次重復點擊進行有效的屏蔽,但不能對人為的點擊欺詐進行有效的檢測.文獻[9]李愛春等提出了一種基于web挖掘算法的研究,同時設計了一套點擊欺詐檢測模型,該模型對點擊數據進行一系列時序分析、離群點挖掘、非線性等分類來有效檢測點擊欺詐.文獻[10]中Kantardzic等人開發了CCFDP系統實時檢測點擊欺詐,同時考慮到了實時性會影響廣告的展示速度與效果.
通過對點擊廣告的基本特征進行分析,發現點擊欺詐發布商與正常發布商的點擊行為存在著一些區別,點擊欺詐表現出來的常見異常特征主要有:
1)點擊率突然上升,高于往常水平;
2)每次點擊的平均頁面瀏覽量驟然下降;
3)關鍵字流量的平均停留時間突然下降等.
因此龔尚福,姜曉旭[1]提出了一種基于用戶行為特征分析的點擊欺詐檢測,對基于用戶行為特征的分類方法通常有SVM、BP神經網絡、貝葉斯網絡等,但很多研究在使用SVM分類算法對點擊欺詐發布商與正常發布商進行分類的過程中忽略了真實生活中欺詐與非欺詐發布商數據是兩類不平衡的數據,因此本文提出了一種將隨機欠抽樣、SMOTE相結合對數據集進行處理后得到多個平衡數據集的方法來避免數據的不平衡對最終決策準確度的影響.同時為解決小樣本隨機問題時精確度不高的情況,可以引入集成學習方法,對SVM建立的基模型的基礎上進行迭代,來提高檢分類的準確度,文獻[5]就利用Adaboost與SVM相結合的集成方法來進行網絡入侵的檢測.因此本文利用Boosting-SVM的方法來提高檢測的準確率,即在得到的每個平衡數據集上利用Boosting對訓練得到基SVM分類器迭代.
3 點擊欺詐檢測系統
3.1 檢測系統框架
根據用戶行為特征從原始點擊數據中構造出每個廣告發布商的用于訓練學習的特征向量Pubi,將特征-標簽對構成訓練數據集D={(Pub1,y1),(Pub2,y2),…,(Pubn,yn)},其中yi={-1,1},1表示點擊欺詐的發布商,-1表示正常點擊的發布商.之后利用欠抽樣與SMOTE相結合的方法對不平衡數據進行處理,得到多個平衡數據集.訓練過程中利用本文提出的Boosting-SVM集成檢測方法,最后將訓練得到的多個強分類器模型進行組合得到最終的分類器,利用測試集(一組新的發布商數據T)對生成的模型進行評估,本文提出的點擊欺詐檢測系統的實現框架如圖1.
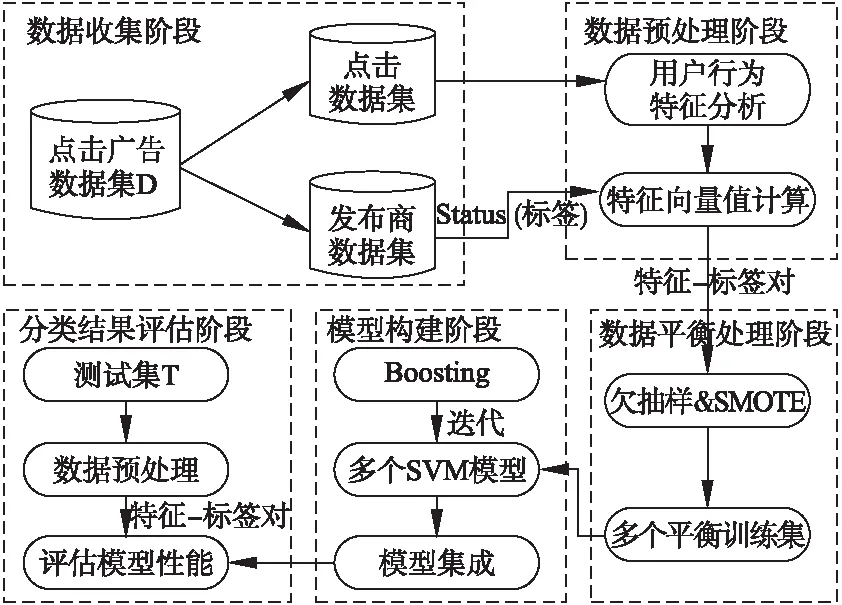
圖1 點擊欺詐檢測系統實現框架Fig.1 Framework of click fraud detection system
3.2 數據平衡處理方法
Singapore Management University2012年組織的FDMA2012 競賽中提供的點擊欺詐檢測標準數據集中,非欺詐發布商占95%左右,而欺詐點擊發布商只占5%,是兩類不平衡的數據集,如果檢測過程中不進行數據的平衡處理,會造成決策邊界的偏倚[7,11].所以本文利用隨機欠抽樣與SMOTE相結合的方法對不平衡數據集進行處理,最終得到多個平衡數據集,具體實現過程如圖2所示.
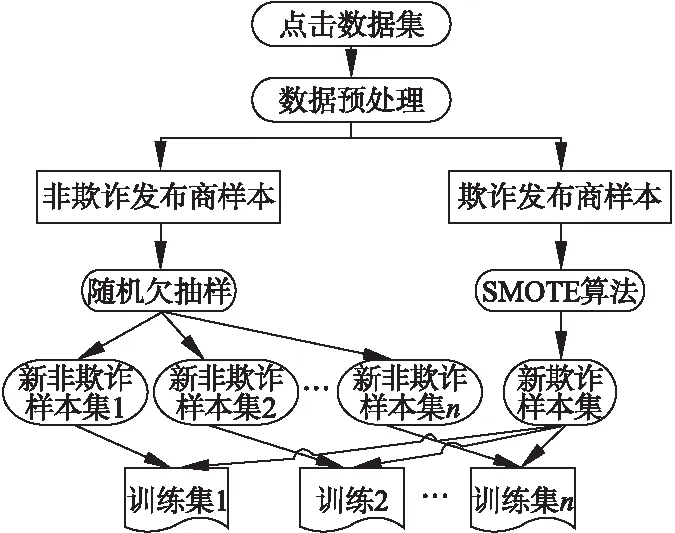
圖2 數據集平衡處理實現方法Fig.2 Method to handle imbalanced datasets
隨機欠抽樣是在多數類中隨機抽取一部分數據.SMOTE是在兩個較近的少數樣本附近通過線性插值的方法來產生數據達到數據平衡的目的[12],該方法不同于隨機過抽樣只是簡單的復制樣本,而是根據原有的少數樣本來增加并不存在的樣本,在一定程度上避免了簡單過抽樣造成的過擬合現象,具體算法描述如下所示:
算法:SMOTE(Dmin,N,k)
輸入:Dmin={Pub1,Pub2,…,Pubt}t個少數類樣本集;采樣倍率N;近鄰數k
輸出:Dmin×N個人造樣本
過程:
1.根據樣本不平衡比例確定采樣倍率N
2.fori=1,2,…,tdo
3.計算Pubi的k個近鄰:C={Pubi1,…,Pubik}
4.從其k近鄰C中隨機選擇N個樣本
5.對隨機選取的近鄰Pubij構建新樣本:
Pubnew=Pubi+rand(0,1)×(Pubij-Pubi)
(1)
6.endfor
3.3 Boosting-SVM集成檢測方法
支持向量機是1990s Vapnik等人在VC維理論和結構風險最小化原則基礎上,提出的針對小樣本、非線性、高維問題的一種新型機器學習方法[11,13],其基本模型定義為特征空間上尋找間隔最大的線性分類器:
(2)
因為很多欺詐點擊特征與正常點擊比較相似,導致欺詐點擊的特征具有一定的弱隨機性,直接使用SVM會有一個較低的精度,因此本文采用Boosting-SVM集成方法來提高分類器的預測性能,從而完成對點擊欺詐發布商的有效檢測,即利用Boosting分別對每個平衡數據集上得到的基SVM模型進行迭代得到多個強分類器模型,最后再將多個強分類器進行集成.具體實現過程如圖3所示.
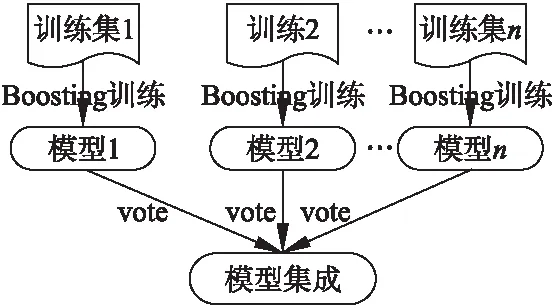
圖3 本文提出的集成方法實現過程Fig.3 Proposed ensemble method
本文用于點擊欺詐發布商檢測的Boosting-SVM集成分類器的訓練算法描述如下:
算法:Boosting-SVM集成方法
輸入:D1={(Pub1,y1),(Pub2,y2),…,(Pubm,ym)}m個帶標簽的訓練樣本;算法迭代次數T
輸出:由多個弱分類器構成的強分類器
過程:
1.初始化m個樣本的分布權重w1(i)=1/m;
2.forj=1,2,…,Tdo
3.利用樣本訓練得到SVM弱分類器
hj(Pub)=f(Pub,y,wj)
(3)
4.計算弱分類器的分類誤差ej
(4)
5.調整弱分類器權重αj
(5)
6.調整各樣本權重wj(i)并進行歸一化
(6)
7.endfor
8.根據多個弱分類器以及權重求得強分類器
(7)
最后將在每個平衡數據集上利用Boosting算法迭代后的多個強分類器模型以投票的方式進行集成,定義如式(8),利用該分類器對廣告發布商進行檢測.
F(pub)=vote[H1(Pub),…,Hn(Pub)]
(8)
4 實驗與結果分析
為了驗證我們提出的集成方法能有效地進行網絡廣告點擊欺詐發布商的檢測,利用BuzzCity全球移動廣告網絡公司提供的真實網絡廣告點擊數據進行了一系列的實驗,實驗中數據預處理過程對特征向量值的計算、SMOTE的實現、Boosting-SVM集成方法訓練過程以及用測試集進行的預測分析都利用python軟件實現.最終從幾百萬原始點擊數據出發完成對超過3000個廣告發布商進行檢測.
4.1 實驗數據集
本文實驗采用FDMA2012 競賽中提供的一個真實的點擊欺詐檢測標準數據集,該數據集由BuzzCity全球移動廣告網絡公司提供,可在http://palanteer.sis.smu.edu.sg/fdma2012/獲取[14].原始數據集由發布商數據集和點擊數據集構成,實驗所用的數據統計信息如表1所示(為了便于分析,將Observation類發布商歸為Fraud類中),欺詐發布商與正常發布商具有極大的分布不平衡性.

表1 實驗數據統計Table 1 Statistics of experimental data
發布商數據集中每一條信息表示某一條已經被分類的發布商點擊記錄,主要描述發布商的基本信息,包括partnerid(廣告發布商的唯一標識符)、bankaccount(存儲廣告費用的發布商賬戶)、address(發布商的郵箱地址)以及status(分類的類標號),表3(a)展示了部分發布商數據集樣本.點擊數據集中每一條信息表示某一用戶的點擊記錄日志,表2為點擊數據集中包含的屬性特征以及其含義,表3(b)展示了兩條點擊數據集樣本,利用兩個數據集中共有的屬性partnerid建立聯系,分析點擊廣告的基本特征.
4.2 數據預處理
為了將點擊日志轉換成適合挖掘及訓練的形式,首先對原始數據集進行預處理,從表2中的基本特征出發,利用簡單的統計性特征平均值、標準差和百分比等為每一個發布商構造特征向量Pubi,構造的新特征應能夠捕捉欺詐性發布商的特征和趨勢,并計算相應的特征向量值.因為對幾百萬條點擊數據進行清洗、整理并計算,所以這部分工作是整個實驗過程中工作量最大也是很重要的一部分.
構造的特征都是針對每一個廣告發布商從點擊行為的時間和空間屬性進行統計的,所以第一步是將廣告發布商i所涉及到的所有點擊數據流篩選出來,點擊的總數量為其中一個特征值total_clicks.計算過程中缺失的值置0,很多特征值屬于同一類型,所以只介紹部分特征的計算過程.

表2 點擊數據集屬性特征以及其含義Table 2 Features in the click dataset
欺詐性發布商經常使用不同的手段如生成非常稀疏的點擊序列、改變IP地址、在不同的國家不同電腦上實施點擊等其它手段來偽裝他們的點擊行為.所以利用iplong、agent、cid、cntr、referrer屬性來計算出發布商i這幾個特征不同的數量,如distinct_iplong是通過iplong屬性來統計,有一個不同的iplong即加1,計算點擊該發布商發布廣告的不同iplong數,同時以每分鐘為間隔計算平均值和標準值,即avg_distinct_iplong和std_distinct_iplong.考慮到發布商網站類型的不同會對是否欺詐有一定影響,所以以category特征來計算,如category_es表示種類為es的點擊數量.
有些則堅持傳統的方法在一段時間里點擊所允許的最大點擊次數,所以對欺詐點擊來說,可能在較短的時間被更多的重復點擊.而對重復點擊行為來說,更短的點擊間隔會在預測分類時產生更好的結果,所以以一分鐘為間隔,以多個特征組合或單個特征來構造多特征重復點擊和單特征重復點擊的行為特征.比如多特征avg_spiky_ReAgCnIpCi表示每分鐘相同referrer、agent、cntr、iplong、cid被重復點擊的平均點擊量,原始點擊數據流是以點擊時間排列的,查找每分鐘內這幾個特征相同的點擊數據流,如果有兩條一樣的點擊數據則計1,有三條一樣的點擊數據計2,以此類推,將每分鐘進行統計后的值相加除以三天總的分鐘數即該特征的值.其他相類似的重復點擊行為特征的計算也是按這種思路.
我們的目標是要捕獲發布商短期和長期的行為,這些行為是基于觀察到的發布者嘗試合理的行為和在稀疏的時間間隔內的持續點擊行為,可以基于細粒度的時間間隔構造特征,從點擊時間屬性(timeat)推演出幾種統計特征,如每1分鐘、每15分鐘、1小時和每6小時,也就是將一天以6小時為時間段劃分為四個階段:night(12am-5:59am)、morning(6am-11:59am)、afternoon(12pm-5:59pm)和evening(6pm-11:59pm).同時將一個小時分為4部分:first、second、third、last.在每個時間間隔,對每個發布商的點擊數據進行統計特征的計算.如night_click_percent是計算出12am-5:59am期間點擊數量占總點擊數量total_clicks的比例,以及avg_per_hour_density是先計算出每小時的點擊密度,即每小時的點擊數量占總點擊數量的百分比,再以每小時為時間間隔,計算平均值.
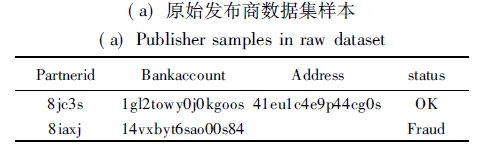
表3 數據預處理過程Table 3 Data pre-processing

(b) 原始點擊數據集樣本(b) Click samples in raw datasetIdIplongAgentPartneridCidCntrTimeatCategoryReferrer134303553411584580MAUI8jc3s8gjrsin00:07:50ad134180963648406743GT-I91008iaxj8fj2mru00:00:08ad24w9x4d25ts00400(c) 數據預處理后的特征-標簽對(Pubi,yi)(c)Feature-label dataset

Partneridtotal_clicksavg_spiky_ReAgCnIpCiavg_distinct_iplongnight_click_percentbrand_MAUI_percent…Status(yi)8jc3s15010.0011570.3430560.4170550.057295…OK(-1)8iaxj395980.0038026.7898150.3495630.014849…Fraud(+1)
除此之外我們還考慮了點擊者的移動代理商(agent)以及點擊者國家(cntr)對點擊欺詐的影響,如brand_MAUI_percent指MAUI代理商的點擊數量占總點擊量的比例,在這過程中我們不考慮使用的設備具體型號.
本文使用的特征列表可在以下網址獲取:http://clifton.phua.googlepages.com/feature-list.txt,對其中118維特征值進行計算得到每個廣告發布商的特征向量Pubi={total_clicks,avg_spiky_ReAgCnIpCi,…,avg_distinct_iplong,…,night_click_percent,…,brand_MAUI_percent,…},表3展示了數據預處理的計算過程,最終得到訓練集中發布商特征向量-標簽對(Pubi,yi)樣本如表3(c)所示(部分特征值),在實際訓練過程中需要對這118維特征進行特征選擇.
4.3 實驗結果分析
為驗證本文提出方法的有效性,進行一系列實驗.在數據的不平衡處理過程中,SMOTE算法中N和K值選擇N=2,K=5.Boosting-SVM集成方法訓練階段利用C-SVM作為基分類器,實驗中懲罰因子C=100,并選擇RBF核函數K(xi,xj)=exp(γ‖xi-xj‖2),核函數參數γ取默認值,并選用boosting中最為經典的Adaboost集成方法,算法迭代次數T=100.因118維特征較多,為消除特征之間的冗余,在訓練階段利用python自帶的sklearn庫的Adaboost分類器類中的特征選擇方法輸出每個特征權重進行特征選擇,將特征選擇后的特征用于訓練.在實驗分析過程,為避免抽樣的偶然性,每組實驗進行10次,求平均值,作為最后的分類結果.
對于檢測系統來說檢測準確度越高越好,所以需要一些評估指標對模型進行分析,在具體介紹評估指標前,我們首先介紹混淆矩陣,如表4所示.
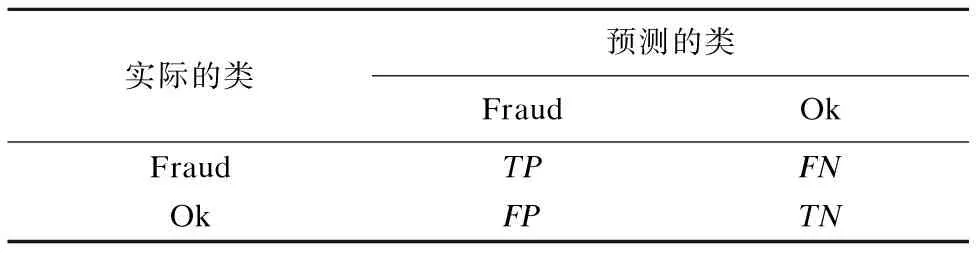
表4 分類預測混淆矩陣Table 4 Confusion matrix
本文實驗中利用準確率 (查準率)、 召回率 (查全率)、F值、G-mean值以及P-R曲線這幾個常用的指標來衡量本文提出方法的性能:
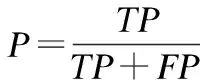
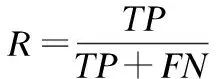
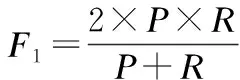
若直接將訓練集中的3081個發布商作為訓練數據輸入,此時訓練時間5.1s,檢測時間2.3s,但檢測結果召回率接近于0,這是因為正常的發布商94.9%,而點擊欺詐廣告發布商只占5.1%,點擊欺詐檢測是類不平衡問題.因此首先分析數據的不平衡性對分類結果的影響,分別從測試集中選取1:1、1:2、1:3、1:4、1:5的數據,保持其他訓練參數一致.結果如圖4所示.隨著選取的兩類數據樣本越來越不平衡,SVM會產生嚴重偏倚,幾乎不能檢測出少數類,所以需要對數據進行平衡處理.
解決不平衡的方法有很多種,常用的就是抽樣方法,比較本文提出的解決不平衡的方法與單獨利用RUS(隨機欠抽樣)、ROS(隨機過抽樣)、SMOTE處理本文的不平衡數據后構建模型的檢測結果.結果如表5所示,本文中對數據不平衡的處理方法最為有效,解決了點擊欺詐檢測中的非平衡數據問題,也避免了因為欠抽樣造成的重要信息的丟失以及過抽樣造成的過擬合現象.
為更好的驗證本文提出的集成方法的有效性,將測試集中3000個發布商隨機分為6組測試數據,分別以無Boosting過程的單純SVM集成方法以及本文提出的Boosting-SVM集成方法在多個平衡數據集上訓練構建出最終的集成模型進行實驗,結果如表6-表7所示,分析發現利用了Boosting對SVM模型進行迭代后,進一步提高了對廣告點擊欺詐發布商的檢出率.
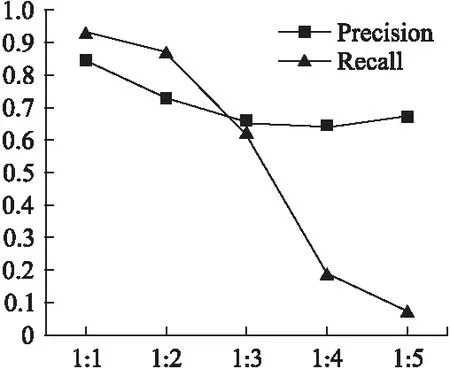
圖4 不平衡度對SVM的影響Fig.4 Influence of imbalanced degree on SVM
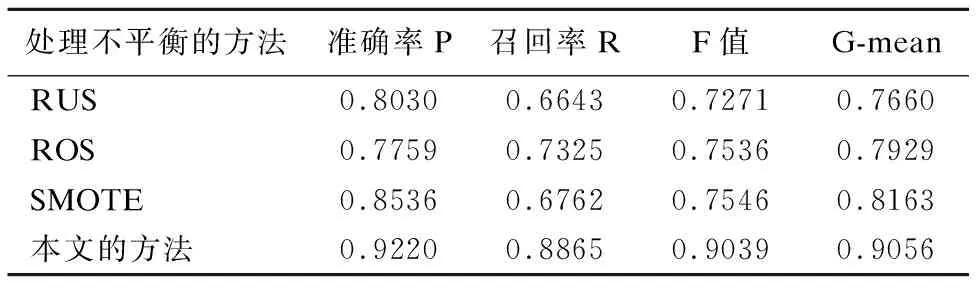
表5 多種抽樣方法處理不平衡數據后的檢測結果Table 5 Results of multiple sampling methods on the imbalance datasets
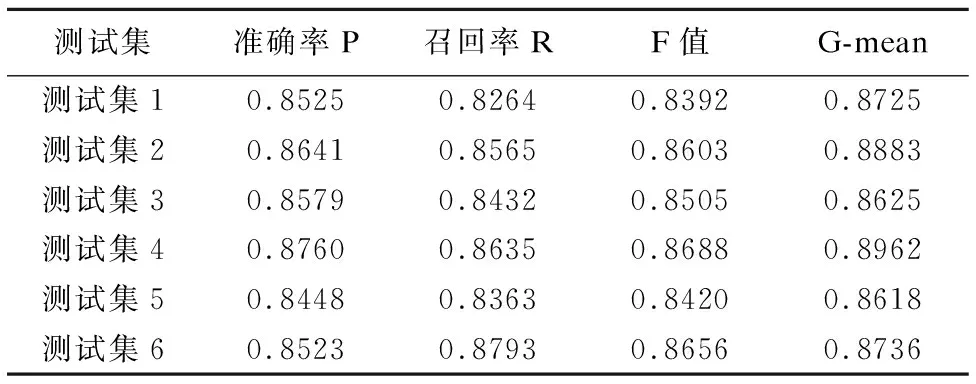
表6 無Boosting迭代過程的點擊欺詐檢測結果Table 6 Click fraud detection results without boosting
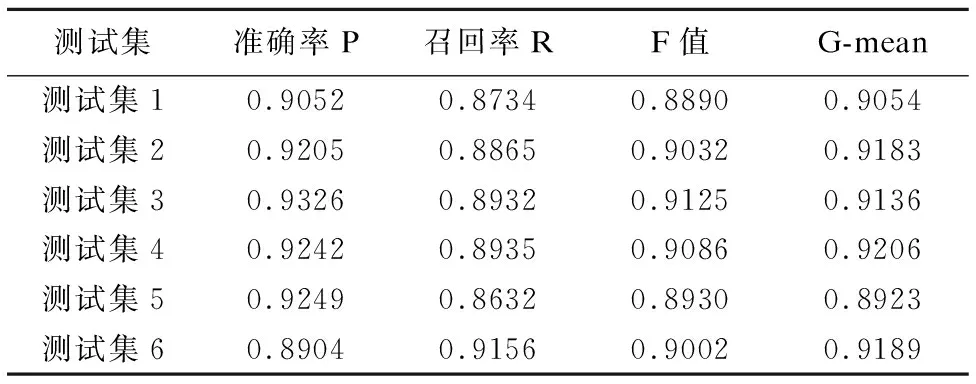
表7 有Boosting迭代過程的點擊欺詐檢測結果Table 7 Click fraud detection results with boosting
最后為更直觀的評估本文提出的方法,引入P-R曲線,P-R曲線越往右上角凸說明分類器的性能越好.本文提出的集成方法與無Boosting過程的單純SVM集成方法在整個測試集上的的P-R曲線如圖5所示,無Boosting過程構建的集成模型平衡點(BEP)為0.85,而本文提出的集成方法訓練得到的檢測模型平衡點大于0.90,完全包住單純SVM集成方法的曲線,表明本文提出的Boosting-SVM集成方法對樣本分布有更好的擬合效果,即對不發法布商的檢測有較高的準確度,能夠更加有效的解決網絡廣告中發布商進行的點擊欺詐問題.
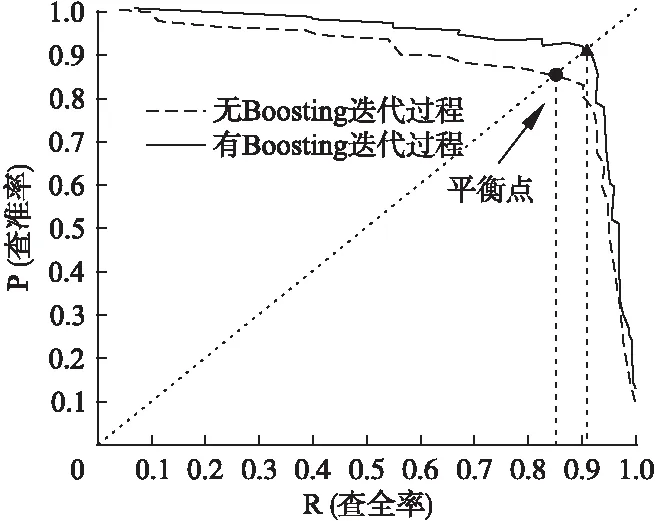
圖5 P-R曲線對比圖Fig.5 Comparison of algorithms′ P-R curves
5 總 結
本文在分析網絡廣告點擊欺詐特征的基礎上,發現點擊欺詐特征具有一定的弱隨機性,因此本文提出Boosting-SVM的集成方法來提高檢測的精度.同時考慮到數據不平衡對分類決策的影響,會導致最終訓練得到的模型不能對點擊欺詐廣告發布商進行有效的檢測,因此本文中采用抽樣與SMOTE相結合處理不平衡數據后得到多個平衡數據集,最后在多個平衡數據分別利用Boosting對SVM基分類器進行迭代得到多個強分類,再將多個強分類以投票的方式進行集成,從而完成對廣告發布商進行有效分類,檢測出進行欺詐點擊的發布商.接下來的研究中我們將進一步分析點擊欺詐廣告發布商的特點,考慮從特征選擇、其他方法進行不平衡數據的處理以及其多種分類算法相結合等著手來進一步提高對點擊欺詐廣告發布商的檢出率.
:
[1] Gong Shang-fu,Jiang Xiao-xu.Detection fraudulent clicks in advertisement based on user behavior analysis[J].Computer Application and Software,2011,28(4):127-128.
[2] Linden J,Teeter T.Method for performing real-time click fraud detection,prevention and reporting for online advertising[P].US:US9367857,2016:6-14.
[3] Kitts B,Zhang J Y,Wu G,et al.Click fraud detection:adversarial pattern recognition over 5 years at microsoft[C].In:Abou-Nasr M,Lessmann S,Stahlbock R,et al.Real World Data Mining Application,Heidelberg:Springer,2015:181-201.
[4] Perera K S,Neupane B,Faisal M A,et al.A novel ensemble learning-based approach for click fraud detection in mobile advertising
[C].Proceedings of 2013 International Conference on Mining Intelligence and Knowledge Exploration,Lecture Notes in Computer Science,vol 8284,2013:370-382.
[5] Tan Ai-ping,Chen Hao,Wu Bo-qiao.Network intrusion intelligent detection algorithm based on Adaboost [J].Computer Science,2014,41(2):197-200.
[6] King M A,Abrahams A S,Ragsdale C T.Ensemble learning methods for pay-per-click campaign management[J].Expert Systems with Applications,2015,42(10):4818- 4829.
[7] Zhi Wei-mei,Guo Hua-ping,Zhang Yin-feng,et al.Case-based ensemble selection for classification of imbalance datasets[J].Journal of Chinese Computer Systems,2014,35(4):770-775.
[8] Yuan Jian,Zhang Jin-song,Ma Liang.Effective strategy for prevent click fraud[J].Journal of Computer Applications,2009,29(7):1790-1792.
[9] Li Ai-chun,Teng Shao-hua.Application of mining technology to click fraud detection[J].Computer Engineering and Design,2012,33(3):957-962.
[10] Kantardzic M,Walgampaya C,Wenerstrom B,et al.Improving click fraud detection by real time data fusion[C].Proceedings of the 9th IEEE International Symposium on Signal Processing and Information Technology (ISSPIT2009),IEEE,2009:69-74.
[11] Akbani R,Kwek S,Japkowicz N.Applying support vector machines to imbalanced datasets[C].Proceedings of the 15th European Conference on Machine Learning (ECML),Heidelberg:Springer,2004:39-50.
[12] Chawla N V,Bowyer K W,Hall L O,et al.SMOTE:synthetic minority over-sampling technique [J].Journal of Artificial Intelligence Research,2002,16(1):321-357.
[13] Vapnik V N.The nature of satistical learning theory[M].New York:Springer Science + Business Media,1999.
[14] Oentaryo R,Lim E P,Finegold M,et al.Detecting click fraud in online advertising:a data mining approach [J].Journal of Machine Learning Research,2014,15(1):99- 140.
附中文參考文獻:
[1] 龔尚福,姜曉旭.基于用戶行為分析的廣告欺詐點擊檢測[J].計算機應用與軟件,2011,28(4):127-128.
[5] 譚愛平,陳 浩,吳伯橋.基于SVM的網絡入侵檢測集成學習算法[J].計算機科學,2014,41(2):197-200.
[7] 職為梅,郭華平,張銀峰,等.一種面向非平衡數據集分類問題的組合選擇方法[J].小型微型計算機系統,2014,35(4):770-775.
[8] 袁 健,張勁松,馬 良.一種有效預防點擊欺詐的策略[J].計算機應用,2009,29(7):1790-1792.
[9] 李愛春,滕少華.Web挖掘在網絡廣告點擊欺詐檢測中的應用[J].計算機工程與設計,2012,33(3):957-962.
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
