移動(dòng)醫(yī)療中個(gè)性化l-多樣性匿名隱私保護(hù)模型*
2018-05-09 08:50:02黃麗韶羅恩韜
計(jì)算機(jī)與生活 2018年5期
李 文,黃麗韶,羅恩韜,2+
1.湖南科技學(xué)院 電子與信息工程學(xué)院,湖南 永州 425199
2.中南大學(xué) 信息科學(xué)與工程學(xué)院,長沙 410083
1 引言
隨著移動(dòng)醫(yī)療技術(shù)的迅猛發(fā)展,醫(yī)療數(shù)據(jù)共享范圍的逐步擴(kuò)大,以及數(shù)據(jù)挖掘技術(shù)、深度學(xué)習(xí)技術(shù)的不斷更新,醫(yī)療數(shù)據(jù)在不同醫(yī)院之間的共享越來越方便。數(shù)據(jù)、信息的挖掘和共享也創(chuàng)造出巨大的經(jīng)濟(jì)價(jià)值和社會(huì)價(jià)值。但是,在數(shù)據(jù)發(fā)布和共享過程中存在一個(gè)不容忽視的問題,那就是醫(yī)療患者的隱私泄露。如果醫(yī)療機(jī)構(gòu)在共享數(shù)據(jù)的時(shí)候沒有充分考慮數(shù)據(jù)隱私問題,那么非法用戶(攻擊者)就可以利用其他機(jī)構(gòu)發(fā)布的數(shù)據(jù)進(jìn)行串聯(lián)推測,甚至利用同一醫(yī)院不同時(shí)段發(fā)布的數(shù)據(jù)漏洞獲取到醫(yī)療患者隱私敏感信息,從而對患者隱私造成不可預(yù)測的泄漏風(fēng)險(xiǎn)。
以往醫(yī)療機(jī)構(gòu)在共享或者發(fā)布醫(yī)療數(shù)據(jù)時(shí),出于隱私保護(hù)的目的,會(huì)選擇將一部分個(gè)人識(shí)別信息去除,如姓名、地址和電話等,然而攻擊者仍然可以通過其他手段獲得用戶某些不敏感信息,利用這些信息與用戶的疾病診斷數(shù)據(jù)進(jìn)行對應(yīng),從而獲得病人關(guān)于其所患疾病的隱私,這種攻擊也稱為鏈接攻擊[1]。
表1是一張醫(yī)療數(shù)據(jù)表,醫(yī)院在發(fā)布時(shí)并沒有顯式地給出病人的姓名。然而,假設(shè)攻擊者在網(wǎng)絡(luò)中得到表2所示的用戶所轄區(qū)選民投票表,那么攻擊者就可以通過將兩張表的共同屬性,例如郵編(430056),進(jìn)行鏈接推導(dǎo),從而推斷出病人的姓名(Kevin)及所患疾病“過度肥胖”。如果不法攻擊者將這些信息出賣給減肥中心,就直接導(dǎo)致病人(Kevin)的隱私信息泄露。
2 基于匿名原則的隱私保護(hù)
基于匿名原則的隱私保護(hù),主要是在數(shù)據(jù)發(fā)布或者共享前,通過數(shù)據(jù)泛化、數(shù)據(jù)抑制[1-3]等技術(shù)手段對數(shù)據(jù)表中的相關(guān)屬性進(jìn)行處理,不發(fā)布或限制發(fā)布某些數(shù)據(jù),從而讓個(gè)人標(biāo)識(shí)信息與敏感屬性失去關(guān)聯(lián),達(dá)到隱私保護(hù)的目的[4-6]。

Table 1 Sheet of medical data表1 醫(yī)療數(shù)據(jù)表

Table 2 List of voter poll表2 選民投票表
2.1 k-匿名思想
在眾多基于匿名原則的隱私保護(hù)方法中,k-匿名思想因其在保護(hù)隱私信息的同時(shí)也保證數(shù)據(jù)可用性,成為數(shù)據(jù)發(fā)布中進(jìn)行隱私保護(hù)的重要技術(shù)手段[7-12]。其核心思想是通過概括和隱匿技術(shù),發(fā)布精度較低的數(shù)據(jù),使得每條記錄至少與數(shù)據(jù)表中其他k-1條數(shù)據(jù)具有完全相同的準(zhǔn)標(biāo)識(shí)符屬性值,從而減少鏈接攻擊所導(dǎo)致的隱私泄漏。
定義1k-匿名(k-anonymity):給定數(shù)據(jù)表T{A1,A2,…,An},T的準(zhǔn)標(biāo)識(shí)符為QI,當(dāng)且僅當(dāng)T[QI]中每一個(gè)值序列在T[QI]中至少出現(xiàn)k次,稱表T滿足QI上的k-匿名。T[QI]表示表T的元組在QI上的投影。
2.2 k-匿名實(shí)質(zhì)
k-匿名實(shí)質(zhì)就是要求數(shù)據(jù)集中每一條記錄都要與至少k-1條記錄在準(zhǔn)標(biāo)識(shí)符上的投影相同,因此,個(gè)體所在記錄被確定的概率不超過1k。而泛化[13]是典型的實(shí)現(xiàn)匿名化隱私保護(hù)的技術(shù)手段,其實(shí)質(zhì)是用一般化的值或區(qū)間來替代具體值,通過降低數(shù)據(jù)精度增加攻擊者獲取個(gè)體隱私信息的難度。
表3是經(jīng)過泛化后的一張滿足k=2的匿名醫(yī)療數(shù)據(jù)表。
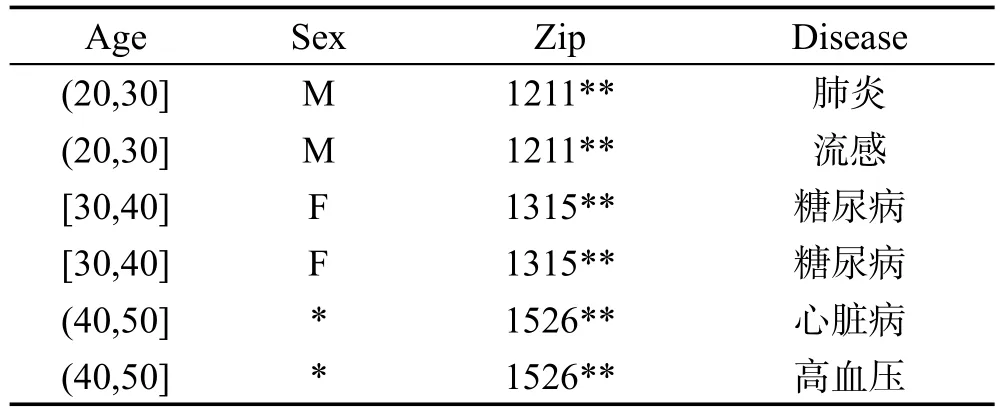
Table 3 Meeting 2-anonymous data sheet表3 滿足2-匿名數(shù)據(jù)表
2.3 k-匿名缺點(diǎn)
雖然k-匿名算法提高了發(fā)布信息的安全性,但是由于需要對數(shù)據(jù)表的某些屬性進(jìn)行泛化和隱匿,損失了一部分?jǐn)?shù)據(jù)的可用性。同時(shí)k-匿名算法在運(yùn)算過程中,存在查詢結(jié)果不精確的缺點(diǎn),尤其是在用戶稀少的場景下,將產(chǎn)生較大的匿名區(qū)域,從而增大通信開銷。
3 信息熵l-多樣性模型
經(jīng)過泛化后的數(shù)據(jù)表滿足k-匿名,保證了某個(gè)用戶處于k個(gè)同類別的個(gè)體集合之中,使得擁有相同準(zhǔn)標(biāo)識(shí)符的用戶個(gè)體不可區(qū)分,從而達(dá)到一定的匿名性保護(hù)。然而,如果處于同一等價(jià)類中的k個(gè)元組在敏感屬性上的取值相同,則用戶個(gè)體記錄會(huì)受到同質(zhì)性攻擊而造成屬性泄露,例如表3中第二個(gè)等價(jià)類。
為了解決同質(zhì)性攻擊帶來的隱私泄露問題,文獻(xiàn)[13]提出了l-diversity模型,即l-多樣性模型,要求每個(gè)等價(jià)類至少含有l(wèi)個(gè)表現(xiàn)良好(well-presented)的敏感屬性值,考慮了對敏感屬性的約束。如果數(shù)據(jù)表中每個(gè)等價(jià)類中含有l(wèi)個(gè)不同的敏感屬性值,那么就稱該數(shù)據(jù)表滿足l-多樣性規(guī)則。文獻(xiàn)[7]還給出了一種信息熵l-多樣性規(guī)則。
定義2信息熵l-多樣性(entropyl-diversity):給定數(shù)據(jù)表T{A1,A2,…,An},準(zhǔn)標(biāo)識(shí)符屬性為QI{Ai,Ai+1,…,Aj},敏感屬性為SA,S={Si,Si+1,…,Sj}為敏感屬性值。表T滿足k-匿名,并且其等價(jià)類集合為E={E1,E2,…,En},當(dāng)且僅當(dāng)對每一個(gè)等價(jià)類Ei=1,2,…,n?E,都滿足式(1)時(shí),則稱數(shù)據(jù)表T滿足信息熵l-多樣性。
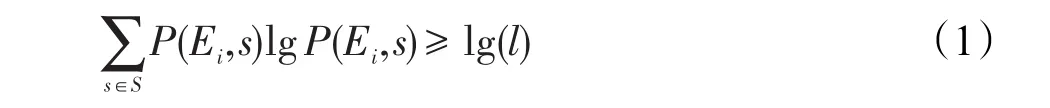
其中,P(Ei,s)為等價(jià)類Ei中敏感屬性值s出現(xiàn)的頻率;為等價(jià)類Ei的信息熵,又稱信息熵多樣性,記作Entropy(Ei)。信息熵反映了屬性的分布情況,信息熵越大,意味著等價(jià)中敏感屬性值分布越均勻,推導(dǎo)出具體個(gè)體的難度也就越大。由式(1)可知,要想等價(jià)類滿足信息熵l-多樣性,那么等價(jià)類的信息熵至少為lg(l)。表4是匿名數(shù)據(jù)表中的一個(gè)等價(jià)類。

Table 4 Meeting 5-anonymous equivalence class表4 滿足5-匿名等價(jià)類
表4中等價(jià)類的信息熵l-多樣性計(jì)算結(jié)果如下:
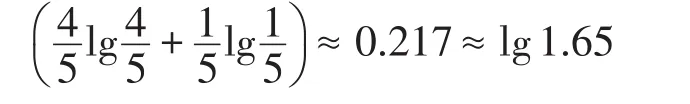
從結(jié)果來看,對于該等價(jià)類來說,其信息熵多樣性為lg1.65,參數(shù)l的取值不能超過1.65,那么只能取1,考慮到l-多樣性的定義,也就是說等價(jià)類中至少有1個(gè)不同的敏感屬性值,對于實(shí)際發(fā)布的數(shù)據(jù)表而言,這種結(jié)論顯然意義不大。
并且該等價(jià)類中的敏感屬性,有4個(gè)是“流感”,對于很多病人來說,顯然這并不是敏感屬性,如果等價(jià)類中包含4個(gè)如“肺結(jié)核”這種敏感程度很高的敏感屬性,假設(shè)攻擊者知道某人處于該等價(jià)類中,那么攻擊者有很大把握推測該人有“肺氣腫”的疾病傾向特征,這對于病人來說是不可接受的。實(shí)際上,醫(yī)療信息中包含著大量的諸如“流感”或者“發(fā)燒”這些非敏感屬性值,這些屬性值的公開并不會(huì)侵犯到個(gè)體隱私。因此,信息熵l-多樣性模型沒有區(qū)分敏感屬性值,不能反映出這種情況下隱私泄露的風(fēng)險(xiǎn)。本文提出一種個(gè)性化信息熵l-多樣性模型來保護(hù)用戶的醫(yī)療數(shù)據(jù)隱私。
4 個(gè)性化信息熵l-多樣性模型
4.1 個(gè)性化信息熵
多樣性模型定義針對信息熵l-多樣性模型存在的不足,一方面需要提高等價(jià)類的信息熵值,另一方面需要區(qū)分敏感屬性值,降低敏感屬性強(qiáng)的信息泄露概率。
因此,可以將敏感屬性值分為強(qiáng)敏感值SV(sensitive value)和弱敏感值DV(don't care value),修改信息熵l-多樣性規(guī)則后得到新的個(gè)性化信息熵l-多樣性規(guī)則。
定義3個(gè)性化信息熵l-多樣性:給定數(shù)據(jù)表T{A1,A2,…,An},QI{Ai,Ai+1,…,Aj}為T的準(zhǔn)標(biāo)識(shí)符,SA為敏感屬性,S={Si,Si+1,…,Sj}為敏感屬性值集合,SV表示強(qiáng)敏感值,DV為弱敏感值,|SV|為強(qiáng)敏感值的個(gè)數(shù),|DV|為弱敏感值的個(gè)數(shù)。表T滿足k-匿名,并且其等價(jià)類集合為E={E1,E2,…,En},當(dāng)且僅當(dāng)對每一個(gè)等價(jià)類Ei=0,1,…,n?E,都滿足式(2)時(shí),則稱數(shù)據(jù)表T滿足個(gè)性化信息熵l-多樣性。
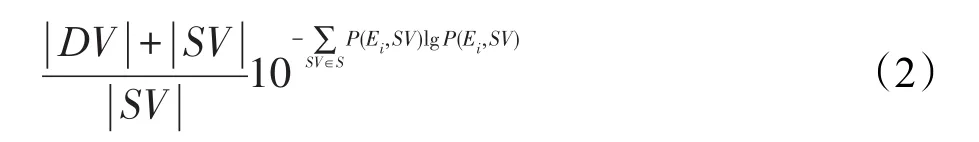
其中,P(Ei,SV)為強(qiáng)敏感屬性值在等價(jià)類中出現(xiàn)的頻率;為個(gè)性化等價(jià)類的信息熵多樣性。
由式(2)可知,需要計(jì)算等價(jià)類中強(qiáng)敏感屬性值的頻率P(Ei,SV),而不需要計(jì)算會(huì)降低P(Ei,SV)lgP(Ei,SV)值的弱敏感屬性值出現(xiàn)的頻率。用式(2)計(jì)算表4中等價(jià)類的信息熵,有DV={流感},SV={肺氣腫},|DV|=1,|SV|=1,SV在等價(jià)類中出現(xiàn)的概率為1/5,那么改進(jìn)后的信息熵多樣性為:

根據(jù)計(jì)算結(jié)果,l的取值不超過2.282 8,則l為2,該等價(jià)類滿足2-多樣性。個(gè)性化信息熵l-多樣性相比較信息熵l-多樣性,提高了等價(jià)類信息熵,降低了從等價(jià)類中鏈接推導(dǎo)出隱私信息與身份信息的對應(yīng)關(guān)系。
4.2 信息損失度量
基于k-匿名以及在其基礎(chǔ)上改進(jìn)的匿名隱私保護(hù)模型在保護(hù)隱私信息的同時(shí),不可避免地會(huì)產(chǎn)生信息損失,從而對數(shù)據(jù)精度造成影響,這就是匿名代價(jià)(anonymization cost)。匿名代價(jià)是在對原始數(shù)據(jù)進(jìn)行泛化和抑制預(yù)處理操作時(shí)產(chǎn)生的,匿名代價(jià)度量是衡量數(shù)據(jù)匿名化后信息損失的指標(biāo),同時(shí)也可以判斷匿名后的數(shù)據(jù)集的優(yōu)化程度。信息損失越小,數(shù)據(jù)精度越大,數(shù)據(jù)可用性越高。反之亦然。因此,在進(jìn)行匿名化操作過程中,應(yīng)盡量降低匿名代價(jià)。
本文采用基于泛化層級(jí)的方法度量匿名代價(jià),而使用該方式度量匿名代價(jià),則需要構(gòu)建屬性的域泛化層級(jí)。處于域泛化層級(jí)中每一層包含的信息量是不同的。通常,對于同一屬性來說,處于泛化高層的數(shù)據(jù)比處于低層級(jí)數(shù)據(jù)所包含的信息量較少。計(jì)算公式如下:

其中,Prec表示數(shù)據(jù)精度,為原始數(shù)據(jù)表;RT為泛化后的數(shù)據(jù)表;N表示數(shù)據(jù)表中屬性個(gè)數(shù);NA為數(shù)據(jù)集的記錄數(shù);|DGHAi|為屬性Ai泛化層級(jí)結(jié)構(gòu)的高度;h表示屬性Ai在泛化層級(jí)結(jié)構(gòu)中處于的高度。
定義4域泛化層級(jí)(domain generalization hierar-chy):設(shè)A為數(shù)據(jù)表T的屬性,存在函數(shù)fh:h=0,1,…,n-1,使得,并且A=A0,|An|=1,那么屬性A在fh:h=0,1,…,n-1上的泛化域?qū)蛹?jí)可表示為,記作 |DGHA|。
{Z0,Z1,Z2,Z3}展示的是Zip屬性自下而上的泛化過程,每一層表示該屬性的一個(gè)泛化域。隨著DGH一直往上,屬性的泛化程度越來越高,直到最后達(dá)到抑制的狀態(tài),泛化過程描述如下:

5 實(shí)驗(yàn)結(jié)果及分析
本實(shí)驗(yàn)采用文獻(xiàn)[14]提出的Incognito算法完成匿名操作過程。Incognito算法的基本思想是采用全局重編碼技術(shù),按照自底向上的寬度優(yōu)先方式對原始數(shù)據(jù)集執(zhí)行泛化操作,同時(shí)對泛化圖(generalization graph)進(jìn)行必要的剪枝、迭代操作,使原始數(shù)據(jù)集逐步優(yōu)化,從而達(dá)到匿名效果。本文方案主要考慮算法執(zhí)行時(shí)間與數(shù)據(jù)表的信息損失。
5.1 實(shí)驗(yàn)數(shù)據(jù)與實(shí)驗(yàn)環(huán)境
實(shí)驗(yàn)所采用的數(shù)據(jù)集為UCI中的Adult數(shù)據(jù)庫[15],該數(shù)據(jù)庫是用于k-匿名研究最常用的數(shù)據(jù)源。該數(shù)據(jù)庫共有32 206條數(shù)據(jù),大小為5.5 MB,數(shù)據(jù)集共含有15個(gè)屬性。選取其中的8個(gè)屬性作為準(zhǔn)標(biāo)識(shí)符的屬性集,選取Disease屬性作為敏感屬性。表5描述了實(shí)驗(yàn)數(shù)據(jù)集的結(jié)構(gòu)。
實(shí)驗(yàn)采用MySQL 5.5存儲(chǔ)數(shù)據(jù);算法用Java語言實(shí)現(xiàn);實(shí)驗(yàn)運(yùn)行環(huán)境是CPU為3.3 GHz Intel?Core i5處理器,4 GB RAM。
選取Disease作為實(shí)驗(yàn)敏感屬性。Disease屬性含10個(gè)值,隨機(jī)產(chǎn)生疾病種類,用敏感權(quán)重來衡量敏感度,值越大,說明敏感度越高,見表6。實(shí)驗(yàn)中將敏感權(quán)重低于0.5的疾病設(shè)為弱敏感屬性。

Table 5 Structure of adult data set表5 Adult數(shù)據(jù)集結(jié)構(gòu)

Table 6 Weight of disease表6 Disease權(quán)重
5.2 時(shí)間復(fù)雜度分析
本文方案首先需要計(jì)算強(qiáng)敏感值|SV|和弱敏感值|DV|的個(gè)性化信息熵l-多樣性×,因此計(jì)算開銷是線性的,時(shí)間復(fù)雜度為O(n)。其次需要對信息損失度量進(jìn)行計(jì)算,,計(jì)算過程中有兩次和的累乘運(yùn)算,因此在該階段的計(jì)算開銷為O(n2)。最后需要對屬性進(jìn)行域泛化層級(jí)處理,每次泛化的計(jì)算開銷為線性的,因此計(jì)算復(fù)雜度為O(n)。
5.3 執(zhí)行時(shí)間分析
從圖1可知,隨著QI個(gè)數(shù)增加,3種模型的執(zhí)行時(shí)間都會(huì)增加。這是因?yàn)殡S著QI值增大,等價(jià)類中要求記錄更多的準(zhǔn)標(biāo)識(shí)符屬性,這就需要更多的泛化次數(shù),這個(gè)過程也就需要算法執(zhí)行更多次的循環(huán),所以執(zhí)行時(shí)間會(huì)增大。
同時(shí),可以看到,隨著QI值增大,本文方案相比較信息熵l-多樣性模型執(zhí)行時(shí)間更短一些。這是因?yàn)樾畔㈧豯-多樣性模型判斷等價(jià)類中強(qiáng)敏感屬性和弱敏感屬性需要更長的時(shí)間。
圖2描述的是QI記錄數(shù)目從0到1 000遞增時(shí),3種匿名模型中數(shù)據(jù)精度隨k或l值的變化。橫坐標(biāo)為記錄個(gè)數(shù),縱坐標(biāo)是執(zhí)行不同算法的時(shí)間,可以看到本文方案在提高數(shù)據(jù)精度的同時(shí),減少了算法的執(zhí)行時(shí)間。

Fig.1 Comparison of execution time with the number of quasi identifiers圖1 準(zhǔn)標(biāo)識(shí)符個(gè)數(shù)變化執(zhí)行時(shí)間比較

Fig.2 Comparison of execution time with the number of records圖2 記錄個(gè)數(shù)變化執(zhí)行時(shí)間比較
5.4 精確度分析
圖3 描述的是QI記錄數(shù)目從1 000到3 500遞增時(shí),3種匿名模型中數(shù)據(jù)精度隨k或l值的變化。橫坐標(biāo)為記錄個(gè)數(shù),縱坐標(biāo)是匿名數(shù)據(jù)集的數(shù)據(jù)精度,可以發(fā)現(xiàn)隨著記錄個(gè)數(shù)的增加,本文方案的精度高于其他方案。
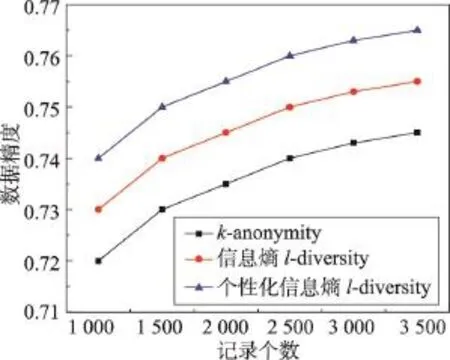
Fig.3 Comparison of data accuracy with the number of records圖3 記錄個(gè)數(shù)變化數(shù)據(jù)精度比較
5.5 信息損失分析
圖4 描述的是QI個(gè)數(shù)為0~8時(shí),3種匿名模型中數(shù)據(jù)精度隨k或l值的變化。橫坐標(biāo)為k、l值,縱坐標(biāo)是匿名數(shù)據(jù)集的數(shù)據(jù)精度。

Fig.4 Comparison of data accuracy withk,lvalue圖4 數(shù)據(jù)精度隨k、l值比較
從圖4可知,隨著k、l值的增加,數(shù)據(jù)精度呈下降趨勢。這是因?yàn)殡S著k、l值的增大,等價(jià)類中需要泛化的元組數(shù)也就越多,泛化層級(jí)越高,信息損失也越大,從而數(shù)據(jù)精度就會(huì)降低。同等情況下,個(gè)性化信息熵l-多樣性的信息損失高于信息熵l-多樣性。這是因?yàn)閭€(gè)性化信息熵l-多樣性對匿名約束性強(qiáng)于信息熵l-多樣性,需要對準(zhǔn)標(biāo)識(shí)符進(jìn)行更高層級(jí)的泛化,所以信息損失相對多一些。
6 結(jié)束語
針對信息熵l-多樣性模型中沒有區(qū)分強(qiáng)弱敏感屬性的問題,本文提出了個(gè)性化信息熵l-多樣性模型并進(jìn)行實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明,本文方案在執(zhí)行時(shí)間和數(shù)據(jù)精度方面的表現(xiàn)優(yōu)于信息熵l-多樣性模型與k-匿名模型,且有更好的隱私性,可以運(yùn)用到移動(dòng)醫(yī)療系統(tǒng)中來保護(hù)醫(yī)療用戶的隱私數(shù)據(jù)不被泄漏。
[1]Gong Qiyuan,Yang Min,Luo Junzhou.Data anonymization approach for incomplete microdata[J].Journal of Software,2013,24(12):2883-2896.
[2]Janpuangtong S,Shell D A.Helping novices avoid the hazards of data:leveraging ontologies to improve model generalization automatically with online data sources[J].AI Magazine,2016,37(2):19-32.
[3]Komishani E G,Abadi M,Deldar F.PPTD:preserving personalized privacy in trajectory data publishing by sensitive attribute generalization and trajectory local suppression[J].Knowledge-Based Systems,2016,94:43-59.
[4]Vu K,Zheng Rong,Gao Jie.Efficient algorithms forkanonymous location privacy in participatory sensing[C]//Proceedings of the 31st Annual IEEE International Conference on Computer Communications,Orlando,Mar 25-30,2012.Piscataway:IEEE,2012:2399-2407.
[5]LeFevre K,DeWitt D J,Ramakrishnan R.Incognito:efficient full-domaink-anonymity[C]//Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data,Baltimore,Jun 14-16,2005.New York:ACM,2005:49-60.
[6]Rebollo-Monedero D,Forné J,Soriano M,et al.k-anonymous microaggregation with preservation of statistical dependence[J].Information Sciences,2016,342:1-23.
[7]Xin Tingting,Liu Guohua.Top-kqueries underK-anonymity privacy protection model[J].Journal of Frontiers of Computer Science and Technology,2011,5(8):751-759.
[8]Wang Danli,Liu Guohua,Song Jinling,et al.Problem of finding the optimal value on quasi-identifier fork-anonymity model[J].Journal of Frontiers of Computer Science and Technology,2010,4(11):1010-1018.
[9]Dai Jiazhu,Hua Liang.Method of anonymous area generation for sensitive location protection under road networks[J].Computer Science,2016,43(3):137-144.
[10]S?derstr?m-Anttila V,Miettinen A,Rotkirch A,et al.Shortand long-term health consequences and current satisfaction levels for altruistic anonymous,identity-release and known oocyte donors[J].Human Reproduction,2016,31(3):597-606.
[11]Moja L,Friz H P,Capobussi M,et al.Implementing an evidence-based computerized decision support system to improve patient care in a general hospital:the CODES study protocol for a randomized controlled trial[J].Implementation Science,2016,11(1):89.
[12]Fields L,Arntzen E,Nartey R K,et al.Effects of a meaningful,a discriminative,and a meaningless stimulus on equivalence class formation[J].Journal of the Experimental Analysis of Behavior,2012,97(2):163-181.
[13]Zhou Changli,Ma Chunguang,Yang Songtao.Research of LBS privacy preserving based on sensitive location diversity[J].Journal on Communications,2015,36(4):125-136.
[14]Zhang Xiaojian,Meng Xiaofeng.Differential privacy in data publication and analysis[J].Chinese Journal of Computers,2014,37(4):927-949.
[15]Blake E K C,Merz C J.UCI repository of machine learning databases[EB/OL].(1998).http://www.ics.uci.edu/~mlearn/MLRepository.html.
附中文參考文獻(xiàn):
[1]龔奇源,楊明,羅軍舟.面向缺失數(shù)據(jù)的數(shù)據(jù)匿名方法[J].軟件學(xué)報(bào),2013,24(12):2883-2896.
[7]辛婷婷,劉國華.K-匿名隱私保護(hù)模型下的Top-k查詢[J].計(jì)算機(jī)科學(xué)與探索,2011,5(8):751-759.
[8]王丹麗,劉國華,宋金玲,等.k-匿名模型中準(zhǔn)標(biāo)識(shí)符最佳值的求解問題[J].計(jì)算機(jī)科學(xué)與探索,2010,4(11):1010-1018.
[9]戴佳筑,華亮.路網(wǎng)環(huán)境下敏感位置匿名區(qū)域的生成方法[J].計(jì)算機(jī)科學(xué),2016,43(3):137-144.
[13]周長利,馬春光,楊松濤.基于敏感位置多樣性的LBS位置隱私保護(hù)方法研究[J].通信學(xué)報(bào),2015,36(4):125-136.
[14]張嘯劍,孟小峰.面向數(shù)據(jù)發(fā)布和分析的差分隱私保護(hù)[J].計(jì)算機(jī)學(xué)報(bào),2014,37(4):927-949.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中外會(huì)展(2014年4期)2014-11-27 07:46:46
中學(xué)數(shù)學(xué)雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
