城市住宅價格指數編制方法探討
2018-04-26 01:48:34祁煒
統計與決策 2018年7期
祁 煒
(北京師范大學 地理科學學部,北京 100875)
0 引言
住宅的異質性問題是房價指數編制中需要面對的重要問題。構成不同住宅價格的各個特征,如位置、樓層、朝向、小區環境、所在區域的交通狀況、教育資源等,因缺乏統一的價格標準,無法直接進行比較,需要客觀準確的方法對住宅價格進行合理評估。特征價格法較好地克服了市場比較法等傳統方法中存在的問題,有較好的評估效果。國際上從20世紀80年代已經在房地產價格評估中采用這一方法,我國仍處于理論研究和實踐的探索階段。
本文以非線性Hedonic模型為基本模型。在影響住宅價格的各種因素中廣泛地選擇特征變量,進行顯著性檢驗,通過顯著性檢驗的特征作為特征價格模型的自變量保留,建立房價與特征變量之間的關系。選取足夠的樣本,運用傳統的參數回歸方法進行回歸分析,檢驗模型的解釋能力。通過對線性、半對數、對數等形式特征價格模型的對比分析,選取擬合度較好的模型,并采用Box-Cox變換進行優化,建立特征價格模型,并以武漢市新建商品住宅為例進行住宅價格指數編制。
1 武漢市房地產特征價格模型的建立
1.1 指標選取和數據描述
基于國內外研究經驗及武漢市的城市特點,結合數據獲取的難易程度,本文從住宅的區位特征、建筑特征、環境特征三方面綜合選取了22個特征因素,加上時間變量,共量化為26個特征變量。具體解釋如下頁表1所示:
1.2 數據來源
(1)網簽數據。房管部門備案登記的武漢市2015年1月至2016年5月期間的網簽數據。網簽數據中包含的特征變量有:住房價格、住房區位、所在樓層、層高類別和建筑結構。(2)國家統計局房價信息管理系統數據。包含的特征變量主要有:綠化率、容積率、車位比、開盤時間。(3)實地調查取得的補充數據。網簽數據只能提供部分特征變量值,考慮到數據搜集的可操作性和數據的可獲得性,通過抽樣調查的方法補充網簽和房價信息管理系統無法直接提供的特征值。主要包括樓盤交通情況、教育資源、休閑環境、商業環境等。
1.3 數據整理
1.3.1 分層抽樣選取實地調查樣本
采用精度控制下分層簡單隨機抽樣的方法,在有網簽數據的1707個樓盤中抽選94個樣本樓盤。抽樣方法如下:①精度控制:以1707個樓盤17個月網簽數據為總體,控制總量指標的抽樣精度,要求在95%的概率保證程度下,樓盤價格的最大相對誤差控制在5%以內。②數據清理:在抽樣之前,剔除網簽數據中保障性住宅、存在明顯登記錯誤的記錄、累計銷售套數在200以下和每月均價4000元以下的樓盤。③樣本抽選:以各樓盤17個月成交均價為依據,采用累計平方根法確定分層界限,共分為5層,確定出本文所需樣本數為94個。分配結果如下頁表2所示。采用“永久隨機數”方法抽取樣本。
1.3.2 實地調查收集數據
根據建模指標設置需要,設計調查問卷,通過到有關部門走訪和樣本樓盤實地調研,了解商品住宅樓盤特征值。
1.3.3 數據整理和補缺
整合多渠道獲得的數據,形成規范、統一、準確的數據庫。由于部分樓盤在17個月的時間跨度中存在少數月份無銷售的現象,造成該月價格缺失。在所抽取的94個樓盤17個月共1598個價格值中,缺失價格81個,占總量的5%,使用整理后的標準化未缺失房價數據和對應的特征值數據,運用人工神經網絡方法進行建模。
1.3.4 數據標準化處理
對數據進行標準化處理主要為了避免數據性質不同和數據不可比的問題。不同性質和不可比指標直接加總不能正確反映不同作用力的綜合結果,須先考慮改變逆指標數據性質,使所有指標對模型的作用力同趨化。代表異質性商品的基本功能;X為住房的n個特征;β為各個特征所對應的特征價格;t為反映住房價格中時間影響的系數;Dt為住房在t期的啞元變量;ε為隨機誤差項。
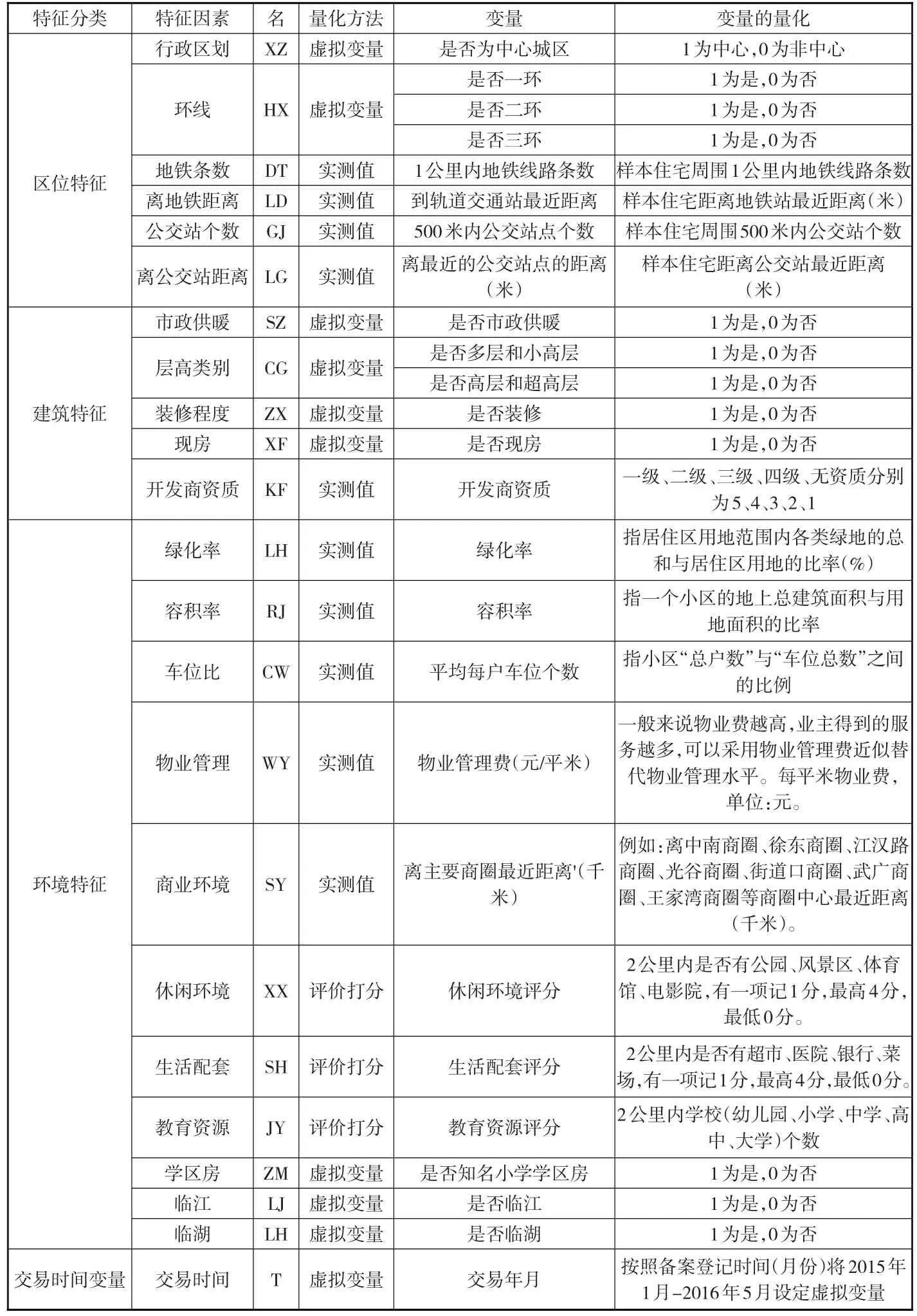
表1 特征價格模型常用解釋變量

表2 分層抽樣每層所需樣本數
1.4.1 模型形式選取
本文首先構建Hedonic模型的線性、對數和半對數形式。由表3可知,總體來看,半對數形式的Hedonic模型最優,因此,本文選擇半對數Hedonic模型繼續進行指數測算。
半對數Hedonic模型的擬合優度檢驗:方程的相關系數為0.928,調整后的判定系數R2為0.859,模型能夠解釋因變量差異的85.9%。該模型在特征價格擬合程度上具有良好的解釋能力。
回歸模型總體顯著性檢驗:方差分析的檢驗統計量F值為407.434,在概率小于0.01拒絕自變量系數均為0的原假設下,表明進入模型的自變量對因變量的共同影響具有顯著性,回歸方程總體有效。
1.4.2 特征變量顯著性檢驗
基于構建的半對數形式Hedonic模型,對選取的26個變量進行顯著性檢驗,結果見下頁表4。

表3 三種形式的Hedonic模型統計量對比
除“學校個數”、“休閑得分”、“生活得分”和“離最近公交站點距離”外,其他特征變量的回歸系數在10%顯著水平下均
1.4 Hedonic模型的建立和選取
一般而言,Hedonic模型有線性、半對數、對數和Box-Cox變換等多種形式,在構建模型過程中,通過測算選出擬合度較好的模型形式。特征價格法基本模型如下:

其中,p為異質性商品的市場價格;c為模型常數項,能通過t檢驗,表明模型中所選的特征變量具有較好的顯著性。
多重共線性檢驗:各特征變量的方差膨脹因子VIF均小于5,絕大多數小于2,可以認為模型中不存在明顯的多重共線性問題。
由半對數形式模型運算得到殘差圖,模型的殘差近似正態分布,構建的半對數Hedonic模型對武漢市的住宅價格具有較高的擬合優度和較好的解釋能力,可以解釋該市樓盤特征變量對住宅價格的影響。

表4 半對數Hedonic模型系數的顯著性檢驗
1.4.3 分月價格指數的計算
(1)確定標準住宅。標準住宅代表著市場上住宅的普遍水平,標準住宅的選取,是消除住宅異質性的關鍵。樣本樓盤在選取時充分考慮了代表性,本文以考察的17個月中各個特征變量的平均值作為市場存在的普遍水平,代表本區域房地產市場的標準住宅。
(2)測算指數對比。把標準住宅的各個特征值代入17個分月半對數Hedonic模型,得到各月的標準住宅價格。17個標準住宅價格消除了住宅價格的異質性(特征差異),具有同質可比性,當月價格比上月價格即可得到當月房地產價格環比指數,見表5。

表5 2015年1月至2016年5月武漢市商品住宅特征價格指數計算結果

圖1半對數Hedonic模型編制環比與國家公布指數對比
通過半對數Hedonic模型測算,所得環比指數呈震蕩上行態勢,幅度在-5.7%~6.9%之間波動。國家統計局每月公布環比指數處于溫和上漲態勢,漲幅在0%~2.3%之間。對比發現(見圖1)半對數Hedonic模型測算結果與國家公布數據總體趨勢一致,17個月測算環比指數圍繞國家統計局公布指數上下波動,少數月份與公布指數完全吻合,超五成月份與公布指數漲跌趨勢存在一定差異。對于存在的這種差異,將進一步通過Box-Cox變換進行優化,以達到更優的效果。
1.5 模型優化
將半對數形式的因變量進行Box-Cox變換,運用R軟件,可以得到λ最優值,其最優值為λ=-0.15。回歸結果顯示,Box-Cox變換的半對數形式模型回歸結果中,各特征變量系數基本與預期影響相符,在10%的顯著性水平下,26個變量中除“周圍1公里軌道交通條數”、“總層高”和“平均每戶車位個數”三個特征變量外,其余特征變量均具有較好的顯著性。
擬合優度檢驗結果表明,回歸模型的相關系數為0.89,調整后的判定系數R2=0.789,表明模型能夠解釋因變量差異的78.9%,擬合程度較好。
回歸模型的總體顯著性檢驗表明,方差分析檢驗統計量F值為260,在概率小于0.01拒絕自變量系數均為0的原假設下,表明進入模型的自變量對因變量的共同影響具有顯著性,回歸方程總體有效。
多重共線性檢驗結果表明,各自變量的方差膨脹因子均小于5,表明模型中不存在明顯的多重共線性。模型殘差近似正態分布。
綜上所述,構建的武漢市商品住宅Box-Cox變換的半對數形式特征價格模型具有良好的擬合優度和較高的解釋能力,各特征變量的回歸系數具有統計意義上的顯著性,通過統計檢驗,可以用來分析住宅特征變量對住宅價格的影響。
按照上述各步驟,可以得出武漢市17個月的分月住宅特征價格模型。
下頁圖2是采用半對數和Box-Cox變換的半對數模型編制出的住宅價格指數與國家公布指數的比較。通過Box-Cox變換的半對數模型測算所得環比指數呈震蕩上行態勢,幅度在-3.92%~5.14%之間波動,與之前的半對數模型相比變化幅度縮小,17個月環比指數據中超五成月份與國家公布指數漲跌趨勢一致,整體來看更接近國家公布的環比指數趨勢。

圖2不同方法編制的住宅價格指數比較
2 結論和展望
2.1 主要結論
(1)數據來源更加全面準確有效。本模型以武漢市房管局提供的網簽數據為基礎,比網絡搜索和網絡爬蟲方法獲取的數據更為準確。通過實地采訪調研的方式獲取樓盤特征值,補充網簽數據無法提供的房地產特征,構建了較為完整的住宅價格特征變量體系。采用在一定精度控制保證下分層抽樣方法抽取樓盤樣本,確保了實地調查樣本的代表性。
(2)對特征價格模型的線性、半對數、對數、Box-cox變換模型形式進行對比分析。在真實的市場交易中,住宅價格受多方面因素共同影響,與各個特征變量之間并不是簡單的線性關系,因此,本文在線性模型的基礎上引進了半對數、對數和Box-Cox變換模型,更全面地考量了住宅價格和各個特征變量之間的關系。
(3)以樓盤為樣本單位,避免了以個體住宅為樣本的缺陷。樓盤均價能較好地反映住宅價格分布結構。當前,國內外研究多以住宅為樣本單位,這種做法存在一定缺陷。一是住宅的朝向、景觀等特征值收集困難;二是若某研究時間段內,具有同一特征因素的住宅銷售量占比過大時,該特征值會產生較大影響,造成這些特征值相關度過大。以樓盤為研究對象可以平滑影響。
2.2 研究展望
本文為研究城市住宅價格提供了一種統計技術上的有益探索,但離全面深入運用Hedonic模型編制住宅價格指數還有一段距離,因此對Hedonic模型及其應用的研究還得繼續。第一,本文在建模時樓盤價格仍使用混合平均價,沒有實現用樓盤標準價進入模型,在后續研究中,將進一步探索用樓盤標準價進行建模測算;第二,可嘗試非參數、半參數等多種參數估計方法在模型中的運用;第三,進一步探索對大數據的匹配、篩選、挖掘等預處理的有效方法。
參考文獻:
[1]Case B,Pollakowski H O,Wachter S M.On Choosing Among House Price Index Methodologies[J].AREUEA Journal,1991,19(3).
[2]程亞鵬.基于住房子市場的Hedonic住房價格指數[J].經濟問題,2010,(10).
[3]李占風,周歆毅.我國房地產價格的統計方法研究[J].統計與決策,2012,(8).
[4]孫玉環.基于海量交易數據的房地產特征價格模型的構建[J].統計與決策,2011,(10).
[5]程亞鵬.我國城市住宅價格測試—Hedonic方法與實證[M].北京:光明日報出版社,2013.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
