改進的多目標回歸實時人臉檢測算法
2018-06-01 10:49:58吳志洋廖生輝
計算機工程與應用 2018年11期
吳志洋,卓 勇,廖生輝
WU Zhiyang,ZHUO Yong,LIAO Shenghui
廈門大學 航空航天學院,福建 廈門 361005
College of Aerospace Engineering,Xiamen University,Xiamen,Fujian 361005,China
1 引言
人臉檢測是計算機視覺和模式識別中一個重要而又基礎的研究,同時也是眾多跟人臉相關應用的關鍵環節,比如人臉識別、人證比對等。傳統計算機領域的研究者對人臉檢測的研究主要集中在人工設計特征提取器,如SIFT[1]、HOG[2]用傳統的機器學習算法訓練有效的分類器來進行圖像中的人臉檢測和識別任務。這樣的方法要求研究人員必須手工提取到有效的特征,然后對每個部分分別進行優化,這導致了在檢測過程中得到的往往是局部最優而不是全局最優。基于Adaboost[3]的傳統人臉檢測算法現階段在速度上仍然具有明顯優勢,而深度學習方法在檢測的準確率上則可以取得更好的性能表現,比如,在人臉測評數據集FDDB[4]上,傳統方法只有85%的準確率,而深度學習方法已超過95%,包括人臉識別的深度學習方法[5]也取得了極大進展。因此,基于深度學習的人臉檢測方法已經成為當前的研究主流。
目前,基于深度學習的主流方法可以總結為三個步驟:首先,從一張圖片中提取目標候選區,常用的方法有Selective Search[6]等;然后,把這些提取到的候選區送入一個卷積神經網絡中進行識別或者分類;最后,對某些分類結果的候選區進行邊框微調。對于以上的三個環節,其中的瓶頸在于候選區的提取,即第一個環節,這個環節同時制約著物體檢測的準確率與檢測速度。一方面,由于候選區提取環節是基于低級的語義特征的,且傳統的區域推薦算法對局部外觀變化敏感,導致了算法在許多情況下會失效,比如物體遮擋等情況;另一方面,大量的區域推薦算法基于圖像分割[6]或者是稠密的滑動窗口形式[7],這帶來了龐大的計算量,使得算法無法在實時的物體檢測系統中得到應用。
為了克服這些缺陷,近幾年出現了一系列改進的深度學習算法,大大加速了區域推薦環節。Zhang Xiang[8]等為檢測的目標訓練一個分類器,用一種高效的滑動窗口的方式遍歷多張不同尺寸的圖像,實現了物體的分類與定位,由于檢測器需要在圖像金字塔上面遍歷所有層級的圖像,當層級過多時,將耗費大量的計算時間,而當層級太少時,檢測效果則會明顯下降;Girshick R等[9]提出了R-CNN方法,該方法首先在一張圖像上產生2 000個候選區域,然后把這些區域送入SVM分類器,最后把含有物體的區域傳入下一個網絡進行邊框的回歸,這種復雜的方式導致檢測速度慢,且每個部分是獨立訓練的,造成優化十分困難;為了克服這些問題,Ren S等[10]提出了Faster R-CNN方法,在生成候選框的部分采用一個淺層的全卷積網絡RPN在每張圖像上生成約300個候選框,但是由于這些候選框的尺度和比例是提前設計好的,且是固定的,這就造成了當圖像中物體尺寸范圍波動較大時,RPN網絡表現不理想;Redmon J等[11]把物體檢測看作是一個簡單的回歸問題,把圖片劃分成7×7的網格,直接回歸出每個物體的種類與邊框,且不需要圖像金字塔,因而在檢測速度方面具有十分明顯的優勢。然而,該方法對物體邊框信息的四個變量用L2損失函數(平方誤差)分別進行回歸,這種過于簡單的方式割裂了四個位置變量之間的關系,導致在物體定位上效果不夠理想且網絡訓練不易收斂,而Jiang Y等[12]提出了IoU Loss避免了L2損失函數的缺陷,但在檢測速度上卻達不到實時性,很難應用于實際的工程項目。
本文受回歸思想與IoU Loss的啟發,創造性地提出了結合回歸思想與檢測評價函數IoU作為損失函數的人臉檢測算法,該算法與傳統算法以及經典深度學習算法相比具有如下3個優點:
(1)應用卷積神經網絡能夠自動學習到數據中的特征,比傳統的人工設計特征更加有效。
(2)融合IoU函數克服了實時多目標回歸算法變量分離的缺陷,使得模型的代價函數更加合理,不僅使原有的多目標回歸算法在檢測不同尺度的人臉時更加魯棒,而且使得深度網絡的訓練更加容易收斂。
(3)不需要采用圖片金字塔的方式,只需處理一個層級的圖片,較好地權衡了算法的檢測速度與檢測精度。
2 相關算法與分析
2.1 實時多目標回歸算法YOLO
YOLO是Redmon J等[11]提出的一種通用物體檢測深度卷積神經網絡模型,它主要由24個卷積層、4個最大池化層、2個全連接層、L2損失函數層組成,如圖1所示。圖中省略了激活函數層、Batch Normalization(BN)層[13],其中C代表卷積層,P代表最大池化層,FC代表全連接層,L2 Loss代表平方損失層,且在所有的卷積層、倒數第二個全連接層后附加Leaky[11]激活函數層,所有卷積層之前帶有BN層。

圖1 網絡結構示意圖(省略了激活函數層、BN層)
YOLO把物體檢測分開的幾個部分整合到一個深度卷積神經網絡中,整體流程如圖2所示,該方法把一張圖片分割成7×7個小網格,然后每個網格回歸出兩個包圍框,最后用NMS[14]算法合并多余的人臉框,得到最終的人臉區域。
其損失函數定義如下:
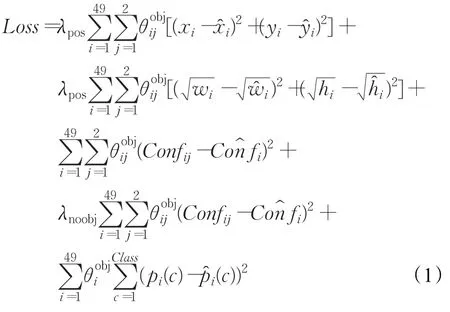

圖2 多目標回歸算法示意圖
其中,Loss表示網絡的損失值;λpos=5;λnoobj=1;表示第i個網格中的第 j個包圍框含有物體中心,當有物體中心時,=1,否則=0;表示第i個網格是否含有物體中心,如果有物體中心時,=1,否則為0;xi、yi表示預測出來的包圍框中心點坐標相對于網格的大小;、表示訓練圖片中標記的物體邊框的中心點坐標相對于網格的大小;wi、hi表示預測出來的包圍框的寬和高相對于整張圖片的大小;、表示訓練圖片中標記的物體邊框的寬和高相對于圖片的大小;Confij、Cofij分別表示第i個網格中預測的第 j個包圍框的置信度與第i個網格訓練圖片標注的置信度;pi(c),(c)分別表示第i個網格預測出的類別概率和訓練數據標注的類別概率,其中位置參數如圖3示。
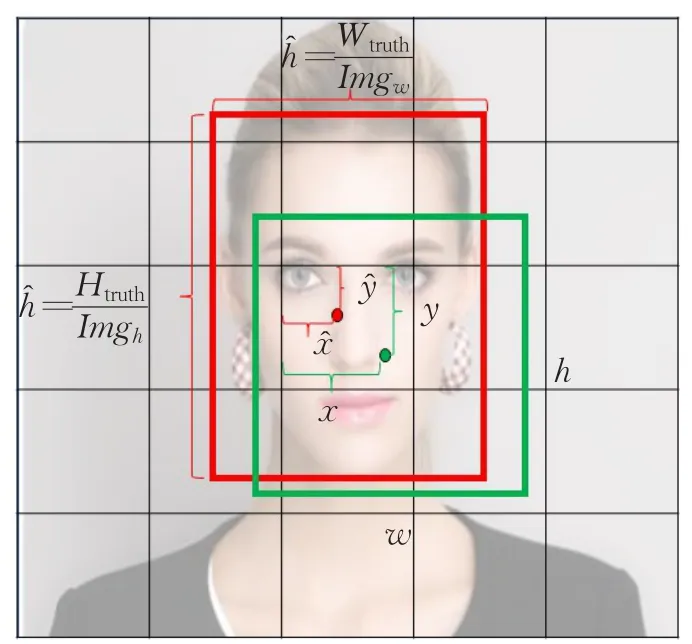
圖3 位置參數示意圖
2.2 YOLO算法缺陷分析
檢測評價函數IoU(Intersection over Union)是被用來評價模型檢測效果好壞的一個標準,表示的是兩個框的交集I和并集U的比例,如圖4所示:重疊程度越高,IoU值越大。其中紅色框是標注框,綠色框是預測框,IoU函數表達式為IoU=I/U。
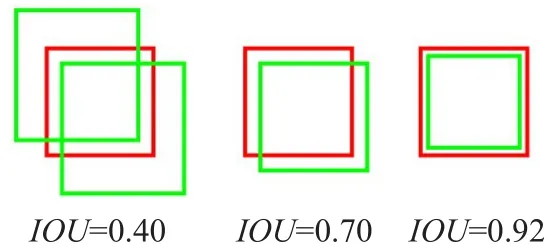
圖4 IoU示意圖
通過式(1)所示:模型的預測框參數x,y,w,h通過L2損失函數獨立進行優化,這樣的方式割裂了四個位置參數之間的強相關性。可以得出:
(1)在相同IoU的條件下,理論上網絡損失函數的貢獻應該是均等的,但當用L2損失函數時,如圖5所示,尺度大的人臉對損失函數所產生的誤差將大大超過小尺度人臉所產生的誤差,導致深度網絡在訓練時,更加偏向于尺度較大的人臉,而容易忽略尺度較小的人臉,這對于網絡的收斂以及模型的檢測效果都將帶來負面影響。

圖5 相同IoU下的大小人臉
(2)人臉數據集中人臉尺寸的跨度較大,且小人臉占了一定的比例,在FDDB[4]中,分辨率為40×40的小人臉占到10%左右,在Wider Face[14]中則占到33%左右,也就意味著(1)中所分析的情況,如果采用L2 Loss,則帶來的缺陷是不可避免的。
(3)當單獨優化各個位置參數時,容易導致僅有部分變量回歸正確,如圖6所示,回歸出的人臉區域(綠色)僅有人臉區域的左上角坐標回歸正確,而無法完全正確回歸出整個人臉位置。
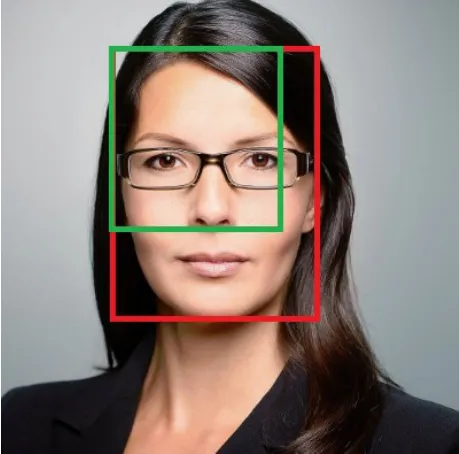
圖6 位置參數單獨優化的缺陷
3 融合多目標回歸與IoU損失的人臉檢測算法MIFD(Multi-objective regression with IoU loss Face Detection)
3.1 算法的實時性分析
基于卷積神經網絡的人臉檢測算法在檢測的準確程度上比傳統人臉檢測算法有較大的優勢,而在檢測速度上,大多數深度學習算法卻達不到實時性。
如基于Faster RCNN[14]的人臉檢測,其不能達到實時的核心問題在于人臉推薦區域的環節上,其設計相當于是用一個滑動窗口對最后的特征圖上的每一個位置都進行了估計,每個位置上預測9種不同尺度的候選區域,一張圖片約推薦2 000個候選區,代價在于采用滑動窗口的方式十分耗時,且推薦了過多的候選區,而這些候選區還要進入下一級網絡再次進行特征提取;DenseBox[15]與Overfeat[8]則需要通過構建多個層級的圖像金字塔來保證檢測效果,由于要處理多張圖像,將帶來巨大的計算量;Unibox[12]提出了一種不需要圖像金字塔的人臉檢測策略,通過對圖像中的每一個像素進行分類(人臉與非人臉),以及在每一個像素預測出距離人臉邊界的距離,通過獲取人臉置信度大于閾值的像素以及該像素對應的邊界距離來實現人臉檢測,但由于其對像素的分類提取的是網絡的淺層特征,往往會得到過多被預測為人臉的像素,遍歷這些像素需要較多的計算時間。
在多目標回歸算法中,直接將輸入圖像劃分為7×7個網格,每個網格預測2個人臉區域,共有98個候選區,相比于Faster RCNN,這種網格劃分的方式在獲取候選區方面,速度上有著巨大的優勢;相比于DenseBox與Overfeat,多目標回歸算法則不需要構建圖像金字塔;相比于Unibox,多目標回歸算法則直接對這98個候選框進行位置參數的調整,并不會產生不可預估的大量候選區。
為了實現實時檢測的目的,本文選擇多目標回歸的機制進行人臉檢測。
3.2 改進思路
基于2.2節的算法缺陷分析,本文擬作如下改進:
首先,發現IoU函數在面對任意尺度的人臉時,當人臉預測框與標注框(ground truth)具有相同的重合效果時,其IoU值是一致的,如果用IoU函數來作為位置參數的損失函數,將能夠避免2.2節中(1)、(2)所分析的缺陷,即克服了不同人臉尺度帶來誤差不均衡的問題。
其次,從2.1節式(1)中截取了部分關于位置參數的L2損失函數,令,則,可以看出 xi,yi的梯度并無牽連。當用IoU作為損失函數時,如果一個網格中包含物體中心,其IoU值應為1,當不包含物體中心時,其IoU值應為0,因此,將該輸出情況看作0~1分布,引入交叉熵損失函數來對IoU進行優化,約束模型的輸出分布與訓練數據標簽分布的一致性。設期望的輸出分布為 p,則在含有物體中心的網格,p=1,則交叉熵損失函數為:J2=-pln(IoU)-(1-p)ln(1-IoU)=-ln(IoU),對 J2求導數得:

從式(2)可以看出,各個變量的梯度都是關于xi,yi,,的函數,即網絡在更新參數時,是進行聯動更新,而非獨立優化四個位置參數,更具體的求導公式參考3.2節。
此外,由于IoU的取值范圍為[0,1],自動地將任意尺度的輸入數據標簽進行了歸一化處理。
3.2.1 IoU函數前向傳播算法
前向傳播算法如下所示。
前向傳播算法(Forward)步驟如下:
輸入:G表示訓練樣本中的標注框
P表示模型預測出的包圍框
輸出:L表示位置參數的損失
步驟1:對含有物體中心的網格進行如下計算:
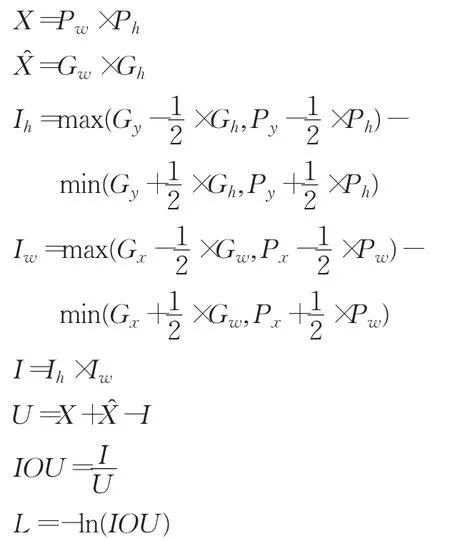
步驟2:對不含物體中心的網格:
L=0
其中,X表示預測出的包圍框的面積;X表示訓練標注框的面積;Gx、Gy、Px、Py分別表示預測出的包圍框和訓練標注框的中心點坐標值;Gw、Gh、Pw、Ph分別表示預測出的包圍框和訓練標注框的寬和高;I表示預測框與標注框的交集;U表示預測框與標注框的并集;Iw、Ih表示預測框和標注框交集部分的寬和高,參考圖3。
3.2.2 IoU函數反向傳播算法
為了更簡潔地描述反向傳播算法的計算公式,本文進行了相應的符號規定:?pI表示I對P中任意一個參數的偏導數,即 ?pI為?pxI、?pyI、?pwI、?phI中任意一個;?pX表示X對P中任意一個參數的偏導數;且令:
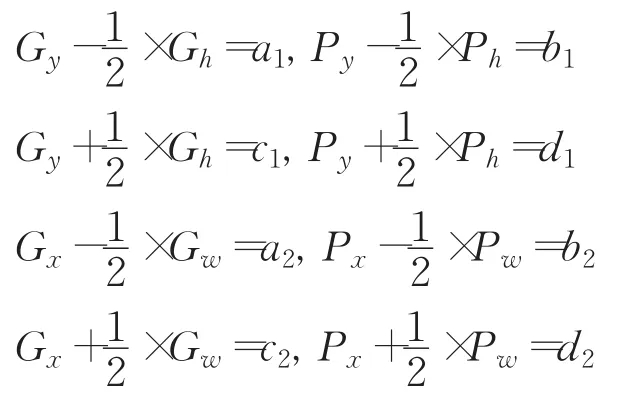
則位置信息損失函數L對預測框的梯度為:
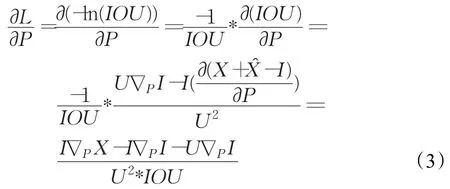
其中,
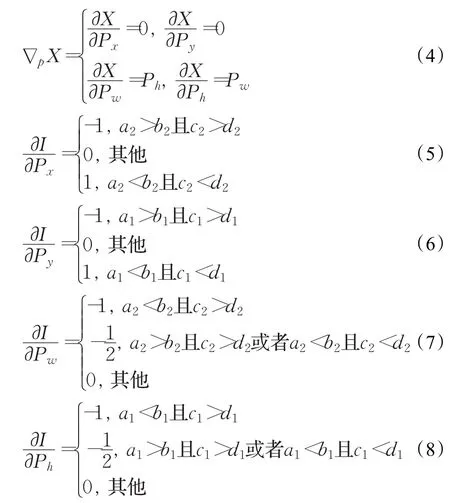
式(3)~(8)即為隨機梯度下降算法的深度網絡位置參數的學習算法。
3.3 深度網絡結構MIFD及整體損失函數IoU Loss
本文基于實時多目標回歸模型YOLO,融合IoU函數,構建了本文的模型結構,如圖7所示。
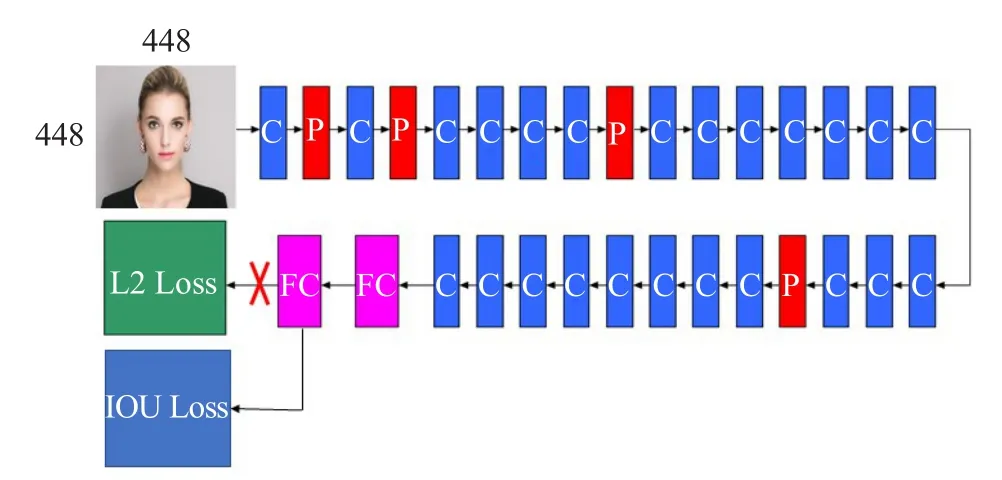
圖7 本文提出的網絡結構MIFD示意圖
IoU Loss定義如下:

其中,ln(IOUij)表示取第i個網格的第 j個包圍框與標注信息IoU的對數值,其余參數的含義與取值參考公式(1)中的相關說明。
4 實驗結果與分析
4.1 模型訓練策略
實驗建立在64位的Linux操作系統和NVIDIA GTX Geforce 1080 GPU的服務器上,采用的深度學習框為caffe,下載地址為:https://github.com/BVLC/caffe,相關軟件有Python2.7版本、Matlab2014b版本。
為驗證本文提出的算法MIFD在圖像中人臉檢測的有效性,采用的數據集為香港中文大學公開的人臉檢測基準數據集Wider Face[16],有32 203張圖片,共包含393 703張人臉,全部手工標注,標注的人臉有較大程度的尺寸、姿態和遮擋等變化。另一個數據集為馬薩諸塞大學計算機系維護的一套公開數據庫FDDB[4],共有2 845張圖片包含5 171張人臉,涵蓋了在自然環境下的各種姿態的人臉。Wider Face分為2個部分,分別用于訓練集、驗證集,FDDB為測試集。
為了方便本文提出的算法MIFD與YOLO的算法對比,訓練兩個模型時,采取了相同的訓練數據與訓練策略,圖片均劃分為11×11個網格。將每張訓練圖片隨機截取面積不小于圖片面積70%,舍棄殘缺的標注框,對保留下來的框的坐標進行相應的變換,然后截取的區域縮放到448×448,作為數據增強的手段,來減小過擬合。初始學習率(learning rate)設置為1×10-5,每個批次的圖片數量(batch size)為32,網絡從YOLO的原始模型獲得初始權重,采用隨機優化算法Adam[17]進行網絡訓練。
4.2 實驗結果與分析
4.2.1 MIFD與YOLO的性能對比
圖8為本文算法MIFD和YOLO算法的人臉檢測效果圖,可以看到:YOLO采用了L2 Loss,在面對不同尺度的人臉時,本文提出的MIFD更具魯棒性;L2 Loss不采用位置參數聯合優化的方式,雖然能夠將某些尺度下的人臉框住,但是框住人臉的準確程度卻不如IOU Loss。

圖8 檢測結果圖
為進一步比較本文算法與基礎算法的性能,本文將兩個模型在人臉數據庫FDDB上進行測試,繪制ROC曲線(圖9),并給出模型訓練時Loss的收斂情況(圖10)。
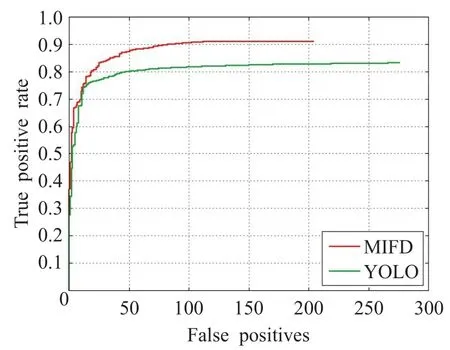
圖9 MIFD與YOLO的ROC曲線對比

圖10 訓練情況對比
如圖9所示,橫軸表示圖像中非人臉區域被誤檢為人臉的數量,YOLO的誤檢數量為275,MIFD的誤檢數量為205,誤檢率降低了(275-205)/275=24.5%;縱軸表示人臉區域被正確檢出的比例,YOLO為82.5%,MIFD達到91.2%,準確率提高了91.2%-82.5%=8.7%;如圖10所示,橫坐標代表訓練迭代次數,縱坐標代表訓練過程中的Loss值,可以看出,MIFD最終的loss比YOLO模型的更小,且更為穩定,充分說明了本文算法在加快訓練收斂的有效性。
4.2.2 MIFD與傳統主流人臉檢測算法Adaboost的對比
基于Opencv庫的Adaboost分類器,在CPU模式下進行對比分析。從FDDB人臉庫中隨機抽取1 000張圖片,共含有1 605張人臉,進行算法性能比較。
從表1可以得出,本文提出的方法相比于傳統的人臉檢測算法Adaboost,檢測精度上:準確率提升了7.9%,漏檢率減少了7.88%,誤檢率減少了30.5%;檢測速度上:Adaboost則具有明顯的優勢,MIFD可通過GPU加速來彌補檢測速度上的不足。

表1 MIFD與Adaboost算法性能比較
4.2.3 MIFD與其他深度學習方法對比
這部分對比包括檢測精度與檢測速度,選取了其他四種經典的人臉檢測深度學習算法進行檢測精度上的比較,分別是CascadeCNN[18]、Boosted Exemplar[19]、PEPAdapt[20]、Faster-RCNN[14],將這些算法在FDDB數據集上進行評估,繪制ROC曲線,在1080 GPU的服務器上進行測試,結果如圖11所示。

圖11 各算法檢測效果比較
選取了MIFD、YOLO、Faster RCNN進行了算法檢測速度的比較,結果如表2所示。
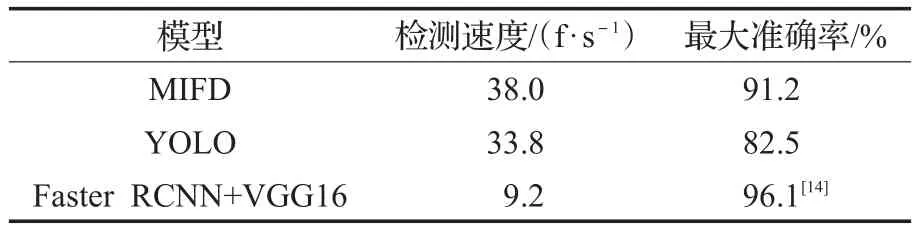
表2 模型檢測速度對比
通過圖11可以得出,本文提出的算法MIFD在誤檢數量上低于其他深度學習方法;在檢測準確率上不如Faster RCNN方法,但與其他深度學習方法相比,仍然具有明顯優勢。根據表2可以得出,MIFD的檢測速度達到38 f/s,能達到實時檢測人臉的目的,速度是Faster RCNN的4.13倍,在檢測速度上具有十分明顯的優勢。因此,本文算法MIFD在檢測精度與檢測速度上取得了一個很好的權衡。
5 結束語
構建實用的人臉檢測相關的應用系統,需要解決自然環境下的各種姿態、不同尺度人臉的檢測準確性、魯棒性問題,同時在檢測速度上必須達到一定的要求。本文基于深度卷積神經網絡自動學習特征的優越特性,且基于實時多目標回歸思想,使得提出的算法滿足了檢測實時性的要求;同時,分析了實時多目標回歸算法割裂了位置參數之間的關系,造成了模型的檢測效果不夠理想的問題,針對存在的缺陷,引入了IOU函數,把位置參數變量融合為一個整體進行優化,克服了該缺陷,提升了檢測效果。實驗結果表明:提出的算法在人臉檢測的精度以及檢測速度上取得了一個較好的平衡,檢測精度上優于傳統主流的Adaboost算法,檢測速度也能夠達到實時性,該算法可用于出入口人證比對、視頻監控分析等人臉相關的視覺系統。
參考文獻:
[1]Lowe D G.Distinctive image features from scale invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[2]Dalal N,Triggs B.Histograms of oriented gradients forhuman detection[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Los Alamitos:IEEE Computer SocietyPress,2005:886-893.
[3]曾鴻軍,沈燕飛,王毅.基于感興趣區域的頭像視頻前處理方法[J].計算機工程與應用,2017,53(6):188-192.
[4]Jain V,Learned-Miller E.FDDB:A benchmark for facedetection in unconstrained settings[R].UMass Amherst-Technical Report,2010:222-231.
[5]張國云,向燦群,羅百通,等.一種改進的人臉識別CNN結構研究[J].計算機工程與應用,2017,53(17):180-185.
[6]Uijlings J R R,Sande K E A V D,Gevers T,et al.Selective search for object recognition[J].International Journal of Computer Vision,2013,104(2):154-171.
[7]Zitnick C L,Dollar P.Edge boxes:Locating object proposals from edges[C]//European Conference on Computer Vision,2014:162-172.
[8]Zhang Xiang,Sermanet P.Overfeat:Integrated recognition,localization and detection using convolution networks[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Columbus:IEEE Computer Society Press,2014:651-667.
[9]Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition,2014:580-587.
[10]Ren S,He K,Girshick R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,39(6):1137-1148.
[11]Redmon J,Divvala S,Girshick R,et al.You only look once:Unified,real-time object detection[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE Computer Society Press,2016:779-788.
[12]Jiang Y,Jiang Y,Cao Z,et al.UnitBox:An advanced object detection network[C]//ACM on Multimedia Conference,2016:516-520.
[13]Ioffe S,Szegedy C.Batch normalization:Accelerating deep network training by reducing internal covariate shift[J].Computer Science,2015,70(2):23-35.
[14]Jiang H,Learned-Miller E.Face detection with the Faster RCNN[EB/OL].[2016-07-10].http://arxiv.org/abs/1606.03473.
[15]Huang L,Yang Y,Deng Y,et al.DenseBox:Unifyinglandmark localization with end to end object detection[J].Computer Science,2015,26(3):254-267.
[16]Yang S,Luo P,Chen C L,et al.WIDER FACE:A face detection benchmark[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2016:5525-5533.
[17]Kingma D P,Ba J.Adam:A method for stochastic optimization[J].Computer Science,2014,32(3):111-125.
[18]Li H,Lin Z,Shen X,et al.A convolutional neural network cascade for face detection[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2015:5325-5334.
[19]Li H,Lin Z,Brandt J,et al.Efficient boosted exemplar based face detection[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2014:1843-1850.
[20]Li H,Hua G,Lin Z,et al.Probabilistic elastic part model for unsupervised face detector adaptation[C]//Proceedings of 2014 IEEE International Conference on Computer Vision,2014:793-800.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
