基于情境感知的廣播電視群組發現策略
2018-05-30 01:40:06王子磊奚宏生
計算機工程 2018年5期
陳 建,王子磊,奚宏生
(中國科學技術大學 自動化系,合肥 230027)
0 概述
目前,大多數的電視節目推薦系統直接采用網站視頻推薦方法。文獻[1]采用基于內容的推薦方法,利用聚類技術訓練出向量空間模型形式的用戶興趣;文獻[2]使用協同過濾推薦方法中的SVD模型,研究如何為用戶推薦電視視頻。還有一些電視推薦系統采用了混合策略[3-4],將協同過濾和基于內容的推薦方法結合使用。然而廣播電視和網站視頻的觀看場景存在著很大的差異。首先,電視用戶為多成員用戶,家庭用戶的收視興趣是所有成員用戶收視興趣的復合形式;其次,成員自由組合,形成了多種觀看模式,用戶的收視興趣存在頻繁遷移的現象。因此,直接應用網站視頻推薦方法來實現電視節目推薦,效果難以保證。
針對廣播電視用戶的多成員用戶問題,一些工作通過識別家庭成員來改善電視推薦系統的性能[5]。ACM在2010年和2011年舉辦了情境感知電影推薦競賽[6](CAMRa),參賽者以家庭為群組單位,實現對家庭成員的識別,并向一個家庭推薦節目。參賽者大多采用分類預測模型,取得了一定的效果。但是這些工作都是建立在家庭成員構成已知的情況下,在實際情況下,成員組成情況往往是難以獲得的。另外,家庭用戶的某個觀看模式,不一定只對應單個成員,而是某些成員組合而成的觀看群組[7]。因此,在家庭成員組成未知的情況下,是無法采用分類模型來解決電視推薦問題的。
在家庭用戶結構未知的情況下,在特定的時段,多個成員組合形成觀看群組,觀看群組的收視興趣可以代表家庭用戶在此時段的收視興趣。文獻[8]利用時間信息,將收視記錄按照時段進行聚類操作;文獻[9]利用時間維度信息,將家庭的總興趣模擬為多個“偽用戶”興趣的組合,通過識別每個家庭的“偽用戶”來提高推薦系統精確度。這些研究工作利用時間情境信息將復合的家庭用戶收視興趣劃分為分時段的用戶子興趣,在一定程度上緩解了因用戶興趣的復合特征而造成推薦精度下降的問題。但是,僅考慮用戶的時段興趣效應是不充足的,電視節目類型十分豐富,致使相同時段播放的節目也可能是不同類別的成員所感興趣的,興趣復合性問題依然存在。
為解決廣播用戶收視興趣復合性問題,并發現收視興趣相似的多家庭用戶群組,本文提出一種基于時間情境感知的電視用戶群組發現策略。其中,收視記錄中的觀看時間是本文所使用的情境參量。具體為采用張量分解來獲取節目和收視時間的隱性特征矩陣,無需使用深度EPG中的節目本體數據[10];利用馬爾可夫聚類算法實現對收視記錄的分類,并根據記錄分類結果發現用戶群組。用戶群組以家庭為單位,群組內每個家庭的收視興趣在收視時間和收視內容上均相似。
1 問題描述
電視群組推薦系統的目標是為群組推薦電視節目或視頻,群組構建的基本原則是各成員在收視興趣上保持相似。因此,如何確定用戶群組是實現群組推薦系統的關鍵。本文所要解決的問題是:有效利用時間情境和節目特征信息,發現在收視時間和收視內容上均相似的用戶群組。表1為本文中所定義的概念符號及其簡略解釋。
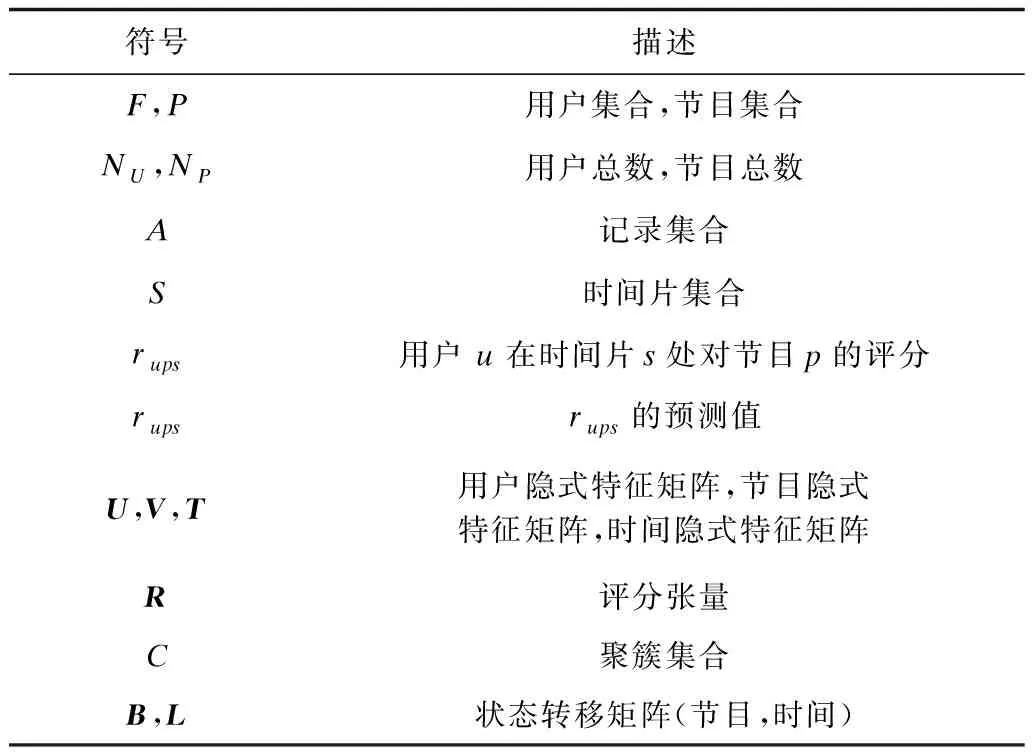
表1 符號定義及描述
典型家庭用戶群組觀看模式的一般場景為:單個家庭用戶由多個家庭成員組成,在某個時段s,某些家庭用戶對節目組ps感興趣,這些家庭用戶構成了一個用戶群組。另外可以認為在時間段s,這些家庭用戶均具有相似的興趣。在其他時段,同樣對應著相應的用戶群組。一個家庭用戶可以被劃分到多個用戶群組中。圖1給出了電視用戶分時段群組構成的一個概念例子:4個電視用戶在3個時段上觀看了電視節目,每個時段對應著一組節目。某些用戶由于在同一時段體現了對同一組節目的興趣,因此這些用戶被劃分為一個用戶群組(如圖1所示的3個群組)。
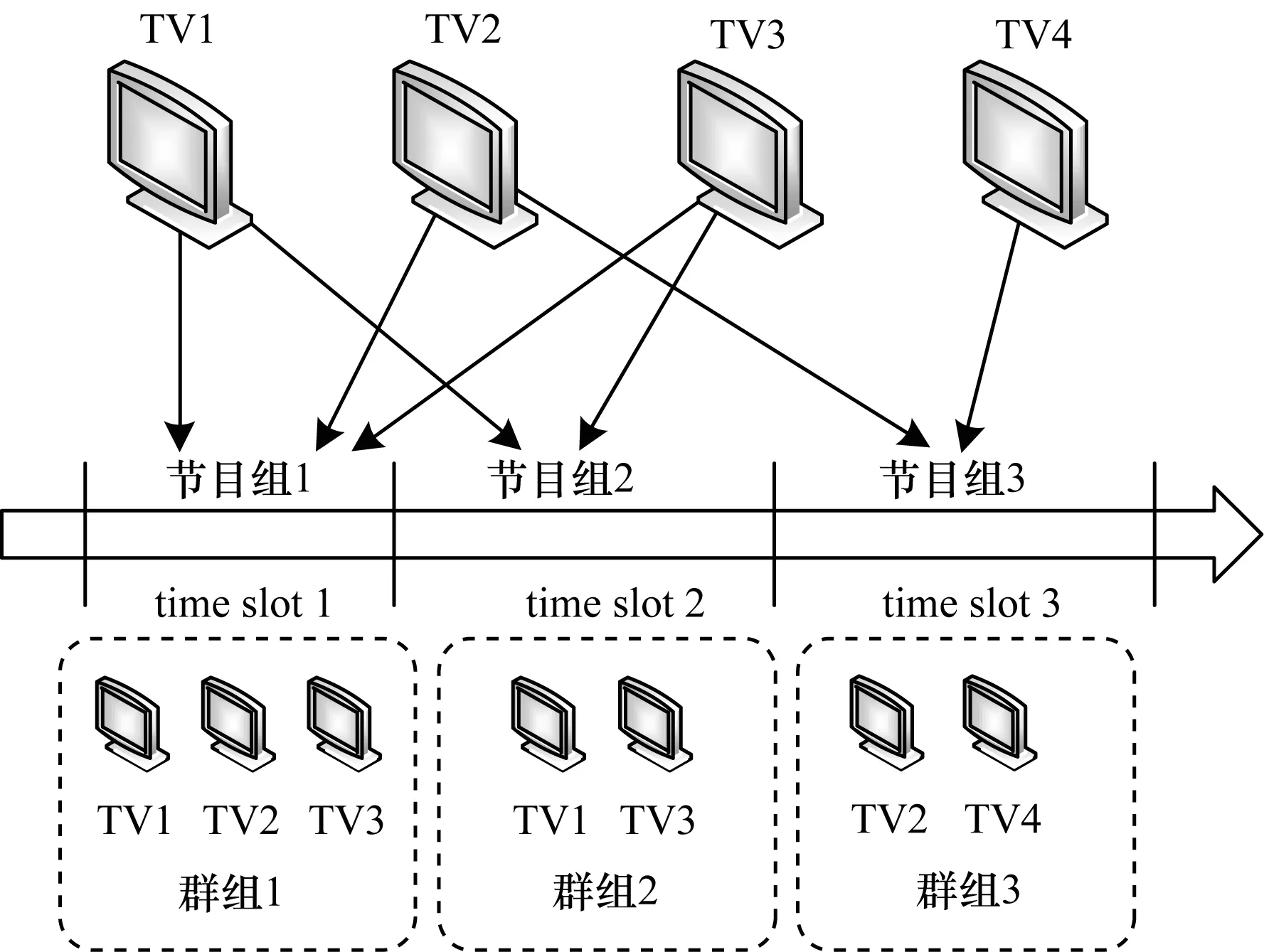
圖1 電視用戶分時段群組構成示例
基于以上考慮,將收視時間特征和收視內容特征作為重要的數據源。輸入的數據集中包括每個家庭用戶的收視情況。通過數據預處理,可以得到用戶-節目-時間-觀看時長這樣的記錄模式。為了精簡地表達時間信息,需要手動將時間維度信息進行離散化處理,即將24 h劃分為不相交的若干時段,即:
(1)
根據離散化的時段,計算用戶在每個時段sl對節目的評分,并構建三維的評分張量R∈NU×NP×|S|。第一步所要完成的是以R為輸入,訓練出節目特征矩陣V以及時間特征矩陣T。矩陣V和矩陣T為后續分析記錄之間的相似性提供了依據。記錄a∈A具有2個屬性,即記錄所對應的節目a.p和對應的收視時段a.s。
設在時段集合Sb?S,興趣相似的家庭用戶分為一組,形成了用戶數為Nb的用戶群組:
(2)
其中,csi表示時段集合s對應的用戶簇cs中的第i個用戶,則對于時段集合S而言,用戶群組總集合可表示為:
(3)
本文的主要目標就是以記錄集合A為輸入來發現用戶群組總集合C,并針對C中的每一個群組推薦節目。實現這個過程需要解決2個關鍵問題:在沒有深度EPG數據的情況下實現對節目的聚類;發現觀看時間和觀看內容均相似的用戶群組。
2 群組發現策略
為解決問題定義中提出的2個主要問題:本文采用張量Tucker分解模型獲取用戶、節目以及時間這3個維度的特征矩陣;以時間、節目特征矩陣分別作為收視記錄的屬性特征,應用馬爾可夫聚類(MCL)算法完成群組發現工作。
2.1 隱性特征獲取
在基于內容的推薦方法中,通常需要使用項目的特征信息,以便于通過聚類、TF-IDF等算法來訓練用戶的特征偏好。在電視節目推薦問題中,一般也是根據深度EPG數據來訓練用戶對節目的偏好模型[7,10-12]。由于節目本體信息存在于深度EPG數據中,而深度EPG數據通常難以獲取,因此本文未使用節目的本體信息,而是利用張量分解模型來自動學習出節目的特征向量,這些特征是通常被稱為隱性特征。同理,還可以學習出時間維度上的特征向量。隱性特征可以代表節目和時間的屬性特征,這樣不同的節目和時間就可以進行相似比較,在此基礎上就能實現對節目和時間的聚類。
張量分解模型是矩陣分解模型在多維空間上的推廣。張量分解有多種形式,目前比較流行的分解有Tucker分解和CP分解。本文選擇Tucker分解模型來獲取隱性特征矩陣。Tucker分解將張量分解成為一個核心張量沿每一階乘上一個矩陣。本文在用戶-節目-時間3個維度所構建的評分張量R∈NU×NV×|S|上做Tucker分解,其中rups∈R表示為用戶u在時段s對節目p的偏好評分。R是一個稀疏的張量,每一個元素都對應著一條隱式評分記錄,采用式(4)計算R中的非空值:
(4)
其中,nups表示用戶u在時段s觀看節目p的次數,dupsi為用戶u第i次觀看節目p所占用的時間,ts為時段s所占的總時長(以分鐘計)。最終計算得到的評分的范圍區間為[0,10]。
對于張量R,其分解式為:
R=M×UU×VV×TT
(5)
即張量R可分解為矩陣U∈NU×dU,T∈|T|×dT,V∈NP×dV和核心稠密張量M∈dU×dV×dT,×U表示張量與矩陣的乘法。矩陣V表示的是節目的隱式特征矩陣,其每一行代表著一個節目的隱性特征,節目之間的特征相似度可以通過比較它們各自的隱性特征來獲得。同理,對于矩陣T也是如此。學習上述3個矩陣和核心張量,需要最小化式(6)所示的損失函數:
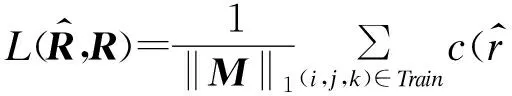
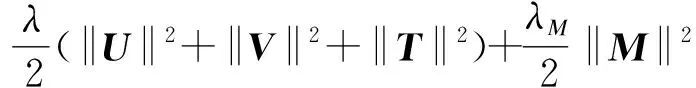
(6)
其中,第2項和第3項是為了避免模型過擬合而設置的正則項,且有:
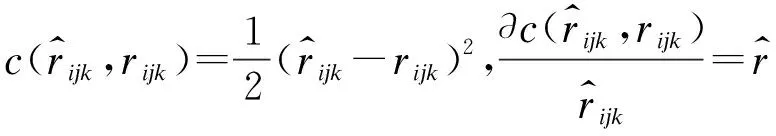
(7)
本文采用隨機梯度下降法(SGD)來學習隱性特征矩陣V、T。首先定義矩陣V、T中的行向量,即vj*表示V的第j行,tk*表示T的第k行。SGD首先計算損失函數的梯度,如式(8)~式(11)所示。
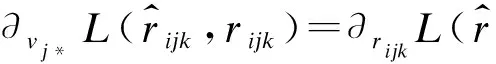
(8)
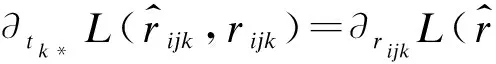
(9)
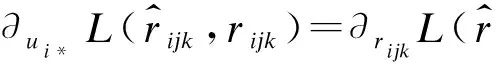
(10)
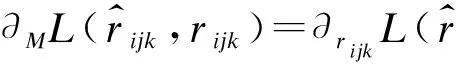
(11)
根據上述計算得到的梯度可以用來更新特征行向量和核心張量,更新行向量的公式為:
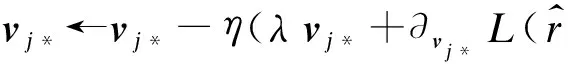
(12)
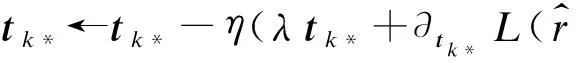
(13)
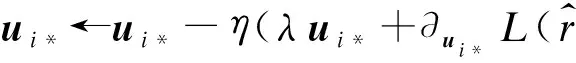
(14)
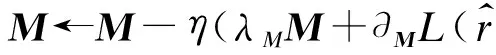
(15)
其中,η為學習率,它表示SGD的學習速率。在實際執行SGD時,首先是選定一個迭代次數d,根據評分矩陣R的評分項劃分好訓練集和測試集,并用隨機值初始化矩陣U、V、T以及核心張量M。然后針對評分矩陣R中的每一項評分,根據式(12)~式(15)計算梯度并更新行向量和核心張量。經過d次迭代,可以獲得矩陣U、V中的任意行向量。
在隱性特征獲取的過程中,dU、dV和dT的值可以自由選擇,但為了保證M的稠密性,一般都設置為較小的值,本文將它們設置為10。另外,可以用區間[0,1]之間的隨機值來實現隱性特征矩陣和核心張量的初始化過程。
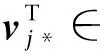
2.2 基于MCL算法的用戶群組發現策略
利用張量Tucker分解訓練出節目和時間2個維度上的隱性特征向量,為發現用戶的聚簇效應提供了必要的條件。廣播電視用戶群組具有一些重要特征:每個家庭用戶的收視興趣是復合的,隨時間呈現周期變化;有些家庭用戶雖整體興趣不同,但在某些時段上是相似的;在相似的時段內,觀看相似節目的用戶表現出的興趣是相似的。根據用戶群組的特征,本文將相同的時段收看相似節目的所有用戶歸為一個用戶群組。
經過處理的觀看記錄包含時間和節目2個屬性,根據記錄和用戶的關聯關系可以鎖定觀看同一類記錄的用戶。為了實現用戶群組發現,本文采用的做法是:首先采用MCL算法[13]分別對收視時間和收視節目進行聚類;然后根據聚類結果對記錄進行分類,即將時間和節目屬性均相似的記錄歸為一類;最后利用記錄分類結果確定對同一類記錄有偏好的用戶群體。
以節目聚類為例,給定2個已經過零-均值規范化處理的節目特征向量v1和v2,且v1,v2∈V,采用余弦相似度來度量2個特征向量的距離:
(16)
根據式(16),可以構建節目特征的狀態轉移矩陣B∈NP×NP。其第i行第j列元素bij表示節目i和節目j之間的相似度。同理可構建時間特征的狀態轉移矩陣L∈|S|×|S|,這2個矩陣即是MCL算法的輸入矩陣。基于MCL算法的用戶群組發現算法過程如下:
算法基于MCL的用戶群組發現
輸入B,L
輸出C
1.給定相似度門檻值θ ,迭代次數MaxIter ,擴展系數e ,膨脹系數r
2.B=MCL(B,θ)/*執行MCL算法*/
3.初始化節目聚簇集CP,cpi∈CP /*節目聚簇歸類*/
4.for i←1 to NPdo
5. for j←1 to NPdo
6. if B(i,j)>0 then
7.cpi←cpi+B(i,j)
8./*接著對時間維度執行MCL算法即聚簇歸類*/
9.CT=get_time_cluster(L)
10./*對記錄進行分類*/
11.初始化AC /*初始化分類記錄結果*/
12.for i←1 to A.size do
13. set ACi←ai
14. for j←i+1 to A.size do
15. if ai.nP=aj.nPand ai.nT=aj.nTthen
16. ACi←ACi+ai
17.AC←AC+ACi
18.rm_repeat(AC)/*去除重復的分類記錄*/
19.初始化用戶群簇集C /*確定用戶群*/
20.for ACiin AC do
21. 遍歷所有對ACi中記錄產生過高評分的用戶Ci
22. C←C+Ci
23.returnC
MCL是群組發現算法的核心部分,它的重點是迭代并交替地執行expansion和inflation操作。在迭代執行MCL算法的擴展和膨脹操作時,有一個去除噪聲的步驟,即設定相似度門檻值θ,將特征矩陣中低于θ的所有值置為0,以去除噪聲,加快收斂速度。經過足夠次數的迭代過程,特征矩陣趨于穩定的收斂狀態。通過觀察矩陣中每一行的正值點,就可以確定節目聚簇和時間聚簇。最后,通過對記錄進行分類來發現用戶群組。對每一條記錄ai∈A,它有2個屬性:ai.nP表示該記錄所屬的節目群簇標號;ai.nT表示該記錄所屬的時間群簇標號。當2條記錄的這2個屬性均在同一個簇(即相似)時,可以將這2條記錄劃分為一類。對每一類記錄產生過高評分的用戶聚集起來,即是最終要發現的用戶群組。這樣通過MCL算法,就成功實現了分段用戶群組的發現。
3 實驗評估
3.1 實驗設置
本文實驗所使用的數據集的主體內容為廣播電視用戶收視記錄,主要包括我國某地區廣播電視家庭用戶從2016年3月1日—3月26日的收視數據。其中,用戶均為廣播電視家庭用戶,沒有家庭成員結構信息:收視內容主要為廣播節目,節目類型豐富,包括電視劇、動畫、紀錄片、電影等。該數據集匹配本文所要解決的問題,可以用于驗證本文所提出的策略的效果。從數據集隨機抽取9 965個用戶的收視數據,經過數據預處理過程,最終的數據集中包括3 424 815條記錄,10 492個廣播節目。訓練集包括3月1號—19號的數據,剩余的數據則作為訓練集。
(17)
3.2 實驗結果
3.2.1 性能分析
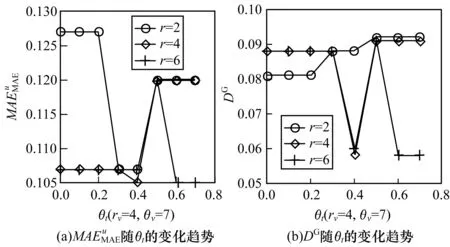
在MCL算法執行的過程中,相似度門檻系數θ和膨脹系數r均會對群組發現的結果產生影響。實驗過程中執行了2次MCL算法,分別是基于特征相似度的時間聚類和時段聚類。這2個過程涉及以下參數:即膨脹系數rv、rt以及相似度門檻系數θv、θt。
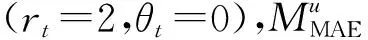
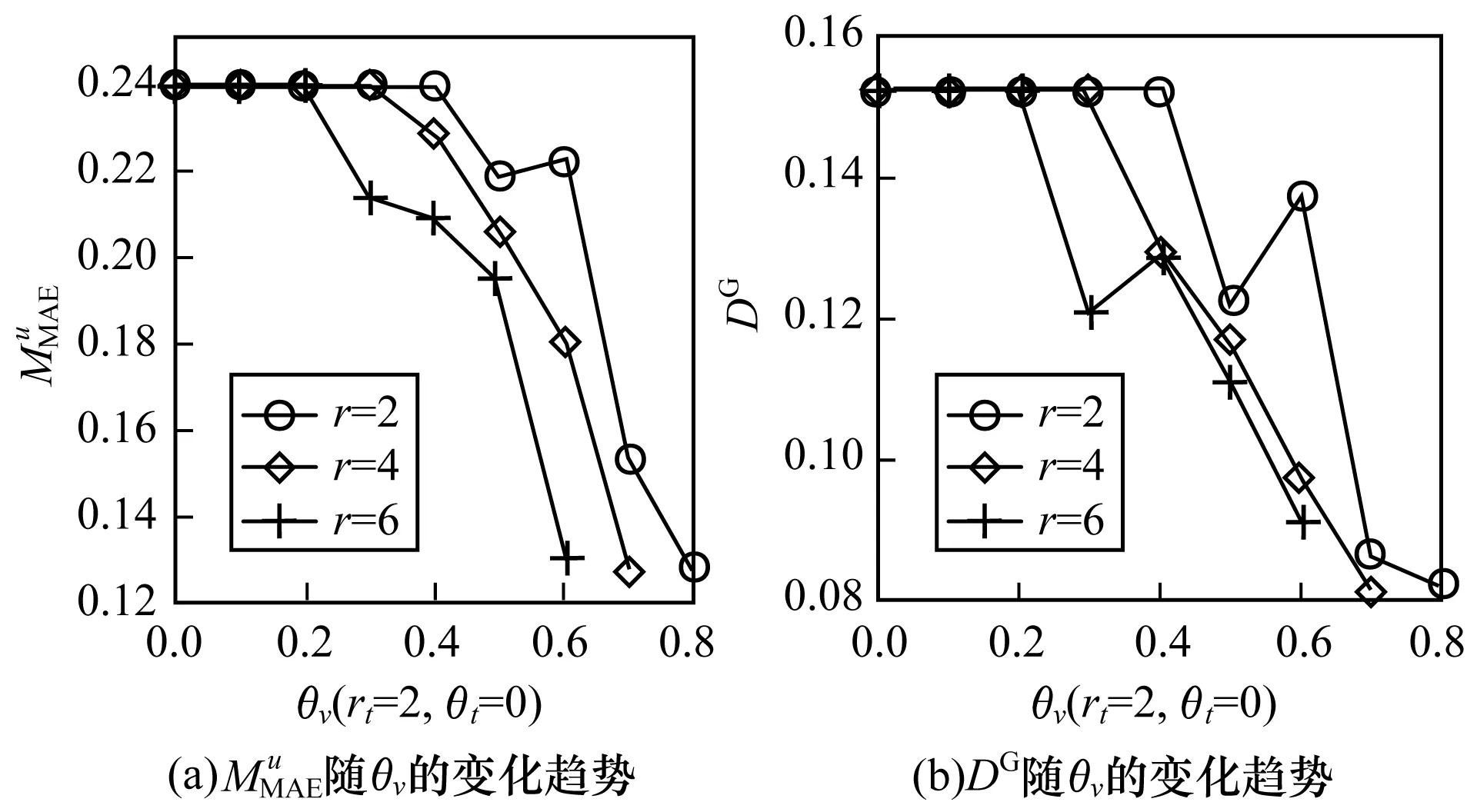
圖和DG隨θv的變化趨勢(非情境)
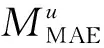
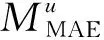
圖和DG隨θt的變化趨勢
群組發現的結果是節目特征聚類結果和時間特征聚類結果的交集,調整參數使得最終發現的群組呈現出不同的結構。MCL算法在執行基于時間特征的記錄聚類時,當θt=0.4時,群組推薦效果達到最優。
3.2.2 性能比較
為了驗證本文所提出的群組發現策略的性能,本文選擇TDP[8]算法和TCC[9]算法實現群組發現策略,并比較它們與本文所提策略在性能方面的差異。這2種算法都采用了時間情境感知的推薦思想,充分考慮到了電視用戶的多成員屬性,利用時間情境信息參與建模過程的方式將復合的電視用戶收視興趣劃分為時段子興趣。相比于基于家庭的興趣特征分析方法,它們是目前更有效的電視用戶興趣模型分析方法。
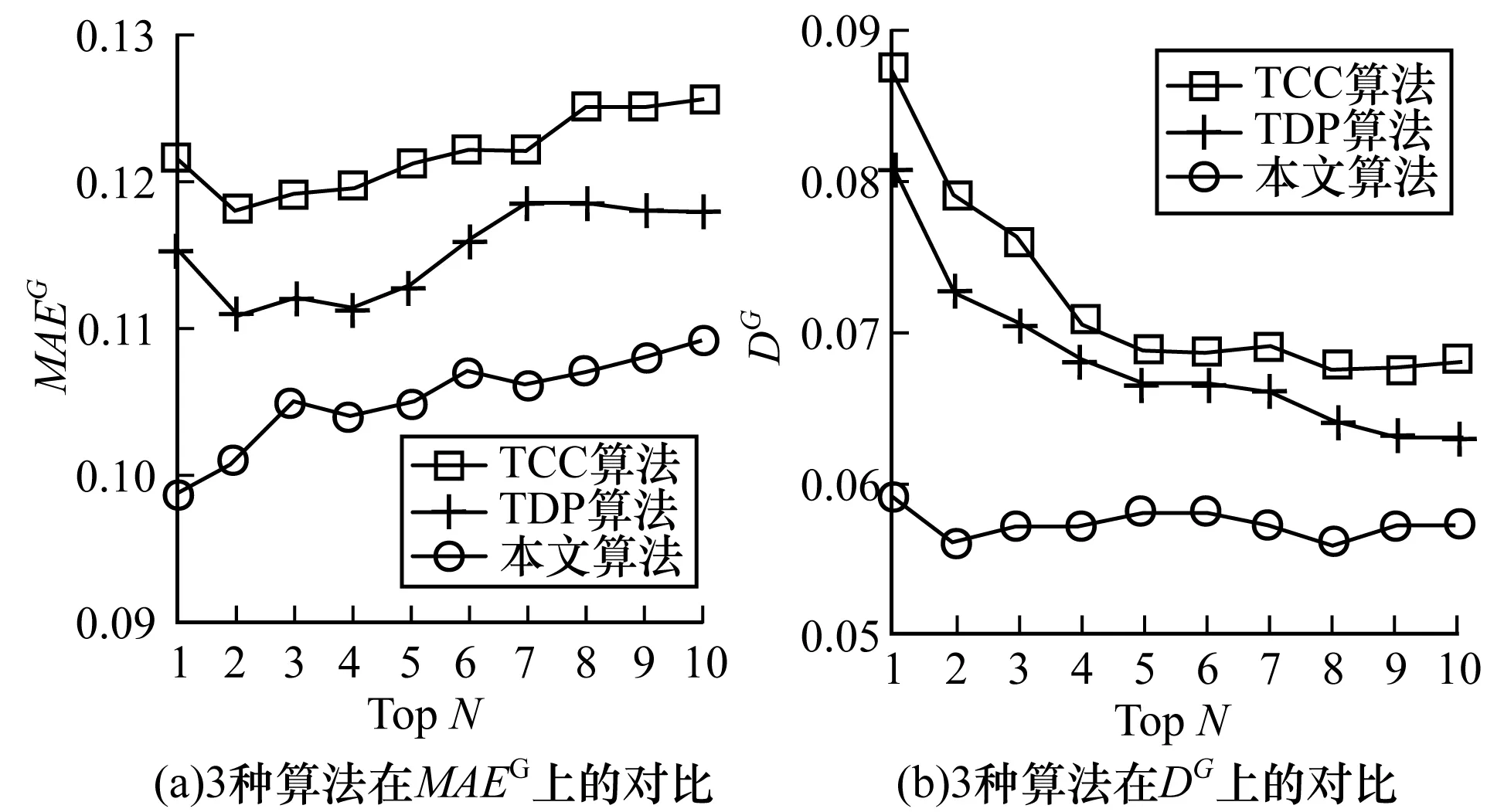
圖4 3種算法在和DG指標上的對比實驗結果
根據上述實驗和分析結果可以看出,本文所提出的MCL群組發現策略成功地發現了在收視時間和收視興趣均相似的用戶群體,且達到了更好的群組推薦性能。
4 結束語
本文提出一種基于情境感知的廣播電視群組發現策略。該策略以家庭用戶為單位,可以識別出特定時段具有相似觀看興趣的所有家庭用戶,并針對家庭用戶群組實現節目推薦功能。群組發現策略可為廣電運營商在個性化付費頻道的設計、客戶細分的研究等工作提供重要的參考。此外,由于本文僅考慮了廣播電視節目群組發現問題,而目前大多電視用戶也傾向于在電視上觀看點播視頻,因此用戶的廣播興趣和點播興趣之間的相互作用關系,將是后續工作的重點內容。
[1] BJELACA M.Towards TV recommender system:experiments with user modeling[J].IEEE Transactions on Consumer Electronics,2010,56(3):1763-1769.
[2] WANG X,NIE X,WANG X,et al.A new recommender system framework for TV video[C]//Proceedings of the 6th International Conference on Information Science and Technology.Washington D.C.,USA:IEEE Press,2016:147-152.
[3] BARRAGANS-MARTINEZ A B,COSTA-MONTENEGRO E,BURGUILLO J C,et al.A hybrid content-based and item-based collaborative filtering approach to recommend TV programs enhanced with singular value decomposition[J].Information Sciences,2010,180(22):4290-4311.
[4] 黃 慧.云媒體電視智能推薦系統的設計與實現[D].南京:東南大學,2015.
[5] CAMPOS P G,BELLOGIN A,DIEZ F,et al.Time feature selection for identifying active household members[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management.New York,USA:ACM Press,2012:2311-2314.
[6] SAID A,BERKOVSKY S,de LUCA E W,et al.Challenge on context-aware movie recommendation:CAMRa2011[C]//Proceedings of the 5th ACM Conference on Recommender Systems.New York,USA:ACM Press,2011:385-386.
[7] LI H,ZHU H,GE Y,et al.Personalized TV recommendation with mixture probabilistic matrix factorization[C]//Proceedings of 2015 SIAM International Conference on Data Mining.Washington D.C.,USA:IEEE Press,2015:352-360.
[8] OH J,SUNG Y,KIM J,et al.Time-dependent user profiling for TV recommendation[C]//Proceedings of the 2nd International Conference on Cloud and Green Computing.Washington D.C.,USA:IEEE Press,2012:783-787.
[9] WANG Z,HE L.User identification for enhancing IP-TV recommendation[J].Knowledge-based Systems,2016,98:68-75.
[10] 李 寧,王子磊,吳 剛,等.個性化影片推薦系統中用戶模型研究[J].計算機應用與軟件,2010,27(12):51-54.
[11] KIM J,KWON E,CHO Y,et al.Recommendation system of IPTV TV program using ontology and k-means clustering[C]//Proceedings of International Conference on Ubiquitous Computing and Multimedia Applications.Berlin,Germany:Springer,2011:123-128.
[12] 陳天昊,帥建梅,朱 明.一種基于協作過濾的電影推薦方法[J].計算機工程,2014,40(1):55-58,62.
[13] VAN D S.A cluster algorithm for graphs[J].Report-information Systems,2000 (10):1-40.
[14] 張玉潔,杜雨露,孟祥武.組推薦系統及其應用研究[J].計算機學報,2016,39(4):745-764.
[15] GARCIA I,PAJARES S,SEBASTIA L,et al.Preference elicitation techniques for group recommender systems[J].Information Sciences,2012,189(20):155-175.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
