基于異類近鄰的支持向量機加速算法
2018-05-30 01:26:08陳景年胡順祥
計算機工程 2018年5期
陳景年,胡順祥,徐 力
(a.山東財經大學 信息與計算科學系,濟南 250014; b.魯南技師學院 商務管理系,山東 臨沂 276021; c.濟南市公路管理局 信息科,濟南250013)
0 概述
支持向量機(Support Vector Machine,SVM)是基于統計學習理論的一種機器學習方法,在結構風險最小化基礎上,可有效地避免傳統方法中局部極小、過擬合、維數災難等常見問題,并且在小樣本集上依然能取得好的學習效果[1]。因此,在文本分類、網頁過濾、目標跟蹤等領域得到了廣泛應用[2-4]。
標準的SVM訓練過程歸結為一個凸二次規劃問題。 隨著訓練樣本的增多,其訓練空間和時間會急劇增加。所以,SVM難以適用于大規模數據集。如何提高 SVM 的學習效率以適應大規模數據處理的需求成為近年來的一個研究熱點[5-8]。
本文利用異類近鄰來選擇邊界樣本,這一方法不僅適用于復雜邊界的情形,而且對多類分類問題也非常有效。
1 研究背景
文獻[1]指出,在SVM的訓練過程中,只有支持向量對構建分類模型起作用,并且支持向量往往位于類邊界附近。因此,邊界附近的樣本對SVM的分類結果起決定作用。所以在構建SVM分類模型時,不必應用所有訓練樣本,而只需選取其中最有可能成為支持向量的邊界樣本參與訓練過程。這樣,在保持構建的分類模型效果的同時,因訓練樣本的減少而可以大幅度提高訓練效率。
基于上述思路,研究人員給出了一些有效的方法以選取潛在的支持向量來構成精簡的訓練集,提高了訓練效率。
文獻[9]利用一個樣本分別到2類樣本中每個類的中心的距離之比來判斷該樣本是否為邊界樣本。該方法在保持SVM分類效果的情況下,可明顯提高SVM的訓練速度。文獻[10]首先用一個小樣本子集訓練得到一個初始的SVM分類超平面,然后將原樣本集中離此平面較遠的樣本刪除。通過該方法可以刪除一些冗余樣本,在保持SVM泛化能力的同時,提高了其訓練速度。
文獻[11]利用每個樣本的k近鄰在訓練集中的序號及相應的距離對樣本打分,并按打分高低選擇樣本。文獻[12]根據樣本的k近鄰中異類樣本數來選擇樣本。
近來,文獻[13]利用每個樣本的最近鄰信息得到訓練集的一致子集,然后利用此子集訓練SVM。該選擇算法的效率較高,但有時樣本選擇效果不夠理想。文獻[14]以每類樣本的聚類中心作為參照來選擇其他類中的邊界樣本。
上述研究工作在保持分類效果和提高訓練效率方面都有一定作用,但在數據集的類別邊界非常復雜和類別較多的情況下,選擇效果往往不理想。
2 基于異類近鄰的邊界樣本選擇
為使提出的算法更具普適性,考慮一般的多類分類問題。由于SVM分類模型是針對二類分類問題建模的,因此在應用SVM模型進行分類時,通常將一個多類分類問題轉化為多個二類分類問題來解決。常用的轉化方式有2種:一對一方式和一對多方式。在一對一方式中,多類中的每2個類之間都要構建一個SVM模型。這樣,不僅需要訓練大量的模型,而且使后續的分類過程變慢。在一對多方式中,每個類輪流做一次正類。在一個類作為正類時,其余類合起來作為負類。由于一對多方式需訓練的SVM模型較少,而且后續的分類過程效率高,因此,在下面的樣本選擇算法中,將采用一對多方式。
假定訓練集A是由L類樣本所組成,A中的樣本總數為N。A中的每一類樣本都輪流做一次正類樣本,與此同時,其余樣本作為負類樣本。下面考慮第c(1≤c≤L)類樣本為當前的正類樣本時的邊界樣本選擇問題,記選擇的結果為Sc。
選擇過程包括正類樣本選擇和負類樣本選擇2個方面。選擇結果Sc初始化為空集φ。首先進行的是負類樣本的選擇。對于第c類中的每個樣本x,計算x在第l(1≤l≤L,l≠c)類中的k個最近鄰xlj(1≤j≤k)。判斷xlj是否屬于Sc。如果xlj∈Sc,則將xlj選入Sc。這里,計算k近鄰的操作是在每一小類樣本中進行的,不同于傳統的做法在整個數據集中進行。因此,上述k近鄰的搜索過程因搜索范圍的縮小而較傳統做法具有更高的效率。
正類樣本的選擇過程與負類樣本選擇類似。由于在多類分類問題中采用了一對多的轉化模式,這可能會引起正類與負類之間樣本數目嚴重不均衡的問題。因此,在正類樣本的選擇過程中,增加了一項調節正類和負類之間均衡性的操作,即在正類樣本明顯偏少的情況下(比如少于選擇的負類樣本數的一半),則正類樣本將全部保留。整個邊界樣本選擇過程如圖1所示。其中,L為訓練集A中的樣本類數,N為A中的樣本總數,Nc為第c類樣本數,Ns為選擇的負例數,Sc為第c類作為當前正類時樣本選擇的結果。
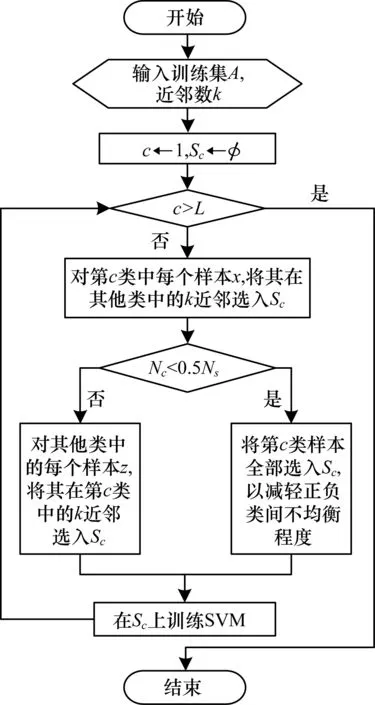
圖1 基于異類近鄰的樣本選擇算法流程
下面是所給的樣本選擇和模型訓練的算法描述。
算法基于異類近鄰的樣本選擇算法
輸入訓練集A(含有L個類,共N個樣本),近鄰數k
輸出對每個類別c(1≤c≤L),輸出以c類樣本為正類,其余樣本為負類時的選擇結果Sc
1)初始化:c=1;Sc←φ。
2)以c類樣本為正例,其余樣本為負例。
3)負例(即負類樣本)的選擇過程:
(1)l=1;
(2)如果l≠c,則:
①對于第c類中的每個樣本x,計算x在第l類中的k個最近鄰xlj(l≤j≤k)。
②如果xlj∈Sc,則Sc←Sc∪{xlj}。
(3)l←l+1;
(4)如果l≤L,則轉(2),否則轉4)。
4)正例(即正類樣本)的選擇過程:
(1)比較c類樣本數Nc和選擇的負例數Ns的大小關系。
(2)如果Nc<0.5Ns,則所有c類樣本被選入Sc,轉5)。
(3)對每個負例y:
①計算y在第c類中的k個最近鄰xcj(l≤j≤k)。
②如果xcj∈Sc,則Sc←Sc∪{xcj}。
5)在得到的Sc上訓練SVM模型。
6)c←c+1。
7)如果c≤L,轉2)。
8)結束。
3 算法說明
3.1 與相關算法的不同之處
盡管上述基于異類近鄰的邊界樣本選擇算法利用了樣本的k近鄰來進行樣本選擇,但與以往基于k近鄰的樣本選擇方法相比,本文所給算法有如下不同之處:
1)以往基于k近鄰的算法往往是在整個訓練集中搜索一個樣本的k近鄰,而上述算法是在除當前正類之外的每個小類中搜索一個正類樣本的k近鄰,簡稱異類k近鄰。因此,搜索的效率會明顯提高。
2)與以往基于k近鄰的算法相比,在上述算法中,異類k近鄰的使用使得選擇算法能夠適用于各種復雜的類別邊界,而不像以往算法往往受邊界條件的限制。
3)在正類樣本的選擇過程中,能夠根據正類與負類樣本數的差距來消除正、負類之間的不均衡問題,這也是上述算法的一個獨到之處。
3.2 算法的復雜度分析
所給算法包含了負例選擇和正例選擇2個過程,并且正例選擇過程的復雜度不超過(許多情況下遠低于)負例選擇過程的復雜度。所以,這里只對負例選擇過程的復雜度進行分析。
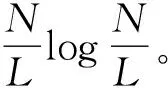
3.3 算法的參數設置方法
在給出的樣本選擇算法中,一個樣本的近鄰數k對算法的效果和效率具有重要的作用。很顯然,k越小,選擇的樣本越少,訓練效率會越高。同時,也越容易損失一些支持向量,易引起訓練效果的下降。反之,k越大,越不容易漏掉支持向量,但也往往會選入一些冗余的樣本,不僅使選擇的樣本增多,訓練效率降低,同時,較多的冗余樣本也會降低訓練效果。因此,k的值不宜過大或過小,而應在一定的范圍內尋找合適的k值。實驗發現,絕大多數情況下,在2~10的范圍內即可找到一個理想的k值。因此,通過實驗不難確定合適的k值。
4 實驗結果與分析
為驗證本文所給算法的有效性,將它與性能顯著的2個邊界樣本選擇算法NPPS[12]以及FCNN[13]進行多方位的比較,具體包括如下3個方面:1)樣本選擇的效果,即利用選擇的樣本得到的分類模型的分類準確率;2)選擇的樣本占總訓練樣本的比例;3)利用選擇的樣本訓練分類模型所需的時間。
4.1 實驗數據集
實驗共采用了12個數據集,其中6個為小規模數據集,另6個為中等規模或大規模數據集。它們大都來自于UCI的機器學習數據庫[15]。另外,為了驗證所給算法對多類分類,特別是大類別數據集分類的效果,實驗中還采用了一個包含3 755類的手寫中文字符數據集HCL2000[16]。其中每一類都包含1 000個樣本,被分成了700個訓練樣本和300個測試樣本。實驗中選取了其中的前100個類中的樣本,并通過提取8-方向梯度特征得到512個屬性。表1列出了每個實驗數據集中包含的樣本數、屬性數(也稱為特征數)以及類數。其中,第1個~第6個數據集為小規模數據集,其余6個為中等或大規模數據集。
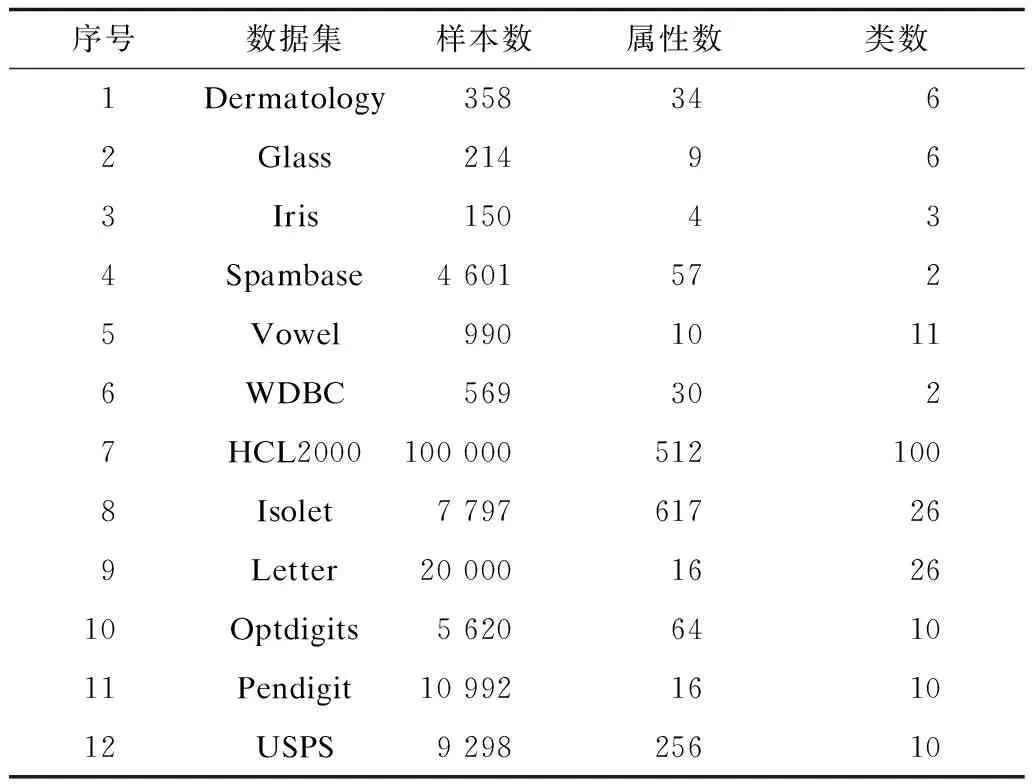
表1 實驗數據集參數
4.2 實驗參數
在所有SVM模型的訓練過程中,采用了下式定義的高斯核函數。
k(xi,xj)=exp(-‖xi-xj‖2/2σ2)
(1)
除了大類別集的數據集HCL2000[16]外,在每個數據集上都采用5重交叉驗證的方法進行實驗。由于原始的數據集HCL2000規模很大,且已被分成了訓練集和測試集,這里沒再對其重新劃分。
在每個數據集上,對式(1)中高斯核函數的參數σ2、SVM模型的誤差限C、本文所給算法的異類近鄰數k以及NPPS算法[12]中的近鄰數kn都通過實驗的方法進行優化。表2列出了在每個數據集上的具體參數取值。由于FCNN[13]中采用的是最近鄰算法,因此不需要對其進行參數設置。
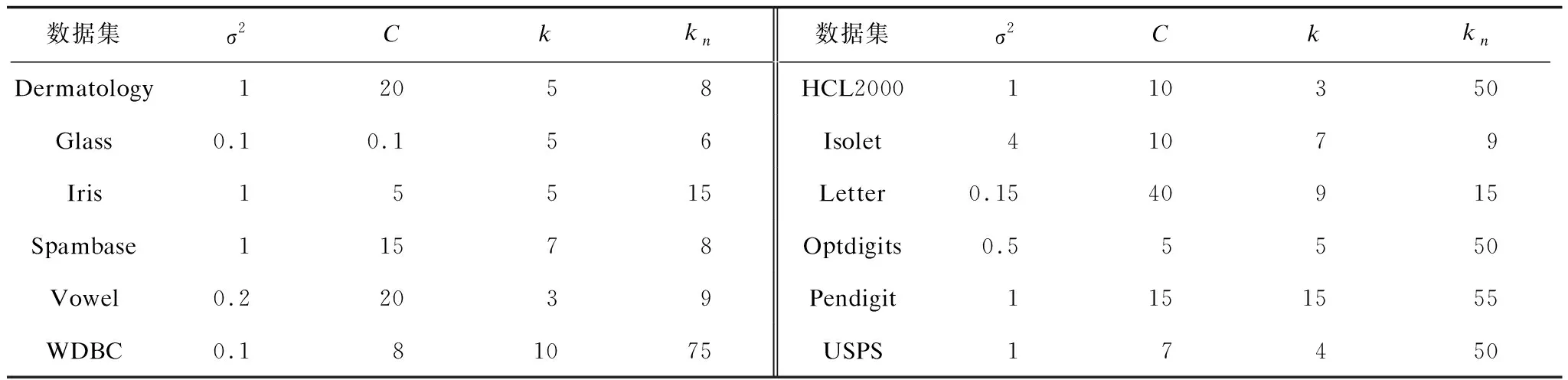
表2 在每個數據集上的參數取值
4.3 實驗結果
表3列出了在6個小規模數據集上的分類準確率、樣本選擇比例及訓練時間。表4則給出了在其余6個中等或大規模數據集上的實驗結果。為了直觀地對所給算法與FCNN以及NPPS進行比較,圖2~圖7用折線圖描繪了它們分別在2組數據集上的分類準確率、樣本選擇比例及樣本選擇后的訓練時間與未進行樣本選擇的訓練時間之比。
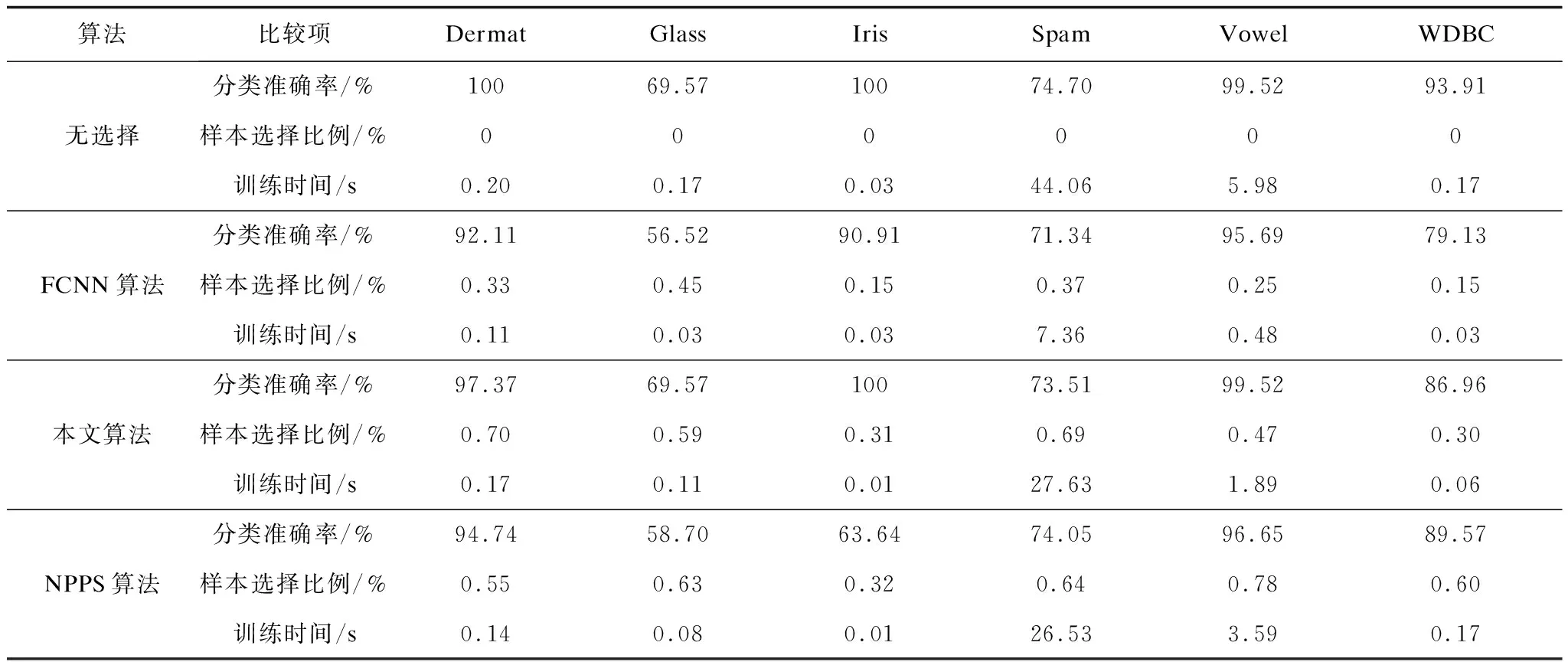
表3 在小規模數據集上的實驗結果
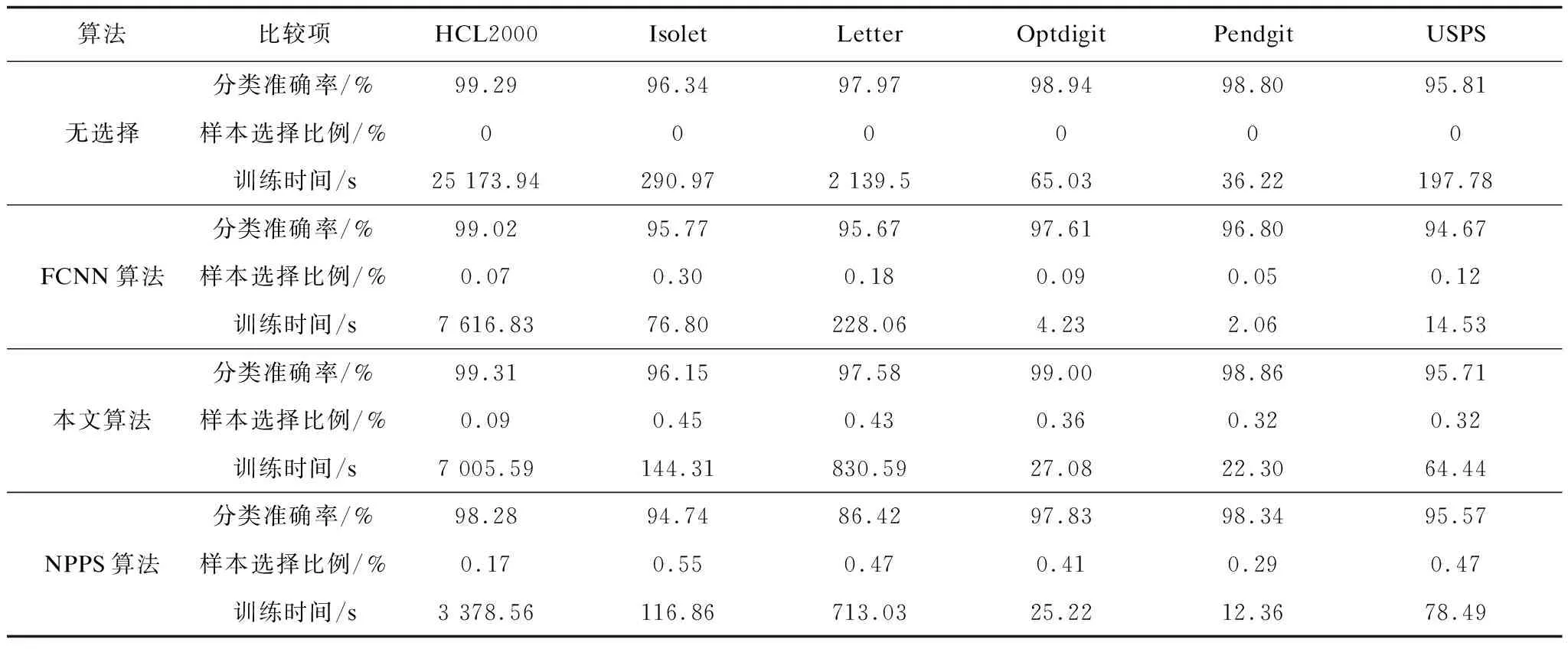
表4 在中等或大規模數據集上的實驗結果
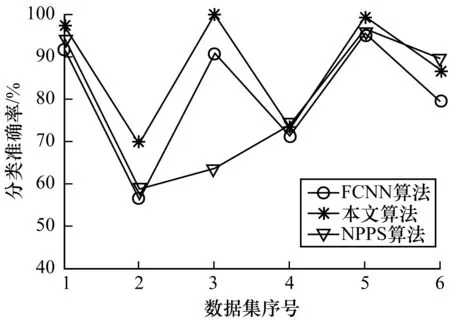
圖2 小規模數據集上的分類精度
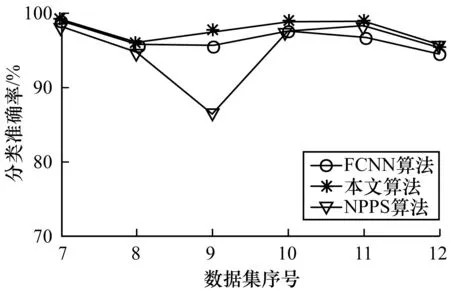
圖3 中大規模數據集上的分類精度
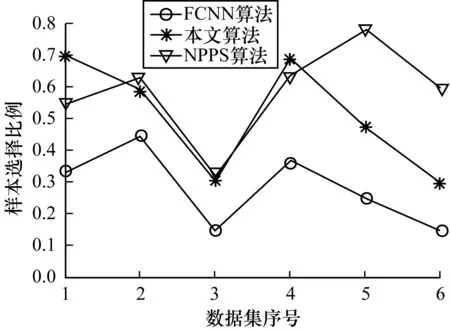
圖4 小規模數據集上的樣本選擇比例
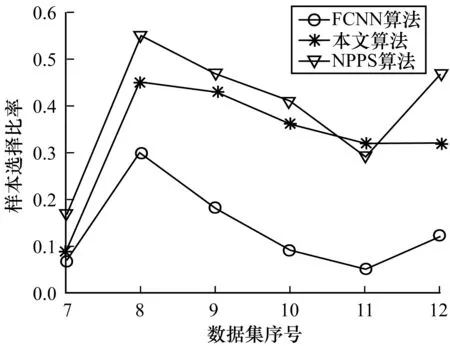
圖5 中大規模數據集上的樣本選擇比例
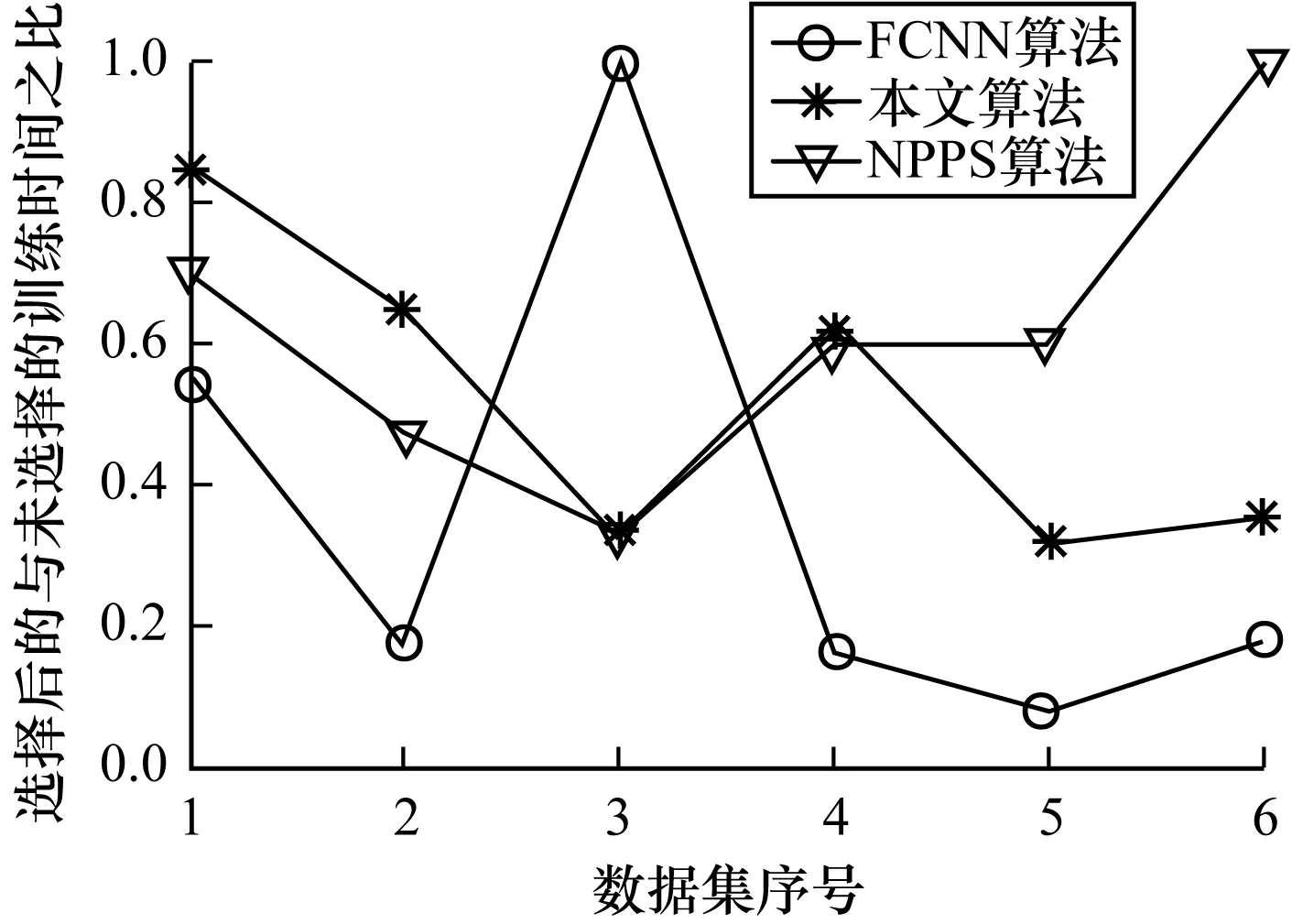
圖6 小規模數據集上的訓練時間比

圖7 中大規模數據集上的訓練時間比
由圖2和圖3可以直觀地發現,在大部分小規模數據集和所有中等規模與大規模數據集上,本文提出的樣本選擇算法在提高了SVM的訓練效率的同時,使分類取得了最好的效果。從表3和表4可以發現,在實驗的每個數據集上,本文算法的分類效果沒有明顯的降低。甚至在HCL2000、Optdigit以及Pendigit等數據集上分類準確率比未進行樣本選擇的情況下還有所提高。相比之下,FCNN算法與NPPS算法都沒有很好地保持分類效果。例如在Dermat、Glass、Iris、WDBC等數據集上,FCNN使得分類精度明顯下降。NPPS在Glass、Iris、Letter等數據集上引起了分類效果的明顯降低。上述實驗結果表明,本文給出的選擇算法在選擇效果上有著明顯的優勢。
由圖4和圖5可以發現,本文所給算法選擇的樣本的比例總體上略低于NPPS算法的選擇比例而高于FCNN算法。在比較的樣本選擇算法中,FCNN算法選擇的樣本比例最低,在降低訓練數據規模上具有一定優勢。但由上文對選擇效果的比較來看,FCNN算法容易引起分類效果明顯降低。這說明選擇的樣本并不是越少越好。
從圖6和圖7綜合來看,在提高訓練效率方面本文所給算法和NPPS算法相當,而FCNN算法在這方面具有一定優勢。這同樣是由于FCNN算法選擇的樣本比例較低的緣故。
5 結束語
在眾多的分類算法中,支持向量機(SVM)因其較高的分類精度和堅實的理論基礎而倍受關注,在諸多的應用領域中取得了顯著的分類效果。然而,SVM對于樣本數目來說,具有立方級的訓練復雜度。因此,如何提高SVM的訓練效率一直是機器學習研究中的熱點問題。
為了在保持SVM效果的同時提高其效率,本文給出了精簡訓練集的一種算法,即利用異類近鄰來選擇邊界樣本。這一算法不僅適用于復雜邊界的情形,也可以有效地用于多類分類問題,而且能在很大程度上減輕不均衡數據對分類模型的影響。在多個實驗數據集上的實驗結果表明,該算法在使訓練效率大幅提高的同時,能更好地保持甚至改善分類效果。
為了使所給算法能更有效地用于大規模數據集,特別是大數據處理,還需要對算法在效率上做進一步改進,這是下一步要做的一項研究內容。
[1] VAPNIK V.The Nature of statistical learning theory[M].New York,USA:Springer,1995.
[2] JOACHIMS T.Text categorization with support vector machine:learning with many relevant features[C]//Proceedings of the 10th European Conference on Machine Learning.New York,USA:ACM Press,1998:137-142.
[3] 王憲亮,吳志剛,楊金超,等.基于SVM一對一分類的語種識別方法[J].清華大學學報(自然科學版),2013,53(6):808- 812.
[4] 孫俊濤,張順利,張 利.基于聯合支持向量機的目標跟蹤算法[J].計算機工程,2017,43(3):266-270.
[5] DONG Jianxiong,KRZYZAK A,SUEN C Y.Fast SVM training algorithm with decomposition on very large data sets[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(4):603-618.
[6] LI Boyan,WANG Qiangwei,HU Jinglu.Fast SVM training using edge detection on very large datasets[J].IEEE Transactions on Electrical and Electronic Engineering,2013,8(3):229-237.
[7] JUNG H G.Support vector number reduction: survey and experimental evaluations novel[J].IEEE Transactions on Intelligent Transportation Systems,2014,5(2):463-476.
[8] 包文穎,胡清華,王長忠.基于多粒度數據壓縮的支持向量機[J].南京大學學報(自然科學版),2013,49(5):637- 643.
[9] 焦李成,張 莉,周偉達.支撐矢量預選取的中心距離比值法[J].電子學報,2001,29(3):383-386.
[10] 李紅蓮,王春花,袁保宗,等.針對大規模訓練集的支持向量機的學習策略[J].計算機學報,2004,27(5):715-719.
[11] PANDA N,CHANG E Y,WU Gang.Concept boundary detection for speeding up SVM[C]//Proceedings of International Conference on Machine Learning.New York,USA:ACM Press,2006:681-688.
[12] SHIN H,CHO S.Neighborhood property based pattern selection for support vector machines[J].Neural Computation,2007,19(3):816-855.
[13] ANGIULLI F,ASTORINO A.Scaling up support vector machines using nearest neighbor condensation[J].IEEE Transactions on Neural Networks,2010,21(2):351-357.
[14] CHEN Jingnian,ZHANG Caiming,XUE Xiaoping,et al.Fast instance selection for speeding up support vector machines[J].Knowledge-based Systems,2013,45(6):1-7.
[15] HETTICH S,BLAKE C L,MERZ C J.UCI repository of machine learning databases[EB/OL].[2017-03-21].http//www.ics.uci.edu/ ~mlearn/MLRepository.html.
[16] ZHANG Honggang,GUO Jun,CHEN Guang,et al.HCL2000——a large-scale handwritten Chinese character database for handwritten character recognition[C]//Proceedings of the 10th International Conference on Document Analysis and Recognition.Berlin,Germany:Springer,2009:286-289.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中老年保健(2021年12期)2021-11-30 02:58:01
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中華詩詞(2018年11期)2018-03-26 06:41:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年8期)2016-10-09 02:11:50
