基于MapReduce的分布式貪心EM算法*
2018-06-05 11:46:23曹家慶吳觀茂
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2018年5期
關(guān)鍵詞:實(shí)驗(yàn)模型
曹家慶, 吳觀茂
(安徽理工大學(xué) 計(jì)算機(jī)科學(xué)與工程學(xué)院,安徽 淮南 232001)
0 引言
期望最大化算法(Expectation Maximization Algorithm,EM算法)是一種在概率模型中尋找參數(shù)最大似然估計(jì)或者最大后驗(yàn)估計(jì)的迭代算法,可以極大地降低求解最大似然估計(jì)的計(jì)算復(fù)雜度。然而傳統(tǒng)EM算法作為數(shù)據(jù)挖掘中非常重要的聚類(lèi)算法,在面對(duì)TB級(jí)別、PB級(jí)別等大規(guī)模數(shù)據(jù)集和高維數(shù)據(jù)集時(shí),其缺陷顯得越來(lái)越突出。因此如何對(duì)傳統(tǒng)EM算法進(jìn)行優(yōu)化是機(jī)器學(xué)習(xí)算法的研究熱點(diǎn)之一。現(xiàn)階段對(duì)于EM算法優(yōu)化的具體方向便是如何有效地處理如下兩個(gè)問(wèn)題:(1)初始模型成分?jǐn)?shù)目需要人為設(shè)定;(2)收斂速度隨著數(shù)據(jù)規(guī)模的增大而急劇減慢。
針對(duì)上述第一個(gè)問(wèn)題,在傳統(tǒng)EM算法的基礎(chǔ)上使用貪心策略(貪心EM算法),通過(guò)對(duì)僅含一個(gè)模型成分的高斯混合模型迭代增加新模型分量,直到滿(mǎn)足某種終止條件為止。雖然該算法有效地提高了算法的準(zhǔn)確度,但是上述第二個(gè)問(wèn)題仍未得到有效解決。
為了解決上述問(wèn)題,本文提出了一種分布式貪心EM算法。
1 相關(guān)工作
在EM算法和MapReduce的領(lǐng)域內(nèi),國(guó)內(nèi)外已經(jīng)有很多學(xué)者進(jìn)行過(guò)深入的研究,因此本文基于EM算法和MapReduce的相關(guān)工作做進(jìn)一步研究。
1.1 EM算法的相關(guān)工作
文獻(xiàn)[1]中提出了一種基于MapReduce的EM算法,通過(guò)MapReduce的并行化處理解決了傳統(tǒng)EM算法收斂速度隨著數(shù)據(jù)規(guī)模變大而減慢的問(wèn)題,但存在初始模型數(shù)需要預(yù)先設(shè)定的問(wèn)題。文獻(xiàn)[2]中通過(guò)使用牛頓法求解beta分布參數(shù)的算法,并提出一個(gè)合適的初值選擇算法,使得EM算法能夠有效地求解隱回歸模型的參數(shù),但是對(duì)所有的分布都采用beta分布作為自變量的假設(shè)會(huì)帶來(lái)一定的偏差。文獻(xiàn)[3]中提出了一種基于密度檢測(cè)的EM算法,通過(guò)基于密度和距離的方法對(duì)初始值進(jìn)行選擇,降低傳統(tǒng)EM算法的初始值選擇對(duì)收斂效果的影響,但算法性能仍需提高。文獻(xiàn)[4]中提出了一種快速、魯棒的有限高斯混合模型聚類(lèi)算法,通過(guò)對(duì)模型成分混合系數(shù)及樣本所屬成分的概率系數(shù)施加熵懲罰算子的方法,使算法在很少的迭代次數(shù)內(nèi)收斂到確定值,但算法運(yùn)行效率還需進(jìn)一步提高。文獻(xiàn)[5]中提出了一種快速、貪心的高斯混合模型EM算法,通過(guò)采用貪心的策略以及對(duì)隱含參數(shù)設(shè)置適當(dāng)閾值的方法,使算法能快速收斂,并在很少的迭代次數(shù)內(nèi)獲取高斯混合模型的模型成分?jǐn)?shù),但是不能保證有噪聲數(shù)據(jù)集的聚類(lèi)效果。
1.2 MapReduce的相關(guān)工作
文獻(xiàn)[6]中對(duì)Hadoop云平臺(tái)下的聚類(lèi)算法進(jìn)行了研究。文獻(xiàn)[7]中采用MapReduce編程模型,對(duì)特征選擇算法進(jìn)行了研究。文獻(xiàn)[8]中提出了基于MapReduce模型的高效頻繁項(xiàng)集挖掘算法,利用MapReduce框架對(duì)Apriori算法進(jìn)行了改進(jìn),提高了Apriori算法運(yùn)行速度。文獻(xiàn)[9]中提出了一種基于MapReduce的Bagging決策樹(shù)算法,運(yùn)用MapReduce框架對(duì)決策樹(shù)算法進(jìn)行了并行化處理,提高了決策樹(shù)算法對(duì)大數(shù)據(jù)集的分析能力。文獻(xiàn)[10]中提出了一種基于MapReduce的文本聚類(lèi)算法,運(yùn)用MapReduce分布式框架對(duì)K-means算法進(jìn)行了改進(jìn)。文獻(xiàn)[11]中對(duì)MapReduce近年來(lái)在文本處理各個(gè)方面的應(yīng)用進(jìn)行分類(lèi)總結(jié)和處理,并對(duì)MapRedcue的系統(tǒng)和性能方面的研究做了一些介紹。文獻(xiàn)[12]中總結(jié)了近年來(lái)基于MapReduce編程模型的大數(shù)據(jù)處理平臺(tái)與算法的研究進(jìn)展。文獻(xiàn)[13]中基于MapReduce計(jì)算框架,對(duì)傳統(tǒng)蟻群算法進(jìn)行了改進(jìn),使得算法能夠快速有效地處理大規(guī)模數(shù)據(jù)集。
2 分布式貪心EM算法
2.1 貪心EM算法
貪心EM算法的關(guān)鍵是通過(guò)全局搜索將原始數(shù)據(jù)集初始化為一個(gè)僅含有一個(gè)模型分量的高斯混合模型,然后通過(guò)局部搜索逐漸增加新的模型分量到原有的高斯混合模型中,不斷更新混合模型分量的參數(shù)使得似然度最大。算法過(guò)程如下:
假設(shè)樣本集X={x1,x2,x3,…,xm},并服從高斯混合分布,則高斯混合分布的概率密度函數(shù)fk(x)[14]為:
(1)
其中,xi是p維向量,Φj(xi;θj)是第j個(gè)高斯模型分量的概率密度,θj是它的參數(shù),wj是第j個(gè)分量的混合系數(shù),表示第j個(gè)高斯模型分量包含的樣本所占樣本總數(shù)的比例,k是高斯混合模型的模型成分?jǐn)?shù)[15]。θj=(μj,Σj),μj為高斯模型分量均值,Σj為高斯模型分量協(xié)方差矩陣。其中高斯分量概率密度Φj(xi;θj)表達(dá)式為:
(2)
此時(shí)將某一新分量δ(x;θ)加入一個(gè)已有k個(gè)分量的混合密度函數(shù)fk(x),則生成的新的高斯混合模型密度函數(shù)如下式所示:
fk+1(x)=(1-α)fk(x)+αδ(x;θ)
(3)
其中,α是新增模型分量的混合系數(shù),0<α<1。則新生成的對(duì)數(shù)似然函數(shù)為:
(4)
已知新的高斯混合模型包括混合模型分量和新增分量,而混合模型fk(x)已被設(shè)置為不變,所以貪心EM算法的核心就是優(yōu)化新增模型分量的混合系數(shù)α以及新增分量的參數(shù),使新生成對(duì)數(shù)似然函數(shù)Lk+1最大化。所以,首先通過(guò)全局搜索找到一組新增分量的初始參數(shù)μ0、Σ0和α0。在α0處展開(kāi)Lk+1的二階泰勒公式并且最大化關(guān)于α的二次函數(shù)得到似然函數(shù)的一個(gè)近似:
(5)
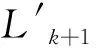
(6)
則Lk+1在α0=0.5附近的對(duì)數(shù)似然局部最優(yōu)可以寫(xiě)成:
(7)
(8)
在求出新增模型分量估計(jì)值之后,通過(guò)傳統(tǒng)EM算法可得:
(9)
(10)
通過(guò)公式迭代獲取新增模型參數(shù)最優(yōu)解{αk+1,μk+1,Σk+1},從而獲取新的高斯混合模型的對(duì)數(shù)似然函數(shù)值Lk+1。
2.2 分布式貪心EM算法
依據(jù)MapReduce的框架結(jié)構(gòu),在設(shè)計(jì)分布式貪心EM算法時(shí),首要的考慮便是定義Map函數(shù)和Reduce函數(shù)。算法過(guò)程如下:
(1)Mapper階段
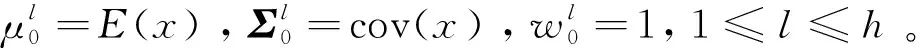
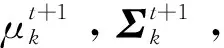
(2)Reducer階段
步驟三:將所有節(jié)點(diǎn)得到的鍵值對(duì)進(jìn)行整合,將高斯混合模型密度函數(shù)進(jìn)行求和,然后再取對(duì)數(shù),得到整合后的對(duì)數(shù)似然函數(shù)為:
(11)
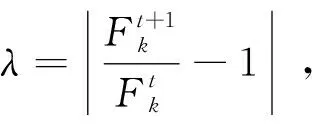
步驟五:判斷滿(mǎn)足收斂條件的Fk是否滿(mǎn)足Fk+1≤Fk,如不滿(mǎn)足則重新進(jìn)行步驟一,如果滿(mǎn)足則結(jié)束算法,輸出理想模型成分?jǐn)?shù)k。
具體算法流程如下所示:
算法:分布式貪心EM算法
輸入:樣本集X={x1,x2,x3,…,xm}
輸出:高斯混合模型理想模型成分?jǐn)?shù)k
1 將數(shù)據(jù)集平均分配到h個(gè)節(jié)點(diǎn)中
2 While(true)
3 對(duì)于每個(gè)節(jié)點(diǎn):
4 初始化節(jié)點(diǎn),設(shè)置迭代次數(shù)ε=1
9 ifλ<10-6,則收斂結(jié)束
10 else跳轉(zhuǎn)到步驟4,ε+1
11 end if
12 ifFk+1≤Fk,輸出理想模型成分?jǐn)?shù)為k,break
13 else跳轉(zhuǎn)到步驟2。
14 end if
15 end while
本算法主要是在Map(映射)、Reduce(歸化)、判斷的過(guò)程中得到最優(yōu)的最大似然Fk,從而得到理想模型成分值k。
上述算法中,步驟1~7為Mapper階段,首先對(duì)每個(gè)節(jié)點(diǎn)初始化高斯混合模型參數(shù),然后通過(guò)更新參數(shù)得到最新的高斯混合模型密度函數(shù),最后將數(shù)據(jù)映射處理并生成相應(yīng)的鍵值對(duì),并作為Reducer階段的輸入。步驟8~11為Reducer階段,此階段是將Mapper階段傳遞過(guò)來(lái)的鍵值對(duì)進(jìn)行整合得到Fk,再利用判斷因子λ判斷是否滿(mǎn)足收斂條件,當(dāng)λ<10-6時(shí),F(xiàn)k達(dá)到收斂值,迭代結(jié)束。步驟12~15,因?yàn)樵趯?duì)原高斯混合模型添加新模型分量的過(guò)程中,數(shù)據(jù)集的對(duì)數(shù)似然函數(shù)值呈逐漸增長(zhǎng)的趨勢(shì),所以當(dāng)高斯混合模型的對(duì)數(shù)似然函數(shù)取得最大值,即當(dāng)Fk+1≤Fk時(shí),F(xiàn)k為收斂值,即為最優(yōu)解,則算法循環(huán)結(jié)束,k即為理想模型成分?jǐn)?shù)。
算法復(fù)雜度分析如下:
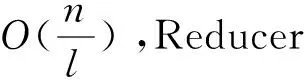
3 實(shí)驗(yàn)結(jié)果與分析
3.1 實(shí)驗(yàn)環(huán)境
整個(gè)實(shí)驗(yàn)是在Hadoop平臺(tái)下進(jìn)行的,所用的版本為Hadoop2.6.5。每臺(tái)主機(jī)系統(tǒng)使用的是Unbuntu14.04版本。建立的集群由1個(gè)主節(jié)點(diǎn)、4個(gè)從節(jié)點(diǎn)組成。所有節(jié)點(diǎn)的硬件設(shè)備為聯(lián)想主機(jī),其中使用了主頻為3.3 GHz的Intel四核處理器,內(nèi)存為2 GB。
3.2 實(shí)驗(yàn)數(shù)據(jù)
實(shí)驗(yàn)數(shù)據(jù)來(lái)自UCI機(jī)器學(xué)習(xí)和知識(shí)發(fā)現(xiàn)研究中使用的大型數(shù)據(jù)集KDD數(shù)據(jù)庫(kù)存儲(chǔ)庫(kù)。其中第一組數(shù)據(jù)大小為0.6 GB,包含200個(gè)數(shù)據(jù),模型成分?jǐn)?shù)為9;第二組數(shù)據(jù)大小為1.4 GB,包含500個(gè)數(shù)據(jù),模型成分?jǐn)?shù)為9;第三組數(shù)據(jù)大小為2.0 GB,包含1 000個(gè)數(shù)據(jù),模型成分?jǐn)?shù)為15;第四組數(shù)據(jù)大小為3.2 GB,包含1 500個(gè)數(shù)據(jù),模型成分?jǐn)?shù)為15。
3.3 實(shí)驗(yàn)結(jié)果及分析
3.3.1運(yùn)行時(shí)間
將本文算法與傳統(tǒng)EM算法、貪心EM算法在求解高斯混合模型理想成分?jǐn)?shù)的時(shí)間上作比較。固定節(jié)點(diǎn)個(gè)數(shù)為8個(gè),分別使用本文算法、傳統(tǒng)EM算法、貪心算法對(duì)4組實(shí)驗(yàn)試驗(yàn)數(shù)據(jù)求解高斯混合模型的成分?jǐn)?shù),并進(jìn)行時(shí)間對(duì)比,實(shí)驗(yàn)結(jié)果如圖1所示。
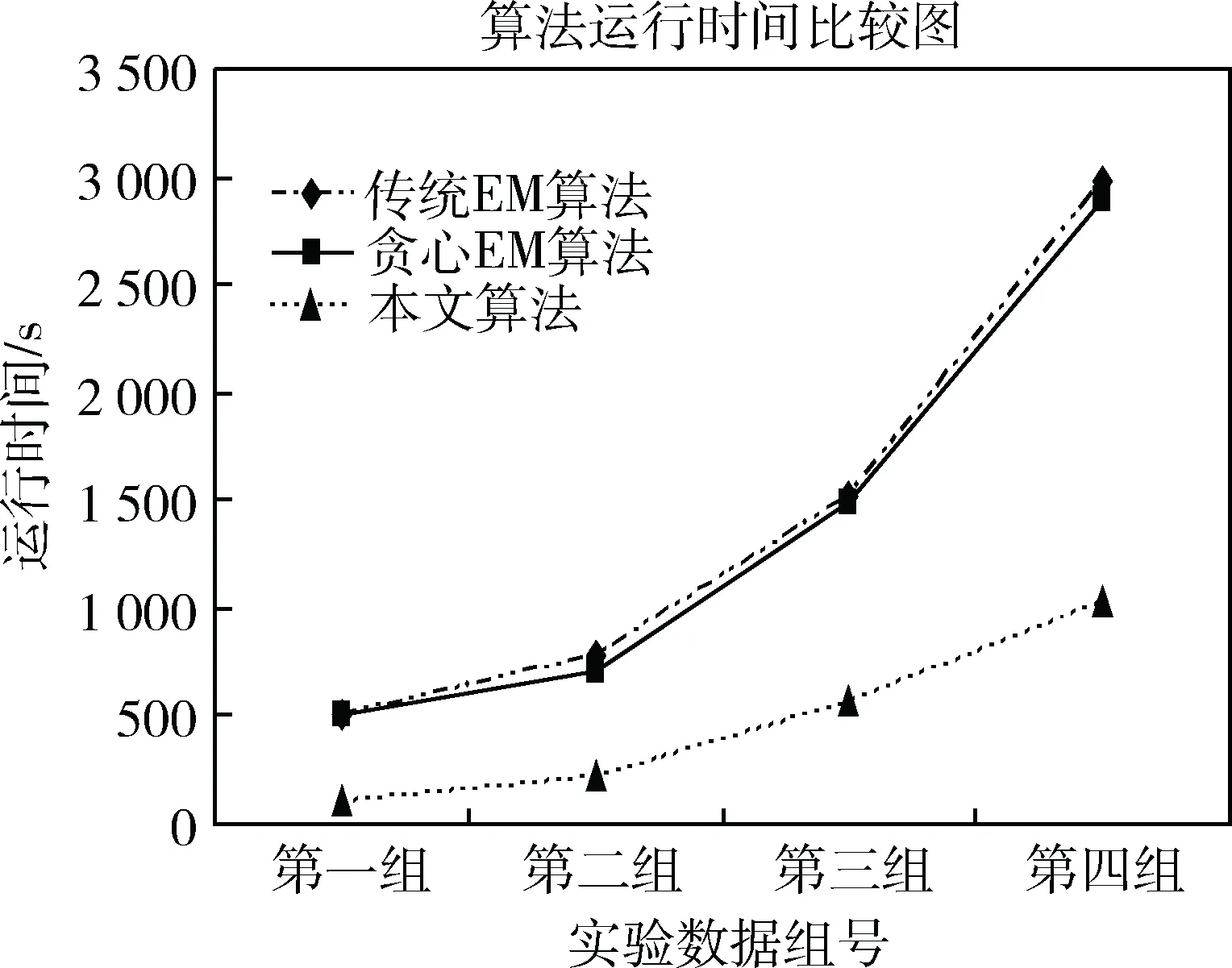
圖1 算法運(yùn)行時(shí)間比較圖
三種算法下對(duì)于第一組和第二組實(shí)驗(yàn)輸出模型成分?jǐn)?shù)都為9,第三組和第四組實(shí)驗(yàn)輸出模型成分?jǐn)?shù)都為15,輸出結(jié)果正確。由圖1可以看出,對(duì)于這4組實(shí)驗(yàn)數(shù)據(jù),本文算法相對(duì)于傳統(tǒng)EM算法以及貪心EM算法在處理數(shù)據(jù)集時(shí)運(yùn)行時(shí)間大幅減少,當(dāng)數(shù)據(jù)規(guī)模更大時(shí),速度優(yōu)勢(shì)更為明顯,同時(shí)可以看出,隨著數(shù)據(jù)集的變大,本文算法的運(yùn)行時(shí)間基本呈線性增長(zhǎng),具有較好的數(shù)據(jù)可擴(kuò)展性。
3.3.2系統(tǒng)的可擴(kuò)展性
實(shí)驗(yàn)二通過(guò)改變節(jié)點(diǎn)個(gè)數(shù),設(shè)置節(jié)點(diǎn)數(shù)分別為2,4,6,8,觀察本文算法下求解4組數(shù)據(jù)的模型成分?jǐn)?shù)的時(shí)間變化,實(shí)驗(yàn)結(jié)果如圖2所示。
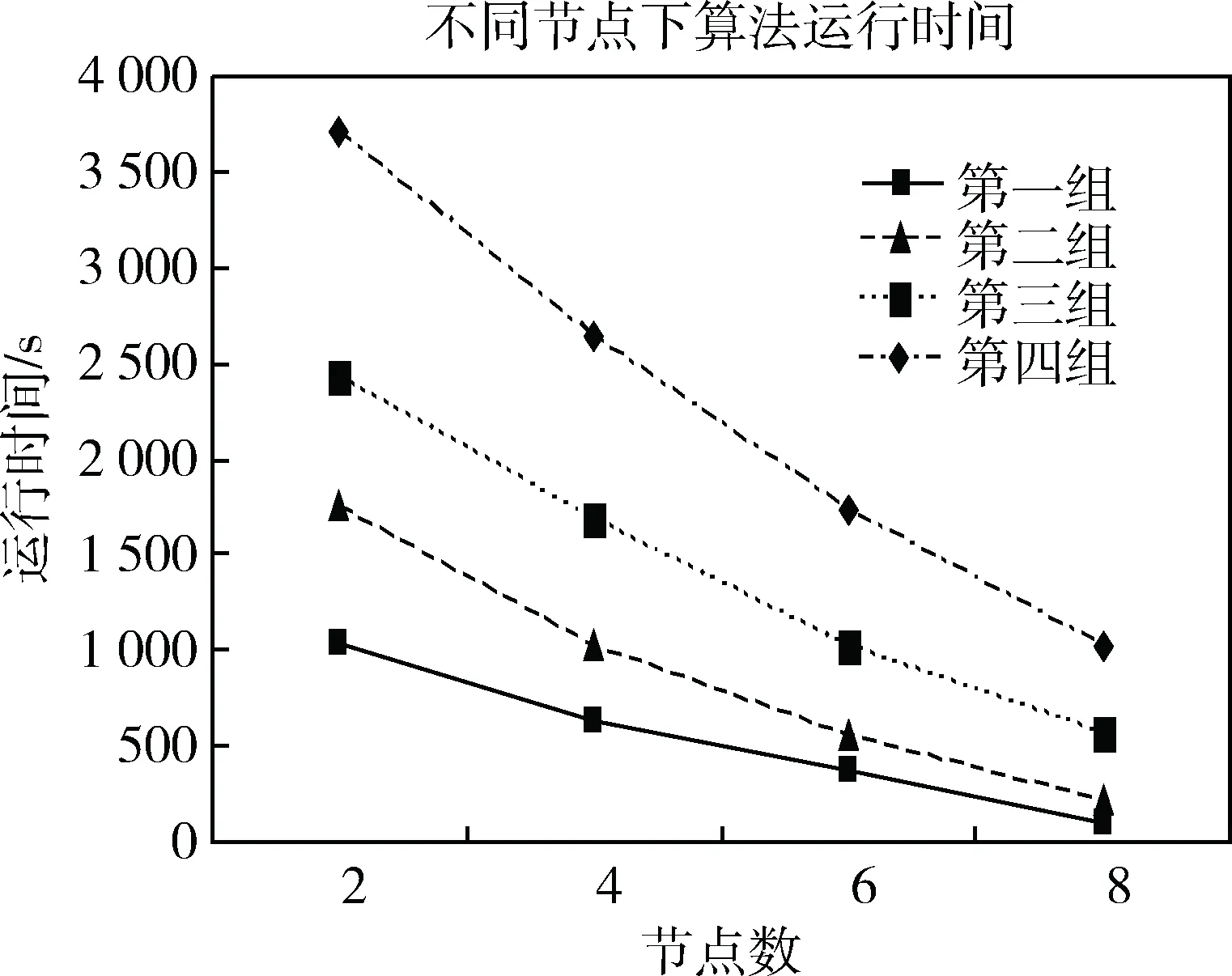
圖2 不同節(jié)點(diǎn)下算法運(yùn)行時(shí)間
由圖2可以看出,隨著節(jié)點(diǎn)數(shù)的增加,本文算法運(yùn)行時(shí)間逐漸減少,因此可以通過(guò)增加計(jì)算節(jié)點(diǎn)的個(gè)數(shù)來(lái)增加本算法運(yùn)行速度。同時(shí)在數(shù)據(jù)集較小的時(shí)候,隨著節(jié)點(diǎn)數(shù)的增加,算法運(yùn)行時(shí)間減少的幅度非常小,這是由于在小規(guī)模數(shù)據(jù)集下算法迭代計(jì)算的時(shí)間很小,時(shí)間大部分都花費(fèi)在節(jié)點(diǎn)與節(jié)點(diǎn)之間的通信上。
4 結(jié)論
本文在貪心EM算法的基礎(chǔ)上,提出了一種基于MapReduce分布式框架的貪心EM算法,該算法在保證了無(wú)需預(yù)先指定初始模型成分?jǐn)?shù)目并能準(zhǔn)確得到模型成分?jǐn)?shù)的前提下,極大地提高了處理大數(shù)據(jù)集時(shí)的收斂速度。實(shí)驗(yàn)結(jié)果與分析表明,本文算法較之傳統(tǒng)EM算法和貪心EM算法在處理大規(guī)模數(shù)據(jù)上有明顯的加速效果,并且隨著節(jié)點(diǎn)數(shù)的增加可以進(jìn)一步提高收斂速度,并且具有很好的擴(kuò)展性。實(shí)驗(yàn)僅對(duì)求解高斯混合模型的模型成分?jǐn)?shù)的時(shí)間進(jìn)行了對(duì)比,并未對(duì)聚類(lèi)的準(zhǔn)確度進(jìn)行實(shí)驗(yàn),因此后續(xù)研究者可以就高斯混合模型聚類(lèi)的準(zhǔn)確度作進(jìn)一步研究。
[1] 胡愛(ài)娜. 基于MapReduce的分布式EM算法的研究與應(yīng)用[J]. 科技通報(bào), 2013(6):68-70.
[2] 韓忠明, 呂濤, 張慧,等. 帶隱變量的回歸模型EM算法[J]. 計(jì)算機(jī)科學(xué), 2014, 41(2):136-140.
[3] 戴月明, 張朋, 吳定會(huì). 基于密度檢測(cè)的EM算法[J]. 計(jì)算機(jī)應(yīng)用研究, 2016, 33(9):2697-2700.
[4] 胡慶輝, 丁立新, 陸玉靖,等. 一種快速、魯棒的有限高斯混合模型聚類(lèi)算法[J]. 計(jì)算機(jī)科學(xué), 2013, 40(8):191-195.
[5] 邢長(zhǎng)征, 苑聰. 一種快速、貪心的高斯混合模型EM算法研究[J]. 計(jì)算機(jī)工程與應(yīng)用, 2015, 51(20):111-115.
[6] 譚躍生, 楊寶光, 王靜宇,等. Hadoop云平臺(tái)下的聚類(lèi)算法研究[J]. 計(jì)算機(jī)工程與設(shè)計(jì), 2014, 35(5):1683-1687.
[7] 陸江, 李云. 基于MapReduce的特征選擇并行化研究[J]. 計(jì)算機(jī)科學(xué), 2015, 42(8):44-47.
[8] 朱坤, 黃瑞章, 張娜娜. 一種基于MapReduce模型的高效頻繁項(xiàng)集挖掘算法[J]. 計(jì)算機(jī)科學(xué), 2017, 44(7):31-37.
[9] 張?jiān)Q, 陳苗, 陸佳煒,等. 基于MapReduce的Bagging決策樹(shù)優(yōu)化算法[J]. 計(jì)算機(jī)工程與科學(xué), 2017, 39(5):841-848.
[10] 李釗, 李曉, 王春梅,等. 一種基于MapReduce的文本聚類(lèi)方法研究[J]. 計(jì)算機(jī)科學(xué), 2016, 43(1):246-250.
[11] 李銳, 王斌. 文本處理中的MapReduce技術(shù)[J]. 中文信息學(xué)報(bào), 2012, 26(4):9-20.
[12] 宋杰, 孫宗哲, 毛克明,等. MapReduce大數(shù)據(jù)處理平臺(tái)與算法研究進(jìn)展[J]. 軟件學(xué)報(bào), 2017, 28(3):514-543.
[13] 凌海峰, 劉超超. 基于MapReduce框架的并行蟻群優(yōu)化聚類(lèi)算法[J]. 計(jì)算機(jī)工程, 2015, 41(8):168-173.
[14] 馬江洪,葛詠,圖像線狀模式的有限混合模型及其EM算法[J].計(jì)算機(jī)學(xué)報(bào),2007,30(2):288-296.
[15] 李斌,鐘潤(rùn)添,王先基,等. 一種基于遞增估計(jì)GMM的連續(xù)優(yōu)化算法[J].計(jì)算機(jī)學(xué)報(bào),2007,30(6):979-985.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫(huà)刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
