基于隨機(jī)森林的惡意代碼檢測
2018-06-29 02:01:32戴逸輝殷旭東
網(wǎng)絡(luò)空間安全 2018年2期
關(guān)鍵詞:機(jī)器學(xué)習(xí)
戴逸輝 殷旭東


摘 要:面對惡意代碼高速增長、變種繁多的現(xiàn)狀,使用了基于隨機(jī)森林的惡意代碼分類方法。通過將IDA反匯編工具生成的ASM文件,利用灰度共生矩陣提取ASM惡意代碼灰度圖的紋理特征,通過ASM 文件OpCode 序列的3-gram特征,再結(jié)合隨機(jī)森林算法對特征進(jìn)行分類。對9種惡意代碼家族的樣本進(jìn)行實(shí)驗認(rèn)證,獲得混淆矩陣,分析隨機(jī)森林的分類效果,并與樸素貝葉斯算法和K近鄰分類算法進(jìn)行比較。實(shí)驗結(jié)果表明:隨機(jī)森林算法是一個優(yōu)秀的用于惡意代碼分類檢測的算法,上述兩類特征抽取的方法均能有效地進(jìn)行惡意代碼的檢測工作,且將兩種特征的隨機(jī)森林結(jié)合時,其分類效果更佳。
關(guān)鍵詞:隨機(jī)森林;惡意代碼檢測;多種特征;機(jī)器學(xué)習(xí)
中圖分類號:TP391 文獻(xiàn)標(biāo)識碼:A
Malicious code detection based on random forest
Abstract: A method in the detection of malicious code based on random forest is used in this paper in the face of the rapid growth and variations of malicious code. The texture features of ASM code grayscale map through GLCM and 3-gram features through ASM OpCode list were obtained by using the ASM files generated by the IDA disassembler tool. Then using random forest algorithm and these features, malicious code can be classified. The samples of nine malicious code families were used for the experiment to get the confusion matrix, analyze the classification effect of random forest .The random forest is also compared with the Naive Bayes and the k-Nearest Neighbour in this experiment. The results show that the random forest algorithm is an excellent algorithm for classification detection of malicious code. Both of two feature extraction methods above can works effectively, and even works better when they are combined.
Key words: random forest; malicious code detection; a variety of features; machine learning
1 引言
隨著技術(shù)的發(fā)展,惡意代碼的種類、數(shù)量、規(guī)模在不斷增加。據(jù)國家計算機(jī)網(wǎng)絡(luò)應(yīng)急技術(shù)處理協(xié)調(diào)中心的監(jiān)測數(shù)據(jù)[1],2017年4月,境內(nèi)感染網(wǎng)絡(luò)病毒的終端數(shù)為近144萬個,較上月增長12.7%;在捕獲的新增網(wǎng)絡(luò)病毒中,按名稱統(tǒng)計新增10個;按惡意代碼家族統(tǒng)計新增3個,較上月增長 50.0%;境內(nèi)8978萬余個用戶感染移動互聯(lián)網(wǎng)惡意程序,惡意程序累計傳播次數(shù)75萬余次。
雖然惡意代碼的規(guī)模不斷增大,但是大多數(shù)是在傳播過程中為了逃過查殺或者是黑客通過關(guān)鍵模塊重用、自動化工具等手段產(chǎn)生的變種[2],因此有很大的內(nèi)連性和相似性。采用隨機(jī)森林算法,能夠克服數(shù)據(jù)規(guī)模大的障礙。此外,通過對龐大數(shù)據(jù)集的訓(xùn)練對惡意代碼進(jìn)行分類,能夠判斷某個惡意代碼屬于已知種類或是新種類,從而可采取相應(yīng)的安全措施,是一種值得嘗試的方法。
2 相關(guān)研究
目前,已經(jīng)有很多的將機(jī)器學(xué)習(xí)用于惡意代碼的研究,并且已由傳統(tǒng)的PC平臺,引申至Android平臺的惡意代碼的研究[3]。目前,機(jī)器學(xué)習(xí)算法例如隨機(jī)森林算法、貝葉斯算法、神經(jīng)網(wǎng)絡(luò)算法、K近鄰算法、SVM算法[4]等,已被大量應(yīng)用于惡意代碼的分類[5]。常見的特征工程為基于惡意代碼圖像的紋理特征,基于語義的如Ngram特征。
3 關(guān)鍵算法與技術(shù)
3.1決策樹與隨機(jī)森林
決策樹是一種樹形的結(jié)構(gòu),它的一個非葉子節(jié)點(diǎn)表示一次對于某個屬性的判斷,它所對應(yīng)的的分支表示了一個判斷的結(jié)果輸出,葉節(jié)點(diǎn)表示了一個特定的類別。決策樹是一個預(yù)測模型,它代表了特征與類別之間的映射關(guān)系。根據(jù)對分裂規(guī)則,建樹,去枝的不同處理,決策樹的實(shí)現(xiàn)算法有ID3、C4.5、CART等。
隨機(jī)森林就是以隨機(jī)的方式建立的一個包含了多棵決策樹的分類器,當(dāng)有一個輸入時,多棵樹分別對其進(jìn)行判斷,最后經(jīng)過結(jié)合處理后得到最終的分類結(jié)果。隨機(jī)森林對于很多種的資料,可以產(chǎn)生高準(zhǔn)確度的分類器,減少泛化和誤差,且學(xué)習(xí)過程是很快的[6]。隨機(jī)森林結(jié)合了Breimans的“Bootstrap aggregating”想法和Ho的“Random Subspace Method”想法,隨機(jī)性體現(xiàn)在樣本的隨機(jī)性與特征的隨機(jī)性上。前者有利于保證每棵樹的數(shù)據(jù)的側(cè)重不一樣,后者有利于樣本的分裂的多樣性。
3.2惡意代碼圖像
惡意代碼圖像的概念,最早是由Nataraj等[7] 人2011年提出的,將惡意代碼的二進(jìn)制文件轉(zhuǎn)換成灰度圖,再結(jié)合GIST特征來進(jìn)行聚類。由于采用可視化的思維,此后不斷有學(xué)者在此基礎(chǔ)上進(jìn)行研究,并且采用的原數(shù)據(jù)形式與圖像形式各異。
3.3 OpCode N-gram
2008年,Moskovitch等[8]人提出用Opcode的形式來概括表達(dá)可執(zhí)行文件。對惡意代碼文件進(jìn)行反匯編,就可以得到惡意代碼的匯編代碼,通常一條指令的第一部分就是Opcode,它簡單地表明了一個基本操作。
N-gram是大詞匯連續(xù)語音識別中常用的一種語言模型,該模型基于這樣一種假設(shè),第n個詞的出現(xiàn)只與前面n-1個詞相關(guān),而與其它任何詞都不相關(guān)。整句的概率就是各個詞出現(xiàn)概率的乘積,這些概率可以通過直接從語料中統(tǒng)計n個詞同時出現(xiàn)的次數(shù)得到。
4 實(shí)驗過程
4.1檢測模型
本系統(tǒng)力求在相對較少的數(shù)據(jù)規(guī)模(1800)下,能夠得到惡意代碼的ASM灰度圖,并利用ASM文件的OpCode 3-gram特征和灰度圖的紋理特征,結(jié)合隨機(jī)森林算法進(jìn)行分類,并對結(jié)果進(jìn)行分析。本文使用的代碼功能塊,分析流程,重要算法如圖1所示。
4.2實(shí)驗數(shù)據(jù)
本文的數(shù)據(jù)來自Microsoft Malware Classification Challenge。惡意代碼一共有九類,包括Ramnit、Lollipop、Kelihos_ver3、Vundo、Simda、Tracur、Kelihos_ver1、Obfuscator.ACY、Gatak。本文在所給的解壓184G的測試數(shù)據(jù)中,抽取1800條數(shù)據(jù)用于進(jìn)行實(shí)驗,包括60%用于訓(xùn)練和40%用于測試。
4.3實(shí)驗環(huán)境
本文的所有編碼及代碼運(yùn)行均使用Python 2.7.6 版本完成,實(shí)驗環(huán)境虛擬機(jī)OS為64位 ubuntu 3.13.0-24-generic,內(nèi)存2G,處理器為Intel Core 4210H。本文的一些數(shù)據(jù)分析工作在OS為win7的PC機(jī)上完成。
4.4基于ASM惡意代碼圖像的特征提取
惡意代碼圖像需要多少的像素,是個值得深入研究和交叉驗證的研究點(diǎn),本文的側(cè)重點(diǎn)不在此,為了兼顧圖像的相對完整性和減少計算量,本文采取了10000個像素點(diǎn)。取ASM文件的前10000個字節(jié),每個字節(jié)范圍在00~FF之間,對應(yīng)灰度圖的0~255取值,先得到像素點(diǎn)的CSV格式文件。然后得到100×100的矩陣,最后將矩陣轉(zhuǎn)化成灰度圖。
對于紋理特征的提取,本文采用灰度共生矩陣。灰度共生矩陣是一種通過研究灰度的空間相關(guān)特性來描述紋理的常用方法[9]。最先由Haralick等人提出了用它來描述紋理特征。若是不對灰度圖的級數(shù)做處理,則本文的100行100列的圖像求一次的基本運(yùn)算量為2562×100×100,為了加快運(yùn)算速度,則將灰度級壓縮為0~7 八級。
這樣的話得到的灰度共生矩陣為8×8。本文計算時調(diào)用的是scikit-image庫的greycomatrix()函數(shù),其中distances參數(shù)設(shè)置為[1-3],angles設(shè)置為[0, np.pi/4, np.pi/2, 3×np.pi/4],則對于同一個灰度圖,計算了不同偏移距離和角度的3×4共12個灰度共生矩陣。
之后對每個矩陣調(diào)用greycoprops()函數(shù)來計算對比度、相異性、同質(zhì)性、能量、自相關(guān)的特征值寫入CSV文件。至此,基于ASM惡意代碼圖像的特征提取完畢。
4.5 基于OpCode N-gram的特征提取
先將ASM通過正則表達(dá)式的提取,獲取OpCode序列。再提取出現(xiàn)次數(shù)超過500的OpCode 3-gram特征,寫入CSV文件。之所以采取3-gram,是因為高于四元的用的很少,訓(xùn)練它需要更龐大的語料,而且數(shù)據(jù)稀疏嚴(yán)重,時間復(fù)雜度高,精度卻提高的不多。
4.6隨機(jī)森林算法實(shí)現(xiàn)
本文的隨機(jī)森林算法實(shí)現(xiàn)采用的是Python第三方庫scikit-learn中的相關(guān)函數(shù)。隨機(jī)森林算法幾乎不需要輸入的準(zhǔn)備,它的實(shí)現(xiàn)方法的參數(shù)設(shè)置初始值也都是合理的。對于RandomForestClassifier()函數(shù):n_jobs統(tǒng)一設(shè)置為-1,充分利用CPU性能,修改n_estimators的值來對決策樹的棵樹進(jìn)行設(shè)置,其他均采用默認(rèn)值。
本文將數(shù)據(jù)集的60 %用于訓(xùn)練,40%用于測試。用sklearn.metrics下的confusion_matrix()來獲得混淆矩陣。用到的分類算法評價指標(biāo):準(zhǔn)確率(Accuracy)、精確率(Precision)、召回率(Recall)、f1值(F1-score),四項指標(biāo)的取值均為0~1。采用sklearn.metrics下的classification_report()函數(shù)獲取評價指標(biāo)數(shù)據(jù)。
5 實(shí)驗結(jié)果與分析
5.1基于惡意代碼圖像的隨機(jī)森林
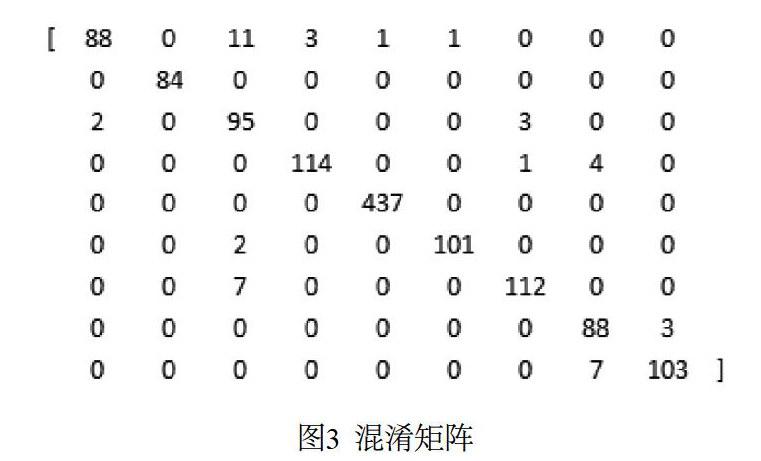
根據(jù)本文對于參數(shù)設(shè)置,當(dāng)n_estimators設(shè)置為500時,得到time=45,accuracy=0.96448,混淆矩陣和評價指標(biāo)如圖3所示。
由圖3可知:一類實(shí)例共有104例,預(yù)測正確的有88例,錯誤預(yù)測成三類的有11例,錯誤預(yù)測成四、五、六類的各有3、1、1個;二類預(yù)測正確的有84例,無預(yù)測錯誤,以此類推。
上述表明利用隨機(jī)森林算法和灰度共生矩陣獲得的特征值,能有效地對惡意代碼進(jìn)行分類 。
此外,為了探尋決策樹棵樹變化時,準(zhǔn)確率的一些變化,改變n_estimators的值。令n_estimators 分別取不同的值時得到的結(jié)果如表2所示。可以看出,當(dāng)決策樹棵樹增加時,計算對應(yīng)的時間增加。當(dāng)決策樹的棵樹在較小值時,隨著棵樹的增加,準(zhǔn)確度方面,準(zhǔn)確度整體呈現(xiàn)上升趨勢。當(dāng)決策樹棵樹較高時,準(zhǔn)確度不再繼續(xù)增加而是穩(wěn)定在0.97左右。從而可以提出結(jié)論:隨機(jī)森林中決策樹的增加,雖然可以提高結(jié)果的準(zhǔn)確率,但當(dāng)棵樹超過臨界值后,準(zhǔn)確率穩(wěn)定不再增加。
5.2 基于OpCode 3-gram的隨機(jī)森林
同樣,參照文中的參數(shù)設(shè)置方法,設(shè)置n_estimators為500,得到time=3,accuracy=0.93611,平均的精確率為0.95,召回率和f1值都為0.94。對比可以得出結(jié)論基于OpCode 3-gram的隨機(jī)森林略差于基于惡意代碼圖像灰度共生矩陣的特征值的隨機(jī)森林,但是其同樣也能有效的對惡意代碼進(jìn)行分類 。
5.3使用兩類特征的隨機(jī)森林
將以上的兩種特征抽取方法抽取的特征值結(jié)合使用,同樣設(shè)置n_estimators為500。
如表3所示,每項數(shù)據(jù)分別為單獨(dú)使用灰度共生矩陣的特征值、單獨(dú)使用Opcode 3-gram特征、結(jié)合使用上述兩類特征。
可以得出結(jié)論,結(jié)合兩類特征值的隨機(jī)森林在本文使用的各項指標(biāo)上均優(yōu)于使用單類的特征值的隨機(jī)森林。
5.4 與樸素貝葉斯算法和K近鄰分類算法的簡單比較
本文,對于兩種算法的分類器的實(shí)現(xiàn)同樣采用python的scikit-learn包。分別采用 sklearn.naive_bayes. GaussianNB()和 sklearn.neighbors.KNeighborsClassifier()函數(shù)實(shí)現(xiàn)。參數(shù)均為默認(rèn)。采用的特征為OpCode 3-gram。結(jié)果匯總成表4所示。
由表可知,在各項的評價指標(biāo)上,均呈現(xiàn)出隨機(jī)森林算法>K近鄰分類算法>樸素貝葉斯算法。可以得出結(jié)論,在本文的數(shù)據(jù)規(guī)模和特征選擇上,隨機(jī)森林算法要優(yōu)于K近鄰分類算法和樸素貝葉斯算法。
6 結(jié)束語
本文通過將惡意代碼的ASM文件轉(zhuǎn)化成100×100的灰度圖,利用灰度共生矩陣提取圖像的紋理特征,通過在ASM文件中提取OpCode序列,提取3-gram特征,并結(jié)合隨機(jī)森林算法對特征進(jìn)行分類。對九類惡意代碼樣本進(jìn)行實(shí)驗驗證。結(jié)果表明,上述的兩類特征值抽取方法結(jié)合隨機(jī)森林算法均可以有效的進(jìn)行惡意代碼的分類,在本文選取的準(zhǔn)確率、精確率、召回率、f1值的評價指標(biāo)上隨機(jī)森林算法相優(yōu)于其他分類K近鄰和樸素貝葉斯。下一步工作,優(yōu)化特征值抽取的方法,獲取更大規(guī)模的數(shù)據(jù)集進(jìn)行訓(xùn)練,通過調(diào)參優(yōu)化分類的過程,取得效率和結(jié)果的平衡,并將其運(yùn)用到現(xiàn)實(shí)的惡意代碼的分類工作中。
基金項目:
2016年教育部產(chǎn)學(xué)合作協(xié)同育人項目(項目編號:201602024005)。
參考文獻(xiàn)
[1] CNCERT互聯(lián)網(wǎng)安全威脅報告(2017年04月)[EB/OL].http://www.cac.gov.cn/2017-06/23/c_1121197479.htm,2017-6-23/2018-3-12.
[2] 米蘭·黑娜亞提,艾克帕爾·艾合買提,涂偉滬.基于信息安全的計算機(jī)主動防御反病毒技術(shù)研究[J]. 網(wǎng)絡(luò)空間安全, 2016,7(07):40-42.
[3] 童振飛. Android惡意軟件靜態(tài)檢測方案的研究[D].南京郵電大學(xué), 2012.
[4] 苗發(fā)彪,王晴.基于支持向量機(jī)的Android惡意軟件靜態(tài)檢測技術(shù)的研究[J].網(wǎng)絡(luò)空間安全,2016,7(05):34-36.
[5] 張小康.基于數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)的惡意代碼檢測技術(shù)研究[D].中國科學(xué)技術(shù)大學(xué), 2009.
[6] 李欣海.隨機(jī)森林模型在分類與回歸分析中的應(yīng)用[J].應(yīng)用昆蟲學(xué)報, 2013, 50(4):1190-1197.
[7] Nataraj L, Karthikeyan S, Jacob G, et al. Malware images:visualization and automatic classification[C]// International Symposium on Visualization for Cyber Security. ACM, 2011:1-7.
[8] Moskovitch R, Feher C, Tzachar N, et al. Unknown Malcode Detection Using OPCODE Representation[C]// Intelligence and Security Informatics, First European Conference, EuroISI 2008, Esbjerg, Denmark, December 3-5, 2008. Proceedings. DBLP, 2008:204-215.
[9] 高程程,惠曉威.基于灰度共生矩陣的紋理特征提取[J].計算機(jī)系統(tǒng)應(yīng)用, 2010, 19(6):195-198.
猜你喜歡
電子技術(shù)與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導(dǎo)刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學(xué)與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(shù)(2016年20期)2016-08-19 18:49:49
電腦知識與技術(shù)(2016年12期)2016-06-14 00:45:31
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 19:17:03
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(shù)(2016年3期)2016-04-07 16:12:55
