基于備份的RAID6在線重構框架
2018-05-22 07:18:56徐偉
計算機應用與軟件 2018年5期
關鍵詞:系統(tǒng)
徐 偉
(國家安全生產監(jiān)督管理總局通信信息中心 北京 100713)
0 引 言
針對RAID在線重構研究,國內外相關研究從預測失效、spare布局、數據布局和重構策略四個方面來探索如何加速RAID在線重構。
預測失效主要使用磁盤自動檢測功能,探測出即將不能正常運行的磁盤,在失效前將其復制到spare盤上,從而減少重構時間,提高磁盤陣列可靠性。在大型peer-to-peer的存儲系統(tǒng)Oceanstore里也采取了磁盤失效預測技術[1]。但這種方式不能完全準確預測出磁盤失效。文獻[2]指出:現有技術只能預告實際磁盤故障的50%,其效果被夸大。
Spare布局分為Dedicated sparing、Parity sparing[3]和Distributed sparing[4]這三種方式。Dedicated sparing模式專門用一塊磁盤作為空閑盤,當磁盤陣列發(fā)生磁盤失效,將失效磁盤上數據完全重構到spare磁盤。Parity sparing將spare磁盤作為第二塊parity盤,減少parity組長度。當陣列中某塊磁盤失效,兩個parity組合并生成一個更大的單一陣列,該陣列只有一個parity組。Distributed sparing將spare空間分布在所有磁盤上,而不是專門用一個磁盤作為spare盤。當陣列中某塊磁盤失效,失效磁盤上數據會被重構,并分布于所有磁盤的空閑空間。但當用戶負載急劇增加時,磁盤陣列RAID5重構性能顯著降低,重構時間大幅增加。
通過優(yōu)化RAID數據布局來加速重構過程是常用的一種方法。Decluster parity[5]通過虛擬邏輯盤構成磁盤陣列,設物理磁盤個數為C,虛擬邏輯盤個數為G,將(G-1)/(C-1)定義為α,C和G確定了parity數據消耗總磁盤空間,α確定了系統(tǒng)的重構性能。當α值越小,重構所需時間則越少,parity數據所占比例越多;當α值越大,重構所需時間則越多,parity數據所占比例越小。可以調節(jié)α,從而在重構和parity數據所占比例間取得平衡。但是,當α值很小時,用于parity數據的存儲開銷將非常大,而且當用戶負載很大時,重構所需時間仍然相當大。文獻[6]提出了一種新型數據布局方式提高了鏡像磁盤陣列重構過程。文獻[7]在RAID結構里構建了一個子陣列從而顯著加速數據重構過程。文獻[8-10]對RAID6編碼布局進行研究以便改善RAID6重構性能。
重構策略[11]主要由重構對象、重構順序、重構與服務協(xié)作這三個方面組成。
重構對象主要分為面向條帶重構、并行條帶重構和面向磁盤重構。面向條帶重構是按條帶來進行重構的,并行條帶重構采取多個并行的面向條帶重構,面向磁盤重構采取與陣列中磁盤相同個數的進程,一個進程對應一個磁盤。但是,當用戶負載較大時,重構所需時間仍然相當長,且對服務性能影響顯著。
重構順序主要分為head-following、closet active stripe、multiple reconstruction points和基于局部性的多線程重構。head-following重構的主要原理:重構磁盤總是從處于低地址的尚未重構單元進行順序重構。Closest active stripe重構的主要原理:在完成用戶請求時,總是從靠近磁頭位置的尚未重構單元進行重構。Multiple reconstruction points重構的主要原理:將磁盤分為多個重構段,在完成用戶請求時,從當前最近重構點開始重構。基于局部性的多線程重構的主要原理:利用用戶負載訪問的局部性,優(yōu)先重構頻繁訪問的區(qū)域[12]。
重構與服務協(xié)作方面主要分為用戶請求操作、重構速率控制兩方面。用戶請求操作處理方式分為直讀、回寫和直寫。直讀主要原理:如果用戶對失效磁盤讀請求所涉及數據已經被重構并已經在spare盤上,則直接從spare盤上讀取該數據。回寫的主要原理:用戶對失效磁盤讀請求重構出數據,該數據不僅被發(fā)送給用戶,而且被寫到spare盤上。直寫的主要原理:用戶的寫請求直接發(fā)送到spare盤上,寫入spare盤的相應位置。基于NAND閃存的高新能和可靠的PRAID-6[13]提出一種新型的數據提交方法從而獲得與RAID6同樣的恢復能力。文獻[14]通過對磁盤陣列讀寫方式和數據塊聚合來優(yōu)化磁盤陣列讀寫性能。
重構速率控制主要在服務性能和重構速率之間尋找平衡點,從而使得服務性能處于用戶可承受范圍,盡可能提高重構速率文獻[15]。文獻[16-17]指出可以根據磁頭移動軌跡來利用空閑帶寬處理后臺應用,這也有助于提高重構性能和服務性能。其他方式還可以通過文獻[18-20]來加速磁盤陣列重構過程。文獻[18]通過將熱點數據復制到固態(tài)硬盤上來加速重構過程。文獻[19] 在分布式RAID上利用獨立GPU加速重構過程。文獻[20] 利用節(jié)點的計算編碼能力,傳輸經過編碼的數據塊來修復校驗盤,減少修復過程中的數據傳輸量,縮短校驗盤的修復時間。
針對RAID在線重構,國內外相關研究主要從預測失效、spare分布、數據分布、重構策略四個方面來提高磁盤陣列服務性能和重構性能。
在對數據存儲可靠性有高要求時,RAID6作為一種RAID技術,會被經常采用。但國內外現有研究始終無法解決重負載持續(xù)訪問情況下,RAID6的重構性能和服務性能急劇惡化這一問題。而企業(yè)存儲網絡系統(tǒng)多數由生產系統(tǒng)和備份系統(tǒng)構成。生產系統(tǒng)由于直接對外提供服務,其可靠性和可用性非常重要。隨著大容量磁盤越來越便宜,備份系統(tǒng)越來越多采用磁盤存儲備份數據。
因此,本文提出了“利用外部存放的備份數據來加速RAID6在線重構”的思想,構建了基于備份的RAID6在線重構框架,從而充分挖掘了閑置備份系統(tǒng)磁盤存儲設備的強大IO能力,顯著提高生產系統(tǒng)RAID6的在線重構速度。
1 設計思想
基于備份的RAID6在線重構框架的核心思想:當生產系統(tǒng)磁盤陣列RAID6出現磁盤失效時,可以由備份系統(tǒng)虛擬出失效磁盤處于最近備份時間點的歷史版本,通過將歷史版本恢復至spare磁盤上,從而使得spare磁盤映像為處于最近備份時間點的版本;利用生產系統(tǒng)虛擬出的當前版本將失效磁盤上自最近一次備份時間點之后已修改數據重構至spare磁盤上。此框架的主要優(yōu)點為:利用備份系統(tǒng)所提供的穩(wěn)定恢復帶寬,顯著降低了應用負載對重構過程的影響,同時,顯著減少了磁盤陣列RAID6參入重構,使得磁盤陣列RAID6優(yōu)先滿足用戶服務。
重構過程分為兩階段:版本恢復階段和版本修復階段。
當生產系統(tǒng)RAID6出現兩塊磁盤(disk2和disk3)失效時,激活兩塊spare磁盤,如圖1(a)所示。首先,重構過程進入版本恢復階段,把兩塊spare硬盤從生產系統(tǒng)中換出,完全由備份系統(tǒng)將失效磁盤(disk2)處于最近備份時間點的歷史版本恢復至spare磁盤(disk2),從而將spare磁盤(disk2)恢復成失效磁盤(disk2)處于最近備份時間點的版本。另一塊失效磁盤(disk3)版本恢復與上述類似,如圖1(b)所示。然后重構過程進入版本修復階段,將spare磁盤(disk2)重新加入到生產系統(tǒng)磁盤陣列中,利用虛擬當前版本將spare磁盤(disk2)修復為當前版本(disk2),從而完成失效磁盤自最近一次備份時間點之后已修改數據的重構。隨著spare磁盤(disk3)版本修復與上述類似,如圖1(c)所示。通過版本恢復階段和版本修復階段,完成兩塊spare磁盤的數據重構,從而將生產系統(tǒng)恢復到正常運行狀態(tài),如圖1(d)所示。

圖1 損壞兩個硬盤的情況下,此框架的重構過程
當生產系統(tǒng)RAID6出現一塊磁盤失效時,只有一塊spare磁盤參與重構過程,重構過程與上述類似,不再贅述。
2 設計實現
基于備份的RAID6在線重構框架的原型系統(tǒng)主要由面向數據的磁盤陣列架構、映射管理、恢復管理和重構管理四部分構成。通過這四部分協(xié)作,完成磁盤陣列RAID6在線重構過程。
2.1 面向數據的磁盤陣列架構
通過對傳統(tǒng)磁盤陣列進行簡單改進,我們實現了面向數據的磁盤陣列架構。面向數據的磁盤陣列架構與傳統(tǒng)磁盤陣列架構根本差異就是面向數據的磁盤陣列中未被使用邏輯塊上數據一定為零。我們使用一個全局位圖記錄磁盤陣列中所有邏輯塊的使用情況,bit位為0即標識該邏輯塊未被使用(其上數據為零),不需要對該邏輯塊進行寫零操作,并通過在傳統(tǒng)磁盤陣列轉發(fā)讀寫請求路徑上添加訪問位圖接口,從而實現了面向數據的磁盤陣列架構。面向數據磁盤陣列必須按照條帶分配和釋放邏輯單元,以避免引起附加的讀寫操作。
2.2 映射管理
映射管理主要負責以下三類映射關系的建立和維護:(1) 邏輯卷邏輯塊與最新備份數據塊的映射關系;(2) 失效磁盤邏輯塊與最新備份數據塊的映射關系;(3) 失效磁盤上自最近備份時間點之后修改數據塊的位置標識。見圖2。
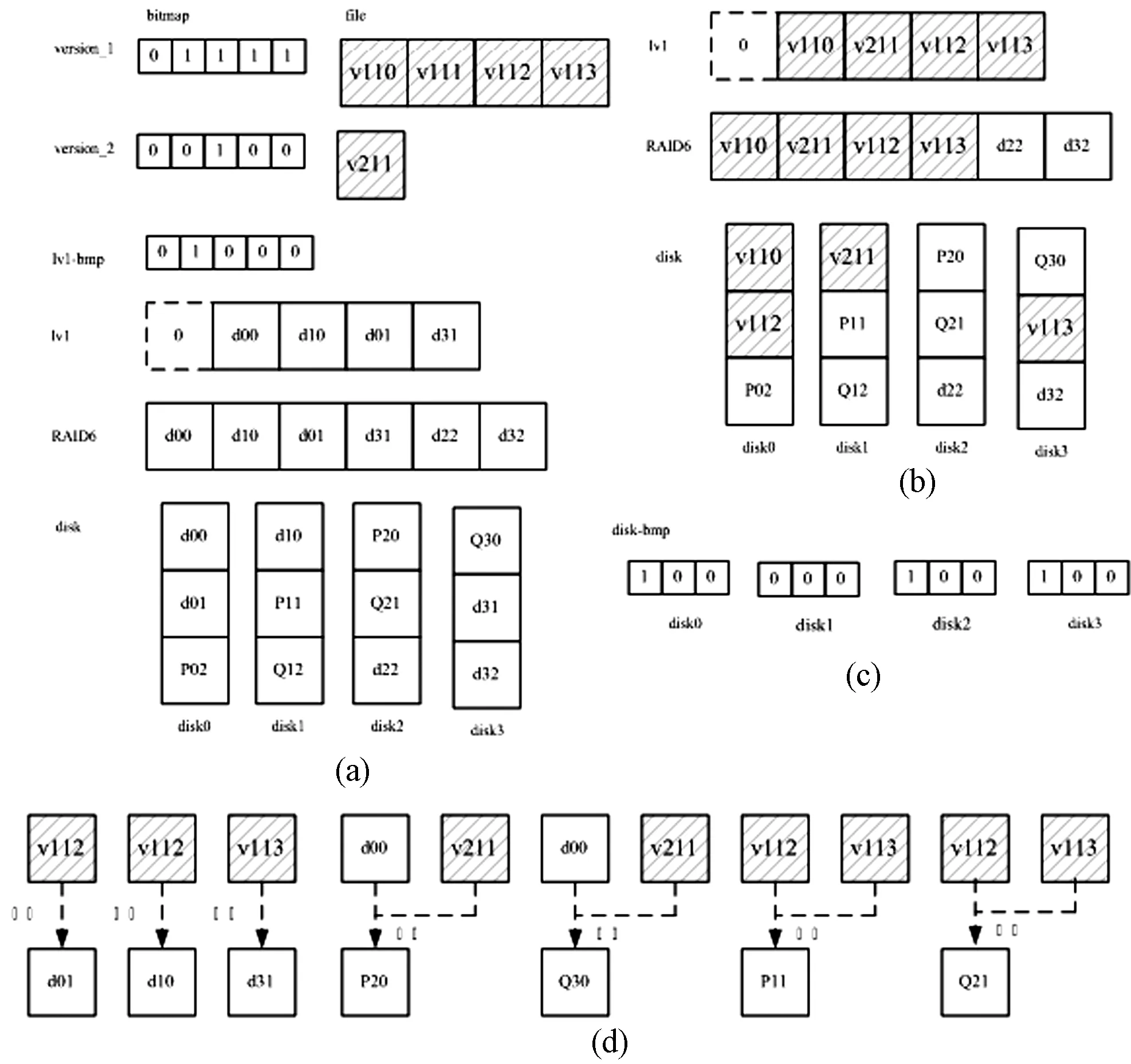
圖2 磁盤邏輯塊與最新備份數據塊的映射關系
圖2(a)描述了備份版本、邏輯卷、磁盤陣列和磁盤之間的映射關系。假設陣列RAID6由disk0、disk1、disk2和disk3四塊磁盤構成;邏輯卷塊級備份粒度(備份數據塊)、磁盤上邏輯塊、RAID6上chunk、邏輯卷空間分配粒度都為4 KB;一個邏輯卷lv1已被創(chuàng)建;邏輯卷lv1做了兩次塊級備份,第一次備份版本為version_1,第二次備份版本為version_2;位圖lv1-bmp為自最近一次備份時間點之后的差別增量位圖,也就是第二次備份時間點之后所修改數據塊的位圖。
如圖2(a)所示,邏輯卷lv1的第0邏輯塊和第4邏輯塊未分配實際磁盤邏輯塊,第1塊映射到磁盤disk0的第0塊(d00),lv1其余邏輯塊與磁盤上邏輯塊的映射關系不再贅述;邏輯卷lv1的version_1上數據塊v110,根據version_1的位圖,v110對應lv1的第1塊數據(處于version_1時刻),其余版本所保存的數據塊與邏輯卷lv1邏輯塊的映射關系不再贅述;根據位圖lv1-bmp,邏輯卷lv1的第1個邏輯塊自最近一次備份時間點之后被修改;磁盤邏輯塊d22和d32未被使用,其上數據為零。
根據圖2(a)的備份版本、邏輯卷與磁盤陣列邏輯塊的映射關系、以及磁盤陣列與磁盤邏輯塊的映射關系,可以計算出任一磁盤邏輯塊與最新備份數據塊的映射關系。根據圖2(a)所描述的映射關系,計算出disk0、disk1、disk2和disk3這四塊磁盤的數據塊與備份數據塊的映射關系,如圖2(b)所示。在圖2(b)中,備份數據塊v110映射在disk0的第0塊(d00)上,其余不再贅述。
圖2(c)描述了各磁盤上自最近一次備份時間點之后修改數據的位置標識(版本修復位圖)。在圖2(a)中,根據位圖lv1-bmp,可知磁盤disk0上邏輯塊d00上數據自最近一次備份之后已被修改,因此,磁盤disk2邏輯塊p20和磁盤disk3邏輯塊Q30上數據自最近一次備份之后都已被修改;生成了磁盤disk0、disk1、disk2和disk3上自最近一次備份時間點之后修改數據的位置標識。
圖2(d)中描述了使用最新備份數據塊來生成各磁盤邏輯塊數據。如圖2(d)所示,磁盤disk0邏輯塊d01數據等同于備份數據塊v112,其他不再贅述;由于磁盤disk0邏輯塊d00自最近一次備份時間點后被修改,所以磁盤disk2邏輯塊P20上數據由邏輯塊d00上數據和備份數據塊V211計算出來,其他不再贅述;由于d01和d31自最近一次備份時間點都未修改,因此,備份數據塊V112和V113計算出P11和Q21。
2.3 恢復管理
恢復管理構件由多個讀線程和一個寫線程構成,映射管理構件由一個線程構成。當恢復管理構件進行spare磁盤的恢復操作時,映射管理構件并行生成映射關系和版本修復位圖。
恢復管理構件采取多個讀線程并發(fā)讀取備份數據。一個讀線程從映射緩沖內順序取出一個映射關系,對于P和Q兩個校驗碼,讀線程將所有相關數據(若干塊備份數據)讀出,計算出P和Q兩個校驗碼,存放于數據緩沖相應位置;對于數據,則將相應數據(一塊備份數據)讀出,存放于數據緩沖相應位置。當某個讀線程完成數據讀取后,則順序處理還未讀取的數據。
恢復管理構件采用單個寫線程將數據順序寫入spare磁盤。恢復管理構件有兩個數據緩沖,當讀線程讀取數據并存放于一個緩沖時,寫線程將已放滿數據的另一個緩沖中數據寫入spare盤中。
2.4 重構管理
在此原型系統(tǒng)中,重構管理構件僅負責版本修復階段。通過版本修復位圖和輔助位圖兩者合作,重構管理構件實現了版本修復功能。版本修復位圖是自最近備份時間點之后修改數據的位置標識,輔助位圖上所有位初始為0,兩個位圖上每一位與磁盤上4 KB邏輯塊一一對應。通過版本修復位圖和輔助位圖之間合作,可以判斷邏輯塊上數據是否有效。spare磁盤邏輯塊上數據被定義了兩種狀態(tài):
VALID——如果版本修復位圖中某位為0或者輔助位圖中某位為1,則對應邏輯塊上數據有效。
INVALID——如果版本修復位圖中某位為1,且輔助位圖中相應位為0,則對應邏輯塊上數據無效,即邏輯塊上數據自最近一次備份時間點之后已被修改。
在版本修復階段,版本修復位圖和輔助位圖協(xié)作過程如下:
(1) 按照版本修復位圖和輔助位圖,順序發(fā)出對于無效數據塊的重構請求。當所計算出的數據被寫入spare磁盤對應邏輯塊之后,則將輔助位圖上相應位設為1,從而標識對應邏輯塊上數據已經有效。
(2) 用戶讀請求訪問spare磁盤時,被訪問邏輯塊上數據有效,則直接訪問spare磁盤;否則,通過同一條帶上其余數據塊構建出被訪問的數據塊,并將其寫入spare盤,同時,將輔助位圖上相應位設為1,從而標識被訪問邏輯塊上數據已經有效。
(3) 用戶寫請求訪問spare磁盤時,將版本修復位圖上相應位設為1,并直接將寫請求發(fā)送給spare磁盤;寫請求完成之后,則將輔助位圖上相應位設為1,標識被訪問邏輯塊上數據已經有效。
通過面向數據的磁盤陣列架構、映射管理、恢復管理和重構管理四個構件,我們實現了基于備份的RAID6在線重構框架的原型系統(tǒng)。
3 性能評價
本文主要使用面向磁盤重構算法DOR(Disk-Oriented Reconstruction)與基于備份的RAID6在線重構框架進行對比。因為DOR方法是現有重構方法中最有效算法之一,而且已經被實現于許多軟RAID6和硬RAID6產品中,并且在許多文獻中受到最廣泛的研究。
本節(jié)的測試配置如下設置:cello99(12-25、和10-05) 和 F1.spc應用模式;對于cello99和F1.spc這兩種應用模式,生產系統(tǒng)RAID6單塊磁盤容量分別設為92 GB和31 GB;邏輯卷空間分配粒度為32 MB,完全隨機分配;生產系統(tǒng)RAID6由10塊磁盤構成,生產系統(tǒng)RAID6中第8塊磁盤單塊磁盤失效和生產系統(tǒng)RAID6中第8塊和第9塊磁盤兩塊磁盤失效兩種情況;4 KB、8 KB和16 KB備份版本集合;每個邏輯卷對應備份版本集合包含了184個版本;備份數據存儲設備為磁盤陣列RAID5,由6塊磁盤構成;恢復管理模塊里讀線程數目設置為30,寫線程數目設置為1。
在下文中,4 KB表示為:備份版本集合的備份粒度為4 KB;8 KB、16 KB含義與4 KB類似。
3.1 重構性能
圖3描述了一塊磁盤失效時,基于備份的RAID6在線重構框架的重構性能相對于DOR提高倍數。在圖3中,對于cello99-12-25應用負載(每天修改數據量較小且負載壓力較小),此框架的重構性能比DOR提高了1.43至3.06倍;而對于cello99-10-05應用負載(每天修改數據量較小且負載壓力較大),此框架的重構性能比DOR提高了11.51至15.49倍;對于F1.spc(每天修改數據量非常大),此框架的重構性能也比DOR提高了2.53至3.01倍左右。

圖3 一塊磁盤失效時,此框架重構性能相對于DOR提高倍數
圖4描述了兩塊磁盤失效時,基于備份的RAID6在線重構框架的重構性能相對于DOR提高倍數。在圖4中,對于cello99-12-25應用負載,此框架的重構性能比DOR提高了1.83至3.46倍;而對于cello99-10-05應用負載,此框架的重構性能比DOR提高了11.95至15.93倍;對于F1.spc,此框架的重構性能也比DOR提高了2.93至3.39倍左右。
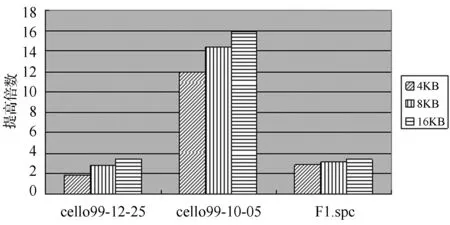
圖4 兩塊磁盤失效時,此框架重構性能相對于DOR提高倍數
3.2 服務性能
圖5描述了一塊磁盤失效時,基于備份的RAID6在線重構框架的總體平均響應時間相對于DOR降低百分比。如圖5所示,當一塊磁盤失效時,對于cello99-12-25應用負載,此框架的總體平均響應時間比DOR降低10%左右;而對于cello99-10-05應用負載,此框架的平均響應時間比DOR降低12.8%左右;對于F1.spc應用模式,此框架的總體平均響應時間僅比DOR降低了7.7%左右。
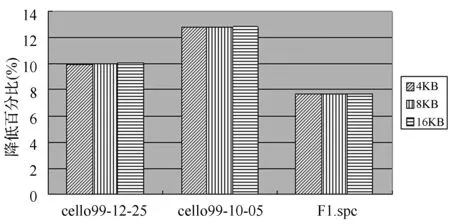
圖5 一塊磁盤失效,此框架的總體平均響應時間相對于DOR降低百分比
圖6描述了基于備份的RAID6在線重構框架的總體平均響應時間相對于DOR降低百分比。如圖6所示,對于cello99-12-25應用負載,此框架的總體平均響應時間比DOR降低10.6%左右;而對于cello99-10-05應用負載,此框架的平均響應時間比DOR降低13.5%左右;對于F1.spc應用模式,此框架的總體平均響應時間僅比DOR降低了8.2%左右。
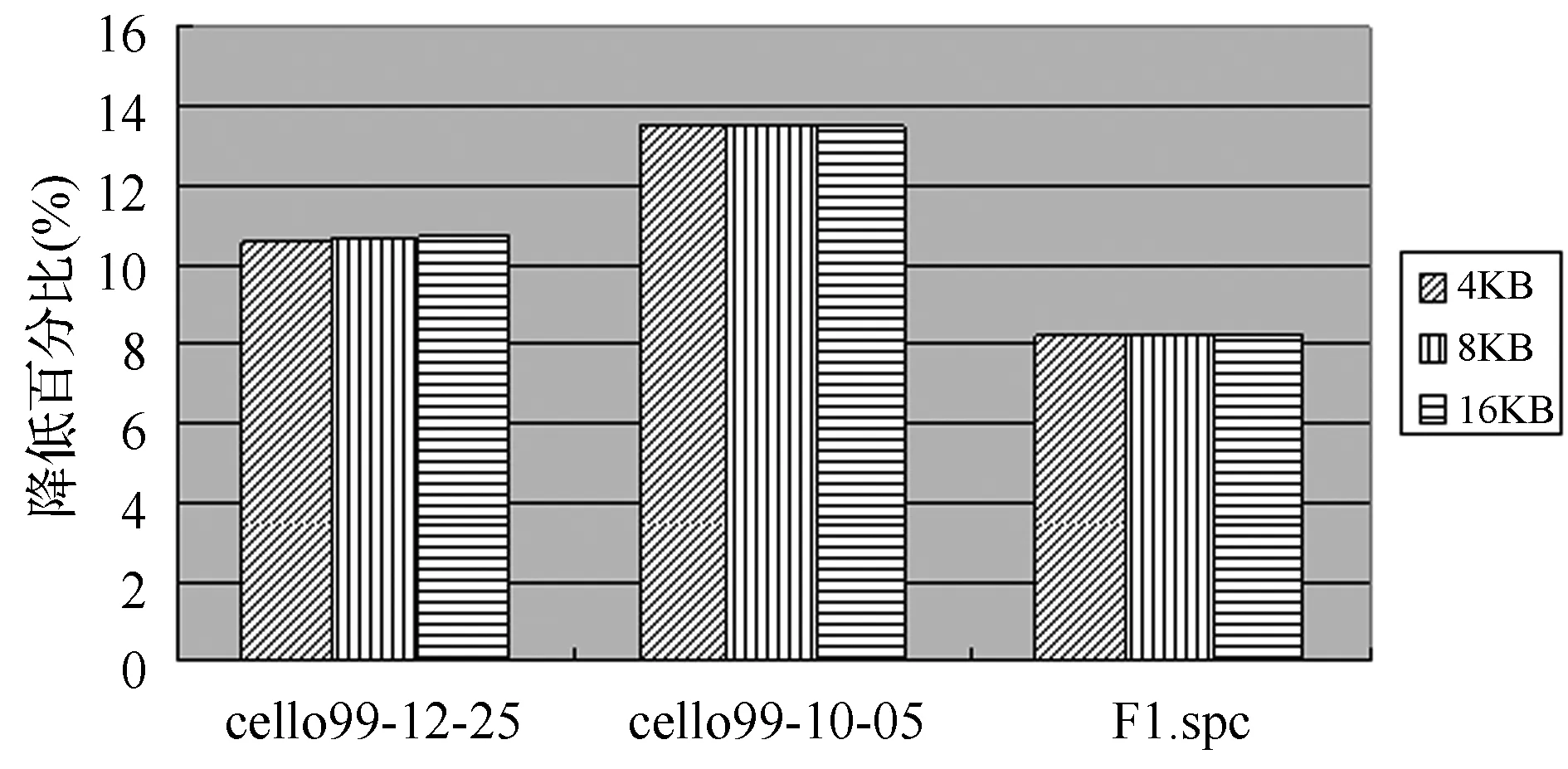
圖6 兩塊磁盤失效,此框架的總體平均響應時間相對于DOR降低百分比
4 代價分析
4.1 磁盤陣列備份映射關系的維護開銷
為了在發(fā)生磁盤失效時能夠盡快建立起所需映射關系,必須維護最新備份數據塊與磁盤陣列上邏輯塊的映射關系(磁盤陣列備份映射關系)。維護此類映射關系的空間開銷和時間開銷如表1所示。
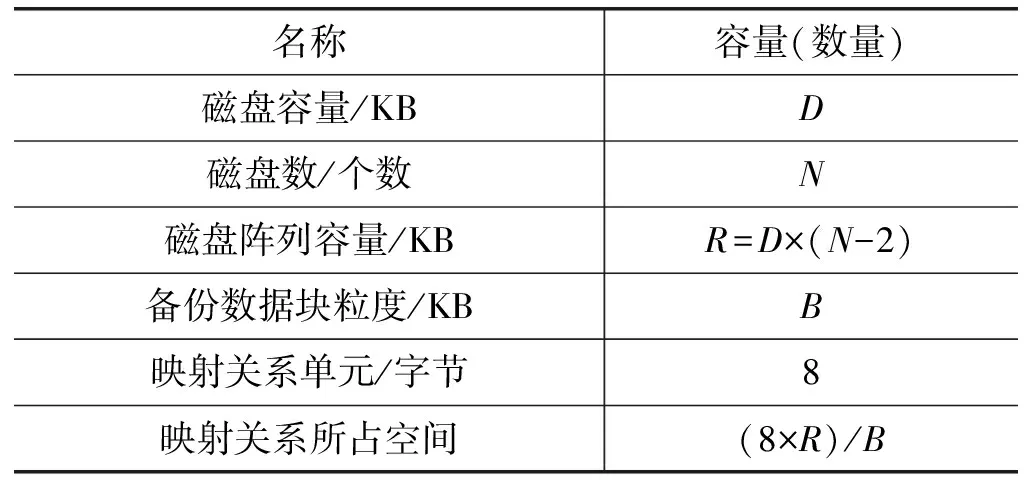
表1 磁盤陣列備份映射關系的維護開銷
(1) 空間開銷。假設磁盤容量為2 TB,磁盤數為6,備份數據塊為4 KB,生產系統(tǒng)上磁盤陣列RAID6存儲容量為8 TB;由于備份系統(tǒng)上存儲容量一般大于生產系統(tǒng),假設備份系統(tǒng)上存儲容量為8 TB;如表1所示,該映射關系占用16 GB空間,僅占備份系統(tǒng)上存儲容量的0.2%;假如備份數據塊粒度為64 KB時,僅占備份系統(tǒng)上存儲容量的0.012%。因此,日常所需維護的映射關系所產生的空間開銷可以忽略不計。
(2) 時間開銷。在備份系統(tǒng)上進行日常維護,日常維護映射關系的算法如下:首先從生產系統(tǒng)里讀取邏輯卷和磁盤陣列邏輯塊映射關系;讀取邏輯卷最新備份版本位圖;然后在內存中更新磁盤陣列備份映射關系(順序排列),每500 MB寫回一次;每個邏輯卷依次進行。
測試配置如下設置:生產系統(tǒng)上磁盤陣列RAID6由6塊磁盤構成,單塊磁盤容量為2 TB;空間分配粒度為32 MB,完全隨機分配;4 KB備份版本集合;生產系統(tǒng)RAID6分配了64個128 GB邏輯卷;備份系統(tǒng)為單塊磁盤,磁盤容量為2 TB,存放了64個邏輯卷全量備份的備份版本位圖,也即每個備份版本位圖所有bit位為1,每個備份版本位圖為4 MB。磁盤陣列備份映射關系文件為16 GB,也存放在備份系統(tǒng)單塊2 TB磁盤上。測試結果顯示更新磁盤陣列備份映射關系只需要14.4 min。而且,在備份系統(tǒng)上通常采用磁盤陣列,則讀寫性能會更高,磁盤陣列備份映射關系維護時間開銷將更少。
4.2 失效磁盤備份映射關系的建立開銷
當磁盤陣列發(fā)生磁盤失效時,需要建立失效磁盤邏輯塊與最新備份數據塊的映射關系(失效磁盤備份映射關系),本節(jié)主要考察了建立失效磁盤備份映射關系的開銷。
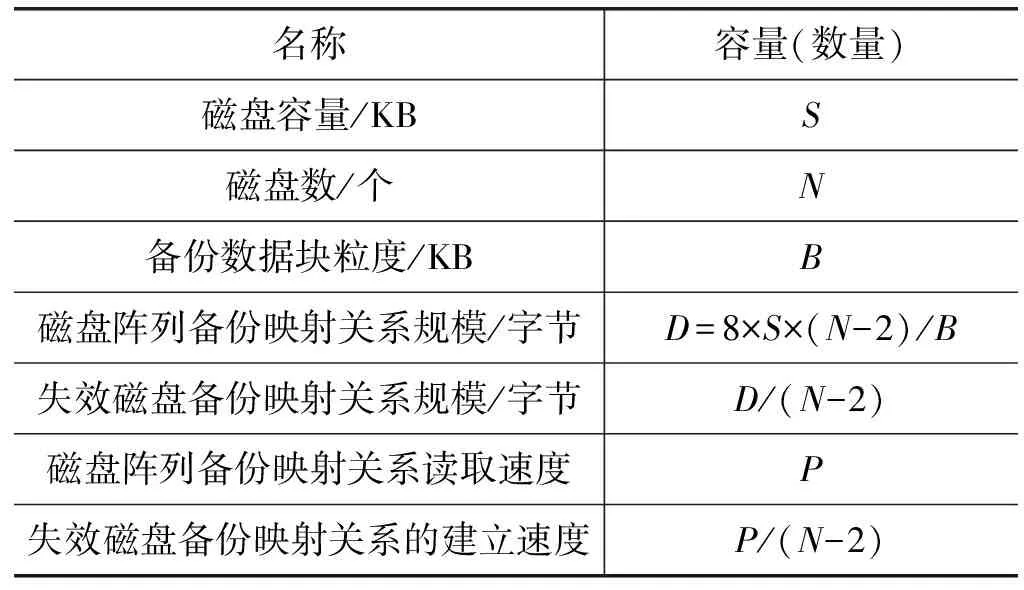
表2 失效磁盤備份映射關系的建立開銷
表2描述了失效磁盤備份映射關系的建立開銷。測試配置如下設置:生產系統(tǒng)上磁盤陣列RAID6由6塊磁盤構成,單塊磁盤容量為2 TB;其中,1塊磁盤失效;空間分配粒度為32 MB,完全隨機分配;4 KB備份版本集合;生產系統(tǒng)RAID6分配了64個128 GB邏輯卷;1個16 GB磁盤陣列備份映射關系文件存放在單塊磁盤上。如表2所示,失效磁盤備份映射關系的建立速度是磁盤陣列備份映射關系讀取速度的0.25倍。由于磁盤陣列備份映射關系讀取速度接近磁盤順序讀速度60 MB/s,失效磁盤備份映射關系的建立速度為15 MB/s。其他條件不變,當生產系統(tǒng)RAID6磁盤數增加到602個時,失效磁盤備份映射關系的建立速度降低為0.1 MB/s,每秒讀取12.8 KB個備份數據塊位置信息,即能夠滿足備份數據塊讀取速度51.2 MB/s,遠超出該框架備份數據讀取速度。
即使生產系統(tǒng)RAID6磁盤數大量增加,失效磁盤備份映射關系建立速度仍然能滿足該框架備份數據讀取速度。
4.3 相關位圖的開銷
相對于傳統(tǒng)RAID重構方法,該框架增加了全局位圖、版本修復位圖和輔助位圖所引起的開銷如表3所示。
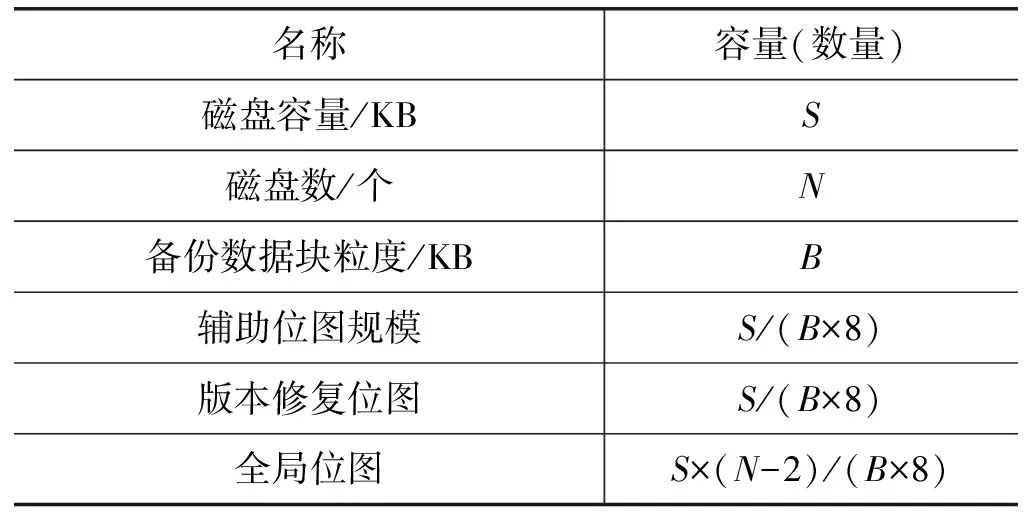
表3 位圖規(guī)模
(1) 訪問開銷。由于全局位圖、版本修復位圖和輔助位圖都存放于內存中,因此,訪問這三個位圖所產生的開銷可以忽略不計。
(2) 空間開銷。1 TB存儲容量一般配置3 GB內存,假設S為2 TB,磁盤數為6,磁盤陣列為RAID6;如表3所示,版本修復位圖和輔助位圖都為64 MB,全局位圖為256 MB,僅為系統(tǒng)內存總量(3×8) GB的1.56%。因此,三個位圖的空間開銷幾乎可以忽略不計。
5 結 語
對于RAID6在線重構的研究,國內外現有研究一直解決不了重負載持續(xù)訪問下磁盤陣列RAID6重構性能急劇惡化的問題。由于大容量磁盤越來越便宜,日常備份系統(tǒng)也常采用磁盤陣列存儲備份數據。
基于備份的RAID6在線重構框架利用備份系統(tǒng)所提供的穩(wěn)定恢復帶寬,顯著降低了應用負載對重構過程的影響,同時,顯著減少了磁盤陣列RAID6參入重構,使得磁盤陣列RAID6優(yōu)先滿足用戶服務。該框架顯著改善了重構性能,也改善了即時服務性能。相對于DOR算法(現在最常用且最有效重構算法之一),在一塊磁盤失效情況下,此框架將重構性能提高了1.43至15.49倍,平均響應時間改善了7.7%至12.8%;在兩塊磁盤失效情況下,此框架將重構性能提高了1.83至15.93倍,平均響應時間改善了8.2%至13.5%。
我們下一步工作將根據應用負載的基本信息,考慮當前的系統(tǒng)服務性能和應用負載特征,確定磁盤陣列RAID6內重構帶寬和備份系統(tǒng)上恢復帶寬的利用比例,并能夠隨著應用負載變化進行自適應調整,以便在服務性能和重構性能之間取得平衡,完成數據重構。
參考文獻
[1] Rhea S, Wells C, Eaton P, et al. Maintenance-free global data storage[J]. IEEE Internet Computing, 2001, 5(5):40-49.
[2] Pinheiro E, Weber W D, Barroso L A. Failure Trends in a Large Disk Drive Population.[C]// Usenix Conference on File and Storage Technologies. San Jose, Usa. USENIX, 2007:17-28.
[3] Reddy A L N, Chandy J, Banerjee P. Design and Evaluation of Gracefully Degradable Disk Arrays[J]. Journal of Parallel & Distributed Computing, 1993, 17(1-2):28-40.
[4] Qin X, Miller E L, Schwarz S J T J E. Evaluation of distributed recovery in large-scale storage systems[C]// IEEE International Symposium on High PERFORMANCE Distributed Computing, 2004. Proceedings. IEEE, 2004:172-181.
[5] Wu X, Li J, Kameda H. Reliability Modeling of Declustered-Parity RAID Considering Uncorrectable Bit Errors[J]. Ieice Transactions on Fundamentals of Electronics Communications & Computer Sciences, 1997, 80(8):1508-1514.
[6] Luo X, Shu J, Zhao Y. Shifted Element Arrangement in Mirror Disk Arrays for High Data Availability during Reconstruction[C]// International Conference on Parallel Processing. IEEE, 2012:178-188.
[7] Wan J, Wang J, Xie C, et al. Formula Not Shown-RAID: Parallel RAID Architecture for Fast Data Recovery[J]. IEEE Transactions on Parallel & Distributed Systems, 2014, 25(6):1638-1647.
[8] Xie P, Huang J Z, Cao Q, et al. V2-Code: A new non-MDS array code with optimal reconstruction performance for RAID-6[C]// 2013 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 2013:1-8.
[9] Xie P, Huang J Z, Dai E W, et al. An efficient data layout scheme for better I/O balancing in RAID-6 storage systems[J]. Frontiers of Information Technology & Electronic Engineering, 2015, 16(5):335-345.
[10] Fu Y, Shu J, Luo X, et al. Short Code: An Efficient RAID-6 MDS Code for Optimizing Degraded Reads and Partial Stripe Writes[J]. IEEE Transactions on Computers, 2016, 66(1):127-137.
[11] Fu G, Thomasian A, Han C, et al. Rebuild Strategies for Redundant Disk Arrays.[C]// Symposium on Mass Storage Systems. 2004:223-226.
[12] Tian L, Feng D, Jiang H, et al. PRO: A Popularity-based Multi-threaded Reconstruction Optimization for RAID-Structured Storage Systems.[C]// Usenix Conference on File and Storage Technologies, FAST 2007, February 13-16, 2007, San Jose, Ca, Usa. DBLP, 2007:277-290.
[13] 陳金忠, 姚念民, 蔡紹濱. 基于NAND閃存的高性能和可靠的PRAID-6[J]. 電子學報,2015,43 (6): 1211-1217.
[14] 劉靖宇,譚毓安,薛靜鋒,等.S-RAID中基于連續(xù)數據特征的寫優(yōu)化策略[J].計算機學報,2014,37(3):721-734.
[15] Lei T, Hong J, Dan F, et al. Implementation and Evaluation of a Popularity-Based Reconstruction Optimization Algorithm in Availability-Oriented Disk Arrays[C]// MASS Storage Systems and Technologies, 2007. MSST 2007. IEEE Conference on. IEEE, 2007:233-238.
[16] Lumb C R,Schindler J,Ganger G R,et al.Towards higher disk head utilization:extracting free bandwidth from busy disk drives[C]// Conference on Symposium on Operating System Design & Implementation.USENIX Association, 2000:7-7.
[17] Thereska E, Schindler J, Bucy J, et al. A framework for building unobtrusive disk maintenance applications[C]// Proceedings of the third USENIX Conference on File and Storage Technologies, 2004,2: 213-226.
[18] Liu F, Pan W, Xie T, et al. PDB: A Reliability-Driven Data Reconstruction Strategy Based on Popular Data Backup for RAID4 SSD Arrays[M]// Algorithms and Architectures for Parallel Processing. 2013:87-100.
[19] Khasymski A, Rafique M M, Butt A R, et al. On the Use of GPUs in Realizing Cost-Effective Distributed RAID[C]// IEEE, International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems. IEEE Computer Society, 2012:469-478.
[20] 高玲玲,許胤龍,王英子,等. 基于RAID6編碼的校驗盤故障修復算法[J]. 計算機應用與軟件,2014, 31(6):248-251,302.
猜你喜歡
工業(yè)設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
