Angel: 一種面向高維度的機器學習框架
2018-05-08 13:20:44張維潘濤范震坤
電子技術與軟件工程 2018年22期
張維 潘濤 范震坤
摘要 隨著互聯網技術的發展,各種數據的數據量也在不斷增長,大數據成為各行業的重要發展方向之一,如何有效地利用大數據技術,對社會中的各行各業都具有產生巨大推動力的作用。分布式機器學習是隨著“大數據”概念興起的。目前,由于分布式的機器學習算法具有復雜性、多樣性以及高維性這樣的特點,導致我們從數據中挖掘內在規律比較困難,小型的機器學習算法框架在處理這樣的問題上就顯得捉襟見肘了。因此,研究適用于大數據背景下的機器學習算法框架成為當下的熱點。本文介紹一種面向高維度的機器學習計算框架稱為Angel。
【關鍵詞】大數據 分布式計算 機器學習
機器學習也就是通過設計一些能夠讓計算機自主地去“學習”的一類算法,它們能夠通過分析已有的數據,去獲得隱藏在這些信息內部的規律,并利用這些規律去對未知的數據進行預測以及分析。隨著互聯網的高速發展,海量數據的產生以及工業界對于計算速度和計算成本要求的提升,傳統的計算機已經很難滿足工業界的需求,因此分布式計算技術就應運而生了。分布式計算也即為“并行計算”,其核心思想就是把一個需要巨大計算能力才能解決的計算任務拆解成多許多小的子任務,將這些子任務分配到多個處理器節點上做計算,最后匯總這些計算結果得到最終的結果。分布式計算或者分布式機器學習除了要把計算任務分配到多個處理器上,更重要的是把計算所需要的各種數據(包括訓練數據以及中間結果)分布開來。隨著谷歌的Map Reduce編程模型和開源的Hadoop分布式計算框架的發布,分布式計算技術逐漸開始普及,并且還呈現出不斷發展和完善的趨勢。隨著工業界對于大數據進行分析和挖掘的需求不斷提升,分布式計算和機器學習的結合也就自然而然地成為了學術界和工業界研究的一個重點。目前,基于分布式計算平臺的機器學習框架主要有基于Hadoop平臺的Mahout、基于Spark平臺的MLlib以及由騰訊主導開發的機器學習框架Angel等。本文重點介紹一種稱為Angel的面向高維度的機器學習計算框架。
1 Angel框架
為能夠支持超大維度的機器學習模型運算,騰訊公司與香港科技大學展開了合作,開發出了面向機器學習的分布式計算框架一一Angel l.0。Angel是使用Java語言開發的面向機器學習算法的計算系統框架,用戶可以不改變使用習慣,就像使用Spark以及MapReduce一樣,來去完成機器學習算法的模型訓練。Angel目前已經能夠非常好地支持梯度下降算法、交替乘子法等優化算法,同時Angel也提供了一些常用的模型;如果用戶還有其他的自定義需求,也可以在框架中提供的現有的最優化算法上快速方便地去封裝自己的模型。Angel在高維度機器學習的各種參數更新過程中,對于不同的計算任務,根據其計算速度有針對性地給那些較慢的計算任務的參數傳遞提供更多的計算資源,從而能夠在整體上大大縮短機器學習算法的運算時間。這一創新的優化調度算法則是源于香港科技大學陳凱教授及其研究小組開發的可感知上層應用的網絡優化方案,以及楊強教授領導的針對大規模機器學習算法的研究方案。此外,北京大學的崔斌教授及其學生也參與了Angel項目的共同研發,并提供了巨大的幫助。在測試實驗以及實際的生產工作任務中,Angel能夠在千萬級到億級的特征緯度條件下運行梯度下降算法,并且它的性能能夠達到Spark的數倍到數十倍。
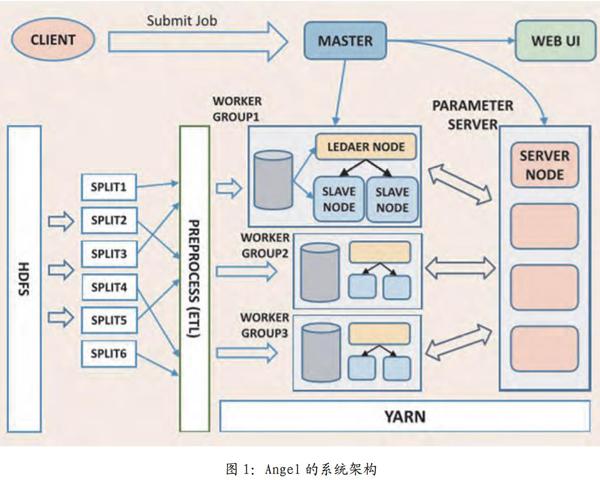
如圖l所示,Angel的整體架構主要參考了由谷歌公司研發的DistBelief框架。為深度學習而設計研發的DistBeilef框架使用了參數服務器,從而解決那些深度學習中巨大模型在訓練時海量參數的更新問題。由于基于大數據的機器學習算法同樣擁有海量的參數,所以這樣參數服務器也就不僅僅局限于深度學習算法,同樣可用于基于大數據的機器學習算法中的模型了。比如在梯度下降算法、交替乘子法以及擬牛頓法等優化算法的計算過程中面臨著每一輪迭代需要對上億個參數進行更新,這就需要使用參數服務器來將參數分布式緩存以提高算法的性能。Angel框架在運算過程中支持批量同步并行、全異步并行、延遲同步并行這三種計算并行計算,其中卡耐基梅隆大學的邢波教授在Petuum項目中曾經驗證了延遲同步并行計算模型,它能夠在機器學習的這種特定運算場景下提升算法的收斂速度,從而提高系統的性能。系統有五個角色:
主控節點:負責資源申請和分配,以及任務的管理。
執行節點:負責任務的執行,以線程的形式存在。
計算節點:獨立進程運行于Yam的容器中,是執行節點的執行容器。
參數服務器:伴隨著一個任務的啟動而生成,任務結束而銷毀,負責在算法的訓練過程中的更新和存儲各種參數。
計算節點組:它是一個虛擬的概念,由若干個計算節點組成,元數據由主控節點維護。為模型的并行拓展考慮,在同一個計算節點組內所有計算節點所運行的訓練數據都是一樣的。雖然在Angel已經提供了一些通用的模型,但并不能滿足所有用戶的需求,而用戶自定義的模型也可以實現Angel的通用接口,形式上等同于MapReduce或Spark。
1.1 友好的用戶交互邏輯
1.1.1 自動化數據切分
Angel系統為用戶提供了自動切分訓練數據的功能,方便用戶進行數據并行運算:系統默認兼容了Hadoop FS接口,原始訓練樣本存儲在支持Hadoop FS接口的分布式文件系統如HDFS。
1.1.2 豐富的數據管理
訓練的樣本數據存儲在分布式的文件系統中,該系統在計算前將樣本數據從文件系統讀取到計算進程中,緩存在內存里以加速迭代運算;如果內存中緩存不下,則將這部分數據暫存到本地磁盤內,并且不需要向分布式文件系統再次發起通訊請求。
1.1.3 豐富的線性代數以及優化算法庫
Angel更提供了能夠高效計算向量及矩陣的運算庫,能夠方便用戶自由地去選擇數據和參數的表達形式。在優化算法方面,Angel已實現了梯度下降法、交替乘子法;而在模型選擇方面,支持了文檔主題生成模型、矩陣分解模型、邏輯回歸模型以及支持向量機等。
1.1.4 可選擇的計算模型
綜述中我們提到了,Angel的參數服務器可以支持批量同步并行、全異步并行、延遲同步并行計算模型。
1.1.5 更細粒度的容錯
在系統中容錯主要分為主控節點的容錯,參數服務器的容錯,計算節點進程內的參數的緩存以及遠程過程調用的容錯。
1.1.6 友好的任務運行及監控
Angel也具有友好的任務運行方式,支持基于Yam的任務運行模式,同時,Angel的Web頁面也可以方便用戶查看集群計算的進度。
1.2 內存優化
在運算過程中為減少對于內存的消耗以及提升單次運算的運算收斂性使用了異步無鎖的Hogwildl模式。它允許在多個CPU上并行執行梯度下降的參數更新。因為多個CPU之間不可能重寫有用的信息,因此處理器可以訪問共享的內存。在大多數情況下,這樣的更新策略可以達到一個非常優秀的收斂速率。同一個運算進程中的N個執行節點如果在運算中都能夠各自保持一個獨立的參數快照,那么對參數的內存開銷就減少了N倍,在訓練模型參數維度越大時消耗減少的就越明顯。在梯度下降的優化算法中,訓練數據絕大多數情況下是稀疏的,因此參數更新沖突的概率就大大降低了,即便沖突了也都是朝著梯度下降的方向更新的,從而總能達到收斂。在實際的使用中,讓多個執行節點在一個進程內共享同一個參數快照,這樣能夠明顯減少內存的消耗并且提升收斂速度。
1.3 網絡優化
(l)進程內的執行節點運算之后的參數,更新合并之后推送到參數服務器更新,這樣大大減少了執行節點所在機器的上行所需要的消耗,同樣的也減少了參數服務器的下行消耗,同時減少在推送更新的過程中的峰值傳輸瓶頸的次數。
(2)通過更深一步的網絡優化解決延遲同步并行的問題:由于延遲同步并行是一種半同步的運算調度機制,能夠在有限的窗口訓練參數,當運算快的節點達到窗口邊緣時,任務就必須要停下來等待最慢的節點去更新最新的參數。面對這樣的問題,我們通過網絡流量的再分配來加速較慢的工作節點。我們分配給較慢的節點更高的帶寬;那么比較快的工作節點就分配更少的帶寬。這樣快的節點與慢的節點之間迭代次數的差距就可以進行有效的控制,減少了發生等待的概率,也就是減少了工作節點由于延遲同步并行窗口而空閑等待時間。
2 總結
大數據,機器學習作為當下的熱門,需要有一套科學合理的算法框架來滿足社會需求,讓數據處理變得更具效率。針對大數據的各個特點,通過運用分布式計算讓數據變得更具條理,更加易于計算,數據處理分析難度得到有效降低,大大提高機器學習的能力。本文介紹的這三種基于大數據的機器學習分布式計算框架各有優缺點,都是為了去滿足大數據以及機器學習對于工業界生產的需求。只有不斷去發展我們的算法框架,滿足不斷提高的需求,才能讓其在大數據時代進發出強勁活力。
參考文獻
[1] Dean J,
Ghemawa t S.
MapReduce:simplified data processing on largeclusters [J] .
Communications of- theACM, 2008, 51 (01) : 107-113.
[2] Shvachko K, Kuang H, Radia S, etal. The hadoop distributed filesystem [Cl//Mass storage systems andtechnologies
(MSST) ,
2010 IEEE 26thsymposium on. Ieee, 2010: 1-10.
[3] AsseFi M. Behravesh E, Liu G. etal. Big data machine learning usingapache spark MLlib [C] //Big Data(Big Data) ,
2017 IEEE InternationalConference on. IEEE, 2017: 3492-3498.
[4] Jiang J, Yu L, Jiang J, et al.Angel: a new large-scale machinelearning system[Jl. National ScienceReview, 2017, 5 (2) : 216-236.
[5] Khumoyun A, Cui Y. Hanku L.Spark based distributed deeplearning framework for big dataapplica tions [C] //Informa tion Scienceand Communications Technologies(ICISCT) ,
Interna tional
Conferenceon. IEEE, 2016: 1-5.
[6] Xing E P, Ho Q, Dai W, et al.Petuum: A new platform fordistributed machine learning on bigdata [J] . IEEE Transactions on BigData, 2015, 1 (2) : 49-67.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科學與財富(2016年28期)2016-10-14 21:19:17
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
