基于緩存映射項(xiàng)重用距離的閃存地址映射方法
2018-05-28 03:06:42周權(quán)彪張興軍梁寧靜霍文潔董小社
計(jì)算機(jī)研究與發(fā)展 2018年5期
周權(quán)彪 張興軍 梁寧靜 霍文潔 董小社
(西安交通大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系 西安 710049) (zhouquanbiao1991@163.com)
在當(dāng)前計(jì)算機(jī)應(yīng)用向數(shù)據(jù)密集型轉(zhuǎn)變的大趨勢下,現(xiàn)代計(jì)算機(jī)系統(tǒng)對(duì)外存IO性能的要求不斷提高.磁盤作為傳統(tǒng)外存設(shè)備,雖然容量大、成本低,但是由于固有機(jī)械部件的限制,其IO性能無法滿足當(dāng)下快速交互型應(yīng)用的需求.閃存作為一種無機(jī)械結(jié)構(gòu)存儲(chǔ)介質(zhì),性能遠(yuǎn)優(yōu)于磁盤,具有隨機(jī)存取速度快、能耗低、抗震能力好等優(yōu)點(diǎn),是外存介質(zhì)的理想選擇.隨著閃存技術(shù)的不斷成熟,閃存被廣泛應(yīng)用于消費(fèi)電子和企業(yè)級(jí)計(jì)算機(jī)系統(tǒng)中,以大容量緩存或外存的形式存在[1].
閃存采用浮柵型場效應(yīng)管作為數(shù)據(jù)儲(chǔ)存單元,通過場效應(yīng)管內(nèi)浮置柵極存儲(chǔ)的電荷量多少表示不同的數(shù)據(jù).這種不同于磁盤的數(shù)據(jù)存儲(chǔ)方式,使得閃存具有其獨(dú)特的讀寫性質(zhì),包括“按頁讀寫”、“按塊擦除”和“寫前先擦除”[2],其含義分別是:1)“按頁讀寫”是指對(duì)閃存的讀寫操作必須以物理頁為單位進(jìn)行;2)“按塊擦除”是指閃存擦除操作必須以物理塊為單位進(jìn)行;3)“寫前先擦除”(erase-before-write)是指1個(gè)閃存單元在經(jīng)過1次寫入操作后,必須對(duì)該閃存單元進(jìn)行1次擦除操作后,才能夠?qū)懭胄聰?shù)據(jù).
由于這3個(gè)性質(zhì)的限制,對(duì)閃存的數(shù)據(jù)更新操作必須采取“異地更新”(out-of-place update)[3]的方式完成.“異地更新”是指在閃存中,對(duì)某一邏輯地址的寫入操作,不能直接將新的數(shù)據(jù)內(nèi)容覆蓋寫到原有邏輯地址對(duì)應(yīng)的物理地址上,而必須將新數(shù)據(jù)內(nèi)容寫入一個(gè)新的空閑物理地址,然后通過修改邏輯地址和物理地址映射信息的方式,使邏輯地址指向新的物理地址,并將原物理地址的數(shù)據(jù)無效化,從而達(dá)到更新數(shù)據(jù)的目的.
由于閃存擁有這些獨(dú)特的性質(zhì)和操作,在閃存存儲(chǔ)系統(tǒng)中,為了屏蔽閃存與傳統(tǒng)磁盤不一樣的讀寫特性,需要一個(gè)專用軟件層來對(duì)閃存進(jìn)行管理和優(yōu)化,這就是閃存轉(zhuǎn)換層(flash translation layer,F(xiàn)TL)[4].閃存轉(zhuǎn)換層作為閃存系統(tǒng)中的核心軟件管理層,在整個(gè)閃存軟件棧中起到屏蔽閃存底層存取細(xì)節(jié),向上層文件系統(tǒng)提供存取接口的作用.通過閃存轉(zhuǎn)換層,閃存固態(tài)盤被封裝成像磁盤一樣的塊設(shè)備,上層文件系統(tǒng)不需要修改,即可像讀寫磁盤一樣,正常地讀寫閃存固態(tài)盤.閃存轉(zhuǎn)換層具有一些重要的功能,如地址映射、垃圾回收、磨損均衡、壞塊管理、讀寫數(shù)據(jù)緩存、閃存數(shù)據(jù)糾錯(cuò)和數(shù)據(jù)加密等[4].
閃存轉(zhuǎn)換層地址映射方法的優(yōu)劣極大影響到閃存的性能和壽命.DFTL(demand-based FTL)[5]是經(jīng)典的地址映射方法,它把較大的全局映射表放在閃存中,只將常用的映射項(xiàng)放在緩存中,根據(jù)映射項(xiàng)訪問的近期性作為緩存替換的依據(jù).
DFTL同樣存在一些問題.首先,DFTL采用最近最少使用(least recently used, LRU)替換算法充分尊重了時(shí)間局部性原理,但忽略了負(fù)載的空間局部性特點(diǎn),使得在負(fù)載訪問的地址空間發(fā)生變化時(shí)會(huì)發(fā)生頻繁的緩存失效,導(dǎo)致緩存命中率的下降.
此外,在發(fā)生緩存失效時(shí),如果被換出的映射項(xiàng)是臟映射項(xiàng),即若該映射項(xiàng)曾被修改,那么必須將該臟映射項(xiàng)寫回閃存,以保證元數(shù)據(jù)映射信息的一致性.而臟映射項(xiàng)的頻繁換出,會(huì)帶來對(duì)閃存的頻繁寫操作,為閃存的性能和壽命帶來額外負(fù)擔(dān).
另一方面,DFTL無法優(yōu)化閃存中存在的由于垃圾回收導(dǎo)致的寫放大(write amplification)[6]問題.寫放大問題指對(duì)閃存系統(tǒng)實(shí)際寫入的數(shù)據(jù)量大于文件系統(tǒng)請(qǐng)求寫入的數(shù)據(jù)量.閃存的垃圾回收過程是造成寫放大問題的主要因素之一.在垃圾回收過程中,若被回收物理塊內(nèi)有未被覆寫的有效數(shù)據(jù)頁,則必須進(jìn)行有效頁遷移操作,每個(gè)有效頁需要至少1次讀操作和1次寫操作來完成遷移過程.此外,有效頁的遷移還會(huì)導(dǎo)致其對(duì)應(yīng)的邏輯地址和物理地址映射信息發(fā)生改變,從而引起額外的元數(shù)據(jù)讀寫操作.被回收物理塊內(nèi)的有效頁越多,則需要遷移的有效頁也越多,對(duì)閃存性能和壽命帶來的負(fù)面影響也更大.
針對(duì)上述問題,本文研究采用基于緩存映射項(xiàng)重用距離的地址映射方法IRR-FTL(inter-reference recency-based FTL),優(yōu)化閃存地址映射過程.本文的貢獻(xiàn)主要在:1)通過設(shè)置獨(dú)立的映射頁緩存槽,充分利用負(fù)載的空間局部性,提高緩存映射表的命中率.2)通過基于緩存映射項(xiàng)重用距離的負(fù)載自適應(yīng)寫緩存映射表冷熱分區(qū)方法,將寫緩存映射表分為熱寫緩存映射表和冷寫緩存映射表,并對(duì)冷寫緩存映射表采取非臟映射項(xiàng)優(yōu)先換出和臟映射項(xiàng)最大化批量更新的策略,減少映射頁寫回次數(shù).3)針對(duì)閃存垃圾回收中存在的寫放大問題,實(shí)現(xiàn)基于緩存映射項(xiàng)重用距離的冷熱數(shù)據(jù)分離存儲(chǔ),提高垃圾回收效率.
1 相關(guān)工作
閃存轉(zhuǎn)換層的地址映射過程是指SSD系統(tǒng)將上層文件系統(tǒng)請(qǐng)求的邏輯地址,通過地址映射表轉(zhuǎn)換為下層閃存物理地址的過程.閃存轉(zhuǎn)換層的地址映射策略[4],可以根據(jù)地址映射粒度的大小,大致分為3種,即頁級(jí)地址映射策略[5,7-10]、塊級(jí)地址映射策略[4]和基于日志塊的混合地址映射策略[11-13].
在頁級(jí)地址映射策略中,每一個(gè)邏輯頁地址可以映射到任意一個(gè)物理頁地址.因此在頁級(jí)地址映射表中,需要記錄每一個(gè)邏輯頁和對(duì)應(yīng)物理頁的映射關(guān)系.這種映射方式靈活高效、優(yōu)化空間大、性能較好,但由于映射粒度較小,導(dǎo)致映射表?xiàng)l目較多,因此需要維護(hù)一個(gè)較大的頁級(jí)地址映射表.但由于目前固態(tài)盤容量越來越大,而在固態(tài)盤中往往采用存取速度極快、單位存儲(chǔ)成本較高的RAM,因此一般完整的頁級(jí)地址映射表無法全部裝入RAM中,因此純頁級(jí)映射策略在實(shí)際中應(yīng)用較少.
在塊級(jí)地址映射策略中,每一個(gè)邏輯塊可以映射到任意一個(gè)物理塊上,塊內(nèi)的數(shù)據(jù)頁則需要嚴(yán)格按照邏輯地址的塊內(nèi)偏移量進(jìn)行排列[4].相比于頁級(jí)地址映射策略,塊級(jí)地址映射策略的映射粒度大,所以塊級(jí)地址映射表較小,占用的RAM空間較少.但是,為了維護(hù)塊內(nèi)數(shù)據(jù)頁的偏移量,塊級(jí)地址映射策略在進(jìn)行垃圾回收過程中,需要進(jìn)行數(shù)據(jù)塊合并操作,這種合并操作往往涉及到大量數(shù)據(jù)頁的拷貝和移動(dòng),對(duì)閃存的性能影響較大.因此,相對(duì)于頁級(jí)地址映射策略而言,塊級(jí)地址映射策略是以犧牲映射靈活性和性能為代價(jià),換取空間開銷的減少.
在基于日志塊的混合地址映射策略中,閃存分為數(shù)據(jù)塊區(qū)(data block area)和日志塊區(qū)(log block area).其中數(shù)據(jù)塊區(qū)采用塊級(jí)地址映射策略,而日志塊區(qū)采用頁級(jí)地址映射策略,日志塊區(qū)僅占閃存總?cè)萘康?%[13].通過日志塊暫時(shí)接納寫入的無序數(shù)據(jù),當(dāng)日志塊區(qū)滿時(shí),再使用合并操作(merge operation),將日志塊與對(duì)應(yīng)的數(shù)據(jù)塊進(jìn)行合并.由于日志塊采用性能較好的頁級(jí)地址映射策略,因此可以較好地吸收隨機(jī)寫入的數(shù)據(jù).但是由于在日志塊與數(shù)據(jù)塊的合并過程中,有較大幾率發(fā)生開銷較大的“全合并”(full merge)操作,因此基于日志塊的混合地址映射策略同樣會(huì)出現(xiàn)閃存性能下降的現(xiàn)象.典型的基于日志塊的混合地址映射策略包括BAST[11],F(xiàn)AST[12],SuperBlock[13].
為了解決基于日志塊的混合地址映射策略中合并操作帶來的額外讀寫開銷問題,2009年Gupta等人[5]提出了基于需求的閃存轉(zhuǎn)換層地址映射方法DFTL.DFTL采用頁級(jí)地址映射策略,無需數(shù)據(jù)塊合并操作,它將占用空間較大的全局頁級(jí)地址映射表以映射頁的形式存放在容量較大的閃存中,在容量較小而速度較快的RAM中設(shè)置緩存映射表,根據(jù)負(fù)載需求,動(dòng)態(tài)地將最近最常使用的映射信息換入緩存映射表中,實(shí)現(xiàn)性能和RAM空間開銷的平衡.此外,DFTL還在RAM中設(shè)置全局映射目錄(global translation directory, GTD)記錄映射頁在閃存中的物理位置.DFTL采用邏輯頁級(jí)的LRU算法保證緩存映射表的命中率,減少由于緩存失效造成的元數(shù)據(jù)換入換出操作;通過批量更新和推遲拷貝技術(shù),減少由于元數(shù)據(jù)更新而造成的閃存映射頁寫回操作,提高閃存IO性能.但DFTL未充分利用負(fù)載的空間局部性特點(diǎn)提高緩存命中率.緩存中臟映射項(xiàng)的頻繁換出也會(huì)帶來額外映射頁操作開銷.此外,DFTL也未能對(duì)閃存垃圾回收過程中存在的有效頁遷移開銷進(jìn)行優(yōu)化.
此后,針對(duì)DFTL存在的問題,國內(nèi)外有許多基于DFTL的研究被提出[7-10, 14-17].LazyFTL[7]通過設(shè)置更新數(shù)據(jù)區(qū)和冷數(shù)據(jù)區(qū)分離冷熱數(shù)據(jù),并通過設(shè)置更新映射表推遲映射信息的更新操作;通過設(shè)置標(biāo)志位,選擇更新開銷最小的映射信息進(jìn)行更新,減少映射頁額外操作.OAT[8]則將緩存映射信息的粒度從映射項(xiàng)增大到映射頁,以提高命中率;同時(shí),為了解決DFTL的垃圾回收過程中涉及過多映射頁的問題,通過將映射頁對(duì)應(yīng)的數(shù)據(jù)頁聚集到同一物理塊內(nèi),減少垃圾回收過程中的映射頁操作.TPFTL[9]則充分挖掘負(fù)載的空間局部性,根據(jù)緩存中映射項(xiàng)特征,動(dòng)態(tài)調(diào)整預(yù)取的映射項(xiàng)數(shù)量,提高緩存命中率.CPFTL[10]將映射表劃分為冷映射表和熱映射表,對(duì)冷映射表采用頁聚簇的方法,減少由于映射項(xiàng)換出而導(dǎo)致的額外映射頁操作.與文獻(xiàn)[7-10]不同,本文通過獨(dú)立的映射頁緩存槽挖掘負(fù)載的空間局部性,提高緩存命中率.此外,通過緩存映射項(xiàng)重用距離,實(shí)現(xiàn)負(fù)載自適應(yīng)的寫緩存映射表冷熱分區(qū)方法,優(yōu)先換出冷寫緩存映射表中已被更新的非臟映射項(xiàng),并且采用臟映射項(xiàng)最大化批量更新策略,減少由于緩存失效造成的映射頁操作開銷.
另一方面,在閃存中冷熱數(shù)據(jù)分離存儲(chǔ)對(duì)減少垃圾回收開銷、提高垃圾回收效率有重要作用[3].通過將熱度相近的頁面存儲(chǔ)在同一物理塊中,使得同一物理塊內(nèi)的頁面更有可能在相近的時(shí)間段內(nèi)被更新,從而減少在垃圾回收過程時(shí)進(jìn)行的有效頁遷移次數(shù),提高垃圾回收效率.有諸多文獻(xiàn)是通過閃存冷熱數(shù)據(jù)分離存儲(chǔ)[14-17],減少垃圾回收過程中的有效頁遷移開銷,提高閃存性能.
LAST[14]采用不同的地址映射策略管理隨機(jī)請(qǐng)求和連續(xù)請(qǐng)求,同時(shí)通過冷熱數(shù)據(jù)分離,減少垃圾回收開銷.HFTL[15]則基于多Hash框架,先識(shí)別冷熱邏輯塊,再進(jìn)一步判斷熱邏輯塊內(nèi)部的邏輯頁冷熱性質(zhì),找出被頻繁更新的邏輯頁,實(shí)現(xiàn)冷熱數(shù)據(jù)分離.文獻(xiàn)[16]采用多層布隆過濾器的方法分離冷熱數(shù)據(jù),不僅考慮了數(shù)據(jù)存取頻率,還考慮了數(shù)據(jù)使用的近期性,采用滑動(dòng)窗口的方式捕捉細(xì)粒度的數(shù)據(jù)近期性信息,實(shí)現(xiàn)閃存冷熱數(shù)據(jù)分離.不同于上述基于數(shù)據(jù)存取頻率判別數(shù)據(jù)冷熱性質(zhì)的方法,本文將數(shù)據(jù)訪問的重用距離作為判斷冷熱數(shù)據(jù)的標(biāo)準(zhǔn),相比數(shù)據(jù)訪問頻率,數(shù)據(jù)訪問重用距離對(duì)數(shù)據(jù)的冷熱變化更敏感.而對(duì)于閃存而言,數(shù)據(jù)頁的寫入重用距離即是數(shù)據(jù)頁被無效化的時(shí)間間隔,因此也更適合作為閃存冷熱數(shù)據(jù)分離標(biāo)準(zhǔn).
ASA-FTL[17]將邏輯頁寫入間隔作為冷熱數(shù)據(jù)分離的依據(jù),記錄每一個(gè)邏輯頁面的寫入間隔大小,并采用抽樣聚類的方式將頁面分組存儲(chǔ),實(shí)現(xiàn)冷熱數(shù)據(jù)分離.與之類似,本文同樣將頁面寫入間隔,即數(shù)據(jù)頁寫入重用距離作為判斷冷熱性質(zhì)的依據(jù),但是相比ASA-FTL,IRR-FTL不需要記錄所有頁面的重用距離,而是通過分離出在當(dāng)前負(fù)載中熱度較高的緩存映射項(xiàng),從而識(shí)別出當(dāng)前熱度較高的數(shù)據(jù)頁,從而在節(jié)省空間開銷的同時(shí)降低記錄和計(jì)算頁面重用距離的復(fù)雜性.
2 負(fù)載自適應(yīng)的寫緩存冷熱分區(qū)方法
針對(duì)寫緩存映射表,本文提出一種基于緩存映射項(xiàng)重用距離的寫緩存映射表冷熱分區(qū)方法.不同于采用訪問頻率作為分離標(biāo)準(zhǔn),本方法將緩存映射表中的寫緩存映射項(xiàng)分為重用距離較短的熱映射項(xiàng)和重用距離較長的冷映射項(xiàng),并根據(jù)冷熱重用距離閾值將寫緩存映射表分為熱寫緩存映射表和冷寫緩存映射表.同時(shí),該方法能夠根據(jù)負(fù)載局部性情況動(dòng)態(tài)調(diào)節(jié)冷熱分區(qū)的相對(duì)大小,實(shí)現(xiàn)負(fù)載自適應(yīng).
2.1 數(shù)據(jù)對(duì)象熱度評(píng)價(jià)標(biāo)準(zhǔn)
一般而言,對(duì)數(shù)據(jù)對(duì)象的熱度有2種評(píng)價(jià)方法:1)根據(jù)數(shù)據(jù)對(duì)象在一定時(shí)間間隔內(nèi)的訪問次數(shù)即訪問頻率來判斷頁面熱度[13].訪問頻率越高的頁面,則其熱度越高;相反,若某頁面在一個(gè)較長時(shí)間間隔內(nèi)訪問次數(shù)較少,則證明其熱度較低.2)數(shù)據(jù)對(duì)象熱度評(píng)價(jià)方法,則是根據(jù)數(shù)據(jù)對(duì)象2次訪問之間的時(shí)間間隔[18],即重用距離進(jìn)行判斷.若數(shù)據(jù)對(duì)象2次訪問之間的時(shí)間間隔較短,則該數(shù)據(jù)對(duì)象更有可能是熱度較高的數(shù)據(jù)對(duì)象.
基于數(shù)據(jù)對(duì)象訪問頻率的冷熱數(shù)據(jù)判別方法是判斷冷熱數(shù)據(jù)最直接的方法.但是,由于現(xiàn)實(shí)中的工作負(fù)載處于不斷變化的過程之中,在前一個(gè)時(shí)間段內(nèi)訪問次數(shù)較多的熱數(shù)據(jù)可能會(huì)因?yàn)樨?fù)載變化而冷卻成為訪問較少的冷數(shù)據(jù),但此時(shí)熱數(shù)據(jù)可能會(huì)由于前一個(gè)時(shí)間段較高的訪問次數(shù),而需要經(jīng)過較長的時(shí)間后才會(huì)被冷卻.相比之下,數(shù)據(jù)對(duì)象2次訪問的時(shí)間間隔,即重用距離,對(duì)負(fù)載的變化則更為敏感.當(dāng)新數(shù)據(jù)對(duì)象的訪問時(shí)間間隔短于熱數(shù)據(jù)最后一次訪問時(shí)間點(diǎn)距離當(dāng)前時(shí)間點(diǎn)的時(shí)間間隔時(shí),新數(shù)據(jù)對(duì)象即可取代原來的熱數(shù)據(jù)對(duì)象,成為新的熱數(shù)據(jù).在本文中,數(shù)據(jù)對(duì)象是指緩存映射項(xiàng),重用距離特指對(duì)特定邏輯頁地址的2次寫入操作之間的時(shí)間間隔.
對(duì)閃存而言,某一邏輯頁面的2次寫入操作之間的時(shí)間間隔,代表了該頁面在第1次寫入閃存后,其數(shù)據(jù)頁在閃存中作為有效數(shù)據(jù)頁存在直至被無效化的時(shí)間間隔.若該時(shí)間間隔越短,則該頁面熱度越高,同時(shí)也意味著該頁面被無效化越快,在垃圾回收時(shí)更有可能不需要進(jìn)行額外的有效頁遷移操作.因此,相對(duì)于使用頁面訪問頻率作為冷熱數(shù)據(jù)判斷標(biāo)準(zhǔn),頁面的寫入時(shí)間間隔,即重用距離,更適合作為閃存數(shù)據(jù)冷熱分離的判斷依據(jù).
2.2 緩存映射項(xiàng)重用距離
映射項(xiàng)重用距離(inter-reference recency,IRR)[18],此處特指寫入重用距離,是指對(duì)某一映射項(xiàng)的2次寫入之間,間隔地被其他寫入請(qǐng)求訪問的不同的映射項(xiàng)數(shù)量.例如對(duì)于寫入訪問序列:{1,2,3,2,4,1,4}、映射項(xiàng)1的2次訪問之間,間隔了3個(gè)不同的邏輯頁映射項(xiàng)2,3,4,因此映射項(xiàng)1的重用距離是3.同理,映射項(xiàng)4的重用距離是1.
采用映射項(xiàng)重用距離作為區(qū)分冷熱元數(shù)據(jù)的標(biāo)準(zhǔn),是因?yàn)橄鄬?duì)于映射項(xiàng)訪問頻率而言,重用距離對(duì)映射項(xiàng)熱度的變化更敏感.此外,映射項(xiàng)的重用距離也隱含了映射項(xiàng)對(duì)應(yīng)的數(shù)據(jù)頁在閃存中被無效化的寫入間隔.如果一個(gè)映射項(xiàng)的重用距離為5,則意味著在經(jīng)過5次寫入操作之后,該映射項(xiàng)對(duì)應(yīng)的數(shù)據(jù)頁被無效化.因此,重用距離更適合用于閃存冷熱數(shù)據(jù)分離.
本文在緩存映射表中使用LRU鏈表來計(jì)算緩存映射項(xiàng)的重用距離.在某時(shí)刻,在緩存映射表的LRU鏈表中,某命中的映射項(xiàng)的重用距離,可以表征為:該映射項(xiàng)被命中時(shí),其結(jié)點(diǎn)所在位置距離鏈表首部的距離.如圖1所示,若此時(shí)映射項(xiàng)1被命中,則映射項(xiàng)1的重用距離為該映射項(xiàng)距離鏈表首部的距離,此時(shí)是3.

Fig. 1 Translation entry’s IRR in cache mapping table圖1 緩存映射表中被命中映射項(xiàng)的重用距離
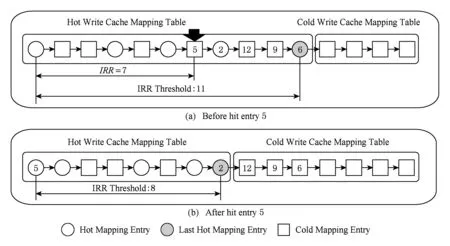
Fig. 2 The workload adaptive hot/cold cache mapping area based on IRR圖2 基于重用距離的負(fù)載自適應(yīng)寫緩存映射表冷熱分區(qū)
同時(shí),我們定義某時(shí)刻映射項(xiàng)的潛在重用距離為:當(dāng)前時(shí)刻,該映射項(xiàng)結(jié)點(diǎn)距離鏈表首部的距離.若當(dāng)前時(shí)刻,該映射項(xiàng)被命中,則該映射項(xiàng)潛在重用距離等于重用距離.某一時(shí)刻某一映射項(xiàng)的潛在重用距離,表征在當(dāng)前時(shí)刻該映射項(xiàng)可能達(dá)到的最短重用距離,該映射項(xiàng)下一次命中時(shí)的重用距離大于或等于潛在重用距離,若該時(shí)刻該映射項(xiàng)命中,則等號(hào)成立.
在基于緩存映射項(xiàng)重用距離的緩存映射表中,將映射項(xiàng)根據(jù)上一次命中時(shí)重用距離的大小分為冷緩存映射項(xiàng)和熱緩存映射項(xiàng).緩存映射項(xiàng)鏈表同樣遵循LRU規(guī)則,每次命中的映射項(xiàng),無論是冷緩存映射項(xiàng)或是熱緩存映射項(xiàng),都會(huì)被移動(dòng)到鏈表首部.而在緩存中,冷熱重用距離閾值即為鏈表中最后一個(gè)熱映射項(xiàng)的潛在重用距離.
冷熱映射項(xiàng)之間的轉(zhuǎn)換規(guī)則可以定義為:當(dāng)某一冷映射項(xiàng)命中時(shí),若該冷映射項(xiàng)的重用距離比最后一個(gè)熱映射項(xiàng)的潛在重用距離更短,即若該冷映射項(xiàng)比最后一個(gè)熱映射項(xiàng)更靠近鏈表首部,則該冷映射項(xiàng)可以取代最后一個(gè)熱映射項(xiàng)成為熱映射項(xiàng).這是因?yàn)椋谀硶r(shí)刻,若某冷映射項(xiàng)命中時(shí),其位置在最后一個(gè)熱映射項(xiàng)之前,則該命中的冷映射項(xiàng)當(dāng)前的重用距離必定比最后一個(gè)熱映射項(xiàng)未來命中時(shí)的重用距離更短.因此,該冷映射項(xiàng)可以代替原來的最后一個(gè)熱映射項(xiàng)轉(zhuǎn)變?yōu)闊嵊成漤?xiàng),而最后一個(gè)熱映射項(xiàng)作為潛在重用距離最長的熱映射項(xiàng),將被轉(zhuǎn)換為冷映射項(xiàng).
舉例分析,有如圖2(a)所示的LRU鏈表,當(dāng)冷映射項(xiàng)5被命中時(shí),此時(shí)映射項(xiàng)5的重用距離為7,而最后一個(gè)熱映射項(xiàng)6的潛在重用距離為11,意味著熱映射項(xiàng)6在未來命中時(shí)的重用距離大于等于11,比冷映射項(xiàng)5的重用距離更長,因此冷映射項(xiàng)5可以取代熱映射項(xiàng)6成為新的熱映射項(xiàng),而熱映射項(xiàng)6則被冷卻為冷映射項(xiàng).
2.3 基于IRR的寫緩存冷熱分區(qū)方法
如圖2所示,本文基于緩存映射項(xiàng)的重用距離,以最后一個(gè)熱映射項(xiàng)為界,將寫緩存映射表分為熱寫緩存映射表(hot write cache mapping table,HW-CMT)和冷寫緩存映射表(cold write cache mapping table,CW-CMT).潛在重用距離小于冷熱重用距離閾值的映射項(xiàng)在HW-CMT中,潛在重用距離大于冷熱重用距離閾值的映射項(xiàng)在CW-CMT中.
HW-CMT中存放的是最后一個(gè)熱映射項(xiàng)之前的映射項(xiàng),即所有的熱映射項(xiàng)和一部分最近發(fā)生寫入操作的冷映射項(xiàng).由于該部分冷映射項(xiàng)最近曾被訪問,如果再次命中,則由于其重用距離比最后一個(gè)熱映射項(xiàng)的潛在重用距離更短,因此可以代替最后一個(gè)熱映射項(xiàng),轉(zhuǎn)換為新的熱映射項(xiàng),并被放到HW-CMT鏈表首部.
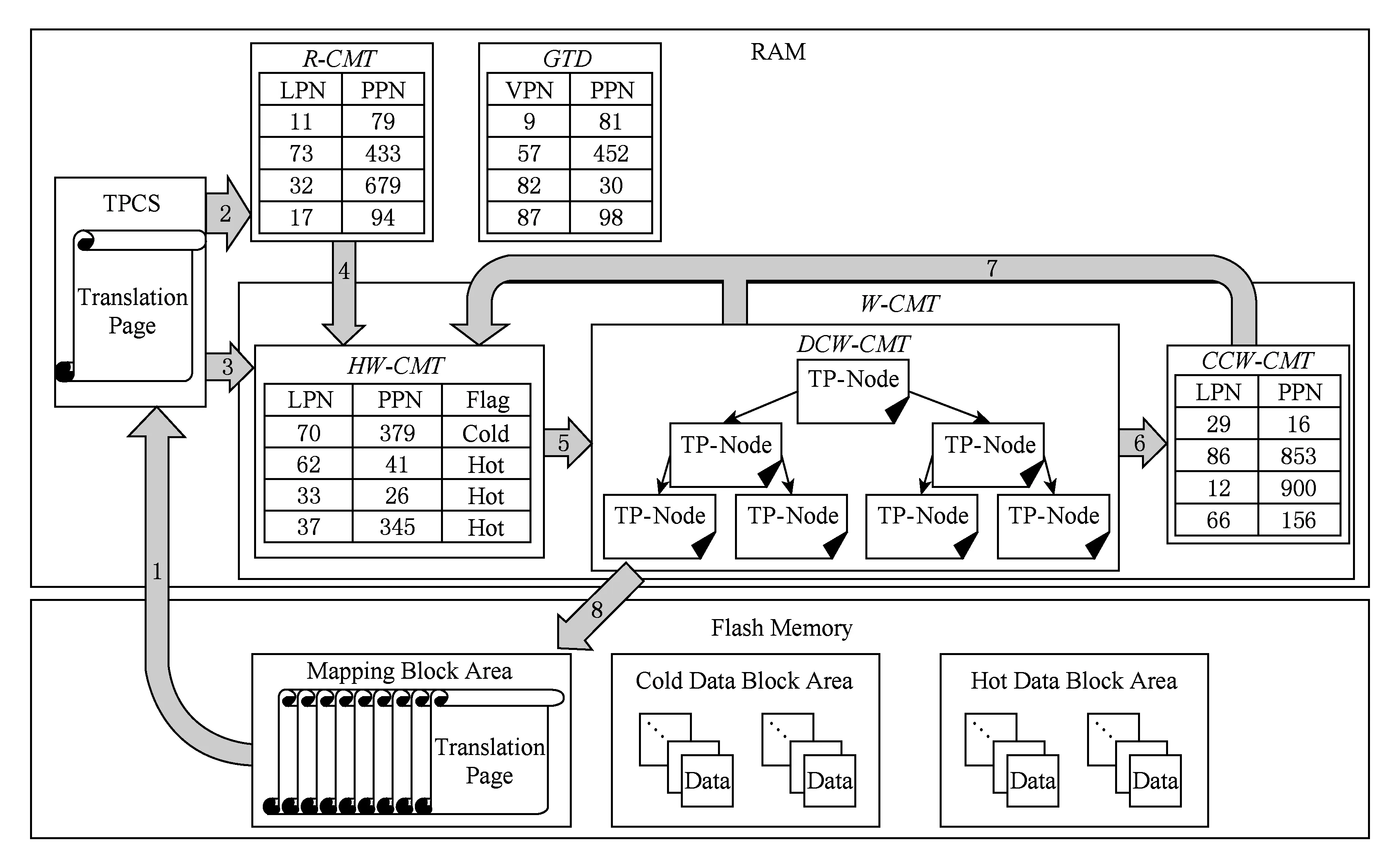
Fig. 3 The overall framework of IRR-FTL圖3 IRR-FTL整體框架
CW-CMT中存放的是最后一個(gè)熱映射項(xiàng)之后的冷映射項(xiàng).CW-CMT中的冷映射項(xiàng)即使再次命中,因?yàn)槠洚?dāng)前命中的重用距離大于最后一個(gè)熱映射的潛在重用距離,所以無法轉(zhuǎn)換為熱映射項(xiàng),而是以冷映射項(xiàng)的形式再次插入HW-CMT鏈表首部,給予其在HW-CMT被命中而轉(zhuǎn)換為熱映射項(xiàng)的機(jī)會(huì).當(dāng)寫緩存發(fā)生失效且寫緩存已滿時(shí),系統(tǒng)會(huì)從CW-CMT中采用特定策略選擇映射項(xiàng)進(jìn)行換出操作.
當(dāng)HW-CMT中的最后一個(gè)熱映射項(xiàng)被轉(zhuǎn)換為冷映射項(xiàng)或最后一個(gè)熱映射項(xiàng)因被命中而被移動(dòng)到HW-CMT隊(duì)首時(shí),會(huì)進(jìn)行“剪枝”操作,即將HW-CMT鏈表尾部所有的非熱映射項(xiàng)移動(dòng)到CW-CMT中,保證了冷熱寫緩存映射表分區(qū)原則,即HW-CMT鏈表的最后一個(gè)映射項(xiàng)是熱映射項(xiàng).如圖2(a)所示,當(dāng)冷映射項(xiàng)5因命中而轉(zhuǎn)變?yōu)闊嵊成漤?xiàng)時(shí),最后一個(gè)熱映射項(xiàng)6將轉(zhuǎn)化為冷映射項(xiàng).此時(shí),由于HW-CMT最后一個(gè)映射項(xiàng)不是熱映射項(xiàng),因此發(fā)生“剪枝”操作,如圖2(b)所示,冷映射項(xiàng)12,9,6將落入CW-CMT中.而最后一個(gè)熱映射項(xiàng)變?yōu)橛成漤?xiàng)2,冷熱重用距離閾值將變?yōu)?.
2.4 負(fù)載自適應(yīng)的冷熱緩存映射區(qū)比例
如圖2所示,在本方法中,HW-CMT和CW-CMT的總大小是固定的.但是,它們的相對(duì)大小是不斷變化的.HW-CMT和CW-CMT的相對(duì)大小由最后一個(gè)熱映射項(xiàng)的潛在重用距離決定的.若最后一個(gè)熱映射項(xiàng)距離鏈表首部越遠(yuǎn),則HW-CMT越大、CW-CMT越小.當(dāng)冷熱映射項(xiàng)的比例一定時(shí),若負(fù)載的局部性越強(qiáng),則最后一個(gè)熱映射項(xiàng)越靠近鏈表首部,HW-CMT越小,CW-CMT越大;相同負(fù)載環(huán)境下,若熱映射項(xiàng)比例越小,則最后一個(gè)熱映射項(xiàng)距離鏈表首部更近,HW-CMT越小,CW-CMT越大.
因此,為了保證CW-CMT不為空,需要維持CW-CMT的長度處于一個(gè)合理的區(qū)間內(nèi).當(dāng)CW-CMT小于該區(qū)間時(shí),系統(tǒng)會(huì)通過減少熱映射項(xiàng)數(shù)量的方式,使最后一個(gè)熱映射項(xiàng)位置靠前,使得更多的映射項(xiàng)落入CW-CMT中;當(dāng)CW-CMT大于該區(qū)間時(shí),系統(tǒng)會(huì)通過增大熱映射項(xiàng)數(shù)量的方式,使最后一個(gè)熱映射項(xiàng)位置靠后,從而使更多映射項(xiàng)被保留在HW-CMT中.
3 基于IRR的閃存轉(zhuǎn)換層地址映射方法
本文基于頁級(jí)地址映射策略,提出一種基于緩存映射項(xiàng)重用距離的閃存轉(zhuǎn)換層地址映射方法IRR-FTL.圖3展示了IRR-FTL系統(tǒng)整體框架.
IRR-FTL通過設(shè)置獨(dú)立的映射頁緩存槽,充分利用負(fù)載的空間局部性,提高緩存命中率;通過讀寫緩存映射表分離,避免讀請(qǐng)求對(duì)計(jì)算寫入重用距離造成影響;通過基于緩存映射項(xiàng)重用距離的負(fù)載自適應(yīng)寫緩存映射冷熱分區(qū)方法,分離出重用距離較長的熱映射項(xiàng)和重用距離較短的冷映射項(xiàng),并將其對(duì)應(yīng)數(shù)據(jù)寫入不同的閃存區(qū)域,實(shí)現(xiàn)冷熱數(shù)據(jù)分離;此外,將冷寫緩存映射表分為非臟緩存映射區(qū)和臟緩存映射區(qū),通過非臟映射項(xiàng)優(yōu)先換出和臟映射項(xiàng)最大化批量更新的方式,減少映射信息寫回開銷,提高閃存性能.
3.1 系統(tǒng)架構(gòu)
IRR-FTL將閃存分為冷數(shù)據(jù)區(qū)(cold data block area)、熱數(shù)據(jù)區(qū)(hot data block area)和映射塊區(qū)(mapping block area),分別存儲(chǔ)冷用戶數(shù)據(jù)、熱用戶數(shù)據(jù)和全局映射表.全局映射表以映射頁的形式存儲(chǔ)在閃存的映射塊區(qū)中.在RAM中,使用全局轉(zhuǎn)換目錄(global translation directory,GTD)記錄映射頁在閃存中的物理位置.系統(tǒng)分別設(shè)置讀緩存映射表(read cache mapping table,R-CMT)和寫緩存映射表(write cache mapping table,W-CMT).通過分離讀寫緩存映射表,避免讀請(qǐng)求對(duì)寫請(qǐng)求重用距離計(jì)算造成的影響.同時(shí),為了適應(yīng)負(fù)載變化,系統(tǒng)會(huì)根據(jù)前一段時(shí)間負(fù)載的讀寫比例,動(dòng)態(tài)調(diào)整R-CMT和W-CMT的相對(duì)大小.
W-CMT中存放的是被寫請(qǐng)求訪問過的映射項(xiàng).根據(jù)第2節(jié)中論述的基于緩存映射項(xiàng)重用距離的負(fù)載自適應(yīng)寫緩存映射表冷熱分區(qū)方法,W-CMT被分為HW-CMT和CW-CMT.而CW-CMT又被進(jìn)一步分為冷臟寫緩存映射表和冷非臟寫緩存映射表.冷臟寫緩存映射表(dirty cold write cache mapping table,DCW-CMT)存放冷映射項(xiàng)中未同步寫回閃存的臟映射項(xiàng),該部分映射項(xiàng)的換出需要進(jìn)行映射頁寫回操作;冷非臟寫緩存映射表(clean cold write cache mapping table,CCW-CMT)存放冷映射項(xiàng)中已被寫回閃存的非臟映射項(xiàng),由于該部分映射項(xiàng)已經(jīng)被寫回閃存,所以可以直接丟棄,而不需要換出開銷.
下面分別介紹IRR-FTL的關(guān)鍵數(shù)據(jù)結(jié)構(gòu).
1) 映射頁緩存槽TPCS
本文在RAM中設(shè)置大小為1個(gè)映射頁的映射頁緩存槽(translation page cache slot, TPCS),用以緩存每次讀入的映射頁(如圖3中箭頭1所示).每個(gè)映射頁包含了一定邏輯地址范圍內(nèi)的映射項(xiàng)信息,有利于吸收連續(xù)的和較大的讀寫請(qǐng)求,充分挖掘負(fù)載的空間局部性.同時(shí),為了保證元數(shù)據(jù)的一致性,當(dāng)某映射項(xiàng)被讀或?qū)憰r(shí),該映射項(xiàng)會(huì)被從TPCS移動(dòng)到R-CMT或W-CMT中(如圖3中箭頭2和箭頭3所示).在地址轉(zhuǎn)換過程中,將會(huì)先檢索讀寫緩存映射表中是否有目標(biāo)映射項(xiàng),若找不到則才會(huì)檢索TPCS.當(dāng)發(fā)生緩存失效時(shí),TPCS內(nèi)原有的映射信息將被丟棄,然后再將需求的映射頁換入TPCS.
2) 讀緩存映射表R-CMT
讀緩存映射表(read cache mapping table,R-CMT)中存放的是只被讀請(qǐng)求訪問過的映射項(xiàng),以LRU方式組織.由于閃存讀操作并不會(huì)改變映射信息,因此,讀緩存映射表的換出操作沒有映射項(xiàng)寫回開銷.當(dāng)讀請(qǐng)求導(dǎo)致緩存失效且R-CMT滿時(shí),將以LRU方式換出R-CMT的最后一個(gè)映射項(xiàng).但是,當(dāng)R-CMT中的映射項(xiàng)被寫請(qǐng)求命中時(shí),由于映射項(xiàng)將被寫請(qǐng)求修改,因此需要將該映射項(xiàng)移動(dòng)到HW-CMT中(如圖3中箭頭4所示).
3) 熱寫緩存映射表HW-CMT
HW-CMT以LRU鏈表的方式組織,鏈表中的每一個(gè)結(jié)點(diǎn)是一個(gè)映射項(xiàng),并使用flag標(biāo)記每個(gè)映射項(xiàng)的冷熱性質(zhì),任何被命中的映射項(xiàng)都會(huì)被移動(dòng)到HW-CMT的鏈表首部.同時(shí),由于本文第3節(jié)闡明的原因,HW-CMT鏈表必須保證鏈表的末尾是一個(gè)熱映射項(xiàng),否則將進(jìn)行HW-CMT“剪枝”操作(pruning),即HW-CMT末尾的冷映射項(xiàng)將被移動(dòng)到DCW-CMT中(如圖3中箭頭5所示).有2種情況會(huì)觸發(fā)HW-CMT“剪枝”操作:1)當(dāng)HW-CMT中最后一個(gè)熱映射項(xiàng)被命中時(shí),由于該映射項(xiàng)會(huì)被移動(dòng)到首部,因此此時(shí)最后一個(gè)映射項(xiàng)可能不是熱映射項(xiàng);2)當(dāng)HW-CMT中的冷映射項(xiàng)被命中時(shí),會(huì)發(fā)生冷熱映射項(xiàng)的轉(zhuǎn)換,被命中的冷映射項(xiàng)會(huì)被轉(zhuǎn)換為熱映射項(xiàng),此時(shí),尾部的最后一個(gè)熱映射項(xiàng)將被轉(zhuǎn)換成冷映射項(xiàng).
4) 冷臟寫緩存映射表DCW-CMT
DCW-CMT被分為若干個(gè)映射頁結(jié)點(diǎn)項(xiàng)(translation page node, TP-Node),每個(gè)TP-Node內(nèi)的臟映射項(xiàng)屬于同一個(gè)映射頁,從HW-CMT中淘汰的冷臟映射項(xiàng),會(huì)根據(jù)其所屬的映射頁號(hào),放在其映射頁對(duì)應(yīng)的TP-Node中.如果未找到,則會(huì)為其新建一個(gè)TP-Node.TP-Node內(nèi)的臟映射項(xiàng)按照該臟映射項(xiàng)進(jìn)入DCW-CMT的時(shí)間順序排列.全部TP-Node以大頂堆的形式組織,大頂堆按照每個(gè)TP-Node內(nèi)的臟映射項(xiàng)數(shù)量為關(guān)鍵字進(jìn)行排序,臟映射項(xiàng)數(shù)目最多的TP-Node會(huì)被放在大頂堆頂部.在需要進(jìn)行臟映射項(xiàng)寫回時(shí),將選擇頂部的TP-Node進(jìn)行批量寫回(如圖3中箭頭8所示).通過這種方法,我們可以快速找到并優(yōu)先寫回?fù)碛信K映射項(xiàng)最多的映射頁,最大化寫回閃存的映射項(xiàng)數(shù)量,從而降低臟映射項(xiàng)寫回而帶來的元數(shù)據(jù)更新代價(jià).此外,根據(jù)負(fù)載的空間局部性原理,若某個(gè)TP-Node內(nèi)冷映射項(xiàng)較多,也意味著該TP-Node映射頁所代表的邏輯地址范圍的熱度出現(xiàn)下降,優(yōu)先寫回該映射頁,符合負(fù)載的空間局部性原理的要求.被批量更新后的臟映射項(xiàng)會(huì)變成非臟映射項(xiàng)并被移動(dòng)至CCW-CMT中(如圖3中箭頭6所示).若DCW-CMT內(nèi)的映射項(xiàng)被寫請(qǐng)求命中,會(huì)被以冷映射項(xiàng)的形式移至HW-CMT首部(如圖3中箭頭7所示),以便計(jì)算其近期的重用距離,給予其變成熱映射項(xiàng)的機(jī)會(huì).
5) 冷非臟緩存映射表CCW-CMT
CCW-CMT存放的均是從DCW-CMT中被批量更新的映射項(xiàng).在寫緩存映射表滿,需要進(jìn)行換出時(shí),優(yōu)先選擇CCW-CMT中的映射項(xiàng)換出,避免頻繁的臟映射項(xiàng)換出導(dǎo)致額外映射頁操作.若CCW-CMT內(nèi)的映射項(xiàng)被寫請(qǐng)求命中,基于第3節(jié)的原因,會(huì)被以冷映射項(xiàng)的形式移至HW-CMT首部(如圖3中箭頭7所示),給予其變成熱映射項(xiàng)的機(jī)會(huì),并由于寫操作再次成為臟映射項(xiàng).
3.2 冷熱數(shù)據(jù)分離
通過寫緩存映射表冷熱分區(qū)方法可以有效區(qū)分重用距離較長的冷映射項(xiàng)和重用距離較短的熱映射項(xiàng).由于元數(shù)據(jù)映射信息的頻繁使用,意味著其所對(duì)應(yīng)的邏輯地址具有較高熱度,因此分離冷熱映射項(xiàng)對(duì)于分離寫入冷熱數(shù)據(jù)有重要意義.另一方面,重用距離較短的熱映射項(xiàng)能夠產(chǎn)生更多的無效頁,因此將重用距離相近的邏輯數(shù)據(jù)放在同一物理區(qū)域,使得同一物理塊內(nèi)的數(shù)據(jù)頁有更大概率在垃圾回收前被無效化,從而有效減少在閃存垃圾回收過程中需要進(jìn)行的有效頁遷移次數(shù).因此,對(duì)于HW-CMT內(nèi)映射項(xiàng)對(duì)應(yīng)邏輯地址的寫入操作,其數(shù)據(jù)將會(huì)被寫入到閃存的熱數(shù)據(jù)塊區(qū)中;對(duì)于CCW-CMT,DCW-CMT或R-CMT內(nèi)映射項(xiàng)對(duì)應(yīng)的邏輯地址的寫入操作,將會(huì)被寫入到閃存的冷數(shù)據(jù)塊區(qū)中;由于垃圾回收時(shí)被回收塊內(nèi)的有效頁相對(duì)于被無效頁來說是相對(duì)熱度較低的數(shù)據(jù)頁,因此被回收塊內(nèi)的有效頁也將遷移至冷數(shù)據(jù)塊區(qū).
3.3 地址轉(zhuǎn)換過程
算法1展示了IRR-FTL的地址轉(zhuǎn)換過程.輸入是請(qǐng)求的邏輯頁地址和請(qǐng)求類型,經(jīng)過地址轉(zhuǎn)換過程后,請(qǐng)求被完成并且結(jié)束地址轉(zhuǎn)換過程.
算法1. IRR-FTL算法.
/*LPN:請(qǐng)求的邏輯頁號(hào)、Request_type:請(qǐng)求的操作類型*/
輸入:LPN,Request_Type.
① if (請(qǐng)求類型是讀請(qǐng)求)
② if (LPN在R-CMT或W-CMT中命中)
③ 在緩存找到對(duì)應(yīng)物理地址并返回;
④ else if (LPN不在TPCS中)
⑤ 從閃存中將目標(biāo)映射頁裝入TPCS;
⑥ end if
⑦ if (R-CMT已滿)
/*此時(shí)目標(biāo)映射項(xiàng)在TPCS中,需要將目標(biāo)映射項(xiàng)放入R-CMT*/
⑧ 根據(jù)LRU規(guī)則淘汰R-CMT的映射項(xiàng);
⑨ end if
⑩ 從TPCS將目標(biāo)映射項(xiàng)裝入R-CMT;
/*寫請(qǐng)求的邏輯地址觸發(fā)緩存失效*/
算法2展示了當(dāng)寫緩存映射表滿時(shí),如何選擇換出的映射項(xiàng).當(dāng)寫緩存映射表滿,需要換出映射項(xiàng)時(shí)會(huì)首先檢查CCW-CMT,由于非臟映射項(xiàng)的換出不需要執(zhí)行閃存寫回操作,因此優(yōu)先換出非臟映射項(xiàng),能夠有效減少映射頁寫回操作次數(shù);如果CCW-CMT為空,則會(huì)選擇DCW-CMT頂部的結(jié)點(diǎn),對(duì)該結(jié)點(diǎn)對(duì)應(yīng)的臟映射項(xiàng)鏈表進(jìn)行批量更新,由于該結(jié)點(diǎn)內(nèi)的映射項(xiàng)最多,因此寫回更新代價(jià)相對(duì)較小.之后,將該鏈表插入CCW-CMT中,再換出最后一個(gè)映射項(xiàng).
算法2. W-CMT_swap_out算法.
/*寫緩存映射項(xiàng)換出算法*/
① if (CCW-CMT≠?)
/*優(yōu)先從CCW-CMT中換出非臟映射項(xiàng)*/
② 按照LRU規(guī)則淘汰CCW-CMT中的映射項(xiàng);
③ el se
/*若CCW-CMT≠?,則按照最大化批量更新策略,更新DCW-CMT大頂堆頂部的映射頁結(jié)點(diǎn)*/
④ 將DCW-CMT堆頂?shù)腡P_node中的映射項(xiàng)批量寫回閃存;
⑤ 更新GTD;
⑥ 將更新后的clean entries從DCW-CMT移動(dòng)到CCW-CMT;
⑦ 換出CCW-CMT中最后一個(gè)映射項(xiàng);
⑧ end if
算法3.Pruning_HW-CMT剪枝算法.
/*HW-CMT剪枝算法*/
① while(HW-CMT鏈表最后一個(gè)映射項(xiàng)不是冷映射項(xiàng)時(shí))
② 將HW-CMT鏈表尾部所有的冷映射項(xiàng)移動(dòng)到DCW-CMT;
③ end while
4 實(shí)驗(yàn)與結(jié)果
4.1 實(shí)驗(yàn)設(shè)置
本文實(shí)驗(yàn)使用被廣泛運(yùn)用在科研領(lǐng)域的開源閃存模擬器Flashsim[19],我們?cè)贔lashsim上分別實(shí)現(xiàn)了基于緩存映射項(xiàng)重用距離的閃存轉(zhuǎn)換層地址映射算法IRR-FTL和DFTL算法,并將兩者進(jìn)行比較.本文衡量系統(tǒng)有效性的主要指標(biāo)包括系統(tǒng)響應(yīng)時(shí)間、塊擦除次數(shù)、緩存命中率、映射頁的寫回次數(shù)、垃圾收集過程中拷貝的有效頁數(shù)量.
表1列出了本實(shí)驗(yàn)中對(duì)閃存模擬器Flashsim的參數(shù)設(shè)置.考慮到標(biāo)準(zhǔn)負(fù)載數(shù)據(jù)集寫入數(shù)據(jù)總量的大小,本實(shí)驗(yàn)?zāi)M的SSD大小為2 GB,著重考查IRR-FTL對(duì)閃存垃圾回收性能的提高.
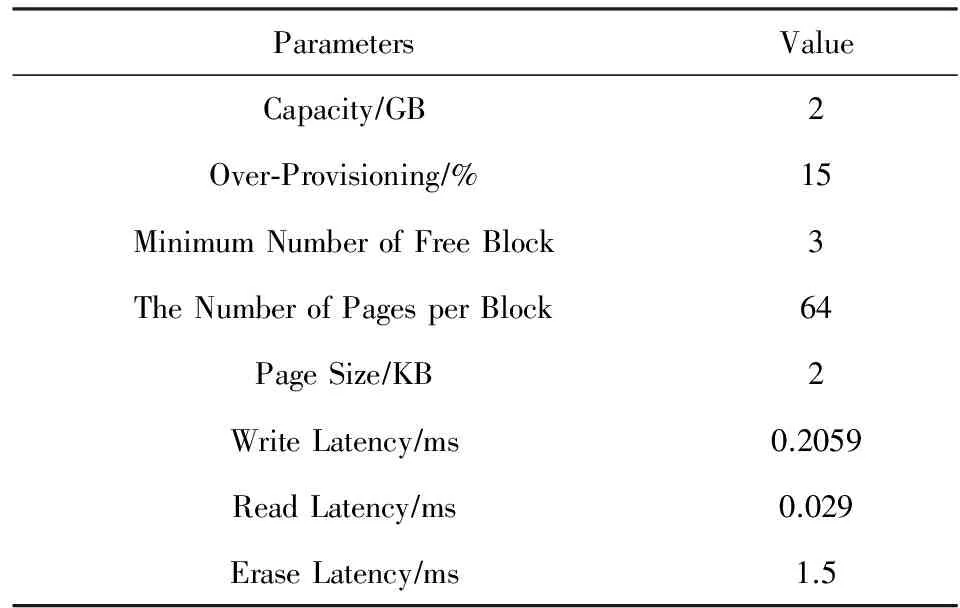
Table 1 Flash Memory Configuration表1 實(shí)驗(yàn)閃存配置參數(shù)
表2列出了各個(gè)標(biāo)準(zhǔn)負(fù)載數(shù)據(jù)集的特點(diǎn).本文分別使用多個(gè)具有不同特點(diǎn)的標(biāo)準(zhǔn)負(fù)載數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),以便能夠客觀評(píng)價(jià)本方法的有效性和普適性.
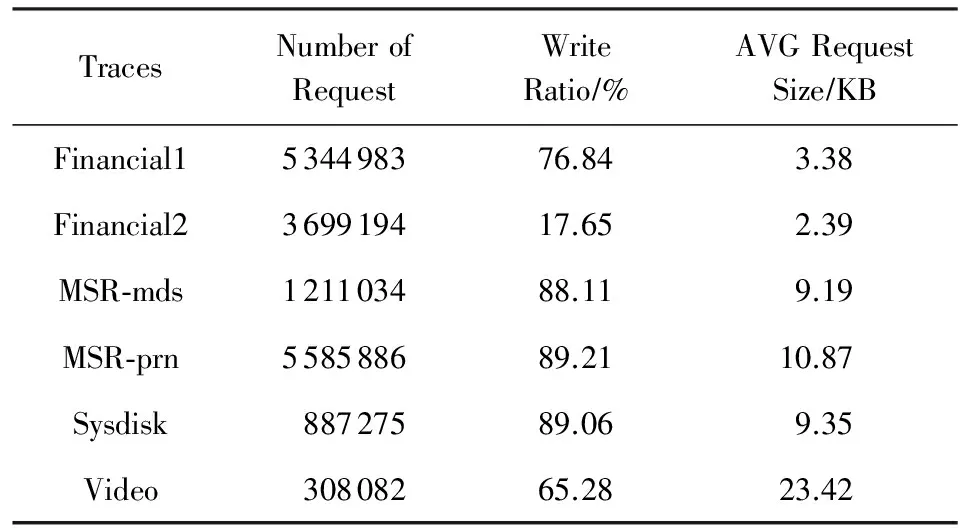
Table 2 Characteristics of Traces表2 標(biāo)準(zhǔn)數(shù)據(jù)集特征
實(shí)驗(yàn)采用的標(biāo)準(zhǔn)負(fù)載數(shù)據(jù)集包括Financial1[20],F(xiàn)inancial2[20],MSR-mds[21],MSR-prn[21],Sysdisk,Video.其中,F(xiàn)inancial1和Financial2來自于SPC的金融型OLTP應(yīng)用標(biāo)準(zhǔn)負(fù)載數(shù)據(jù)集.Financial1的特點(diǎn)是請(qǐng)求中寫操作比例較高,但是寫請(qǐng)求大小比較小;Financial2的特點(diǎn)是寫操作比例較低,請(qǐng)求的平均長度較小.MSR-mds和MSR-prn來自于微軟的企業(yè)級(jí)服務(wù)器數(shù)據(jù)集,特點(diǎn)是請(qǐng)求中寫操作比例較高,而且請(qǐng)求平均長度較大,連續(xù)寫入較多.數(shù)據(jù)集Sysdisk和Video是通過DiskMon工具,在本地計(jì)算機(jī)上收集的負(fù)載數(shù)據(jù)集.其中,Sysdisk是日常辦公的負(fù)載集,Video是網(wǎng)絡(luò)視頻負(fù)載集.
基于第3節(jié)的敘述,在本實(shí)驗(yàn)中,通過動(dòng)態(tài)調(diào)整熱數(shù)據(jù)項(xiàng)數(shù)量的方式,確保HW-CMT和冷寫緩存映射表的比例在1∶0.1到1∶0.5之間.
4.2 實(shí)驗(yàn)結(jié)果及分析
實(shí)驗(yàn)結(jié)果如圖4~8所示,下面將逐一分析各個(gè)指標(biāo)的實(shí)驗(yàn)結(jié)果.
圖4是不同負(fù)載下DFTL和IRR-FTL的緩存命中率比較.閃存緩存命中率直接影響閃存性能和壽命,若頻繁發(fā)生緩存失效,則需要進(jìn)行更多的全局映射表讀操作和緩存映射項(xiàng)換出操作,而臟映射項(xiàng)的換出,又會(huì)導(dǎo)致閃存寫回操作,對(duì)閃存性能和壽命帶來負(fù)面影響.可以看到IRR-FTL相對(duì)于DFTL在不同負(fù)載下,緩存命中率均有較大提高.特別是在負(fù)載的平均請(qǐng)求大小較大的情況下,命中率表現(xiàn)更好.緩存命中率平均提高達(dá)29.1%.緩存命中率的提高主要得益于映射頁緩存槽和基于緩存映射項(xiàng)重用距離的冷熱寫緩存映射表,有效地吸收了連續(xù)讀寫請(qǐng)求,同時(shí)優(yōu)先換出冷映射項(xiàng),延長熱映射項(xiàng)在緩存中保留的時(shí)間.
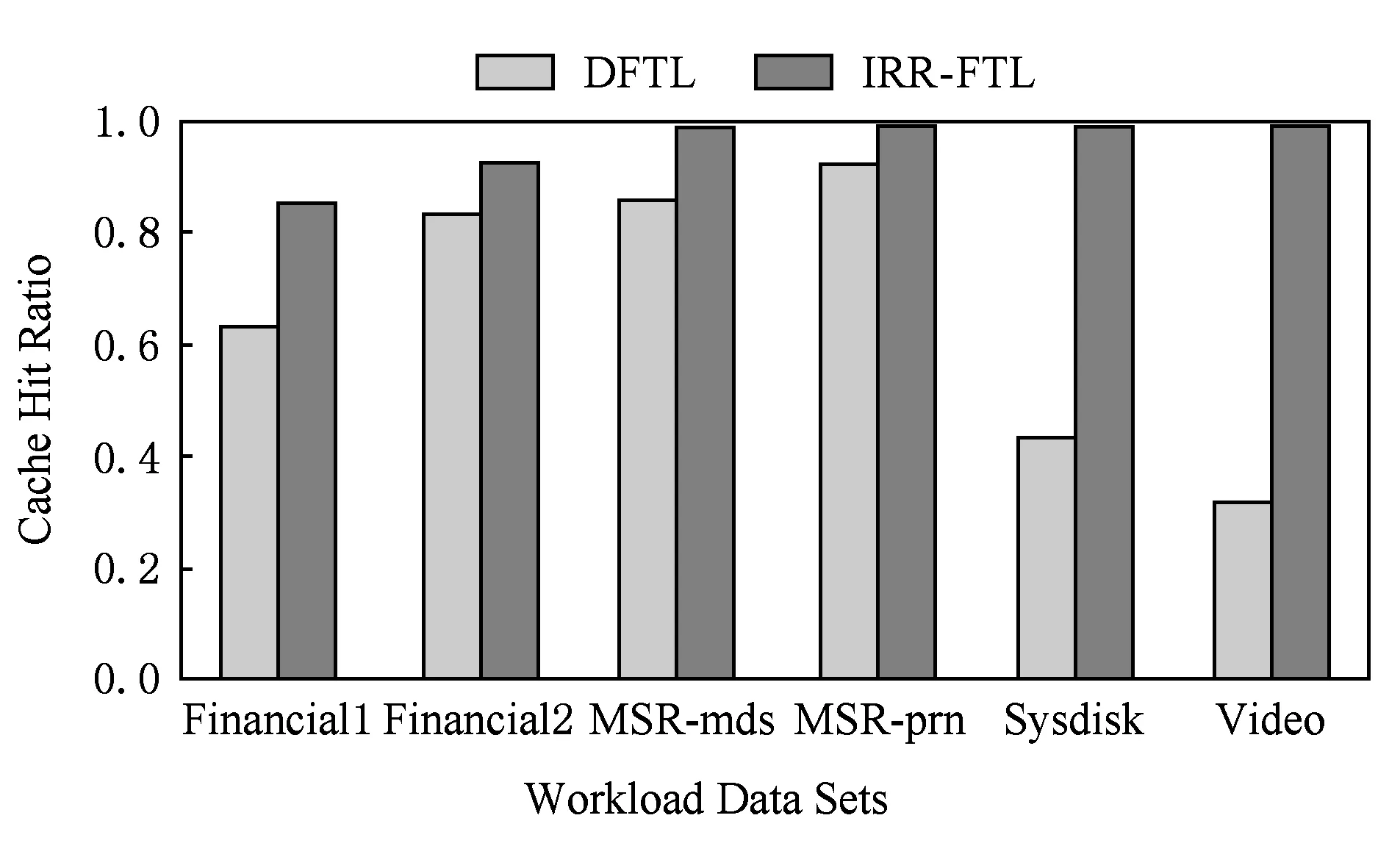
Fig. 4 Cache hit ratio under different workloads圖4 不同負(fù)載下的緩存命中率
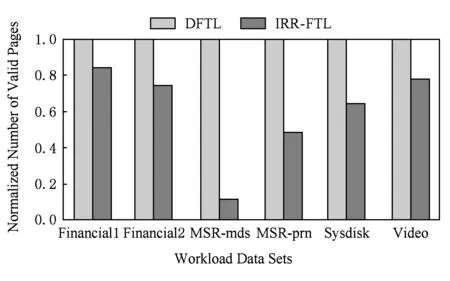
Fig. 5 Number of valid pages under different workloads圖5 不同負(fù)載下的有效頁拷貝次數(shù)
垃圾收集過程中有效頁拷貝是閃存額外讀寫的重要來源,在垃圾收集過程中被回收塊內(nèi)的每一個(gè)有效頁都會(huì)引發(fā)1次閃存讀和閃存寫操作,還會(huì)引起由于有效頁遷移而導(dǎo)致的映射關(guān)系的改變.因此,減少垃圾收集過程中有效頁拷貝次數(shù)對(duì)優(yōu)化閃存數(shù)據(jù)寫放大和元數(shù)據(jù)寫放大有重要意義.圖5是不同負(fù)載下DFTL和IRR-FTL的垃圾收集過程中有效頁拷貝次數(shù)的比較,縱坐標(biāo)表示的是歸一化的垃圾收集過程中有效頁拷貝次數(shù).可以看到,IRR-FTL有效地減少了垃圾收集過程中有效頁拷貝次數(shù),平均降低了39.9%的有效頁拷貝次數(shù).特別在MSR-mds負(fù)載上,由于MSR-mds負(fù)載的邏輯地址冷熱性質(zhì)較為清晰,因此冷熱數(shù)據(jù)分離效果更好,有效頁拷貝次數(shù)下降了88.5%.
由于臟映射項(xiàng)換出而導(dǎo)致的閃存映射頁操作是元數(shù)據(jù)寫放大的重要來源.圖6是在不同負(fù)載下DFTL和IRR-FTL由于臟映射項(xiàng)換出而導(dǎo)致的閃存映射頁寫回操作數(shù)量,縱坐標(biāo)是歸一化的閃存寫回次數(shù).可以看到,在不同負(fù)載環(huán)境下,IRR-FTL比DFTL平均減少了70.8%的額外閃存寫回次數(shù).特別在MSR-prn,Sysdisk,Video等平均請(qǐng)求較大的負(fù)載場景下,IRR-FTL減少了80%以上的映射項(xiàng)寫回操作.能夠取得上述優(yōu)良的效果,得益于冷寫緩存映射表的非臟映射項(xiàng)優(yōu)先換出策略和臟映射項(xiàng)最大化批量更新策略,實(shí)驗(yàn)證明這都能夠有效減少由于臟映射項(xiàng)換出而導(dǎo)致的閃存寫回操作,同時(shí)減少對(duì)緩存命中率的影響.
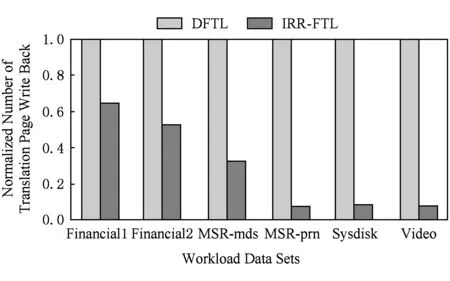
Fig. 6 Number of translation page write back圖6 不同負(fù)載下的映射頁寫回次數(shù)
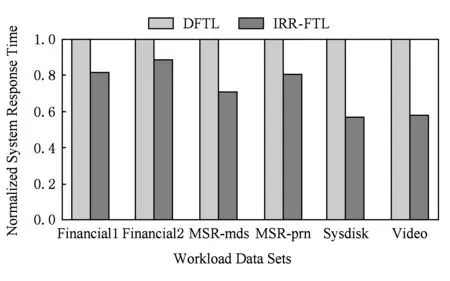
Fig. 7 Average response time under different workloads圖7 不同負(fù)載下的系統(tǒng)響應(yīng)時(shí)間
系統(tǒng)平均響應(yīng)時(shí)間是衡量閃存性能的重要指標(biāo).圖7展示了各個(gè)不同負(fù)載下IRR-FTL和DFTL的系統(tǒng)平均響應(yīng)時(shí)間的對(duì)比,其中縱坐標(biāo)表示歸一化的系統(tǒng)平均響應(yīng)時(shí)間.可以看出,得益于在緩存命中率、垃圾回收效率、元數(shù)據(jù)寫放大等指標(biāo)上的優(yōu)異表現(xiàn),IRR-FTL較DFTL系統(tǒng)平均響應(yīng)時(shí)間降低了27.3%.
塊擦除次數(shù)是衡量閃存壽命的重要指標(biāo).圖8展示了各個(gè)不同負(fù)載下,IRR-FTL和DFTL的塊擦除次數(shù)的對(duì)比,其中,縱坐標(biāo)是歸一化的塊擦除次數(shù).可以看到,由于在垃圾回收時(shí)遷移有效頁數(shù)量的減少和元數(shù)據(jù)映射項(xiàng)寫回次數(shù)的減少,從而盡可能的減少閃存中發(fā)生的不必要的數(shù)據(jù)遷移和元數(shù)據(jù)同步.相應(yīng)的在擦除次數(shù)上,IRR-FTL較DFTL平均降低了約10.7%,有效地減少了閃存內(nèi)部發(fā)生的額外寫入次數(shù),提高了閃存壽命.
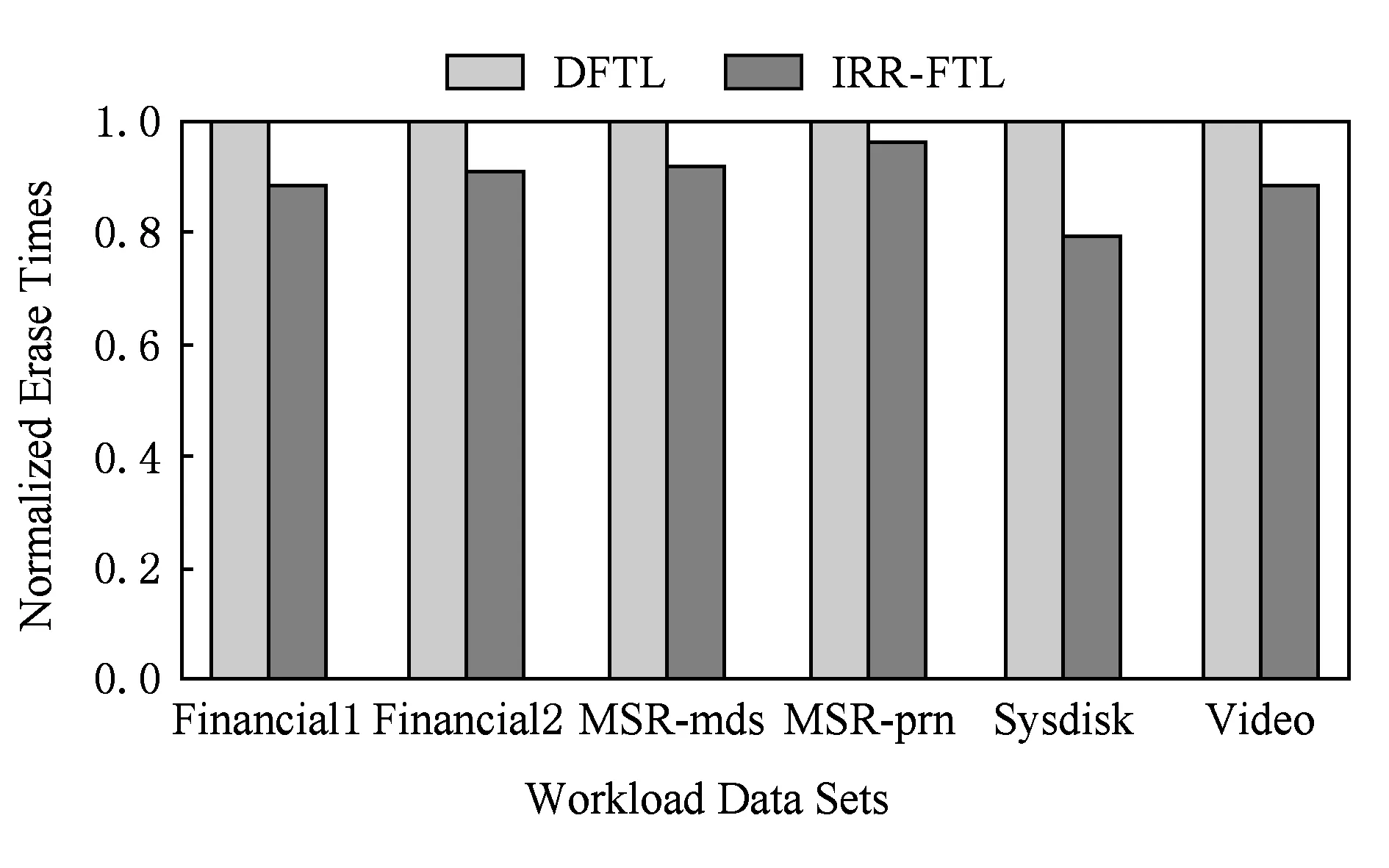
Fig. 8 Erase times under different workloads圖8 不同負(fù)載下的塊擦除次數(shù)
在IRR-FTL中,空間開銷主要來源于每一個(gè)映射項(xiàng)會(huì)增加1個(gè)冷熱標(biāo)志位,這個(gè)標(biāo)志位僅占用1 b空間.按每個(gè)映射項(xiàng)8 B計(jì)算,每個(gè)映射項(xiàng)增加1 b大小,則需要額外空間占原大小的1.5%.此外,DCW-CMT中的大頂堆中每個(gè)結(jié)點(diǎn)都有一個(gè)映射項(xiàng)數(shù)量計(jì)數(shù)器,而大頂堆中的結(jié)點(diǎn)數(shù)隨著負(fù)載的變化而動(dòng)態(tài)分配與釋放,因此占用空間大小并不確定.但是,根據(jù)負(fù)載的空間局部性原理可以推斷負(fù)載某時(shí)間段內(nèi)訪問涉及的TP-Node數(shù)量有限,同時(shí)以TP-Node映射頁為單位的批量更新策略也可以有效更新和控制DCW-CMT中的TP-Node.
5 總 結(jié)
本文提出一種基于緩存映射項(xiàng)重用距離的閃存轉(zhuǎn)換層地址映射方法IRR-FTL.針對(duì)DFTL中存在的對(duì)負(fù)載的空間局部性利用不強(qiáng)、頻繁映射頁寫回和垃圾回收導(dǎo)致的寫放大等問題,通過設(shè)置獨(dú)立映射頁緩存槽,充分挖掘負(fù)載的空間局部性.通過基于緩存映射項(xiàng)重用距離的負(fù)載自適應(yīng)寫緩存映射表冷熱分區(qū)方法,將寫緩存映射表分為熱寫緩存映射表和冷寫緩存映射表,并將不同區(qū)域內(nèi)映射項(xiàng)對(duì)應(yīng)的冷熱數(shù)據(jù)分別寫入閃存不同區(qū)域,實(shí)現(xiàn)冷熱數(shù)據(jù)分離,減少數(shù)據(jù)寫放大;同時(shí)對(duì)于冷寫緩存映射表,采取臟映射項(xiàng)最大化批量更新和非臟映射項(xiàng)優(yōu)先換出策略,減少元數(shù)據(jù)寫放大.在實(shí)驗(yàn)部分,本文通過多個(gè)不同負(fù)載類型數(shù)據(jù)集,驗(yàn)證IRR-FTL的有效性,結(jié)果證明IRR-FTL較DFTL緩存命中率提高29.1%,同時(shí)減少了39.9%的由于垃圾回收造成的額外讀寫操作和70.8%的映射頁寫回操作,使得整體系統(tǒng)響應(yīng)時(shí)間降低了27.3%,擦除次數(shù)降低了10.7%.
[1]Lu Youyou, Shu Jiwu. Survey on flash-based storage systems[J]. Journal of Computer Research and Development, 2013, 50(1): 49-59 (in Chinese)
(陸游游, 舒繼武. 閃存存儲(chǔ)系統(tǒng)綜述[J]. 計(jì)算機(jī)研究與發(fā)展, 2013, 50(1): 49-59)
[2]Chen Feng, Koufaty D A, Zhang Xiaodong. Understanding intrinsic characteristics and system implications of flash memory based solid state drives[C] //Proc of the 35th ACM SIGMETRICS Int Conf on Measurement and Modeling of Computer Systems. New York: ACM, 2009: 181-192
[3]Agrawal N, Prabhakaran V, Wobber T, et al. Design tradeoffs for SSD performance[C] //Proc of the 19th USENIX Annual Technical Conference(ATC). Berkeley, CA: USENIX Association, 2008: 57-70
[4]Ma Dongzhe, Feng Jianhua, Li Guoliang. A survey of address translation technologies for flash memories[J]. ACM Computing Surveys, 2014, 46(3): 238-276
[5]Gupta A, Kim Y, Urgaonkar B. DFTL: A flash translation layer employing demand-based selective caching of page-level address mappings[C] //Proc of the 14th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2009: 229-240
[6]Grupp L M, Davis J D, Swanson S. The bleak future of NAND flash memory[C] //Proc of the 10th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2012: 17-24
[7]Ma Dongzhe, Feng Jianhua, Li Guoliang. LazyFTL: A page-level flash translation layer optimized for nand flash memory[C] //Proc of the 30th ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2011: 1-12
[8]Zhang Qi, Wang Linzhang, Zhang Tian, et al. Optimized address translation method for flash memory[J]. Journal of Software, 2014, 25(2): 314-325 (in Chinese)
(張琦, 王林章, 張?zhí)? 等. 一種優(yōu)化的閃存地址映射方法[J]. 軟件學(xué)報(bào), 2014, 25(2): 314-325)
[9]Zhou You, Wu Fei, Huang Ping, et al. An efficient page-level FTL to optimize address translation in flash memory[C] //Proc of the 10th European Conf on Computer Systems. New York: ACM, 2015: 227-242
[10]Yao Yingbiao, Du Chenjie, Wang Fakuan. A clustered page-level flash translation layer algorithm based on classification strategy[J]. Journal of Computer Research and Development, 2017, 54(1): 142-153 (in Chinese)
(姚英彪, 杜晨杰, 王發(fā)寬. 一種基于分類策略的聚簇頁級(jí)閃存轉(zhuǎn)換層算法[J]. 計(jì)算機(jī)研究與發(fā)展, 2017, 54(1): 142-153)
[11]Kim J, Kim J M, Noh S H. A space-efficient flash translation layer for compactflash systems[J]. IEEE Trans on Consumer Electronics, 2002, 48(2): 366-375
[12]Lee S W, Park D J, Chung T S. A log buffer-based flash translation layer using fully-associative sector translation[J]. ACM Trans on Embedded Computing Systems, 2007, 6(3): 70-96
[13]Jung D, Kang J U, Jo H, et al. Superblock FTL: A superblock-based flash translation layer with a hybrid address translation scheme[J]. ACM Trans on Embedded Computing Systems, 2010, 9(4): 658-673
[14]Lee S, Shin D, Kim Y J, et al. LAST: Locality-aware sector translation for NAND flash memory-based storage systems[J]. ACM SIGOPS Operating Systems Review, 2008, 42(6): 36-42
[15]Lee H S, Yun H S, Lee D H. HFTL: Hybrid flash translation layer based on hot data identification for flash memory[J]. IEEE Trans on Consumer Electronics, 2009, 55(4): 2005-2011
[16]Park D, Du D. Hot data identification for flash-based storage systems using multiple bloom filters[C] //Proc of the 27th IEEE Symp on Mass Storage Systems and Technologies (MSST). Los Alamitos, CA: IEEE Computer Society, 2011: 1-11
[17]Xie Wei, Chen Yong, Roth P. ASA-FTL: An adaptive separation aware flash translation layer for solid state drives[J]. Parallel Computing, 2016, 61: 3-17
[18]Jiang Song, Zhang Xiaodong. LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance[C] //Proc of the 28th ACM SIGMETRICS Int Conf on Measurement and Modeling of Computer Systems. New York: ACM, 2002: 31-42
[19]Kim Y, Tauras B, Gupta A, et al. Flashsim: A simulator for NAND flash-based solid-state drives[C] //Proc of the 1st Int Conf on Advances in System Simulation. Los Alamitos, CA: IEEE Computer Society, 2009: 125-131
[20]Liberate M, Shenoy P. OLTP trace from umass trace repository[EB/OL]. [2016-12-19]. http://traces.cs.umass.edu/index.php/Storage
[21]Microsoft. MSR cambridge traces[EB/OL]. [2016-12-19]. http://iotta.snia.org/traces/388
