基于主題序列模式的旅游產品推薦引擎
2018-05-28 03:45:50朱桂祥
計算機研究與發展 2018年5期
朱桂祥 曹 杰,2
1(南京理工大學計算機科學與工程學院 南京 210094) 2 (南京財經大學江蘇省電子商務重點實驗室 南京 210003) (zgx881205@gmail.com)
近年來,推薦系統領域的研究工作發展迅猛,各種各樣的推薦系統亦隨之在電子商務、社交網站、電子旅游、互聯網廣告等大量領域得到了廣泛應用,并展示出優越的效果與前景[1-3].其中,隨著越來越多的在線旅游網站的興起(如Expedia,Travelzoo、途牛等)能刻畫用戶旅游興趣偏好的在線數據越來越豐富,使得旅游產品推薦成為推薦系統研究領域的熱門議題之一[4-6].
目前,針對傳統商品的推薦已有許多成熟的推薦算法得到廣泛應用,如協同過濾算法[7]、基于內容的推薦算法[8]和混合型推薦算法[9]等.然而大量已有研究表明[4-6,10-12]:旅游產品推薦與電影、商品等傳統推薦有顯著差異.1)用戶通常不會頻繁或大量購買旅游產品,這導致“用戶-產品”關聯矩陣極為稀疏;2)旅游產品描述信息維度多樣復雜,微小的參數變化會導致完全不同的旅游產品,如景點參觀線路和日程、酒店和交通工具選擇等因素的變化,然而這類有內在關聯的不同旅游產品卻指向用戶共同的興趣偏好;3)用戶往往不會長期關注旅游產品,即在電子旅游網站上留下訪問記錄,而往往是有了旅游目標和安排之后,才開始瀏覽旅游產品,這導致在線旅游數據中存在大量冷啟動用戶.因此,針對傳統商品的推薦算法很難直接應用到旅游推薦領域.
基于上述原因,本文首先從旅游數據的特征入手,對旅游數據的稀疏性和冷啟動問題進行了深入的分析,并從日志會話的相似性角度進行了論證,以啟發研究基于主題序列模式的旅游產品推薦引擎.具體而言,本文首先提出了面向旅游產品的推薦引擎(sequential recommendation engine for travel products, SECT),該引擎通過用戶實時點擊流可以捕捉用戶的興趣偏好,并實時產生旅游產品推薦列表.其次,本文分別從旅游頁面的主題挖掘、訪問序列的模式挖掘和模式庫的存儲、匹配計算等方面對SECT的原理進行了詳細的說明.為了提升在線匹配計算的效率,本文設計一種新的多叉樹數據結構PSC-tree用于存儲歷史模式庫,并與在線計算模塊無縫銜接.最后,本文選取了常用的基準推薦算法,在真實的旅游數據集上進行了實驗對比,并從多個評價指標上對實驗結果進行分析.實驗結果表明:SECT推薦引擎不但性能上比傳統推薦算法更有優勢,更值得注意的是SECT在對冷啟動用戶和長尾物品推薦方面也具有顯著的優勢.
1 相關工作
本節主要回顧一些與本文相關的研究工作,這些工作主要圍繞旅游推薦和基于序列模式的推薦展開.
1) 旅游推薦.從應用場景角度看,旅游推薦大致包含2類:①興趣點或路徑推薦;②旅游產品或套餐推薦.第1類應用場景吸引了大部分研究者的目光,試圖融合移動終端數據與地理信息數據為用戶推薦興趣點(points of interest, POI)[13-15]或為旅游者動態推薦旅游路徑[16-18].如文獻[15]從用戶大量的GPS軌跡數據中挖掘興趣點和旅行線路序列,通過協同過濾方法為用戶推薦景點和線路;文獻[18]從社交網絡中的旅游圖片信息抽取用戶的特征并根據旅游地標和路徑信息挖掘出頻繁模式,最終構建貝葉斯學習模型對用戶線路進行個性化推薦;面向第2類應用場景的研究則相對偏少,已有研究[4-5,12]針對旅游數據稀疏性強等特點,大多先從異構數據中提取描述旅游產品的多維度特征,如從文本中提取的隱含主題、景點與地域的關系、時間與價格的關系等,以期加強用戶和產品之間的關聯,從而設計出一些新穎的協同過濾或基于內容的推薦方法.比如Liu等人[4-5]的系列研究嘗試從STA Travel*STA Travel, URL: http://www.statravel.com/旅游套餐描述文本中挖掘潛在主題,結合季節和價格等因素提出混合協同過濾推薦方法,該類方法有效地解決了協同過濾推薦在極其稀疏的旅游數據中應用的問題.
2) 基于時間序列的推薦.本文的研究立足于第2類應用場景,試圖從用戶點擊旅游網站頁面留下的日志數據出發挖掘用戶行為模式,從而根據用戶實時點擊流推薦旅游產品.因此,與本文研究相關的另一系列研究工作是基于時間序列或軌跡數據的推薦系統.文獻[19-20]基于出租車GPS軌跡數據的挖掘推薦最近載客點及避擁堵行駛路徑;文獻[21]通過挖掘播放列表預測用戶喜歡的音樂標簽;文獻[22]則研究了時間序列數據中的事件預測問題;文獻[23]提出了一種排序學習模型,它通過融合潛在因子和行為序列的效用函數來提升購買預測的精度.由于時間序列數據的復雜性及應用問題的多樣性,基于時間序列數據的推薦問題仍然呈現出開放性[24-25];同時,從日志數據角度切入研究旅游產品推薦問題雖然已經有一定的研究成果,但是此類工作[11,26-27]的日志數據大多是基于用戶分享的地理位置標簽或者發表的游記,該類日志數據類型單一,可以用于刻化旅游產品的特征比較少,也很難精確地表征用戶的興趣偏好;如文獻[11]從游記文本中抽取地理信息并構建了一個“Location-Topic”主題模型進行景點或者旅游目的地推薦.
總的來說,以上已有的相關推薦技術在某種程度上解決了旅游推薦問題.但是這類推薦技術只適應于數據結構相對簡單的旅游數據或者依賴于地理信息數據,且很難全面地捕捉用戶的實時興趣偏好.而本文使用的數據為旅游企業真實的Web服務器日志,該日志蘊含了豐富的旅游產品相關信息和大量的用戶行為的點擊記錄,通過構建推薦引擎能夠根據用戶實時的點擊流精確地捕捉用戶即時的興趣并對站內旅游產品進行個性化推薦.
2 數據描述
2.1 數據來源與規模
本文所使用的旅游產品數據集來自于途牛旅游網*http://www.tuniu.com/,包含用戶訪問Web服務器日志和用戶訂單記錄.每條服務器日志記錄表示為一個五元組:由User_ID,Page_ID,Page_Name,Time,Session_ID字段構成.其中User_ID用于跟蹤用戶,為用戶匿名標識,由瀏覽器Cookie生成;Page_ID和Page_Name分別表示途牛頁面標識及相應代表頁面的語義文本描述;Time為用戶訪問時間;Session_ID用于標識該條記錄所屬的用戶會話.用戶訂單記錄則由User_ID,Item_ID,Time構成,其中User_ID代表下單的用戶;Item_ID為用戶購買的旅游產品標識;Time代表為用戶下單時間.
旅游產品數據集的時間跨度為2個月(即2013年7-8月).本文實驗以7月份用戶訪問日志為訓練集,用于挖掘用戶興趣偏好;8月份訂單記錄及其所屬會話為測試集,用于驗證推薦引擎的效果.我們對訓練數據做了必要的預處理,包括:1)刪除了大量重復出現的首頁;2)刪除了會員登錄后訪問留下的重定向登錄頁面.表1展示了預處理后訓練集的規模,其中#Session,#Record,#User,#Page分別表示會話、記錄、用戶和頁面的數量,#L表示會話平均長度.頁面包含產品頁面和非產品頁面,產品頁面又進一步細分為出境簽證、旅游線路及景點門票,這些產品不僅能體現出用戶的興趣偏好,同時也是推薦的目標對象.與其不同的是,非產品頁面包含分類頁面和攻略頁面2類,分類頁面是包含用戶選定的旅游目的地或旅游主題的所有產品頁面的匯總,例如西藏旅游、歐洲旅游、名山勝水、游樂園、海邊海島等;攻略頁面介紹了目的地的旅游景點、線路、美食、住宿、地圖、游記等.這2類頁面的主題有助于推薦引擎刻畫用戶的興趣偏好.表2展示了訓練集頁面的分類及規模,其中#Visa,#Route,#Ticket,#Category,#Guide分別代表出境簽證、旅游線路、景點門票、分類和攻略頁面的數量.可以看出,非產品頁面數量甚至超過了產品頁面數量,這意味著基于“用戶-項目”矩陣的傳統產品推薦方法將不能利用非產品頁面中蘊含的豐富信息.

Table 1 Statistic of the Training Set表1 訓練集日志數據特征
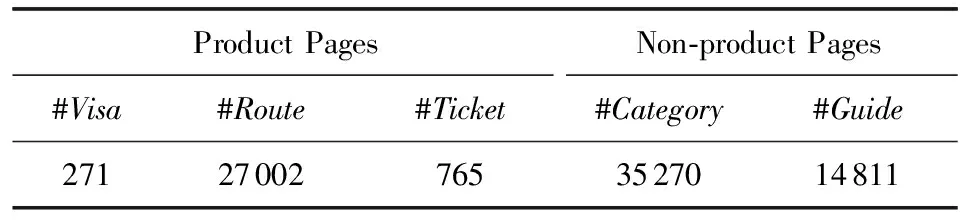
Table 2 Category and Sizes of Web Pages表2 頁面分類及規模
2.2 數據特點
本節通過分析旅游數據集的特點,以闡明提出本文方法的動機.
特點1.“用戶-項目”購買矩陣極度稀疏.
表3描述了測試集中訂單數據的基本特征,其中#Order,#User,#Item分別代表訂單、用戶、項目數量,Density代表密度.如果構建“用戶-項目”購買矩陣使用協同過濾算法[28]進行推薦,矩陣中非零值比例僅為0.0155%,而常用的MovieLens100K*http://grouplens.org/datasets/movielens/100k/“用戶-項目”評分矩陣的密度為6.3%.我們再觀察用戶購買旅游產品的次數分布,如圖1所示,有27 551(94.8%)的用戶僅購買1種旅游產品,僅有0.07%的用戶購買了5種以上的旅游產品.因此,傳統協同過濾算法難以直接運行于“用戶-項目”購買矩陣.

Table 3 Statistic of Purchase Record in Test Data表3 測試集訂單數據特征
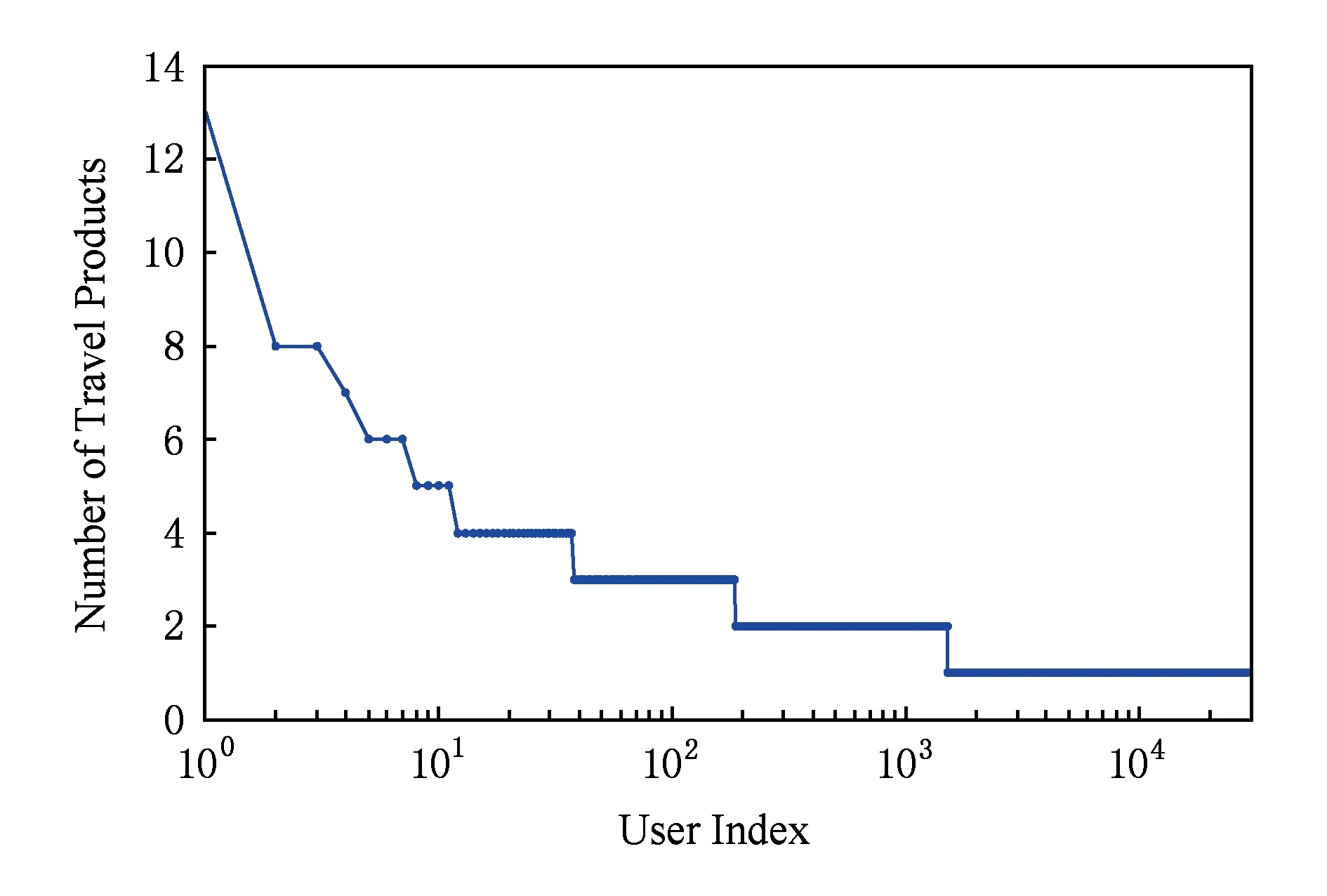
Fig. 1 The distribution of user-item purchasing matrix圖1 用戶購買旅游產品次數分布
特點2. 冷啟動用戶比例極高.
在測試集的訂單數據中,有20 990個用戶為冷啟動用戶,比例達到63.7%,即存在大量用戶在訓練數據中沒有任何訪問記錄.當然,部分冷啟動用戶可能使用不同終端訪問網站,利用Cookie標識用戶容易引起冷啟動用戶比例偏高.圖2展示了剩余的8 067個用戶在訓練集中的訪問網頁數量,可以看出,接近半數的用戶在上個月訪問網頁數量不足10個.因此,冷啟動用戶比例高是基于日志數據推薦所面臨的挑戰性問題之一,即如果構造“用戶-項目”訪問頻率矩陣同樣面臨數據稀疏性問題,傳統協同過濾算法仍然難以奏效.
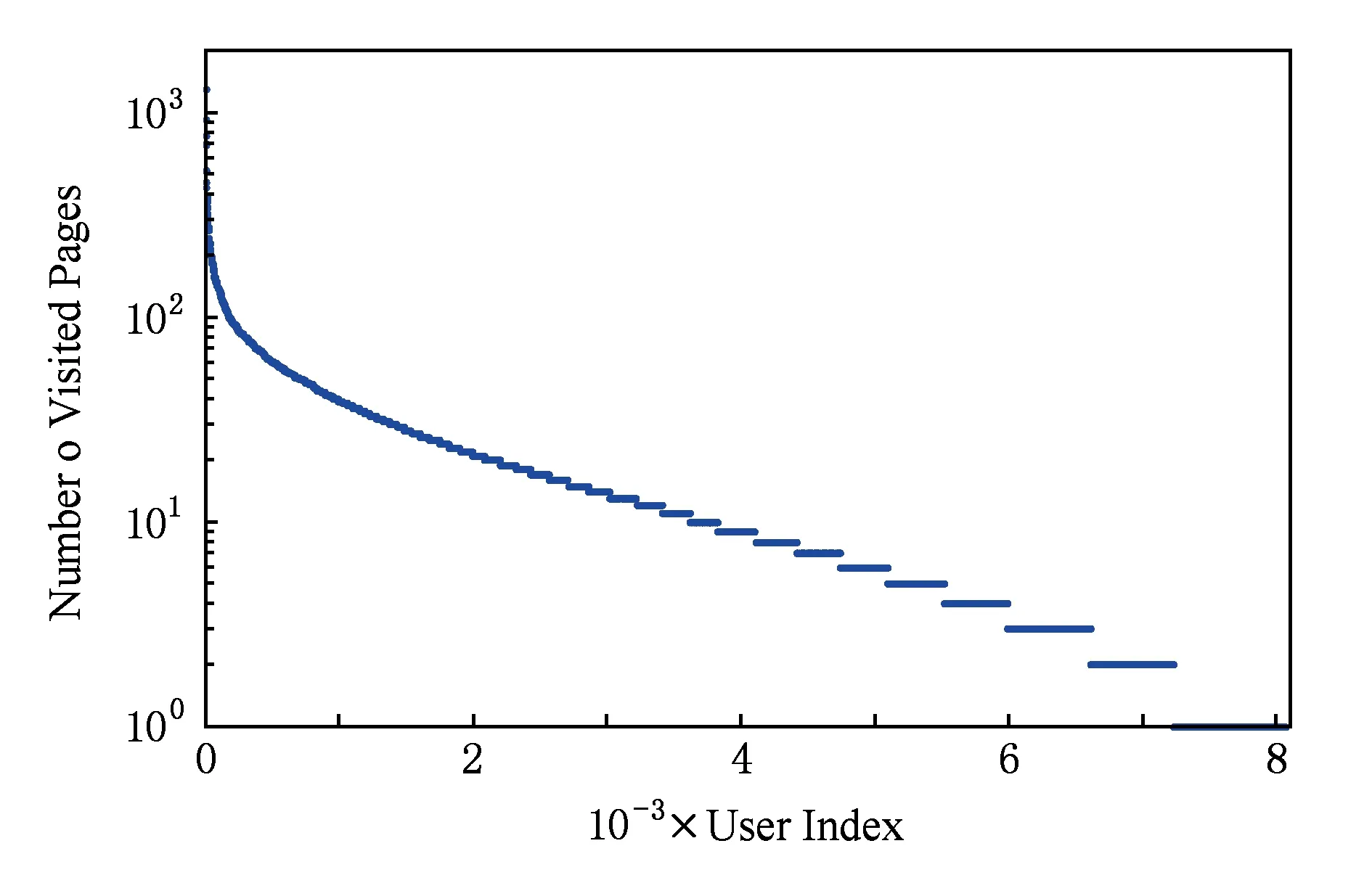
Fig. 2 The distribution of user-item visiting matrix圖2 用戶瀏覽頁面的數量分布
特點3. 購買同種產品的會話相似性高.
從測試集的訂單數據中,我們首先提取被購買超過10次的熱門旅游產品688個,再抽取不同用戶購買每個產品的訪問會話22 584條,該會話包含下訂單操作.動態時間規劃(dynamic time warping, DTW)定義了序列之間的最佳對齊匹配關系,支持不同長度時間序列的相似性度量[29],被廣泛用于衡量時間序列的相似性.我們計算購買同種產品會話的DTW距離(標記為Intra-Sessions),為便于比較,我們再計算每個會話與其他所有會話的DTW距離(標記為Inter-Sessions),圖3展示了上述2種情況的DTW距離分布.
Fig. 3 The DTW distribution among sessions purchasing the same product圖3 購買同種產品的會話DTW距離分布
從圖3可以看出,在最小DTW區間[0,3)上,Intra-Sessions比例遠遠高于基準線,而在較大的DTW距離區間上(如[6,9),[9,12),[12,15),[18,21]),Intra-Sessions比例卻低于基準線.因此,盡管用戶興趣迥異,購買同個旅游產品的訪問序列(即會話)卻有較高的相似性,這啟發著本文利用頻繁序列模式作為推薦引擎的計算依據.
3 推薦引擎總體框架
本節簡要介紹SECT推薦引擎的總體框架,如圖4所示,主要分為離線批處理和在線計算兩大模塊,其功能簡述:
1) 離線批處理.①從頁面語義文本描述中挖掘主題,將相似度高的線路產品映射到同一泛化主題,以期擴大匹配范圍,技術細節將在4.1節中介紹;②將經主題泛化后會話集合看作時間序列事務數據集,從中挖掘序列頻繁模式,形成點擊模式庫,并為每個模式尋找相關聯的候選產品,技術方案將在4.2節中闡述.
2) 在線計算.該模塊的任務主要是根據用戶最新的訪問會話,基于由離線批處理所產生的模式庫進行匹配計算和推薦分值計算,最終依據推薦分值的排序,產生一個Top-k的推薦列表,技術細節將在4.3節中予以介紹.
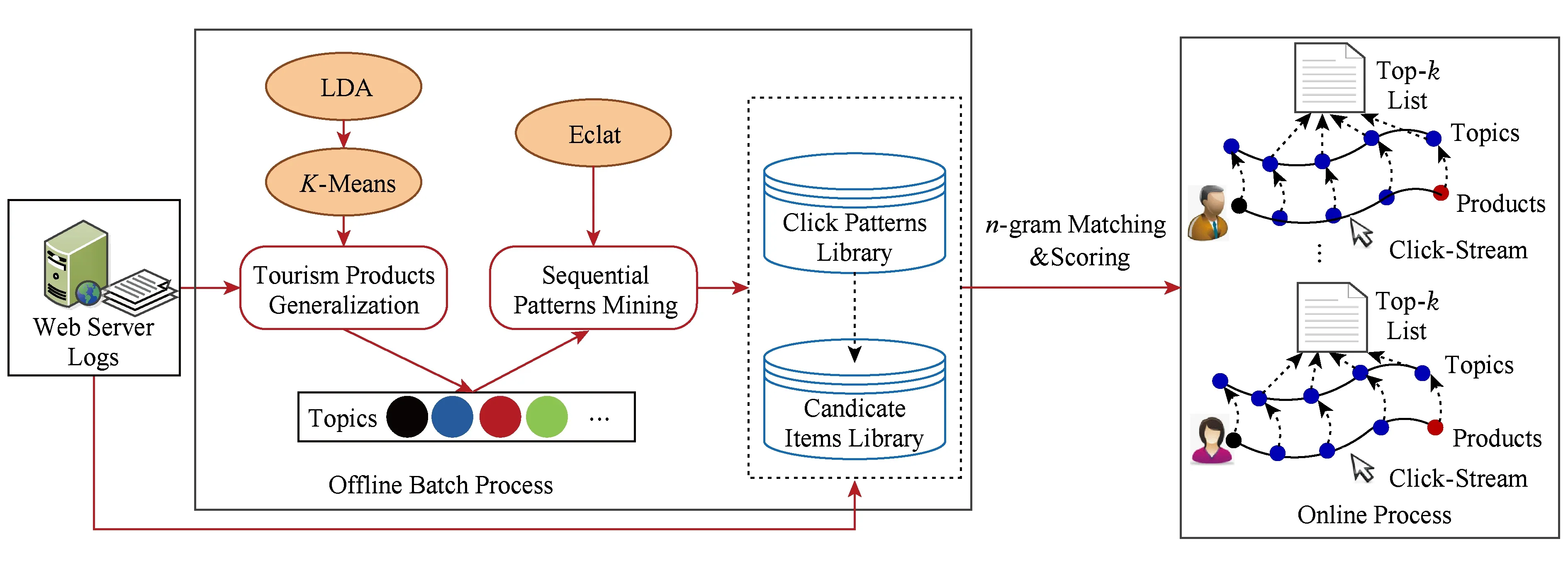
Fig. 4 The framework of SECT engine圖4 SECT推薦引擎總體框架
SECT推薦引擎具有較好的可擴展性,離線批處理在空閑時間周期性執行,承擔計算繁重的主題挖掘與序列頻繁模式挖掘任務;而在線計算模塊則負責輕量級的匹配和分值計算任務.
4 基于主題序列模式的推薦方法
4.1 頁面主題泛化
頁面主題泛化試圖將內容相似的不同頁面投影到同一個主題,進而將主題相同的訪問序列合并成一個主題序列.圖5給出了一個說明性例子,從Page_ID上看,2個用戶訪問序列差異甚大.但是,從頁面描述文本上看,2個訪問序列均反映出用戶計劃去北京旅游的興趣偏好.此外,訪問序列中的分類頁面和攻略頁面也同樣反映出用戶的興趣偏好.
旅游線路頁面的文本描述信息復雜多樣化,且具有顯著的領域特色.抽取主題本質上是文本聚類問題,通常,最樸素直觀的思路是將文本形成詞袋模型,然后通過不同的聚類算法進行文本聚類操作,從而實現主題抽取.但是這種方法對數據噪音比較敏感,在實際應用中文本聚類難以獲得良好效果,因此我們提出用主題模型(latent Dirichlet allocation, LDA)[30]模型降維并過濾噪音,再通過K-Means[31]進行文本聚類實現主題抽取.首先,對線路頁面文本信息進行分詞、去停用詞等預處理操作得到文本向量矩陣.其次,借助LDA模型對所有文本向量矩陣進行主題建模,并采用Gibbs抽樣法對建模后的文本向量矩陣進行求解,得到線路頁面的隱含主題概率分布矩陣,進而將該矩陣作為K-Means的輸入.最終聚類后的每個類簇分別代表線路頁面的不同主題.
與線路頁面不同的是簽證和門票頁面的文本描述信息為明確的結構化數據,其中簽證頁面包含簽證國家和簽證類型,門票頁面包含景點名稱和景點所在地,我們分別依據簽證國家和景點所在地對簽證和門票頁面進行主題泛化.在分類頁面和攻略頁面中,考慮到這些頁面的文本描述特點,我們直接依據旅游目的地或者旅游主題對這2類頁面進行主題泛化.
設I={i1,i2,…,iM}為訓練集中所有的頁面集合,Т={t1,t2,…,tK}為所有頁面泛化后的主題集合,頁面主題泛化可以抽象為函數:
φ(ip)→tk,
(1)
其中,1≤p≤M,1≤k≤K,M表示頁面的數量,設K為頁面泛化的主題數量,tk表示為頁面ip經泛化后的主題.
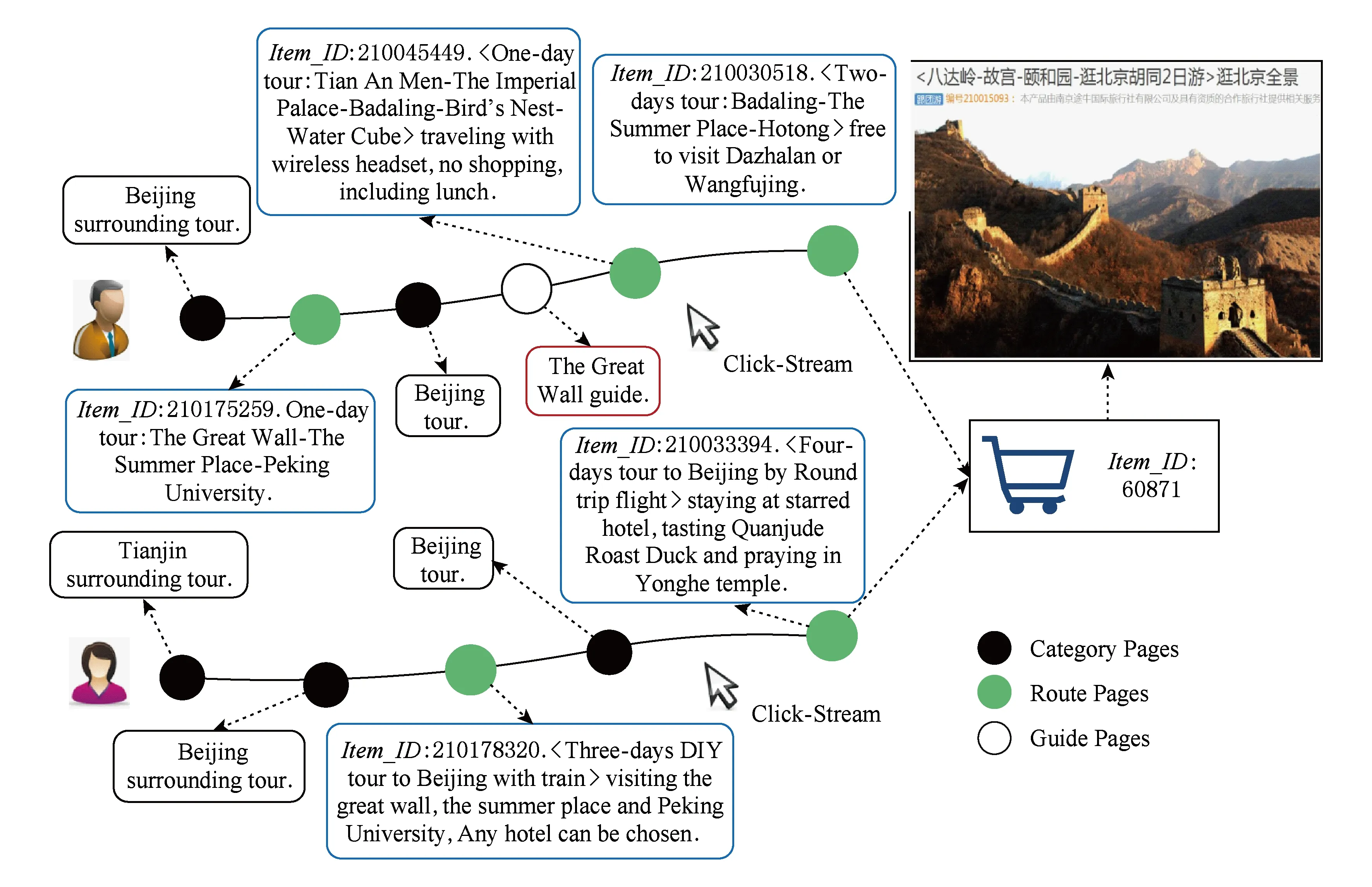
Fig. 5 An example of two different sessions which can reflect the same preferences to travel around Beijing圖5 體現出北京旅游偏好的2個不同會話的舉例
4.2 序列模式挖掘及存儲結構
由2.2節中旅游數據特點可知,購買同個旅游產品的訪問序列具有較高的相似性,而且用戶當前的興趣偏好能夠通過訪問序列的頁面主題來刻畫.因此,挖掘用戶訪問主題序列的模式對于刻畫用戶興趣偏好顯得尤為重要.每一個主題模式代表不同用戶訪問旅游頁面的興趣偏好.
定義1. 主題訪問序列事務集.主題訪問序列事務集由訓練集中所有主題訪問序列組成,記為D={D1,D2,…,DU},1≤u≤U.其中,U為用戶數量,Du表示由連續訪問頁面組成的訪問序列Xu通過式(1)泛化后得到的主題訪問序列.因此,Xu包含的項集都是I的子集,Du包含的項集都是T的子集.
定義2. 主題頻繁時序模式.令P為主題時序模式,模式P的支持度計數與支持度分別表示成σ(P)和supp(P),設min_supp為最小支持度閾值,若σ(P)≥min_supp,則稱P為主題頻繁時序模式.
本文采用Eclat (equivalence class transformation)算法[32]對主題序列模式進行挖掘.Eclat算法是采用垂直數據表示的頻繁項集挖掘方法,在序列模式挖掘中應用廣泛.將主題訪問序列事務集D作為Eclat的輸入,設置min_supp,通過運行Eclat程序得到挖掘出的主題頻繁時序模式項集,記為P={P1,P2,…,PS},其中S為模式的數量.
在基于關聯規則的推薦算法里候選項目取之于關聯規則右邊的項目[33],即候選項目被頻繁模式所包含.由于每個頻繁模式里的項目都是頻繁的,這極大地限制了候選項集的質量和多樣性.為了解決這個難題,我們抽取了每個頻繁模式在原始會話中緊跟著的旅游產品頁面作為候選項集,方法如算法1所示,其中模式Ps(1≤s≤S)對應的候選集記為CPs,每個模式對應的候選集都是I的子集.最終所有模式對應的候選集記為C={CP1,CP2,…,CPs}.
算法1. SECT產品候選集提取算法.
輸入:模式項集P、主題序列事務集合D;
輸出:產品候選集C.
① fors=1 toSdo
② for eachDu∈Ddo
③ ifPsinDuthen
④ 返回Ps在主題訪問序列Du中的末尾位置l并從訪問序列Xu中提取第l+1個訪問頁面it;
⑤ ifit為產品頁面then
⑥CPs←CPs∪{it};
⑦ end if
⑧ end if
⑨ end for
⑩C←C∪CPs;
測試集中用戶的主題序列與模式庫中模式項集的匹配對于推薦引擎的效率而言是極大的挑戰,通常一種蠻力的做法是將主題序列與模式庫中的模式一一匹配,但是考慮到模式庫中模式的數量,這種做法不但影響推薦引擎的效率,而且還增加推薦引擎的運行負擔.為了使SECT推薦引擎能夠根據用戶訪問會話快速匹配到模式庫中的主題模式,我們提出了一個多叉樹數據結構PSC-tree (pattern support candidate-tree)用于存儲歷史模式庫,并與匹配計算模塊無縫銜接.
定義3. PSC-tree.PSC-tree是一個多叉樹:
1) 包含一個名為Root的根節點,其余節點為Root節點的孩子節點;
2) 每個節點都有2個域,第1個域存儲模式的支持度計數,第2個域存儲產品候選集;
3) 從PSC-tree第2層的每個節點開始,每一個遍歷到孩子節點的路徑分別代表對應的主題序列模式.
圖6展示了PSC-tree的構造示例:1)將主題頻繁時序模式項集中的模式按照頁面標識進行排序,形成如圖6(a)中的列表;2)初始的PSC-tree只有一個根節點,按照以下方法依據圖6(a)中的模式列表依次構造孩子節點:①讀取第1個主題頻繁時序模式T1,T2,構造節點T1和T2,增加路徑Root→T1→T2,支持度計數σ(T1,T2)=20存儲在節點T2的第1個域中,推薦候選集CT1,T2={i3,i5,i6}存儲在第2個域中;②第2個模式T1,T2,T3與第1個模式具有公共的前綴T1,T2,因此,節點T3增加在路徑Root→T1→T2的終點,節點T3的2個域也存儲對應的信息;3)以上過程直到每一個模式映射到PSC-tree中的其中一條路徑為止.按照圖6(a)中的模式項集,構造PSC-tree的最終結果如圖6(b)所示.
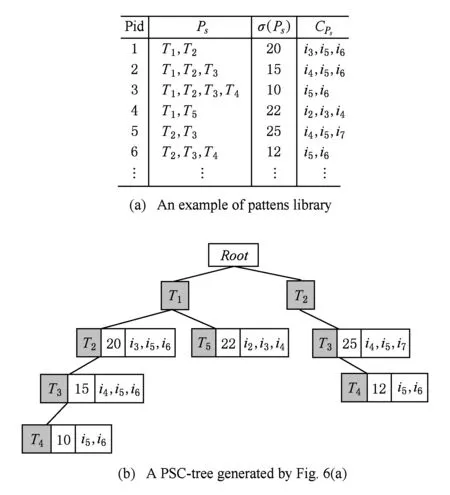
Fig. 6 An illustration of PSC-tree圖6 PSC-tree的示例說明
4.3 基于n-gram模型的推薦計算
不失一般性,設用戶u的實時頁面訪問會話為:Xu=i1,i2,…,ip,ip為最晚訪問的頁面.初始設待推薦的目標產品為it,我們將會話Xu中每個產品映射到對應的主題,即Xu=T1,T2,…,Tp,Tq=φ(iq),1≤q≤p.為了更簡明地表示,我們將T1,T2,…,Tp標記為Tp1.我們用條件概率Pr(it|Tp1)表示給定會話Xu時,用戶u對產品it的偏好程度,即:Pr(it|Tp1)越大表明用戶u購買該目標產品的概率越高.理論上,Pr(it|Tp1)由Xu的所有子序列所決定:
(2)
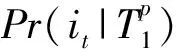
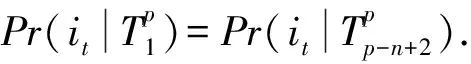
(3)
在Markovn-gram獨立性假設之下,求解式(3)可以簡化為
① http://mahout.apache.org/
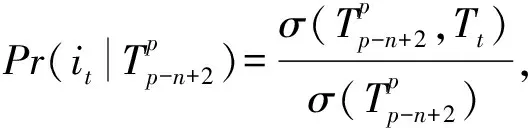
(4)
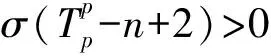
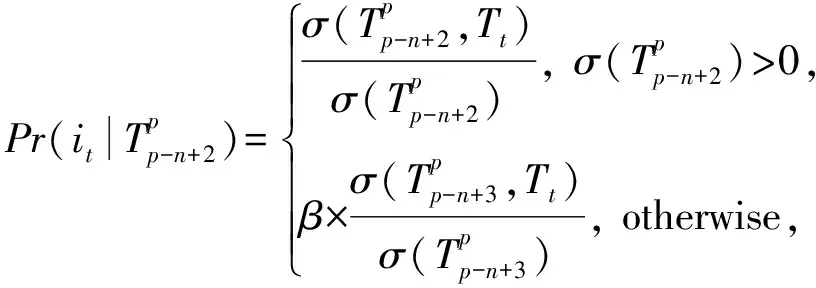
(5)
其中,β為懲罰因子,衡量的是平滑處理后的n-2項子序列和處理前n-1項序列之間的條件概率衰減,可計算為
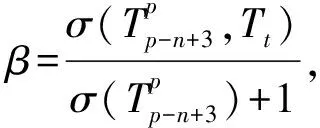
(6)
算法2展示了基于主題序列模式的推薦算法.對于給定的用戶u的實時會話Xu,首先將其映射為主題序列,我們再重復執行以上的back-off models流程直到生成一個推薦分值集合R為止.對于任意一個給定的目標產品it,其對應的分值集合記為R(it),我們將目標產品分值集合按照降序排列,最終取分值最高的k個產品作為推薦列表,記為Top-k.
算法2. 基于n-gram的推薦算法.
輸出:推薦列表Top-k.
② forj=p-n+2 topdo
③ 在PSC-tree中尋找路徑Root→Tj→…→Tp,從路徑終點Tp讀取σ(Ps)和CPs;*Ps=*
④ if (σ(Ps)>0) then
⑤ for eachit∈CPsdo
⑥Tt=φ(it),沿著路徑Root→Tj→…→
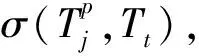
⑦R←R∪R(it);
⑧ end for
⑨ break;
⑩ end if
5 實驗結果和分析
本節展示在實際旅游數據集(如第2節所述)上的實驗結果及比較分析.
5.1 實驗設置
1) 基準推薦算法.我們選擇4種最常見的推薦算法作為比較對象:
① 基于用戶的協同過濾算法(user-based coll-aborative filtering, UCF)[38],選擇余弦為相似度度量,近鄰用戶數量設為10.
② 基于矩陣分解模型的協同過濾(singular value decomposition, SVD)[39],潛變量維度設為100.UCF和SVD均借助開源項目Mahout①實現,同時,由于2.2節的研究已經表明旅游數據中“用戶-項目”購買矩陣極度稀疏,因此我們構造“用戶-項目”訪問頻率矩陣作為協同過濾的輸入,矩陣中的元素表示用戶點擊線路頁面的次數.
③ 流行推薦算法Popular,按照購買次數直接排序,取最熱門的Top-k種產品作為推薦列表;
④ 基于關聯規則挖掘的推薦算法(max confi-dence algorithm, MCA)[33],從訓練數據中挖掘頻繁項集,以置信度作為推薦分值計算依據.SECT和MCA中的min_supp均默認設置為15,主題數量K均設為80.由于訓練集中會話平均長度為5.64,因此當測試集中會話長度大于6時,推薦算法中n取5,否則n即為會話長度.
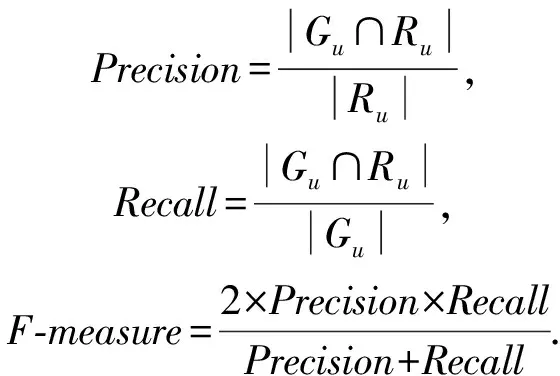
2) 評價指標.我們選擇3類指標從不同角度衡量推薦引擎的性能,其中,F-measure是體現推薦引擎準確率的綜合指標[40],Coverage是反映推薦列表多樣性的指標[41],NDCG@k(normalized discounted cumulative gain)則用于衡量推薦列表的排序優劣[42].具體地,假設為用戶u推薦生成的Top-k列表記為Ru,Ru(j)代表為用戶u產生的推薦列表在位置j上的產品,測試集中用戶u真正購買的產品列表為Gu,上述3種評價指標的計算方法如下:
①F-measure是準確率(Precision)和召回率(Recall)的調和平均值,值越高則表明推薦系統的精度越好.
(7)
②Coverage指的是推薦結果里的物品占全部物品的比例,比例越高代表推薦系統推薦的產品覆蓋范圍越廣.
(8)
③NDCG@k是一個考慮推薦項目次序的指標,該指標衡量了推薦項目的排名,值越高代表排序推薦效果越好:
(9)
NDCG@k計算的是位置j從1到k總的NDCG值;Rel是一個指示函數,計算的是推薦項目出現在位置j的增益,在本文中,如果列表中位置為j的推薦產品為用戶下單的產品,則Rel的值為1,否則為0;IDCG為規格化因子,代表最理想情況下的DCG值[43],在本文中,最理想的DCG情況為用戶實際下單產品在推薦列表中排名第一,即IDCG=1.
5.2 總體性能比較分析
圖7分別展示了SECT和另外4種基準算法在3類評價指標上的對比結果,x軸為Top-k推薦列表長度,分別設為3,5,10,20.總體上看,SECT推薦引擎在不同指標上均明顯優于其他基準推薦算法,其中Popular流行推薦效果最差,這說明用戶在購買旅游產品時具有明顯的個性化偏好,排行榜式的推薦難以取得良好效果.
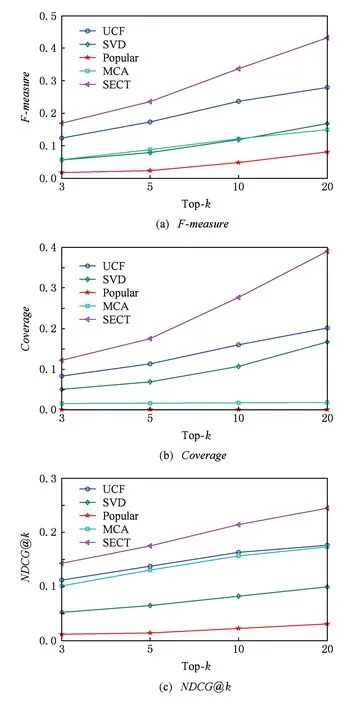
Fig. 7 Performance comparison on different evaluation metrics圖7 在不同評價指標上的比較
從圖7(a)可以看出,當k值分別取10和20時,SECT的F-measure超過30%,比排名第2的UCF算法高出至少10%.從平均意義上,SECT每推薦10種旅游產品將會帶來3次的實際購買.
從圖7(b)可以看出,SECT在Coverage指標上的性能最好,且隨著k的增大,優勢變得更加顯著,當k=20時,Coverage達到40%,這表明SECT推薦結果能覆蓋更多的產品;UCF和SVD通過“用戶-項目”訪問頻率矩陣能夠找到的相似用戶的數量比較少,因此,推薦的產品覆蓋范圍有限;Popular針對所有用戶都是推薦同樣的流行產品,因此,Coverage值最低,接近于0.
從圖7(c)可以看出,SECT的推薦列表排序效果最好,UCF其次,MCA僅次于UCF,當k值逐漸增大到20,MCA和UCF的推薦產品的排序性能接近.當k值分別取10和20時,SECT要比UCF和MCA高出至少5%,比SVD高出至少10%.這充分說明SECT推薦的正確的產品位置比較靠前,排序性能較好.
5.3 冷啟動用戶推薦效果
旅游數據冷啟動問題是影響旅游推薦的一個難題.正如2.2節中所提及,本文旅游數據集中的冷啟動用戶比例較高,測試集中冷啟動用戶數量達到20 090.因此,針對冷啟動用戶的推薦性能評估顯得尤為重要.我們選擇了5.2節中推薦效果相對不錯的UCF和SVD作為基準算法,考察針對冷啟動用戶的推薦性能.
圖8展示了SECT與基準算法在產生推薦的冷啟動用戶比例方面的對比,可以看出SECT能夠為93.1%的冷啟動用戶產生推薦列表.從平均意義來看,每10個冷啟動用戶就有9個能夠被SECT產生推薦.而SVD要比SECT要低10.9%.此外,UCF產生推薦的冷啟動用戶比例最低,僅為67.7%.
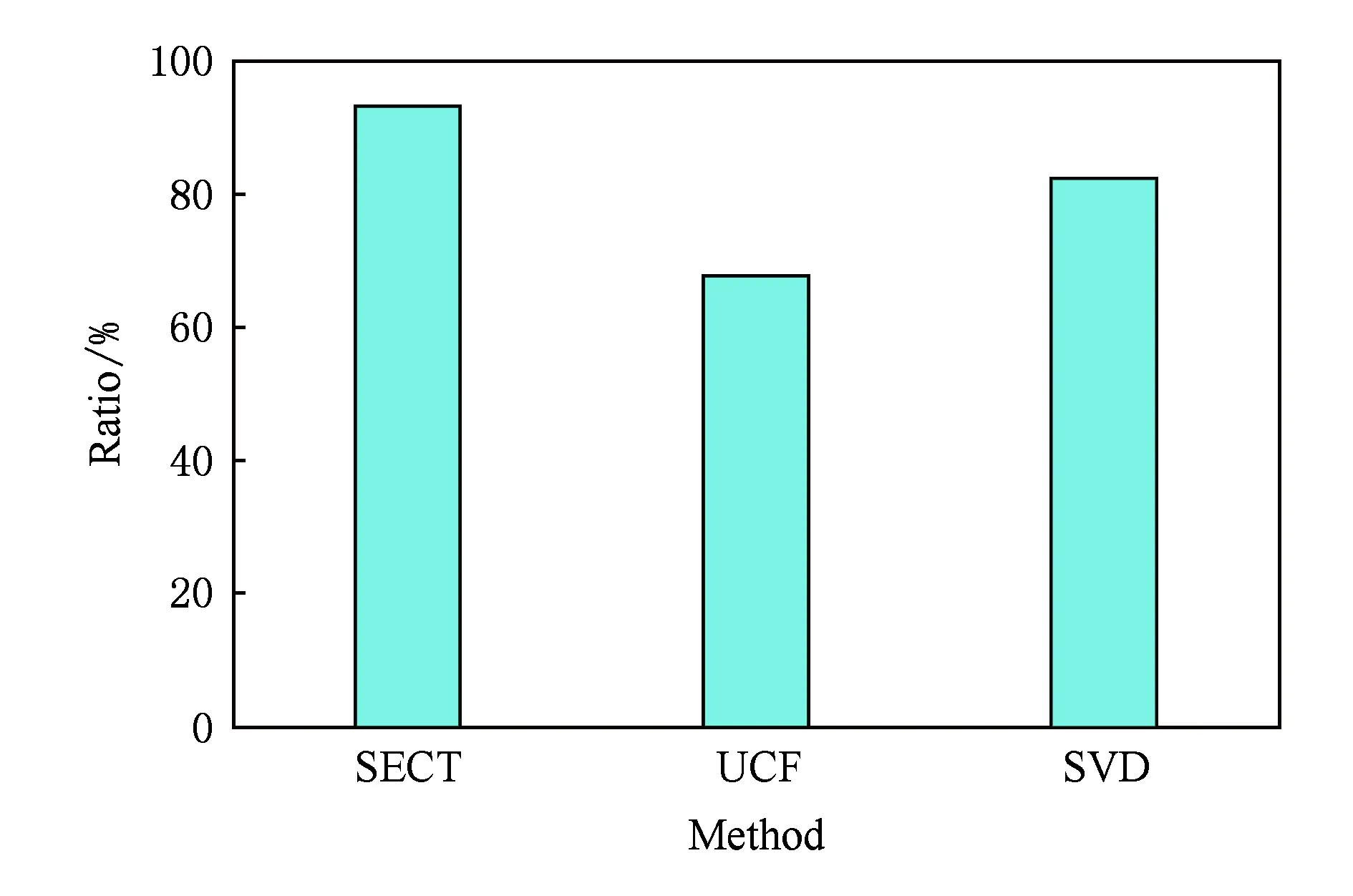
Fig. 8 Cold-start users with successful recommendations圖8 產生推薦的冷啟動用戶
圖9展示了SECT與基準算法針對冷啟動用戶推薦準確率的對比,可以看出SECT性能最出色.當k值分別取3和5時,UCF與SECT在推薦準確率方面接近,而隨著k值增加,SECT的優勢越來越顯著.當k=20時,準確推薦的冷啟動用戶占產生推薦的冷啟動用戶的比例高達44.3%,分別比UCF和SVD的勝出5%和32%.盡管UCF在產生推薦的冷啟動用戶的性能方面要差于SVD,但是在冷啟動用戶推薦準確率方面要更勝一籌.
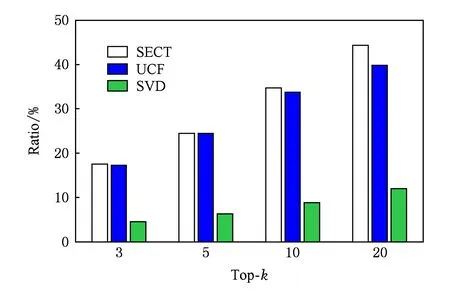
Fig. 9 Cold-start users with accurate recommendations圖9 準確推薦的冷啟動用戶
表4進一步將SECT對測試集中冷啟動用戶和全局用戶的推薦結果進行了對比,可以看出冷啟動用戶的會話并沒有降低SECT的推薦性能,與全局用戶上的推薦性能基本一致.因此,相比于協同過濾算法,SECT在解決冷啟動問題上優勢顯著.
Table4PerformanceComparisonamongCold-startUsersandGlobalUsersinTermsofF-measureResults
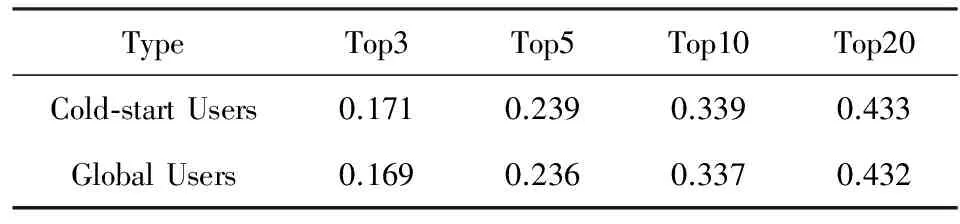
表4 冷啟動用戶和全局用戶在F-measure上的比較
從以上實驗分析可知,相比于傳統推薦算法,SECT推薦引擎不但性能具有明顯優勢,而且針對冷啟動用戶的推薦率和準確率方面也提高顯著.這是由于SECT根據用戶實時會話從主題泛化的層面捕捉用戶興趣,且不受冷啟動問題的困擾,而UCF和SVD借助的“用戶-項目”訪問頻率矩陣比較稀疏,因此,在冷啟動用戶的方面表現都不如SECT.
5.4 長尾物品的推薦
眾所周知,對于推薦系統而言推薦流行的商品較為容易也微不足道,而推薦長尾物品增加了推薦商品的新穎性,同時也是一個挑戰[44].
圖10展示了訓練集中所有產品的訪問頻率分布,可以看出長尾現象尤其顯著.具體而言,訓練集中所有產品的平均訪問頻率為17,此外,低于平均訪問頻率的產品比例高達80.7%,這意味著大多數的訪問集中于少數的流行產品.我們同樣選擇UCF和SVD作為基準算法來考察SECT挖掘長尾物品的能力.
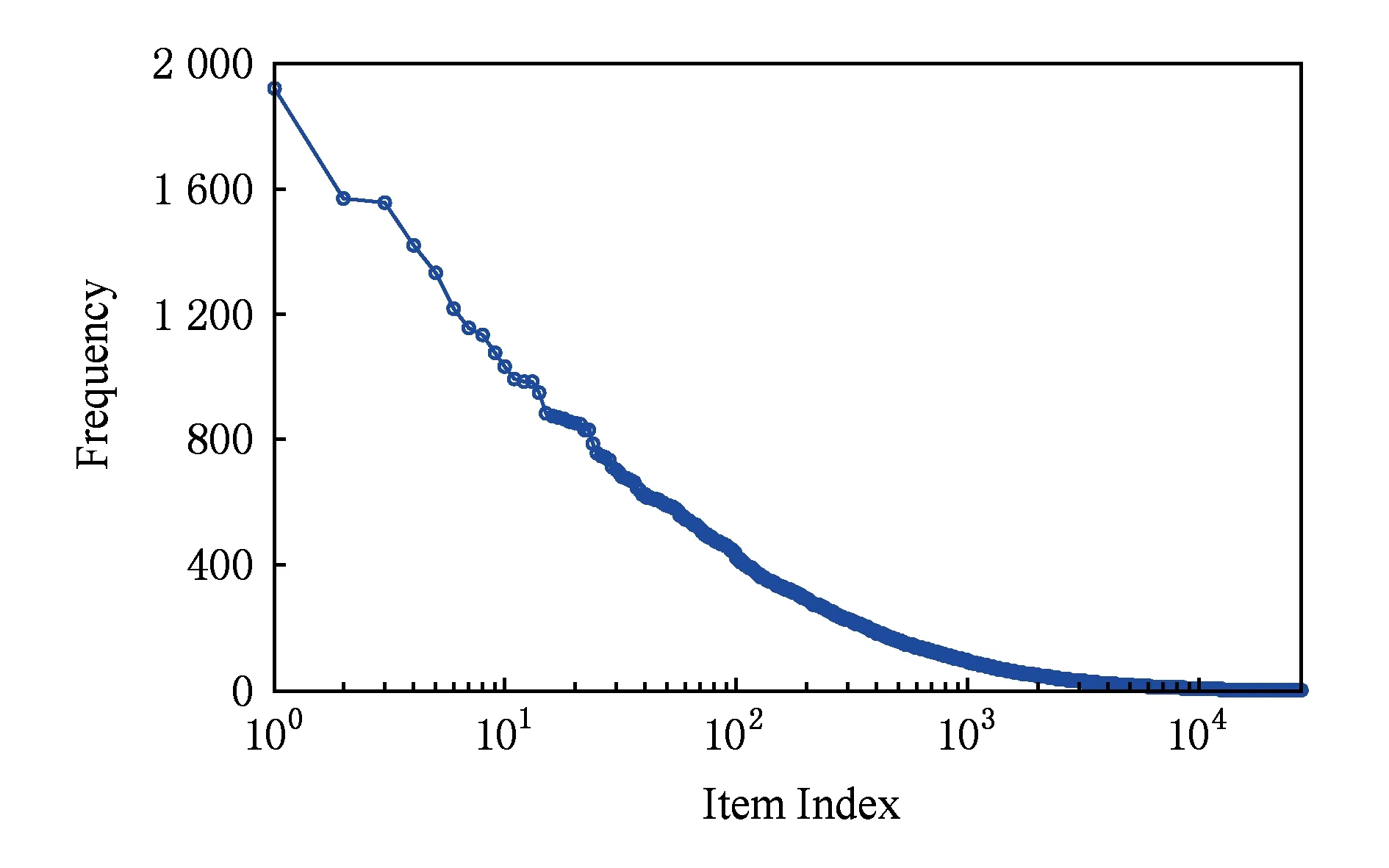
Fig. 10 Visiting distribution over items in the training set圖10 訓練集中產品的訪問頻率分布
圖11展示了3種算法在旅游數據集上推薦產品的平均流行度(即產品在訓練集中的訪問頻率).總體來看,SECT推薦的產品的流行度要低于UCF和SVD,其中UCF最高,SVD其次.當k分別取值3和5時,SECT和SVD接近,而UCF的流行度明顯偏高.相比于UCF和SVD,隨著k的不斷增大SECT推薦的產品的流行度下降趨勢更加顯著,當k=20時,SECT的流行度為221,而UCF和SVD分別高達319和278.
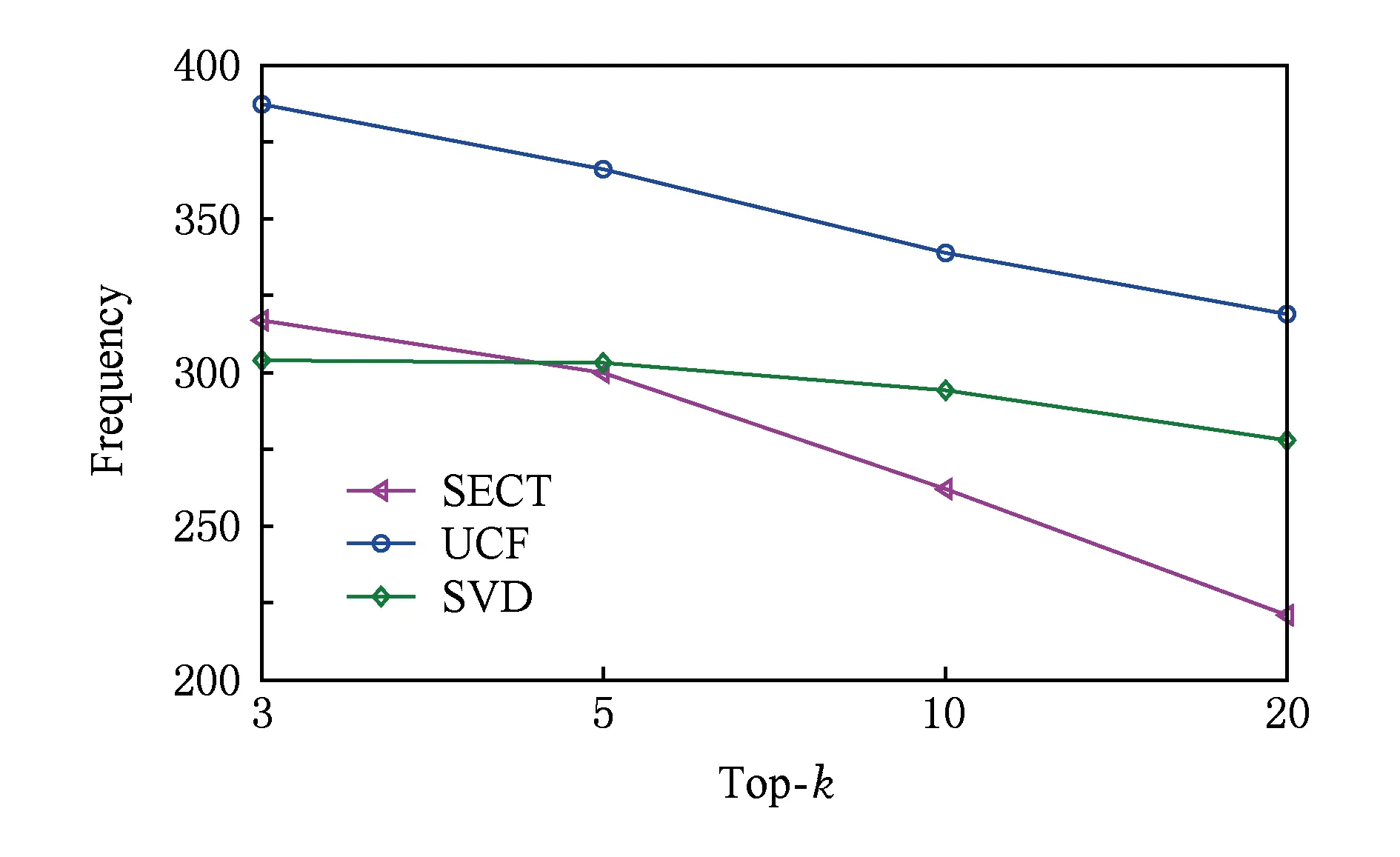
Fig. 11 Average frequency of recommended items圖11 推薦商品的平均流行度
我們將訓練集中所有物品根據訪問頻率進行倒序排序,分別將排在前60%,70%,80%,90%的產品標記為長尾物品.圖12分別展示了SECT與基準算法在Top-20推薦列表中準確推薦的長尾產品的比例.從圖12可以看出,在長尾產品閾值從0.6~0.9之間SECT性能要優于UCF和SVD,且隨著閾值增加,SECT優勢越來越顯著.當閾值設為0.9時,SECT推薦準確的長尾產品比例為22.8%,分別比UCF和SVD的性能高出9%和12%.因此,相比于傳統的協同過濾算法,SECT的推薦列表更具有新穎性,能夠準確推薦更多的長尾物品,這得益于SECT能夠從歷史會話中挖掘出很多有趣的模式.
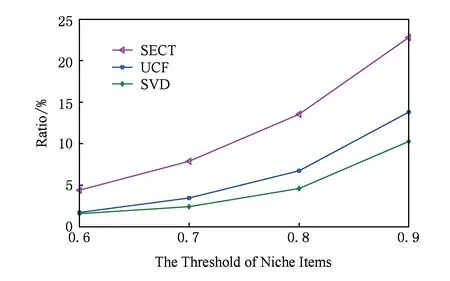
Fig. 12 Niche items with accurate recommendations圖12 準確推薦的長尾產品
6 總 結
本文研究了基于主題序列模式的旅游產品推薦問題.首先,本文提出了SECT推薦引擎,離線批處理階段,SECT利用已有的LDA和K-Means算法從頁面語義描述文本中挖掘旅游主題,并通過ECLAT算法對在線旅游網站點擊日志進行挖掘產生頻繁序列模式,最后依據本文提出的算法從模式庫和日志會話中產生候選產品集;在線計算階段,提出了基于Markovn-gram的推薦算法,依據用戶實時點擊流進行模式匹配和推薦產品的分值計算,最終產生旅游產品推薦列表.同時,設計了一種新的多叉樹數據結構PSC-tree以存儲模式庫并提升在線匹配計算的效率.為了驗證SECT的優勢,本文在真實旅游數據集上進行了實驗,實驗結果表明:SECT推薦引擎不但在性能上比傳統推薦算法更有優勢,而且能有效提升冷啟動用戶和長尾物品的推薦率和準確率.
[1]Guo Hongyi, Liu Gongshen, Su Bo, et al. Collaborative filtering recommendation algorithms combining community structure and interest clusters[J]. Journal of Computer Research and Development, 2016, 53(8): 1664-1672 (in Chinese)
(郭弘毅, 劉功申, 蘇波, 等. 融合社區結構和興趣聚類的協同過濾推薦算法[J]. 計算機研究與發展, 2016, 53(8): 1664-1672)
[2]Ge Yong, Xiong Hui, Tuzhilin A, et al. An energy-efficient mobile recommender system[C] //Proc of the 16th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2010: 899-908
[3]Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[J]. IEEE Trans on Knowledge and Data Engineering, 2005, 17(6): 734-749
[4]Liu Qi, Ge Yong, Li Zhongmou, et al. Personalized travel package recommendation[C] //Proc of the 11th Int Conf on Data Mining. Los Alamitos, CA: IEEE Computer Society, 2011: 407-416
[5]Liu Qi, Chen Enhong, Xiong Hui, et al. A cocktail approach for travel package recommendation[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(2): 278-293
[6]Ge Yong, Liu Qi, Xiong Hui, et al. Cost-aware travel tour recommendation[C] //Proc of the 17th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2011: 983-991
[7]Ge Yong, Xiong Hui, Tuzhilin A, et al. Collaborative filtering with collective training[C] //Proc of the 5th ACM Int Conf on Recommender Systems. New York: ACM, 2011: 281-284
[8]Pazzani M J, Billsus D. Content-Based Recommendation Systems[M]. Berlin: Springer, 2007: 325-341
[9]Burke R. Hybrid Web Recommender Systems[M]. Berlin: Springer, 2007: 377-408
[10]Jannach D, Zanker M, Fuchs M. Constraint-based recommendation in tourism: A multiperspective case study[J]. Information Technology & Tourism, 2009, 11(2): 139-155
[11]Hao Qiang, Cai Rui, Wang Changhu, et al. Equip tourists with knowledge mined from travelogues[C] //Proc of the 19th Int Conf on World Wide Web. New York: ACM, 2010: 401-410
[12]Tan Chang, Liu Qi, Chen Enhong, et al. Object-oriented travel package recommendation[J].ACM Trans on Intelligent Systems and Technology, 2014, 5(3): 43:1-43:26
[13]Baltrunas L, Ludwig B, Peer S, et al. Context-aware places of interest recommendations for mobile users[C] //Proc of the 14th Int Conf of Design, User Experience, and Usability. Berlin: Springer, 2011: 531-540
[14]Gavalas D, Konstantopoulos C, Mastakas K, et al. Mobile recommender systems in tourism[J]. Journal of Network and Computer Applications, 2014, 39: 319-333
[15]Zheng Yu, Xie Xing. Learning travel recommendations from user-generated GPS traces[J]. ACM Trans on Intelligent Systems and Technology, 2011, 2(1): 9:1-9:29
[16]Cao Xin, Cong Gao, Jensen C S. Mining significant semantic locations from GPS data[J]. Proceedings of the VLDB Endowment, 2010, 3(1): 1009-1020
[17]Drosatos G, Efraimidis P S, Arampatzis A, et al. Pythia: A privacy-enhanced personalized contextual suggestion system for tourism[C] //Proc of the 39th Annual Int Conf Computers, Software & Applications. Los Alamitos, CA: IEEE Computer Society, 2015: 822-827
[18]Cheng Anjung, Chen Yanying, Huang Yenta, et al. Personalized travel recommendation by mining people attributes from community-contributed photos[C] //Proc of the 19th ACM Int Conf on Multimedia. New York: ACM, 2011: 83-92
[19]Ge Yong, Liu Chuanren, Xiong Hui, et al. A taxi business intelligence system[C] //Proc of the 17th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2011: 735-738
[20]Yuan Jing, Zheng Yu, Zhang Chengyang, et al. T-drive: Driving directions based on taxi trajectories[C] //Proc of the 18th SIGSPATIAL Int Conf on Advances in Geographic Information Systems. New York: ACM, 2010: 99-108
[21]Hariri N, Mobasher B, Burke R. Context-aware music recommendation based on latenttopic sequential patterns[C] //Proc of the 6th ACM Conf on Recommender Systems. New York: ACM, 2012: 131-138
[22]Letham B, Rudin C, Madigan D. Sequential event prediction[J]. Machine Learning, 2013, 93(2): 357-380
[23]Zeng Xianyu, Liu Qi, Zhao Hongke, et at. Online consumptions prediction via modeling user behaviors and choices[J]. Journal of Computer Research and Development, 2016, 53(8): 1673-1683 (in Chinese)
(曾憲宇, 劉淇, 趙洪科, 等. 用戶在線購買預測: 一種基于用戶操作序列和選擇模型的方法[J]. 計算機研究與發展, 2016, 53(8): 1673-1683)
[24]Chen Wei, Niu Zhendong, Zhao Xiangyu, et al. A hybrid recommendation algorithm adapted in e-learning environments[J]. World Wide Web, 2014, 17(2): 271-284
[25]Wright A P, Wright A T, McCoy A B, et al. The use of sequential pattern mining to predict next prescribed medications[J]. Journal of Biomedical Informatics, 2015, 53(C): 73-80
[26]Kennedy L S, Naaman M. Generating diverse and representative image search results for landmarks[C] //Proc of the 17th Int Conf on World Wide Web. New York: ACM, 2008: 297-306
[27]Mei Qiaozhu, Liu Chao, Su Hang, et al. A probabilistic approach to spatiotemporal theme pattern mining on weblogs[C] //Proc of the 15th Int Conf on World Wide Web. New York: ACM, 2006: 533-542
[28]Schafer J B, Frankowski D, Herlocker J, et al. Collaborative Filtering Recommender Systems[M]. Berlin: Springer, 2007: 291-324
[29]Fu A W C, Keogh E, Lau L Y, et al. Scaling and time warping in time series querying[J]. The VLDB Journal, 2008, 17(4): 899-921
[30]Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993-1022
[31]Kanungo T, Mount D M, Netanyahu N S, et al. An efficientk-means clustering algorithm: Analysis and implementation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2002, 24(7): 881-892
[32]Zaki M J. Scalable algorithms for association mining[J]. IEEE Trans on Knowledge & Data Engineering, 2000, 12(3): 372-390
[33]Rudin C, Letham B, et al. Sequential event prediction with association rules[C] //Proc of the 24th Annual Conf on Learning Theory. New York: ACM, 2011: 615-63
[34]Peng Fuchun, Schuurmans D, Wang Shaojun. Augmenting naive bayes classifiers with statistical language models[J]. Information Retrieval, 2004, 7(3): 317-345
[35]Fakhraei S, Foulds J, Shashanka M, et al. Collective spammer detection in evolving multi-relational social networks[C] //Proc of the 21st ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2015: 1769-1778
[36]Ney H, Essen U, Kneser R. On structuring probabilistic dependences in stochastic language modelling[J]. Computer Speech & Language, 1994, 8(1): 1-38
[37]Chen S F, Goodman J. An empirical study of smoothing techniques for language modeling[C] //Proc of the 34th Annual Meeting on Association for Computational Linguistics. New York: ACM, 1996: 310-318
[38]Resnick P, Iacovou N, Suchak M, et al. GroupLens: An open architecture for collaborative filtering of netnews[C] //Proc of the 1994 ACM Conf on Computer Supported Cooperative Work. New York: ACM, 1994: 175-186
[39]Koren Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model[C] //Proc of the 14th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2008: 426-434
[40]Powers D M. Evaluation: From precision, recall andF-measure to ROC, informedness, markedness and correlation[J]. Journal of Machine Learning Technologies, 2011, 2(1): 37-63
[41]Ge Mouzhi, Delgado-Battenfeld C, Jannach D. Beyond accuracy: Evaluating recommender systems by coverage and serendipity[C] //Proc of the 4th ACM Conf on Recommender Systems. New York: ACM, 2010: 257-260
[42]J?rvelin K, Kek?l?inen J. IR evaluation methods for retrieving highly relevant documents[C] //Proc of the 23rd Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2000: 41-48
[43]Hu Meiqun, Lim Eepeng, Sun Aixin, et al. Measuring article quality in Wikipedia: Models and evaluation[C] //Proc of the 16th ACM Conf on Information and Knowledge Management. New York: ACM, 2007: 243-252
[44]Yin Hongzhi, Cui Bin, Li Jing, et al. Challenging the long tail recommendation[J]. Proceedings of the VLDB Endowment, 2012, 5(9): 896-907
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
數學大王·低年級(2014年7期)2014-08-11 16:36:44
海外英語(2013年8期)2013-11-22 09:16:04
電腦愛好者(2011年11期)2011-06-22 08:20:18
