關聯圖譜和輿情分析在異常傳導路徑分析中的應用
2018-05-30 01:48:00上交所技術有限責任公司
電子世界 2018年9期
關鍵詞:關聯
上交所技術有限責任公司 王 泊
0.引言
傳統的指數貢獻度算法,主要使用漲跌幅乘以權重的計算方法,這種方法只能計算個股(行業)本身對指數貢獻的直接影響。現實情況下,個股(行業)之間不是孤立的,是有相互影響的。如果不考慮個股(行業)對其它個股(行業)的影響而衍生出對指數影響的話,市場分析工作就有很大的局限性。
本研究突破傳統的指數貢獻度算法的局限,首次量化個股對其關聯個股的影響,以及行業對其關聯行業的影響,并且更加精確地衡量個股、行業對指數的影響程度,結合對輿情關聯行情數據的分類處理,繪制個股(行業)的異常傳導路徑,為日常對異動股票、異動行業的監管提供了理論支持。
1.研究背景
在證券二級市場上,市場風險具有較強的擴散性的特性,例如,概念股炒作往往從龍頭個股開始,接力炒作龍二、龍三等股票。研究個股(行業)異常波動之間的相關性和風險的傳播方向就顯得尤為重要。
如果能根據個股(行業)出現異常波動之間的相關性,在風險擴散的初級階段提前以預警方式提示風險,則能從源頭上抑制炒作,有效的控制風險。比如,如果能從歷史的交易信息中,提前挖掘出可能炒作的與龍頭關聯的龍二、龍三等股票,并以預警形式提請關注,則可以為實現事前監管累積豐富的基礎。
另一方面,輿情信息也對市場波動有重要影響。本文考慮將股市異常分析與輿情分析相結合,構建出異常股票(行業)的關聯和風險傳播網絡圖譜,用以更好地偵查和控制風險。在實際應用中,個股信息和新聞信息是海量、高維度的,并存在數據噪聲需要處理,因此本研究結合深度學習、貝葉斯網絡和自然語言處理技術,對數據進行有效的篩選,構建出兼具準確性、可解釋性和不斷自我學習優化的傳導模型。
2.繪制異常傳導路徑的理論和算法
如“深度貝葉斯網絡技術及股票關聯機器學習識別”一文中介紹,可以通過抓取異常節點和計算節點連接強度的方法,搭建股票的關聯圖譜。如果我們引入時間軸,將個股或行業在某一個時間點的異常波動抓取出來、作為圖譜的節點,沿用節點連接強度的計算方法,并結合輿情分析給節點標注利好或利空的分數,進而調整節點的連接強度(即異常傳導的相關系數),得到的股票(行業)的異常傳導路徑,用以解釋或預測股市的波動。模型整體思路的架構圖如圖1所示:

圖1 抓取異常傳導路徑的模型架構圖
第三、四兩章將分別介紹用行情數據搭建異常節點網絡和用輿情數據計算利好利空分數這兩部分內容。第五章介紹綜合前兩步計算的結果、尋找異常傳導路徑的過程。第六章介紹數據實驗和結論部分。
3.用行情數據搭建異常節點網絡和節點相關性的計算
異常節點網絡的搭建分為節點識別、節點連接、網絡參數優化和網絡微調四個部分,詳細的流程如圖2所示:
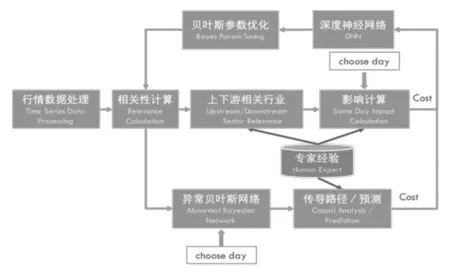
圖2 異常貝葉斯網絡搭建機器學習算法框架圖
3.1 節點識別
“在股票關聯圖譜中,節點的定義是某個股或行業。節點的篩選,可以通過專家規則來確定,或者是通過確定異常節點閾值的方式進行選擇。如果是通過專家規則來定義的話,就由市場分析專家來確定將哪些個股(行業)作為節點。如果通過異常節點的方式來定義的話,考慮到個股(行業)的形態不同,需要對個股采用用不同的閾值。不同個股(行業)的波動率(Volatility)不同,因此每個個股的異常定義也不同。對于波動率較低的個股,其異常閾值也相對較低。”以上這段文字是敘述在構建股票關聯圖譜中抓取節點的方法,這里的波動率是一段時間的平均波動率,異常閾值的設定也是針對一段時間的平均值。而在本研究中,異常節點是指某個時間點上波動異常的某支股票或某個行業,我們要構建的是存在時間軸的傳導網絡。
3.2 節點連接
運用點互信息(Pointwise Mutual Information (PMI))計算出節點連接強度,公式如下:

其中各符號含義如下:
p(x)是事件x單獨出現的概率;
p(y)是事件y單獨出現的概率;
p(x, y)是兩個事件x, y共現的概率;
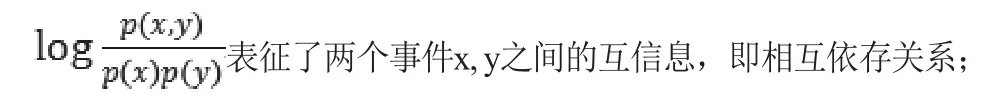
log(p(x, y))是歸一化項,采用歸一化處理的PMI值更加穩定。
3.3 網絡參數優化和網絡微調
基于構建好的節點和連接強度,結合人類專家標記出個股(行業)間的關聯關系,可對貝葉斯網絡的參數進行調整。具體地,系統在收到人類專家的反饋后,會根據懲罰函數對現有參數進行調整,重新計算連接強度,專家提供的懲罰函數具體可由如下兩種形式來實現:
方式一,個股(行業)間關系的排序。人類專家標記出個股(行業)間的關聯關系,可以作為有監督學習的標簽。在系統計算出每對行業之間的相關性后,懲罰函數如下:

其中,Rij是行業i,j之間的相關性,UDij代表上下游行業關系。UDij是1代表有上下游關系,此時Rij越大懲罰值越小,UDij是0代表沒有上下游關系,此時Rij越大懲罰值越大。
方式二,人類專家給定的關聯關系權重值。對于系統分析出的關聯關系中的每條邊,人類專家可以給予1-5的評分,用以評判關聯關系的準確性。懲罰函數的數學表達如下:
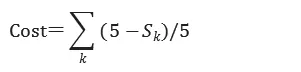
其中,關聯關系由k條邊組成,Sk代表人類專家對每條邊的打分。
得分越高,懲罰函數值越小,反之亦然。最終的懲罰函數等于所有邊的調整過的懲罰值相加。
4.用輿情數據計算利好或利空分數
除了股票價格的直接波動,輿情也是影響異常事件傳導的重要因素。本研究的一個創新之處,即把輿情分析得到的利多或利空判斷與異常股票的關聯性相結合,作為異常傳導路徑的計算要素。
本研究用自然語言處理技術(Natural Language Processing),對輿情信息進行數據篩選、文本清理,建立了輿情信息與個股和行業的關聯以及利多、利空的識別模型。
為解決高維數據與數據噪聲問題,研究對輿情文本進行數據預處理,并引入關鍵詞引擎ElasticSearch輔助生成行情利多利空特征,加強輿情分類判斷的準確性。其中預處理和關鍵詞引擎與云腦Deepro NLP形成多次迭代,通過機器學習不斷優化模型。
輿情分析整個流程具備高度自動化與高度適應性的能力,可以應對不同種類的文本數據輸入,如:各種類別財經新聞。對于新引入的行情關鍵詞可以快速更新模型庫,以便調整分類與評判結果。整體流程設計模塊化,具備標準API調用接口,并充分考慮了可擴展性,預留模塊包括專家經驗引入,以及根據專家對分類結果的反饋等。如圖3所示。
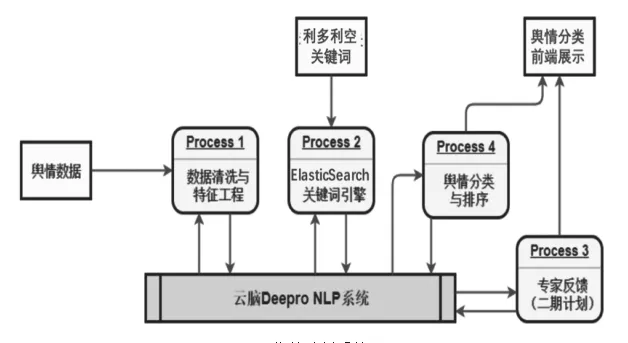
圖3 輿情分析系統圖
4.1 用BM25模型獲取利好(利空)分數
研究在現有的輿情數據集的基礎上,測試了一系列排序與打分算法,包括:BM25、TF-IDF、DFR、DFI、IB、LM Dirichlet、LM Jelinek Mercer等,憑借BM25算法在文本查詢排序與文本誤查率等評判標準中的優異表現,將BM25算法選定為本課題的輿情分析的最終算法。
BM是在概率搜索的框架下被提出的Best Matching(最佳匹配)算法的縮寫,BM25又常被稱為“Okapi BM25”。BM算法返回與搜索關鍵詞相關性最符合的結果,并給出結果排序,被廣泛應用于復雜搜索引擎中。BM25核心計算公式如下:
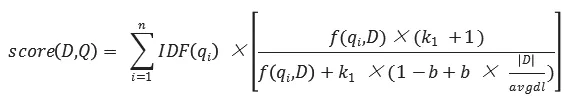
其中各符號含義如下:
D:文檔;
Q:搜索詞(多個);
f(qi, D):qi這個詞在文檔D中出現的次數;
|D|:D的單詞數;
avgdl:整個文檔庫中文檔的平均長度;
k1, b:自由參數,一般取值范圍是k1 ∈ [1.2,2.0], b = 0.75。IDF(qi)(inverse document frequency):通常由下述公式計算
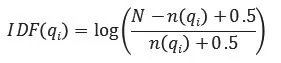
其中,N是文檔庫中的文章總數,n(qi)是包含qi這個詞的文章總數。
4.2 用NLP預測利好(利空)分數
通過以上過程我們得到一系列訓練數據,包括新聞的文本和針對每一篇文本用BM25標記的利好和利空分數。接下來,本研究用循環神經網絡(RNN)中的長短期記憶網絡(LSTMs)模型對文字的處理,將所有和節點相關的新聞進行利好或利空的分類,并輸出每個節點的利好、利空分數,作為下一步綜合系數計算連接強度的輸入。簡單介紹下模型:
循環神經網絡(RNN)是在傳統神經網絡的基礎上,加入一個循環的操作,這種循環結構使得某個時刻的狀態能夠傳到下一個時刻,即每一網絡會把它的輸出傳遞到下一個網絡中。把循環神經網絡在時間步上進行展開,就得到如圖4這樣的模型:
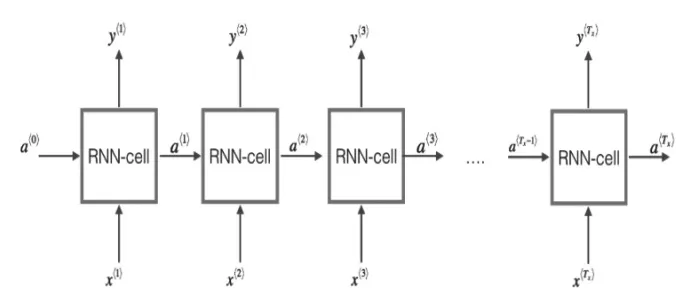
圖4 RNN原理說明圖
循環神經網絡的出現和廣泛應用,主要是因為它們能夠把以前的信息聯系到現在,從而解決現在的問題。比如在視頻中利用前面的畫面,能夠幫助我們理解當前畫面的內容。有時候,我們在處理當前任務的時候,只需要看一下比較近的一些信息,即我們所要預測的內容和相關信息間的間隔很小,這種情況下RNN就能夠很容易利用過去的信息進行預測。但是非常幸運地,長短期記憶網絡(LSTMs)的出現可以幫助我們避免這種長期依賴(long-term dependency)的問題。它們的本質就是能夠記住很長時期內的信息,其原理如圖5所示:
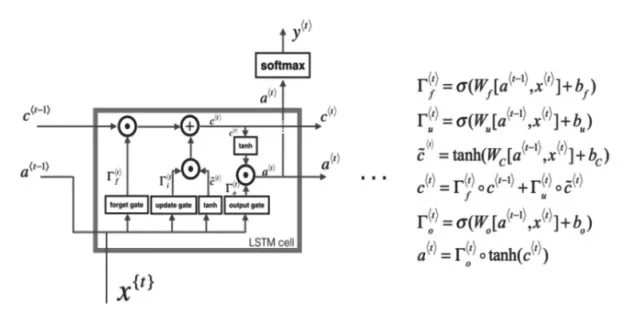
圖5 LSTMs原理說明圖
長短期記憶網絡最關鍵的地方在于每個單元(cell)的狀態和結構圖上面的那條橫穿的水平線。單元狀態的傳輸就像一條傳送帶,向量從整個單元中穿過,只是做了少量的線性操作。這種結構能夠很輕松地實現信息從整個單元中穿過而不做改變,從而實現長期記憶的保留。
5.綜合系數模型和尋找異常傳導路徑
5.1 綜合系數模型
前文敘述了抓取異常節點、用點互信息的方法計算節點連接強度和計算利好或利空分數的過程,這部分內容將把用點互信息計算的連接強度和利好利空分數結合,綜合考慮了股市的異常波動和輿情傳播兩種情況對節點連接的影響。綜合系數模型計算新的連接強度的公式如下:
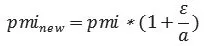
其中,pmi是2.2節中計算出的連接強度,ε是用LSTM預測的利好利空分數,a是一個比較大的常數,其取值可以通過參數微調的過程進行優化。
5.2 尋找異常傳導路徑
得到異常節點和新的節點連接強度后,用最長路徑算法在這個有向無環圖中尋找異常傳播路徑。即:
拓撲排序圖(G)中的所有節點;
對于線性排序的每個節點v ∈ V,dist(v)=max(u, v)∈E{dist(u)+w(u, v)},w(u, v)是節點v和節點u的連接強度;
返回maxv ∈ V{dist(v)}。
6.數據實驗結果輸出和結論
本例中,系統分析2017年4月19日上證指數的異常波動。所輸出的異常傳導路徑從2017年4月17日國防軍工板塊異常,到4月18日的銀行板塊與多個權重個股異常,到4月19日的鋼鐵板塊異常,以及上證指數異常。其中,板塊,個股之間異常事件的相關性也一并標出。經過行業專家與當時輿情驗證驗證,證明此分析與專家經驗分析類似。
各節點說明如下:
(1)國防軍工(申萬)跌幅異常:-3.24%
(2)銀行(申萬)跌幅異常:-1.37%
(3)包鋼股份跌幅異常:-3.10%
(4)交通銀行跌幅異常:-1.80%
(5)浦發銀行跌幅異常:-1.67%
(6)興業銀行跌幅異常:-1.77%
(7)鋼鐵(申萬)跌幅異常:-2.73%
(8)上證綜指5日跌幅超3%:-3.15%
本系統將用深度貝葉斯網絡構建關聯圖譜的方法遷移到構建異常節點網絡的模型中,結合輿情信息的分析。從股票價格和輿情這兩個維度出發、刻畫風險如何從輿情傳導到相應的股票或行業,進而傳導到關聯的股票和行業,最終形成對指數波動的影響。以異常傳導路徑的方法,可以更加直觀和準確地刻畫出市場波動的原因。從創新角度,本系統首次將貝葉斯網絡技術與NLP自然語言處理技術有機結合,利用NLP技術從非結構化的輿情中提取有效相關信息,作為結構化的證券行情數據的標簽。整個系統需要經過多輪迭代,以同時優化貝葉斯網絡參數與NLP系統的參數。本系統的高精確度來源于深度貝葉斯網絡快速收斂的特性,以及NLP系統中采用的LSTM對語言序列高精度建模的能力。經過專家驗證,本系統在證券行業的實際應用中,能高度協助,并在某些場景下超越專家經驗的分析。
[1]K.W.Church and et al.(March 1990).“Word association norms,mutual information, and lexicography”.Compute. Linguist.16(1):22-29.
[2]T.M.Cover and et al.(1991).Elements of Information Theory(Wiley ed.).ISBN 978-0-471-24195-9.
[3]C.D.Manning and et al.,An Introduction to Information Retrieval,Cambridge University Press,2009,p.233.
[4]S.E.Robertson and et al.(November 1994).Okapi at TREC-3.Proceedings of the Third Text REtrieval Conference(TREC 1994).Gaithersburg, USA.
[5]S.E.Robertson and et al.(November 1998).Okapi at TREC-7.Proceedings of the Seventh Text REtrieval Conference.Gaithersburg,USA.
[6]A.Y.Ng,sequence model course slides on coursera, https://www.coursera.org/learn/nlp-sequence-models/.
[7]C.Olah,Understanding LSTM Networks, http://colah.github.io/posts/2015-08-Understanding-LSTMs/.
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
