關聯規則挖掘在游戲視頻銷售中的研究與應用
2018-05-15 02:19:52閆東明陳占芳姜曉明
軟件工程 2018年3期
關鍵詞:數據挖掘
閆東明 陳占芳 姜曉明


摘 要:數據挖掘是一項熱門技術,該技術融合了數據庫、統計學等領域知識,關聯規則的挖掘則能找出商品銷售中商品之間的聯系。本文針對Apriori算法,及其改進算法FP-Growth進行了研究,對比了Apriori算法與FP-Growth算法的效率,得出FP-Growth算法由于只需要對數據進行一次掃描即可生成相應的數據集,使其生成數據集的整體效率要高于Apriori算法。
關鍵詞:Apriori算法;數據挖掘;FP-Growth算法;關聯規則;游戲銷售
中圖分類號:TP391 文獻標識碼:A
Abstract:Data mining is a hot technology which comprises database,artificial intelligence,statistics,etc.The mining association rules can find out the relations among the selling commodities.This paper studies Apriori algorithm and its improved algorithm,FP-Growth,and compares the efficiency of them,where it is found that corresponding data set can be generated after only one data scanning based on FP-Growth algorithm,leading to higher overall efficiency of the generated data set than that of Apriori algorithm.
Keywords:Apriori algorithm;data mining;FP-Growth algorithm;association rules;game sale
1 引言(Introduction)
關聯規則是近年來數據挖掘領域中最熱門的問題之一,它已經被證明對于市場與零售業,以及其他不同領域都有很重要的作用。關聯規則問題涉及了諸多技術知識,如數據庫、人工智能和統計學等,該問題的研究目的是統計龐雜的數據并提取出有效信息進行分析,得到同一事件出現在不同項的相關性,關聯規則發現的主要對象是交易型數據庫。
Apriori算法是一種經典的挖掘關聯規則的算法,該算法根據用戶給出的最小支持度閾值找到交易型數據庫中所有頻繁項集,再通過計算找出符合最小置信度的強關聯規則,從而挖掘出有用的知識。Apriori算法的核心思想有兩點:(1)非頻繁項的超集是非頻繁項集;(2)頻繁項的子集是頻繁項集。該算法利用了一個層次順序搜索的循環方法來完成頻繁項集的挖掘計算。但是,多次掃描數據庫和產生數量巨大的候選集是Apriori算法的兩個無法避免的性能瓶頸[1]。很多基于Apriori算法的方法被提出,目的都是為了提搞掃描數據庫的效率或是減少候選集的產生,其中AprioriTid算法對Apriori算法的循環掃描方式做出了改進[2],AprioriTid算法僅在計算第一個頻繁項集時掃描一次數據庫,然后使用候選集Ck-1來計算項集的支持度并得到頻繁k-項集,從而使掃描候選項集的次數隨著頻繁項集階數的增加而逐步減少,提高了掃描數據的效率。在掃描的初始階段,由于候選項集數量遠大于數據項數量,這將導致候選事務的數據量可能遠大于原始事務的數據量,所以此時AprioriTid算法的效率要低于Apriori算法[3-5],而后隨著候選項集的減少,AprioriTid只需要掃描比原始數據庫小得多的候選事務數據庫,使運算效率得以大幅提升。
2 理論基礎(Theoretical basis)
關聯規則挖掘的問題被定義為:
為一個或多個的n項組,項目是其中的一個字段,一般指一次交易中的一個物品[6];
為一組被稱為交易數據庫的事務集,而每個事務t都是I的非空子集,即每一個交易都與一個唯一的標識符對應。每一條事務中僅包含該事務涉及的項目,并不包含項目中的具體信息;
:表示規則(Rule),其中并且,項和分別是規則的前提和結論,或被稱為左手邊與右手邊;
:表示項和的支持度,支持度的計算公式如公式(1)所示:
:被稱為規則的置信度,置信度的計算公式如公式(2)所示:
:表示用戶自定義的一個衡量支持度的閾值,同時也表示該項目集在統計意義上的最低閥值,用支持度來衡量規則是非常重要的,因為非常低的支持度只會偶然發生,低支持度的規則從商業的角度出發看起來也是沒有意義的,因為推廣客戶購買非常低可能性同時出售的商品可能是無利可圖的,基于上述原因,支持度常被用來消除無意義的規則;
頻繁項集:對于一個項目集,如果,則稱為頻繁項集。
強關聯規則:如果的置信度和支持度不小于用戶自定義的和,則稱是一個強關聯規則,否則為弱關聯規則。
關聯規則的挖掘是在事務數據庫中,找到滿足用戶定義的最小支持度和最小置信度要求的關聯規則,其過程主要有兩個階段:
(1)第一個階段必須先從所有數據集合中找出所有的頻繁項集。
在事務數據庫D的所有數據中找出滿足條件的全部頻繁項的集合,也就是找出所有的的項集X。
(2)第二個階段是在這些頻繁項中產生關聯規則
利用頻繁項集產生關聯規則,針對每一頻繁項集X,如果,Y非空,且,則X與Y構成了關聯規則,滿足用戶給定的最小支持度和最小置信度。
關聯規則的第一個階段是從原始的數據集合中開始的,需要找出所有頻繁項集,這一步驟是關聯規則挖掘的一個重點問題,也是能夠衡量關聯規則算法優良的指標。頻繁項集的是指某一個項出現的頻率相對于所有記錄而言,必須到達某一水平。第二個問題相對容易一些,目前所有的關聯規則算法都是針對第一個問題提出的[7]。
3 Apriori算法與AprioriTid算法的研究(Research on Apriori algorithm and AprioriTid algorithm)
Apriori算法是一種基本的挖掘關聯規則算法,該算法的第一步為確定初始的一個大項集,記為L1。接下來的K步包含兩部分,第一部分,項集Lk-1做(k-1)次Apriori-gen循環以產生候選集Ck。第二部分,掃描數據并計算候選集Ck中每一項的支持度。如果存在候選K-集,其支持度不小于最小支持度,則判定為頻繁K-項集,Apriori-gen循環到不再產生候選集結束。Apriori算法輸入為銷售型數據庫D,和最小支持度閾值,輸出的是計算過后的頻繁項集,該頻繁項集包含了所有滿足最小支持度的項。
Apriori算法偽代碼實現:
//找出頻繁1-項集,即通過單遍掃描確定每個項的支持度,得到頻繁1-項集的集合L1
L1=find_frequent_1-itemsets(D);
For(k=2;Lk-1!=null;k++)
{
Ck=apriori_gen(Lk-1); //產生候選集,并剪枝
For each 事務t 屬于 D //掃描D并計數
{
Ct=subset(Ck,t); //得到t的子集
For each 候選子集c屬于Ct
c.count++;
}
//返回候選項集中,候選子集不小于最小支持度的的集合,即頻繁k-項集Lk
Lk={c屬于Ck|c.count>=min_sup}
}
Return L=所有的頻繁項集;
第一步:連接步
Procedure apriori_gen(Lk-1:frequent(k-1)-items)
For each 項集l1處于Lk-1
For each 項集l2屬于Lk-1
If((l1[1]=l2[1])&&(l1[2]=l2[2])&&
……&& (l1[k-2]=l2[k-2])&&(l1[k-1] then { c=l1連接l2 //連接步:產生候選子集c,若頻繁k-1-項集Lk-1中已經存在子集c則進行剪枝 If has_infrequent_subset(c,Lk-1)then Delete c; //剪枝步:刪除不符合條件的候選子集 else add c to Ck; } Return Ck; 即通過將Lk-1與自身連接產生候選k-項集的集合Ck。 第二步:剪枝步 Procedure has_infrequent_subset(c:candidate k-itemset; Lk-1:frequent(k-1)-itemsets) For each (k-1)-subset s of c If s不屬于Lk-1 then Return true; Return false; 如代碼中描述的,Apriori算法的工作模式是先生產,再檢驗。如果數據集非常大,那么不斷掃描數據集就會造成運算效率較低這一問題。 FP-Growth算法的思路是首先掃描兩次數據集,構建出FP-Tree;然后將數據集中的所有事務映射在FP-Tree上;最后通過FP-Tree找出其中的頻繁項集。FP-Growth算法的輸入輸出與Apriori算法一致,而構建FP-Tree的過程為: 1)第一次掃描數據庫,計算每個項的支持度并得到頻繁1-項集 2)把項按支持度遞減排序 3)第二次掃描數據庫,建立FP-Tree 挖掘頻繁項集的過程: 1)根據D和minsupp,調用FP-Tree; 2)倘若FP-Tree是一條簡單路徑 組合路徑上所有支持度大于minsupp的節點,得到頻繁項集else初始化最大頻繁集 3)根據支持度從大到小排序,以每個1-頻繁項為后綴,調用挖掘算法挖掘最大頻繁項集 4)輸出所有頻繁項集。 根據以上兩個過程,我們就可以完成FP-Growth的頻繁項集挖掘。FP-Growth算法可以避免產生大量的候選集,但由于該伏安法要遞歸生成條件數據庫和條件FP-Tree,所以內存開銷較大,且只能用于挖掘單維的布爾型關聯規則。 4 對比試驗(Contrast test) 本實驗通過使用Weka軟件,對Apriori算法與FP-Growth算法進行比對,輸入數據為超市商品銷售數據,其格式如圖1所示。 其橫坐標代表了每一次顧客的購買記錄,若購買了嬰幼兒必須品,則在該類別中以t為記錄,縱坐標表示了商品的種類。輸入最小支持度與置信度,當計算出最小支持度后,與項的概率相除即置信度,既可以找出相應支持度與置信度的關聯規則,首先應用Apriori算法對書籍進行處理,當最小支持度設置為0.15,置信度設置為0.9時,得到的關聯規則如圖2所示。 由圖可知當支持度為0.15,置信度為0.9時,購買餅干、冷凍食品、水果,則很有可能買面包和蛋糕,購買炊事用品、餅干和水果時、很有可能買了面包和蛋糕等。 再利用FP-Growth算法,對同樣的數據進行挖掘計算,得到的結果如圖3所示。
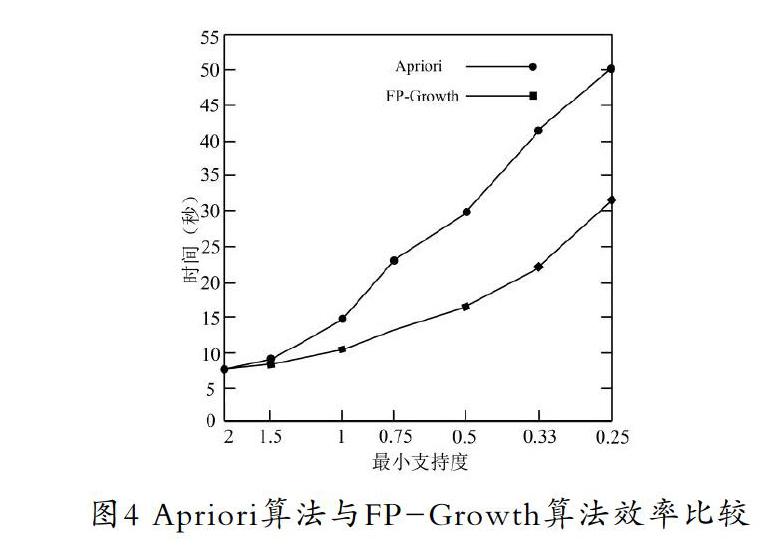
由圖3和圖4可以看出,FP-Growth算法效率要高于Apriori算法。
5 結論(Conclusion)
本文對Apriori算法及其改進的算法進行了研究,并將Apriori算法應用于游戲銷售數據中,挖掘出銷售數據中的強關聯規則,并對相關規則作出描述,總結出了一套視頻游戲的銷售規律。
參考文獻(References)
[1] Tsai C F,Lin Y C,Chen C P.A new fast a-lgorithms for mining association rules in large databases[C].IEEE International Conference on Systems,Man and Cybernetics.IEEE,2002,7:6.
[2] Khabzaoui M,Dhaenens C,TalbiEG.Fast algorithms for mining association rules[J].Journal of Computer Science & Technology,2008,15(6):619-624.
[3] Yang L,Wang F,Wang T.Analysis of dishonorable behavior on railway online ticketing system based on k-means and FP-growth[C].IEEE International Conference on Information and Automation.IEEE,2017:1173-1177.
[4] Pamba R V,Sherly E,Mohan K.Automated Information Retrieval Model Using FP Growth Based Fuzzy Particle Swarm Optimization[J].International Journal of Information Technology & Computer Science,2017,9(1):105-111.
[5] 林穎華,陳長鳳.基于關聯規則的企業財務風險評價研究[J].會計之友, 2017(1):32-35.
[6] 高曉佳.Apriori算法優化策略的研究[J].長春理工大學學報(自然科學版),2009,32(4):660-662.
[7] 劉玉鋒.數據挖掘中關聯規則算法的研究與應用[D].長春理工大學,2010.
作者簡介:
閆東明(1989-),男,碩士生.研究領域:數據庫與數據挖掘.
陳占芳(1980-),男,博士,副教授.研究領域:數據庫與數據挖掘.
姜曉明(1988-),男,碩士生.研究領域:數據庫與數據挖掘.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
