時政名人姓名檢測系統(tǒng)的設(shè)計及其在字幕制作中的應(yīng)用
2018-06-26 10:57:50李海彬
視聽 2018年7期
關(guān)鍵詞:檢測
□李海彬
一、引 言
電視時政新聞的采訪對象主要是國內(nèi)外的一些時政名人,為他們出字幕人名條是字幕員的日常工作之一。這個工作看似簡單,然而卻是最容易犯錯誤的地方,特別在大型會議的電視直播過程中,由于值班時間長、制作任務(wù)重等客觀原因,加上心情緊張等主觀因素,會增加人名字幕出錯的概率,從而造成播出安全事故。
如何將此類錯誤發(fā)生的概率降低呢?我們認(rèn)為應(yīng)該通過技術(shù)的手段去解決,而不僅僅只通過人工校對審核的方式,在本文中將介紹自主研發(fā)的一個時政名人姓名檢測系統(tǒng)。
二、立項背景
我臺新聞頻道在某次電視直播中,將某位領(lǐng)導(dǎo)的字幕人名條錯打?yàn)槟趁餍堑拿郑Y(jié)果造成了播出事故。事后經(jīng)分析發(fā)現(xiàn),前線記者在文稿系統(tǒng)中錄入稿件時使用的是拼音輸入法,由于兩個名字的拼音相近而造成原稿存在錯誤,而字幕員將文稿串編單里的新聞標(biāo)題復(fù)制到字幕機(jī)軟件制作人名條時,因?yàn)闄z查上的疏忽而造成了本次事故。
這個教訓(xùn)是深刻的,為了在今后的工作中減少此類事件的發(fā)生,頻道領(lǐng)導(dǎo)認(rèn)為需要建立時政名人姓名檢測系統(tǒng),并根據(jù)字幕員的工作習(xí)慣,要求將此功能集成到新聞文稿系統(tǒng)中。
三、檢錯算法的難點(diǎn)
初步的思路是建立一個時政人名庫,將國家和省內(nèi)主要領(lǐng)導(dǎo)的名字,以及一些外國國家首腦的中文譯名錄入庫中,檢錯系統(tǒng)以此為標(biāo)準(zhǔn)進(jìn)行字符串匹配,將打錯的名字標(biāo)注出來。
假設(shè)某位時政名人的名字為“張小軍”,當(dāng)天有一條關(guān)于他的新聞如“張小軍到北海調(diào)研”,結(jié)果名字中“軍”錯打成“君”,此時系統(tǒng)可以用彩色字體明顯地標(biāo)注出錯之處,如“張小君(紅字顯示)到北海調(diào)研”。
檢錯算法的原理是將人名庫里的名字與新聞標(biāo)題里的內(nèi)容進(jìn)行逐字匹配,從而找出可能錯誤的名字,如果要完成如上的檢測,算法的一般流程如下:
1.將姓名逐字分拆為“張”“小”“軍”三個字;
2.先查找“張”字的位置,在找到后檢測其后的字符是否為“小”及“軍”,從而找到錯誤的位置;
3.如果“張”字沒有找到,就從“小”字開始查找,找到后檢測其后字符是否為“軍”字,如果姓氏出錯了,則報錯。
在姓名由3個文字組成的情況下,這種算法可以檢測出1個文字的錯誤,如“章小軍”“張曉軍”等,而如果出現(xiàn)2個以上的文字錯誤就無法判斷對錯了。對于因拼音輸入法的問題造成兩個名字的中文漢字完全不同時,根本就沒有辦法檢錯。
另外,這種算法存在一個重要的漏洞,即當(dāng)新聞標(biāo)題中未包含人名時,則檢測的結(jié)果也可能會出錯。例如新聞標(biāo)題“我區(qū)邊防某部隊參加國慶60周年大閱兵”,標(biāo)題中并未包含人名,但假如人名庫中存在“李國慶”這樣的名字,此時就會產(chǎn)生錯誤的檢測了。人名庫記錄的人名數(shù)量越多,檢測錯誤的概率就會越高。
因此,在現(xiàn)有的技術(shù)條件下,要完成上面所說的姓名檢錯基本不可能。
四、設(shè)計思路
既然無法完成“姓名檢錯”,那就做一個“姓名檢對”功能,即通過人名庫里的名字,與新聞標(biāo)題進(jìn)行字符串匹配,如果匹配成功則表示名字錄入正確,將正確的名字采用不同的顏色標(biāo)注出來,使字幕員可以一眼分辨出錯對。
假設(shè)人名庫中記錄了這些名字:張福明、劉正軍、馬峰、何洪海。將這些名字與某天的新聞串編單標(biāo)題進(jìn)行逐一匹配,其結(jié)果應(yīng)該如表1所示。

表1 新聞串編單
其中第1~3條匹配成功了;第4條將“何洪海”打錯成了“何紅海”,匹配失敗;第5~6條新聞標(biāo)題中沒有人名庫中的名字,匹配失敗。
實(shí)現(xiàn)這種檢測的軟件算法就簡單多了:將人名庫中的名字分別與新聞串編單的新聞標(biāo)題逐一進(jìn)行匹配,假設(shè)人名庫中的人名數(shù)量為N,新聞條目為M,需要進(jìn)行N×M次檢測即可得到全部檢測結(jié)果。
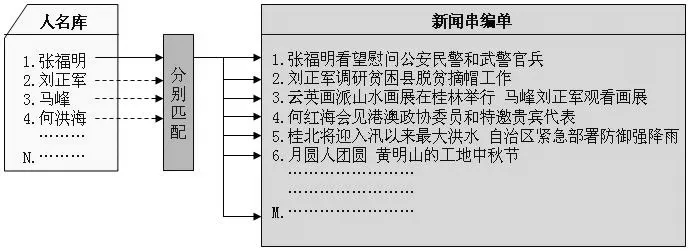
圖1 人名檢測算法
那這種算法的實(shí)際檢測速度如何呢?該系統(tǒng)預(yù)計人名庫的人名數(shù)量小于200,新聞串編單條目小于100,新聞標(biāo)題的平均字符數(shù)小于100字節(jié)。則最多需要檢測200×100=20000次,遍歷字符串總長度為2MB字節(jié),經(jīng)測試其運(yùn)算所需時間非常少,可以忽略不計。
五、實(shí)現(xiàn)方法及效果
(一)建立人名庫
在文稿數(shù)據(jù)庫中增加一個數(shù)據(jù)表,表名為leader,字段如下:Names nchar(20):存儲姓名
BkText ntext:存儲備注信息
增加人名庫編輯模塊,用于動態(tài)更新信息,如圖2。
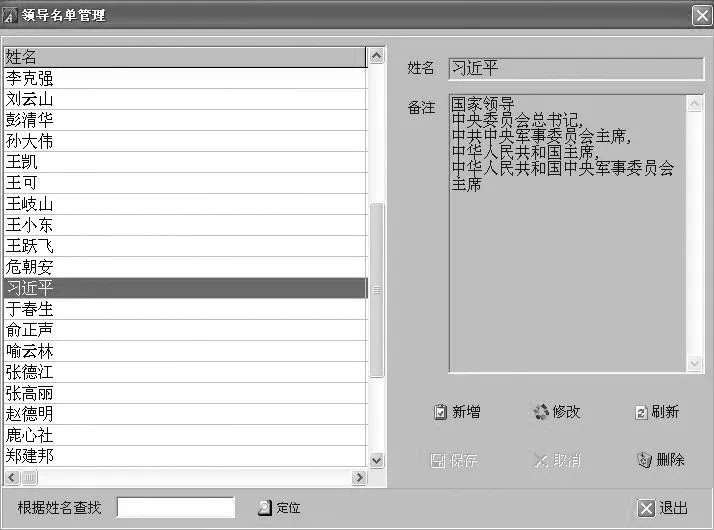
圖2 人名庫編輯管理模塊
(二)檢測及標(biāo)注方法
在完成檢測后,如何將錄入正確的人名區(qū)分出來呢?這里采用HTML網(wǎng)頁封裝方式。即將檢測結(jié)果輸出為HTML文件,對于匹配成功的名字使用紅色字顯示,而其他內(nèi)容使用黑色字顯示。
HTML又稱為超文本標(biāo)記語言,其結(jié)構(gòu)包括“頭”部分和“主體”部分,通過標(biāo)記符號來標(biāo)記要顯示的網(wǎng)頁中的各個部分,其源程序?yàn)槲谋疚募恍枰幾g執(zhí)行,瀏覽器按順序閱讀HTML文件內(nèi)容,然后根據(jù)標(biāo)記符解釋和顯示其標(biāo)記的內(nèi)容。
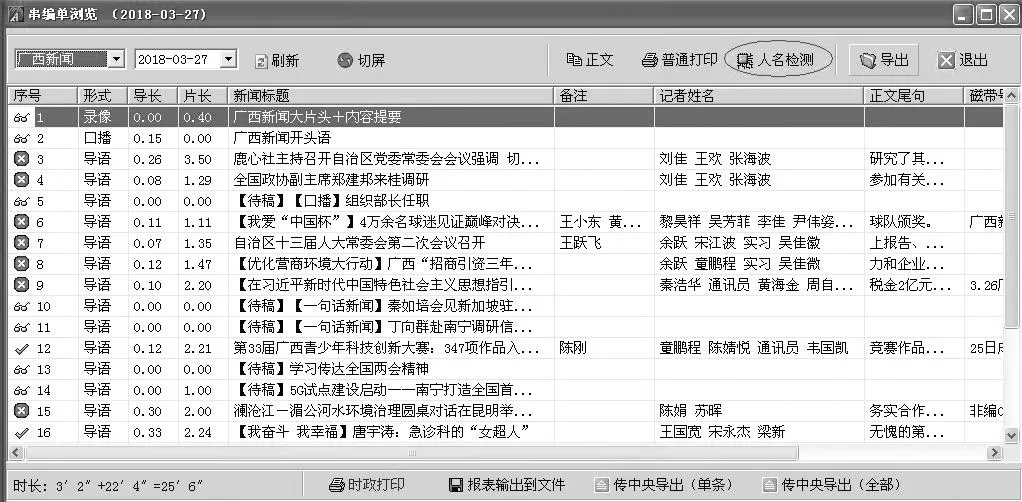
圖3 《廣西新聞》串編單模塊
由于涉及HTML結(jié)構(gòu)的輸出,因此在算法步驟上做了一些改動,首先是將串編單里的全部新聞標(biāo)題進(jìn)行HTML結(jié)構(gòu)封裝,合成為一個長的字符串,之后再進(jìn)行人名匹配和標(biāo)注。在文稿串編單模塊增加一個功能按鈕,如圖3。
點(diǎn)擊“人名檢測”功能按鈕,檢測功能將按以下步驟工作:
1.在內(nèi)存中創(chuàng)建一個最基本的HTML文件頭部結(jié)構(gòu)和表格結(jié)構(gòu):
| 標(biāo)簽封裝為1行2列的表格: |
4.循環(huán)調(diào)取人名庫的每個名字,分別與內(nèi)存中的HTML格式字符串進(jìn)行匹配;
5.將匹配成功的名字進(jìn)行字符串替換,加上字體顏色標(biāo)簽:如“張福明”替換為“”;
6.將內(nèi)存中的HTML格式字符串輸出到文件,通過瀏覽器控件顯示。
執(zhí)行檢測的結(jié)果如圖4。從圖中可以看到,第3、4、9、10、11條新聞標(biāo)題中,成功檢測出人名庫里記錄的名字,并使用紅色字做了標(biāo)注;而第16條新聞標(biāo)題中雖然也出現(xiàn)了一個人名“唐宇濤”,但由于這個名字沒有錄入到人名庫中,因此沒有標(biāo)注出來。

圖4 人名檢測結(jié)果
通過圖4的檢測結(jié)果,字幕員很容易區(qū)分哪些新聞標(biāo)題中時政名人的姓名是正確的,對于沒有提示的新聞標(biāo)題,重點(diǎn)進(jìn)行檢查即可。在確認(rèn)無誤后,即可直接將網(wǎng)頁里的新聞標(biāo)題復(fù)制到字幕軟件中進(jìn)行制作。
六、結(jié)語
檢測系統(tǒng)雖然無法從根本上解決字幕人名條中錯打時政名人名字的問題,但通過對匹配成功的人名進(jìn)行標(biāo)注提示,提高了字幕員人工校對的效率,也大大降低了字幕出錯的概率。檢測系統(tǒng)在2017年10月初建成并投入使用,為2017年十九大、2018年廣西“兩會”和全國“兩會”等重要保障期的新聞安全播出做出了貢獻(xiàn)。
猜你喜歡
中國設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
