知識圖譜補全算法綜述
2018-05-03 10:01:43丁建輝賈維嘉
信息通信技術 2018年1期
丁建輝 賈維嘉
上海交通大學計算機科學與工程系上海200240
引言
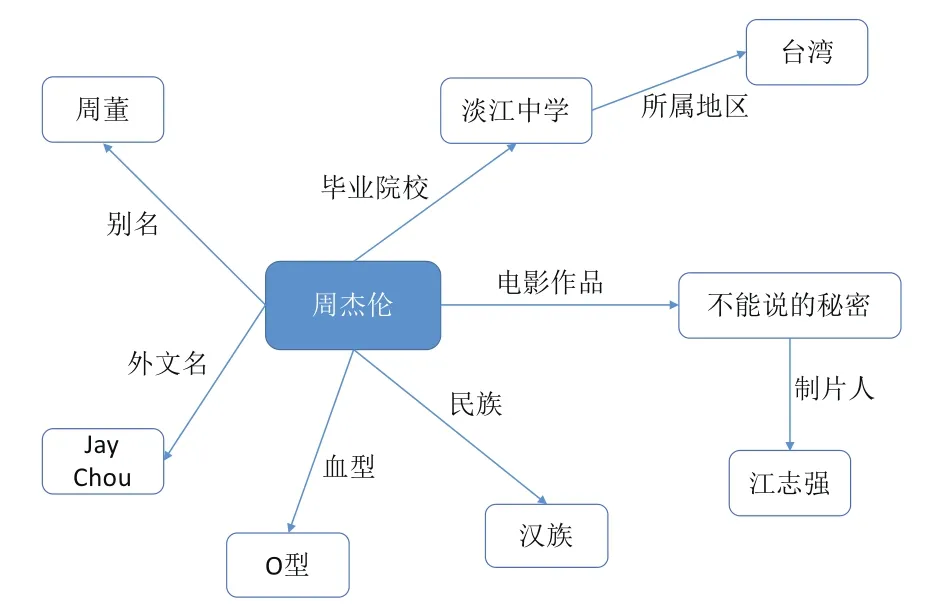
圖1 周杰倫的知識圖譜
知識圖譜這個概念最早由Google在2012年提出,Google認為“things,not strings”,即對于搜索引擎,世界中的各種物體不應該僅僅是strings,而是具有實際含義的things,例如“蘋果”這個詞,既可以代表美國的蘋果公司,也可以代表一種水果。借助知識圖譜,Google的搜索引擎實現了從strings到things的變化,使得機器能更好地理解用戶搜索詞所代表的具體含義。知識圖譜通常以高度結構化的形式表示,描述了現實世界中各種實體之間的關系[1],圖1展示了歌手周杰倫的知識圖譜。目前,知識圖譜已經廣泛地應用于人工智能的多個領域,例如自動問答、搜索引擎、信息抽取等。典型的知識圖譜由大量結構化的三元組構成,例如(奧巴馬,國籍,美國),該三元組描述了“奧巴馬的國籍是美國”這件事實。
雖然知識圖譜能提供高質量的結構化數據,但是大部分開放知識圖譜,例如Freebase[2]、DBpedia[3]都是由人工或者半自動的方式構建,這些圖譜通常比較稀疏,大量實體之間隱含的關系沒有被充分地挖掘出來。在Freebase中,有71%的人沒有確切的出生日期,75%的人沒有國籍信息[4]。由于知識圖譜具有高質量的結構化數據,是很多人工智能應用的基石,因此,近期很多工作都在研究如何利用機器學習算法更好地表示知識圖譜,并以此為基礎進行知識圖譜補全,從而擴大知識圖譜的規模。本文借助知識圖譜補全這個任務,來介紹知識圖譜表示學習的研究進展。
1 知識圖譜補全簡介
知識圖譜補全的目的是預測出三元組中缺失的部分,從而使知識圖譜變得更加完整。對于知識圖譜G,假設G中含有實體集E={e1,e2,…,eM}(M為實體的數量)、關系集R={r1,r2,…,rN}(N為關系的數量)以及三元組集T={(ei,rk,ej)|ei、ej屬于E,rk屬于R}。由于知識圖譜G中實體和關系的數量通常是有限的,因此,可能存在一些實體和關系不在G中。記不在知識圖譜G中的實體集為E*={e1*,e2*,…,es*}(S為實體的數量),關系集為R*={r1*,r2*,…,rT*}(T為關系的數量)。
根據三元組中具體的預測對象,知識圖譜補全可以分成3個子任務:頭實體預測、尾實體預測以及關系預測。對于頭(尾)實體預測,需給定三元組的尾(頭)實體以及關系,然后預測可以組成正確三元組的實體,例如(姚明,國籍,?),(?,首都,北京)。對于關系預測,則是給定頭實體和尾實體,然后預測兩個實體之間可能存在的關系,例如(姚明,?,中國)。
根據三元組中實體和關系是否均屬于知識圖譜G,可以把知識圖譜補全分成兩類:1)靜態知識圖譜補全(Static KGC),涉及的實體entity∈E以及關系relation∈R,該場景的作用是補全已知實體之間的隱含關系;2)動態知識圖譜補全(Dynamic KGC),涉及不在知識圖譜G中的實體或關系(entity∈E*或者relation∈R*),該場景能夠建立知識圖譜與外界的關聯,從而擴大知識圖譜的實體集、關系集以及三元組集。
2 表示學習的相關理論
為了進行知識圖譜補全,首先得給知識圖譜中的實體和關系選擇合適的表示,即構建出合適的特征對實體和關系進行編碼。在機器學習中,特征構建通常有兩種方法:一種是手工構建,這種方法需要較多的人工干預,并且需要對所涉及的任務有深入的了解,才可能構建出較好的特征。對于較為簡單的任務,該方法是可行的,但對于較為復雜的任務,構建出合適的特征可能需要耗費大量的人力物力。另一種方法是表示學習,該方法需要較少的人工干預,直接通過機器學習算法自動地從數據中學得新的表示,能夠根據具體的任務學習到合適的特征。表示學習其實是一個比較廣泛的概念,機器學習中不少算法都屬于某種形式的表示學習,例如目前人工智能領域的研究熱點——深度學習,就是一類常見的表示學習算法。隨著硬件的升級以及大數據時代的到來,深度學習在很多領域(圖像識別、語音識別、機器翻譯等)都擊敗了傳統的機器學習算法,例如經典的多層感知機算法、基于統計學的方法等。但是深度學習也不是萬能的,基于深度學習的模型通常擁有大量的參數,加大模型容量的同時也引入了過擬合的風險;因此,為了增強模型的泛化能力,基于深度學習的模型通常需要在大規模數據集上進行訓練。此外,深度學習比較適用于原始特征是連續的且處于比較低層次的領域,例如語音識別、圖像識別,深度學習能基于低層次的特征構造出適合任務的高層次語義特征,從而產生較大的突破。而對于自然語言處理領域,語言相關的特征通常已經處于高層次,例如語法結構、依存關系等特征。此外,語言的特征通常是離散的,并且存在多義性;因此,深度學習在該領域的突破相對要小一點。
手工構建和表示學習這兩種方法各有利弊,前者雖然需要較多的人工干預,但是構建出的特征通常具有較好的可解釋性,有利于研究人員對模型起作用的原因以及任務的本質有更深入的認識。例如計算機視覺領域著名的HOG特征、SIFT特征,其背后就有嚴謹的數學原理。表示學習雖然在較少的人工干預下能自動地根據任務構建特征,但構建出的特征的可解釋性通常比較差,例如現在應用十分廣泛的卷積神經網絡(CNN),雖然在很多領域都取得了突破性的成果,但是學術界目前也還沒從數學角度嚴謹地證明CNN能起作用的本質原因。最近的一種研究趨勢是把這兩種構建方式結合起來,將手工構建的特征作為先驗知識去指導或者優化表示學習算法進行特征的學習,這種做法在不少任務上取得了較好的效果。例如在知識圖譜補全這個任務上,不少工作就利用了規則、實體類型、多跳路徑等信息構造出高質量的先驗知識,并將這些先驗知識融合到表示學習上。
接下來,本文將分別介紹Static KGC以及Dynamic KGC這兩類場景的相關工作。由于不少綜述性文章[1]都已經介紹過Static KGC場景的很多工作,因此本文重點介紹能解決Dynamic KGC的工作。
3 知識圖譜表示學習
3.1 靜態知識圖譜補全——Static KGC
知識圖譜可以看成是一個有向圖,實體是結點,而有向邊則代表了具體的關系。對于Static KGC場景,其實就是給知識圖譜中不同的結點尋找潛在的有向邊(關系)。早期的不少工作都屬于基于圖的表示學習方法,這些方法在小規模的知識圖譜上表現良好。然而,隨著知識圖譜規模的擴大,數據稀疏問題會加重,算法的效率也會降低。為了能適應大規模Static KGC,人們陸續提出多種基于知識圖譜結構特征(三元組)的表示學習算法,這些算法將知識圖譜中的實體和關系嵌入到低維稠密空間[1],然后在這個空間計算實體和關系的關聯,從而進行Static KGC。
最經典的工作是Bordes等人于2013年提出的翻譯模型——TransE[5],如圖2所示,該模型認為正確的三元組(h,r,t)(h代表頭實體的向量,r代表關系的向量,t代表尾實體的向量) 需滿足 h + r ≈t,即尾實體是頭實體通過關系平移(翻譯)得到的。TransE不僅簡單高效,而且還具有較好的擴展性。然而,通過深入分析可以得知,TransE不適合對復雜關系進行建模。例如“性別”這類“N-1”(多對一)型關系,如圖3所示,當訓練數據中含有三元組(張三,性別,男)以及(李四,性別,男)時,經過TransE訓練后,張三和李四這兩個實體的向量可能會比較接近。然而張三和李四在其他方面可能存在差異,例如年齡、籍貫等屬性,而TransE無法對這些信息進行有效地區分,導致TransE在復雜關系上的表現比較差。
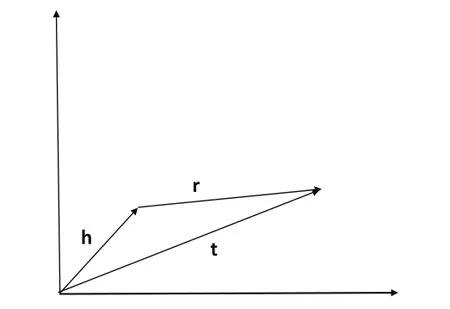
圖2 TransE的基本思想
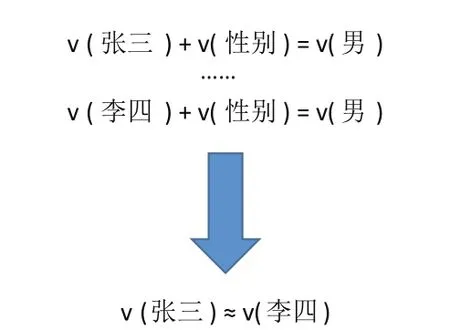
圖3 TransE的復雜關系建模
為了能在復雜關系下有較好的表現,不少工作考慮實體在不同關系下應該擁有不同的向量。其中,文獻[6]設計了TransH模型,該模型將實體投影到由關系構成的超平面上。文獻[7]提出TransR模型,該模型則認為實體和關系存在語義差異,它們應該在不同的語義空間。此外,不同的關系應該構成不同的語義空間,因此TransR通過關系投影矩陣,將實體空間轉換到相應的關系空間。文獻[8]沿用了TransR的思想,提出了TransD模型,該模型認為頭尾實體的屬性通常有比較大的差異,因此它們應該擁有不同的關系投影矩陣。此外,考慮矩陣運算比較耗時,TransD將矩陣乘法改成了向量乘法,從而提升了運算速度。文獻[9]基于實體描述的主題分布來構造實體的語義向量,并且將實體的結構向量投影到對應的語義向量上,從而增強了模型的辨別能力。文獻[10]考慮了實體多語義的性質,認為實體應該擁有多個語義向量,而語義向量則是根據實體所處的語境動態生成的。此外,文獻[10]通過實體類型構造了關系的類型信息,并將實體與關系、實體與實體之間的相似度作為先驗知識融合到表示學習算法中。此外,還有不少工作將規則、路徑等信息融入到表示學習中。這些工作通過更加細致的建模以及引入先驗知識,在靜態知識圖譜補全任務上取得了一定的提升。值得一提的是,文獻[11]設計了一個基于共享memory的網絡架構IRNs(Implicitly ReasonNets),在向量空間中進行了多跳推理,該模型在復雜關系上取得了目前最好的結果。
3.2 動態知識圖譜補全—Dynamic KGC
前面的表示學習算法均屬于“離線”算法,它們有一個共同的局限性,只能在訓練過程中得到實體以及關系的向量。當實體或關系不在訓練集中時,就無法獲得它們的向量。然而,為了維持知識圖譜的可靠性以及擴大它的規模,我們通常需要對知識圖譜中的數據進行“增”、“刪”、“改”操作。對于“離線”算法,一旦知識圖譜中的數據發生變化,就得重新訓練所有實體以及關系的向量,擴展性較差并且耗時耗力。
對于大規模開放知識圖譜,例如Freebase、DBPedia,隨著時間的變化,它們所含有的事實類三元組可能會發生改變。例如2007年和2017年的美國總統不是同一個人,顯而易見,(奧巴馬,總統,美國) 這個三元組在2017年就是錯誤的。為了維持知識圖譜的可靠性,我們需要不定期地對知識圖譜中與時間相關的事實類三元組進行更新。文獻[12]考慮了知識圖譜中三元組的時間有效性,并提出了一個時間敏感型(timeaware)知識圖譜補全模型——TAE,該模型融合了事實的時序信息,將三元組擴展成四元組——(頭實體,關系,尾實體,時間)。其中,時間信息能夠有效約束向量空間的幾何結構。
現有知識圖譜中實體和關系的數量通常是有限的。然而,大部分表示學習模型只能在知識圖譜中的實體和關系之間進行補全,因此這些模型無法自動地引入新實體或者新關系來擴大知識圖譜的規模。新實體和知識圖譜中的實體通常擁有豐富的額外信息,例如名稱、描述、類型等,這些信息從不同角度對實體進行了刻畫。為了能實現自動向知識圖譜中添加新實體的需求,不少方法結合了額外信息來獲得新實體的向量,從而建立新實體與現有知識圖譜的關聯。對于新關系,若有高質量的額外信息,同樣可以通過這些信息來建立相應的向量,從而實現關聯。
向知識圖譜中添加新實體或者新關系的場景其實可以抽象為遷移學習(Transfer Learning)中的零數據學習(Zero-Shot Learning)問題,知識圖譜中的實體和關系為源域(Source Domain),新實體和新關系為目標域(Target Domain)。實現遷移學習的基本前提是源域與目標域之間要存在相關性,即要共享相同或者類似的信息(例如特征),否則遷移效果就會比較差,甚至出現負遷移的情況。例如,對于實體的描述信息,若兩個域中實體的描述均是英文,由于兩個域之間可能共享一些相同或者相似的英文單詞,因此可以通過對描述信息建模從而實現遷移,遷移的效果取決于兩個域之間英文單詞的共享程度;若實體的描述信息不屬于同一種語言,例如源域中實體的描述是英文,而目標域中實體的描述是中文,兩個域之間共享的信息就非常少,直接進行遷移學習會非常困難;因此,為了能提高添加新實體或者新關系場景的準確率,需要尋找兩個域之間所共享的額外信息,然后結合源域中的三元組數據對這些額外信息進行建模,再將學習到的模型遷移到目標域中,得到目標域中實體的向量,從而實現動態知識圖譜補全。
在現實世界中,關系的數量一般遠少于實體的數量;因此,現有知識圖譜的不完整性主要來源于實體的缺失。為了提升知識圖譜的完整性,大部分工作主要研究如何準確地向知識圖譜中添加新實體,而添加新關系這個場景的相關工作目前還比較少。當向知識圖譜中添加新實體時,可以根據知識圖譜中的實體以及新實體所擁有的額外信息分成兩類場景。(1)新實體擁有豐富的文本信息,例如實體名稱、實體描述以及類型;(2)新實體與知識圖譜中的實體以及關系有顯性的三元組關聯,這些三元組通常被稱為輔助三元組。輔助三元組不會參與模型的訓練過程,它們的作用在于借助訓練好的模型推理出新實體的向量。
對于場景(1),相關工作主要通過建立實體與額外信息的映射關系來挖掘以及增強源域與目標域之間的關聯。例如,對于源域中的實體A,若它的描述中出現“人口總量”、“國土面積”等詞匯,說明實體A很有可能代表一個國家。根據實體與詞匯之間的映射關系,當實體B的描述中也出現這些詞匯時,表明實體B很有可能也是一個國家,那么實體B應該具備實體A的一些屬性。早期的模型主要通過將知識圖譜中的結構信息(實體、關系)與額外信息統一到同一個空間來建立兩者的關聯。
文獻[13]提出了首個聯合對齊模型L,該模型分為3個子模型:知識圖譜模型K、文本模型T以及對齊模型A。

知識圖譜模型K主要通過條件概率Pr(h|r,t)、Pr(r|h,t)、Pr(t|h,r)來獲得實體和關系的向量,其中E代表實體集,R代表關系集。
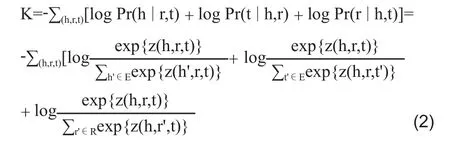
文本模型T借鑒了word2vec[14]的skip-gram算法,從而獲得額外信息(實體名稱以及維基百科anchors)的詞向量,其中V代表詞庫,
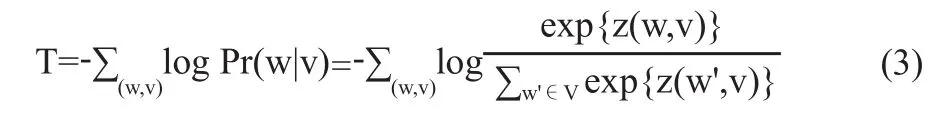
對齊模型A的作用是建立實體與其額外信息中詞語之間的映射,其中De代表實體e描述中的詞,z(e,w)=7-
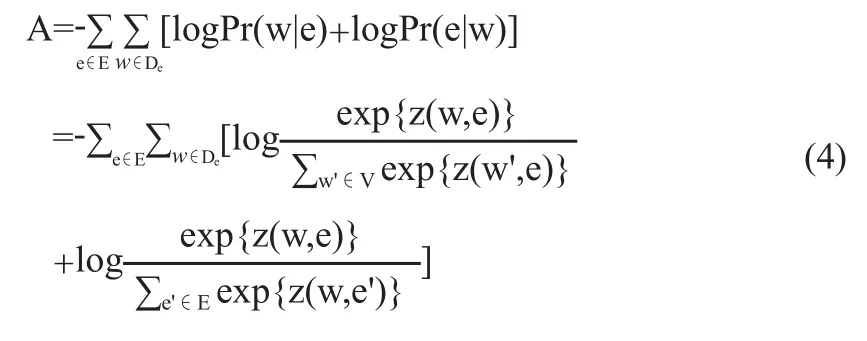
然而,這個對齊模型依賴于維基百科的anchors,因此應用范圍受到了限制。文獻[15]對它進行了改進,將額外信息替換成實體的描述信息。相比維基百科的anchors,實體的描述信息更加常見,因此能夠增大模型的應用范圍。
此外,不少工作利用神經網絡來獲得實體的向量。文獻[16]提出一種張量神經網絡,用實體名稱中所有詞的詞向量的平均作為該實體的向量,從而讓擁有類似名稱的實體能夠共享文本信息。文獻[17]使用了兩種表示學習方法,連續詞袋模型(CBOW)以及卷積神經網絡模型(CNN)來建立基于實體描述的語義向量。文獻[18]結合了知識圖譜的結構信息以及實體的描述信息,并提出了基于門機制(Gate-based)的聯合學習模型。此外,文獻[18]認為實體具有多語義,在不同場景(關系)下可能偏向于某一種語義,而語義則通過實體描述中的詞體現。因此,文獻[18]設計了一種注意力機制來計算實體描述中的詞在不同關系下的權重,使得實體在不同關系下擁有不同的語義向量。
對于場景(2),文獻[19]提出了一種基于圖神經網絡(Graph-NNs)的模型。該模型分為兩部分:傳播模型以及輸出模型。其中,傳播模型負責在圖中的節點之間傳播信息,而輸出模型則是根據具體任務定義了一個目標函數。對于知識圖譜補全任務,文獻[19]將圖譜中相鄰(頭/尾)實體的向量進行組合,從而形成最終的向量。對于輸出模型,本文使用了經典的翻譯模型—TransE。為了模擬場景(2),文獻[19]構造了3組測試集:僅三元組的頭實體是新實體,僅尾實體是新實體以及頭尾實體都是新實體。此外,給每個新實體設計了相應的輔助三元組(頭尾實體中僅含有一個新實體),用于獲得新實體的向量。
為了更好地構造知識圖譜,實現對數據進行“增”、“刪”的需求,文獻[20]提出一個新穎的在線(online)知識圖譜表示學習模型—puTransE (Parallel Universe TransE)。相比經典的翻譯模型,例如TransE、TransR,puTransE具有更好的魯棒性以及擴展性,并且對超參數不太敏感,具有更好的實用價值。puTransE利用分而治之的思想,通過生成多個向量空間,將語義或結構相似的三元組放在同一個空間中進行訓練。此外,每個空間中的超參數均是在給定范圍下隨機生成,因此,不需要進行大規模的超參數調優。在多個大規模數據集上的測試結果表明,puTransE在效率以及準確率上均優于翻譯模型。
4 結語
本文借助知識圖譜補全任務,將知識圖譜表示學習算法進行了大致梳理。早期的工作主要集中在靜態知識圖譜補全,以TransE為代表的翻譯模型在這個場景上獲得了較好的效果。然而,這些模型對超參數比較敏感,并且擴展性也比較差。在真實世界中,可能會不間斷地產生新實體以及新關系,翻譯模型無法滿足自動添加新實體以及新關系的需求,因此,大家逐漸把重心轉移到動態知識圖譜補全上,從而能自動地擴大知識圖譜的規模。相比Static KGC,Dynamic KGC能建立現有知識圖譜與外界的有效關聯,并且能對知識圖譜中的數據進行更新,具有更好的現實意義。因此,如何設計高效的在線學習算法來解決Dynamic KGC是目前一個較好的研究點。
[1]劉知遠,孫茂松,林衍凱,等.知識表示學習研究進展[J].計算機研究與發展,2016,53(2):247-261
[2]BOLLACKER K D,EVANS C,PARITOSH P,et al.:Freebase: a collaboratively created graph database for structuring human knowledge[C]//the ACM SIGMOD International Conference on Management of Data,SIGMOD 2008,Vancouver,BC,Canada,June 10-12,2008:1247-1250
[3]AUER S,BIZER C,KOBILAROV G,et al.DBpedia:A Nucleus for a Web of Open Data[C]//The Semantic Web,6th International Semantic Web Conference,2nd Asian Semantic Web Conference,ISWC 2007 + Aswc 2007,Busan,Korea,2007:722-735
[4]DONG X,GABRILOVICH E,HEITZ G,et al.Knowledge vault: a web-scale approach to probabilistic knowledge fusion[C]//In:The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,KDD '14,New York,2014:601-610
[5]BORDES A,USUNIER N.Translating embeddings for modeling multi-relational data[C]//Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013:2787-2795
[6]WANG Z,ZHANG J,FENG J,et al.Knowledge graph embedding by translating on hyperplanes[C]//the Twenty-Eighth AAAI Conference on Artificial Intelligence,Canada,2014:1112-1119
[7]LIN Y,LIU Z,SUN M,et al.Learning entity and relation embeddings for knowledge graph completion[C]//the Twenty-Ninth AAAI Conference on Artificial Intelligence,2015:2181-2187
[8]JI G,HE S,XU L,et al.Knowledge graph embedding via dynamic mapping matrix[C]//the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing,Beijing,China,2015:687-696
[9]XIAO H,HUANG M,MENG L,et al.SSP:Semantic space projection for knowledge graph embedding with text descriptions[C]//the Thirty-First AAAI Conference on Artificial Intelligence,San Francisco,California,U SA,2017:3104-3110
[10]MA S,DING J,JIA W,et al.Transt:Type-based multiple embedding representations for knowledge graph completion[C]//Machine Learning and Knowledge Discovery in Databases-European Conference,ECMLPKDD 2017:717-733
[11]SHEN Y,HUANG P,CHANG M,et al.Modeling largescale structured relationships with shared memory for knowledge base completion[C]//the 2nd Workshop on Representation Learning for NLP,Rep4NLP@ACL 2017:57-68
[12]JIANG T,LIU T,GE T,et al.Towards time-aware knowledge graph completion[C]//COLING 2016,26th International Conference on Computational Linguistics,Jap an.2016:1715-1724
[13]WANG Z,ZHANG J,FENG J,et al.Knowledge graph and text jointly embedding[C]//the 2014 Conference on Empirical Methods in Natural Language Processing,2014:1591-1601
[14]Tomas Mikolov,Kai Chen,Greg Corrado,et al.Efficient estimation of word representations in vector space[EB/OL].[2018-02-06].https://www.researchgate.net/publication/234131319_Efficient_Estimation_of_Word_Representations_in_Vector_Space
[15]ZHONG H,ZHANG J,WANG Z,et al.Aligning knowledge and text embeddings by entity descriptions[C]//the 2015 Conference on Empirical Methods in Natural Language Processing,2015:267-272
[16]SOCHER R,CHEN D,MANNING C D,et al.Reasoning with neural tensor networks for knowledge base completion[C]//Advances in Neural Information Processing Systems 26:27th Annual Conference on Neural Information Processing Systems,2013:926-934
[17]XIE R,LIU Z,JIA J,et al.Representation learning of knowledge graphs with entity descriptions[C]//the Thirtieth AAAI Conference on Artificial Intelligence,2016:2659-2665
[18]XU J,QIU X,CHEN K,et al.Knowledge graph representation with jointly structural and textual encoding[C]//the Twenty-Sixth International Joint Conference on Artificial Intelligence,2017:1318-1324
[19]HAMAGUCHI T,OIWA H,SHIMBO M,et al.Knowledge transfer for out-of-knowledge-base entities: A graph neural network approach[C]//the Twenty-Sixth International Joint Conference on Artificial Intelligence,2017:1802-1808
[20]TAY Y,LUU A T,HUI S C.Non-parametric estimation of multiple embeddings for link prediction on dynamic knowledge graphs[C]//The Thirty-First AAAI Conference on Artificial Intelligence,2017:1243-1249
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
