TensorFlow平臺(tái)下基于深度學(xué)習(xí)的數(shù)字識(shí)別*
2018-05-23 06:17:11張永愛(ài)
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2018年4期
靳 濤,張永愛(ài)
(福州大學(xué) 物理與信息工程學(xué)院,福建 福州 350116)
0 引言
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)中的一個(gè)分支,其通過(guò)多個(gè)隱藏層對(duì)輸入數(shù)據(jù)的處理進(jìn)行特征抽象,進(jìn)而理解輸入的數(shù)據(jù)[1]。近年來(lái),深度學(xué)習(xí)非常火熱,在圖像處理、語(yǔ)音處理、文本理解等眾多領(lǐng)域的應(yīng)用越來(lái)越多,技術(shù)也越來(lái)越成熟[2-3]。2016年,谷歌AlphaGo戰(zhàn)勝了李世石引起了社會(huì)廣泛關(guān)注;科大訊飛的智能語(yǔ)音、百度識(shí)圖、谷歌的機(jī)器翻譯等技術(shù)都應(yīng)用到了現(xiàn)實(shí)生活中,給人們的生活帶來(lái)了極大的方便。
目前主流的開(kāi)源深度學(xué)習(xí)框架主要有谷歌的TensorFlow、微軟的CNTK、FaceBook的Torch、賈揚(yáng)清主導(dǎo)開(kāi)發(fā)的Caffe和蒙特利爾大學(xué)Lisa Lab團(tuán)隊(duì)開(kāi)發(fā)的Theano[4-5]。TensorFlow框架自2015年被谷歌開(kāi)源后,就受到了極大的關(guān)注,用戶(hù)數(shù)量大幅上升[6]。TensorFlow是相對(duì)高階的機(jī)器學(xué)習(xí)庫(kù),其核心代碼用C++編寫(xiě),上層接口除了C++語(yǔ)言外,還可以用Python或者Java編寫(xiě)。用戶(hù)不必親自編寫(xiě)底層核心的C++代碼就可容易地搭建神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),極大降低了深度學(xué)習(xí)的門(mén)檻。同時(shí),TensorFlow的另外一個(gè)優(yōu)點(diǎn)是它靈活的移植性,模型的訓(xùn)練和最終的部署可以運(yùn)行在有CPU或GPU的PC、服務(wù)器或者移動(dòng)設(shè)備上。隨著計(jì)算機(jī)技術(shù)的飛速發(fā)展以及計(jì)算能力的大幅提升,普通的計(jì)算機(jī)也能在TensorFlow平臺(tái)上構(gòu)建深度學(xué)習(xí)模型,降低了學(xué)習(xí)深度學(xué)習(xí)的成本,更易驗(yàn)證自己的算法。
1 深度學(xué)習(xí)
1.1 卷積神經(jīng)網(wǎng)絡(luò)原理
卷積神經(jīng)網(wǎng)絡(luò)是含有多個(gè)處理層的神經(jīng)網(wǎng)絡(luò)[7-8]。典型的卷積神經(jīng)網(wǎng)絡(luò)主要由輸入層、卷積層、下采樣層、全連接層和輸出層組成[9]。其主要包括前向傳播和反向傳播兩個(gè)過(guò)程,前向傳播通過(guò)網(wǎng)絡(luò)結(jié)構(gòu)預(yù)測(cè)結(jié)果,反向傳播根據(jù)預(yù)測(cè)結(jié)果與理想結(jié)果的差值進(jìn)行參數(shù)調(diào)整。輸入層一般為需要處理的圖像。卷積層即采用規(guī)模小的矩陣與上一層的圖像進(jìn)行卷積,矩陣相當(dāng)于特征過(guò)濾器,通過(guò)移動(dòng)小矩陣去處理圖像的每一塊,將圖像中的特征提取出來(lái),其原理如式(1)所示:
(1)
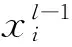
下采樣層也叫池化層,可看做特殊的卷積過(guò)程,一般有兩種形式:最大值采樣和平均值采樣。下采樣層對(duì)特征圖進(jìn)行降維,原理如式(2)所示:
(2)
卷積神經(jīng)網(wǎng)絡(luò)反向傳播常用的優(yōu)化方法是梯度下降法。殘差通過(guò)梯度下降進(jìn)行反向傳播,逐層更新卷積神經(jīng)網(wǎng)絡(luò)的各個(gè)層的參數(shù)值。
(3)
(4)
1.2 卷積神經(jīng)網(wǎng)絡(luò)模型
圖1是卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)示意圖。主要包括輸入層、兩層卷積層、兩層下采樣層、全連接層和輸出層。其中,卷積層是通過(guò)一個(gè)或多個(gè)可訓(xùn)練的卷積核對(duì)上一層的圖片進(jìn)行卷積,加上偏置的值,然后應(yīng)用激活函數(shù),得到卷積層的特征圖;下采樣層是對(duì)上一層特征圖中每個(gè)22的鄰域求最大值得到下采樣層的一個(gè)值,因此下采樣層的特征圖在各個(gè)維度都為上一層特征圖的一半;全連接層是將最后一層下采樣層的64張?zhí)卣鲌D展開(kāi)成一個(gè)向量。在全連接層和輸出層之間加入了Dropout層,可以防止模型過(guò)擬合,降低神經(jīng)元之間的依賴(lài),提高模型的泛化能力。最后通過(guò)softmax回歸模型進(jìn)行分類(lèi)輸出。
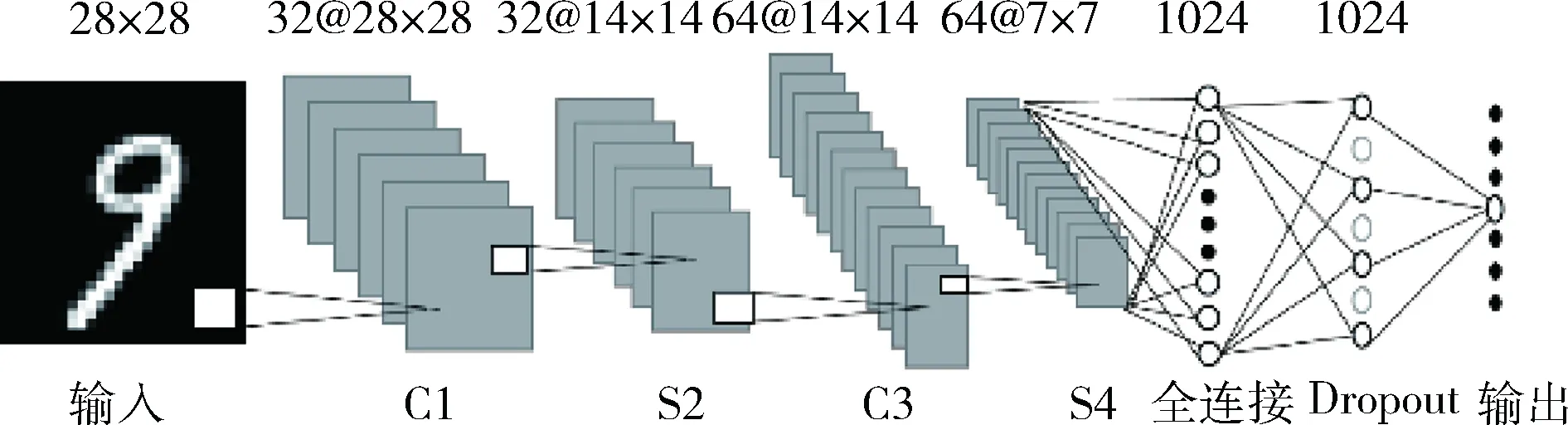
圖1 卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)示意圖
2 TensorFlow實(shí)現(xiàn)數(shù)字識(shí)別
2.1 TensorFlow 平臺(tái)
TensorFlow,也就是張量(Tensor)和流(Flow),意味著張量和流是TensorFlow的基礎(chǔ)[10]。TensorFlow中所有數(shù)據(jù)用張量數(shù)據(jù)結(jié)構(gòu)來(lái)表示,流意味著數(shù)據(jù)的流動(dòng)和計(jì)算。TensorFlow的結(jié)構(gòu)由會(huì)話(huà)(session)、圖(graph)、節(jié)點(diǎn)(operation)和邊(tensor)組成。TensorFlow程序開(kāi)發(fā)流程如圖2所示,分為構(gòu)建圖和執(zhí)行圖兩個(gè)階段。在構(gòu)建圖階段,節(jié)點(diǎn)的執(zhí)行步驟被描述成一個(gè)圖,用來(lái)表示計(jì)算任務(wù)。在執(zhí)行階段,第一步是創(chuàng)建一個(gè)會(huì)話(huà)對(duì)象,然后圖在會(huì)話(huà)的上下文中執(zhí)行,更新變量的狀態(tài),最后用feed或fetch賦值或者獲取數(shù)據(jù)。

圖2 TensorFlow程序開(kāi)發(fā)流程圖
TensorBoard是TensorFlow自帶的一款可視化工具,可顯示標(biāo)量、輸入圖像、模型結(jié)構(gòu)、訓(xùn)練過(guò)程中各層參數(shù)的變化情況,更加方便代碼的理解、調(diào)試。TensorBoard 通過(guò)讀取 TensorFlow 的事件文件來(lái)運(yùn)行。TensorFlow 的事件文件包括TensorFlow 運(yùn)行中涉及的主要數(shù)據(jù),例如可以向節(jié)點(diǎn)添加scalar_summary操作來(lái)輸出學(xué)習(xí)速度和期望誤差,可以附加 histogram_summary 運(yùn)算來(lái)收集權(quán)重變量和梯度輸出。
2.2 數(shù)據(jù)集
MNIST是一個(gè)手寫(xiě)數(shù)字?jǐn)?shù)據(jù)庫(kù),它有60 000個(gè)訓(xùn)練樣本集和10 000個(gè)測(cè)試樣本集。MNIST數(shù)據(jù)庫(kù)含有4個(gè)文件:訓(xùn)練集圖像、訓(xùn)練集標(biāo)簽、測(cè)試集圖像和測(cè)試集標(biāo)簽。每個(gè)樣本圖像都是2828像素大小,每個(gè)像素值的范圍是0~255。標(biāo)簽值為0~9十個(gè)不同的數(shù)字。圖3所示為用TensorBoard工具顯示MNIST數(shù)據(jù)庫(kù)中的手寫(xiě)數(shù)字。
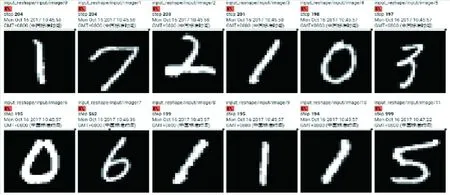
圖3 MNIST手寫(xiě)數(shù)字
2.3 代碼實(shí)現(xiàn)
圖4是通過(guò)TensorBoard可視化工具顯示的整個(gè)模型結(jié)構(gòu),包含了兩個(gè)卷積層conv1和conv2、兩個(gè)池化層pool1和pool2、一個(gè)全連接層fc1、一個(gè)輸出層fc2。在兩個(gè)輸出層之間添加了Dropout,防止數(shù)據(jù)過(guò)擬合。accuracy表示模型訓(xùn)練或測(cè)試時(shí)預(yù)測(cè)結(jié)果與標(biāo)簽吻合的準(zhǔn)確度,loss表示模型預(yù)測(cè)結(jié)果與圖像標(biāo)簽的差值。
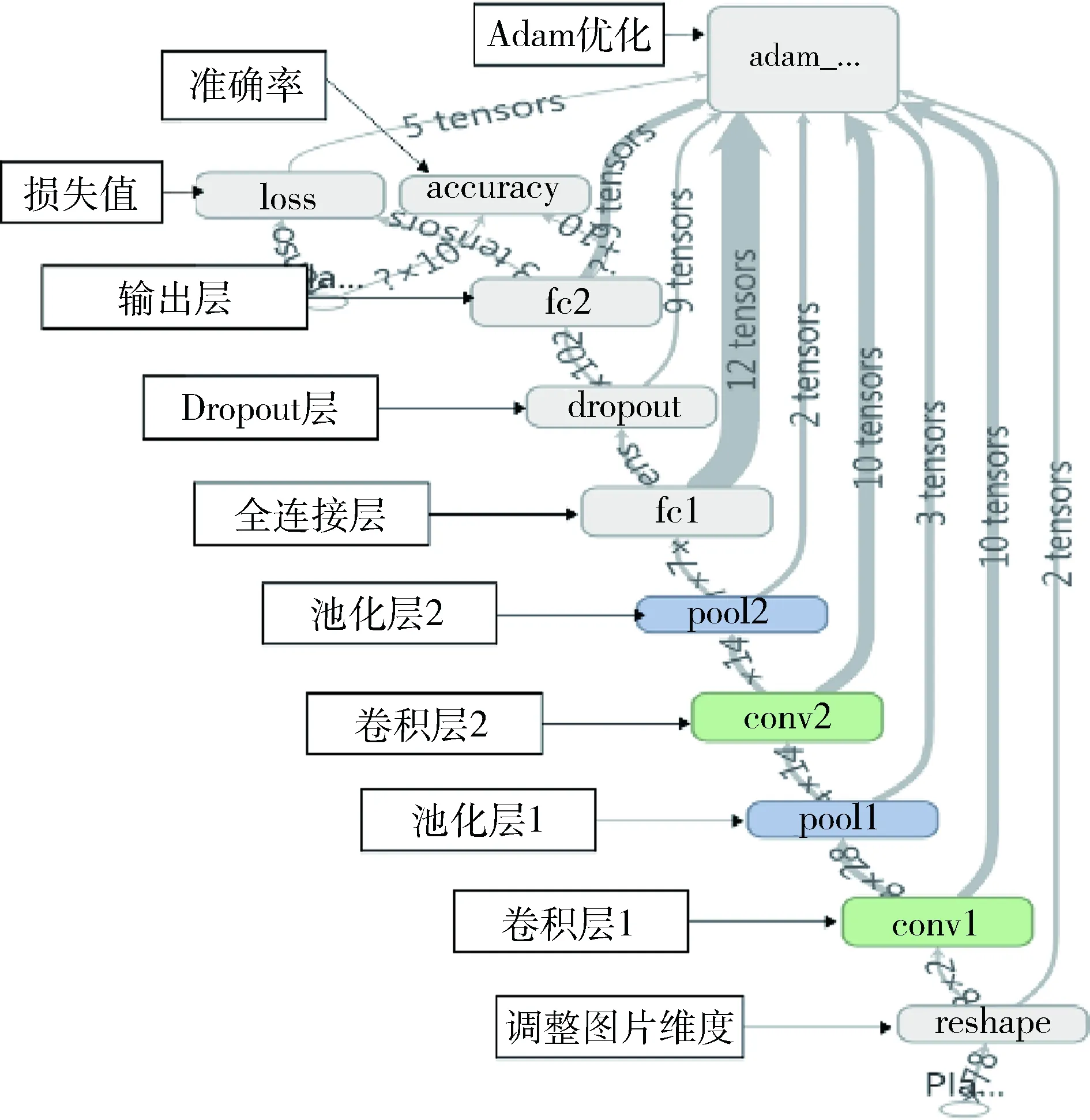
圖4 模型結(jié)構(gòu)示意圖
初始化:模型識(shí)別率高低的一個(gè)重要因素是參數(shù)值的確定,訓(xùn)練的過(guò)程就是找到最優(yōu)的參數(shù)值。卷積神經(jīng)網(wǎng)絡(luò)需要確定權(quán)重和偏置值。初始化時(shí)需要設(shè)置參數(shù)為非0值,以避免輸出恒為零值的情況。代碼中用標(biāo)準(zhǔn)差為0.1的正態(tài)分布生成隨機(jī)值賦給權(quán)重,用0.1常數(shù)初始化偏置,shape變量為維度值,在調(diào)用的時(shí)候再定義。
def weight_variable(shape):
initial=tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
reshape將調(diào)整輸入圖像的行數(shù)、列數(shù)及維度。MNIST數(shù)據(jù)集的一張圖片有28×28共784個(gè)像素,按行順序存儲(chǔ),需要將連續(xù)讀取的784個(gè)數(shù)值調(diào)整為28行乘以28列的圖片。x為輸入的數(shù)據(jù)集,將它變?yōu)閇-1,28,28,1]四維向量,第一維的-1表示圖片的數(shù)量;第二、三維的28代表圖片的寬和高;第四維表示圖片顏色的通道,由于MNIST數(shù)據(jù)集是灰度圖,因此這里是1。
x_image = tf.reshape(x, [-1,28,28,1])
conv1是模型第一層,即卷積層。將輸入圖片(x_image)和權(quán)重(W_conv1)進(jìn)行卷積,加上偏置(b_conv1)的值,最后應(yīng)用ReLU激活函數(shù)。權(quán)重的張量是[5,5,1,32],前兩個(gè)維度表示卷積核的大小;第三維是輸入的通道數(shù)目,這里輸入的是原始圖片,通道數(shù)為1;最后一維是輸出的通道數(shù)目,這里是32,即卷積后生成32張?zhí)卣鲌D。對(duì)應(yīng)的偏置數(shù)為32。
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
TensorFlow進(jìn)行卷積計(jì)算時(shí)對(duì)邊界的處理有兩種模式:SAME和VALID。SAME采用0邊距來(lái)保證輸出和輸入的圖片是同樣的大小,VALID沒(méi)有0邊距,輸出的圖片比輸入的小。strides表示卷積核移動(dòng)的步長(zhǎng),四個(gè)維度上的步長(zhǎng)都為1。輸入的圖片經(jīng)過(guò)第一層的卷積后,輸出32張28×28的特征圖。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=′SAME′)
pool1是池化層。池化一般有最大值池化和平均值池化,最大值池化是取池化窗口中的最大值,平均值池化是取池化窗口中所有數(shù)的平均值。這里采用最大值池化。x為第一層卷積層輸出的32張?zhí)卣鲌D,ksize表示池化窗口的大小為2×2,strides與卷積層一樣,表示步長(zhǎng),這里對(duì)特征圖的水平和垂直方向的移動(dòng)步長(zhǎng)設(shè)置為2。經(jīng)過(guò)池化層的處理,輸出32張14×14的特征圖。
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding=′SAME′)
conv2是第二層卷積層,在池化層的后面。與第一層卷積層類(lèi)似,卷積核的大小還是5×5,輸入的通道變成了32,輸出通道為64,相應(yīng)的偏置數(shù)變成了64。經(jīng)過(guò)這層的卷積處理,輸出64張14×14大小的特征圖。
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
pool2為池化層,對(duì)特征圖進(jìn)行采樣,降低數(shù)據(jù)量。池化窗口大小為2×2,步長(zhǎng)為2。池化處理后,輸出64張7×7大小的特征圖。
fc1是全連接層。經(jīng)過(guò)前面四層的處理,圖片尺寸已經(jīng)縮小為7×7,接著加入一層全連接層,用于處理整張圖片。全連接層將pool2層輸出的64張?zhí)卣鲌D調(diào)整為含有1 024個(gè)神經(jīng)元的行向量,然后與權(quán)重矩陣相乘,加上偏置,最后對(duì)其使用ReLU激活函數(shù)。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
為了減少過(guò)擬合,在輸出層之前加入Dropout。Dropout就是在訓(xùn)練過(guò)程中以一定的概率讓部分神經(jīng)元輸出為0,但是其當(dāng)前的權(quán)重值保持不變,下次訓(xùn)練的過(guò)程中,又恢復(fù)它的權(quán)重。keep_prob用來(lái)定義訓(xùn)練過(guò)程中神經(jīng)元的輸出為0的概率。
sep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
fc2為輸出層,采用softmax回歸模型對(duì)圖片進(jìn)行分類(lèi),它可以解決多分類(lèi)的問(wèn)題,在識(shí)別10個(gè)不同的單個(gè)數(shù)字方面具有很大用處。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
loss是模型的輸出值與圖片對(duì)應(yīng)標(biāo)簽的差值。accuracy是模型預(yù)測(cè)輸出的準(zhǔn)確度。adam_optimizer是Adam優(yōu)化算法,其為一個(gè)尋找全局最優(yōu)點(diǎn)的優(yōu)化算法,引入了二次方梯度校正。
2.4 結(jié)果分析
MNIST有60 000訓(xùn)練集和10 000測(cè)試集,隨機(jī)從訓(xùn)練集中抽取一組圖片進(jìn)行訓(xùn)練,當(dāng)訓(xùn)練到10 000次后,用測(cè)試集對(duì)模型進(jìn)行檢測(cè)。圖5展示了卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的訓(xùn)練次數(shù)與訓(xùn)練識(shí)別率之間的關(guān)系。圖5是TensorFlow自帶的可視化工具TensorBoard導(dǎo)出的,其中,橫坐標(biāo)表示訓(xùn)練的次數(shù),一共訓(xùn)練了10 000次,每訓(xùn)練100次測(cè)試一次識(shí)別率。縱坐標(biāo)顯示的是識(shí)別率的大小。從圖中可以看出,隨著訓(xùn)練次數(shù)的增加,訓(xùn)練識(shí)別率逐漸升高,最后趨于穩(wěn)定。當(dāng)訓(xùn)練到300次以后,識(shí)別率就上升到了90%;當(dāng)訓(xùn)練到6 000次后,識(shí)別率就接近100%了。圖6展示了卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的訓(xùn)練次數(shù)與損失值之間的關(guān)系,與識(shí)別率正好相反。當(dāng)訓(xùn)練的次數(shù)達(dá)到6 000次后,誤差就接近于零了。圖7是最終用測(cè)試集測(cè)試的結(jié)果示意圖,測(cè)試識(shí)別率高達(dá)99%。
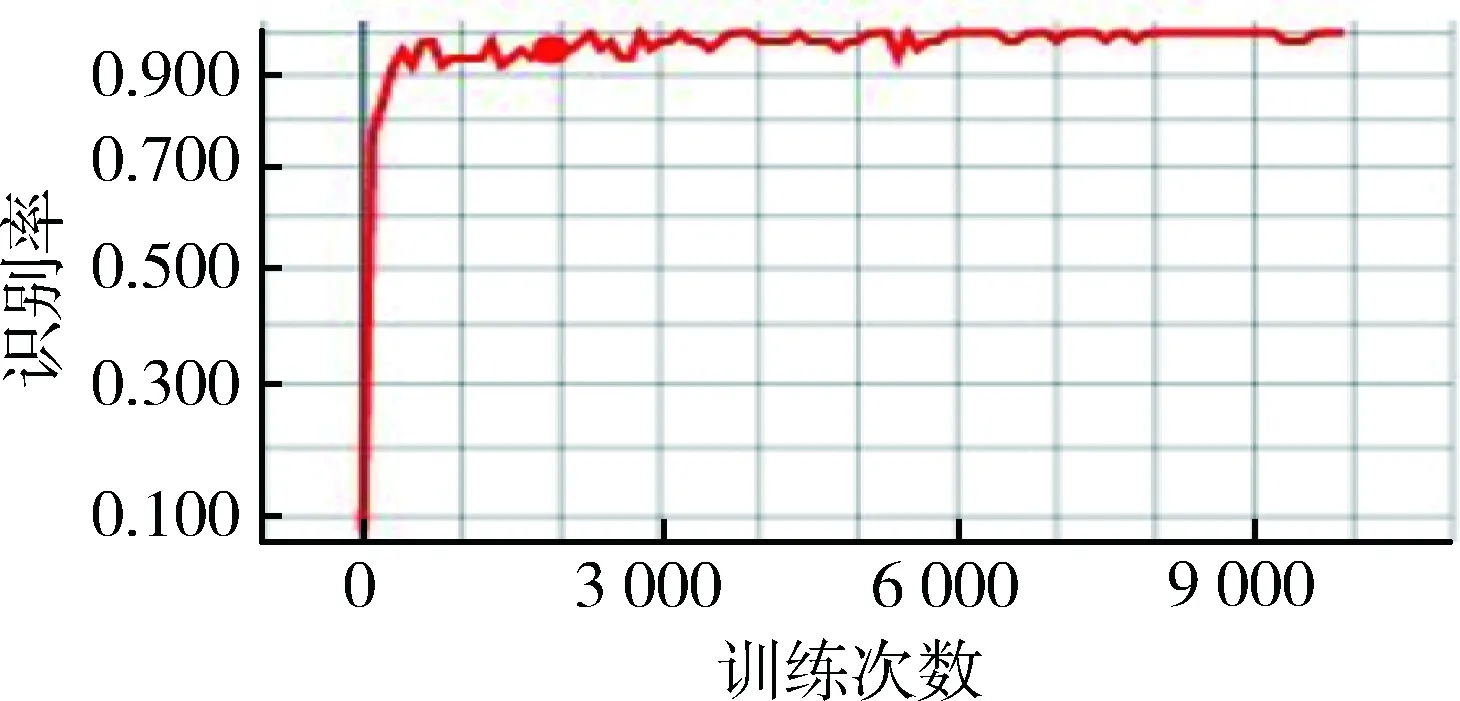
圖5 訓(xùn)練次數(shù)與識(shí)別率的關(guān)系圖
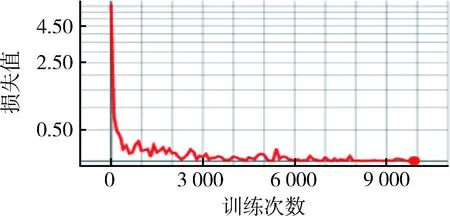
圖6 訓(xùn)練次數(shù)與損失值的關(guān)系圖
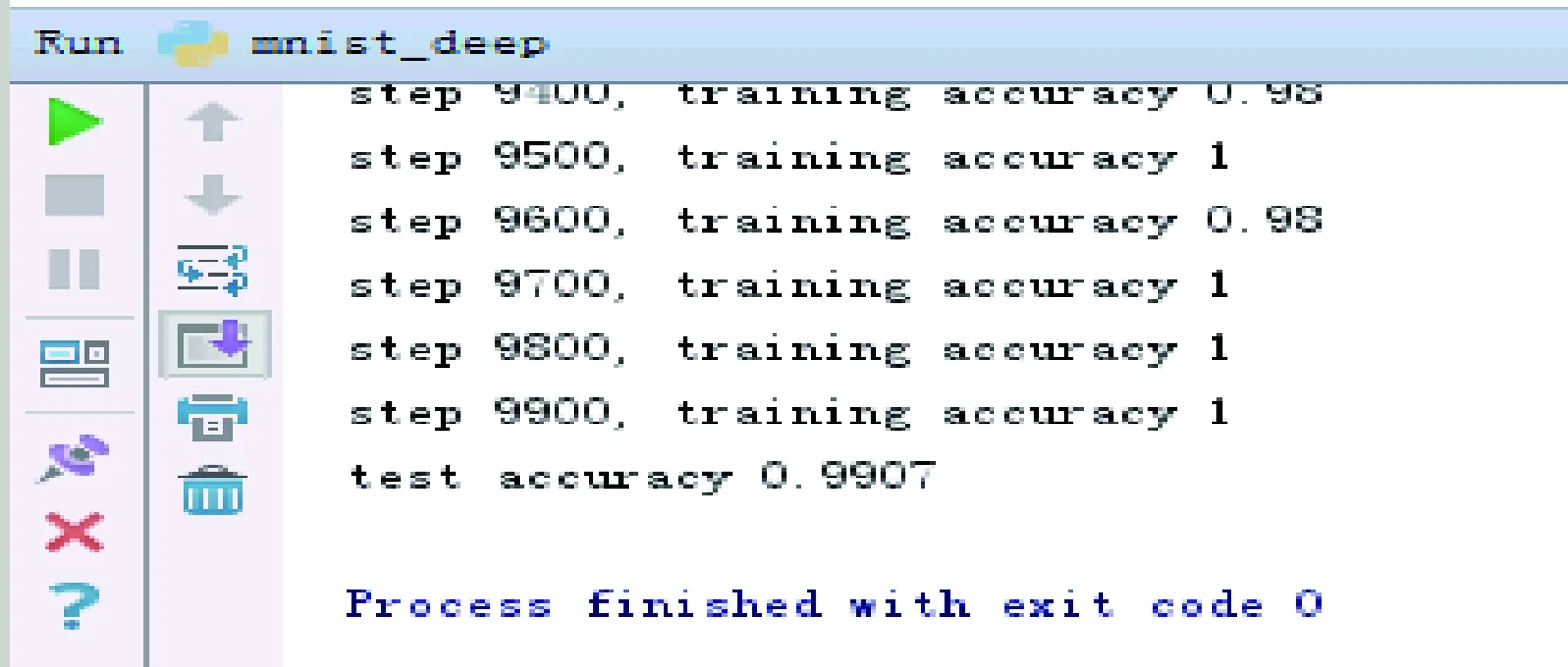
圖7 測(cè)試結(jié)果
圖8是從識(shí)別錯(cuò)誤的測(cè)試集中挑選出來(lái)的圖片。其中圖8(a)對(duì)應(yīng)標(biāo)簽為4,模型的識(shí)別結(jié)果為6,圖8(b)對(duì)應(yīng)標(biāo)簽為2,模型的識(shí)別結(jié)果為8。圖8(a)由于書(shū)寫(xiě)的不規(guī)范而具有了數(shù)字6的特征,圖8(b)具有數(shù)字8的特征,這種因書(shū)寫(xiě)不規(guī)范而具有其他數(shù)字特征的圖片的識(shí)別錯(cuò)誤率較高。除了書(shū)寫(xiě)不規(guī)范外,模型的過(guò)擬合是識(shí)別率低的重要原因。模型過(guò)擬合后,訓(xùn)練時(shí)識(shí)別率較高,但測(cè)試時(shí)識(shí)別率較低。增加訓(xùn)練的數(shù)據(jù)集,模型中加入Dropout層可以有效降低模型的過(guò)擬合程度。

圖8 識(shí)別錯(cuò)誤的圖片
3 結(jié)論
本文通過(guò)谷歌開(kāi)源的軟件庫(kù)TensorFlow快速地搭建了一個(gè)深度卷積神經(jīng)網(wǎng)絡(luò),采用MNIST數(shù)據(jù)集對(duì)模型進(jìn)行訓(xùn)練及測(cè)試,用TensorBoard可視化工具顯示測(cè)試結(jié)果及模型各層的參數(shù)值,驗(yàn)證了TensorFlow工具的簡(jiǎn)單易用性。同時(shí)在經(jīng)典卷積神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)上,增加了卷積核的數(shù)量,在第二次卷積處理后,特征圖從12張?jiān)黾拥?4張,便于提取更加豐富的特征。最終測(cè)試達(dá)到了99%的識(shí)別率。
參考文獻(xiàn)
[1] 尹寶才, 王文通, 王立春. 深度學(xué)習(xí)研究綜述[J]. 北京工業(yè)大學(xué)學(xué)報(bào), 2015, 41(1): 48-59.
[2] 余凱, 賈磊, 陳雨強(qiáng), 等. 深度學(xué)習(xí)的昨天、今天和明天[J]. 計(jì)算機(jī)研究與發(fā)展, 2013, 50(9): 1799-1804.
[3] AFFONSO C, ROSSI A L D, VIEIRA F H A, et al. Deep learning for biological image classification[J]. Expert Systems with Applications, 2017, 85: 114-122.
[4] ERICKSON B J, KORFIATIS P, AKKUS Z, et al. Toolkits and libraries for deep learning[J]. Journal of Digital Imaging, 2017, 30(4): 400-405.
[5] 王茜,張海仙. 深度學(xué)習(xí)框架Caffe在圖像分類(lèi)中的應(yīng)用[J]. 現(xiàn)代計(jì)算機(jī),2016(5):72-75,80.
[6] WONGSUPHASAWAT K, SMILKOV D, WEXLER J, et al. Visualizing dataflow graphs of deep learning models in TensorFlow[J]. IEEE Transactions on Visualization and Computer Graphics, 2017(99): 1-7.
[7] KRIZHEVSKY A,SUTSKEVER I,HINTON G. Image net classifi-cation with deep convolutional neural networks[C]. Advances in Neural Information Processing Systems(NIPS 2012), 2012: 1106-1114.
[8] 李彥冬, 郝宗波, 雷航. 卷積神經(jīng)網(wǎng)絡(luò)研究綜述[J]. 計(jì)算機(jī)應(yīng)用, 2016, 36(9): 2508-2515.
[9] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[10] 李河偉. 一種移動(dòng)式TensorFlow平臺(tái)的卷積神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)方法[J]. 電腦知識(shí)與技術(shù), 2017, 13(22): 179-182.
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
